
Stuart Reid
Нейронные сети – один из самых популярных классов алгоритмов для машинного обучения. В финансовом анализе они чаще всего применяются для прогнозирования, создания собственных индикаторов, алгоритмического трейдинга и моделирования рисков. Несмотря на все это, репутация у нейронных сетей подпорчена, поскольку результаты их применения можно назвать нестабильными.
Количественный аналитик хедж-фонда NMRQL Стюарт Рид в статье на сайте TuringFinance попытался объяснить, что это означает, и доказать, что все проблемы кроются в неадекватном понимании того, как такие системы работают. Мы представляем вашему вниманию адаптированный перевод его статьи.
1. Нейронная сеть – это не модель человеческого мозга
Человеческий мозг – одна из самых больших загадок, над которой бьются ученые не одно столетие. До сих пор нет единого понимания, как все это функционирует. Есть две основные теории: теория о «клетке бабушки» и теория дистрибутивного представительства. Первая утверждает, что отдельные нейроны имеют высокую информационную вместимость и способны формировать сложные концепты. Например, образ вашей бабушки или Дженнифер Энистон. Вторая говорит о том, что нейроны намного проще в своем устройстве и представляют комплексные объекты лишь в группе. Искусственную нейронную сеть можно в общих чертах представить как развитие идей второй модели.
Огромная разница ИНС от человеческого мозга, помимо очевидной сложности самих нейронов, в размерах и организации. Нейронов и синапсов в мозгу несоизмеримо больше, они самостоятельно организуются и способны к адаптации. ИНС конструируют как архитектуру. Ни о какой самоорганизации в обычном понимании не может быть речи.

Что из этого следует? ИНС создаются по архетипу человеческого мозга в том же смысле, как олимпийский стадион в Пекине был собран по модели птичьего гнезда. Это ведь не означает, что стадион – это гнездо. Это значит, что в нем есть некоторые элементы его конструкции. Лучше говорить о сходстве, а не совпадении структуры и дизайна.
Нейронные сети, скорее, имеют отношение к статистическим методам – соответствия кривой и регрессии. В контексте количественных методов в финансовой сфере заявка на то, что нечто работает по принципам человеческого мозга, может ввести в заблуждение. А в неподготовленных умах вызвать страх угрозы вторжения роботов и прочую фантастику.

Пример кривой, также известной как функция приближения. Нейронные сети очень часто используют для аппроксимации сложных математических функций
2. Нейронная сеть – не упрощенная форма статистики
Нейронные сети состоят из слоев соединенных между собой узлов. Отдельные узлы называются перцептронами и напоминают множественную линейную регрессию. Разница в том, что перцептроны упаковывают сигнал, произведенный множественной линейной регрессией, в функцию активации, которая может быть как линейной, так и нелинейной. В системе со множеством слоев перцептронов (MLP) перцептроны организованы в слои, которые в свою очередь соединены друг с другом. Есть три типа слоев: слои входных данных и выходных сигналов, скрытые слои. Первый слой получает паттерны входных данных, второй может поддерживать список классификации или сигналы вывода в соответствии со схемой. Скрытые слои регулируют веса входных данных, пока риски ошибки не сводятся к минимуму.
Картирование инпутов/аутпутов
Перцепторы получают векторы входных данных — z=(z1,z2,…,zn) из n атрибутов. Вектор называется входным паттерном (input pattern). Вес такого «инпута» определяется весом вектора, принадлежащего к этому перцептрону — v=(v1,v2,…,vn). В контексте множественной линейной регрессии это можно представить как коэффициент регрессии. Сигнал перцептрона в сети, net, обычно складывается из входного паттерна и его веса.
![]()
Сигнал минус смещение θ затем преобразуется в некую активационную функцию. Обычно это монотонно возрастающая функция с границами (0,1) или (-1,1). Некоторые наиболее популярные функции представлены на картинке:
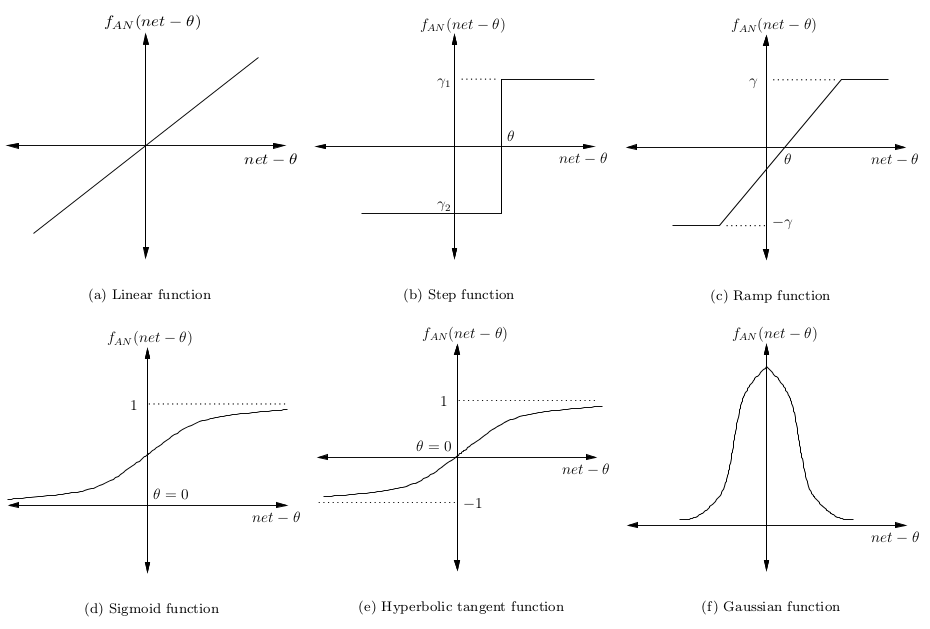
Простейшая нейронная сеть – так, которая имеет лишь один нейрон, картирующий входные сигналы в выходные.
Создание слоев

Как видно из рисунка, перцептроны организованы в слои. Первый слой, который позже получит название входного, получает паттерн p в процессе обучения – Pt. Последний слой привязан к ожидаемым выходным сигналам для этих паттернов. Паттерны могут быть величинами разных технических индикаторов, а потенциальные выходные сигналы могут быть категориями {BUY,HOLD,SELL}.
Скрытый слой – тот, который получает инпуты и аутпуты от другого слоя и формирует аутпуты для следующего. По одной из версий, скрытые слои извлекают выступающие элементы из входящих данных, которые имеют значение для предсказания результата. В статистике такая техника зовется первичным компонентным анализом.
Глубокая нейронная сеть имеет большое количество скрытых слоев и способна извлекать больше подходящих элементов данных. Недавно их с успехом использовали для решения проблем распознавания образов.
В задачах трейдинга при использовании глубоких сетей есть одна проблема: данные на входе уже подготовлены и может быть сразу несколько элементов, которые необходимо извлечь.
Правила обучения
Задача нейронной сети минимизировать степень ошибки ϵ. Обычно этот показатель рассчитывается как сумма квадратов ошибок. Хотя такой вариант может быть чувствителен к постороннему шуму.

Для наших целей мы можем использовать алгоритм оптимизации, чтобы приспособить показатели веса к сети. Чаще всего для обучения сети применяют алгоритм градиентного спуска. Он работает через калькуляцию частичных дериватов ошибок с учетом их веса для каждого слоя и затем двигается в обратном направлении по уклону. Минимизируя ошибку, мы увеличиваем производительность сети в выборке.
Математически это правило обновления можно выразить в следующей формуле:

η – частота обучения, отвечающая за то, как быстро или медленно сеть конвергируется. Выбор частоты обучения имеет серьезные последствия в плане производительности нейронной сети. Маленькое значение приведет к медленной конвергенции, большое может привести к отклонениям в обучении.
Итак, нейронная сеть – это не есть упрощенная форма статистики для ленивых аналитиков. Это некая выдержка серьезных статистических методов, применяемых уже сотни лет.
3. Нейронная сеть может быть исполнена в разной архитектуре
До этого момента мы рассуждали о самой примитивной архитектуре нейронной сети – системе многоуровневых перцептронов. Есть еще множество вариантов, от которых зависит производительность. Современные достижения в изучении машинного обучения связаны не только с тем, как работают оптимизационные алгоритмы, но как они взаимодействуют с перцептронами. Автор предлагает рассмотреть наиболее интересные, с его точки зрения, модели.
Рекуррентная нейронная сеть: у нее некоторые или все соединения отыгрывают назад. По сути, это принцип технологии Feed Back Loop (уведомление провайдера сервису рассылки при наборе критического числа жалоб на спам). Считается, что такая сеть лучше работает на серийных данных. Если так, то этот вариант вполне уместен в отношении финансовых рынков. Для более подробного ознакомления нам предлагают почитать вот эту статью.

На диаграмме изображены три популярных архитектуры нейронных сетей
Последний из придуманных вариантов архитектуры рекуррентной нейронной сети – нейронная машина Тьюринга. Она объединяет архитектуру стандартной сети с памятью.
Нейронная сеть Больцмана – одна из первых полностью связанных нейронных сетей. Она одной из первых была способна обучаться внутренним представлениям и решать сложные задачи по комбинаторике. Про нее говорят, что это версия Монте-Карло рекуррентной нейронной сети Хопфилда. Ее сложнее обучать, но если поставлены ограничения, то она эффективней традиционной сети. Самое распространенное ограничение в отношении сети Больцмана – запрет на соединения между скрытыми нейронами. Собственно, еще один вариант архитектуры.
Глубокая нейронная сеть – сеть со множеством скрытых слоев. Такие сети стали крайне популярны в последние годы, из-за их способности с блеском решать проблемы по распознаванию голоса и изображения. Число архитектур в данном варианте растет небывалыми темпами. Самые популярные: глубокие сети доверия, сверточные нейронные сети, автокодировщики стэка и прочее. Самая главная проблема с глубокими сетями, особенно в случае с финансовым анализом, — переобучение.
Адаптивная нейронная сеть одновременно адаптирует и оптимизирует архитектуру в процессе обучения. Она может наращивать архитектуру (добавлять нейроны) или сжимать ее, убирая ненужные скрытые нейроны. По мнению автора, эта сеть лучше всего подходит для работы на финансовых рынках, потому что сами эти рынки не стационарны. То есть сеть способна подстраиваться под динамику рынка. Все, что было здорово вчера, не факт, что будет оптимально работать завтра.

Два типа адаптивных нейронных сетей: каскадная и самоорганизующаяся карта
Радиально-базисная сеть – не то чтобы отдельный тип архитектуры в плане размещения соединений и перцептронов. Здесь в качестве активирующей функции используется радиально-базисная функция, чьи аутпуты зависят от расстояния от конкретной точки. Самое распространенное применение этой функции – гауссовское распределение. Она также используется как ядро в векторной машине поддержки.
Проще всего – попробовать несколько вариантов на практике и выбрать наиболее подходящий под конкретные задачи.
4. Размер имеет значение, но больше – не всегда значит лучше
После выбора архитектуры возникает вопрос, насколько большой или насколько небольшой должна быть нейронная сеть? Сколько должно быть «инпутов»? Сколько нужно использовать скрытых нейронов? Скрытых слоев (в случае с глубокой сетью)? Сколько «аутпутов» нужно нейронам? Если мы промахнемся с размером, сеть может пострадать от переобучения или недообучения. То есть не будет способна грамотно обобщать.
Сколько и какие инпуты нужно использовать?
Число входных сигналов зависит от решаемой проблемы, количества и качества доступной информации и, возможно, некоторой доли креатива. Выходные сигналы – это простые переменные, на которые мы возлагаем некие предсказательные способности. Если входные данные к проблеме не ясны, можно определять переменные для включения через систематический поиск корреляций и кросс-корреляций между потенциальными независимыми переменными и зависимыми переменными. Этот подход детально рассматривается в этой статье.
С использованием корреляций есть две основные проблемы. Во-первых, если вы используете метрику линейной корреляции, вы можете непреднамеренно исключить нужные переменные. Во-вторых, две относительно не коррелированных переменных могут быть потенциально объединены для получения одной хорошо коррелированной переменной. Когда вы смотрите на переменные изолировано, вы можете упустить эту возможность. Здесь можно использовать основной компонентный анализ для извлечения полезный векторов в качестве входных сигналов.
Другая проблема при выборе переменных – мультиколлинеарность. Это когда две или более переменных, загруженных в модель, имеют высокую корреляцию. В контексте регрессивных моделей это может вызвать хаотичные изменения регрессивного коэффициента в ответ на незначительные изменения в модели или в данных. Учитывая то, что нейронные сети и регрессионные модели схожи, можно предположить, что та же проблема распространяется на нейронные сети.
Еще один момент связан с тем, что за выбранные переменные принимают пропущенные отклонения в переменных. Они появляются, когда модель уже сформирована, а за бортом осталась парочка важных каузальных переменных. Отклонения проявляют себя, когда модель получает неверное возмещение отсутствующим переменным через переоценку или недооценку других переменных.
Сколько необходимо скрытых нейронов?
Оптимальное число скрытых элементов – специфическая проблема, решаемая опытным путем. Но общее правило: чем больше скрытых нейронов – тем выше риск переобучения. В этом случае система не изучает возможности данных, а как бы запоминает сами паттерны и любой содержащийся в них шум. Такая сеть отлично работает на выборке и плохо за пределами выборки. Как можно избежать переобучения? Есть два популярных метода: ранняя остановка и регуляризация. Автор предпочитает свой, связанный с глобальным поиском.
Ранняя остановка предполагает разделение процесса обучения на этапы самого обучения и валидации результатов. Вместо того чтобы обучать сеть на ограниченном числе итераций, вы обучаете ее пока производительность сети на этапе подтверждения не начинает падать. По-существу, это не дает сети использовать все доступные параметры и ограничивает способности к простому запоминанию паттернов. Ниже показаны две возможные точки остановки:

Еще одна картинка показывает производительность и степень переобучение сети при остановке в этих точках a и b:

Регуляризация штрафует нейронную сеть за использования усложненной архитектуры. Сложность в данном случае измеряется размером и весом сети. Она устанавливается через добавление интервала к функции ошибки, который привязан к весу и размеру. Это то же самое, что добавление приоритета, который заставляет поверить нейронную сеть функцию на однородность.

n- это число нагрузок (весов) в нейронной сети. Параметры α и β контролируют уровень, после которого наступает недообучение или переобучение сети. Подходящие значения для них можно подобрать через Байесовский анализ и оптимизацию.

Другая техника, довольно дорогостоящая в плане вычислений, — глобальный поиск. Здесь алгоритм поиска используется для дифференциации архитектуры сети и нахождения ее оптимального варианта. Обычно для этого берут алгоритм генерации, о котором будет сказано ниже.
Что такое «аутпуты»?
Нейронную сеть можно использовать для регрессии или классификации. В первой модели мы работаем с единичным значением на выходе. То есть нужен всего один нейрон выхода. Во второй модели нейрон выхода нужен для каждого класса, к которому может принадлежать паттерн, в отдельности. Если классы не известны – используются самоорганизующиеся карты.
Подытожим эту часть рассказа. Лучший подход для определения размера сети – следовать принципу Оккама. То есть для двух моделей с одинаковой производительностью, модель с меньшим количеством параметров будет генерализировать успешней. Это не значит, что нужно обязательно выбирать простую модель в целях повысить производительность. Верно обратное утверждение: множество скрытых нейронов и слоев не гарантирует превосходство. Слишком много внимание сегодня уделяется большим сетям, и слишком мало самим принципам их разработки. Больше – не всегда лучше.
5. К нейронной сети применимо множество обучающих алгоритмов
Обучающий алгоритм призван оптимизировать вес нейронной сети, пока не наткнется на некое условие остановки. Это может быть связано с появлением ошибки в тренировочном сете на приемлемом уровне точности (например, когда работа сети на этапе валидации начинает ухудшаться). Это может быть точка, когда израсходован некий вычислительный бюджет сети. Самый популярный вариант алгоритма – метод обратного распространения с использованием градиентного стохастического спуска. Обратное распространение состоит из двух шагов:
— Прямое прохождение: обучающие данные проходят через сеть, записывается выходной сигнал и подсчитываются ошибки.
— Обратное распространение: сигнал ошибки протаскивается обратно через сеть, вес сети оптимизируется с использованием градиентного спуска.
С этим подходом может возникнуть несколько проблем. Подгонка всех весов одновременно может привести к чрезмерному перемещению сети в весовом пространстве. Алгоритм градиентного спуска довольно медленный и восприимчив к локальному минимуму. Локальный минимум – специфическая проблема для определенных нейронных сетей. Первая проблема решаема через использования разных вариантов градиентного спуска: (QuickProp), Nesterov’s Accelerated Momentum (NAG), Adaptive Gradient Algorithm (AdaGrad), Resilient Propagation (RProp) или Root Mean Squared Propagation (RMSProp).

Но все эти алгоритмы не могут преодолеть локальный минимум, и менее полезны, когда пытаются одновременно оптимизировать архитектуру и нагрузку сети. Нужен алгоритм глобальной оптимизации. Это может быть метод роя частиц (Particle Swarm Optimization) или генетический алгоритм. Вот, как это работает.
Векторное представление нейронной сети кодирует нейронную сеть по вектору нагрузки, каждый из векторов представляет вес соединения в сети. Мы можем обучать сеть, используя мета-эвристический поисковой алгоритм. На слишком больших сетях метод работает плохо, потому что сами векторы становятся слишком большими.

На диаграмме показано, как нейронная сеть может быть представлена в векторной нотации
Метод роя частиц обучает сеть через построение популяции/роя. Каждая нейронная сеть здесь представлена как вектор нагрузки и скорректирована по отношению к позиции глобальной лучшей частицы и ее собственной лучшей позиции.
Эта функция приспособления просчитывается как сумма квадратов ошибок реконструированной нейронной сети после завершения одного прямого прохождения. Выгоду получаем на оптимизации скорости обновления весов связей. Если весы будут регулироваться слишком быстро, сумма квадратов ошибок стагнирует, обучение не происходит.
Генетический алгоритм строит популяцию вектора, представляющего нейронную сеть. Далее с ней проводятся три последовательные операции для улучшения работы сети:
— Выборка: после каждого прямого прохождения подсчитывается сумма квадратов ошибок, популяция нейронной сети ранжируется. Верхний процент популяции выбирается для выживания и используется для кроссовера.
— Кроссовер: верхний x% генов популяции соревнуется между собой, получаем некое новое потомство, каждое потомство представляет, по сути, новую нейронную сеть.
— Мутация: этот оператор требует поддержки генетического разнообразия в популяции, небольшой процент ее отбирается для прохождения мутации, то есть некоторые весы сети будут регулироваться случайно.
6. Нейронным сетям не всегда нужен большой объем данных
Нейронные сети могут использовать три основных обучающих стратегии: контролируемое обучение, неконтролируемое и усиленное обучение. Для первой, нужны, по крайней мере, два обучающих сета данных. Один из них будет состоять из входных с ожидаемыми выходными сигналами, второй с входными без ожидаемых выходных. Оба должны включать маркированные данные, то есть паттерны с изначально неизвестным предназначением.
Неконтролируемая стратегия обычно используется для выявления скрытых структур в немаркированных данных (например, скрытых цепей Маркова). Принцип работы тот же, что и у кластерных алгоритмов. Усиленное обучение основано на простом допущении о наличие выигрышных сетей и помещении их в плохие условия. Два последних варианта не подразумевают использование маркированных данных, поэтому правильный выходной сигнал здесь неизвестен.
Неконтролируемое обучение
Одна из самых популярных архитектур для такого типа сети – самоорганизующаяся карта. По сути, это техника масштабирования в нескольких измерениях, которая конструирует приближение функции плотности вероятности какого-либо основного цикла данных. Z – сохраняет топологическую структуру сета данных, картируя векторы входных сигналов – zi. Она взвешивает векторы — vj, в будущей карте V. Сохранение топологической структуры означает, что, если два вектора стоят близко друг к другу в Z, нейроны, к которым они относятся, также будут расположены в V. Более подробно можно почитать здесь.
Усиленное обучение
Эта стратегия состоит из трех компонентов: установки на то, как нейронная сеть будет принимать решения, используя технические и фундаментальные индикаторы, функции достижения цели, которая отделяет зерна от плевел, и функции значения, нацеленной на перспективу.
7. Нейронную сеть нельзя обучить на любых данных
Одна из главных проблем, почему нейронная сеть может не работать, заключается в том, что нередко данные плохо готовят перед загрузкой в систему. Нормализация, удаление избыточной информации, резко отклоняющихся значений должны проводиться перед началом работы с сетью, чтобы улучшить ее производственные возможности.
Мы знаем, что у нас есть слои перцептронов, соединенных по весу. Каждый перцептрон содержит функцию активации, который, в свою очередь, разделены по рангу. Входные сигналы должны быть масштабированы, исходя из этого ранга, чтобы сеть могла различать входные паттерны. Это предпосылки для нормализации данных.
Резко выделяющиеся значения или намного больше или намного меньше большинства других значений в наборе данных для сета. Такие вещи могут вызвать проблемы в применении статистических методов – регрессии и подгонки кривой. Потому что система постарается приспособить эти значения, производительность ухудшится. Выявить такие значения самостоятельно может быть проблематично. Здесь можно посмотреть инструкцию по техникам работы с резко отклоняющимися значениями.
Внесение двух или более независимых переменных, которые близко коррелируют друг с другом также может вызвать снижение способности к обучению. Удаление избыточных переменных, ко всему прочему, ускоряет время обучения. Для удаления избыточных соединений и перцептронов можно использовать адаптивные нейронные сети.
8. Нейронные сети иногда требуется обучать заново
Даже если вы настроили должным образом нейронную сеть, и она торгует успешно в выборке и за ее пределами, еще не значит, что через некоторое время она не перестанет работать. Дело не в ней, дело в том, как ведет себя финансовый рынок. Финансовые рынки – комплексные адаптивные системы. То, что работает сегодня, может не работать завтра. Эту их характеристику называют нестационарностью или динамической оптимизацией. Нейронные сети пока не умеют с этим справляться.
Динамическая среда финансовых рынков очень сложная штука для моделирования нейронной сетью. Есть два выхода из ситуации: время от времени переобучать сеть или использовать динамическую нейронную сеть. Она призвана отслеживать изменения в среде по времени и приспосабливать их к архитектуре и нагрузке системы. Для решения динамических проблем можно использовать многосторонние мета-эвристические алгоритмы оптимизации. Они будут отслеживать изменения к локальному опыту по времени. Один из вариантов – оптимизация множественного роя, производная от метода роя частиц. Генетические алгоритмы с улучшенной диверсификацией и памятью также могут быть полезны в динамичной среде.
9. Нейронная сеть – это не черный ящик
Сама по себе нейронная сеть – это «черный ящик». Это создает определенные проблемы для людей, которые работают или планируют с ней работать. Например, фондовые управляющие не понимают, как система принимает решения по финансовым операциям. Отсюда получается, что нельзя рассчитать риск трейдинговой стратегии, которой обучилась сеть. Опять же банки, использующие нейронную сеть для просчетов кредитных рисков, не могут верифицировать ее позиции по кредитному рейтингу для тех или иных клиентов. Для этих целей были придуманы алгоритмы извлечения правил работы сети. Знания могут быть вытащены из сети в виде математических формул, символической логики, нечеткой логики, дерева решений.

Математические правила: некоторые алгоритмы позволяют извлекать множественные строки линейной регрессии. Проблема в том, что зачастую они понятны только в контексте работы «черного ящика».
Пропозициональная логика: раздел математической логики, который имеет дело с дискретными значениями переменных. Эти переменные A и B чаще всего имеют значения «верно» — «неверно», но также могут иметь значения дискретного уровня – «покупать, «удерживать», «продавать».
К ним применимы логические операции: OR, AND и XOR. Результаты этих операция называются предикатами, количественные значения которых также можно рассчитать. Между предикатами и пропозициональной логикой есть различие. Если у нас простая нейронная сеть с ценой (P), простым скользящим средним (SMA), экспоненциальным скользящим средним (EMA) в качестве входных сигналов, и мы хотим извлечь тренд стратегии в пропозициональной логике, мы действуем по следующим правилам:

Нечеткая логика (fuzzy logic) – это то место, где встречается вероятность и пропозициональная логика. Последняя имеет дело с абсолютами – «купить», «продать», «верно», «неверно», 0 или 1. Трейдер никак не может подтвердить подлинность этих результатов. Нечеткая логика преодолевает это ограничение, вводя функцию членства, обозначающую принадлежность переменной к определенной области, домену. Например, компания (GOOG) имеет значение 0,7 в домене BUY и 0,3 в домене SELL. Комбинация такой логики и нейронной сети называется нейро-нечеткая система.
Дерево решений показывает, как принимаются решения при загрузке определенной информации. В этой статье можно почитать, как построить анализ безопасности дерева решения, используя генетическое программирование.

