Причины отказов программного обеспечения
Основными причинами,
непосредственно вызывающими нарушения
нормального функционирования программы,
являются:
-
ошибки, скрытые
в самой программе; -
искажения входной
информации, подлежащей обработке; -
неверные действия
пользователя; -
неисправности
аппаратуры установки, на которой
реализуется вычислительный процесс.
Скрытые ошибки
программы.
Специфика создания сложных программных
средств состоит в том, что в процессе
их отладки практически невозможно
обнаружить и ликвидировать все ошибки.
В результате в программах остается
некоторое количество скрытых ошибок.
Они могут вызвать неверное функционирование
программ при определенных сочетаниях
входных данных. Наличие скрытых ошибок
программного обеспечения является
главным фактором нарушения нормальных
условий его функционирования.
Можно выделить
следующие основные классы ошибок в
программах.
Ошибки вычислений.
Ошибки данного класса содержатся в
закодированных математических выражениях
или в получаемых с их помощью результатах.
Примерами ошибок, относящихся к данному
классу, являются неверное преобразование
типов переменных, неверный знак операции,
ошибка в выражении индекса, переполнение
или потеря значимости при вычислениях.
Логические ошибки
являются причиной искажения алгоритма
решения задачи. Такого рода ошибки
возникают в связи с неверной передачей
управления, неверным заданием диапазона
изменения параметра цикла, неверным
условием и т. д.
Ошибки ввода-вывода,
связанные с такими действиями, как
управление вводом-выводом, формирование
выходных записей, определение размеров
записей и т. д. Примерами ошибок
ввода-вывода являются неправильная
форма ввода (вывода), отсутствие признака
конца файла и т. д.
Ошибки
манипулирования данными.
Примерами таких ошибок являются неверно
определенное число элементов данных;
неверные начальные значения, присвоенные
данным; неверно указанные длина операнда,
имя переменной и т. д.
Ошибки совместимости
связаны с отсутствием совместимости с
операционной системой или другими
прикладными программами, используемыми
в данной программе.
Ошибки сопряжений
вызывают неверное взаимодействие
программы с другими программами
(подпрограммами), с системными программами,
устройствами ЭВМ, входными данными и
т. д. В качестве примеров ошибок сопряжения
могут быть названы несовместимость
аргументов и параметров подпрограммы,
отсутствие в системе необходимой
подпрограммы, нарушения синхронизации
при асинхронном выполнении программ и
т. д.
Искажение
информации, подлежащей обработке,
вызывает нарушение функционирования
программного обеспечения, когда входные
данные не попадают в область допустимых
значений переменных программы. В этом
случае между исходной информацией и
характеристиками программы возникает
несоответствие.
Причинами искажения
вводимой информации могут быть, например,
следующие:
-
искажение данных
на первичных носителях информации; -
сбои и отказы в
аппаратуре ввода данных с первичных
носителей информации; -
шумы и сбои в
каналах связи при передаче сообщений
по линиям связи; -
сбои и отказы в
аппаратуре передачи или приема
информации; -
потери или искажения
сообщений в буферных накопителях
вычислительной системы; -
ошибки в документации,
используемой для подготовки вводимых
данных; -
ошибки пользователей
при подготовке исходной информации.
Неверные действия
пользователя,
приводящие к отказу в процессе
функционирования ПО, связаны прежде
всего с неправильной интерпретацией
сообщений, с неправильными действиями
пользователя в процессе диалога с ЭВМ
и т. д.
Отказы ПО,
обусловленные ошибками пользователя,
называются ошибками
использования.
Часто эти ошибки являются следствием
некачественной программной документации
(неверное описание возможностей
программы, режимов работы, форматов
входной и выходной информации,
диагностических сообщений и т. д.).
Неисправность
аппаратуры.
Неисправности, возникающие при работе
аппаратуры, используемой для реализации
вычислительного процесса, оказывают
определенное влияние на характеристику
надежности ПО. Появление отказа или
сбоя в работе аппаратуры приводит к
нарушению нормального хода вычислительного
процесса и во многих случаях—к искажению
данных и текстов программ в основной и
внешней памяти.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
A software bug is an error, flaw or fault in the design, development, or operation of computer software that causes it to produce an incorrect or unexpected result, or to behave in unintended ways. The process of finding and correcting bugs is termed «debugging» and often uses formal techniques or tools to pinpoint bugs. Since the 1950s, some computer systems have been designed to deter, detect or auto-correct various computer bugs during operations.
Bugs in software can arise from mistakes and errors made in interpreting and extracting users’ requirements, planning a program’s design, writing its source code, and from interaction with humans, hardware and programs, such as operating systems or libraries. A program with many, or serious, bugs is often described as buggy. Bugs can trigger errors that may have ripple effects. The effects of bugs may be subtle, such as unintended text formatting, through to more obvious effects such as causing a program to crash, freezing the computer, or causing damage to hardware. Other bugs qualify as security bugs and might, for example, enable a malicious user to bypass access controls in order to obtain unauthorized privileges.[1]
Some software bugs have been linked to disasters. Bugs in code that controlled the Therac-25 radiation therapy machine were directly responsible for patient deaths in the 1980s. In 1996, the European Space Agency’s US$1 billion prototype Ariane 5 rocket was destroyed less than a minute after launch due to a bug in the on-board guidance computer program.[2] In 1994, an RAF Chinook helicopter crashed, killing 29; this was initially blamed on pilot error, but was later thought to have been caused by a software bug in the engine-control computer.[3] Buggy software caused the early 21st century British Post Office scandal, the most widespread miscarriage of justice in British legal history.[4]
In 2002, a study commissioned by the US Department of Commerce’s National Institute of Standards and Technology concluded that «software bugs, or errors, are so prevalent and so detrimental that they cost the US economy an estimated $59 billion annually, or about 0.6 percent of the gross domestic product».[5]
History[edit]
The Middle English word bugge is the basis for the terms «bugbear» and «bugaboo» as terms used for a monster.[6]
The term «bug» to describe defects has been a part of engineering jargon since the 1870s[7] and predates electronics and computers; it may have originally been used in hardware engineering to describe mechanical malfunctions. For instance, Thomas Edison wrote in a letter to an associate in 1878:[8]
… difficulties arise—this thing gives out and [it is] then that «Bugs»—as such little faults and difficulties are called—show themselves[9]
Baffle Ball, the first mechanical pinball game, was advertised as being «free of bugs» in 1931.[10] Problems with military gear during World War II were referred to as bugs (or glitches).[11] In a book published in 1942, Louise Dickinson Rich, speaking of a powered ice cutting machine, said, «Ice sawing was suspended until the creator could be brought in to take the bugs out of his darling.»[12]
Isaac Asimov used the term «bug» to relate to issues with a robot in his short story «Catch That Rabbit», published in 1944.

A page from the Harvard Mark II electromechanical computer’s log, featuring a dead moth that was removed from the device.
The term «bug» was used in an account by computer pioneer Grace Hopper, who publicized the cause of a malfunction in an early electromechanical computer.[13] A typical version of the story is:
In 1946, when Hopper was released from active duty, she joined the Harvard Faculty at the Computation Laboratory where she continued her work on the Mark II and Mark III. Operators traced an error in the Mark II to a moth trapped in a relay, coining the term bug. This bug was carefully removed and taped to the log book. Stemming from the first bug, today we call errors or glitches in a program a bug.[14]
Hopper was not present when the bug was found, but it became one of her favorite stories.[15] The date in the log book was September 9, 1947.[16][17][18] The operators who found it, including William «Bill» Burke, later of the Naval Weapons Laboratory, Dahlgren, Virginia,[19] were familiar with the engineering term and amusedly kept the insect with the notation «First actual case of bug being found.» This log book, complete with attached moth, is part of the collection of the Smithsonian National Museum of American History.[17]
The related term «debug» also appears to predate its usage in computing: the Oxford English Dictionary‘s etymology of the word contains an attestation from 1945, in the context of aircraft engines.[20]
The concept that software might contain errors dates back to Ada Lovelace’s 1843 notes on the analytical engine, in which she speaks of the possibility of program «cards» for Charles Babbage’s analytical engine being erroneous:
… an analysing process must equally have been performed in order to furnish the Analytical Engine with the necessary operative data; and that herein may also lie a possible source of error. Granted that the actual mechanism is unerring in its processes, the cards may give it wrong orders.
«Bugs in the System» report[edit]
The Open Technology Institute, run by the group, New America,[21] released a report «Bugs in the System» in August 2016 stating that U.S. policymakers should make reforms to help researchers identify and address software bugs. The report «highlights the need for reform in the field of software vulnerability discovery and disclosure.»[22] One of the report’s authors said that Congress has not done enough to address cyber software vulnerability, even though Congress has passed a number of bills to combat the larger issue of cyber security.[22]
Government researchers, companies, and cyber security experts are the people who typically discover software flaws. The report calls for reforming computer crime and copyright laws.[22]
The Computer Fraud and Abuse Act, the Digital Millennium Copyright Act and the Electronic Communications Privacy Act criminalize and create civil penalties for actions that security researchers routinely engage in while conducting legitimate security research, the report said.[22]
Terminology[edit]
While the use of the term «bug» to describe software errors is common, many have suggested that it should be abandoned. One argument is that the word «bug» is divorced from a sense that a human being caused the problem, and instead implies that the defect arose on its own, leading to a push to abandon the term «bug» in favor of terms such as «defect», with limited success.[23] Since the 1970s Gary Kildall somewhat humorously suggested to use the term «blunder».[24][25]
In software engineering, mistake metamorphism (from Greek meta = «change», morph = «form») refers to the evolution of a defect in the final stage of software deployment. Transformation of a «mistake» committed by an analyst in the early stages of the software development lifecycle, which leads to a «defect» in the final stage of the cycle has been called ‘mistake metamorphism’.[26]
Different stages of a «mistake» in the entire cycle may be described as «mistakes», «anomalies», «faults», «failures», «errors», «exceptions», «crashes», «glitches», «bugs», «defects», «incidents», or «side effects».[26]
Prevention[edit]

The software industry has put much effort into reducing bug counts.[27][28] These include:
Typographical errors[edit]
Bugs usually appear when the programmer makes a logic error. Various innovations in programming style and defensive programming are designed to make these bugs less likely, or easier to spot. Some typos, especially of symbols or logical/mathematical operators, allow the program to operate incorrectly, while others such as a missing symbol or misspelled name may prevent the program from operating. Compiled languages can reveal some typos when the source code is compiled.
Development methodologies[edit]
Several schemes assist managing programmer activity so that fewer bugs are produced. Software engineering (which addresses software design issues as well) applies many techniques to prevent defects. For example, formal program specifications state the exact behavior of programs so that design bugs may be eliminated. Unfortunately, formal specifications are impractical for anything but the shortest programs, because of problems of combinatorial explosion and indeterminacy.
Unit testing involves writing a test for every function (unit) that a program is to perform.
In test-driven development unit tests are written before the code and the code is not considered complete until all tests complete successfully.
Agile software development involves frequent software releases with relatively small changes. Defects are revealed by user feedback.
Open source development allows anyone to examine source code. A school of thought popularized by Eric S. Raymond as Linus’s law says that popular open-source software has more chance of having few or no bugs than other software, because «given enough eyeballs, all bugs are shallow».[29] This assertion has been disputed, however: computer security specialist Elias Levy wrote that «it is easy to hide vulnerabilities in complex, little understood and undocumented source code,» because, «even if people are reviewing the code, that doesn’t mean they’re qualified to do so.»[30] An example of an open-source software bug was the 2008 OpenSSL vulnerability in Debian.
Programming language support[edit]
Programming languages include features to help prevent bugs, such as static type systems, restricted namespaces and modular programming. For example, when a programmer writes (pseudocode) LET REAL_VALUE PI = "THREE AND A BIT", although this may be syntactically correct, the code fails a type check. Compiled languages catch this without having to run the program. Interpreted languages catch such errors at runtime. Some languages deliberately exclude features that easily lead to bugs, at the expense of slower performance: the general principle being that, it is almost always better to write simpler, slower code than inscrutable code that runs slightly faster, especially considering that maintenance cost is substantial. For example, the Java programming language does not support pointer arithmetic; implementations of some languages such as Pascal and scripting languages often have runtime bounds checking of arrays, at least in a debugging build.
Code analysis[edit]
Tools for code analysis help developers by inspecting the program text beyond the compiler’s capabilities to spot potential problems. Although in general the problem of finding all programming errors given a specification is not solvable (see halting problem), these tools exploit the fact that human programmers tend to make certain kinds of simple mistakes often when writing software.
Instrumentation[edit]
Tools to monitor the performance of the software as it is running, either specifically to find problems such as bottlenecks or to give assurance as to correct working, may be embedded in the code explicitly (perhaps as simple as a statement saying PRINT "I AM HERE"), or provided as tools. It is often a surprise to find where most of the time is taken by a piece of code, and this removal of assumptions might cause the code to be rewritten.
Testing[edit]
Software testers are people whose primary task is to find bugs, or write code to support testing. On some projects, more resources may be spent on testing than in developing the program.
Measurements during testing can provide an estimate of the number of likely bugs remaining; this becomes more reliable the longer a product is tested and developed.[citation needed]
Debugging[edit]
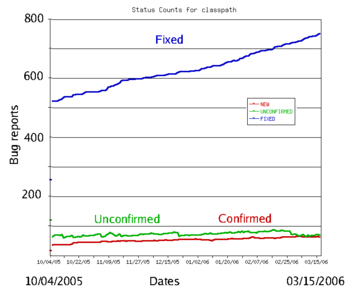
The typical bug history (GNU Classpath project data). A new bug submitted by the user is unconfirmed. Once it has been reproduced by a developer, it is a confirmed bug. The confirmed bugs are later fixed. Bugs belonging to other categories (unreproducible, will not be fixed, etc.) are usually in the minority
Finding and fixing bugs, or debugging, is a major part of computer programming. Maurice Wilkes, an early computing pioneer, described his realization in the late 1940s that much of the rest of his life would be spent finding mistakes in his own programs.[31]
Usually, the most difficult part of debugging is finding the bug. Once it is found, correcting it is usually relatively easy. Programs known as debuggers help programmers locate bugs by executing code line by line, watching variable values, and other features to observe program behavior. Without a debugger, code may be added so that messages or values may be written to a console or to a window or log file to trace program execution or show values.
However, even with the aid of a debugger, locating bugs is something of an art. It is not uncommon for a bug in one section of a program to cause failures in a completely different section,[citation needed] thus making it especially difficult to track (for example, an error in a graphics rendering routine causing a file I/O routine to fail), in an apparently unrelated part of the system.
Sometimes, a bug is not an isolated flaw, but represents an error of thinking or planning on the part of the programmer. Such logic errors require a section of the program to be overhauled or rewritten. As a part of code review, stepping through the code and imagining or transcribing the execution process may often find errors without ever reproducing the bug as such.
More typically, the first step in locating a bug is to reproduce it reliably. Once the bug is reproducible, the programmer may use a debugger or other tool while reproducing the error to find the point at which the program went astray.
Some bugs are revealed by inputs that may be difficult for the programmer to re-create. One cause of the Therac-25 radiation machine deaths was a bug (specifically, a race condition) that occurred only when the machine operator very rapidly entered a treatment plan; it took days of practice to become able to do this, so the bug did not manifest in testing or when the manufacturer attempted to duplicate it. Other bugs may stop occurring whenever the setup is augmented to help find the bug, such as running the program with a debugger; these are called heisenbugs (humorously named after the Heisenberg uncertainty principle).
Since the 1990s, particularly following the Ariane 5 Flight 501 disaster, interest in automated aids to debugging rose, such as static code analysis by abstract interpretation.[32]
Some classes of bugs have nothing to do with the code. Faulty documentation or hardware may lead to problems in system use, even though the code matches the documentation. In some cases, changes to the code eliminate the problem even though the code then no longer matches the documentation. Embedded systems frequently work around hardware bugs, since to make a new version of a ROM is much cheaper than remanufacturing the hardware, especially if they are commodity items.
Benchmark of bugs[edit]
To facilitate reproducible research on testing and debugging, researchers use curated benchmarks of bugs:
- the Siemens benchmark
- ManyBugs[33] is a benchmark of 185 C bugs in nine open-source programs.
- Defects4J[34] is a benchmark of 341 Java bugs from 5 open-source projects. It contains the corresponding patches, which cover a variety of patch type.
Bug management[edit]
Bug management includes the process of documenting, categorizing, assigning, reproducing, correcting and releasing the corrected code. Proposed changes to software – bugs as well as enhancement requests and even entire releases – are commonly tracked and managed using bug tracking systems or issue tracking systems.[35] The items added may be called defects, tickets, issues, or, following the agile development paradigm, stories and epics. Categories may be objective, subjective or a combination, such as version number, area of the software, severity and priority, as well as what type of issue it is, such as a feature request or a bug.
A bug triage reviews bugs and decides whether and when to fix them. The decision is based on the bug’s priority, and factors such as project schedules. The triage is not meant to investigate the cause of bugs, but rather the cost of fixing them. The triage happens regularly, and goes through bugs opened or reopened since the previous meeting. The attendees of the triage process typically are the project manager, development manager, test manager, build manager, and technical experts.[36][37]
Severity[edit]
Severity is the intensity of the impact the bug has on system operation.[38] This impact may be data loss, financial, loss of goodwill and wasted effort. Severity levels are not standardized. Impacts differ across industry. A crash in a video game has a totally different impact than a crash in a web browser, or real time monitoring system. For example, bug severity levels might be «crash or hang», «no workaround» (meaning there is no way the customer can accomplish a given task), «has workaround» (meaning the user can still accomplish the task), «visual defect» (for example, a missing image or displaced button or form element), or «documentation error». Some software publishers use more qualified severities such as «critical», «high», «low», «blocker» or «trivial».[39] The severity of a bug may be a separate category to its priority for fixing, and the two may be quantified and managed separately.
Priority[edit]
Priority controls where a bug falls on the list of planned changes. The priority is decided by each software producer. Priorities may be numerical, such as 1 through 5, or named, such as «critical», «high», «low», or «deferred». These rating scales may be similar or even identical to severity ratings, but are evaluated as a combination of the bug’s severity with its estimated effort to fix; a bug with low severity but easy to fix may get a higher priority than a bug with moderate severity that requires excessive effort to fix. Priority ratings may be aligned with product releases, such as «critical» priority indicating all the bugs that must be fixed before the next software release.
A bug severe enough to delay or halt the release of the product is called a «show stopper»[40] or «showstopper bug».[41] It is named so because it «stops the show» – causes unacceptable product failure.[41]
Software releases[edit]
It is common practice to release software with known, low-priority bugs. Bugs of sufficiently high priority may warrant a special release of part of the code containing only modules with those fixes. These are known as patches. Most releases include a mixture of behavior changes and multiple bug fixes. Releases that emphasize bug fixes are known as maintenance releases, to differentiate it from major releases that emphasize feature additions or changes.
Reasons that a software publisher opts not to patch or even fix a particular bug include:
- A deadline must be met and resources are insufficient to fix all bugs by the deadline.[42]
- The bug is already fixed in an upcoming release, and it is not of high priority.
- The changes required to fix the bug are too costly or affect too many other components, requiring a major testing activity.
- It may be suspected, or known, that some users are relying on the existing buggy behavior; a proposed fix may introduce a breaking change.
- The problem is in an area that will be obsolete with an upcoming release; fixing it is unnecessary.
- «It’s not a bug, it’s a feature».[43] A misunderstanding has arisen between expected and perceived behavior or undocumented feature.
Types[edit]
In software development projects, a mistake or error may be introduced at any stage. Bugs arise from oversight or misunderstanding by a software team during specification, design, coding, configuration, data entry or documentation. For example, a relatively simple program to alphabetize a list of words, the design might fail to consider what should happen when a word contains a hyphen. Or when converting an abstract design into code, the coder might inadvertently create an off-by-one error which can be a «<» where «<=» was intended, and fail to sort the last word in a list.
Another category of bug is called a race condition that may occur when programs have multiple components executing at the same time. If the components interact in a different order than the developer intended, they could interfere with each other and stop the program from completing its tasks. These bugs may be difficult to detect or anticipate, since they may not occur during every execution of a program.
Conceptual errors are a developer’s misunderstanding of what the software must do. The resulting software may perform according to the developer’s understanding, but not what is really needed. Other types:
Arithmetic[edit]
In operations on numerical values, problems can arise that result in unexpected output, slowing of a process, or crashing.[44] These can be from a lack of awareness of the qualities of the data storage such as a loss of precision due to rounding, numerically unstable algorithms, arithmetic overflow and underflow, or from lack of awareness of how calculations are handled by different software coding languages such as division by zero which in some languages may throw an exception, and in others may return a special value such as NaN or infinity.
Control flow[edit]
Control flow bugs are those found in processes with valid logic, but that lead to unintended results, such as infinite loops and infinite recursion, incorrect comparisons for conditional statements such as using the incorrect comparison operator, and off-by-one errors (counting one too many or one too few iterations when looping).
Interfacing[edit]
- Incorrect API usage.
- Incorrect protocol implementation.
- Incorrect hardware handling.
- Incorrect assumptions of a particular platform.
- Incompatible systems. A new API or communications protocol may seem to work when two systems use different versions, but errors may occur when a function or feature implemented in one version is changed or missing in another. In production systems which must run continually, shutting down the entire system for a major update may not be possible, such as in the telecommunication industry[45] or the internet.[46][47][48] In this case, smaller segments of a large system are upgraded individually, to minimize disruption to a large network. However, some sections could be overlooked and not upgraded, and cause compatibility errors which may be difficult to find and repair.
- Incorrect code annotations.
Concurrency[edit]
- Deadlock, where task A cannot continue until task B finishes, but at the same time, task B cannot continue until task A finishes.
- Race condition, where the computer does not perform tasks in the order the programmer intended.
- Concurrency errors in critical sections, mutual exclusions and other features of concurrent processing. Time-of-check-to-time-of-use (TOCTOU) is a form of unprotected critical section.
Resourcing[edit]
- Null pointer dereference.
- Using an uninitialized variable.
- Using an otherwise valid instruction on the wrong data type (see packed decimal/binary-coded decimal).
- Access violations.
- Resource leaks, where a finite system resource (such as memory or file handles) become exhausted by repeated allocation without release.
- Buffer overflow, in which a program tries to store data past the end of allocated storage. This may or may not lead to an access violation or storage violation. These are frequently security bugs.
- Excessive recursion which—though logically valid—causes stack overflow.
- Use-after-free error, where a pointer is used after the system has freed the memory it references.
- Double free error.
Syntax[edit]
- Use of the wrong token, such as performing assignment instead of equality test. For example, in some languages x=5 will set the value of x to 5 while x==5 will check whether x is currently 5 or some other number. Interpreted languages allow such code to fail. Compiled languages can catch such errors before testing begins.
Teamwork[edit]
- Unpropagated updates; e.g. programmer changes «myAdd» but forgets to change «mySubtract», which uses the same algorithm. These errors are mitigated by the Don’t Repeat Yourself philosophy.
- Comments out of date or incorrect: many programmers assume the comments accurately describe the code.
- Differences between documentation and product.
Implications[edit]
The amount and type of damage a software bug may cause naturally affects decision-making, processes and policy regarding software quality. In applications such as human spaceflight, aviation, nuclear power, health care, public transport or automotive safety, since software flaws have the potential to cause human injury or even death, such software will have far more scrutiny and quality control than, for example, an online shopping website. In applications such as banking, where software flaws have the potential to cause serious financial damage to a bank or its customers, quality control is also more important than, say, a photo editing application.
Other than the damage caused by bugs, some of their cost is due to the effort invested in fixing them. In 1978, Lientz et al. showed that the median of projects invest 17 percent of the development effort in bug fixing.[49] In 2020, research on GitHub repositories showed the median is 20%.[50]
Residual bugs in delivered product[edit]
In 1994, NASA’s Goddard Space Flight Center managed to reduce their average number of errors from 4.5 per 1000 lines of code (SLOC) down to 1 per 1000 SLOC.[51]
Another study in 1990 reported that exceptionally good software development processes can achieve deployment failure rates as low as 0.1 per 1000 SLOC.[52] This figure is iterated in literature such as Code Complete by Steve McConnell,[53] and the NASA study on Flight Software Complexity.[54] Some projects even attained zero defects: the firmware in the IBM Wheelwriter typewriter which consists of 63,000 SLOC, and the Space Shuttle software with 500,000 SLOC.[52]
Well-known bugs[edit]
A number of software bugs have become well-known, usually due to their severity: examples include various space and military aircraft crashes. Possibly the most famous bug is the Year 2000 problem or Y2K bug, which caused many programs written long before the transition from 19xx to 20xx dates to malfunction, for example treating a date such as «25 Dec 04» as being in 1904, displaying «19100» instead of «2000», and so on. A huge effort at the end of the 20th century resolved the most severe problems, and there were no major consequences.
The 2012 stock trading disruption involved one such incompatibility between the old API and a new API.
In popular culture[edit]
- In both the 1968 novel 2001: A Space Odyssey and the corresponding 1968 film 2001: A Space Odyssey, a spaceship’s onboard computer, HAL 9000, attempts to kill all its crew members. In the follow-up 1982 novel, 2010: Odyssey Two, and the accompanying 1984 film, 2010, it is revealed that this action was caused by the computer having been programmed with two conflicting objectives: to fully disclose all its information, and to keep the true purpose of the flight secret from the crew; this conflict caused HAL to become paranoid and eventually homicidal.
- In the English version of the Nena 1983 song 99 Luftballons (99 Red Balloons) as a result of «bugs in the software», a release of a group of 99 red balloons are mistaken for an enemy nuclear missile launch, requiring an equivalent launch response, resulting in catastrophe.
- In the 1999 American comedy Office Space, three employees attempt (unsuccessfully) to exploit their company’s preoccupation with the Y2K computer bug using a computer virus that sends rounded-off fractions of a penny to their bank account—a long-known technique described as salami slicing.
- The 2004 novel The Bug, by Ellen Ullman, is about a programmer’s attempt to find an elusive bug in a database application.[55]
- The 2008 Canadian film Control Alt Delete is about a computer programmer at the end of 1999 struggling to fix bugs at his company related to the year 2000 problem.
See also[edit]
- Anti-pattern
- Bug bounty program
- Glitch removal
- Hardware bug
- ISO/IEC 9126, which classifies a bug as either a defect or a nonconformity
- Orthogonal Defect Classification
- Racetrack problem
- RISKS Digest
- Software defect indicator
- Software regression
- Software rot
- Automatic bug fixing
References[edit]
- ^ Mittal, Varun; Aditya, Shivam (January 1, 2015). «Recent Developments in the Field of Bug Fixing». Procedia Computer Science. International Conference on Computer, Communication and Convergence (ICCC 2015). 48: 288–297. doi:10.1016/j.procs.2015.04.184. ISSN 1877-0509.
- ^ «Ariane 501 — Presentation of Inquiry Board report». www.esa.int. Retrieved January 29, 2022.
- ^ Prof. Simon Rogerson. «The Chinook Helicopter Disaster». Ccsr.cse.dmu.ac.uk. Archived from the original on July 17, 2012. Retrieved September 24, 2012.
- ^ «Post Office scandal ruined lives, inquiry hears». BBC News. February 14, 2022.
- ^ «Software bugs cost US economy dear». June 10, 2009. Archived from the original on June 10, 2009. Retrieved September 24, 2012.
{{cite web}}: CS1 maint: unfit URL (link) - ^ Computerworld staff (September 3, 2011). «Moth in the machine: Debugging the origins of ‘bug’«. Computerworld. Archived from the original on August 25, 2015.
- ^ «bug». Oxford English Dictionary (Online ed.). Oxford University Press. (Subscription or participating institution membership required.) 5a
- ^ «Did You Know? Edison Coined the Term «Bug»«. August 1, 2013. Retrieved July 19, 2019.
- ^ Edison to Puskas, 13 November 1878, Edison papers, Edison National Laboratory, U.S. National Park Service, West Orange, N.J., cited in Hughes, Thomas Parke (1989). American Genesis: A Century of Invention and Technological Enthusiasm, 1870-1970. Penguin Books. p. 75. ISBN 978-0-14-009741-2.
- ^ «Baffle Ball». Internet Pinball Database.
(See image of advertisement in reference entry)
- ^ «Modern Aircraft Carriers are Result of 20 Years of Smart Experimentation». Life. June 29, 1942. p. 25. Archived from the original on June 4, 2013. Retrieved November 17, 2011.
- ^ Dickinson Rich, Louise (1942), We Took to the Woods, JB Lippincott Co, p. 93, LCCN 42024308, OCLC 405243, archived from the original on March 16, 2017.
- ^ FCAT NRT Test, Harcourt, March 18, 2008
- ^ «Danis, Sharron Ann: «Rear Admiral Grace Murray Hopper»«. ei.cs.vt.edu. February 16, 1997. Retrieved January 31, 2010.
- ^ James S. Huggins. «First Computer Bug». Jamesshuggins.com. Archived from the original on August 16, 2000. Retrieved September 24, 2012.
- ^ «Bug Archived March 23, 2017, at the Wayback Machine», The Jargon File, ver. 4.4.7. Retrieved June 3, 2010.
- ^ a b «Log Book With Computer Bug Archived March 23, 2017, at the Wayback Machine», National Museum of American History, Smithsonian Institution.
- ^ «The First «Computer Bug», Naval Historical Center. But note the Harvard Mark II computer was not complete until the summer of 1947.