Пример простой стратегии онлайн-трейдинга, представленной в виде дерева решений. Треугольники представляют узлы решений (например, BUY, HOLD или SELL для покупки, удержания или продажи акций). Каждый элемент представляет собой пару
![]()
10. Нейронную сеть создать и применить нетрудно
Если говорить о практике, создать нейронную сеть с нуля довольно проблематично. К счастью, сейчас существуют сотни пакетов с открытым доступом, которые делают работу с нейронными сетями немного проще. Ниже приведен список таких пакетов, которые можно пользовать в количественном анализе в финансовой сфере. Список далеко не полный, инструменты даны в алфавитном порядке.
Caffe
Сайт — http://caffe.berkeleyvision.org/
Репозиторий на GitHub — https://github.com/BVLC/caffe
Encog
Сайт — http://www.heatonresearch.com/encog/
Репозиторий на GitHub — https://github.com/encog
H2O
Сайт — http://h2o.ai/
Репозиторий на GitHub — https://github.com/h2oai
Google TensorFlow
Сайт — http://www.tensorflow.org/
Репозиторий на GitHub — https://github.com/tensorflow/tensorflow
Microsoft Distributed Machine Learning Tookit
Сайт — http://www.dmtk.io/
Репозиторий на GitHub — https://github.com/Microsoft/DMTK
Microsoft Azure Machine Learning
Сайт — https://azure.microsoft.com/en-us/services/machine-learning
Репозиторий на GitHub — github.com/Azure?utf8=%E2%9C%93&query=MachineLearning
MXNet
Сайт — http://mxnet.readthedocs.org/en/latest/
Репозиторий на GitHub — https://github.com/dmlc/mxnet
Neon
Сайт — http://neon.nervanasys.com/docs/latest/index.html
Репозиторий на GitHub — https://github.com/nervanasystems/neon
Theano
Сайт — http://deeplearning.net/software/theano/
Репозиторий на GitHub — https://github.com/Theano/Theano
Torch
Сайт — http://torch.ch/
Репозиторий на GitHub — https://github.com/torch/torch7
SciKit Learn
Сайт — http://scikit-learn.org/stable/
Репозиторий на GitHub — https://github.com/scikit-learn/scikit-learn
Заключение
Нейронные сети – это класс мощных алгоритмов машинного обучения. В их основе лежат статистические методы анализа. Вот уже много лет их с успехом применяют к разработке стратегий трейдинга и финансовых моделей. Несмотря на это, у нейронных сетей не очень хорошая репутация, основанная на неудачах практического применения. В большинстве случаев причины неудач лежат в неадекватных конструкторских решениях и общем непонимании того, как они работают. В этой статье автор попытался артикулировать лишь некоторые из самых распространенных заблуждений в надежде, что кому-нибудь эта информация пригодится в реальной практике.

1. Какой пункт из нижеперечисленных не является истинным?
- Искусственный интеллект – это комплекс технологических решений, имитирующий когнитивные функции человека
- Искусственный интеллект получает в наследство убеждения и стереотипы своих создателей
- Искусственный интеллект помогает бороться с коронавирусом
- Близкий к бесконечному интеллект сможет быстро разрешить все наши проблемы
2. Расставьте следующие понятия об областях знаний ИИ в хронологической последовательности возникновения терминов
- Машинное обучение, глубокое обучение, искусственный интеллект
- Искусственный интеллект, машинное обучение, глубокое обучение
- Глубокое обучение, машинное обучение, искусственный интеллект
3. Сколько определений искусственного интеллекта существует?
- Ни одного
- Одно
- Несколько
4. Что не входит в рамки возможностей искусственного интеллекта на современном этапе?
- Саморазвитие
- Предсказание
- Классификация объектов
5. Выберите верные утверждения:
- ИИ активно применяется в сельском хозяйстве, медицине, финансах, промышленности, робототехнике и других сферах.
- Для оплаты московского метро с помощью биометрии используются технологии распознавания речи
- Оба утверждения неверны
- Верно только первое утверждение
- Верно только второе утверждение
- Верны оба утверждения
6. Выберите один или несколько правильных вариантов ответа
- Искусственный интеллект – это раздел машинного обучения
- Глубокое обучение включает в себя искусственный интеллект
- Искусственный интеллект включает в себя машинное обучение
7. Что такое Deep Fake?
- Выдача неправильных прогнозов нейросетями
- Публикация пропагандистских текстов в социальных сетях
- Замена нейросетями лиц на изображениях и в видео
8. Какое приблизительное количество нейронных клеток в человеческом мозге?
- 100 миллионов
- 10 миллиардов
- 100 миллиардов
9. Что такое «демократизация искусственного интеллекта»?
- Упрощение использования технологий искусственного интеллекта
- Использование технологий искусственного интеллекта для выборов в органы власти
10. Какой пункт из нижеперечисленных не является целью этичного искусственного интеллекта? ИИ должен быть:
- Подконтролен и полезен обществу
- Безопасен для человека
- Надежен в эксплуатации и предсказуем в действиях
- Все принятые решения и ошибки искусственного интеллекта должны быть прозрачны для понимания и доступны для анализа
- Все принятые искусственным интеллектом решения должны быть наилучшими в текущей ситуации
11. Какой тип нейронных сетей используется для синтеза речи?
- Многослойный персептрон
- Рекуррентная нейронная сеть
- Сверточная нейронная сеть
12. Какие разделы математики используются в машинном обучении? Отметить все подходящие
- Топология
- Статистика
- Линейная алгебра
- Дифференциальное исчисление
13. Какой уровень распознавания картинок у среднестатистического человека?
- 99%
- 95%
- 90%
- 85%
- 80%
14. Выберите из списка виды базового машинного обучения
- Обучение без учителя
- Обучение с руководителем
- Обучение с учителем
- Обучение без руководителя
15. Какая зависимость количества вычислений для обучения нейронной сети от количества ячеек этой сети?
- Линейная
- Степенная
- Экспоненциальная
16. Против какой супер-ЭВМ играл в го Ли Седоль?
- Deep Purple
- Go Pro
- AlphaGo
- Deep Blue
17. Что не было прообразом искусственной нейронной сети?
- Паутинная сеть
- Структура головного мозга
- Компьютерная сеть
18. Какой тип нейронных сетей в основном используется для компьютерного зрения?
- Рекуррентная нейронная сеть
- Сверточная нейронная сеть
- Многослойный персептрон
19. Где уже применяются технологии ИИ? Выберите один или несколько вариантов ответов:
- Распознавание предметов на видео
- Беспилотные летательные аппараты
- Улучшение качества фотографий
- Выявление нежелательных электронных писем (спама)
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
Согласно проведенным исследованиям, искусственные нейронные сети применяются в различных областях науки: начиная от систем распознавания речи до распознавания вторичной структуры белка, классификации различных видов рака и генной инженерии. Когда речь идет о задачах, отличных от обработки больших массивов информации, человеческий мозг обладает большим преимуществом по сравнению с компьютером. Человек может распознавать лица, даже если в помещении будет много посторонних объектов и плохое освещение. Несмотря на годы исследований, компьютеры все еще далеки от выполнения подобных задач на высоком уровне. В решении подобных задач наиболее эффективны искусственные нейронные сети. Искусственные нейронные сети способны генерировать значение из сложных или неточных данных, а так же выполнять задачи аппроксимации, классификации и распознавания, со скоростью и точностью, недостижимых для классических алгоритмов программирования.
Главные достоинства нейронных сетей:
– Эффективная фильтрация шумов. После обучения искусственные нейронные сети способны обрабатывать только нужную им информацию, игнорируя посторонние шумы.
– Адаптация. Возможность адаптации искусственные нейронные сети к изменениям во входных данных позволяет им работать в правильном режиме все время. Непрерывное самообучение – самое важное свойство ИНС.
– Отказоустойчивость. Даже при выходе из строя части нейронов, остальные нейроны остаются работоспособными. И, несмотря на снижение точности работы, ответы, выдаваемые поврежденной искусственной нейронной сетью, остаются логичными и правильными.
– Скорость работы. Каждый из нейронов, по сути, является микропроцессором, но поскольку искусственная нейронная сеть состоит из тысяч таких нейронов, между которыми распределяется задача, ее решение происходит очень быстро – намного быстрее, чем при использовании обычных алгоритмов решения.
Несмотря на все достоинства у ИНС есть и недостатки, которые накладывают ограничение на их использование. [1]
Проблема переобучения.
Данная проблема заключается в том, что ИНС «запоминает» ответы вместо того, чтобы выводить закономерности во входных данных. На сегодняшний день разработано несколько способов борьбы с переобучением: регуляризация, нормализация батчей, наращивание данных и другие. Иногда переобученная модель характеризуется большими абсолютными значениями весов. Суть этого явления следующая: исходные данные часто сильно многомерны (одна точка из обучающей выборки изображается большим набором чисел), и вероятность того, что случайно взятая точка окажется неотличимой от выброса, будет тем больше, чем больше размерность. Вместо того, чтобы «вписывать» новую точку в имеющуюся модель, корректируя веса, ИНС генерирует исключение: одну точку следует классифицировать по одним правилам, а другие – по другим. И таких точек бывает очень много.
Простейший метод борьбы с переобучением – так называемая регуляризация весов. Ее суть состоит в искусственном ограничении на значения весов, либо в добавлении штрафа в меру ошибки на этапе обучения. Такой подход не решает проблему полностью, но помогает улучшить результат.
Второй метод состоит в ограничении выходного сигнала, а не значений весов – это нормализация батчей. На этапе обучения данные подаются в ИНС пачками – батчами. Выходные значения для них могут быть любыми, и чем выше значения весов, тем больше абсолютные значения. Если из каждого из них вычесть какое-то определенное значение и поделить результат на другое, одинаковое для всего батча, то можно сохранить качественные соотношения, но выход будет более удобным для обработки его следующим слоем.
Третий подход – наращивание обучающей выборки. Он работает не всегда. Как уже говорилось, переобученная ИНС воспринимает многие точки как аномальные, которые следует обрабатывать отдельно. Идея заключается в наращивании обучающей выборки, чтобы точки были той же природы, что и исходная выборка, но сгенерированы искусственно. Однако тут сразу рождается большое число сопутствующих проблем: подбор параметров для наращивания выборки, критическое увеличение времени обучения и прочие.
В обособленную проблему выделяется поиск настоящих аномалий в обучающей выборке. Иногда это даже рассматривают как отдельную задачу. На рисунке 1 проиллюстрирован эффект исключения аномального значения из набора. В случае ИНС результат будет таким же. Но поиск и исключение аномальных значений – очень сложная задача, для решения которой применяют специальные методики. [2]
Рисунок 1 – Эффект от удаления аномального значения из тренировочной выборки
Черный ящик.
Еще одна проблема ИНС состоит в том, что они, по сути, являются черными ящиками. То есть кроме результата, из ИНС нельзя получить никакую информацию, даже статистические данные. Из-за этого очень сложно понять, каким образом ИНС принимает решения. Это характерно для большинства типов ИНС, но есть и исключения. Например – сверточные ИНС в задачах распознавания. В этом случае некоторые промежуточные слои имеют смысл карт признаков (одна связь показывает то, встретился ли какой-то простой шаблон в исходной картинке), поэтому возбуждение различных нейронов можно отследить.
Естественно, данная особенность делает достаточно сложным использование ИНС в приложениях, где ошибки критичны. Например, менеджеры фондов не могут понять, как ИНС принимает решения. Из-за этого невозможно корректно оценить риски торговых стратегий. Аналогичная ситуация в банках, использующих ИНС для моделирования кредитных рисков. Они не могут сказать, почему этот самый клиент имеет сейчас именно такой кредитный рейтинг. Поэтому разработчики ИНС пытаются найти способы исправить данный недостаток. Например, ведется разработка так называемых алгоритмов изъятия правил (rule-extraction algorithms), чтобы повысить прозрачность ИНС. Эти алгоритмы извлекают информацию из ИНС либо в виде математических выражений и символьной логики, либо в виде деревьев решений.
Есть несколько способов реализации данного решения. Самый простой – анализ чувствительности. Анализ чувствительности не содержит явных правил, но используется для определения влияния конкретных входных данных на выходные данные ИНС. Общая процедура заключается в записи изменений в выходных данных после внесения изменений в специфические входные атрибуты. Обычно в качестве начальной точки выбирается среднее значение для каждого входа и изменения должны варьироваться от небольших до крайне высоких. Если разница в выходе мала даже при больших изменениях в определенном входном атрибуте, этот атрибут вероятно, не очень важен; то есть ИНС нечувствительна к этому атрибуту. Другие атрибуты могут оказывают большое влияние на выходные данные, значит, ИНС чувствительна к этим атрибутам.
Анализ чувствительности является хорошим инструментом для получения базового понимания функционирования ИНС. Но, к сожалению, анализ чувствительности обычно не позволяет объяснить найденные отношения. Поэтому он используется либо как инструмент для поиска и удаления неважных входных данных, атрибутов, или как отправная точка для другого метода работы с ИНС.
Декомпозиционные подходы сосредоточены на извлечении правил на уровне отдельных блоков в рамках обученной ИНС. Основным требованием для этой категории извлечения правил является то, что вычисленный выход из каждого блока должен быть отображен как двоичный результат, соответствующий следующему правилу.
Каждый блок может быть интерпретирован как ступенчатая функция, что означает, что проблема сводится к поиску набора входящих связей, суммарные веса которых гарантируют превышение смещения блока независимо от других входящих связей. Когда такая комбинация связей найдена, это легко переводится в правило, в котором выход этого блока является следствием входов. Затем правила, извлеченные на отдельном уровне единицы, агрегируются для формирования составного набора правил для ИНС в целом. Самый простой способ понять процесс состоит в том, чтобы рассматривать извлечение правила ИНС как пример прогнозирующего моделирования, где каждый шаблон ввода-вывода состоит из исходного входного вектора и соответствующего прогноза из непрозрачной модели. С этой точки зрения извлечение правила ИНС становится задачей моделирования функции из исходных входных данных в непрозрачные предсказания модели.
Оценка алгоритмов извлечения правила.
Существует несколько критериев, используемых для оценки алгоритмов извлечения правил:
– Наглядность. Степень, в которой извлеченные правила понятны для человека.
– Правильность. Степень, в которой извлеченные правила точно моделируют ИНС, из которых они извлекается.
– Точность. Способность выделенных правил делать точные прогнозы по ранее неизученным случаям.
– Масштабируемость. Способность метода масштабироваться к сетям с большими входными объемами данных и большим количеством связей.
– Универсальность. Степень, в которой метод требует специальных режимов обучения или устанавливает ограничения на архитектуру ИНС. [3-4].
Катастрофическая забывчивость.
Искусственные нейронные сети отличаются от биологических аналогов неспособностью «запомнить» прошлые навыки при обучении новой задаче. Работа в динамически изменяющихся средах (например, в финансовых) сложна для нейронных сетей. Даже если удалось успешно натренировать сеть, нет гарантий, что она не перестанет работать в будущем. Финансовые рынки постоянно трансформируются, поэтому то, что работало вчера, может с тем же успехом перестать работать сегодня. В этой сфере исследователям или приходится тестировать разнообразные архитектуры сетей и выбирать из них лучшую, или использовать динамические нейронные сети. Последние «следят» за изменениями среды и подстраивают свою архитектуру в соответствии с ними. Одним из используемых в этом случае алгоритмов является метод MSO (multi-swarm optimization).
Более того, нейросети обладают определенной особенностью, которую называют катастрофической забывчивостью (catastrophic forgetting). Она сводится к тому, что нейросеть нельзя последовательно обучить нескольким задачам – на каждой новой обучающей выборке все веса нейронов будут переписаны, и прошлый опыт будет «забыт». Например, искусственный интеллект, натренированный на распознавание людей, не сможет различать животных. Для этого его придется переобучить, однако при этом сеть лишиться опыта распознавания людей.
На данный момент самым эффективным способом борьбы с этой проблемой является метод упругого закрепления весов, разработанный учеными из компании DeepMind и Имперского колледжа Лондона. Этот метод обучения глубоких нейронных сетей способен приобретать новые навыки, сохраняя «память» о предыдущих задачах.
Нейронная сеть состоит из нескольких связей, для каждой из которых вычисляется её вес. Каждому весу в нейронной сети присваивается параметр F, который определяет его значимость. Чем больше значение F для конкретного нейрона, тем меньше вероятность его замены при дальнейшем обучении. Поэтому нейронная сеть как бы «запоминает» наиболее важные приобретенные навыки. Методика получила название Elastic Weight Consolidation, или «упругое закрепление весов». Работа алгоритма тестировалась на играх Atari. Ученые показали, что без «закрепления весов» программа быстро забывала игры, когда переставала в них играть (синий график). При использовании алгоритма EWC нейросеть «запомнила» веса, необходимые для выполнения всех предыдущих задач. И хотя EWC-сеть проиграла в каждом отдельном случае классическому алгоритму, она продемонстрировала хорошие результаты по сумме всех этапов (красный и коричневый графики на рисунке 2).
Рисунок 2 – Демонстрация точности работы EWC-сети
Ученое сообщество уже предпринимало попытки создания глубоких нейронных сетей, способных выполнять сразу несколько задач. Однако прошлые решения были или недостаточно мощными, или же требовали больших вычислительных ресурсов, поскольку сети обучались сразу на крупной объединенной выборке (а не на нескольких последовательных). Такой подход не приближал алгоритмы к принципам работы человеческого мозга.
Еще есть альтернативные архитектуры нейронных сетей для работы с текстом, музыкой и сериями длинных данных. Они носят название рекуррентных и имеют долгосрочную и краткосрочную память, что позволяет переключаться с глобальных проблем на локальные (например, с анализа отдельных слов на правила стилистики языка в целом). Рекуррентные нейронные сети имеют память, однако уступают глубоким сетям в способности анализировать сложные наборы признаков, которые встречаются, например, при обработке графики. Поэтому новое решение от DeepMind в перспективе позволит создавать умные универсальные алгоритмы, которые найдут применение в программном обеспечении для решения задач, требующих нелинейных преобразований.
ЗАКЛЮЧЕНИЕ
Разработка ИНС и машинное обучение являются перспективными направлениями информационных технологий. Несмотря на описанные выше недостатки, ИНС остаются мощным инструментом, который при правильном применении способен решать задачи, которые невозможно решить классическими программными алгоритмами. ИНС активно совершенствуются. Ученые и программисты ведут поиск средств, которые позволят минимизировать недостатки ИНС или полностью от них избавиться.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
Нейросети: что это такое и как работает. URL: https://www.mirf.ru/science/kak-rabotayut-nejroseti (дата обращения: 19.10.2017).
Что может и чего не может нейросеть. URL: https://habrahabr.ru/company/neurodatalab/blog/335238/ (дата обращения: 25.04.2017).
Z.-H. Zhou, Rule Extraction: Using Neural Networks or For Neural Networks? //Journal of Computer Science & Technology, 19(2):249-253, 2004.
M. Craven, Extracting Comprehensive Models from Trained Neural Networks, Ph.D. Thesis, University of Wisconsin-Madiso
Сетью без обратных связей называется сеть,
- все слои которой соединены иерархически
- (Правильный ответ) у которой нет синаптических связей, идущих от выхода некоторого нейрона к входам этого же нейрона или нейрона из предыдущего слоя
- у которой есть синаптические связи
Какие сети характеризуются отсутствием памяти?
- однослойные
- многослойные
- с обратными связями
- (Правильный ответ) без обратных связей
Входом персептрона являются:
- (Правильный ответ) вектор, состоящий из действительных чисел
- значения 0 и 1
- вектор, состоящий из нулей и единиц
- вся действительная ось (-?;+?)
Теорема о двухслойности персептрона утверждает, что:
- в любом многослойном персептроне могут обучаться только два слоя
- способностью к обучению обладают персептроны, имеющие не более двух слоев
- (Правильный ответ) любой многослойный персептрон может быть представлен в виде двухслойного персептрона
Обучением называют:
- процедуру вычисления пороговых значений для функций активации
- процедуру подстройки сигналов нейронов
- (Правильный ответ) процедуру подстройки весовых значений
Нейронная сеть является обученной, если:
- при подаче на вход некоторого вектора сеть будет выдавать ответ, к какому классу векторов он принадлежит
- (Правильный ответ) при запуске обучающих входов она выдает соответствующие обучающие выходы
- алгоритм обучения завершил свою работу и не зациклился
Подаем на вход персептрона вектор a. В каком случае весовые значения нужно уменьшать?
- всегда, когда на выходе 1
- (Правильный ответ) если на выходе 1, а нужно 0
- если сигнал персептрона не совпадает с нужным ответом
- если на выходе 0, а нужно 1
Алгоритм обратного распространения заканчивает свою работу, когда:
- величина ? становится ниже заданного порога
- величина ?w для каждого нейрона становится ниже заданного порога
- (Правильный ответ) сигнал ошибки становится ниже заданного порога
Метод импульса заключается в:
- использовании производных второго порядка
- (Правильный ответ) добавлении к коррекции веса значения, пропорционального величине предыдущего изменения веса
- умножении коррекции веса на значение, пропорциональное величине предыдущего изменения веса
Паралич сети может наступить, когда:
- (Правильный ответ) весовые значения становятся очень большими
- размер шага становится очень большой
- размер шага становится очень маленький
- весовые значения становятся очень маленькими
Если сеть имеет очень большое число нейронов в скрытых слоях, то:
- время, необходимое на обучение сети, минимально
- (Правильный ответ) возможно переобучение сети
- сеть может оказаться недостаточно гибкой для решения поставленной задачи
Дискриминантной функцией называется:
- активационная функция, используемая в многослойном персептроне
- функция, моделирующая пространство решений данной задачи
- (Правильный ответ) функция, равная единице в той области пространства объектов, где располагаются объекты из нужного класса, и равная нулю вне этой области
При методе кросс-проверки считается, что множество обучающихся пар корректно разделено на две части, если:
- ошибка сети на обучающем множестве убывает быстрее, чем на контрольном множестве
- в начале работы ошибки сети на обучающем и контрольном множествах существенно отличаются
- (Правильный ответ) в начале работы ошибки сети на обучающем и контрольном множествах практически не отличались
Если сеть содержит два промежуточных слоя, то она моделирует:
- по одной выпуклой «взвешенности» для каждого скрытого элемента первого слоя
- по одному «сигмовидному склону» для каждого скрытого элемента
- (Правильный ответ) по одной выпуклой «взвешенности» для каждого скрытого элемента второго слоя
- одну выпуклую «взвешенность»
Механизм контрольной кросс-проверки заключается в:
- циклическом использовании множества обучающих пар
- разделении множества обучающих пар на две части для поочередного запуска алгоритма обратного распространения то на одной, то на другой части
- (Правильный ответ) резервировании части обучающих пар и использовании их для независимого контроля процесса обучения
Если в алгоритме обучения сети встречного распространения на вход сети подается вектор x, то желаемым выходом является
- вектор y, являющийся эталоном для всех векторов, сходных с вектором x
- двоичный вектор, интерпритирующий номер класса, которому принадлежит вектор x
- (Правильный ответ) сам вектор x
«Победителем» считается нейрон Кохонена
- (Правильный ответ) с максимальным значением величины NET
- с минимальным значением величины NET
- с минимальным значением величины OUT
- с максимальным значением величины OUT
Если данный нейрон Кохонена является «победителем», то его значение OUT
- является максимальным среди всех значений OUT нейронов слоя Кохонена
- равно нулю
- (Правильный ответ) равно единице
Метод аккредитации заключается в:
- активировании двух нейронов, имеющих наибольшее и наименьшее значения NET
- активировании группы нейронов Кохонена, имеющих максимальные значения NET
- (Правильный ответ) активировании лишь одного нейрона Кохонена, имеющего наибольшее значение NET
Стратегия избежания локальных минимумов при сохранении стабильности заключается в
- достаточно больших изменениях весовых значений
- (Правильный ответ) больших начальных шагах изменения весовых значений и постепенном уменьшении этих шагов
- малых начальных шагах изменения весовых значений и постепенном увеличении этих шагов
- достаточно малых изменениях весовых значений
Для какого алгоритма более опасен сетевой паралич?
- алгоритма обратного распространения
- (Правильный ответ) алгоритма распределения Коши
Какова роль искусственной температуры при Больцмановском обучении?
- для регулирования скорости сходимости алгоритма обучения
- (Правильный ответ) при снижении температуры вероятно возможными становятся более маленькие изменения
Сеть Хопфилда заменяется на сеть Хэмминга, если:
- необходимо ускорить время сходимости сети
- необходимо повысить число запомненных образцов
- необходимо обеспечить устойчивость сети
- (Правильный ответ) нет необходимости, чтобы сеть в явном виде выдавала запомненный образец
Какими должны быть весовые значения тормозящих синаптических связей?
- (Правильный ответ) равными величинами из интервала (-1/n,0), где n — число нейронов в одном слое
- небольшими положительными числами
- случайными отрицательными числами
Метод отказа от симметрии синапсов позволяет:
- (Правильный ответ) достигнуть максимальной емкости памяти
- обеспечить устойчивость сети
- избежать локальных минимумов
Метод машины Больцмана позволяет сети Хопфилда:
- (Правильный ответ) избежать локальных минимумов
- ускорить процесс обучения
- избежать сетевого паралича
Сеть ДАП называется адаптивной, если:
- (Правильный ответ) сеть изменяет свои весовые значения в процессе обучения
- любой нейрон может изменять свое состояние в любой момент времени
- для каждого нейрона задается своя пороговая функция
Лотарально-тормозящая связь используется :
- между слоями сравнения и распознавания
- (Правильный ответ) внутри слоя распознавания
- внутри приемника 1
- внутри приемника 2
Процесс лотерального торможения обеспечивает, что
- слой сброса снимает возбуждение с неудачно выбранного нейрона в слое распознавания
- (Правильный ответ) в слое распознавания возбуждается только тот нейрон, чья свертка является максимальной
- система автоматически решает вопрос о прекращении поиска необходимой информации
Если в процессе обучения некоторый вес был обнулен, то:
- (Правильный ответ) он больше никогда не примет ненулевого значения
- он обязательно будет подвергнут новому обучению
Приращение веса тормозящего входа данного постсиноптического нейрона зависит от:
- выходного сигнала тормозящего пресиноптического нейрона и его возбуждающего веса
- выходного сигнала возбуждающего пресиноптического нейрона и его тормозящего веса
- (Правильный ответ) выходного сигнала возбуждающего пресиноптического нейрона и его возбуждающего веса
Чем различаются комплексные узлы, лежащие в разных слоях неокогнитрона?
- (Правильный ответ) каждый слой комплексных узлов реагирует на большее количество преобразований входного образа, чем предыдущий
- (Правильный ответ) каждый слой комплексных узлов реагирует на более широкую область поля входного образа, чем предыдущий
Какой тип обучения можно использовать при обучении неокогнитрона?
- (Правильный ответ) «обучение без учителя»
- (Правильный ответ) «обучение с учителем»
Обучение персептрона считается законченным, когда:
- (Правильный ответ) ошибка выхода становится достаточно малой
- достигнута достаточно точная аппроксимация заданной функции
- по одному разу запущены все вектора обучающего множества
Алгоритм обучения персептрона является:
- (Правильный ответ) алгоритмом «обучения с учителем»
- алгоритмом «обучения без учителя»
Запускаем обучающий вектор Х. В каком случае весовые значения не нужно изменять?
- если на выходе сеть даст 1
- если на выходе сеть даст 0
- (Правильный ответ) если сигнал персептрона совпадает с правильным ответом
Можем ли мы за конечное число шагов после запуска алгоритма обучения персептрона сказать, что персептрон не может обучиться данной задаче?
- нет
- (Правильный ответ) да
- в зависимост от задачи
Сигналом ошибки данного выходного нейрона называется:
- (Правильный ответ) разность между выходом нейрона и его целевым значением
- производная активационной функции
- величина OUT для нейрона, подающего сигнал на данный выходной нейрон
Метод ускорения сходимости заключается в:
- умножении коррекции веса на значение, пропорциональное величине предыдущего изменения веса
- (Правильный ответ) использовании производных второго порядка
- добавлении к коррекции веса значения, пропорционального величине предыдущего изменения веса
Если два образца сильно похожи, то:
- они могут объединиться в один образец
- (Правильный ответ) они могут вызывать перекрестные ассоциации
- они могут нарушать устойчивость сети
Отсутствие обратных связей гарантирует:
- (Правильный ответ) устойчивость сети
- сходимость алгоритма обучения
- возможность аппроксимировать данную функцию
В алгоритме обучения обобщенной машины Больцмана вычисление закрепленных вероятностей начинается после:
- запуска каждой обучающей пары
- конечного числа запусков сети с некоторого случайного значения
- (Правильный ответ) после запуска всех обучающих пар
- после однократного запуска сети с некоторого случайного значения
В аналого-цифровом преобразователе весовые значения интерпретируют:
- усилители
- (Правильный ответ) сопротивление
- напряжение
Если входной вектор соответствует одному из запомненных образов, то:
- выходом распознающего слоя является соответствующий запомненный образец
- (Правильный ответ) в распознающем слое возбуждается один нейрон
- срабатывает блок сброса
Если в процессе обучения на вход сети АРТ подавать повторяющиеся последовательности обучающих векторов, то:
- будет происходить циклическое изменение весов
- с каждым новым повтором серии обучающих векторов будет происходить более тонкая настройка весовых значений
- (Правильный ответ) через конечное число обучающих серий процесс обучения стабилизируется
В статистических алгоритмах обучения величина изменения синоптической связи между двумя нейронами зависит:
- от разности между реальным и желаемым выходами нейрона
- от уровня возбуждения пресиноптического нейрона
- от уровня возбуждения постсиноптического нейрона
- (Правильный ответ) изменяется случайным образом
Однонейронным персептроном размерность разделяемого пространства определяется
- контекстом конкретной задачи
- весовыми значениями
- (Правильный ответ) длиной входного вектора
- пороговым значением активационной функции
Однослойный персептрон решает задачи:
- (Правильный ответ) аппроксимации функций
- распознавания образов
- (Правильный ответ) классификации
Теорема о «зацикливании» персептрона утверждает, что:
- (Правильный ответ) если данная задача не представима персептроном, то алгоритм обучения зацикливается
- если задача не имеет решения, то алгоритм обучения зацикливается
- любой алгоритм обучения зацикливается
Все ли нейроны многослойного персептрона возможно обучить?
- только нейроны первого слоя
- да
- (Правильный ответ) только нейроны последнего слоя
При методе кросс-проверки считается, что сеть начала переобучаться, если:
- ошибка сети на контрольном множестве стала расти
- алгоритм обратного распространения зациклился
- (Правильный ответ) ошибка сети на контрольном множестве перестала убывать
Детерминистским методом обучения называется:
- метод, выполняющий псевдослучайные изменения весовых значений
- детерминированный метод обучения с учителем
- детерминированный метод обучения без учителя
- (Правильный ответ) метод, использующий последовательную коррекцию весов, зависящую от объективных значений сети
Есть ли вероятность того, что в алгоритме разобучения сеть «забудет» правильный образ?
- (Правильный ответ) да
- нет
- в зависимости от задачи
В задаче коммивояжера каждый город представляется:
- одним слоем нейронов
- (Правильный ответ) строкой из n нейронов, где n — число городов
- одним нейроном
Чем реакция комплексного узла на данный входной образ отличается от реакции простого узла, лежащего в том же слое?
- (Правильный ответ) комплексный узел менее чувствителен к позиции входного образа
- рецепторная зона комплексного узла гораздо больше рецепторной зоны простого узла
- комплексный узел менее чувствителен к повороту и другим видам движения входного образа
Выходом выходной звезды Гроссберга является
- мера сходства входного вектора с весовым вектором
- номер класса сходных образов
- (Правильный ответ) статическая характеристика обучающего набора
Искусственный нейрон
- (Правильный ответ) имитирует основные функции биологического нейрона
- по своей функциональности превосходит биологический нейрон
- является моделью биологического нейрона
Чтобы избежать паралича сети, необходимо:
- (Правильный ответ) уменьшить размер шага
- увеличить размер шага
- увеличить весовые значения
- уменьшить весовые значения
В однонейронном персептроне размерность разделяющей гиперплоскости определяется:
- (Правильный ответ) количеством входных значений
- весовыми значениями
- количеством выходных значений
В начальный момент времени выходом слоя распознавания является:
- (Правильный ответ) нулевой вектор
- единичный вектор
- входной вектор
Активационной функцией называется:
- функция, суммирующая входные сигналы нейрона
- (Правильный ответ) функция, вычисляющая выходной сигнал нейрона
- функция, распределяющая входные сигналы по нейронам
- функция, корректирующая весовые значения
Память называется гетероассоциативной, если:
- входной образ может быть отнесен к некоторому классу образов
- входной образ может быть только завершен или исправлен
- (Правильный ответ) входной образ может быть ассоциирован с другим образом
Память называется ассоциативной, если извлечение необходимой информации происходит по:
- (Правильный ответ) по содержанию данной информации
- имеющимся образцам
- адресу начальной точки данной информации
Весовые значения тормозящих нейронов:
- обучаются по дельта-правилу
- обучаются по алгоритму, аналогичному алгоритму обратного распространения
- (Правильный ответ) не обучаются
Добавление к коррекции веса значения, пропорционального величине предыдущего изменения веса, используется при методе:
- (Правильный ответ) импульса
- экспоненциального сглаживания
- ускорения сходимости
- добавления нейронного смещения
Фаза распознавания инициализируется:
- в момент срабатывания слоя сброса
- в момент возбуждения победившего нейрона в слое распознавания
- (Правильный ответ) в момент подачи на вход входного вектора
Кодирование ассоциаций — это:
- (Правильный ответ) «обучение с учителем»
- процесс нормального функционирования сети
- «обучение без учителя»
В статистических алгоритмах обучения искусственная температура используется для:
- (Правильный ответ) управления размером случайных изменений весовых значений
- минимизации целевой функции
- уменьшения полной энергии сети
При стохастическом методе обучения , если целевая функция увеличивается, то:
- (Правильный ответ) изменения весовых значений скидываются и производятся новые вычисления
- объявляется, что сеть не может обучиться данной задаче
- производятся повторные изменения весовых значений
В чем заключается отличие АРТ-1 от АРТ-2?
- в АРТ-2 используется многослойная иерархия слоев
- в АРТ-2 введен специальный механизм зависимости активности синапсов от времени
- (Правильный ответ) АРТ-1 обрабатывает только битовые сигналы, а АРТ-2 — аналоговые
При обучении когнитрона обучаются:
- все нейроны
- только один нейрон в каждом слое
- (Правильный ответ) только один нейрон в каждой области конкуренции
Какие из перечисленных ниже шагов в алгоритме обратного распространения являются шагами «прохода вперед»?
- (Правильный ответ) вычислить выход сети
- подкорректировать веса сети так, чтобы минимизировать ошибку
- (Правильный ответ) выбрать очередную обучающую пару из обучающего множества; подать входной вектор на вход сети
- повторять шаги с 1 по 4 для каждого вектора обучающего множества до тех пор, пока ошибка на всем множестве не достигнет приемлемого уровня
- вычислить разность между выходом сети и требуемым выходом (целевым вектором обучающей пары)
Из слоя сравнения информация поступает в:
- приемник 2
- (Правильный ответ) слой распознавания
- приемник 1
- внешнюю среду
- (Правильный ответ) слой сброса
Обучение сети встречного распространения является:
- «обучением без учителя»
- (Правильный ответ) «обучением с учителем»
При стохастическом методе обучения изменения весовых значений сохраняются, если
- (Правильный ответ) они уменьшают целевую функцию
- они увеличивают целевую функцию
- в любом случае
В каком случае персептрон может обучиться решать данную задачу?
- если задача имеет целое численное решение
- (Правильный ответ) если задача представима персептроном
- если задача имеет решение
Теорема о сходных персептронах утверждает, что:
- найдутся задачи, которым персептроны не смогут обучиться
- алгоритм обучения всегда сходится
- (Правильный ответ) если данная задача представляет персептрон, то он способен ей обучиться
Сети прямого распространения — это:
- (Правильный ответ) сети, у которых нет памяти
- (Правильный ответ) сети, у которых нет соединений, идущих от выходов некоторого слоя к входам предшествующего слоя
- сети, у которых есть память
- сети, имеющие много слоев
Сеть ДАП называется негомогенной, если:
- (Правильный ответ) для каждого нейрона задается своя пороговая функция
- данному входному вектору можно сопоставить несколько альтернативных ассоциаций
- ассоциированные вектора имеют разные размерности
К какому типу памяти относится ДАП?
- адресной
- автоассоциативной
- (Правильный ответ) гетероассоциативной
Если сеть Хопфилда нашла среди запомненных ею образцов, образец соответствующий данному входному вектору, то сеть должна :
- выдать на выходе заданный входной вектор
- (Правильный ответ) остановиться в этом образце
- выдать на выходе единицу
Каким образом можно уменьшить количество слоев когнитрона, не причинив ущерба его вычислительным свойствам?
- путем введения вероятностных синоптических связей
- путем перехода от одномерных слоев к двухмерным слоям
- (Правильный ответ) путем расширения областей связи в последующих слоях
Самоорганизующиеся сети используются для:
- (Правильный ответ) распознавания образов
- аппроксимации функций
- (Правильный ответ) классификации образов
Рецептивные области узлов каждой плоскости простых узлов
- не пересекаются, но покрывают все поле входного образа
- совпадают и покрывают все поле входного образа
- (Правильный ответ) пересекаются и покрывают все поле входного образа
В каком случае сигнал OUT совпадает с сигналом NET для данного нейрона когнитрона?
- если NET=0
- (Правильный ответ) если NET?0
- если NET?? где ? — заданное пороговое значение
Однонейронный персептрон с двумя входами:
- выделяет замкнутую область
- разделяет трехмерное пространство XOY на два полупространства
- (Правильный ответ) разделяет плоскость XOY на две полуплоскости
Метод восстановления ассоциаций заключается в том, что:
- определяется, являются ли два заданных вектора взаимно ассоциированными
- (Правильный ответ) по частично зашумленному вектору восстанавливается вектор, ассоциированный с ним
- по заданным векторам находятся ассоциации, их соединяющие
Сколько нейронов необходимо для реализации задачи коммивояжера, где n — число городов?
- 2n нейронов
- n! нейронов
- (Правильный ответ) n2 нейронов
- n нейронов
Значение активационной функции является:
- (Правильный ответ) выходом данного нейрона
- весовым значением данного нейрона
- входом данного нейрона
При обучении персептрона предполагается обучение:
- синоптических связей, соединяющих одновременно возбужденные нейроны
- синоптических связей только «победившего» нейрона
- (Правильный ответ) всех синоптических связей
Фаза поиска считается успешно завершенной, если:
- (Правильный ответ) найдется нейрон, в котором запомнен образ, достаточно похожий на входной образ
- весовые значения «победившего» нейрона из слоя распознавания будут подкорректированы согласно данному входному вектору
- входному образу будет сопоставлен нейрон, в котором никакой информации еще не было запомнено
Если до начала процедуры обучения по алгоритму обратного распространения все весовые значения сети сделать равными, то
- процесс обучения будет ускорен
- (Правильный ответ) сеть, скорее всего, не обучится
- процесс обучения будет замедлен
Модификация алгоритма обучения методом «чувства справедливости» заключается в:
- блокировании нейронов, которые очень часто побеждают
- (Правильный ответ) занижении весовых значений тех нейронов, которые очень часто «побеждают»
- повышении весовых значений тех нейронов, которые очень редко «побеждают»
Скрытым слоем обобщенного многослойного персептрона называется:
- (Правильный ответ) слой, не являющийся ни входным, ни выходным
- слой, не производящий вычислений
- слой, состоящий из элементов, которые только принимают входную информацию и распространяют ее по сети
Ортогонализация исходных образов позволяет:
- избежать локальных минимумов
- (Правильный ответ) обеспечить устойчивость сети
- (Правильный ответ) достигнуть максимальной емкости памяти
В предыдущей главе мы ознакомились с такими понятиями, как искусственный интеллект, машинное обучение и искусственные нейронные сети.
В этой главе я детально опишу модель искусственного нейрона, расскажу о подходах к обучению сети, а также опишу некоторые известные виды искусственных нейронных сетей, которые мы будем изучать в следующих главах.
Упрощение
В прошлой главе я постоянно говорил о каких-то серьезных упрощениях. Причина упрощений заключается в том, что никакие современные компьютеры не могут быстро моделировать такие сложные системы, как наш мозг. К тому же, как я уже говорил, наш мозг переполнен различными биологическими механизмами, не относящиеся к обработке информации.
Нам нужна модель преобразования входного сигнала в нужный нам выходной. Все остальное нас не волнует. Начинаем упрощать.
Биологическая структура → схема
В предыдущей главе вы поняли, насколько сложно устроены биологические нейронные сети и биологические нейроны. Вместо изображения нейронов в виде чудовищ с щупальцами давайте просто будем рисовать схемы.
Вообще говоря, есть несколько способов графического изображения нейронных сетей и нейронов. Здесь мы будем изображать искусственные нейроны в виде кружков.
Вместо сложного переплетения входов и выходов будем использовать стрелки, обозначающие направление движения сигнала.
Таким образом искусственная нейронная сеть может быть представлена в виде совокупности кружков (искусственных нейронов), связанных стрелками.