- ^ IEEE Annals of the History of Computing, Vol 22 Issue 1, 2000
- ^ Journal of the Royal Aeronautical Society. 49, 183/2, 1945 «It ranged … through the stage of type test and flight test and ‘debugging’ …»
- ^ Wilson, Andi; Schulman, Ross; Bankston, Kevin; Herr, Trey. «Bugs in the System» (PDF). Open Policy Institute. Archived (PDF) from the original on September 21, 2016. Retrieved August 22, 2016.
- ^ a b c d Rozens, Tracy (August 12, 2016). «Cyber reforms needed to strengthen software bug discovery and disclosure: New America report – Homeland Preparedness News». Retrieved August 23, 2016.
- ^ «News at SEI 1999 Archive». cmu.edu. Archived from the original on May 26, 2013.
- ^ Shustek, Len (August 2, 2016). «In His Own Words: Gary Kildall». Remarkable People. Computer History Museum. Archived from the original on December 17, 2016.
- ^ Kildall, Gary Arlen (August 2, 2016) [1993]. Kildall, Scott; Kildall, Kristin (eds.). «Computer Connections: People, Places, and Events in the Evolution of the Personal Computer Industry» (Manuscript, part 1). Kildall Family: 14–15. Archived from the original on November 17, 2016. Retrieved November 17, 2016.
- ^ a b «Testing experience : te : the magazine for professional testers». Testing Experience. Germany: testingexperience: 42. March 2012. ISSN 1866-5705. (subscription required)
- ^ Huizinga, Dorota; Kolawa, Adam (2007). Automated Defect Prevention: Best Practices in Software Management. Wiley-IEEE Computer Society Press. p. 426. ISBN 978-0-470-04212-0. Archived from the original on April 25, 2012.
- ^ McDonald, Marc; Musson, Robert; Smith, Ross (2007). The Practical Guide to Defect Prevention. Microsoft Press. p. 480. ISBN 978-0-7356-2253-1.
- ^ «Release Early, Release Often» Archived May 14, 2011, at the Wayback Machine, Eric S. Raymond, The Cathedral and the Bazaar
- ^ «Wide Open Source» Archived September 29, 2007, at the Wayback Machine, Elias Levy, SecurityFocus, April 17, 2000
- ^ Maurice Wilkes Quotes
- ^ «PolySpace Technologies history». christele.faure.pagesperso-orange.fr. Retrieved August 1, 2019.
- ^ Le Goues, Claire; Holtschulte, Neal; Smith, Edward K.; Brun, Yuriy; Devanbu, Premkumar; Forrest, Stephanie; Weimer, Westley (2015). «The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs». IEEE Transactions on Software Engineering. 41 (12): 1236–1256. doi:10.1109/TSE.2015.2454513. ISSN 0098-5589.
- ^ Just, René; Jalali, Darioush; Ernst, Michael D. (2014). «Defects4J: a database of existing faults to enable controlled testing studies for Java programs». Proceedings of the 2014 International Symposium on Software Testing and Analysis — ISSTA 2014. pp. 437–440. CiteSeerX 10.1.1.646.3086. doi:10.1145/2610384.2628055. ISBN 9781450326452. S2CID 12796895.
- ^ Allen, Mitch (May–June 2002). «Bug Tracking Basics: A beginner’s guide to reporting and tracking defects». Software Testing & Quality Engineering Magazine. Vol. 4, no. 3. pp. 20–24. Retrieved December 19, 2017.
- ^ Rex Black (2002). Managing The Testing Process (2Nd Ed.). Wiley India Pvt. Limited. p. 139. ISBN 9788126503131. Retrieved June 19, 2021.
- ^ Chris Vander Mey (August 24, 2012). Shipping Greatness — Practical Lessons on Building and Launching Outstanding Software, Learned on the Job at Google and Amazon. O’Reilly Media. pp. 79–81. ISBN 9781449336608.
- ^ Soleimani Neysiani, Behzad; Babamir, Seyed Morteza; Aritsugi, Masayoshi (October 1, 2020). «Efficient feature extraction model for validation performance improvement of duplicate bug report detection in software bug triage systems». Information and Software Technology. 126: 106344. doi:10.1016/j.infsof.2020.106344. S2CID 219733047.
- ^ «5.3. Anatomy of a Bug». bugzilla.org. Archived from the original on May 23, 2013.
- ^ Jones, Wilbur D. Jr., ed. (1989). «Show stopper». Glossary: defense acquisition acronyms and terms (4 ed.). Fort Belvoir, Virginia, USA: Department of Defense, Defense Systems Management College. p. 123. hdl:2027/mdp.39015061290758 – via Hathitrust.
- ^ a b Zachary, G. Pascal (1994). Show-stopper!: the breakneck race to create Windows NT and the next generation at Microsoft. New York: The Free Press. p. 158. ISBN 0029356717 – via archive.org.
- ^ «The Next Generation 1996 Lexicon A to Z: Slipstream Release». Next Generation. No. 15. March 1996. p. 41.
- ^ Carr, Nicholas (2018). «‘It’s Not a Bug, It’s a Feature.’ Trite—or Just Right?». wired.com.
- ^ Di Franco, Anthony; Guo, Hui; Cindy, Rubio-González. «A Comprehensive Study of Real-World Numerical Bug Characteristics» (PDF). Archived (PDF) from the original on October 9, 2022.
- ^ Kimbler, K. (1998). Feature Interactions in Telecommunications and Software Systems V. IOS Press. p. 8. ISBN 978-90-5199-431-5.
- ^ Syed, Mahbubur Rahman (July 1, 2001). Multimedia Networking: Technology, Management and Applications: Technology, Management and Applications. Idea Group Inc (IGI). p. 398. ISBN 978-1-59140-005-9.
- ^ Wu, Chwan-Hwa (John); Irwin, J. David (April 19, 2016). Introduction to Computer Networks and Cybersecurity. CRC Press. p. 500. ISBN 978-1-4665-7214-0.
- ^ RFC 1263: «TCP Extensions Considered Harmful» quote: «the time to distribute the new version of the protocol to all hosts can be quite long (forever in fact). … If there is the slightest incompatibly between old and new versions, chaos can result.»
- ^ Lientz, B. P.; Swanson, E. B.; Tompkins, G. E. (1978). «Characteristics of Application Software Maintenance». Communications of the ACM. 21 (6): 466–471. doi:10.1145/359511.359522. S2CID 14950091.
- ^ Amit, Idan; Feitelson, Dror G. (2020). «The Corrective Commit Probability Code Quality Metric». arXiv:2007.10912 [cs.SE].
- ^ An overview of the Software Engineering Laboratory (PDF) (Report). Maryland, USA: Goddard Space Flight Center, NASA. December 1, 1994. pp41–42 Figure 18; pp43–44 Figure 21. CR-189410; SEL-94-005. Archived (PDF) from the original on November 22, 2022. Retrieved November 22, 2022. (bibliography: An overview of the Software Engineering Laboratory)
- ^ a b Cobb, Richard H.; Mills, Harlan D. (1990). «Engineering software under statistical quality control». IEEE Software. 7 (6): 46. doi:10.1109/52.60601. ISSN 1937-4194. S2CID 538311 – via University of Tennessee – Harlan D. Mills Collection.
- ^ McConnell, Steven C. (1993). Code Complete. Redmond, Washington, USA: Microsoft Press. p. 611. ISBN 9781556154843 – via archive.org.
(Cobb and Mills 1990)
- ^ Holzmann, Gerard (March 6, 2009). «Appendix D – Software Complexity» (PDF). In Dvorak, Daniel L. (ed.). NASA Study on Flight Software Complexity (Report). NASA. pdf frame 109/264. Appendix D p.2. Archived (PDF) from the original on March 8, 2022. Retrieved November 22, 2022. (under NASA Office of the Chief Engineer Technical Excellence Initiative)
- ^ Ullman, Ellen (2004). The Bug. Picador. ISBN 978-1-250-00249-5.
External links[edit]
- «Common Weakness Enumeration» – an expert webpage focus on bugs, at NIST.gov
- BUG type of Jim Gray – another Bug type
- Picture of the «first computer bug» at the Wayback Machine (archived January 12, 2015)
- «The First Computer Bug!» – an email from 1981 about Adm. Hopper’s bug
- «Toward Understanding Compiler Bugs in GCC and LLVM». A 2016 study of bugs in compilers
A software bug is an error, flaw or fault in the design, development, or operation of computer software that causes it to produce an incorrect or unexpected result, or to behave in unintended ways. The process of finding and correcting bugs is termed «debugging» and often uses formal techniques or tools to pinpoint bugs. Since the 1950s, some computer systems have been designed to deter, detect or auto-correct various computer bugs during operations.
Bugs in software can arise from mistakes and errors made in interpreting and extracting users’ requirements, planning a program’s design, writing its source code, and from interaction with humans, hardware and programs, such as operating systems or libraries. A program with many, or serious, bugs is often described as buggy. Bugs can trigger errors that may have ripple effects. The effects of bugs may be subtle, such as unintended text formatting, through to more obvious effects such as causing a program to crash, freezing the computer, or causing damage to hardware. Other bugs qualify as security bugs and might, for example, enable a malicious user to bypass access controls in order to obtain unauthorized privileges.[1]
Some software bugs have been linked to disasters. Bugs in code that controlled the Therac-25 radiation therapy machine were directly responsible for patient deaths in the 1980s. In 1996, the European Space Agency’s US$1 billion prototype Ariane 5 rocket was destroyed less than a minute after launch due to a bug in the on-board guidance computer program.[2] In 1994, an RAF Chinook helicopter crashed, killing 29; this was initially blamed on pilot error, but was later thought to have been caused by a software bug in the engine-control computer.[3] Buggy software caused the early 21st century British Post Office scandal, the most widespread miscarriage of justice in British legal history.[4]
In 2002, a study commissioned by the US Department of Commerce’s National Institute of Standards and Technology concluded that «software bugs, or errors, are so prevalent and so detrimental that they cost the US economy an estimated $59 billion annually, or about 0.6 percent of the gross domestic product».[5]
History[edit]
The Middle English word bugge is the basis for the terms «bugbear» and «bugaboo» as terms used for a monster.[6]
The term «bug» to describe defects has been a part of engineering jargon since the 1870s[7] and predates electronics and computers; it may have originally been used in hardware engineering to describe mechanical malfunctions. For instance, Thomas Edison wrote in a letter to an associate in 1878:[8]
… difficulties arise—this thing gives out and [it is] then that «Bugs»—as such little faults and difficulties are called—show themselves[9]
Baffle Ball, the first mechanical pinball game, was advertised as being «free of bugs» in 1931.[10] Problems with military gear during World War II were referred to as bugs (or glitches).[11] In a book published in 1942, Louise Dickinson Rich, speaking of a powered ice cutting machine, said, «Ice sawing was suspended until the creator could be brought in to take the bugs out of his darling.»[12]
Isaac Asimov used the term «bug» to relate to issues with a robot in his short story «Catch That Rabbit», published in 1944.
A page from the Harvard Mark II electromechanical computer’s log, featuring a dead moth that was removed from the device.
The term «bug» was used in an account by computer pioneer Grace Hopper, who publicized the cause of a malfunction in an early electromechanical computer.[13] A typical version of the story is:
In 1946, when Hopper was released from active duty, she joined the Harvard Faculty at the Computation Laboratory where she continued her work on the Mark II and Mark III. Operators traced an error in the Mark II to a moth trapped in a relay, coining the term bug. This bug was carefully removed and taped to the log book. Stemming from the first bug, today we call errors or glitches in a program a bug.[14]
Hopper was not present when the bug was found, but it became one of her favorite stories.[15] The date in the log book was September 9, 1947.[16][17][18] The operators who found it, including William «Bill» Burke, later of the Naval Weapons Laboratory, Dahlgren, Virginia,[19] were familiar with the engineering term and amusedly kept the insect with the notation «First actual case of bug being found.» This log book, complete with attached moth, is part of the collection of the Smithsonian National Museum of American History.[17]
The related term «debug» also appears to predate its usage in computing: the Oxford English Dictionary‘s etymology of the word contains an attestation from 1945, in the context of aircraft engines.[20]
The concept that software might contain errors dates back to Ada Lovelace’s 1843 notes on the analytical engine, in which she speaks of the possibility of program «cards» for Charles Babbage’s analytical engine being erroneous:
… an analysing process must equally have been performed in order to furnish the Analytical Engine with the necessary operative data; and that herein may also lie a possible source of error. Granted that the actual mechanism is unerring in its processes, the cards may give it wrong orders.
«Bugs in the System» report[edit]
The Open Technology Institute, run by the group, New America,[21] released a report «Bugs in the System» in August 2016 stating that U.S. policymakers should make reforms to help researchers identify and address software bugs. The report «highlights the need for reform in the field of software vulnerability discovery and disclosure.»[22] One of the report’s authors said that Congress has not done enough to address cyber software vulnerability, even though Congress has passed a number of bills to combat the larger issue of cyber security.[22]
Government researchers, companies, and cyber security experts are the people who typically discover software flaws. The report calls for reforming computer crime and copyright laws.[22]
The Computer Fraud and Abuse Act, the Digital Millennium Copyright Act and the Electronic Communications Privacy Act criminalize and create civil penalties for actions that security researchers routinely engage in while conducting legitimate security research, the report said.[22]
Terminology[edit]
While the use of the term «bug» to describe software errors is common, many have suggested that it should be abandoned. One argument is that the word «bug» is divorced from a sense that a human being caused the problem, and instead implies that the defect arose on its own, leading to a push to abandon the term «bug» in favor of terms such as «defect», with limited success.[23] Since the 1970s Gary Kildall somewhat humorously suggested to use the term «blunder».[24][25]
In software engineering, mistake metamorphism (from Greek meta = «change», morph = «form») refers to the evolution of a defect in the final stage of software deployment. Transformation of a «mistake» committed by an analyst in the early stages of the software development lifecycle, which leads to a «defect» in the final stage of the cycle has been called ‘mistake metamorphism’.[26]
Different stages of a «mistake» in the entire cycle may be described as «mistakes», «anomalies», «faults», «failures», «errors», «exceptions», «crashes», «glitches», «bugs», «defects», «incidents», or «side effects».[26]
Prevention[edit]
The software industry has put much effort into reducing bug counts.[27][28] These include:
Typographical errors[edit]
Bugs usually appear when the programmer makes a logic error. Various innovations in programming style and defensive programming are designed to make these bugs less likely, or easier to spot. Some typos, especially of symbols or logical/mathematical operators, allow the program to operate incorrectly, while others such as a missing symbol or misspelled name may prevent the program from operating. Compiled languages can reveal some typos when the source code is compiled.
Development methodologies[edit]
Several schemes assist managing programmer activity so that fewer bugs are produced. Software engineering (which addresses software design issues as well) applies many techniques to prevent defects. For example, formal program specifications state the exact behavior of programs so that design bugs may be eliminated. Unfortunately, formal specifications are impractical for anything but the shortest programs, because of problems of combinatorial explosion and indeterminacy.
Unit testing involves writing a test for every function (unit) that a program is to perform.
In test-driven development unit tests are written before the code and the code is not considered complete until all tests complete successfully.
Agile software development involves frequent software releases with relatively small changes. Defects are revealed by user feedback.
Open source development allows anyone to examine source code. A school of thought popularized by Eric S. Raymond as Linus’s law says that popular open-source software has more chance of having few or no bugs than other software, because «given enough eyeballs, all bugs are shallow».[29] This assertion has been disputed, however: computer security specialist Elias Levy wrote that «it is easy to hide vulnerabilities in complex, little understood and undocumented source code,» because, «even if people are reviewing the code, that doesn’t mean they’re qualified to do so.»[30] An example of an open-source software bug was the 2008 OpenSSL vulnerability in Debian.
Programming language support[edit]
Programming languages include features to help prevent bugs, such as static type systems, restricted namespaces and modular programming. For example, when a programmer writes (pseudocode) LET REAL_VALUE PI = "THREE AND A BIT", although this may be syntactically correct, the code fails a type check. Compiled languages catch this without having to run the program. Interpreted languages catch such errors at runtime. Some languages deliberately exclude features that easily lead to bugs, at the expense of slower performance: the general principle being that, it is almost always better to write simpler, slower code than inscrutable code that runs slightly faster, especially considering that maintenance cost is substantial. For example, the Java programming language does not support pointer arithmetic; implementations of some languages such as Pascal and scripting languages often have runtime bounds checking of arrays, at least in a debugging build.
Code analysis[edit]
Tools for code analysis help developers by inspecting the program text beyond the compiler’s capabilities to spot potential problems. Although in general the problem of finding all programming errors given a specification is not solvable (see halting problem), these tools exploit the fact that human programmers tend to make certain kinds of simple mistakes often when writing software.
Instrumentation[edit]
Tools to monitor the performance of the software as it is running, either specifically to find problems such as bottlenecks or to give assurance as to correct working, may be embedded in the code explicitly (perhaps as simple as a statement saying PRINT "I AM HERE"), or provided as tools. It is often a surprise to find where most of the time is taken by a piece of code, and this removal of assumptions might cause the code to be rewritten.
Testing[edit]
Software testers are people whose primary task is to find bugs, or write code to support testing. On some projects, more resources may be spent on testing than in developing the program.
Measurements during testing can provide an estimate of the number of likely bugs remaining; this becomes more reliable the longer a product is tested and developed.[citation needed]
Debugging[edit]
The typical bug history (GNU Classpath project data). A new bug submitted by the user is unconfirmed. Once it has been reproduced by a developer, it is a confirmed bug. The confirmed bugs are later fixed. Bugs belonging to other categories (unreproducible, will not be fixed, etc.) are usually in the minority
Finding and fixing bugs, or debugging, is a major part of computer programming. Maurice Wilkes, an early computing pioneer, described his realization in the late 1940s that much of the rest of his life would be spent finding mistakes in his own programs.[31]
Usually, the most difficult part of debugging is finding the bug. Once it is found, correcting it is usually relatively easy. Programs known as debuggers help programmers locate bugs by executing code line by line, watching variable values, and other features to observe program behavior. Without a debugger, code may be added so that messages or values may be written to a console or to a window or log file to trace program execution or show values.
However, even with the aid of a debugger, locating bugs is something of an art. It is not uncommon for a bug in one section of a program to cause failures in a completely different section,[citation needed] thus making it especially difficult to track (for example, an error in a graphics rendering routine causing a file I/O routine to fail), in an apparently unrelated part of the system.
Sometimes, a bug is not an isolated flaw, but represents an error of thinking or planning on the part of the programmer. Such logic errors require a section of the program to be overhauled or rewritten. As a part of code review, stepping through the code and imagining or transcribing the execution process may often find errors without ever reproducing the bug as such.
More typically, the first step in locating a bug is to reproduce it reliably. Once the bug is reproducible, the programmer may use a debugger or other tool while reproducing the error to find the point at which the program went astray.
Some bugs are revealed by inputs that may be difficult for the programmer to re-create. One cause of the Therac-25 radiation machine deaths was a bug (specifically, a race condition) that occurred only when the machine operator very rapidly entered a treatment plan; it took days of practice to become able to do this, so the bug did not manifest in testing or when the manufacturer attempted to duplicate it. Other bugs may stop occurring whenever the setup is augmented to help find the bug, such as running the program with a debugger; these are called heisenbugs (humorously named after the Heisenberg uncertainty principle).
Since the 1990s, particularly following the Ariane 5 Flight 501 disaster, interest in automated aids to debugging rose, such as static code analysis by abstract interpretation.[32]
Some classes of bugs have nothing to do with the code. Faulty documentation or hardware may lead to problems in system use, even though the code matches the documentation. In some cases, changes to the code eliminate the problem even though the code then no longer matches the documentation. Embedded systems frequently work around hardware bugs, since to make a new version of a ROM is much cheaper than remanufacturing the hardware, especially if they are commodity items.
Benchmark of bugs[edit]
To facilitate reproducible research on testing and debugging, researchers use curated benchmarks of bugs:
- the Siemens benchmark
- ManyBugs[33] is a benchmark of 185 C bugs in nine open-source programs.
- Defects4J[34] is a benchmark of 341 Java bugs from 5 open-source projects. It contains the corresponding patches, which cover a variety of patch type.
Bug management[edit]
Bug management includes the process of documenting, categorizing, assigning, reproducing, correcting and releasing the corrected code. Proposed changes to software – bugs as well as enhancement requests and even entire releases – are commonly tracked and managed using bug tracking systems or issue tracking systems.[35] The items added may be called defects, tickets, issues, or, following the agile development paradigm, stories and epics. Categories may be objective, subjective or a combination, such as version number, area of the software, severity and priority, as well as what type of issue it is, such as a feature request or a bug.
A bug triage reviews bugs and decides whether and when to fix them. The decision is based on the bug’s priority, and factors such as project schedules. The triage is not meant to investigate the cause of bugs, but rather the cost of fixing them. The triage happens regularly, and goes through bugs opened or reopened since the previous meeting. The attendees of the triage process typically are the project manager, development manager, test manager, build manager, and technical experts.[36][37]
Severity[edit]
Severity is the intensity of the impact the bug has on system operation.[38] This impact may be data loss, financial, loss of goodwill and wasted effort. Severity levels are not standardized. Impacts differ across industry. A crash in a video game has a totally different impact than a crash in a web browser, or real time monitoring system. For example, bug severity levels might be «crash or hang», «no workaround» (meaning there is no way the customer can accomplish a given task), «has workaround» (meaning the user can still accomplish the task), «visual defect» (for example, a missing image or displaced button or form element), or «documentation error». Some software publishers use more qualified severities such as «critical», «high», «low», «blocker» or «trivial».[39] The severity of a bug may be a separate category to its priority for fixing, and the two may be quantified and managed separately.
Priority[edit]
Priority controls where a bug falls on the list of planned changes. The priority is decided by each software producer. Priorities may be numerical, such as 1 through 5, or named, such as «critical», «high», «low», or «deferred». These rating scales may be similar or even identical to severity ratings, but are evaluated as a combination of the bug’s severity with its estimated effort to fix; a bug with low severity but easy to fix may get a higher priority than a bug with moderate severity that requires excessive effort to fix. Priority ratings may be aligned with product releases, such as «critical» priority indicating all the bugs that must be fixed before the next software release.
A bug severe enough to delay or halt the release of the product is called a «show stopper»[40] or «showstopper bug».[41] It is named so because it «stops the show» – causes unacceptable product failure.[41]
Software releases[edit]
It is common practice to release software with known, low-priority bugs. Bugs of sufficiently high priority may warrant a special release of part of the code containing only modules with those fixes. These are known as patches. Most releases include a mixture of behavior changes and multiple bug fixes. Releases that emphasize bug fixes are known as maintenance releases, to differentiate it from major releases that emphasize feature additions or changes.
Reasons that a software publisher opts not to patch or even fix a particular bug include:
- A deadline must be met and resources are insufficient to fix all bugs by the deadline.[42]
- The bug is already fixed in an upcoming release, and it is not of high priority.
- The changes required to fix the bug are too costly or affect too many other components, requiring a major testing activity.
- It may be suspected, or known, that some users are relying on the existing buggy behavior; a proposed fix may introduce a breaking change.
- The problem is in an area that will be obsolete with an upcoming release; fixing it is unnecessary.
- «It’s not a bug, it’s a feature».[43] A misunderstanding has arisen between expected and perceived behavior or undocumented feature.
Types[edit]
In software development projects, a mistake or error may be introduced at any stage. Bugs arise from oversight or misunderstanding by a software team during specification, design, coding, configuration, data entry or documentation. For example, a relatively simple program to alphabetize a list of words, the design might fail to consider what should happen when a word contains a hyphen. Or when converting an abstract design into code, the coder might inadvertently create an off-by-one error which can be a «<» where «<=» was intended, and fail to sort the last word in a list.
Another category of bug is called a race condition that may occur when programs have multiple components executing at the same time. If the components interact in a different order than the developer intended, they could interfere with each other and stop the program from completing its tasks. These bugs may be difficult to detect or anticipate, since they may not occur during every execution of a program.
Conceptual errors are a developer’s misunderstanding of what the software must do. The resulting software may perform according to the developer’s understanding, but not what is really needed. Other types:
Arithmetic[edit]
In operations on numerical values, problems can arise that result in unexpected output, slowing of a process, or crashing.[44] These can be from a lack of awareness of the qualities of the data storage such as a loss of precision due to rounding, numerically unstable algorithms, arithmetic overflow and underflow, or from lack of awareness of how calculations are handled by different software coding languages such as division by zero which in some languages may throw an exception, and in others may return a special value such as NaN or infinity.
Control flow[edit]
Control flow bugs are those found in processes with valid logic, but that lead to unintended results, such as infinite loops and infinite recursion, incorrect comparisons for conditional statements such as using the incorrect comparison operator, and off-by-one errors (counting one too many or one too few iterations when looping).
Interfacing[edit]
- Incorrect API usage.
- Incorrect protocol implementation.
- Incorrect hardware handling.
- Incorrect assumptions of a particular platform.
- Incompatible systems. A new API or communications protocol may seem to work when two systems use different versions, but errors may occur when a function or feature implemented in one version is changed or missing in another. In production systems which must run continually, shutting down the entire system for a major update may not be possible, such as in the telecommunication industry[45] or the internet.[46][47][48] In this case, smaller segments of a large system are upgraded individually, to minimize disruption to a large network. However, some sections could be overlooked and not upgraded, and cause compatibility errors which may be difficult to find and repair.
- Incorrect code annotations.
Concurrency[edit]
- Deadlock, where task A cannot continue until task B finishes, but at the same time, task B cannot continue until task A finishes.
- Race condition, where the computer does not perform tasks in the order the programmer intended.
- Concurrency errors in critical sections, mutual exclusions and other features of concurrent processing. Time-of-check-to-time-of-use (TOCTOU) is a form of unprotected critical section.
Resourcing[edit]
- Null pointer dereference.
- Using an uninitialized variable.
- Using an otherwise valid instruction on the wrong data type (see packed decimal/binary-coded decimal).
- Access violations.
- Resource leaks, where a finite system resource (such as memory or file handles) become exhausted by repeated allocation without release.
- Buffer overflow, in which a program tries to store data past the end of allocated storage. This may or may not lead to an access violation or storage violation. These are frequently security bugs.
- Excessive recursion which—though logically valid—causes stack overflow.
- Use-after-free error, where a pointer is used after the system has freed the memory it references.
- Double free error.
Syntax[edit]
- Use of the wrong token, such as performing assignment instead of equality test. For example, in some languages x=5 will set the value of x to 5 while x==5 will check whether x is currently 5 or some other number. Interpreted languages allow such code to fail. Compiled languages can catch such errors before testing begins.
Teamwork[edit]
- Unpropagated updates; e.g. programmer changes «myAdd» but forgets to change «mySubtract», which uses the same algorithm. These errors are mitigated by the Don’t Repeat Yourself philosophy.
- Comments out of date or incorrect: many programmers assume the comments accurately describe the code.
- Differences between documentation and product.
Implications[edit]
The amount and type of damage a software bug may cause naturally affects decision-making, processes and policy regarding software quality. In applications such as human spaceflight, aviation, nuclear power, health care, public transport or automotive safety, since software flaws have the potential to cause human injury or even death, such software will have far more scrutiny and quality control than, for example, an online shopping website. In applications such as banking, where software flaws have the potential to cause serious financial damage to a bank or its customers, quality control is also more important than, say, a photo editing application.
Other than the damage caused by bugs, some of their cost is due to the effort invested in fixing them. In 1978, Lientz et al. showed that the median of projects invest 17 percent of the development effort in bug fixing.[49] In 2020, research on GitHub repositories showed the median is 20%.[50]
Residual bugs in delivered product[edit]
In 1994, NASA’s Goddard Space Flight Center managed to reduce their average number of errors from 4.5 per 1000 lines of code (SLOC) down to 1 per 1000 SLOC.[51]
Another study in 1990 reported that exceptionally good software development processes can achieve deployment failure rates as low as 0.1 per 1000 SLOC.[52] This figure is iterated in literature such as Code Complete by Steve McConnell,[53] and the NASA study on Flight Software Complexity.[54] Some projects even attained zero defects: the firmware in the IBM Wheelwriter typewriter which consists of 63,000 SLOC, and the Space Shuttle software with 500,000 SLOC.[52]
Well-known bugs[edit]
A number of software bugs have become well-known, usually due to their severity: examples include various space and military aircraft crashes. Possibly the most famous bug is the Year 2000 problem or Y2K bug, which caused many programs written long before the transition from 19xx to 20xx dates to malfunction, for example treating a date such as «25 Dec 04» as being in 1904, displaying «19100» instead of «2000», and so on. A huge effort at the end of the 20th century resolved the most severe problems, and there were no major consequences.
The 2012 stock trading disruption involved one such incompatibility between the old API and a new API.
In popular culture[edit]
- In both the 1968 novel 2001: A Space Odyssey and the corresponding 1968 film 2001: A Space Odyssey, a spaceship’s onboard computer, HAL 9000, attempts to kill all its crew members. In the follow-up 1982 novel, 2010: Odyssey Two, and the accompanying 1984 film, 2010, it is revealed that this action was caused by the computer having been programmed with two conflicting objectives: to fully disclose all its information, and to keep the true purpose of the flight secret from the crew; this conflict caused HAL to become paranoid and eventually homicidal.
- In the English version of the Nena 1983 song 99 Luftballons (99 Red Balloons) as a result of «bugs in the software», a release of a group of 99 red balloons are mistaken for an enemy nuclear missile launch, requiring an equivalent launch response, resulting in catastrophe.