Электрические сигналы → числа
В реальной биологической нейронной сети от входов сети к выходам передается электрический сигнал. В процессе прохода по нейронной сети он может изменяться.

Электрический сигнал всегда будет электрическим сигналом. Концептуально ничего не изменяется. Но что же тогда меняется? Меняется величина этого электрического сигнала (сильнее/слабее). А любую величину всегда можно выразить числом (больше/меньше).
В нашей модели искусственной нейронной сети нам совершенно не нужно реализовывать поведение электрического сигнала, так как от его реализации все равно ничего зависеть не будет.
На входы сети мы будем подавать какие-то числа, символизирующие величины электрического сигнала, если бы он был. Эти числа будут продвигаться по сети и каким-то образом меняться. На выходе сети мы получим какое-то результирующее число, являющееся откликом сети.
Для удобства все равно будем называть наши числа, циркулирующие в сети, сигналами.
Синапсы → веса связей
Вспомним картинку из первой главы, на которой цветом были изображены связи между нейронами – синапсы. Синапсы могут усиливать или ослаблять проходящий по ним электрический сигнал.

Давайте характеризовать каждую такую связь определенным числом, называемым весом данной связи. Сигнал, прошедший через данную связь, умножается на вес соответствующей связи.
Это ключевой момент в концепции искусственных нейронных сетей, я объясню его подробнее. Посмотрите на картинку ниже. Теперь каждой черной стрелке (связи) на этой картинке соответствует некоторое число ( w_i ) (вес связи). И когда сигнал проходит по этой связи, его величина умножается на вес этой связи.

На приведенном выше рисунке вес стоит не у каждой связи лишь потому, что там нет места для обозначений. В реальности у каждой ( i )-ой связи свой собственный ( w_i )-ый вес.
Искусственный нейрон
Теперь мы переходим к рассмотрению внутренней структуры искусственного нейрона и того, как он преобразует поступающий на его входы сигнал.
На рисунке ниже представлена полная модель искусственного нейрона.

Не пугайтесь, ничего сложного здесь нет. Давайте рассмотрим все подробно слева направо.
Входы, веса и сумматор
У каждого нейрона, в том числе и у искусственного, должны быть какие-то входы, через которые он принимает сигнал. Мы уже вводили понятие весов, на которые умножаются сигналы, проходящие по связи. На картинке выше веса изображены кружками.
Поступившие на входы сигналы умножаются на свои веса. Сигнал первого входа ( x_1 ) умножается на соответствующий этому входу вес ( w_1 ). В итоге получаем ( x_1w_1 ). И так до ( n )-ого входа. В итоге на последнем входе получаем ( x_nw_n ).
Теперь все произведения передаются в сумматор. Уже исходя из его названия можно понять, что он делает. Он просто суммирует все входные сигналы, умноженные на соответствующие веса:
[ x_1w_1+x_2w_2+cdots+x_nw_n = sumlimits^n_{i=1}x_iw_i ]
Результатом работы сумматора является число, называемое взвешенной суммой.
Взвешенная сумма (Weighted sum) (( net )) — сумма входных сигналов, умноженных на соответствующие им веса.
[ net=sumlimits^n_{i=1}x_iw_i ]
Роль сумматора очевидна – он агрегирует все входные сигналы (которых может быть много) в какое-то одно число – взвешенную сумму, которая характеризует поступивший на нейрон сигнал в целом. Еще взвешенную сумму можно представить как степень общего возбуждения нейрона.
Пример
Для понимания роли последнего компонента искусственного нейрона – функции активации – я приведу аналогию.
Давайте рассмотрим один искусственный нейрон. Его задача – решить, ехать ли отдыхать на море. Для этого на его входы мы подаем различные данные. Пусть у нашего нейрона будет 4 входа:
- Стоимость поездки
- Какая на море погода
- Текущая обстановка с работой
- Будет ли на пляже закусочная
Все эти параметры будем характеризовать 0 или 1. Соответственно, если погода на море хорошая, то на этот вход подаем 1. И так со всеми остальными параметрами.
Если у нейрона есть четыре входа, то должно быть и четыре весовых коэффициента. В нашем примере весовые коэффициенты можно представить как показатели важности каждого входа, влияющие на общее решение нейрона. Веса входов распределим следующим образом:
- 5
- 4
- 1
- 1
Нетрудно заметить, что очень большую роль играют факторы стоимости и погоды на море (первые два входа). Они же и будут играть решающую роль при принятии нейроном решения.
Пусть на входы нашего нейрона мы подаем следующие сигналы:
- 1
- 0
- 0
- 1
Умножаем веса входов на сигналы соответствующих входов:
- 5
- 0
- 0
- 1
Взвешенная сумма для такого набора входных сигналов равна 6:
[ net=sumlimits^4_{i=1}x_iw_i = 5 + 0 + 0 + 1 =6 ]
Все классно, но что делать дальше? Как нейрон должен решить, ехать на море или нет? Очевидно, нам нужно как-то преобразовать нашу взвешенную сумму и получить ответ.
Вот на сцену выходит функция активации.
Функция активации
Просто так подавать взвешенную сумму на выход достаточно бессмысленно. Нейрон должен как-то обработать ее и сформировать адекватный выходной сигнал. Именно для этих целей и используют функцию активации.
Она преобразует взвешенную сумму в какое-то число, которое и является выходом нейрона (выход нейрона обозначим переменной ( out )).
Для разных типов искусственных нейронов используют самые разные функции активации. В общем случае их обозначают символом ( phi(net) ). Указание взвешенного сигнала в скобках означает, что функция активации принимает взвешенную сумму как параметр.
Функция активации (Activation function) (( phi(net) )) — функция, принимающая взвешенную сумму как аргумент. Значение этой функции и является выходом нейрона (( out )).
[ out=phi(net) ]
Далее мы подробно рассмотрим самые известные функции активации.
Функция единичного скачка
Самый простой вид функции активации. Выход нейрона может быть равен только 0 или 1. Если взвешенная сумма больше определенного порога ( b ), то выход нейрона равен 1. Если ниже, то 0.
Как ее можно использовать? Предположим, что мы поедем на море только тогда, когда взвешенная сумма больше или равна 5. Значит наш порог равен 5:
[ b=5 ]
В нашем примере взвешенная сумма равнялась 6, а значит выходной сигнал нашего нейрона равен 1. Итак, мы едем на море.
Однако если бы погода на море была бы плохой, а также поездка была бы очень дорогой, но имелась бы закусочная и обстановка с работой нормальная (входы: 0011), то взвешенная сумма равнялась бы 2, а значит выход нейрона равнялся бы 0. Итак, мы никуда не едем.
В общем, нейрон смотрит на взвешенную сумму и если она получается больше его порога, то нейрон выдает выходной сигнал, равный 1.
Графически эту функцию активации можно изобразить следующим образом.