- In the 1999 American comedy Office Space, three employees attempt (unsuccessfully) to exploit their company’s preoccupation with the Y2K computer bug using a computer virus that sends rounded-off fractions of a penny to their bank account—a long-known technique described as salami slicing.
- The 2004 novel The Bug, by Ellen Ullman, is about a programmer’s attempt to find an elusive bug in a database application.[55]
- The 2008 Canadian film Control Alt Delete is about a computer programmer at the end of 1999 struggling to fix bugs at his company related to the year 2000 problem.
See also[edit]
- Anti-pattern
- Bug bounty program
- Glitch removal
- Hardware bug
- ISO/IEC 9126, which classifies a bug as either a defect or a nonconformity
- Orthogonal Defect Classification
- Racetrack problem
- RISKS Digest
- Software defect indicator
- Software regression
- Software rot
- Automatic bug fixing
References[edit]
- ^ Mittal, Varun; Aditya, Shivam (January 1, 2015). «Recent Developments in the Field of Bug Fixing». Procedia Computer Science. International Conference on Computer, Communication and Convergence (ICCC 2015). 48: 288–297. doi:10.1016/j.procs.2015.04.184. ISSN 1877-0509.
- ^ «Ariane 501 — Presentation of Inquiry Board report». www.esa.int. Retrieved January 29, 2022.
- ^ Prof. Simon Rogerson. «The Chinook Helicopter Disaster». Ccsr.cse.dmu.ac.uk. Archived from the original on July 17, 2012. Retrieved September 24, 2012.
- ^ «Post Office scandal ruined lives, inquiry hears». BBC News. February 14, 2022.
- ^ «Software bugs cost US economy dear». June 10, 2009. Archived from the original on June 10, 2009. Retrieved September 24, 2012.
{{cite web}}: CS1 maint: unfit URL (link) - ^ Computerworld staff (September 3, 2011). «Moth in the machine: Debugging the origins of ‘bug’«. Computerworld. Archived from the original on August 25, 2015.
- ^ «bug». Oxford English Dictionary (Online ed.). Oxford University Press. (Subscription or participating institution membership required.) 5a
- ^ «Did You Know? Edison Coined the Term «Bug»«. August 1, 2013. Retrieved July 19, 2019.
- ^ Edison to Puskas, 13 November 1878, Edison papers, Edison National Laboratory, U.S. National Park Service, West Orange, N.J., cited in Hughes, Thomas Parke (1989). American Genesis: A Century of Invention and Technological Enthusiasm, 1870-1970. Penguin Books. p. 75. ISBN 978-0-14-009741-2.
- ^ «Baffle Ball». Internet Pinball Database.
(See image of advertisement in reference entry)
- ^ «Modern Aircraft Carriers are Result of 20 Years of Smart Experimentation». Life. June 29, 1942. p. 25. Archived from the original on June 4, 2013. Retrieved November 17, 2011.
- ^ Dickinson Rich, Louise (1942), We Took to the Woods, JB Lippincott Co, p. 93, LCCN 42024308, OCLC 405243, archived from the original on March 16, 2017.
- ^ FCAT NRT Test, Harcourt, March 18, 2008
- ^ «Danis, Sharron Ann: «Rear Admiral Grace Murray Hopper»«. ei.cs.vt.edu. February 16, 1997. Retrieved January 31, 2010.
- ^ James S. Huggins. «First Computer Bug». Jamesshuggins.com. Archived from the original on August 16, 2000. Retrieved September 24, 2012.
- ^ «Bug Archived March 23, 2017, at the Wayback Machine», The Jargon File, ver. 4.4.7. Retrieved June 3, 2010.
- ^ a b «Log Book With Computer Bug Archived March 23, 2017, at the Wayback Machine», National Museum of American History, Smithsonian Institution.
- ^ «The First «Computer Bug», Naval Historical Center. But note the Harvard Mark II computer was not complete until the summer of 1947.
- ^ IEEE Annals of the History of Computing, Vol 22 Issue 1, 2000
- ^ Journal of the Royal Aeronautical Society. 49, 183/2, 1945 «It ranged … through the stage of type test and flight test and ‘debugging’ …»
- ^ Wilson, Andi; Schulman, Ross; Bankston, Kevin; Herr, Trey. «Bugs in the System» (PDF). Open Policy Institute. Archived (PDF) from the original on September 21, 2016. Retrieved August 22, 2016.
- ^ a b c d Rozens, Tracy (August 12, 2016). «Cyber reforms needed to strengthen software bug discovery and disclosure: New America report – Homeland Preparedness News». Retrieved August 23, 2016.
- ^ «News at SEI 1999 Archive». cmu.edu. Archived from the original on May 26, 2013.
- ^ Shustek, Len (August 2, 2016). «In His Own Words: Gary Kildall». Remarkable People. Computer History Museum. Archived from the original on December 17, 2016.
- ^ Kildall, Gary Arlen (August 2, 2016) [1993]. Kildall, Scott; Kildall, Kristin (eds.). «Computer Connections: People, Places, and Events in the Evolution of the Personal Computer Industry» (Manuscript, part 1). Kildall Family: 14–15. Archived from the original on November 17, 2016. Retrieved November 17, 2016.
- ^ a b «Testing experience : te : the magazine for professional testers». Testing Experience. Germany: testingexperience: 42. March 2012. ISSN 1866-5705. (subscription required)
- ^ Huizinga, Dorota; Kolawa, Adam (2007). Automated Defect Prevention: Best Practices in Software Management. Wiley-IEEE Computer Society Press. p. 426. ISBN 978-0-470-04212-0. Archived from the original on April 25, 2012.
- ^ McDonald, Marc; Musson, Robert; Smith, Ross (2007). The Practical Guide to Defect Prevention. Microsoft Press. p. 480. ISBN 978-0-7356-2253-1.
- ^ «Release Early, Release Often» Archived May 14, 2011, at the Wayback Machine, Eric S. Raymond, The Cathedral and the Bazaar
- ^ «Wide Open Source» Archived September 29, 2007, at the Wayback Machine, Elias Levy, SecurityFocus, April 17, 2000
- ^ Maurice Wilkes Quotes
- ^ «PolySpace Technologies history». christele.faure.pagesperso-orange.fr. Retrieved August 1, 2019.
- ^ Le Goues, Claire; Holtschulte, Neal; Smith, Edward K.; Brun, Yuriy; Devanbu, Premkumar; Forrest, Stephanie; Weimer, Westley (2015). «The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs». IEEE Transactions on Software Engineering. 41 (12): 1236–1256. doi:10.1109/TSE.2015.2454513. ISSN 0098-5589.
- ^ Just, René; Jalali, Darioush; Ernst, Michael D. (2014). «Defects4J: a database of existing faults to enable controlled testing studies for Java programs». Proceedings of the 2014 International Symposium on Software Testing and Analysis — ISSTA 2014. pp. 437–440. CiteSeerX 10.1.1.646.3086. doi:10.1145/2610384.2628055. ISBN 9781450326452. S2CID 12796895.
- ^ Allen, Mitch (May–June 2002). «Bug Tracking Basics: A beginner’s guide to reporting and tracking defects». Software Testing & Quality Engineering Magazine. Vol. 4, no. 3. pp. 20–24. Retrieved December 19, 2017.
- ^ Rex Black (2002). Managing The Testing Process (2Nd Ed.). Wiley India Pvt. Limited. p. 139. ISBN 9788126503131. Retrieved June 19, 2021.
- ^ Chris Vander Mey (August 24, 2012). Shipping Greatness — Practical Lessons on Building and Launching Outstanding Software, Learned on the Job at Google and Amazon. O’Reilly Media. pp. 79–81. ISBN 9781449336608.
- ^ Soleimani Neysiani, Behzad; Babamir, Seyed Morteza; Aritsugi, Masayoshi (October 1, 2020). «Efficient feature extraction model for validation performance improvement of duplicate bug report detection in software bug triage systems». Information and Software Technology. 126: 106344. doi:10.1016/j.infsof.2020.106344. S2CID 219733047.
- ^ «5.3. Anatomy of a Bug». bugzilla.org. Archived from the original on May 23, 2013.
- ^ Jones, Wilbur D. Jr., ed. (1989). «Show stopper». Glossary: defense acquisition acronyms and terms (4 ed.). Fort Belvoir, Virginia, USA: Department of Defense, Defense Systems Management College. p. 123. hdl:2027/mdp.39015061290758 – via Hathitrust.
- ^ a b Zachary, G. Pascal (1994). Show-stopper!: the breakneck race to create Windows NT and the next generation at Microsoft. New York: The Free Press. p. 158. ISBN 0029356717 – via archive.org.
- ^ «The Next Generation 1996 Lexicon A to Z: Slipstream Release». Next Generation. No. 15. March 1996. p. 41.
- ^ Carr, Nicholas (2018). «‘It’s Not a Bug, It’s a Feature.’ Trite—or Just Right?». wired.com.
- ^ Di Franco, Anthony; Guo, Hui; Cindy, Rubio-González. «A Comprehensive Study of Real-World Numerical Bug Characteristics» (PDF). Archived (PDF) from the original on October 9, 2022.
- ^ Kimbler, K. (1998). Feature Interactions in Telecommunications and Software Systems V. IOS Press. p. 8. ISBN 978-90-5199-431-5.
- ^ Syed, Mahbubur Rahman (July 1, 2001). Multimedia Networking: Technology, Management and Applications: Technology, Management and Applications. Idea Group Inc (IGI). p. 398. ISBN 978-1-59140-005-9.
- ^ Wu, Chwan-Hwa (John); Irwin, J. David (April 19, 2016). Introduction to Computer Networks and Cybersecurity. CRC Press. p. 500. ISBN 978-1-4665-7214-0.
- ^ RFC 1263: «TCP Extensions Considered Harmful» quote: «the time to distribute the new version of the protocol to all hosts can be quite long (forever in fact). … If there is the slightest incompatibly between old and new versions, chaos can result.»
- ^ Lientz, B. P.; Swanson, E. B.; Tompkins, G. E. (1978). «Characteristics of Application Software Maintenance». Communications of the ACM. 21 (6): 466–471. doi:10.1145/359511.359522. S2CID 14950091.
- ^ Amit, Idan; Feitelson, Dror G. (2020). «The Corrective Commit Probability Code Quality Metric». arXiv:2007.10912 [cs.SE].
- ^ An overview of the Software Engineering Laboratory (PDF) (Report). Maryland, USA: Goddard Space Flight Center, NASA. December 1, 1994. pp41–42 Figure 18; pp43–44 Figure 21. CR-189410; SEL-94-005. Archived (PDF) from the original on November 22, 2022. Retrieved November 22, 2022. (bibliography: An overview of the Software Engineering Laboratory)
- ^ a b Cobb, Richard H.; Mills, Harlan D. (1990). «Engineering software under statistical quality control». IEEE Software. 7 (6): 46. doi:10.1109/52.60601. ISSN 1937-4194. S2CID 538311 – via University of Tennessee – Harlan D. Mills Collection.
- ^ McConnell, Steven C. (1993). Code Complete. Redmond, Washington, USA: Microsoft Press. p. 611. ISBN 9781556154843 – via archive.org.
(Cobb and Mills 1990)
- ^ Holzmann, Gerard (March 6, 2009). «Appendix D – Software Complexity» (PDF). In Dvorak, Daniel L. (ed.). NASA Study on Flight Software Complexity (Report). NASA. pdf frame 109/264. Appendix D p.2. Archived (PDF) from the original on March 8, 2022. Retrieved November 22, 2022. (under NASA Office of the Chief Engineer Technical Excellence Initiative)
- ^ Ullman, Ellen (2004). The Bug. Picador. ISBN 978-1-250-00249-5.
External links[edit]
- «Common Weakness Enumeration» – an expert webpage focus on bugs, at NIST.gov
- BUG type of Jim Gray – another Bug type
- Picture of the «first computer bug» at the Wayback Machine (archived January 12, 2015)
- «The First Computer Bug!» – an email from 1981 about Adm. Hopper’s bug
- «Toward Understanding Compiler Bugs in GCC and LLVM». A 2016 study of bugs in compilers
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.

В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
Содержание:

Введение
Программное обеспечение, согласно ГОСТ 19781-90, – совокупность программ системы обработки информации и программных документов, необходимых для их эксплуатации.
Существует и другое, более простое определение, согласно которому программное обеспечение представляет собой совокупность компьютерных инструкций. Оно охватывает программы, подпрограммы (разделы программы) и данные. Таким образом, программное обеспечение указывает компьютеру, что делать, как, когда, в какой последовательности и как часто. Нередко программное обеспечение называют просто программой.
Проблема надежности программного обеспечения относится, похоже, к категории «вечных». В посвященной ей монографии Г.Майерса, выпущенной в 1980 году (американское издание — в 1976), отмечается, что, хотя этот вопрос рассматривался еще на заре применения вычислительных машин, в 1952 году, он не потерял актуальности до настоящего времени. Отношение к проблеме довольно выразительно сформулировано в книге Р.Гласса: «Надежность программного обеспечения — беспризорное дитя вычислительной техники». Следует далее отметить, что сама проблема надежности программного обеспечения имеет, по крайней мере, два аспекта: обеспечение и оценка (измерение) надежности. Практически вся имеющаяся литература на эту тему, включая упомянутые выше монографии, посвящена первому аспекту, а вопрос оценки надежности компьютерных программ оказывается еще более «беспризорным». Вместе с тем очевидно, что надежность программы гораздо важнее таких традиционных ее характеристик, как время исполнения или требуемый объем оперативной памяти, однако никакой общепринятой количественной меры надежности программ до сих пор не существует.
Для обеспечения надежности программ предложено множество подходов, включая организационные методы разработки, различные технологии и технологические программные средства, что требует, очевидно, привлечения значительных ресурсов. Однако отсутствие общепризнанных критериев надежности не позволяет ответить на вопрос, насколько надежнее становится программное обеспечение при соблюдении данных процедур и технологий и в какой степени оправданы расходы. Получается, что таким образом, приоритет задачи оценки надежности должен быть выше приоритета задачи ее обеспечения, чего на самом деле не наблюдается.
Цель данной работы – рассмотреть классификацию ошибок программного обеспечения для обеспечения его надежности.
Надежность программного обеспечения
Показатели качества программного обеспечения
Оценка качества программного обеспечения могут проводиться с двух позиций: с позиции положительной эффективности и непосредственной адекватности их характеристик назначению, целям создания и применения, а также с негативной позиции, возможного при этом ущерба – риска от пользования ПС или системы. Показатели качества преимущественно отражают положительный эффект от применения программного обеспечения и основная задача разработчиков проекта состоит в обеспечении высоких значений качества. Риски характеризуют возможные негативные последствия проявившихся в ходе эксплуатации ошибок или ущерб для пользователя при применении и функционировании программного обеспечения.