На горизонтальной оси расположены величины взвешенной суммы. На вертикальной оси — значения выходного сигнала. Как легко видеть, возможны только два значения выходного сигнала: 0 или 1. Причем 0 будет выдаваться всегда от минус бесконечности и вплоть до некоторого значения взвешенной суммы, называемого порогом. Если взвешенная сумма равна порогу или больше него, то функция выдает 1. Все предельно просто.
Теперь запишем эту функцию активации математически. Почти наверняка вы сталкивались с таким понятием, как составная функция. Это когда мы под одной функцией объединяем несколько правил, по которым рассчитывается ее значение. В виде составной функции функция единичного скачка будет выглядеть следующим образом:
[ out(net) = begin{cases} 0, net < b \ 1, net geq b end{cases} ]
В этой записи нет ничего сложного. Выход нейрона (( out )) зависит от взвешенной суммы (( net )) следующим образом: если ( net ) (взвешенная сумма) меньше какого-то порога (( b )), то ( out ) (выход нейрона) равен 0. А если ( net ) больше или равен порогу ( b ), то ( out ) равен 1.
Сигмоидальная функция
На самом деле существует целое семейство сигмоидальных функций, некоторые из которых применяют в качестве функции активации в искусственных нейронах.
Все эти функции обладают некоторыми очень полезными свойствами, ради которых их и применяют в нейронных сетях. Эти свойства станут очевидными после того, как вы увидите графики этих функций.
Итак… самая часто используемая в нейронных сетях сигмоида — логистическая функция.

График этой функции выглядит достаточно просто. Если присмотреться, то можно увидеть некоторое подобие английской буквы ( S ), откуда и пошло название семейства этих функций.
А вот так она записывается аналитически:
[ out(net)=frac{1}{1+exp(-a cdot net)} ]
Что за параметр ( a )? Это какое-то число, которое характеризует степень крутизны функции. Ниже представлены логистические функции с разным параметром ( a ).

Вспомним наш искусственный нейрон, определяющий, надо ли ехать на море. В случае с функцией единичного скачка все было очевидно. Мы либо едем на море (1), либо нет (0).
Здесь же случай более приближенный к реальности. Мы до конца полностью не уверены (в особенности, если вы параноик) – стоит ли ехать? Тогда использование логистической функции в качестве функции активации приведет к тому, что вы будете получать цифру между 0 и 1. Причем чем больше взвешенная сумма, тем ближе выход будет к 1 (но никогда не будет точно ей равен). И наоборот, чем меньше взвешенная сумма, тем ближе выход нейрона будет к 0.
Например, выход нашего нейрона равен 0.8. Это значит, что он считает, что поехать на море все-таки стоит. Если бы его выход был бы равен 0.2, то это означает, что он почти наверняка против поездки на море.
Какие же замечательные свойства имеет логистическая функция?
- она является «сжимающей» функцией, то есть вне зависимости от аргумента (взвешенной суммы), выходной сигнал всегда будет в пределах от 0 до 1
- она более гибкая, чем функция единичного скачка – ее результатом может быть не только 0 и 1, но и любое число между ними
- во всех точках она имеет производную, и эта производная может быть выражена через эту же функцию
Именно из-за этих свойств логистическая функция чаще всего используются в качестве функции активации в искусственных нейронах.
Гиперболический тангенс
Однако есть и еще одна сигмоида – гиперболический тангенс. Он применяется в качестве функции активации биологами для более реалистичной модели нервной клетки.
Такая функция позволяет получить на выходе значения разных знаков (например, от -1 до 1), что может быть полезным для ряда сетей.
Функция записывается следующим образом:
[ out(net) = tanhleft(frac{net}{a}right) ]
В данной выше формуле параметр ( a ) также определяет степень крутизны графика этой функции.
А вот так выглядит график этой функции.

Как видите, он похож на график логистической функции. Гиперболический тангенс обладает всеми полезными свойствами, которые имеет и логистическая функция.
Что мы узнали?
Теперь вы получили полное представление о внутренней структуре искусственного нейрона. Я еще раз приведу краткое описание его работы.
У нейрона есть входы. На них подаются сигналы в виде чисел. Каждый вход имеет свой вес (тоже число). Сигналы на входе умножаются на соответствующие веса. Получаем набор «взвешенных» входных сигналов.
Далее этот набор попадает в сумматор, которой просто складывает все входные сигналы, помноженные на веса. Получившееся число называют взвешенной суммой.
Затем взвешенная сумма преобразуется функцией активации и мы получаем выход нейрона.
Сформулируем теперь самое короткое описание работы нейрона – его математическую модель:
Математическая модель искусственного нейрона с ( n ) входами:
[ out=phileft(sumlimits^n_{i=1}x_iw_iright) ]
где
( phi ) – функция активации
( sumlimits^n_{i=1}x_iw_i ) – взвешенная сумма, как сумма ( n ) произведений входных сигналов на соответствующие веса.
Виды ИНС
Мы разобрались со структурой искусственного нейрона. Искусственные нейронные сети состоят из совокупности искусственных нейронов. Возникает логичный вопрос – а как располагать/соединять друг с другом эти самые искусственные нейроны?
Как правило, в большинстве нейронных сетей есть так называемый входной слой, который выполняет только одну задачу – распределение входных сигналов остальным нейронам. Нейроны этого слоя не производят никаких вычислений.
А дальше начинаются различия…
Однослойные нейронные сети
В однослойных нейронных сетях сигналы с входного слоя сразу подаются на выходной слой. Он производит необходимые вычисления, результаты которых сразу подаются на выходы.
Выглядит однослойная нейронная сеть следующим образом:

На этой картинке входной слой обозначен кружками (он не считается за слой нейронной сети), а справа расположен слой обычных нейронов.
Нейроны соединены друг с другом стрелками. Над стрелками расположены веса соответствующих связей (весовые коэффициенты).
Однослойная нейронная сеть (Single-layer neural network) — сеть, в которой сигналы от входного слоя сразу подаются на выходной слой, который и преобразует сигнал и сразу же выдает ответ.
Многослойные нейронные сети
Такие сети, помимо входного и выходного слоев нейронов, характеризуются еще и скрытым слоем (слоями). Понять их расположение просто – эти слои находятся между входным и выходным слоями.

Такая структура нейронных сетей копирует многослойную структуру определенных отделов мозга.

Название скрытый слой получил неслучайно. Дело в том, что только относительно недавно были разработаны методы обучения нейронов скрытого слоя. До этого обходились только однослойными нейросетями.
Многослойные нейронные сети обладают гораздо большими возможностями, чем однослойные.
Работу скрытых слоев нейронов можно сравнить с работой большого завода. Продукт (выходной сигнал) на заводе собирается по стадиям. После каждого станка получается какой-то промежуточный результат. Скрытые слои тоже преобразуют входные сигналы в некоторые промежуточные результаты.
Многослойная нейронная сеть (Multilayer neural network) — нейронная сеть, состоящая из входного, выходного и расположенного(ых) между ними одного (нескольких) скрытых слоев нейронов.
Сети прямого распространения
Можно заметить одну очень интересную деталь на картинках нейросетей в примерах выше.
Во всех примерах стрелки строго идут слева направо, то есть сигнал в таких сетях идет строго от входного слоя к выходному.
Сети прямого распространения (Feedforward neural network) (feedforward сети) — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Такие сети широко используются и вполне успешно решают определенный класс задач: прогнозирование, кластеризация и распознавание.
Однако никто не запрещает сигналу идти и в обратную сторону.
Сети с обратными связями
В сетях такого типа сигнал может идти и в обратную сторону. В чем преимущество?
Дело в том, что в сетях прямого распространения выход сети определяется входным сигналом и весовыми коэффициентами при искусственных нейронах.
А в сетях с обратными связями выходы нейронов могут возвращаться на входы. Это означает, что выход какого-нибудь нейрона определяется не только его весами и входным сигналом, но еще и предыдущими выходами (так как они снова вернулись на входы).

Возможность сигналов циркулировать в сети открывает новые, удивительные возможности нейронных сетей. С помощью таких сетей можно создавать нейросети, восстанавливающие или дополняющие сигналы. Другими словами такие нейросети имеют свойства кратковременной памяти (как у человека).
Сети с обратными связями (Recurrent neural network) — искусственные нейронные сети, в которых выход нейрона может вновь подаваться на его вход. В более общем случае это означает возможность распространения сигнала от выходов к входам.
Обучение нейронной сети
Теперь давайте чуть более подробно рассмотрим вопрос обучения нейронной сети. Что это такое? И каким образом это происходит?
Что такое обучение сети?
Искусственная нейронная сеть – это совокупность искусственных нейронов. Теперь давайте возьмем, например, 100 нейронов и соединим их друг с другом. Ясно, что при подаче сигнала на вход, мы получим что-то бессмысленное на выходе.
Значит нам надо менять какие-то параметры сети до тех пор, пока входной сигнал не преобразуется в нужный нам выходной.
Что мы можем менять в нейронной сети?
Изменять общее количество искусственных нейронов бессмысленно по двум причинам. Во-первых, увеличение количества вычислительных элементов в целом лишь делает систему тяжеловеснее и избыточнее. Во-вторых, если вы соберете 1000 дураков вместо 100, то они все-равно не смогут правильно ответить на вопрос.
Сумматор изменить не получится, так как он выполняет одну жестко заданную функцию – складывать. Если мы его заменим на что-то или вообще уберем, то это вообще уже не будет искусственным нейроном.
Если менять у каждого нейрона функцию активации, то мы получим слишком разношерстную и неконтролируемую нейронную сеть. К тому же, в большинстве случаев нейроны в нейронных сетях одного типа. То есть они все имеют одну и ту же функцию активации.
Остается только один вариант – менять веса связей.
Обучение нейронной сети (Training) — поиск такого набора весовых коэффициентов, при котором входной сигнал после прохода по сети преобразуется в нужный нам выходной.
Такой подход к термину «обучение нейронной сети» соответствует и биологическим нейросетям. Наш мозг состоит из огромного количества связанных друг с другом нейросетей. Каждая из них в отдельности состоит из нейронов одного типа (функция активации одинаковая). Мы обучаемся благодаря изменению синапсов – элементов, которые усиливают/ослабляют входной сигнал.
Однако есть еще один важный момент. Если обучать сеть, используя только один входной сигнал, то сеть просто «запомнит правильный ответ». Со стороны будет казаться, что она очень быстро «обучилась». И как только вы подадите немного измененный сигнал, ожидая увидеть правильный ответ, то сеть выдаст бессмыслицу.
В самом деле, зачем нам сеть, определяющая лицо только на одном фото. Мы ждем от сети способности обобщать какие-то признаки и узнавать лица и на других фотографиях тоже.
Именно с этой целью и создаются обучающие выборки.
Обучающая выборка (Training set) — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит обучение сети.
После обучения сети, то есть когда сеть выдает корректные результаты для всех входных сигналов из обучающей выборки, ее можно использовать на практике.
Однако прежде чем пускать свежеиспеченную нейросеть в бой, часто производят оценку качества ее работы на так называемой тестовой выборке.
Тестовая выборка (Testing set) — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит оценка качества работы сети.
Мы поняли, что такое «обучение сети» – подбор правильного набора весов. Теперь возникает вопрос – а как можно обучать сеть? В самом общем случае есть два подхода, приводящие к разным результатам: обучение с учителем и обучение без учителя.
Обучение с учителем
Суть данного подхода заключается в том, что вы даете на вход сигнал, смотрите на ответ сети, а затем сравниваете его с уже готовым, правильным ответом.
Важный момент. Не путайте правильные ответы и известный алгоритм решения! Вы можете обвести пальцем лицо на фото (правильный ответ), но не сможете сказать, как это сделали (известный алгоритм). Тут такая же ситуация.
Затем, с помощью специальных алгоритмов, вы меняете веса связей нейронной сети и снова даете ей входной сигнал. Сравниваете ее ответ с правильным и повторяете этот процесс до тех пор, пока сеть не начнет отвечать с приемлемой точностью (как я говорил в 1 главе, однозначно точных ответов сеть давать не может).
Обучение с учителем (Supervised learning) — вид обучения сети, при котором ее веса меняются так, чтобы ответы сети минимально отличались от уже готовых правильных ответов.
Где взять правильные ответы?
Если мы хотим, чтобы сеть узнавала лица, мы можем создать обучающую выборку на 1000 фотографий (входные сигналы) и самостоятельно выделить на ней лица (правильные ответы).
Если мы хотим, чтобы сеть прогнозировала рост/падение цен, то обучающую выборку надо делать, основываясь на прошлых данных. В качестве входных сигналов можно брать определенные дни, общее состояние рынка и другие параметры. А в качестве правильных ответов – рост и падение цены в те дни.
И так далее…
Стоит отметить, что учитель, конечно же, не обязательно человек. Дело в том, что порой сеть приходится тренировать часами и днями, совершая тысячи и десятки тысяч попыток. В 99% случаев эту роль выполняет компьютер, а точнее, специальная компьютерная программа.
Обучение без учителя
Обучение без учителя применяют тогда, когда у нас нет правильных ответов на входные сигналы. В этом случае вся обучающая выборка состоит из набора входных сигналов.
Что же происходит при таком обучении сети? Оказывается, что при таком «обучении» сеть начинает выделять классы подаваемых на вход сигналов. Короче говоря – сеть начинает кластеризацию.
Например, вы демонстрируете сети конфеты, пирожные и торты. Вы никак не регулируете работу сети. Вы просто подаете на ее входы данные о данном объекте. Со временем сеть начнет выдавать сигналы трех разных типов, которые и отвечают за объекты на входе.
Обучение без учителя (Unsupervised learning) — вид обучения сети, при котором сеть самостоятельно классифицирует входные сигналы. Правильные (эталонные) выходные сигналы не демонстрируются.
Выводы
В этой главе вы узнали все о структуре искусственного нейрона, а также получили полное представление о том, как он работает (и о его математической модели).
Более того, вы теперь знаете о различных видах искусственных нейронных сетей: однослойные, многослойные, а также feedforward сети и сети с обратными связями.
Вы также ознакомились с тем, что представляет собой обучение сети с учителем и без учителя.
Вы уже знаете необходимую теорию. Последующие главы – рассмотрение конкретных видов нейронных сетей, конкретные алгоритмы их обучения и практика программирования.
Вопросы и задачи
Материал этой главы надо знать очень хорошо, так как в ней содержатся основные теоретические сведения по искусственным нейронным сетям. Обязательно добейтесь уверенных и правильных ответов на все нижеприведенные вопросы и задачи.
Опишите упрощения ИНС по сравнению с биологическими нейросетями.
Из каких элементов состоит искусственный нейрон?
Что такое взвешенная сумма? Какой компонент искусственного нейрона ее вычисляет?

Вычислите взвешенную сумму нейрона (рисунок выше)
Что такое функция активации?
Запишите математическую модель искусственного нейрона.
Чем отличаются однослойные и многослойные нейронные сети?
В чем отличие feedforward сетей от сетей с обратными связями?
Что такое обучающая выборка? В чем ее смысл?
Что понимают под обучением сети?
Что такое обучение с учителем и без него?
Искусственные нейронные сети применяются в различных областях науки: начиная от систем распознавания речи до распознавания вторичной структуры белка, классификации различных видов рака и генной инженерии. Однако, как они работают и чем они хороши?
Когда речь идет о задачах, отличных от обработки больших массивов информации, человеческий мозг обладает большим преимуществом по сравнению с компьютером. Человек может распознавать лица, даже если в помещении будет много посторонних объектов и плохое освещение. Мы легко понимаем незнакомцев даже когда находимся в шумном помещении. Но, несмотря на годы исследований, компьютеры все еще далеки от выполнения подобных задач на высоком уровне.
Человеческий мозг удивительно надежный: по сравнению с компьютером он не перестанет работать только потому, что несколько клеток погибнет, в то время как компьютер обычно не выдерживает каких-либо поломок в CPU. Но самой удивительной особенностью человеческого мозга является то, что он может учиться. Не нужно никакого программного обеспечения и никаких обновлений, если мы хотим научиться ездить на велосипеде.
Расчеты головного мозга производятся посредством тесно взаимосвязанных нейронных сетей, которые передают информацию, отсылая электрические импульсы через нейронные проводки, состоящие из аксонов, синапсов и дендритов. В 1943 году, компания McCulloch and Pitts смоделировала искусственный нейрон, как переключатель, который получает информацию от других нейронов и в зависимости от общего взвешенного входа, либо приводится в действие, либо остается неактивным. В узле ИНС пришедшие сигналы умножаются на соответствующие веса синапсов и суммируются. Эти коэффициенты могут быть как положительными (возбуждающими), так и отрицательными (тормозящими). В 1960 годах было доказано, что такие нейронные модели обладают свойствами, сходными с мозгом: они могут выполнять сложные операции распознавания образов, и они могут функционировать, даже если некоторые связи между нейронами разрушены. Демонстрация персептона Розенблатта показала, что простые сети из таких нейронов могут обучаться на примерах, известных в определенных областях. Позже, Минский и Паперт доказали, что простые пресептоны могут решать только очень узкий класс линейно сепарабельных задач (см. ниже), после чего активность изучения ИНС уменьшилась. Тем не менее, метод обратного распространения ошибки обучения, который может облегчить задачу обучения сложных нейронных сетей на примерах, показал, что эти проблемы могут быть и не сепарабельными.
Программа NETtalk применяла искусственные нейронные сети для машинного чтения текста и была первым широкоизвестным приложением. В биологии, точно такой же тип сети был применен для прогнозирования вторичной структуры белка; в самом деле, некоторые из лучших исследователей до сих пор пользуются тем же методом. С этого началась другая волна, вызвавшая интерес к исследованиям ИНС и поднявшая шумиху вокруг магического обучения мыслящих машин. Некоторые из наиболее важных ранних открытий приведены в 5 источнике.
ИНС могут быть созданы путем имитации модели сетей нейронов на компьютере. Используя алгоритмы, которые имитируют процессы реальных нейронов, мы можем заставить сеть «учиться», что помогает решить множество различных проблем. Модель нейрона представляется как пороговая величина (она проиллюстрирована на рисунке 1а). Модель получает данные от ряда других внешних источников, определяет значение каждого входа и добавляет эти значения. Если общий вход выше пороговой величины, то выход блока равен единице, в противном случае – нулю. Таким образом, выход изменяется от 0 до 1, когда общая «взвешенная» сумма входов равна пороговой величине. Точки в исходном пространстве, удовлетворяющие этому условию, определяют, так называемые, гиперплоскости. В двух измерениях, гиперплоскость – линия, в то время как в трех измерениях, гиперплоскость является нормальной (перпендикулярной) плоскостью. Точки с одной стороны от гиперплоскости классифицируются как 0, а точки с другой стороны – 1. Это означает, что задача классификации может быть решена с использованием пороговой величины, если два класса будут разделены гиперплоскостью. Эти проблемы называются линейно сепарабельными и изображены на рисунке 1b.
рисунок 1
Искусственные нейронные сети. (а) Графическое представление модели нейронной сети и порогового элемента McCulloch and Pitts. Пороговый блок получает входной сигнал от N других блоков или внешних источников, пронумерованных от 1 до N. Входной i называется xi и связывается с весом wi. Общий вход в устройство измерения суммы весов по всем входам, wixi=w1x1+w2x2+.. .+wNxΣi=1 N N.Если значение ниже порога t, то выход блока будет равен 1, в противном случае – 0. Таким образом, вывод может быть выражен как wixi Σi=1 – t g( N ), где g – ступенчатая функция, которая равна 0, если аргумент отрицателен, и 1, если аргумент положительный (фактическое значение в неле не имеет значения, здесь, мы выбрали 1). Так называемая, передаточная функция, g, также может быть неприрывной и «сигмоидальной», как показано красной линией. (b) Линейная сепарабельность (отделимость). В трех измерениях пороговое значение может классифицировать моменты, которые могут разделяться плоскостью. Каждая точка представляет входное значение х1, х2, х3 на пороге блока. Зеленые точки соответствуют точкамданных класса 0, и красные точки – 1. Зеленые и красные кресты иллюстрируют логическую функцию исключающего или. Найти плоскости, которые отделяют зеленые и красные точки, (или линии в х1, х2, плоскости) невозможно.(с) Однонаправленная ИНС. Показанная сеть занимает семь входов, имеет пять единиц в скрытом слое и один выход. Это двухслойная сеть, т.к. входной слой не выполняет никаких изменений и не учитывается. (d) переобучение. Восемь точек показаны плюсами на параболе (за исключением «экспериментального» шума). Они использованы для обучения трех различных ИНС. Сети воспринимают значения х в качестве входных данных (один вход) и обучаются с у значением, как желаемым результатом. Как и ожидалось, сеть с одним скрытым блоком (зеленая) не справляется с работой на высоком уровне. Сети с 10 скрытыми элементами (синяя) приближает основные функции на удивление хорошо. Последняя сеть с 20 скрытыми элементами (фиолетовая) перерабатывает информацию хорошо, сеть прекрасно обучилась, но для некоторых промежуточных областей она чрезмерно креативна.
Обучение
Если проблема классификации сепарабельна, то нам все еще нужно найти способ установления веса и пороговой величины таким образом, чтобы пороговое устройство решало задачу классификации правильно. Этого можно добиться путем постоянного добавления примеров из ранее известной классификации. Такой процесс называется обучением или тренировкой, так как он напоминает процесс изучения чего-либо человеком. Моделирование обучения с помощью компьютера предполагает постоянное изменение весов и порогов таким образом, что классификация приобретает более высокий уровень после каждого шага. Обучение может быть реализовано различными алгоритмами, об одном из таких алгоритмов мы поговорим позже.
Во время тренировки гиперплоскость движется то в одну сторону, то в другую, пока не найдет правильное положение в пространстве, после чего она уже не будет значительно изменяться. Такой процесс хорошо продемонстрирован программой Neural Java (http://lcn.epfl.ch/tutorial/english/index.html); следуйте по ссылке «Adline, Percepton and Backpropagation» (красные и синие точки представляют два класса) и нажмите «play».
Рассмотрим пример задачи, для которой легко применить искусственную нейронную сеть. Из двух видов рака, только один отвечает на определенные способы лечения. Так как не существует простых биомаркеров, позволяющих отличить эти два вида рака друг от друга, вы решаете измерить генную экспрессию образцов опухоли, что бы определить тип каждой опухоли. Предположим, вы измерили значения 20 различных генов в 50 опухолях класса 0 (нереагирующих) и 50 класса 1 (реагирующих). На основе этих данных, вы обучаете пороговое устройство, который принимает 20 значений генов в качестве входных данных и выдает 0 или 1 в качестве результата для определения одного из двух классов, соответственно. Если данные линейно сепарабельны, то пороговый блок будет классифицировать обучающие данные правильно.
Тем не менее, многие проблемы классификации не являются линейно сепарабельными. Мы можем разделить классы в таких нелинейных задачах путем введения большего количества гиперплоскостей, а именно за счет введения более чем одного порогового блока. Обычно это осуществляется добавлением дополнительного (скрытого) уровня порогового элемента, каждая из которых производит частичную классификацию входных данных и посылает выводные данные на последний уровень. На заключительном уровне собираются все частичные классификации для составления окончательной (рис. 1b). Такие сети называют многоуровневыми перцептонами или однонаправленной сетью. Однонаправленные нейронные сети также могут быть использованы для задач регрессии, которые требуют постоянного выхода, в отличие от бинарных выходов (0 и 1). Заменяя ступенчатую функцию непрерывной, мы получаем вещественное число в качестве выхода. Зачастую, когда используется «сигмоидальная» функция активации, она является временной пороговой функцией (рис. 1а). «Сигмоидальная» функция активации также может быть использована для задач классификации, интерпретируя выход ниже 0.5, как класс 0, и выход выше 0.5, как класс 1. Также имеет смысл интерпретировать результат как вероятность класса 1.
В вышеприведенном примере, также возможны следующие варианты: класс 1 характеризуется как ярко выраженный ген 1 и бессимптомный класс — 0, или наоборот. Если оба из генов ярко выражены или бессимптомны, то присваивается класс 0 (опухоль). Это соответствует исключающему логическому «или» и является каноническим примером нелинейно сепарабельной функции (рис. 1b). В данном случае, для классификации опухолей было необходимо использовать многоуровневую сеть.
Обратная передача ошибки обучения
Вышеуказанный алгоритм обратной передачи ошибки обучения работает на однонаправленных нейронных сетях с аналоговым выходом. Обучение начинается с установки всех весов в сеть малых случайных чисел. Теперь, для каждого входного примера сеть дает выход, который начинается случайно. Мы измеряем квадрат разности между этими двумя выходами и желаемыми результатами для соответствующего класса или значения. Сумма всех этих чисел за все учебные примеры называется общей ошибкой сети. Если число равно нулю, то сеть является идеальной, следовательно, чем меньше погрешность, тем лучше сеть.
При выборе весов, которые сведут суммарную погрешность к минимуму, мы получим нейронную сеть, решающую проблему лучшим способом. Это то же самое, что и линейная регрессия, где два параметра характеризуют выбранные линии так, чтобы сумма квадратов разностей между линией и информационными точками была минимальной. Такую задачу можно решить аналитически в линейной регрессии, но нет никакого решения в однонаправленных нейронных сетях со скрытыми элементами. В алгоритме обратной передачи ошибки, веса и пороги меняются каждый раз, когда предоставляется новый пример, таким образом, возможность ошибки постепенно становится меньше. Процесс повторяется сотни раз, пока ошибка не остается неизменной. Наглядное представление этого процесса можно найти на сайте Neural Java, который указан выше, перейдя по ссылке «Multi-layer Perceptron» (с выходом нейрона {0, 1}).
В алгоритме обратной передачи ошибки, численный метод оптимизации называется алгоритмом градиентного спуска, который особенно упрощает математические вычисления. Название этот алгоритм получил из-за формы уравнений, которые он помогает решить. Есть несколько параметров обучения (так называемый коэффициент обучения и импульса), которые нуждаются в настройке при использовании обратной передачи ошибки. Также существуют и другие проблемы, которые стоит рассмотреть. Например, алгоритм градиентного спуска не гарантирует нахождение глобального минимума ошибки, поэтому результат обучения зависит от начальных значений весов. Тем не менее, одна проблема затмевает все остальные: проблема переобучения.
Переобучение происходит, когда нейронная сеть имеет слишком много параметров, которые можно извлечь из числа имеющихся параметров, то есть, когда несколько пунктов соответствуют функции со слишком большим количеством свободных параметров (рис. 1d). Несмотря на то, что все эти методы подходят и для классификации, и для регрессии, нейронные сети обычно склонны к перепараметризации. Например, сеть с 10 скрытыми элементами для решения нашей проблемы будет иметь 221 параметр: 20 скрытых весов и пороговых величин, а также 10 весов и пороговых величин на выходе. Это слишком большое количество параметров, которые можно извлечь из 100 примеров. Сеть, которая слишком подходит для обучающих данных, вряд ли обобщит выходные данные, не являющиеся обучающими. Существует множество способов для ограничения переобучения сети (исключая создание маленькой сети), но наиболее распространенные включают усреднение по нескольким сетям, регуляризацию и использование метода Байесовской статистики.
Для оценки производительности нейронных сетей, необходимо тестировать их на независимых данных, которые не использовались во время обучения сети. Обычно производится перекрестная проверка, где набор данных делится, например, на несколько комплектов одинакового размера. Тогда, сеть обучается по 9 комплектам и тестируется на десятом, и эта операция повторяется десять раз, так что все наборы используются для тестирования. Это дает оценку способности сети к обобщению, то есть, ее способности классифицировать входные данные, которым сеть не была обучена. Чтобы получить объективную оценку, что является очень важным, отдельные наборы не должны содержать похожие примеры.
Расширения и приложения
И простой персептрон с одним блоком, и многослойные сети с несколькими устройствами могут быть легко обобщены для прогнозирования более чем двух параметров, простым добавлением большего количества выходных значений. Любая проблема классификации может быть закодирована набором бинарных выходов. В вышеприведенном примере, мы могли бы, например, представить, что существуют три различных метода лечения, и для данной опухоли мы хотим знать, какой из методов лечения будет эффективным. Проблема может быть решена использованием трех выходных элементов, по одному для каждого вида лечения, которые подключены к тем же скрытым единицам.
Нейронные сети применяются для многих интересных проблем в различных областях науки, медицины и техники, а в некоторых случаях они обеспечивают высокотехнологичные решения. Нейронные сети иногда случайно использовались для задач, где более простые методы давали лучшие результаты, тем самым давая плохую репутацию ИНС среди некоторых ученых.
Существуют и другие типы нейронных сетей, которые не описывались здесь. Например, машина Больцмана, неконтролируемые сети и сети Кохонена. Поддержка векторных машин тесно связанных с ИНС. Для более детального ознакомления, я советую книгу Криса Бишопа, старые книги с моим соавторством, книгу Дуда и др. Существует множество программ, которые можно использовать для создания ИНС, обученных по собственным данным. К ним относятся расширения и плагины для Microsoft Excell, Matlab, и R (http://www.r-project.org/), а также библиотеки кода и большие коммерческие пакеты. FANN библиотеки (http://leenissen.dk/fann/), которые используются для серьезных приложений. Она наполнена открытым программным кодом на С, но может быть вызвана из, например, Perl и Python программ.
Дополнительная литература
1. Minsky, M.L. & Papert, S.A. Perceptrons (MIT Press,Cambridge, 1969).
2. Rumelhart, D.E., Hinton, G.E. & Williams, R.J. Nature 323, 533–536 (1986).
3. Sejnowski, T.J. & Rosenberg, C.R. Complex Systems 1, 145–168 (1987).
4. Qian, N. & Sejnowski, T.J. J. Mol. Biol. 202, 865–884 (1988).
5. Anderson, J.A. & Rosenfeld, E. (eds). Neurocomputing: Foundations of Research (MIT Press, Cambridge, 1988).
6. Bishop, C.M. Neural Networks for Pattern Recognition (Oxford University Press, Oxford, 1995).
7. Noble, W.S. Nat. Biotechnol. 24, 1565–1567 (2006).
8. Bishop, C.M. Pattern Recognition and Machine Learning (Springer, New York, 2006).
9. Hertz, J.A., Krogh, A. & Palmer, R. Introduction to the Theory of Neural Computation (Addison-Wesley, Redwood City, 1991).
10. Duda, R.O., Hart, P.E. & Stork, D.G. Pattern Classification (Wiley Interscience, New York, 2000).
Перевод статьи (Anders Krogh NATURE BIOTECHNOLOGY VOLUME 26 NUMBER 2 FEBRUARY 2008)
Главная / Искусственный интеллект и робототехника /
Основы теории нейронных сетей / Тест 1
Упражнение 1:
Номер 1
Что является входом искусственного нейрона?
Ответ:
(1) множество сигналов
(2) единственный сигнал
(3) весовые значения
(4) значения активационной функции
Номер 2
Что такое множество весовых значений нейрона?
Ответ:
(1) множество значений, характеризующих «силу» соединений данного нейрона с нейронами предыдущего слоя
(2) множество значений, характеризующих «силу» соединений данного нейрона с нейронами последующего слоя
(3) множество значений, моделирующих «силу» биологических синоптических связей
(4) множество значений, характеризующих вычислительную «силу» нейрона