Согласно ГОСТ 9126[2], качество программного обеспечения – это весь объем признаков и характеристик программного обеспечения, который относится к ее способности удовлетворять установленным или предполагаемым потребностям.
Качество программного обеспечения оценивается следующими характеристиками:
- Функциональные возможности (Functionality). Набор атрибутов, относящихся к сути набора функций и их конкретным свойствам. Функциями являются те, которые реализуют установленные или предполагаемые потребности.
- Надежность (Reliability). Набор атрибутов относящихся к способности программного обеспечения сохранять свой уровень качества функционирования при установленных условиях за установленный период времени.
- Практичность (Usability). Набор атрибутов, относящихся к объему работ, требуемых для использования и индивидуальной оценки такого использования определенным и предполагаемым кругом пользователей.
- Эффективность (Efficiencies). Набор атрибутов, относящихся к соотношению между уровнем качества функционирования программного обеспечения и объемом используемых ресурсов при установленных условиях.
- Сопровождаемость (Maintainability). Набор атрибутов, относящихся к объему работ, требуемых для проведения конкретных изменений (модификаций).
- Мобильность (Portability). Набор атрибутов, относящихся к способности программного обеспечения быть перенесенным из одного окружения в другое.
В общем случае под ошибкой подразумевается неправильность, погрешность или неумышленное искажение объекта или процесса, что может быть причиной ущерба – риска при функционировании или применении программы. При этом предполагается, что известно правильное, эталонное состояние объекта или процесса по отношению к которому может быть определено наличие отклонения. Исходным эталоном для любого программного обеспечения являются спецификации требований заказчика или потенциального пользователя, предъявляемых к программам и ожидаемый пользователем или заказчиком эффект от использования программного обеспечения. Важной особенностью при этом является отсутствие полностью определенной программы – эталона, которой должны соответствовать текст и результаты функционирования разрабатываемой программы. Поэтому определить качество программного обеспечения и наличие ошибок в нем путем сравнения разрабатываемой программы с эталонной программой невозможно.
Риски проявляются как негативные последствия проявления ошибок в программном обеспечении в ходе его пользования и функционирования, которые могут нанести ущерб системе, в которой используется это программное обеспечение, внешней среде или пользователям этой системы в результате отклонения характеристик программного обеспечения заданных или ожидаемых пользователем или заказчиком.
Исходя из определения ошибки в программном обеспечении, приведенном выше, можно сделать вывод, что ошибки, возникающие в ходе использования программного обеспечения, могут изменять некоторые или все показатели качества. В работе рассматриваются ошибки, изменения которых влияют на надежность использования программного обеспечения.
По правилу, установленному в [2], надежность – свойство объекта осуществлять заданные функции, храня во времени значения установленных эксплуатационных показателей в заданных пределах, соответствующим заданным режимам и условиям использования, ремонта, технического обслуживания, хранения, транспортирования.

Рис. 1. Надежность по ГОСТ 27.002 – 89
При этом надежность является комплексным свойством, которое в зависимости от функции объекта и условий его использования может включать безотказность, ремонтопригодность, долговечность, сохраняемость или некоторые сочетания данных свойств (рис. 1). Так как программное обеспечение в процессе эксплуатации не изнашивается, его поломка и ремонт в общепринятом смысле не делается, то надежность программного обеспечения имеет смысл характеризовать только с точки зрения безотказности его функционирования и возможности исправления функционирования после отказов по вызванных проявлениями ошибок.
В [3] надежность программного обеспечения предлагается характеризовать с помощью следующих характеристик (рис. 2): стабильность, устойчивость и восстанавливаемость.

Рис. 2. Надежность программного обеспечения
В этом случае стабильность и устойчивость характеризуют безотказность программного обеспечения, а восстанавливаемость – возможность восстановления функционирования программного обеспечения после его отказа. Для количественной оценки надежности программного обеспечения необходимо определить показатели надежности для каждого свойства и методику их определения (оценки).
Для оценки стабильности программного обеспечения возможно использование показателей характеризующих безотказность технических устройств [2] (рис. 3).

Рис. 3. Показатели безотказности
В большинстве случаев поток программных ошибок может быть описан негомогенным процессом Пуассона [4]. Это означает, что программные ошибки происходят в статистически независимые моменты времени, наработки подчиняются экспоненциальному распределению, а интенсивность проявления ошибок изменяется во времени. Обычно используют убывающую интенсивность проявления ошибок. Это означает, что ошибки, как только они выявлены, эффективно устраняются без введения новых ошибок. Главная цель анализа надежности программного обеспечения заключается в том, чтобы определить форму функции интенсивности проявления ошибок и оценить ее параметры по наблюдаемым данным. Как только функция интенсивности проявления ошибок определена, могут быть найдены такие показатели надежности как:
- общее количество ошибок;
- количество остающихся ошибок;
- время до проявления следующей ошибки;
- вероятность безошибочной работы;
- интенсивность проявления ошибок;
- остаточное время испытаний (до принятия решения);
- максимальное количество ошибок (относительно срока службы).
При этом следует различать понятия ошибка и отказ. Применительно к надежности программного обеспечения ошибка это погрешность или искажение кода программы, неумышленно внесенные в нее в процессе разработки, которые в ходе функционирования этой программы могут вызвать отказ или снижение эффективности функционирования. Под отказом в общем случае понимают событие, заключающееся в нарушении работоспособности объекта [2]. Состояние объекта, при котором значения всех параметров характеризующих способность выполнять заданные функции, соответствуют требованиям нормативно – технической и (или) конструкторской (проектной) документации – называется работоспособным. При этом критерии отказов, как признаки или совокупность признаков нарушения работоспособного состояния программного обеспечения, должны определяться исходя из его предназначения в нормативно – технической и (или) конструкторской (проектной) документации.
В общем случае отказ программного обеспечения можно определить как:
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время превышающее заданный порог;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время не превышающее заданный порог, но с потерей всех или части обрабатываемых данных;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) потребовавшее перезагрузки ЭВМ, на которой функционирует программное обеспечение.
При этом исходя из [2], все отказы в программном обеспечении следует трактовать как сбои (самоустраняющиеся отказы или однократные отказы, устраняемые незначительным вмешательством оператора), поскольку восстановление работоспособного состояния программного обеспечения может произойти без вмешательства оператора (перезагрузка ЭВМ не требуется), либо при участии оператора или эксплуатирующего персонала (перезагрузка ЭВМ необходима).
Приведенные выше критерии отказов приводят к необходимости анализа временных характеристик функционирования программы и динамических характеристик потребителей данных, полученных в ходе функционирования программного обеспечения. Временная зона перерыва нормальной выдачи информации и потери работоспособности, которую следует рассматривать как зону сбоя (отказа), тем шире, чем более инертный объект находится под воздействием данных, полученным в ходе работы программы. Пороговое время восстановления работоспособного состояния системы, при превышении которого следует соответствующему потребителю (абоненту).
Для любого потребителя данных существует допустимое время отсутствия данных от программы, при котором его характеристики находятся в допустимых пределах. Исходя из этого времени, можно установить границы временной зоны, которая разделяет работоспособное и неработоспособное состояние программного обеспечения и позволяет использовать данные критерии отказов.
Из приведенного выше определения программной ошибки с точки зрения надежности, можно сделать вывод о том, что ошибки, при их проявлении, не всегда вызывают отказ программного обеспечения и каждую ошибку можно характеризовать условной вероятностью возникновения отказа при проявлении этой ошибки. Следует также отметить, что само по себе наличие ошибки в исходном коде не определяет надежность программы до тех пор, пока не произойдет проявления этой ошибки, поэтому пользоваться для оценки надежности программного обеспечения только показателями характеризующие общее количество ошибок в программе, количество оставшихся ошибок и максимального количества ошибок нельзя.
В [5] стабильность предлагается оценивать вероятностью безотказной работы, которая оценивается исходя из модели относительной частоты, при этом применение ее ограничено периодом эксплуатации программного обеспечения, что не всегда приемлемо, поскольку надежность объекта, как правило, необходимо оценивать не только в процессе его эксплуатации, но и до начала эксплуатации этого объекта. Ограничение модели относительной частоты вызвано тем, что в этой модели не учитываются процессы тестирования и отладки, а конкретно то, что при возникновении отказа программного обеспечения, ошибка, вызвавшая этот отказ, исправляется.
Наиболее приемлемыми показателями характеризующими стабильность (безотказность) программного обеспечения представляются показатели сходные с показателями безотказности технических систем: вероятность безотказной работы, интенсивность отказов, и среднее время наработки на отказ. Эти показатели взаимосвязаны и, зная один из них, можно определить другие [2]. При определении этих показателей в большинстве случаев можно исходить из модели надежности, предполагающей, что интенсивность проявления ошибок убывает по мере исправления этих ошибок, время между проявлениями ошибок распределено экспоненциально, а интенсивность проявления ошибок постоянна между двумя соседними проявлениями ошибок. Применение такой модели надежности программного обеспечения позволит оценить надежность программного обеспечения во время тестирования и отладки.
Устойчивость, как свойство или совокупность свойств программного обеспечения, характеризующие его возможность поддерживать приемлемый уровень функционирования при проявлениях ошибок в нем, можно оценивать условной вероятностью безотказной работы при проявлении ошибки. Согласно [5] устойчивость оценивается с помощью трех метрик, включающих двадцать оценочных элементов (рис. 4). Результаты оценки каждой метрики определяются результатами оценки определяющих ее оценочных элементов, а результат оценки устойчивости определяются результатами соответствующих ему метрик. Программное обеспечение по каждому из оценочных элементов оценивается группой экспертов – специалистов, компетентных в решении данной задачи, на базе их опыта и интуиции. Для оценочных элементов принимается единая шкала оценки от 0 до 1.
Недостатком такого подхода является одинаковая оценка устойчивости для всех возможных ошибок. Поскольку вероятность возникновения отказа при проявлении разных ошибок может быть разной, возникает необходимость разделения ошибок на несколько категорий. Признаком, по которому в этом случае можно относить ошибки к той или иной категории, можно считать тяжесть ошибки. Под тяжестью ошибки в этом случае следует понимать количественную или качественную оценку вероятного ущерба при проявлении этой ошибки [6], а если говорить о надежности, то оценку вероятности возникновения отказа при проявлении ошибки. При этом категорией тяжести последствий ошибки будет являться классификационная группа ошибок по тяжести их последствий, характеризуемая определенным сочетанием качественных и/или количественных учитываемых составляющих ожидаемого (вероятного) отказа или нанесенного отказом ущерба.
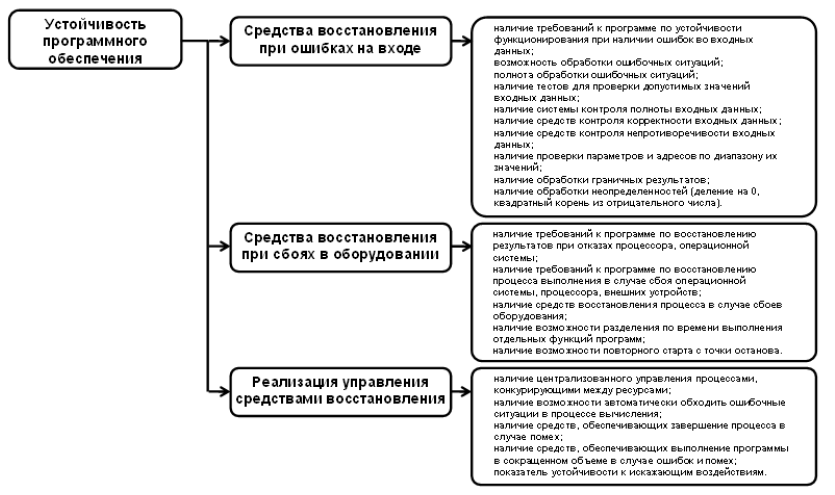
Рис. 4. Метрики и оценочные элементы устойчивости программного обеспечения по ГОСТ 28195 – 89
В качестве показателя степени тяжести ошибки, позволяющего дать количественную оценку тяжести проявления последствий ошибки целесообразно использовать условную вероятность отказа и его возможных последствий при проявлении ошибок разных категорий. Для программного обеспечения, создаваемого для систем управления, потеря работоспособности которых может повлечь за собой катастрофические последствия, возможные категории тяжести ошибок приведены в таблице 1.
Таблица 1. Категории тяжести ошибки в программном обеспечении, нарушение работоспособности которого могут привести к катастрофическим последствиям
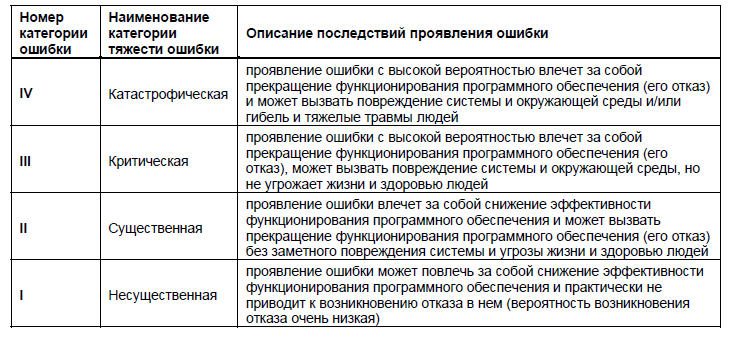
Для программного обеспечения общего применения или программного обеспечения систем, нарушение работоспособности которых не представляет угрозы жизни людей и не приводит к разрушению самой системы, возможные категории тяжести приведены в таблице 2.
Таблица 2. Категории тяжести ошибки в программном обеспечении, нарушение работоспособности которого не приводят к катастрофическим последствиям

Оценку степени тяжести ошибки как условной вероятности возникновения отказа (последствий этого отказа), можно производить согласно [5], используя метрики и оценочные элементы, характеризующие устойчивость программного обеспечения. При этом оценка производится для каждой ошибки в отдельности, а не для всего программного обеспечения. Далее исходя из проведенных оценок возможно определение устойчивости программного обеспечения к проявлениям ошибок каждой из категорий.
Восстанавливаемость программного обеспечения, как свойство или совокупность свойств характеризующих способность программного обеспечения восстановления своего уровня пригодности и восстановления данных, непосредственно поврежденных вследствии проявлении ошибки (отказа), характеризуется полнотой и длительностью восстановления функционирования программ в процессе перезапуска или перезагрузки ЭВМ. В [5] восстанавливаемость предлагается оценивать по среднему времени восстановления. При этом следует учитывать, что время восстановления функционирования программного обеспечения складывается не только из времени потребного для перезагрузки ЭВМ и загрузки самого программного обеспечения, но и из времени необходимого для восстановления данных и это время в ряде случаев может значительно превышать время перезагрузки.
Показатели надежности программного обеспечения в значительной степени адекватны аналогичным характеристикам, принятых для других технических систем. Наиболее широко используется показатель наработки на отказ. Наработка на отказ – это отношение суммарной наработки объекта к математическому ожиданию числа его отказов в течении этой наработки. Для программного обеспечения использование данного показателя затруднено, в силу особенностей тестирования и отладки программного обеспечения (ошибка вызвавшая отказ, как правило, исправляется и больше не повторяется). Поэтому целесообразно использовать показатель средней наработки до отказа – математического ожидания времени функционирования программного обеспечения до отказа. При использовании модели надежности программного обеспечения предполагающей экспоненциальное распределение времени между отказами, среднее время наработки до отказа равно величине обратной интенсивности отказов. Интенсивность отказов можно оценить исходя из оценок стабильности и устойчивости программного обеспечения. Обобщение характеристик отказов и восстановлений производится в показателе коэффициент готовности [2]. Коэффициент готовности программного обеспечения это вероятность того, что программное обеспечение окажется в работоспособном состоянии в произвольный момент времени. Значение коэффициента готовности соответствует доле времени полезной работы программного обеспечения на достаточно большом интервале времени, содержащем отказы и восстановления.
Источники ошибок программного обеспечения
Источниками ошибок в программном обеспечении являются специалисты – конкретные люди с их индивидуальными особенностями, квалификацией, талантом и опытом. Вследствие этого плотность потоков ошибок и размеры необходимых корректировок в модулях и компонентах при разработке и сопровождении программного обеспечения могут различаться в десятки раз. Однако в крупных комплексах программ статистика и распределение ошибок и типов выполняемых изменений, необходимых для их исправления, для коллективов разных специалистов нивелируются и проявляются общие закономерности, которые могут использоваться как ориентиры при выявлении ошибок и их систематизации. Этому могут помогать оценки типовых ошибок, модификаций и корректировок путем их накопления и обобщения по опыту создания определенных классов программного обеспечения.
Основными причинами ошибок программного обеспечения являются:
- Большая сложность программного обеспечения, например, по сравнению с аппаратурой ЭВМ.
- Неправильный перевод информации из одного представления в другое на макро и микро уровнях. На макро уровне, уровне проекта, осуществляется передача и преобразование различных видов информации между организациями, подразделениями и конкретными исполнителями на всех этапах жизненного цикла ПО. На микро уровне, уровне исполнителя, производится преобразование информации по схеме: получить информацию, запомнить, выбрать из памяти, воспроизвести информацию.
Источниками ошибок программного обеспечения являются:
Внутренние: ошибки проектирования, ошибки алгоритмизации, ошибки программирования, недостаточное качество средств защиты, ошибки в документации.
Внешние: ошибки пользователей, сбои и отказы аппаратуры ЭВМ, искажение информации в каналах связи, изменения конфигурации системы.
- Признаками выявления ошибок являются:
- Преждевременное окончание программы.
- Увеличение времени выполнения программы.
- Нарушение последовательности вызова отдельных подпрограмм.
Ошибки выхода информации, поступающей от внешних источников, между входной информацией возникает не соответствие из-за: искажение данных на первичных носителях, сбои и отказы в аппаратуре, шумы и сбои в каналах связи, ошибки в документации.
Ошибки, скрытые в самой программе: ошибка вычислений, ошибка ввода-вывода, логические ошибки, ошибка манипулирования данными, ошибка совместимости, ошибка сопряжения.
Искажения входной информации, подлежащей обработке: искажения данных на первичных носителях информации; сбои и отказы в аппаратуре ввода данных с первичных носителей информации; шумы и сбои в каналах связи при передачи сообщений по линиям связи; сбои и отказы в аппаратуре передачи или приема информации; потери или искажения сообщений в буферных накопителях вычислительных систем; ошибки в документировании; используемой для подготовки ввода данных; ошибки пользователей при подготовки исходной информации.
Неверные действия пользователя:
- Неправильная интерпретация сообщений.
- Неправильные действия пользователя в процессе диалога с программным обеспечением.
- Неверные действия пользователя или по-другому, их можно назвать ошибками пользователя, которые возникают вследствие некачественной программной документации: неверные описания возможности программ; неверные описания режимов работы; неверные описания форматов входной и выходной информации; неверные описания диагностических сообщений.
Неисправности аппаратуры установки: приводят к нарушениям нормального хода вычислительного процесса; приводят к искажениям данных и текстов программ в основной и внешней памяти.
Итак, при рассмотрении основных причин возникновения отказа и сбоев программного обеспечения можно сказать, что эти знания позволяют своевременно принимать необходимые меры по недопущению отказов и сбоев программного обеспечения.
Виды ошибок программного обеспечения
Характеристика основных видов ошибок программного обеспечения
Рассмотрим классификацию ошибок по месту их возникновения, которая рассмотрена в книге С. Канера «Тестирование программного обеспечения». Фундаментальные концепции менеджмента бизнес-приложений. Главным критерием программы должно быть ее качество, которое трактуется как отсутствие в ней недостатков, а также сбоев и явных ошибок. Недостатки программы зависят от субъективной оценкой ее качества потенциальным пользователем. При этом авторы скептически относятся к спецификации и утверждают, что даже при ее наличии, выявленные на конечном этапе недостатки говорят о ее низком качестве. При таком подходе преодоление недостатков программы, особенно на заключительном этапе проектирования, может приводить к снижению надежности. Очевидно, что для разработки ответственного и безопасного программного обеспечения (ПО) такой подход не годится, однако проблемы наличия ошибок в спецификациях, субъективного оценивания пользователем качества программы существуют и не могут быть проигнорированы. Должна быть разработана система некоторых ограничений, которая бы учитывала эти факторы при разработке и сертификации такого рода ПО. Для обычных программ все проблемы, связанные с субъективным оцениванием их качества и наличием ошибок, скорее всего неизбежны.
В краткой классификации выделяются следующие ошибки.
- ошибки пользовательского интерфейса.
- ошибки вычислений.
- ошибки управления потоком.
- ошибки передачи или интерпретации данных.
- перегрузки.
- контроль версий.
- ошибка выявлена и забыта.
- ошибки тестирования.
1. Ошибки пользовательского интерфейса.
Многие из них субъективны, т.к. часто они являются скорее неудобствами, чем «чистыми» логическими ошибками. Однако они могут провоцировать ошибки пользователя программы или же замедлять время его работы до неприемлемой величины. В результате чего мы будем иметь ошибки информационной системы (ИС) в целом. Основным источником таких ошибок является сложный компромисс между функциональностью программы и простотой обучения и работы пользователя с этой программой. Проблему надо начинать решать при проектировании системы на уровне ее декомпозиции на отдельные модули, исходя из того, что вряд ли удастся спроектировать простой и удобный пользовательский интерфейс для модуля, перегруженного различными функциями. Кроме того, необходимо учитывать рекомендации по проектированию пользовательских интерфейсов. На этапе тестирования ПО полезно предусмотреть встроенные средства тестирования, которые бы запоминали последовательности действий пользователя, время совершения отдельных операций, расстояния перемещения курсора мыши. Кроме этого возможно применение гораздо более сложных средств психо-физического тестирования на этапе тестирования интерфейса пользователя, которые позволят оценить скорость реакции пользователя, частоту этих реакций, утомляемость и т.п. Необходимо отметить, что такие ошибки очень критичны с точки зрения коммерческого успеха разрабатываемого ПО, т.к. они будут в первую очередь оцениваться потенциальным заказчиком.
2.Ошибки вычислений.
Выделяют следующие причины возникновения таких ошибок:
- неверная логика (может быть следствием, как ошибок проектирования, так и кодирования);
- неправильно выполняются арифметические операции (как правило — это ошибки кодирования);
- неточные вычисления (могут быть следствием, как ошибок проектирования, так и кодирования). Очень сложная тема, надо выработать свое отношение к ней с точки зрения разработки безопасного ПО.
Выделяются подпункты: устаревшие константы; ошибки вычислений; неверно расставленные скобки; неправильный порядок операторов; неверно работает базовая функция; переполнение и потеря значащих разрядов; ошибки отсечения и округления; путаница с представлением данных; неправильное преобразование данных из одного формата в другой; неверная формула; неправильное приближение.
3.Ошибки управления потоком.
В этот раздел относится все то, что связано с последовательностью и обстоятельствами выполнения операторов программы.
Выделяются подпункты:
- очевидно неверное поведение программы;
- переход по GOTO;
- логика, основанная на определении вызывающей подпрограммы;
- использование таблиц переходов;
- выполнение данных (вместо команд). Ситуация возможна из-за ошибок работы с указателями, отсутствия проверок границ массивов, ошибок перехода, вызванных, например, ошибкой в таблице адресов перехода, ошибок сегментирования памяти.
4.Ошибки обработки или интерпретации данных.
Выделяются подпункты:
- проблемы при передаче данных между подпрограммами (сюда включены несколько видов ошибок: параметры указаны не в том порядке или пропущены, несоответствие типов данных, псевдонимы и различная интерпретация содержимого одной и той же области памяти, неправильная интерпретация данных, неадекватная информация об ошибке, перед аварийным выходом из подпрограммы не восстановлено правильное состояние данных, устаревшие копии данных, связанные переменные не синхронизированы, локальная установка глобальных данных (имеется в виду путаница локальных и глобальных переменных), глобальное использование локальных переменных, неверная маска битового поля, неверное значение из таблицы);
- границы расположения данных (сюда включены несколько видов ошибок: не обозначен конец нуль-терминированной строки, неожиданный конец строки, запись/чтение за границами структуры данных или ее элемента, чтение за пределами буфера сообщения, чтение за пределами буфера сообщения, дополнение переменных до полного слова, переполнение и выход за нижнюю границу стека данных, затирание кода или данных другого процесса);
- проблемы с обменом сообщений (сюда включены несколько видов ошибок: отправка сообщения не тому процессу или не в тот порт, ошибка распознавания полученного сообщения, недостающие или несинхронизированные сообщения, сообщение передано только N процессам из N+1, порча данных, хранящихся на внешнем устройстве, потеря изменений, не сохранены введенные данные, объем данных слишком велик для процесса-получателя, неудачная попытка отмены записи данных).
5.Повышенные нагрузки.
При повышенных нагрузках или нехватке ресурсов могут возникнуть дополнительные ошибки. Выделяются подпункты: требуемый ресурс недоступен; не освобожден ресурс; нет сигнала об освобождении устройства; старый файл не удален с накопителя; системе не возвращена неиспользуемая память; лишние затраты компьютерного времени; нет свободного блока памяти достаточного размера; недостаточный размер буфера ввода или очереди; не очищен элемент очереди, буфера или стека; потерянные сообщения; снижение производительности; повышение вероятности ситуационных гонок; при повышенной нагрузке объем необязательных данных не сокращается; не распознается сокращенный вывод другого процесса при повышенной загрузке; не приостанавливаются задания с низким приоритетом.
7.Ошибки тестирования.
Являются ошибками сотрудников группы тестирования, а не программы. Выделяются подпункты:
- пропущенные ошибки в программе;
- не замечена проблема (отмечаются следующие причины этого: тестировщик не знает, каким должен быть правильный результат, ошибка затерялась в большом объеме выходных данных, тестировщик не ожидал такого результата теста, тестировщик устал и невнимателен, ему скучно, механизм выполнения теста настолько сложен, что тестировщик уделяет ему больше внимания, чем результатам);
- пропуск ошибок на экране;
- не документирована проблема (отмечаются следующие причины этого: тестировщик неаккуратно ведет записи, тестировщик не уверен в том, что данные действия программы являются ошибочными, ошибка показалась слишком незначительной, тестировщик считает, что ошибку не будет исправлена, тестировщика просили не документировать больше подобные ошибки).
8.Ошибка выявлена и забыта.
Описываются ошибки использования результатов тестирования. По-моему, раздел следует объединить с предыдущим. Выделяются подпункты: не составлен итоговый отчет; серьезная проблема не документирована повторно; не проверено исправление; перед выпуском продукта не проанализирован список нерешенных проблем.
Необходимо заметить, что изложенные в 2-х последних разделах ошибки тестирования требуют для устранения средств автоматизации тестирования и составления отчетов. В идеальном случае, эти средства должны быть проинтегрированы со средствами и технологиями проектирования ПО. Они должны стать важными инструментальными средствами создания высококачественного ПО. При разработке средств автоматизированного тестирования следует избегать ошибок, которые присущи любому ПО, поэтому нужно потребовать, чтобы такие средства обладали более высокими характеристиками надежности, чем проверяемое с их помощью ПО.
Меры по повышению надежности программного обеспечения
Лучшим и самым оптимальным способом (если не брать во внимание научно-технический прогресс и постоянное развитие IT-технологий, которые способствуют повышению качества характеристик программ) повышения надёжности программного обеспечения является строжайший контроль продукции на выходе с предприятия.
В последние годы сформировалась комплексная система управления качеством продукции TQM (Totaly Quality Management), которая концептуально близка к предшествующей более общей системе на основе стандартов ИСО серии 9000. Система ориентирована на удовлетворение требований потребителя, на постоянное улучшение процессов производства или проектирования, на управление процессами со стороны руководства предприятия на основе фактического состояния проекта. Основные достижения TQM состоят в углублении и дифференциации требований потребителей по реализации процессов, их взаимодействию и обеспечению качества продукции. Системный подход поддержан рядом специализированных инструментальных средств, ориентированных на управление производством продукции. Поэтому эта система пока не находит применения в области обеспечения качества жизненного цикла программных средств.
Применение этого комплекса может служить основой для систем обеспечения качества программных средств, однако требуется корректировка, адаптация или исключение некоторых положений стандартов применительно к принципиальным особенностям технологий и характеристик этого вида продукции. Кроме того, при реализации систем качества необходимо привлечение ряда стандартов, формально не относящихся к этой серии и регламентирующих показатели качества, жизненный цикл, верификацию и тестирование, испытания, документирование и другие особенности комплексов программ.
Активные методы повышения надежности ПС совершенствуются за счет развития средств автоматизации тестирования программ. Сложность ПС и высокие требования по их надежности требуют выработки принципов структурного построения сложных программных средств, обеспечивающих гибкость модификации ПС и эффективность их отладки. К таким принципам в работе относят:
- модульность и строгую иерархию в структурном построении программ;
- унификацию правил проектирования, структурного построения и взаимодействия компонент ПС;
- унификацию правил организации межмодульного интерфейса;
- поэтапный контроль полноты и качества решения функциональных задач.
Заключение
Несмотря на очевидную актуальность, вопрос надежности программного обеспечения не привлекает должного внимания. Вместе с тем, даже поверхностный анализ проблемы с теоретико-вероятностной точки зрения позволяет выявить некоторые закономерности.
В заключение можно подвести итог:
- В программном обеспечении имеется ошибка, если оно не выполняет того, что пользователю разумно от него ожидать;
- Отказ программного обеспечения — это появление в нем ошибки;
- Надежность программного обеспечения — есть вероятность его работы без отказов в течении определенного периода времени, рассчитанного с учетом стоимости для пользователя каждого отказа.