Номер 3
Что означает величина NET?
Ответ:
(1) выход суммирующего блока
(2) значение активационной функции
(3) входной сигнал нейрона
(4) выходной сигнал нейрона
Номер 4
Что означает величина OUT?
Ответ:
(1) выход суммирующего блока
(2) значение активационной функции
(3) входной сигнал нейрона
(4) выходной сигнал нейрона
Номер 5
Активационной функцией называется:
Ответ:
(1) функция, вычисляющая выходной сигнал нейрона
(2) функция, суммирующая входные сигналы нейрона
(3) функция, корректирующая весовые значения
(4) функция, распределяющая входные сигналы по нейронам
Упражнение 2:
Номер 1
Матричное умножение XW вычисляет:
Ответ:
(1) выходной нейронный сигнал
(2) выход суммирующего блока
(3) входной нейронный сигнал
(4) вход суммирующего блока
Номер 2
Активационная функция применяется для:
Ответ:
(1) активации входного сигнала нейрона
(2) активации выходного сигнала нейрона
(3) активации весовых значений
(4) активации обучающего множества
Номер 3
Значение активационной функции является:
Ответ:
(1) входом данного нейрона
(2) выходом данного нейрона
(3) весовым значением данного нейрона
Номер 4
В каком случае многослойные сети не могут привести к увеличению вычислительной мощности по сравнению с однослойной сетью?
Ответ:
(1) если они имеют два слоя
(2) если они не имеют обратных связей
(3) если они имеют сжимающую активационную функцию
(4) если они имеют линейную активационную функцию
Номер 5
Сетью без обратных связей называется сеть,
Ответ:
(1) все слои которой соединены иерархически
(2) у которой нет синаптических связей, идущих от выхода некоторого нейрона к входам этого же нейрона или нейрона из предыдущего слоя
(3) у которой есть синаптические связи
Упражнение 3:
Номер 1
Активационная функция называется "сжимающей", если
Ответ:
(1) она сужает диапазон значений величины NET диапазона значений OUT
(2) она расширяет диапазон значений величины NET
(3) она сужает диапазон значений величины OUT
(4) она расширяет диапазон значений величины OUT
Номер 2
Слоем нейронной сети называется множество нейронов,
Ответ:
(1) не имеющих между собой синаптических связей
(2) принимающих входные сигналы с одних тех же узлов
(3) выдающих выходные сигналы на одни и те же узлы
Номер 3
Какие сети характеризуются отсутствием памяти?
Ответ:
(1) однослойные
(2) многослойные
(3) без обратных связей
(4) с обратными связями
Номер 4
Входным слоем сети называется:
Ответ:
(1) первый слой нейронов
(2) слой, служащий для распределения входных сигналов
(3) слой, не производящий никаких вычислений
Номер 5
Можно ли построить однослойную нейронную сеть с обратными связями?
Ответ:
(1) да
(2) нет
Упражнение 4:
Номер 1
Сети прямого распространения - это:
Ответ:
(1) сети, имеющие много слоев
(2) сети, у которых нет соединений, идущих от выходов некоторого слоя к входам предшествующего слоя
(3) сети, у которых нет памяти
(4) сети, у которых есть память
Номер 2
Сети с обратными связями это:
Ответ:
(1) сети, имеющие много слоев
(2) сети, у которых существуют соединения, идущие от выходов некоторого слоя к входам предшествующего слоя
(3) сети, у которых нет памяти
Номер 3
"Обучение без учителя" характеризуется отсутствием:
Ответ:
(1) желаемого выхода сети
(2) эксперта, корректирующего процесс обучения
(3) обучающего множества
Номер 4
При каком алгоритме обучения обучающее множество состоит только из входных векторов?
Ответ:
(1) обучение с учителем
(2) обучение без учителя
Номер 5
При каком алгоритме обучения обучающее множество состоит как из входных, так и из выходных векторов?
Ответ:
(1) «обучение с учителем»
(2) «обучение без учителя»
Упражнение 5:
Номер 1
Как происходит обучение нейронной сети?
Ответ:
(1) эксперты настраивают нейронную сеть
(2) сеть запускается на обучающем множестве, и незадействованные нейроны выкидываются
(3) сеть запускается на обучающем множестве, и подстраиваются весовые значения
(4) сеть запускается на обучающем множестве, и добавляются или убираются соединения между нейронами
Номер 2
"Обучение с учителем" это:
Ответ:
(1) использование знаний эксперта
(2) использование сравнения с идеальными ответами
(3) подстройка входных данных для получения нужных выходов
(4) подстройка матрицы весов для получения нужных ответов
Номер 3
Синапсами называются:
Ответ:
(1) точки соединения нейронов, через которые передаются нейронные сигналы
(2) «усики» нейронов, по которым проходят электрохимические сигналы
(3) тело нейрона, в котором происходит обработка электрохимического сигнала
Номер 4
Дендритами называются:
Ответ:
(1) точки соединения нейронов, через которые передаются нейронные сигналы
(2) «усики» нейронов, по которым проходят электрохимические сигналы
(3) тело нейрона, в котором происходит обработка электрохимического сигнала
Номер 5
Искусственный нейрон
Ответ:
(1) является моделью биологического нейрона
(2) имитирует основные функции биологического нейрона
(3) по своей функциональности превосходит биологический нейрон

Добавил:
Вуз:
Предмет:
Файл:
Технологии нейронных сетей принятия решений Итоговый тест
Скачиваний:
39
Добавлен:
04.02.2021
Размер:
1 Mб
Скачать
![]()
►
Тест начат
Состояние Завершенные
Завершен
Прошло времени 1 ч. 19 мин.
Баллы 82,60/111,00
Оценка 74,41 из 100,00
|
Вопрос 1 |
Чем отличаются изображения от других объектов (с точки зрения распознавания)? |
|
Выполнен |
Выберите один ответ: |
|
Баллов: 0,00 из |
a. Изображения имеют 3 цветовых канала |
|
1,00 |
b. Изображения занимают больший объем памяти |
|
c. Изображения обладают локальной связностью |
|
|
Ваш ответ неправильный. |
|
Вопрос 2 |
В чем заключается правило обучения Ойя? |
|
|
Выполнен |
Выберите один ответ: |
|
|
Баллов: 1,00 из |
a. wij (t+1) =wij(t) + ηyi [xj — wij(t)] |
|
|
1,00 |
||
|
b. Δw = ηy(xj — y wi) |
||
|
c. Δwij = xj (di — yi) |
||
|
d. Δw = ηp(w) |
||
|
Ваш ответ верный. |
/
Вопрос 3
Выполнен Баллов: 1,00 из
1,00
Вопрос 4
Выполнен Баллов: 1,00 из
1,00
Вопрос 5
Выполнен Баллов: 1,00 из
1,00
Сколько приблизительно синапсов в головном мозге человека?
Выберите один ответ:
a. 1022
b. 85 миллиардов
c. 85 миллионов
d. 106 e. 1015
Ваш ответ верный.
В какой из моделей нейроны конкурируют между собой?
Выберите один ответ:
a. Нейрон Хебба
b. Инстар Гроссберга
c. Нейрон МакКаллока-Питса
d. Стохастический нейрон
e. Нейрон типа WTA f. Адалайн
Ваш ответ верный.
Каковы преимущества нейронных сетей?
Выберите один ответ:
a. Пошаговое решение задач
b. Помехоустойчивость
c. Высокая точность решений
d. Способность решать вычислительные задачи
Ваш ответ верный.
/
Вопрос 6
Выполнен Баллов: 1,00 из
1,00
Вопрос 7
Выполнен Баллов: 1,00 из
1,00
Чему равно общее число обучаемых параметров в сверточном слое?
Выберите один ответ:
a. fs ·( fc ·fd+1)
b. 4
c. 3
d. 1
e. fc·(fs·fs·fd+1)
Ваш ответ верный.
Какие ИНС называются корреляционными?
Выберите один ответ:
a. Сети с обратными связями
 b. Сети с самоорганизацией, в процессе обучения которых используется информация о зависимостях между сигналами
b. Сети с самоорганизацией, в процессе обучения которых используется информация о зависимостях между сигналами
c. Сети Хопфилда
d. Сети, использующие корреляционные функции в процессе работы
 e. Сети, в процессе обучения которых используется информация о зависимостях между нейронами
e. Сети, в процессе обучения которых используется информация о зависимостях между нейронами
Ваш ответ верный.
/
Вопрос 8
Выполнен Баллов: 1,00 из
1,00
Вопрос 9
Выполнен Баллов: 0,00 из
1,00
Каково количество синапсов, которому соответствуют возможности мозга человека?
Выберите один ответ:
a. 1012
b. 106
c. 105
d. 103
e. 1015
f. 1010
g. 104 h. 109
Ваш ответ верный.
Правило обучения какого нейрона задают формулы?
если yi=0, di=1, то wij(t+1)=wij(t)+xj , а если yi=1, di=0, то wij(t+1)=wij(t)-xj
Выберите один ответ:
a. Персептрона
b. Видроу-Хоффа
c. Адалайн
d. Хебба
e. Гроссберга
Ваш ответ неправильный.
/

Вопрос 10
Выполнен Баллов: 1,00 из
1,00
Вопрос 11
Выполнен Баллов: 0,00 из
1,00
Вопрос 12
Выполнен Баллов: 1,00 из
1,00
В чем состоит обучение нейронной сети?
Выберите один ответ:
a. В подборе функции активации
b. В определении потребного количества нейронов
c. В выборе передаточной функции d. В подборе функции сумматора
e. В подборе весовых коэффициентов
Ваш ответ верный.
Возможно ли линейное разделение обучающих данных, соответствующих простой логической функции XOR, с помощью однослойной ИНС?
Выберите один ответ:
a. Невозможно
b. Возможно в исключительных случаях (вероятность мала)
c. Возможно с вероятностью 0,5 d. Возможно
Ваш ответ неправильный.
Какие известны виды ИНС?
Выберите один ответ:
 a. 1)Однослойные; 2)Многослойные; 3)Прямого распространения; 4)С обратными связями
a. 1)Однослойные; 2)Многослойные; 3)Прямого распространения; 4)С обратными связями
b. 1)Прямые; 2)Обратные; 3)С учителем; 4)Без учителя
 c. 1)С открытыми слоями; 2)Со скрытыми слоями; 3)Обучаемые; 4)Необучаемые
c. 1)С открытыми слоями; 2)Со скрытыми слоями; 3)Обучаемые; 4)Необучаемые
 d. 1)Однослойные; 2)Двухслойные; 3)Многослойные; 4)Параллельные; 5)Последовательные
d. 1)Однослойные; 2)Двухслойные; 3)Многослойные; 4)Параллельные; 5)Последовательные
Ваш ответ верный.
/

Вопрос 13
Выполнен Баллов: 0,00 из
1,00
Вопрос 14
Выполнен Баллов: 1,00 из
1,00
Вопрос 15
Выполнен Баллов: 0,50 из
1,00
Какую из перечисленных задач ИНС не может решить?
Выберите один ответ:
a. Распознавание
b. Классификация
c. Интерполяция
d. Аппроксимация
e. Ассоциация
f. Сжатие данных
g. Вычисление
h. Прогнозирование i. Идентификация
Ваш ответ неправильный.
Какова структура типичной радиальной ИНС?
Выберите один ответ:
a. Один входной слой, два-три скрытых слоя и один выходной слой
b. Один входной слой, три или более скрытых слоев и один выходной слой
c. Два входных слоя, два скрытых слоя и один выходной слой
 d. Один входной слой, один скрытый слой и один выходной слой Один входной слой, много скрытых слоев и один выходной слой
d. Один входной слой, один скрытый слой и один выходной слой Один входной слой, много скрытых слоев и один выходной слой
Ваш ответ верный.
С какими данными работают сверточные нейронные сети?
Выберите один ответ:
a. С пикселями
b. С векторами
c. С матрицами d. С тензорами
Ваш ответ частично правильный.
/

Вопрос 16
Выполнен Баллов: 1,00 из
1,00
Вопрос 17
Выполнен Баллов: 1,00 из
1,00
Вопрос 18
Выполнен Баллов: 1,00 из
1,00
На выходе какого элемента ИНС получается взвешенная сумма?
Выберите один ответ:
a. Сумматора
b. Искусственного нейрона
c. Активатора
d. Синапса
e. Персептрона
Ваш ответ верный.
Что означает аббревиатура RMLP?
Выберите один ответ:
a. Recurrent MultiLayer Perceptron
b. Relaxation Method of Low Power
c. Real time MultiLayer Principle
d. Recurrent McCuLloch Perceptron
Ваш ответ верный.
В персептроне…
Выберите один ответ:
a. одному S-элементу может соответствовать несколько A-элементов
b. может быть несколько S-элементов и только один A-элемент
c. одному A-элементу может соответствовать только один S-элемент
d. Нескольким S-элементам может соответствовать несколько A-элементов e. одному A-элементу может соответствовать несколько S-элементов
Ваш ответ верный.
/
Вопрос 19
Выполнен Баллов: 1,00 из
1,00
Вопрос 20
Выполнен Баллов: 1,00 из
1,00
Вопрос 21
Выполнен Баллов: 1,00 из
1,00
Какие методы оптимизации являются наиболее эффективными в случае непрерывной целевой функции?
Выберите один ответ:
a. Монте-Карло
b. Градиентные
c. Дискретные
d. Гаусса-Зейделя e. Ньютона
Ваш ответ верный.
Какая обобщенная схема нейрона составляет основу большинства моделей нервной клетки?
Выберите один ответ:
a. Гроссберга
b. Хебба
c. МакКаллока-Питса
d. Адалайн
e. Видроу-Хоффа
Ваш ответ верный.
Сколько слоев должна иметь ИНС, выполняющая логическую функцию XOR?
Выберите один ответ:
a. Минимум два
b. Один
c. Не менее трех d. Много
Ваш ответ верный.
/
Вопрос 22
Выполнен Баллов: 1,00 из
1,00
Вопрос 23
Выполнен Баллов: 1,00 из
1,00
Вопрос 24
Выполнен Баллов: 0,00 из
1,00
Какие ИНС называются рекуррентными?
Выберите один ответ:
a. Сети с обратными связями
b. Сети, использующие рекуррентные соотношения при тестировании
c. Другое название сетей Хебба
d. Сети с самоорганизацией
e. Сети, использующие рекуррентные формулы при обучении
Ваш ответ верный.
В чем заключается операция ренормализации весов нейрона Хебба?
Выберите один ответ:
a. В отмене операции нормализации вектора весов нейрона
b. В повторной нормализации вектора выходных сигналов
 c. В подборе на каждом шаге обучения коэффициента забывания γ, чтобы норма вектора весов оставалась единичной
c. В подборе на каждом шаге обучения коэффициента забывания γ, чтобы норма вектора весов оставалась единичной
 d. В подборе на каждом шаге обучения коэффициента α, чтобы норма вектора весов оставалась равной единице
d. В подборе на каждом шаге обучения коэффициента α, чтобы норма вектора весов оставалась равной единице
e. В повторной нормализации вектора входных сигналов
Ваш ответ верный.
Что можно отнести к преимуществам радиальных ИНС?
Выберите один ответ:
a. Они допускают ускоренный алгоритм обучения
b. Они осуществляют глобальную аппроксимацию c. Они осуществляют локальную аппроксимацию
Ваш ответ неправильный.
/
Вопрос 25
Выполнен Баллов: 1,00 из
1,00
Вопрос 26
Выполнен Баллов: 1,00 из
1,00
Персептрон, у которого каждый S-элемент однозначно соответствует одному A- элементу, все S-A связи имеют вес, равный +1, а порог A элементов равен 1, называется…
Выберите один ответ:
a. многослойным (по Румельхарту)
b. элементарным
c. однослойным
d. многослойным (по Розенблатту) e. нейроном
Ваш ответ верный.
Ядро свертки – это…
Выберите один ответ:
a. фильтр низких частот
b. совокупность основных пикселей входного изображения
 c. матрица весовых коэффициентов, устанавливающихся в процессе обучения
c. матрица весовых коэффициентов, устанавливающихся в процессе обучения
Ваш ответ верный.
/

An artificial neural network is an interconnected group of nodes, inspired by a simplification of neurons in a brain. Here, each circular node represents an artificial neuron and an arrow represents a connection from the output of one artificial neuron to the input of another.
Artificial neural networks (ANNs), usually simply called neural networks (NNs) or neural nets,[1] are computing systems inspired by the biological neural networks that constitute animal brains.[2]
An ANN is based on a collection of connected units or nodes called artificial neurons, which loosely model the neurons in a biological brain. Each connection, like the synapses in a biological brain, can transmit a signal to other neurons. An artificial neuron receives signals then processes them and can signal neurons connected to it. The «signal» at a connection is a real number, and the output of each neuron is computed by some non-linear function of the sum of its inputs. The connections are called edges. Neurons and edges typically have a weight that adjusts as learning proceeds. The weight increases or decreases the strength of the signal at a connection. Neurons may have a threshold such that a signal is sent only if the aggregate signal crosses that threshold.
Typically, neurons are aggregated into layers. Different layers may perform different transformations on their inputs. Signals travel from the first layer (the input layer), to the last layer (the output layer), possibly after traversing the layers multiple times.
Training[edit]
Neural networks learn (or are trained) by processing examples, each of which contains a known «input» and «result,» forming probability-weighted associations between the two, which are stored within the data structure of the net itself. The training of a neural network from a given example is usually conducted by determining the difference between the processed output of the network (often a prediction) and a target output. This difference is the error. The network then adjusts its weighted associations according to a learning rule and using this error value. Successive adjustments will cause the neural network to produce output that is increasingly similar to the target output. After a sufficient number of these adjustments, the training can be terminated based on certain criteria. This is known as supervised learning.
Such systems «learn» to perform tasks by considering examples, generally without being programmed with task-specific rules. For example, in image recognition, they might learn to identify images that contain cats by analyzing example images that have been manually labeled as «cat» or «no cat» and using the results to identify cats in other images. They do this without any prior knowledge of cats, for example, that they have fur, tails, whiskers, and cat-like faces. Instead, they automatically generate identifying characteristics from the examples that they process.
History[edit]
Warren McCulloch and Walter Pitts[3] (1943) opened the subject by creating a computational model for neural networks.[4] In the late 1940s, D. O. Hebb[5] created a learning hypothesis based on the mechanism of neural plasticity that became known as Hebbian learning. Farley and Wesley A. Clark[6] (1954) first used computational machines, then called «calculators», to simulate a Hebbian network. In 1958, psychologist Frank Rosenblatt invented the perceptron, the first artificial neural network,[7][8][9][10] funded by the United States Office of Naval Research.[11] The first functional networks with many layers were published by Ivakhnenko and Lapa in 1965, as the Group Method of Data Handling.[12][13][14] The basics of continuous backpropagation[12][15][16][17] were derived in the context of control theory by Kelley[18] in 1960 and by Bryson in 1961,[19] using principles of dynamic programming. Thereafter research stagnated following Minsky and Papert (1969),[20] who discovered that basic perceptrons were incapable of processing the exclusive-or circuit and that computers lacked sufficient power to process useful neural networks.
In 1970, Seppo Linnainmaa published the general method for automatic differentiation (AD) of discrete connected networks of nested differentiable functions.[21][22] In 1973, Dreyfus used backpropagation to adapt parameters of controllers in proportion to error gradients.[23] Werbos’s (1975) backpropagation algorithm enabled practical training of multi-layer networks. In 1982, he applied Linnainmaa’s AD method to neural networks in the way that became widely used.[15][24]
The development of metal–oxide–semiconductor (MOS) very-large-scale integration (VLSI), in the form of complementary MOS (CMOS) technology, enabled increasing MOS transistor counts in digital electronics. This provided more processing power for the development of practical artificial neural networks in the 1980s.[25]
In 1986 Rumelhart, Hinton and Williams showed that backpropagation learned interesting internal representations of words as feature vectors when trained to predict the next word in a sequence.[26]
From 1988 onward,[27][28] the use of neural networks transformed the field of protein structure prediction, in particular when the first cascading networks were trained on profiles (matrices) produced by multiple sequence alignments.[29]
In 1992, max-pooling was introduced to help with least-shift invariance and tolerance to deformation to aid 3D object recognition.[30][31][32] Schmidhuber adopted a multi-level hierarchy of networks (1992) pre-trained one level at a time by unsupervised learning and fine-tuned by backpropagation.[33]
Neural networks’ early successes included predicting the stock market and in 1995 a (mostly) self-driving car.[a][34]
Geoffrey Hinton et al. (2006) proposed learning a high-level representation using successive layers of binary or real-valued latent variables with a restricted Boltzmann machine[35] to model each layer. In 2012, Ng and Dean created a network that learned to recognize higher-level concepts, such as cats, only from watching unlabeled images.[36] Unsupervised pre-training and increased computing power from GPUs and distributed computing allowed the use of larger networks, particularly in image and visual recognition problems, which became known as «deep learning».[37]
Ciresan and colleagues (2010)[38] showed that despite the vanishing gradient problem, GPUs make backpropagation feasible for many-layered feedforward neural networks.[39] Between 2009 and 2012, ANNs began winning prizes in image recognition contests, approaching human level performance on various tasks, initially in pattern recognition and handwriting recognition.[40][41] For example, the bi-directional and multi-dimensional long short-term memory (LSTM)[42][43] of Graves et al. won three competitions in connected handwriting recognition in 2009 without any prior knowledge about the three languages to be learned.[42][43]
Ciresan and colleagues built the first pattern recognizers to achieve human-competitive/superhuman performance[44] on benchmarks such as traffic sign recognition (IJCNN 2012).
Models[edit]

Neuron and myelinated axon, with signal flow from inputs at dendrites to outputs at axon terminals
ANNs began as an attempt to exploit the architecture of the human brain to perform tasks that conventional algorithms had little success with. They soon reoriented towards improving empirical results, mostly abandoning attempts to remain true to their biological precursors. Neurons are connected to each other in various patterns, to allow the output of some neurons to become the input of others. The network forms a directed, weighted graph.[45]
An artificial neural network consists of a collection of simulated neurons. Each neuron is a node which is connected to other nodes via links that correspond to biological axon-synapse-dendrite connections. Each link has a weight, which determines the strength of one node’s influence on another.[46]
Artificial neurons[edit]
ANNs are composed of artificial neurons which are conceptually derived from biological neurons. Each artificial neuron has inputs and produces a single output which can be sent to multiple other neurons.[47] The inputs can be the feature values of a sample of external data, such as images or documents, or they can be the outputs of other neurons. The outputs of the final output neurons of the neural net accomplish the task, such as recognizing an object in an image.
To find the output of the neuron we take the weighted sum of all the inputs, weighted by the weights of the connections from the inputs to the neuron. We add a bias term to this sum.[48] This weighted sum is sometimes called the activation. This weighted sum is then passed through a (usually nonlinear) activation function to produce the output. The initial inputs are external data, such as images and documents. The ultimate outputs accomplish the task, such as recognizing an object in an image.[49]
Organization[edit]
The neurons are typically organized into multiple layers, especially in deep learning. Neurons of one layer connect only to neurons of the immediately preceding and immediately following layers. The layer that receives external data is the input layer. The layer that produces the ultimate result is the output layer. In between them are zero or more hidden layers. Single layer and unlayered networks are also used. Between two layers, multiple connection patterns are possible. They can be ‘fully connected’, with every neuron in one layer connecting to every neuron in the next layer. They can be pooling, where a group of neurons in one layer connect to a single neuron in the next layer, thereby reducing the number of neurons in that layer.[50] Neurons with only such connections form a directed acyclic graph and are known as feedforward networks.[51] Alternatively, networks that allow connections between neurons in the same or previous layers are known as recurrent networks.[52]
Hyperparameter[edit]
A hyperparameter is a constant parameter whose value is set before the learning process begins. The values of parameters are derived via learning. Examples of hyperparameters include learning rate, the number of hidden layers and batch size.[53] The values of some hyperparameters can be dependent on those of other hyperparameters. For example, the size of some layers can depend on the overall number of layers.
Learning[edit]
Learning is the adaptation of the network to better handle a task by considering sample observations. Learning involves adjusting the weights (and optional thresholds) of the network to improve the accuracy of the result. This is done by minimizing the observed errors. Learning is complete when examining additional observations does not usefully reduce the error rate. Even after learning, the error rate typically does not reach 0. If after learning, the error rate is too high, the network typically must be redesigned. Practically this is done by defining a cost function that is evaluated periodically during learning. As long as its output continues to decline, learning continues. The cost is frequently defined as a statistic whose value can only be approximated. The outputs are actually numbers, so when the error is low, the difference between the output (almost certainly a cat) and the correct answer (cat) is small. Learning attempts to reduce the total of the differences across the observations. Most learning models can be viewed as a straightforward application of optimization theory and statistical estimation.[45][54]
Learning rate[edit]
The learning rate defines the size of the corrective steps that the model takes to adjust for errors in each observation.[55] A high learning rate shortens the training time, but with lower ultimate accuracy, while a lower learning rate takes longer, but with the potential for greater accuracy. Optimizations such as Quickprop are primarily aimed at speeding up error minimization, while other improvements mainly try to increase reliability. In order to avoid oscillation inside the network such as alternating connection weights, and to improve the rate of convergence, refinements use an adaptive learning rate that increases or decreases as appropriate.[56] The concept of momentum allows the balance between the gradient and the previous change to be weighted such that the weight adjustment depends to some degree on the previous change. A momentum close to 0 emphasizes the gradient, while a value close to 1 emphasizes the last change.
Cost function[edit]
While it is possible to define a cost function ad hoc, frequently the choice is determined by the function’s desirable properties (such as convexity) or because it arises from the model (e.g. in a probabilistic model the model’s posterior probability can be used as an inverse cost).
Backpropagation[edit]
Backpropagation is a method used to adjust the connection weights to compensate for each error found during learning. The error amount is effectively divided among the connections. Technically, backprop calculates the gradient (the derivative) of the cost function associated with a given state with respect to the weights. The weight updates can be done via stochastic gradient descent or other methods, such as Extreme Learning Machines,[57] «No-prop» networks,[58] training without backtracking,[59] «weightless» networks,[60][61] and non-connectionist neural networks.[citation needed]
Learning paradigms[edit]
Machine learning is commonly separated into three main learning paradigms, supervised learning, unsupervised learning and reinforcement learning.[62] Each corresponds to a particular learning task.
Supervised learning[edit]
Supervised learning uses a set of paired inputs and desired outputs. The learning task is to produce the desired output for each input. In this case, the cost function is related to eliminating incorrect deductions.[63] A commonly used cost is the mean-squared error, which tries to minimize the average squared error between the network’s output and the desired output. Tasks suited for supervised learning are pattern recognition (also known as classification) and regression (also known as function approximation). Supervised learning is also applicable to sequential data (e.g., for hand writing, speech and gesture recognition). This can be thought of as learning with a «teacher», in the form of a function that provides continuous feedback on the quality of solutions obtained thus far.
Unsupervised learning[edit]
In unsupervised learning, input data is given along with the cost function, some function of the data  and the network’s output. The cost function is dependent on the task (the model domain) and any a priori assumptions (the implicit properties of the model, its parameters and the observed variables). As a trivial example, consider the model
and the network’s output. The cost function is dependent on the task (the model domain) and any a priori assumptions (the implicit properties of the model, its parameters and the observed variables). As a trivial example, consider the model  where
where  is a constant and the cost
is a constant and the cost ![textstyle C=E[(x-f(x))^{2}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/2929ecb1606fdfeaddc55477d9671e11c034e21c) . Minimizing this cost produces a value of that is equal to the mean of the data. The cost function can be much more complicated. Its form depends on the application: for example, in compression it could be related to the mutual information between and
. Minimizing this cost produces a value of that is equal to the mean of the data. The cost function can be much more complicated. Its form depends on the application: for example, in compression it could be related to the mutual information between and  , whereas in statistical modeling, it could be related to the posterior probability of the model given the data (note that in both of those examples, those quantities would be maximized rather than minimized). Tasks that fall within the paradigm of unsupervised learning are in general estimation problems; the applications include clustering, the estimation of statistical distributions, compression and filtering.
, whereas in statistical modeling, it could be related to the posterior probability of the model given the data (note that in both of those examples, those quantities would be maximized rather than minimized). Tasks that fall within the paradigm of unsupervised learning are in general estimation problems; the applications include clustering, the estimation of statistical distributions, compression and filtering.
Reinforcement learning[edit]
In applications such as playing video games, an actor takes a string of actions, receiving a generally unpredictable response from the environment after each one. The goal is to win the game, i.e., generate the most positive (lowest cost) responses. In reinforcement learning, the aim is to weight the network (devise a policy) to perform actions that minimize long-term (expected cumulative) cost. At each point in time the agent performs an action and the environment generates an observation and an instantaneous cost, according to some (usually unknown) rules. The rules and the long-term cost usually only can be estimated. At any juncture, the agent decides whether to explore new actions to uncover their costs or to exploit prior learning to proceed more quickly.
Formally the environment is modeled as a Markov decision process (MDP) with states  and actions
and actions  . Because the state transitions are not known, probability distributions are used instead: the instantaneous cost distribution
. Because the state transitions are not known, probability distributions are used instead: the instantaneous cost distribution  , the observation distribution
, the observation distribution  and the transition distribution
and the transition distribution  , while a policy is defined as the conditional distribution over actions given the observations. Taken together, the two define a Markov chain (MC). The aim is to discover the lowest-cost MC.
, while a policy is defined as the conditional distribution over actions given the observations. Taken together, the two define a Markov chain (MC). The aim is to discover the lowest-cost MC.
ANNs serve as the learning component in such applications.[64][65] Dynamic programming coupled with ANNs (giving neurodynamic programming)[66] has been applied to problems such as those involved in vehicle routing,[67] video games, natural resource management[68][69] and medicine[70] because of ANNs ability to mitigate losses of accuracy even when reducing the discretization grid density for numerically approximating the solution of control problems. Tasks that fall within the paradigm of reinforcement learning are control problems, games and other sequential decision making tasks.
Self-learning[edit]
Self-learning in neural networks was introduced in 1982 along with a neural network capable of self-learning named Crossbar Adaptive Array (CAA).[71] It is a system with only one input, situation s, and only one output, action (or behavior) a. It has neither external advice input nor external reinforcement input from the environment. The CAA computes, in a crossbar fashion, both decisions about actions and emotions (feelings) about encountered situations. The system is driven by the interaction between cognition and emotion.[72] Given the memory matrix, W =||w(a,s)||, the crossbar self-learning algorithm in each iteration performs the following computation:
In situation s perform action a; Receive consequence situation s'; Compute emotion of being in consequence situation v(s'); Update crossbar memory w'(a,s) = w(a,s) + v(s').
The backpropagated value (secondary reinforcement) is the emotion toward the consequence situation. The CAA exists in two environments, one is behavioral environment where it behaves, and the other is genetic environment, where from it initially and only once receives initial emotions about to be encountered situations in the behavioral environment. Having received the genome vector (species vector) from the genetic environment, the CAA will learn a goal-seeking behavior, in the behavioral environment that contains both desirable and undesirable situations.[73]
Neuroevolution[edit]
Neuroevolution can create neural network topologies and weights using evolutionary computation. It is competitive with sophisticated gradient descent approaches[citation needed]. One advantage of neuroevolution is that it may be less prone to get caught in «dead ends».[74]
Stochastic neural network[edit]
Stochastic neural networks originating from Sherrington–Kirkpatrick models are a type of artificial neural network built by introducing random variations into the network, either by giving the network’s artificial neurons stochastic transfer functions, or by giving them stochastic weights. This makes them useful tools for optimization problems, since the random fluctuations help the network escape from local minima.[75] Stochastic neural networks trained using a Bayesian approach are known as Bayesian neural networks.[76]
Other[edit]
In a Bayesian framework, a distribution over the set of allowed models is chosen to minimize the cost. Evolutionary methods,[77] gene expression programming,[78] simulated annealing,[79] expectation-maximization, non-parametric methods and particle swarm optimization[80] are other learning algorithms. Convergent recursion is a learning algorithm for cerebellar model articulation controller (CMAC) neural networks.[81][82]
Modes[edit]
Two modes of learning are available: stochastic and batch. In stochastic learning, each input creates a weight adjustment. In batch learning weights are adjusted based on a batch of inputs, accumulating errors over the batch. Stochastic learning introduces «noise» into the process, using the local gradient calculated from one data point; this reduces the chance of the network getting stuck in local minima. However, batch learning typically yields a faster, more stable descent to a local minimum, since each update is performed in the direction of the batch’s average error. A common compromise is to use «mini-batches», small batches with samples in each batch selected stochastically from the entire data set.
Types[edit]
ANNs have evolved into a broad family of techniques that have advanced the state of the art across multiple domains. The simplest types have one or more static components, including number of units, number of layers, unit weights and topology. Dynamic types allow one or more of these to evolve via learning. The latter are much more complicated, but can shorten learning periods and produce better results. Some types allow/require learning to be «supervised» by the operator, while others operate independently. Some types operate purely in hardware, while others are purely software and run on general purpose computers.
Some of the main breakthroughs include: convolutional neural networks that have proven particularly successful in processing visual and other two-dimensional data;[83][84] long short-term memory avoid the vanishing gradient problem[85] and can handle signals that have a mix of low and high frequency components aiding large-vocabulary speech recognition,[86][87] text-to-speech synthesis,[88][15][89] and photo-real talking heads;[90] competitive networks such as generative adversarial networks in which multiple networks (of varying structure) compete with each other, on tasks such as winning a game[91] or on deceiving the opponent about the authenticity of an input.[92]
Network design[edit]
Neural architecture search (NAS) uses machine learning to automate ANN design. Various approaches to NAS have designed networks that compare well with hand-designed systems. The basic search algorithm is to propose a candidate model, evaluate it against a dataset and use the results as feedback to teach the NAS network.[93] Available systems include AutoML and AutoKeras.[94]
Design issues include deciding the number, type and connectedness of network layers, as well as the size of each and the connection type (full, pooling, …).
Hyperparameters must also be defined as part of the design (they are not learned), governing matters such as how many neurons are in each layer, learning rate, step, stride, depth, receptive field and padding (for CNNs), etc.[95]
Use[edit]
Using Artificial neural networks requires an understanding of their characteristics.
- Choice of model: This depends on the data representation and the application. Overly complex models are slow learning.
- Learning algorithm: Numerous trade-offs exist between learning algorithms. Almost any algorithm will work well with the correct hyperparameters for training on a particular data set. However, selecting and tuning an algorithm for training on unseen data requires significant experimentation.
- Robustness: If the model, cost function and learning algorithm are selected appropriately, the resulting ANN can become robust.
ANN capabilities fall within the following broad categories:[citation needed]
- Function approximation, or regression analysis, including time series prediction, fitness approximation and modeling.
- Classification, including pattern and sequence recognition, novelty detection and sequential decision making.[96]
- Data processing, including filtering, clustering, blind source separation and compression.
- Robotics, including directing manipulators and prostheses.
Applications[edit]
Because of their ability to reproduce and model nonlinear processes, artificial neural networks have found applications in many disciplines. Application areas include system identification and control (vehicle control, trajectory prediction,[97] process control, natural resource management), quantum chemistry,[98] general game playing,[99] pattern recognition (radar systems, face identification, signal classification,[100] 3D reconstruction,[101] object recognition and more), sensor data analysis,[102] sequence recognition (gesture, speech, handwritten and printed text recognition[103]), medical diagnosis, finance[104] (e.g. automated trading systems), data mining, visualization, machine translation, social network filtering[105] and e-mail spam filtering. ANNs have been used to diagnose several types of cancers[106][107] and to distinguish highly invasive cancer cell lines from less invasive lines using only cell shape information.[108][109]
ANNs have been used to accelerate reliability analysis of infrastructures subject to natural disasters[110][111] and to predict foundation settlements.[112] ANNs have also been used for building black-box models in geoscience: hydrology,[113][114] ocean modelling and coastal engineering,[115][116] and geomorphology.[117] ANNs have been employed in cybersecurity, with the objective to discriminate between legitimate activities and malicious ones. For example, machine learning has been used for classifying Android malware,[118] for identifying domains belonging to threat actors and for detecting URLs posing a security risk.[119] Research is underway on ANN systems designed for penetration testing, for detecting botnets,[120] credit cards frauds[121] and network intrusions.
ANNs have been proposed as a tool to solve partial differential equations in physics[122][123][124] and simulate the properties of many-body open quantum systems.[125][126][127][128] In brain research ANNs have studied short-term behavior of individual neurons,[129] the dynamics of neural circuitry arise from interactions between individual neurons and how behavior can arise from abstract neural modules that represent complete subsystems. Studies considered long-and short-term plasticity of neural systems and their relation to learning and memory from the individual neuron to the system level.
Theoretical properties[edit]
Computational power[edit]
The multilayer perceptron is a universal function approximator, as proven by the universal approximation theorem. However, the proof is not constructive regarding the number of neurons required, the network topology, the weights and the learning parameters.
A specific recurrent architecture with rational-valued weights (as opposed to full precision real number-valued weights) has the power of a universal Turing machine,[130] using a finite number of neurons and standard linear connections. Further, the use of irrational values for weights results in a machine with super-Turing power.[131]
Capacity[edit]
A model’s «capacity» property corresponds to its ability to model any given function. It is related to the amount of information that can be stored in the network and to the notion of complexity.
Two notions of capacity are known by the community. The information capacity and the VC Dimension. The information capacity of a perceptron is intensively discussed in Sir David MacKay’s book[132] which summarizes work by Thomas Cover.[133] The capacity of a network of standard neurons (not convolutional) can be derived by four rules[134] that derive from understanding a neuron as an electrical element. The information capacity captures the functions modelable by the network given any data as input. The second notion, is the VC dimension. VC Dimension uses the principles of measure theory and finds the maximum capacity under the best possible circumstances. This is, given input data in a specific form. As noted in,[132] the VC Dimension for arbitrary inputs is half the information capacity of a Perceptron. The VC Dimension for arbitrary points is sometimes referred to as Memory Capacity.[135]
Convergence[edit]
Models may not consistently converge on a single solution, firstly because local minima may exist, depending on the cost function and the model. Secondly, the optimization method used might not guarantee to converge when it begins far from any local minimum. Thirdly, for sufficiently large data or parameters, some methods become impractical.
Another issue worthy to mention is that training may cross some Saddle point which may lead the convergence to the wrong direction.
The convergence behavior of certain types of ANN architectures are more understood than others. When the width of network approaches to infinity, the ANN is well described by its first order Taylor expansion throughout training, and so inherits the convergence behavior of affine models.[136][137] Another example is when parameters are small, it is observed that ANNs often fits target functions from low to high frequencies. This behavior is referred to as the spectral bias, or frequency principle, of neural networks.[138][139][140][141] This phenomenon is the opposite to the behavior of some well studied iterative numerical schemes such as Jacobi method. Deeper neural networks have been observed to be more biased towards low frequency functions.[142]
Generalization and statistics[edit]
Applications whose goal is to create a system that generalizes well to unseen examples, face the possibility of over-training. This arises in convoluted or over-specified systems when the network capacity significantly exceeds the needed free parameters. Two approaches address over-training. The first is to use cross-validation and similar techniques to check for the presence of over-training and to select hyperparameters to minimize the generalization error.
The second is to use some form of regularization. This concept emerges in a probabilistic (Bayesian) framework, where regularization can be performed by selecting a larger prior probability over simpler models; but also in statistical learning theory, where the goal is to minimize over two quantities: the ’empirical risk’ and the ‘structural risk’, which roughly corresponds to the error over the training set and the predicted error in unseen data due to overfitting.