Из данных определений можно сделать важные выводы:
- Надежность программного обеспечения является не только внутренним свойством программы;
- Надежность программного обеспечения — это функция как самого ПО, так и ожиданий (действий) его пользователей.
Основными причинами ошибок программного обеспечения являются:
- большая сложность ПО, например, по сравнению с аппаратурой ЭВМ;
- неправильный перевод информации из одного представления в другое.
Список использованной литературы
- ГОСТ 27.002 – 89. Надежность в технике. Основные понятия. Термины и определения. // М.: Издательство стандартов, 1990.
- ГОСТ Р ИСО/МЭК 9126 – 93. Информационная технология. Оценка программной продукции. Характеристики качества и руководства по их применению. // М.: Издательство стандартов, 1994.
- ГОСТ 51901.5 – 2005. Менеджмент риска. Руководство по применению методов анализа надежности. // М.: Издательство стандартов, 2007.
- ГОСТ 28195 – 89. Оценка качества программных средств. Общие положения. // М.: Издательство стандартов, 1989.
- ГОСТ 27.310 – 95. Надежность в технике. Анализ видов, последствий и критичности отказов. // М.: Издательство стандартов, 1995.
- ГОСТ 51901.12 – 2007. Менеджмент риска. Метод анализа видов и последствий отказов. // М.: Издательство стандартов, 2007.
- Братчиков И.Л. «Синтаксис языков программирования» Наука, М.:Инси, 2005. — 344 с.
- Дейкстра Э. Заметки по структурному программированию.- М.:Дрофа, 2006, — 455 с.
- Ершов А.П. Введение в теоретическое программирование.- М.:РОСТО, 2008, — 288 с.
- Кнут Д. Искусство программирования для ЭВМ, т.1. М.: 2006, 735 с.
- Коган Д.И., Бабкина Т.С. «Основы теории конечных автоматов и регулярных языков. Учебное пособие» Издательство ННГУ, 2002. — 97 с.
- Липаев В. В. / Программная инженерия. Методологические основы. // М.: ТЕИС, 2006.
- Майерс Г. Надежность программного обеспечения.- М.:Дрофа, 2008, — 360 с.
- Рудаков А. В. Технология разработки программных продуктов. М.:Издательский центр «Академия», 2006. — 306 с.
- Тыугу, Э.Х. Концептуальное программирование. — М.: Наука, 2001, — 256 с.
- Хьюз Дж., Мичтом Дж. Структурный подход к программированию.-М.:Мир, 2000, — 278 с.

- Разработка клиент-серверного приложения по работе с базой данных «Локомотивное депо «
- Анализ особенности управления мотивацией сотрудников на предприятиях гостиничного и ресторанного бизнеса на примере АО ТГК «Вега»
- СУЩНОСТЬ И СОДЕРЖАНИЕ БАНКОВСКОГО МАРКЕТИНГА
- Оформление и ведение учета операций с сомнительными, неплатежеспособными и имеющими признаки подделки денежными знаками
- Виды, понятия, задачи оплаты труда на предприятии
- ценообразование на услуги фитнес-клубов (Российский рынок фитнес-услуг)
- Место и роль спортивной индустрии в экономике России (Теоретические аспекты индустрии спорта)
- Влияние кадровой стратегии на работу службы персонала. (СОДЕРЖАНИЕ И СУЩНОСТЬ КАДРОВОЙ СТРАТЕГИИ)
- Эффективный лидер и его команда (Виды лидерства)
- Межфирменная научно-техническая кооперация
- Прогнозирование эффективности реальных инвестиций коммерческого банка. Анализ инвестиционной деятельности ПАО «Сбербанк»
- Страхование и его государственное регулирование в РФ
Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
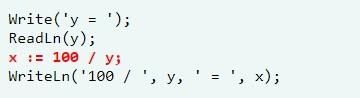
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
Дадим определение основных понятий надежности ПО в соответствии с классической работой Г. Майерса:
- В программном обеспечении имеется ошибка, если оно не выполняет того, что пользователю разумно от него ожидать.
- Отказ программного обеспечения — это появление в нем ошибки.
- Надежность программного обеспечения — вероятность его работы без отказов в течении реки определенного периода Времени, рассчитанного с учетом стоимости для пользователя каждого отказа.
Из данных определений можно сделать важные выводы:
- Надежность программного обеспечения является не только внутренним свойством программы.
- Надежность программного обеспечения — это функция как самого ПО, так и ожиданий (действий) его пользователей.
Основными причинами ошибок программного обеспечения являются:
- Большая сложность ПО, например, по сравнению с аппаратурой ЭВМ.
- Неправильный перевод информации из одного представления в другое на макро- и микроуровнях. На макроуровне, уровне проекта, осуществляется передача и преобразование различных видов информации между организациями, подразделениями и конкретными исполнителями на всех этапах жизненного цикла ПО. На микроуровне, уровне исполнителя, производится преобразование информации по схеме: получить информацию — запомнить — выбрать из памяти (вспомнить) — воспроизвести информацию (передать).
Источниками ошибок (угрозами надежности) программного обеспечения являются:
- Внутренние: ошибки проектирования, ошибки алгоритмизации, ошибки программирования, недостаточное качество средств защиты, ошибки в документации.
- Внешние: ошибки пользователей, сбои и отказы аппаратуры ЭВМ, искажение информации в каналах связи, изменения конфигурации системы.
Методы проектирования надежного программного обеспечения можно разбить на следующие группы:
- Предупреждение ошибок, методы позволяющие минимизировать или исключить появление ошибки.
- Обнаружение ошибок, методы, направленные на разработку дополнительных функций программного обеспечения, помогающих выявить ошибки.
- Устойчивость к ошибкам, дополнительные функции программного обеспечения, предназначенные для исправления ошибок и их последствий и обеспечивающие функционирование системы при наличии ошибок.
Методы предупреждения ошибок концентрируются на отдельных этапах процесса продектирования программного обеспечения и включают в себя:
- Методы, позволяющие справиться со сложностью системы.
- Методы достижения большей точности при переводе информации.
- Методы улучшения обмена информацией.
- Методы немедленного обнаружения и устранения ошибок на каждом шаге (этапе) проектирования, не откладывая их на этап тестирования программы.
Сложность системы является одной из главных причин низкой надежности программного обеспечения. В общем случае, сложность объекта является функцией взаимодействия (количества связей) между его компонентами. В борьбе со сложностью ПО используются две концепции:
- Иерархическая структура. Иерархия позволяет разбить систему по уровням понимания (абстракции, управления). Концепция уровней позволяет анализировать систему, скрывая несущественные для данного уровня детали реализации других уровней. Иерархия позволяет понимать, проектировать и описывать сложные системы.
- Независимость. В соответствии с этой концепцией, для минимизации сложности, необходимо максимально усилить независимость элементов системы.
Это означает такую декомпозицию системы, чтобы её высокочастотная динамика была заключена в отдельных компонентах, а межкомпонентные взаимодействия (связи) описывали только низкочастотную динамику системы. Методы обнаружения ошибок базируются на введении в программное обеспечение системы различных видов избыточности:
- Временная избыточность. Использование части производительности ЭВМ для контроля исполнения и восстановления работоспособности ПО после сбоя.
- Информационная избыточность. Дублирование части данных информационной системы для обеспечения надёжности и контроля достоверности данных.
- Программная избыточность включает в себя: взаимное недоверие — компоненты системы проектируются, исходя из предположения, что другие компоненты и исходные данные содержат ошибки, и должны пытаться их обнаружить; немедленное обнаружение и регистрацию ошибок; выполнение одинаковых функций разными модулями системы и сопоставление результатов обработки; контроль и восстановление данных с использованием других видов избыточности.
Методы обеспечения устойчивости к ошибкам направлены на минимизацию ущерба, вызванного появлением ошибок, и включают в себя:
- обработку сбоев аппаратуры;
- повторное выполнение операций;
- динамическое изменение конфигурации;
- сокращенное обслуживание в случае отказа отдельных функций системы;
- копирование и восстановление данных;
- изоляцию ошибок.
Важным этапом жизненного цикла программного обеспечения, определяющим качество и надёжность системы, является тестирование. Тестирование — процесс выполнения программ с намерением найти ошибки. Этапы тестирования:
- Автономное тестирование, контроль отдельного программного модуля отдельно от других модулей системы.
- Тестирование сопряжений, контроль сопряжений (связей) между частями системы (модулями, компонентами, подсистемами).
- Тестирование функций, контроль выполнения системой автоматизируемых функций.
- Комплексное тестирование, проверка соответствия системы требованиям пользователей.
- Тестирование полноты и корректности документации, выполнение программы в строгом соответствии с инструкциями.
- Тестирование конфигураций, проверка каждого конкретного варианта поставки (установки) системы.
Существуют две стратегии при проектировании тестов:
тестирование по отношению к спецификациям (документации), не заботясь о тексте программы, и тестирование по отношению к тексту программы, не заботясь о спецификациях. Разумный компромисс лежит где-то посередине, смещаясь в ту или иную сторону в зависимости от функций, выполняемых конкретным модулем, комплексом или подсистемой.
Качество подготовки исходных данных для проведения тестирования серьёзно влияет на эффективность процесса в целом и включает в себя:
- техническое задание;
- описание системы;
- руководство пользователя;
- исходный текст;
- правила построения (стандарты) программ и интерфейсов;
- критерии качества тестирования;
- эталонные значения исходных и результирующих данных;
- выделенные ресурсы, определяемые доступными финансовыми средствами.
Однако, исчерпывающее тестирование всех веток алгоритма любой серьёзной программы для всех вариантов входных данных
практически неосуществимо. Следовательно, продолжительность этапа тестирования является вопросом чисто экономическим. Учитывая, что реальные ресурсы любого проекта ограничены бюджетом и графиком, можно утверждать, что искусство тестирования заключается в отборе тестов с максимальной отдачей.
Ошибки в программах и данных могут проявиться на любой стадии тестирования, а также в период эксплуатации системы. Зарегистрированные и обработанные сведения должны использоваться для выявления отклонений от требований заказчика или технического задания. Для решения этой задачи используется система конфигурационного управления версиями программных компонент, база документирования тестов, результатов тестирования и выполненных корректировок программ. Средства накопления сообщений об отказах, ошибках, предложениях на изменения, выполненных корректировках и характеристиках версий являются основной для управления развитием и сопровождением комплекса ПО и состоят из журналов:
- предлагаемых изменений;
- найденных дефектов;
- утвержденных корректировок;
- реализованных изменений;
- пользовательских версий.
ПРИМЕР:
Рассмотрим применение описанных выше методов повышения надёжности программного обеспечения при разработке автоматизированной информационной системы комбината хлебопродуктов (АИС КХП).
Предупреждение ошибок — лучший путь повышения надёжности программного обеспечения. Для его реализации была разработана методика проектирования систем управления предприятиями, соответствующая спиральной модели жизненного цикла ПО. Методика предусматривает последовательное понижение сложности на всех этапах анализа объекта. При декомпозиции АИС были выделены уровни управления системы, затем подсистемы, комплексы задач и так далее, вплоть до отдельных автоматизируемых функций и процедур. Методика базируется на методах структурно-функционального анализа (SADT), диаграммах потоков данных (DFD), диаграммах «сущность-связь» (ERD), методах объектно-ориентированного анализа (OOA) и проектирования (OOD).
На основании методов обнаружения ошибок были разработаны следующие средства повышения надёжности ПО:
- Средства, использующие временную избыточность: авторизация доступа пользователей к системе, анализ доступных пользователю ресурсов, выделение ресурсов согласно ролям и уровням подготовки пользователей, разграничение прав доступа пользователей к отдельным задачам, функциям управления, записям и полям баз данных.
- Средства обеспечения надёжности, использующие информационную избыточность: ссылочная целостность баз данных обеспечивается за счёт системы внутренних уникальных ключей для всех информационных записей системы, открытая система кодирования, позволяющая пользователю в любой момент изменять коды любых объектов классификации, обеспечивает стыковку системы классификации АИС КХП с ПО других разработчиков, механизмы проверки значений контрольных сумм записей системы, обеспечивают выявление всех несанкционированных модификаций (ошибок, сбоев) информации, средства регистрации обеспечивают хранение информации о пользователе и времени последней модификации (ввода, редактирования, удаления) и утверждения каждой записи информационной системы, введение в структуры баз данных системы времени начала и окончания участия записи в расчётах позволяет ограничить объём обрабатываемой информации на любом заданном периоде, а также обеспечить механизмы блокировки информации для закрытых рабочих переводов, ведение служебных полей номеров версий баз данных и операционных признаков записей позволяет контролировать и предупреждать пользователей о конфликтах в случае несоответствия номеров версий модулей и структур баз, либо о нарушении технологических этапов обработки информации, средства автоматического резервного копирования и восстановления данных (в начале, конце сеанса работы или по запросу пользователей) обеспечивают создание на рабочей станции клиента актуальной копии сетевой базы данных, которая может быть использована в случае аварийного сбоя аппаратуры локальной и вычислительной сети и перехода на локальный режим работы и обратно.
- Средства обеспечения надёжности, использующие программную избыточность: распределение реализации одноименных функций по разным модулям АИС КХП с использованием разных алгоритмов и системы накладываемых ограничений и возможностью сравнения полученных результатов; специальные алгоритмы пересчётов обеспечивают в ручном и автоматическом режимах переформирование групп документов, цепочек порождаемых документов и бухгалтерских проводок, что повышает эффективность и надёжность обработки информации; средства обнаружения и регистрации ошибок в сетевом и локальных протоколах; в программные модули системы встроены средства протоколирования процессов сложных расчётов с выдачей подробной диагностики ошибок; средства отладки и трассировки алгоритмов пользовательских бизнес-функций.
- Средства обеспечивающие устойчивость системы к ошибкам: процедура обработки сбоев обеспечивает в автоматическом режиме несколько попыток повторного выполнения операций прежде, чем выдать пользователю сообщение об ошибке (например, для операций раздельного доступа к ресурсам, операций блокировки информации или обращения к внешним устройствам); средства динамического изменения конфигурации осуществляют контроль доступа к сетевым ресурсам, а в случае их недоступности или конфликта обеспечивают автоматический запуск системы по альтернативным путям доступа; средства контроля и обслуживания данных обеспечивают восстановление заголовков баз данных, восстановление индексных файлов, конвертацию модифицированных структур баз данных; средства слияния, копирования, архивирования и восстановления данных.
Для обеспечения качества программного обеспечения АИС КХП на этапе развития и сопровождения системы разработан комплекс программных средств, обеспечивающий:
- управление версиями ПО;
- регистрацию поставок;
- сопровождение заявок клиентов.
Использование рассмотренных методов и средств обеспечения надёжности при проектировании и сопровождении автоматизированной информационной системы комбината хлебопродуктов обеспечило высокий уровень надёжности системы, необходимый для одновременной работы десятков пользователей производственной системы управления в реальном масштабе времени.