Confidence analysis of a neural network
Supervised neural networks that use a mean squared error (MSE) cost function can use formal statistical methods to determine the confidence of the trained model. The MSE on a validation set can be used as an estimate for variance. This value can then be used to calculate the confidence interval of network output, assuming a normal distribution. A confidence analysis made this way is statistically valid as long as the output probability distribution stays the same and the network is not modified.
By assigning a softmax activation function, a generalization of the logistic function, on the output layer of the neural network (or a softmax component in a component-based network) for categorical target variables, the outputs can be interpreted as posterior probabilities. This is useful in classification as it gives a certainty measure on classifications.
The softmax activation function is:

Criticism[edit]
Training[edit]
A common criticism of neural networks, particularly in robotics, is that they require too much training for real-world operation.[citation needed] Potential solutions include randomly shuffling training examples, by using a numerical optimization algorithm that does not take too large steps when changing the network connections following an example, grouping examples in so-called mini-batches and/or introducing a recursive least squares algorithm for CMAC.[81]
Theory[edit]
A central claim[citation needed] of ANNs is that they embody new and powerful general principles for processing information. These principles are ill-defined. It is often claimed[by whom?] that they are emergent from the network itself. This allows simple statistical association (the basic function of artificial neural networks) to be described as learning or recognition. In 1997, Alexander Dewdney commented that, as a result, artificial neural networks have a «something-for-nothing quality, one that imparts a peculiar aura of laziness and a distinct lack of curiosity about just how good these computing systems are. No human hand (or mind) intervenes; solutions are found as if by magic; and no one, it seems, has learned anything».[143] One response to Dewdney is that neural networks handle many complex and diverse tasks, ranging from autonomously flying aircraft[144] to detecting credit card fraud to mastering the game of Go.
Technology writer Roger Bridgman commented:
Neural networks, for instance, are in the dock not only because they have been hyped to high heaven, (what hasn’t?) but also because you could create a successful net without understanding how it worked: the bunch of numbers that captures its behaviour would in all probability be «an opaque, unreadable table…valueless as a scientific resource».
In spite of his emphatic declaration that science is not technology, Dewdney seems here to pillory neural nets as bad science when most of those devising them are just trying to be good engineers. An unreadable table that a useful machine could read would still be well worth having.[145]
Biological brains use both shallow and deep circuits as reported by brain anatomy,[146] displaying a wide variety of invariance. Weng[147] argued that the brain self-wires largely according to signal statistics and therefore, a serial cascade cannot catch all major statistical dependencies.
Hardware[edit]
Large and effective neural networks require considerable computing resources.[148] While the brain has hardware tailored to the task of processing signals through a graph of neurons, simulating even a simplified neuron on von Neumann architecture may consume vast amounts of memory and storage. Furthermore, the designer often needs to transmit signals through many of these connections and their associated neurons – which require enormous CPU power and time.
Schmidhuber noted that the resurgence of neural networks in the twenty-first century is largely attributable to advances in hardware: from 1991 to 2015, computing power, especially as delivered by GPGPUs (on GPUs), has increased around a million-fold, making the standard backpropagation algorithm feasible for training networks that are several layers deeper than before.[12] The use of accelerators such as FPGAs and GPUs can reduce training times from months to days.[148]
Neuromorphic engineering or a physical neural network addresses the hardware difficulty directly, by constructing non-von-Neumann chips to directly implement neural networks in circuitry. Another type of chip optimized for neural network processing is called a Tensor Processing Unit, or TPU.[149]
Practical counterexamples[edit]
Analyzing what has been learned by an ANN is much easier than analyzing what has been learned by a biological neural network. Furthermore, researchers involved in exploring learning algorithms for neural networks are gradually uncovering general principles that allow a learning machine to be successful. For example, local vs. non-local learning and shallow vs. deep architecture.[150]
Hybrid approaches[edit]
Advocates of hybrid models (combining neural networks and symbolic approaches) say that such a mixture can better capture the mechanisms of the human mind.[151]
Gallery[edit]
-

A single-layer feedforward artificial neural network. Arrows originating from
 are omitted for clarity. There are p inputs to this network and q outputs. In this system, the value of the qth output, would be calculated as .
are omitted for clarity. There are p inputs to this network and q outputs. In this system, the value of the qth output, would be calculated as .
-

A two-layer feedforward artificial neural network
-

An artificial neural network
-

An ANN dependency graph
-

A single-layer feedforward artificial neural network with 4 inputs, 6 hidden and 2 outputs. Given position state and direction outputs wheel based control values.
-
A two-layer feedforward artificial neural network with 8 inputs, 2×8 hidden and 2 outputs. Given position state, direction and other environment values outputs thruster based control values.
-

Parallel pipeline structure of CMAC neural network. This learning algorithm can converge in one step.










See also[edit]
- ADALINE
- Autoencoder
- Bio-inspired computing
- Blue Brain Project
- Catastrophic interference
- Cognitive architecture
- Connectionist expert system
- Connectomics
- Large width limits of neural networks
- List of machine learning concepts
- Neural gas
- Neural network software
- Optical neural network
- Parallel distributed processing
- Philosophy of artificial intelligence
- Recurrent neural networks
- Spiking neural network
- Tensor product network
Notes[edit]
- ^ Steering for the 1995 «No Hands Across America» required «only a few human assists».
References[edit]
- ^ Hardesty, Larry (14 April 2017). «Explained: Neural networks». MIT News Office. Retrieved 2 June 2022.
- ^ Yang, Z.R.; Yang, Z. (2014). Comprehensive Biomedical Physics. Karolinska Institute, Stockholm, Sweden: Elsevier. p. 1. ISBN 978-0-444-53633-4. Archived from the original on 28 July 2022. Retrieved 28 July 2022.
- ^ McCulloch, Warren; Walter Pitts (1943). «A Logical Calculus of Ideas Immanent in Nervous Activity». Bulletin of Mathematical Biophysics. 5 (4): 115–133. doi:10.1007/BF02478259.
- ^ Kleene, S.C. (1956). «Representation of Events in Nerve Nets and Finite Automata». Annals of Mathematics Studies. No. 34. Princeton University Press. pp. 3–41. Retrieved 17 June 2017.
- ^ Hebb, Donald (1949). The Organization of Behavior. New York: Wiley. ISBN 978-1-135-63190-1.
- ^ Farley, B.G.; W.A. Clark (1954). «Simulation of Self-Organizing Systems by Digital Computer». IRE Transactions on Information Theory. 4 (4): 76–84. doi:10.1109/TIT.1954.1057468.
- ^ Haykin (2008) Neural Networks and Learning Machines, 3rd edition
- ^ Rosenblatt, F. (1958). «The Perceptron: A Probabilistic Model For Information Storage And Organization in the Brain». Psychological Review. 65 (6): 386–408. CiteSeerX 10.1.1.588.3775. doi:10.1037/h0042519. PMID 13602029.
- ^ Werbos, P.J. (1975). Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences.
- ^ Rosenblatt, Frank (1957). «The Perceptron—a perceiving and recognizing automaton». Report 85-460-1. Cornell Aeronautical Laboratory.
- ^ Olazaran, Mikel (1996). «A Sociological Study of the Official History of the Perceptrons Controversy». Social Studies of Science. 26 (3): 611–659. doi:10.1177/030631296026003005. JSTOR 285702. S2CID 16786738.
- ^ a b c Schmidhuber, J. (2015). «Deep Learning in Neural Networks: An Overview». Neural Networks. 61: 85–117. arXiv:1404.7828. doi:10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509.
- ^ Ivakhnenko, A. G. (1973). Cybernetic Predicting Devices. CCM Information Corporation.
- ^ Ivakhnenko, A. G.; Grigorʹevich Lapa, Valentin (1967). Cybernetics and forecasting techniques. American Elsevier Pub. Co.
- ^ a b c Schmidhuber, Jürgen (2015). «Deep Learning». Scholarpedia. 10 (11): 85–117. Bibcode:2015SchpJ..1032832S. doi:10.4249/scholarpedia.32832.
- ^ Dreyfus, Stuart E. (1 September 1990). «Artificial neural networks, back propagation, and the Kelley-Bryson gradient procedure». Journal of Guidance, Control, and Dynamics. 13 (5): 926–928. Bibcode:1990JGCD…13..926D. doi:10.2514/3.25422. ISSN 0731-5090.
- ^ Mizutani, E.; Dreyfus, S.E.; Nishio, K. (2000). «On derivation of MLP backpropagation from the Kelley-Bryson optimal-control gradient formula and its application». Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for the New Millennium. IEEE: 167–172 vol.2. doi:10.1109/ijcnn.2000.857892. ISBN 0-7695-0619-4. S2CID 351146.
- ^ Kelley, Henry J. (1960). «Gradient theory of optimal flight paths». ARS Journal. 30 (10): 947–954. doi:10.2514/8.5282.
- ^ «A gradient method for optimizing multi-stage allocation processes». Proceedings of the Harvard Univ. Symposium on digital computers and their applications. April 1961.
- ^ Minsky, Marvin; Papert, Seymour (1969). Perceptrons: An Introduction to Computational Geometry. MIT Press. ISBN 978-0-262-63022-1.
- ^ Linnainmaa, Seppo (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors (Masters) (in Finnish). University of Helsinki. pp. 6–7.
- ^ Linnainmaa, Seppo (1976). «Taylor expansion of the accumulated rounding error». BIT Numerical Mathematics. 16 (2): 146–160. doi:10.1007/bf01931367. S2CID 122357351.
- ^ Dreyfus, Stuart (1973). «The computational solution of optimal control problems with time lag». IEEE Transactions on Automatic Control. 18 (4): 383–385. doi:10.1109/tac.1973.1100330.
- ^ Werbos, Paul (1982). «Applications of advances in nonlinear sensitivity analysis» (PDF). System modeling and optimization. Springer. pp. 762–770. Archived (PDF) from the original on 14 April 2016. Retrieved 2 July 2017.
- ^ Mead, Carver A.; Ismail, Mohammed (8 May 1989). Analog VLSI Implementation of Neural Systems (PDF). The Kluwer International Series in Engineering and Computer Science. Vol. 80. Norwell, MA: Kluwer Academic Publishers. doi:10.1007/978-1-4613-1639-8. ISBN 978-1-4613-1639-8. Archived (PDF) from the original on 6 November 2019. Retrieved 24 January 2020.
- ^ David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams , «Learning representations by back-propagating errors Archived 8 March 2021 at the Wayback Machine,» Nature’, 323, pages 533–536 1986.
- ^ Qian, Ning, and Terrence J. Sejnowski. «Predicting the secondary structure of globular proteins using neural network models.» Journal of molecular biology 202, no. 4 (1988): 865-884.
- ^ Bohr, Henrik, Jakob Bohr, Søren Brunak, Rodney MJ Cotterill, Benny Lautrup, Leif Nørskov, Ole H. Olsen, and Steffen B. Petersen. «Protein secondary structure and homology by neural networks The α-helices in rhodopsin.» FEBS letters 241, (1988): 223-228
- ^ Rost, Burkhard, and Chris Sander. «Prediction of protein secondary structure at better than 70% accuracy.» Journal of molecular biology 232, no. 2 (1993): 584-599.
- ^ J. Weng, N. Ahuja and T. S. Huang, «Cresceptron: a self-organizing neural network which grows adaptively Archived 21 September 2017 at the Wayback Machine,» Proc. International Joint Conference on Neural Networks, Baltimore, Maryland, vol I, pp. 576–581, June 1992.
- ^ J. Weng, N. Ahuja and T. S. Huang, «Learning recognition and segmentation of 3-D objects from 2-D images Archived 21 September 2017 at the Wayback Machine,» Proc. 4th International Conf. Computer Vision, Berlin, Germany, pp. 121–128, May 1993.
- ^ J. Weng, N. Ahuja and T. S. Huang, «Learning recognition and segmentation using the Cresceptron Archived 25 January 2021 at the Wayback Machine,» International Journal of Computer Vision, vol. 25, no. 2, pp. 105–139, Nov. 1997.
- ^ J. Schmidhuber., «Learning complex, extended sequences using the principle of history compression Archived 18 March 2020 at the Wayback Machine,» Neural Computation, 4, pp. 234–242, 1992.
- ^ Domingos, Pedro (22 September 2015). «chapter 4». The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World. Basic Books. ISBN 978-0465065707.
- ^ Smolensky, P. (1986). «Information processing in dynamical systems: Foundations of harmony theory.». In D. E. Rumelhart; J. L. McClelland; PDP Research Group (eds.). Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Vol. 1. pp. 194–281. ISBN 978-0-262-68053-0.
- ^ Ng, Andrew; Dean, Jeff (2012). «Building High-level Features Using Large Scale Unsupervised Learning». arXiv:1112.6209 [cs.LG].
- ^ Ian Goodfellow and Yoshua Bengio and Aaron Courville (2016). Deep Learning. MIT Press. Archived from the original on 16 April 2016. Retrieved 1 June 2016.
- ^ Cireşan, Dan Claudiu; Meier, Ueli; Gambardella, Luca Maria; Schmidhuber, Jürgen (21 September 2010). «Deep, Big, Simple Neural Nets for Handwritten Digit Recognition». Neural Computation. 22 (12): 3207–3220. arXiv:1003.0358. doi:10.1162/neco_a_00052. ISSN 0899-7667. PMID 20858131. S2CID 1918673.
- ^ Dominik Scherer, Andreas C. Müller, and Sven Behnke: «Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition Archived 3 April 2018 at the Wayback Machine,» In 20th International Conference Artificial Neural Networks (ICANN), pp. 92–101, 2010. doi:10.1007/978-3-642-15825-4_10.
- ^ 2012 Kurzweil AI Interview Archived 31 August 2018 at the Wayback Machine with Jürgen Schmidhuber on the eight competitions won by his Deep Learning team 2009–2012
- ^ «How bio-inspired deep learning keeps winning competitions | KurzweilAI». www.kurzweilai.net. Archived from the original on 31 August 2018. Retrieved 16 June 2017.
- ^ a b Graves, Alex; Schmidhuber, Jürgen (2009). «Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks» (PDF). In Koller, D.; Schuurmans, Dale; Bengio, Yoshua; Bottou, L. (eds.). Advances in Neural Information Processing Systems 21 (NIPS 2008). Neural Information Processing Systems (NIPS) Foundation. pp. 545–552. ISBN 9781605609492.
- ^ a b Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. (May 2009). «A Novel Connectionist System for Unconstrained Handwriting Recognition» (PDF). IEEE Transactions on Pattern Analysis and Machine Intelligence. 31 (5): 855–868. CiteSeerX 10.1.1.139.4502. doi:10.1109/tpami.2008.137. ISSN 0162-8828. PMID 19299860. S2CID 14635907. Archived (PDF) from the original on 2 January 2014. Retrieved 30 July 2014.
- ^ Ciresan, Dan; Meier, U.; Schmidhuber, J. (June 2012). Multi-column deep neural networks for image classification. 2012 IEEE Conference on Computer Vision and Pattern Recognition. pp. 3642–3649. arXiv:1202.2745. Bibcode:2012arXiv1202.2745C. CiteSeerX 10.1.1.300.3283. doi:10.1109/cvpr.2012.6248110. ISBN 978-1-4673-1228-8. S2CID 2161592.
- ^ a b Zell, Andreas (2003). «chapter 5.2». Simulation neuronaler Netze [Simulation of Neural Networks] (in German) (1st ed.). Addison-Wesley. ISBN 978-3-89319-554-1. OCLC 249017987.
- ^ Artificial intelligence (3rd ed.). Addison-Wesley Pub. Co. 1992. ISBN 0-201-53377-4.
- ^ Abbod, Maysam F (2007). «Application of Artificial Intelligence to the Management of Urological Cancer». The Journal of Urology. 178 (4): 1150–1156. doi:10.1016/j.juro.2007.05.122. PMID 17698099.
- ^ DAWSON, CHRISTIAN W (1998). «An artificial neural network approach to rainfall-runoff modelling». Hydrological Sciences Journal. 43 (1): 47–66. doi:10.1080/02626669809492102.
- ^ «The Machine Learning Dictionary». www.cse.unsw.edu.au. Archived from the original on 26 August 2018. Retrieved 4 November 2009.
- ^ Ciresan, Dan; Ueli Meier; Jonathan Masci; Luca M. Gambardella; Jurgen Schmidhuber (2011). «Flexible, High Performance Convolutional Neural Networks for Image Classification» (PDF). Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence-Volume Volume Two. 2: 1237–1242. Archived (PDF) from the original on 5 April 2022. Retrieved 7 July 2022.
- ^ Zell, Andreas (1994). Simulation Neuronaler Netze [Simulation of Neural Networks] (in German) (1st ed.). Addison-Wesley. p. 73. ISBN 3-89319-554-8.
- ^ Miljanovic, Milos (February–March 2012). «Comparative analysis of Recurrent and Finite Impulse Response Neural Networks in Time Series Prediction» (PDF). Indian Journal of Computer and Engineering. 3 (1).
- ^ Lau, Suki (10 July 2017). «A Walkthrough of Convolutional Neural Network – Hyperparameter Tuning». Medium. Archived from the original on 4 February 2023. Retrieved 23 August 2019.
- ^ Kelleher, John D.; Mac Namee, Brian; D’Arcy, Aoife (2020). «7-8». Fundamentals of machine learning for predictive data analytics: algorithms, worked examples, and case studies (2nd ed.). Cambridge, MA. ISBN 978-0-262-36110-1. OCLC 1162184998.
- ^ Wei, Jiakai (26 April 2019). «Forget the Learning Rate, Decay Loss». arXiv:1905.00094 [cs.LG].
- ^ Li, Y.; Fu, Y.; Li, H.; Zhang, S. W. (1 June 2009). The Improved Training Algorithm of Back Propagation Neural Network with Self-adaptive Learning Rate. 2009 International Conference on Computational Intelligence and Natural Computing. Vol. 1. pp. 73–76. doi:10.1109/CINC.2009.111. ISBN 978-0-7695-3645-3. S2CID 10557754.
- ^ Huang, Guang-Bin; Zhu, Qin-Yu; Siew, Chee-Kheong (2006). «Extreme learning machine: theory and applications». Neurocomputing. 70 (1): 489–501. CiteSeerX 10.1.1.217.3692. doi:10.1016/j.neucom.2005.12.126. S2CID 116858.
- ^ Widrow, Bernard; et al. (2013). «The no-prop algorithm: A new learning algorithm for multilayer neural networks». Neural Networks. 37: 182–188. doi:10.1016/j.neunet.2012.09.020. PMID 23140797.
- ^ Ollivier, Yann; Charpiat, Guillaume (2015). «Training recurrent networks without backtracking». arXiv:1507.07680 [cs.NE].
- ^ Hinton, G. E. (2010). «A Practical Guide to Training Restricted Boltzmann Machines». Tech. Rep. UTML TR 2010-003. Archived from the original on 9 May 2021. Retrieved 27 June 2017.
- ^ ESANN. 2009.[full citation needed]
- ^ Bernard, Etienne (2021). Introduction to Machine Learning. Wolfram Media Inc. p. 9. ISBN 978-1-579550-48-6.
- ^ Ojha, Varun Kumar; Abraham, Ajith; Snášel, Václav (1 April 2017). «Metaheuristic design of feedforward neural networks: A review of two decades of research». Engineering Applications of Artificial Intelligence. 60: 97–116. arXiv:1705.05584. Bibcode:2017arXiv170505584O. doi:10.1016/j.engappai.2017.01.013. S2CID 27910748.
- ^ Dominic, S.; Das, R.; Whitley, D.; Anderson, C. (July 1991). «Genetic reinforcement learning for neural networks». IJCNN-91-Seattle International Joint Conference on Neural Networks. IJCNN-91-Seattle International Joint Conference on Neural Networks. Seattle, Washington, USA: IEEE. pp. 71–76. doi:10.1109/IJCNN.1991.155315. ISBN 0-7803-0164-1.
- ^ Hoskins, J.C.; Himmelblau, D.M. (1992). «Process control via artificial neural networks and reinforcement learning». Computers & Chemical Engineering. 16 (4): 241–251. doi:10.1016/0098-1354(92)80045-B.
- ^ Bertsekas, D.P.; Tsitsiklis, J.N. (1996). Neuro-dynamic programming. Athena Scientific. p. 512. ISBN 978-1-886529-10-6. Archived from the original on 29 June 2017. Retrieved 17 June 2017.
- ^ Secomandi, Nicola (2000). «Comparing neuro-dynamic programming algorithms for the vehicle routing problem with stochastic demands». Computers & Operations Research. 27 (11–12): 1201–1225. CiteSeerX 10.1.1.392.4034. doi:10.1016/S0305-0548(99)00146-X.
- ^ de Rigo, D.; Rizzoli, A. E.; Soncini-Sessa, R.; Weber, E.; Zenesi, P. (2001). «Neuro-dynamic programming for the efficient management of reservoir networks». Proceedings of MODSIM 2001, International Congress on Modelling and Simulation. MODSIM 2001, International Congress on Modelling and Simulation. Canberra, Australia: Modelling and Simulation Society of Australia and New Zealand. doi:10.5281/zenodo.7481. ISBN 0-86740-525-2. Archived from the original on 7 August 2013. Retrieved 29 July 2013.
- ^ Damas, M.; Salmeron, M.; Diaz, A.; Ortega, J.; Prieto, A.; Olivares, G. (2000). «Genetic algorithms and neuro-dynamic programming: application to water supply networks». Proceedings of 2000 Congress on Evolutionary Computation. 2000 Congress on Evolutionary Computation. Vol. 1. La Jolla, California, USA: IEEE. pp. 7–14. doi:10.1109/CEC.2000.870269. ISBN 0-7803-6375-2.
- ^ Deng, Geng; Ferris, M.C. (2008). Neuro-dynamic programming for fractionated radiotherapy planning. Springer Optimization and Its Applications. Vol. 12. pp. 47–70. CiteSeerX 10.1.1.137.8288. doi:10.1007/978-0-387-73299-2_3. ISBN 978-0-387-73298-5.
- ^ Bozinovski, S. (1982). «A self-learning system using secondary reinforcement». In R. Trappl (ed.) Cybernetics and Systems Research: Proceedings of the Sixth European Meeting on Cybernetics and Systems Research. North Holland. pp. 397–402. ISBN 978-0-444-86488-8.
- ^ Bozinovski, S. (2014) «Modeling mechanisms of cognition-emotion interaction in artificial neural networks, since 1981 Archived 23 March 2019 at the Wayback Machine.» Procedia Computer Science p. 255-263
- ^ Bozinovski, Stevo; Bozinovska, Liljana (2001). «Self-learning agents: A connectionist theory of emotion based on crossbar value judgment». Cybernetics and Systems. 32 (6): 637–667. doi:10.1080/01969720118145. S2CID 8944741.
- ^ «Artificial intelligence can ‘evolve’ to solve problems». Science | AAAS. 10 January 2018. Archived from the original on 9 December 2021. Retrieved 7 February 2018.
- ^ Turchetti, Claudio (2004), Stochastic Models of Neural Networks, Frontiers in artificial intelligence and applications: Knowledge-based intelligent engineering systems, vol. 102, IOS Press, ISBN 9781586033880
- ^ Jospin, Laurent Valentin; Laga, Hamid; Boussaid, Farid; Buntine, Wray; Bennamoun, Mohammed (2022). «Hands-On Bayesian Neural Networks—A Tutorial for Deep Learning Users». IEEE Computational Intelligence Magazine. 17 (2): 29–48. arXiv:2007.06823. doi:10.1109/mci.2022.3155327. ISSN 1556-603X. S2CID 220514248. Archived from the original on 4 February 2023. Retrieved 19 November 2022.
- ^ de Rigo, D.; Castelletti, A.; Rizzoli, A. E.; Soncini-Sessa, R.; Weber, E. (January 2005). «A selective improvement technique for fastening Neuro-Dynamic Programming in Water Resources Network Management». In Pavel Zítek (ed.). Proceedings of the 16th IFAC World Congress – IFAC-PapersOnLine. 16th IFAC World Congress. Vol. 16. Prague, Czech Republic: IFAC. pp. 7–12. doi:10.3182/20050703-6-CZ-1902.02172. hdl:11311/255236. ISBN 978-3-902661-75-3. Archived from the original on 26 April 2012. Retrieved 30 December 2011.
- ^ Ferreira, C. (2006). «Designing Neural Networks Using Gene Expression Programming». In A. Abraham; B. de Baets; M. Köppen; B. Nickolay (eds.). Applied Soft Computing Technologies: The Challenge of Complexity (PDF). Springer-Verlag. pp. 517–536. Archived (PDF) from the original on 19 December 2013. Retrieved 8 October 2012.
- ^ Da, Y.; Xiurun, G. (July 2005). «An improved PSO-based ANN with simulated annealing technique». In T. Villmann (ed.). New Aspects in Neurocomputing: 11th European Symposium on Artificial Neural Networks. Vol. 63. Elsevier. pp. 527–533. doi:10.1016/j.neucom.2004.07.002. Archived from the original on 25 April 2012. Retrieved 30 December 2011.
- ^ Wu, J.; Chen, E. (May 2009). «A Novel Nonparametric Regression Ensemble for Rainfall Forecasting Using Particle Swarm Optimization Technique Coupled with Artificial Neural Network». In Wang, H.; Shen, Y.; Huang, T.; Zeng, Z. (eds.). 6th International Symposium on Neural Networks, ISNN 2009. Lecture Notes in Computer Science. Vol. 5553. Springer. pp. 49–58. doi:10.1007/978-3-642-01513-7_6. ISBN 978-3-642-01215-0. Archived from the original on 31 December 2014. Retrieved 1 January 2012.
- ^ a b Ting Qin; Zonghai Chen; Haitao Zhang; Sifu Li; Wei Xiang; Ming Li (2004). «A learning algorithm of CMAC based on RLS» (PDF). Neural Processing Letters. 19 (1): 49–61. doi:10.1023/B:NEPL.0000016847.18175.60. S2CID 6233899. Archived (PDF) from the original on 14 April 2021. Retrieved 30 January 2019.
- ^ Ting Qin; Haitao Zhang; Zonghai Chen; Wei Xiang (2005). «Continuous CMAC-QRLS and its systolic array» (PDF). Neural Processing Letters. 22 (1): 1–16. doi:10.1007/s11063-004-2694-0. S2CID 16095286. Archived (PDF) from the original on 18 November 2018. Retrieved 30 January 2019.
- ^ LeCun Y, Boser B, Denker JS, Henderson D, Howard RE, Hubbard W, Jackel LD (1989). «Backpropagation Applied to Handwritten Zip Code Recognition». Neural Computation. 1 (4): 541–551. doi:10.1162/neco.1989.1.4.541. S2CID 41312633.
- ^ Yann LeCun (2016). Slides on Deep Learning Online Archived 23 April 2016 at the Wayback Machine
- ^ Hochreiter, Sepp; Schmidhuber, Jürgen (1 November 1997). «Long Short-Term Memory». Neural Computation. 9 (8): 1735–1780. doi:10.1162/neco.1997.9.8.1735. ISSN 0899-7667. PMID 9377276. S2CID 1915014.
- ^ Sak, Hasim; Senior, Andrew; Beaufays, Francoise (2014). «Long Short-Term Memory recurrent neural network architectures for large scale acoustic modeling» (PDF). Archived from the original (PDF) on 24 April 2018.
- ^ Li, Xiangang; Wu, Xihong (15 October 2014). «Constructing Long Short-Term Memory based Deep Recurrent Neural Networks for Large Vocabulary Speech Recognition». arXiv:1410.4281 [cs.CL].
- ^ Fan, Y.; Qian, Y.; Xie, F.; Soong, F. K. (2014). «TTS synthesis with bidirectional LSTM based Recurrent Neural Networks». Proceedings of the Annual Conference of the International Speech Communication Association, Interspeech: 1964–1968. Retrieved 13 June 2017.
- ^ Zen, Heiga; Sak, Hasim (2015). «Unidirectional Long Short-Term Memory Recurrent Neural Network with Recurrent Output Layer for Low-Latency Speech Synthesis» (PDF). Google.com. ICASSP. pp. 4470–4474. Archived (PDF) from the original on 9 May 2021. Retrieved 27 June 2017.
- ^ Fan, Bo; Wang, Lijuan; Soong, Frank K.; Xie, Lei (2015). «Photo-Real Talking Head with Deep Bidirectional LSTM» (PDF). Proceedings of ICASSP. Archived (PDF) from the original on 1 November 2017. Retrieved 27 June 2017.
- ^ Silver, David; Hubert, Thomas; Schrittwieser, Julian; Antonoglou, Ioannis; Lai, Matthew; Guez, Arthur; Lanctot, Marc; Sifre, Laurent; Kumaran, Dharshan; Graepel, Thore; Lillicrap, Timothy; Simonyan, Karen; Hassabis, Demis (5 December 2017). «Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm». arXiv:1712.01815 [cs.AI].
- ^ Goodfellow, Ian; Pouget-Abadie, Jean; Mirza, Mehdi; Xu, Bing; Warde-Farley, David; Ozair, Sherjil; Courville, Aaron; Bengio, Yoshua (2014). Generative Adversarial Networks (PDF). Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014). pp. 2672–2680. Archived (PDF) from the original on 22 November 2019. Retrieved 20 August 2019.
- ^ Zoph, Barret; Le, Quoc V. (4 November 2016). «Neural Architecture Search with Reinforcement Learning». arXiv:1611.01578 [cs.LG].
- ^ Haifeng Jin; Qingquan Song; Xia Hu (2019). «Auto-keras: An efficient neural architecture search system». Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM. arXiv:1806.10282. Archived from the original on 21 August 2019. Retrieved 21 August 2019 – via autokeras.com.
- ^ Claesen, Marc; De Moor, Bart (2015). «Hyperparameter Search in Machine Learning». arXiv:1502.02127 [cs.LG]. Bibcode:2015arXiv150202127C
- ^ Turek, Fred D. (March 2007). «Introduction to Neural Net Machine Vision». Vision Systems Design. 12 (3). Archived from the original on 16 May 2013. Retrieved 5 March 2013.
- ^ Zissis, Dimitrios (October 2015). «A cloud based architecture capable of perceiving and predicting multiple vessel behaviour». Applied Soft Computing. 35: 652–661. doi:10.1016/j.asoc.2015.07.002. Archived from the original on 26 July 2020. Retrieved 18 July 2019.
- ^ Roman M. Balabin; Ekaterina I. Lomakina (2009). «Neural network approach to quantum-chemistry data: Accurate prediction of density functional theory energies». J. Chem. Phys. 131 (7): 074104. Bibcode:2009JChPh.131g4104B. doi:10.1063/1.3206326. PMID 19708729.
- ^ Silver, David; et al. (2016). «Mastering the game of Go with deep neural networks and tree search» (PDF). Nature. 529 (7587): 484–489. Bibcode:2016Natur.529..484S. doi:10.1038/nature16961. PMID 26819042. S2CID 515925. Archived (PDF) from the original on 23 November 2018. Retrieved 31 January 2019.
- ^ Sengupta, Nandini; Sahidullah, Md; Saha, Goutam (August 2016). «Lung sound classification using cepstral-based statistical features». Computers in Biology and Medicine. 75 (1): 118–129. doi:10.1016/j.compbiomed.2016.05.013. PMID 27286184.
- ^ Choy, Christopher B., et al. «3d-r2n2: A unified approach for single and multi-view 3d object reconstruction Archived 26 July 2020 at the Wayback Machine.» European conference on computer vision. Springer, Cham, 2016.
- ^ Gessler, Josef (August 2021). «Sensor for food analysis applying impedance spectroscopy and artificial neural networks». RiuNet UPV (1): 8–12. Archived from the original on 21 October 2021. Retrieved 21 October 2021.
- ^ Maitra, D. S.; Bhattacharya, U.; Parui, S. K. (August 2015). «CNN based common approach to handwritten character recognition of multiple scripts». 2015 13th International Conference on Document Analysis and Recognition (ICDAR): 1021–1025. doi:10.1109/ICDAR.2015.7333916. ISBN 978-1-4799-1805-8. S2CID 25739012.
- ^ French, Jordan (2016). «The time traveller’s CAPM». Investment Analysts Journal. 46 (2): 81–96. doi:10.1080/10293523.2016.1255469. S2CID 157962452.
- ^ Schechner, Sam (15 June 2017). «Facebook Boosts A.I. to Block Terrorist Propaganda». The Wall Street Journal. ISSN 0099-9660. Retrieved 16 June 2017.
- ^ Ganesan, N (2010). «Application of Neural Networks in Diagnosing Cancer Disease Using Demographic Data». International Journal of Computer Applications. 1 (26): 81–97. Bibcode:2010IJCA….1z..81G. doi:10.5120/476-783.
- ^ Bottaci, Leonardo (1997). «Artificial Neural Networks Applied to Outcome Prediction for Colorectal Cancer Patients in Separate Institutions» (PDF). Lancet. The Lancet. 350 (9076): 469–72. doi:10.1016/S0140-6736(96)11196-X. PMID 9274582. S2CID 18182063. Archived from the original (PDF) on 23 November 2018. Retrieved 2 May 2012.
- ^ Alizadeh, Elaheh; Lyons, Samanthe M; Castle, Jordan M; Prasad, Ashok (2016). «Measuring systematic changes in invasive cancer cell shape using Zernike moments». Integrative Biology. 8 (11): 1183–1193. doi:10.1039/C6IB00100A. PMID 27735002.
- ^ Lyons, Samanthe (2016). «Changes in cell shape are correlated with metastatic potential in murine». Biology Open. 5 (3): 289–299. doi:10.1242/bio.013409. PMC 4810736. PMID 26873952.
- ^ Nabian, Mohammad Amin; Meidani, Hadi (28 August 2017). «Deep Learning for Accelerated Reliability Analysis of Infrastructure Networks». Computer-Aided Civil and Infrastructure Engineering. 33 (6): 443–458. arXiv:1708.08551. Bibcode:2017arXiv170808551N. doi:10.1111/mice.12359. S2CID 36661983.
- ^ Nabian, Mohammad Amin; Meidani, Hadi (2018). «Accelerating Stochastic Assessment of Post-Earthquake Transportation Network Connectivity via Machine-Learning-Based Surrogates». Transportation Research Board 97th Annual Meeting. Archived from the original on 9 March 2018. Retrieved 14 March 2018.
- ^ Díaz, E.; Brotons, V.; Tomás, R. (September 2018). «Use of artificial neural networks to predict 3-D elastic settlement of foundations on soils with inclined bedrock». Soils and Foundations. 58 (6): 1414–1422. doi:10.1016/j.sandf.2018.08.001. hdl:10045/81208. ISSN 0038-0806.
- ^ Govindaraju, Rao S. (1 April 2000). «Artificial Neural Networks in Hydrology. I: Preliminary Concepts». Journal of Hydrologic Engineering. 5 (2): 115–123. doi:10.1061/(ASCE)1084-0699(2000)5:2(115).
- ^ Govindaraju, Rao S. (1 April 2000). «Artificial Neural Networks in Hydrology. II: Hydrologic Applications». Journal of Hydrologic Engineering. 5 (2): 124–137. doi:10.1061/(ASCE)1084-0699(2000)5:2(124).
- ^ Peres, D. J.; Iuppa, C.; Cavallaro, L.; Cancelliere, A.; Foti, E. (1 October 2015). «Significant wave height record extension by neural networks and reanalysis wind data». Ocean Modelling. 94: 128–140. Bibcode:2015OcMod..94..128P. doi:10.1016/j.ocemod.2015.08.002.
- ^ Dwarakish, G. S.; Rakshith, Shetty; Natesan, Usha (2013). «Review on Applications of Neural Network in Coastal Engineering». Artificial Intelligent Systems and Machine Learning. 5 (7): 324–331. Archived from the original on 15 August 2017. Retrieved 5 July 2017.
- ^ Ermini, Leonardo; Catani, Filippo; Casagli, Nicola (1 March 2005). «Artificial Neural Networks applied to landslide susceptibility assessment». Geomorphology. Geomorphological hazard and human impact in mountain environments. 66 (1): 327–343. Bibcode:2005Geomo..66..327E. doi:10.1016/j.geomorph.2004.09.025.
- ^ Nix, R.; Zhang, J. (May 2017). «Classification of Android apps and malware using deep neural networks». 2017 International Joint Conference on Neural Networks (IJCNN): 1871–1878. doi:10.1109/IJCNN.2017.7966078. ISBN 978-1-5090-6182-2. S2CID 8838479.
- ^ «Detecting Malicious URLs». The systems and networking group at UCSD. Archived from the original on 14 July 2019. Retrieved 15 February 2019.
- ^ Homayoun, Sajad; Ahmadzadeh, Marzieh; Hashemi, Sattar; Dehghantanha, Ali; Khayami, Raouf (2018), Dehghantanha, Ali; Conti, Mauro; Dargahi, Tooska (eds.), «BoTShark: A Deep Learning Approach for Botnet Traffic Detection», Cyber Threat Intelligence, Advances in Information Security, Springer International Publishing, pp. 137–153, doi:10.1007/978-3-319-73951-9_7, ISBN 978-3-319-73951-9
- ^ Ghosh and Reilly (January 1994). «Credit card fraud detection with a neural-network». 1994 Proceedings of the Twenty-Seventh Hawaii International Conference on System Sciences. 3: 621–630. doi:10.1109/HICSS.1994.323314. ISBN 978-0-8186-5090-1. S2CID 13260377.
- ^ Ananthaswamy, Anil (19 April 2021). «Latest Neural Nets Solve World’s Hardest Equations Faster Than Ever Before». Quanta Magazine. Retrieved 12 May 2021.
- ^ «AI has cracked a key mathematical puzzle for understanding our world». MIT Technology Review. Retrieved 19 November 2020.
- ^ «Caltech Open-Sources AI for Solving Partial Differential Equations». InfoQ. Archived from the original on 25 January 2021. Retrieved 20 January 2021.
- ^ Nagy, Alexandra (28 June 2019). «Variational Quantum Monte Carlo Method with a Neural-Network Ansatz for Open Quantum Systems». Physical Review Letters. 122 (25): 250501. arXiv:1902.09483. Bibcode:2019PhRvL.122y0501N. doi:10.1103/PhysRevLett.122.250501. PMID 31347886. S2CID 119074378.
- ^ Yoshioka, Nobuyuki; Hamazaki, Ryusuke (28 June 2019). «Constructing neural stationary states for open quantum many-body systems». Physical Review B. 99 (21): 214306. arXiv:1902.07006. Bibcode:2019PhRvB..99u4306Y. doi:10.1103/PhysRevB.99.214306. S2CID 119470636.
- ^ Hartmann, Michael J.; Carleo, Giuseppe (28 June 2019). «Neural-Network Approach to Dissipative Quantum Many-Body Dynamics». Physical Review Letters. 122 (25): 250502. arXiv:1902.05131. Bibcode:2019PhRvL.122y0502H. doi:10.1103/PhysRevLett.122.250502. PMID 31347862. S2CID 119357494.
- ^ Vicentini, Filippo; Biella, Alberto; Regnault, Nicolas; Ciuti, Cristiano (28 June 2019). «Variational Neural-Network Ansatz for Steady States in Open Quantum Systems». Physical Review Letters. 122 (25): 250503. arXiv:1902.10104. Bibcode:2019PhRvL.122y0503V. doi:10.1103/PhysRevLett.122.250503. PMID 31347877. S2CID 119504484.
- ^ Forrest MD (April 2015). «Simulation of alcohol action upon a detailed Purkinje neuron model and a simpler surrogate model that runs >400 times faster». BMC Neuroscience. 16 (27): 27. doi:10.1186/s12868-015-0162-6. PMC 4417229. PMID 25928094.
- ^ Siegelmann, H.T.; Sontag, E.D. (1991). «Turing computability with neural nets» (PDF). Appl. Math. Lett. 4 (6): 77–80. doi:10.1016/0893-9659(91)90080-F.
- ^ Balcázar, José (July 1997). «Computational Power of Neural Networks: A Kolmogorov Complexity Characterization». IEEE Transactions on Information Theory. 43 (4): 1175–1183. CiteSeerX 10.1.1.411.7782. doi:10.1109/18.605580.
- ^ a b MacKay, David, J.C. (2003). Information Theory, Inference, and Learning Algorithms (PDF). Cambridge University Press. ISBN 978-0-521-64298-9. Archived (PDF) from the original on 19 October 2016. Retrieved 11 June 2016.
- ^ Cover, Thomas (1965). «Geometrical and Statistical Properties of Systems of Linear Inequalities with Applications in Pattern Recognition» (PDF). IEEE Transactions on Electronic Computers. IEEE. EC-14 (3): 326–334. doi:10.1109/PGEC.1965.264137. Archived (PDF) from the original on 5 March 2016. Retrieved 10 March 2020.
- ^ Gerald, Friedland (2019). «Reproducibility and Experimental Design for Machine Learning on Audio and Multimedia Data». MM ’19: Proceedings of the 27th ACM International Conference on Multimedia. ACM: 2709–2710. doi:10.1145/3343031.3350545. ISBN 978-1-4503-6889-6. S2CID 204837170.
- ^ «Stop tinkering, start measuring! Predictable experimental design of Neural Network experiments». The Tensorflow Meter. Archived from the original on 18 April 2022. Retrieved 10 March 2020.
- ^ Lee, Jaehoon; Xiao, Lechao; Schoenholz, Samuel S.; Bahri, Yasaman; Novak, Roman; Sohl-Dickstein, Jascha; Pennington, Jeffrey (2020). «Wide neural networks of any depth evolve as linear models under gradient descent». Journal of Statistical Mechanics: Theory and Experiment. 2020 (12): 124002. arXiv:1902.06720. Bibcode:2020JSMTE2020l4002L. doi:10.1088/1742-5468/abc62b. S2CID 62841516.
- ^ Arthur Jacot; Franck Gabriel; Clement Hongler (2018). Neural Tangent Kernel: Convergence and Generalization in Neural Networks (PDF). 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, Canada. Archived (PDF) from the original on 22 June 2022. Retrieved 4 June 2022.
- ^ Xu ZJ, Zhang Y, Xiao Y (2019). «Training Behavior of Deep Neural Network in Frequency Domain». In Gedeon T, Wong K, Lee M (eds.). Neural Information Processing. ICONIP 2019. Lecture Notes in Computer Science. Vol. 11953. Springer, Cham. pp. 264–274. arXiv:1807.01251. doi:10.1007/978-3-030-36708-4_22. ISBN 978-3-030-36707-7. S2CID 49562099. Archived from the original on 9 November 2020. Retrieved 7 June 2022.
- ^ Nasim Rahaman; Aristide Baratin; Devansh Arpit; Felix Draxler; Min Lin; Fred Hamprecht; Yoshua Bengio; Aaron Courville (2019). «On the Spectral Bias of Neural Networks» (PDF). Proceedings of the 36th International Conference on Machine Learning. 97: 5301–5310. arXiv:1806.08734. Archived (PDF) from the original on 22 October 2022. Retrieved 4 June 2022.
- ^ Zhi-Qin John Xu; Yaoyu Zhang; Tao Luo; Yanyang Xiao; Zheng Ma (2020). «Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks». Communications in Computational Physics. 28 (5): 1746–1767. arXiv:1901.06523. Bibcode:2020CCoPh..28.1746X. doi:10.4208/cicp.OA-2020-0085. S2CID 58981616.
- ^ Tao Luo; Zheng Ma; Zhi-Qin John Xu; Yaoyu Zhang (2019). «Theory of the Frequency Principle for General Deep Neural Networks». arXiv:1906.09235 [cs.LG].
- ^ Xu, Zhiqin John; Zhou, Hanxu (18 May 2021). «Deep Frequency Principle Towards Understanding Why Deeper Learning Is Faster». Proceedings of the AAAI Conference on Artificial Intelligence. 35 (12): 10541–10550. arXiv:2007.14313. doi:10.1609/aaai.v35i12.17261. ISSN 2374-3468. S2CID 220831156. Archived from the original on 5 October 2021. Retrieved 5 October 2021.
- ^ Dewdney, A. K. (1 April 1997). Yes, we have no neutrons: an eye-opening tour through the twists and turns of bad science. Wiley. p. 82. ISBN 978-0-471-10806-1.
- ^ NASA – Dryden Flight Research Center – News Room: News Releases: NASA NEURAL NETWORK PROJECT PASSES MILESTONE Archived 2 April 2010 at the Wayback Machine. Nasa.gov. Retrieved on 20 November 2013.
- ^ «Roger Bridgman’s defence of neural networks». Archived from the original on 19 March 2012. Retrieved 12 July 2010.
- ^ D. J. Felleman and D. C. Van Essen, «Distributed hierarchical processing in the primate cerebral cortex,» Cerebral Cortex, 1, pp. 1–47, 1991.
- ^ J. Weng, «Natural and Artificial Intelligence: Introduction to Computational Brain-Mind,» BMI Press, ISBN 978-0-9858757-2-5, 2012.
- ^ a b Edwards, Chris (25 June 2015). «Growing pains for deep learning». Communications of the ACM. 58 (7): 14–16. doi:10.1145/2771283. S2CID 11026540.
- ^ Cade Metz (18 May 2016). «Google Built Its Very Own Chips to Power Its AI Bots». Wired. Archived from the original on 13 January 2018. Retrieved 5 March 2017.
- ^ «Scaling Learning Algorithms towards AI» (PDF). Archived (PDF) from the original on 12 August 2022. Retrieved 6 July 2022.
- ^ Tahmasebi; Hezarkhani (2012). «A hybrid neural networks-fuzzy logic-genetic algorithm for grade estimation». Computers & Geosciences. 42: 18–27. Bibcode:2012CG…..42…18T. doi:10.1016/j.cageo.2012.02.004. PMC 4268588. PMID 25540468.
Bibliography[edit]
- Bhadeshia H. K. D. H. (1999). «Neural Networks in Materials Science» (PDF). ISIJ International. 39 (10): 966–979. doi:10.2355/isijinternational.39.966.
- Bishop, Christopher M. (1995). Neural networks for pattern recognition. Clarendon Press. ISBN 978-0-19-853849-3. OCLC 33101074.
- Borgelt, Christian (2003). Neuro-Fuzzy-Systeme : von den Grundlagen künstlicher Neuronaler Netze zur Kopplung mit Fuzzy-Systemen. Vieweg. ISBN 978-3-528-25265-6. OCLC 76538146.
- Cybenko, G.V. (2006). «Approximation by Superpositions of a Sigmoidal function». In van Schuppen, Jan H. (ed.). Mathematics of Control, Signals, and Systems. Springer International. pp. 303–314. PDF
- Dewdney, A. K. (1997). Yes, we have no neutrons : an eye-opening tour through the twists and turns of bad science. New York: Wiley. ISBN 978-0-471-10806-1. OCLC 35558945.
- Duda, Richard O.; Hart, Peter Elliot; Stork, David G. (2001). Pattern classification (2 ed.). Wiley. ISBN 978-0-471-05669-0. OCLC 41347061.
- Egmont-Petersen, M.; de Ridder, D.; Handels, H. (2002). «Image processing with neural networks – a review». Pattern Recognition. 35 (10): 2279–2301. CiteSeerX 10.1.1.21.5444. doi:10.1016/S0031-3203(01)00178-9.
- Fahlman, S.; Lebiere, C (1991). «The Cascade-Correlation Learning Architecture» (PDF). Archived from the original (PDF) on 3 May 2013. Retrieved 28 August 2006.
- created for National Science Foundation, Contract Number EET-8716324, and Defense Advanced Research Projects Agency (DOD), ARPA Order No. 4976 under Contract F33615-87-C-1499.
- Gurney, Kevin (1997). An introduction to neural networks. UCL Press. ISBN 978-1-85728-673-1. OCLC 37875698.
- Haykin, Simon S. (1999). Neural networks : a comprehensive foundation. Prentice Hall. ISBN 978-0-13-273350-2. OCLC 38908586.
- Hertz, J.; Palmer, Richard G.; Krogh, Anders S. (1991). Introduction to the theory of neural computation. Addison-Wesley. ISBN 978-0-201-51560-2. OCLC 21522159.
- Information theory, inference, and learning algorithms. Cambridge University Press. 25 September 2003. Bibcode:2003itil.book…..M. ISBN 978-0-521-64298-9. OCLC 52377690.
- Kruse, Rudolf; Borgelt, Christian; Klawonn, F.; Moewes, Christian; Steinbrecher, Matthias; Held, Pascal (2013). Computational intelligence : a methodological introduction. Springer. ISBN 978-1-4471-5012-1. OCLC 837524179.
- Lawrence, Jeanette (1994). Introduction to neural networks : design, theory and applications. California Scientific Software. ISBN 978-1-883157-00-5. OCLC 32179420.
- MacKay, David, J.C. (2003). Information Theory, Inference, and Learning Algorithms (PDF). Cambridge University Press. ISBN 978-0-521-64298-9.
- Masters, Timothy (1994). Signal and image processing with neural networks : a C++ sourcebook. J. Wiley. ISBN 978-0-471-04963-0. OCLC 29877717.
- Maurer, Harald (2021). Cognitive science : integrative synchronization mechanisms in cognitive neuroarchitectures of the modern connectionism. CRC Press. doi:10.1201/9781351043526. ISBN 978-1-351-04352-6. S2CID 242963768.
- Ripley, Brian D. (2007). Pattern Recognition and Neural Networks. Cambridge University Press. ISBN 978-0-521-71770-0.
- Siegelmann, H.T.; Sontag, Eduardo D. (1994). «Analog computation via neural networks». Theoretical Computer Science. 131 (2): 331–360. doi:10.1016/0304-3975(94)90178-3. S2CID 2456483.
- Smith, Murray (1993). Neural networks for statistical modeling. Van Nostrand Reinhold. ISBN 978-0-442-01310-3. OCLC 27145760.
- Wasserman, Philip D. (1993). Advanced methods in neural computing. Van Nostrand Reinhold. ISBN 978-0-442-00461-3. OCLC 27429729.
- Wilson, Halsey (2018). Artificial intelligence. Grey House Publishing. ISBN 978-1-68217-867-6.