Что такое стандартная ошибка оценки? (Определение и пример)
17 авг. 2022 г.
читать 3 мин
Стандартная ошибка оценки — это способ измерения точности прогнозов, сделанных регрессионной моделью.
Часто обозначаемый σ est , он рассчитывается как:
σ est = √ Σ(y – ŷ) 2 /n
куда:
- y: наблюдаемое значение
- ŷ: Прогнозируемое значение
- n: общее количество наблюдений
Стандартная ошибка оценки дает нам представление о том, насколько хорошо регрессионная модель соответствует набору данных. Особенно:
- Чем меньше значение, тем лучше соответствие.
- Чем больше значение, тем хуже соответствие.
Для регрессионной модели с небольшой стандартной ошибкой оценки точки данных будут плотно сгруппированы вокруг предполагаемой линии регрессии:
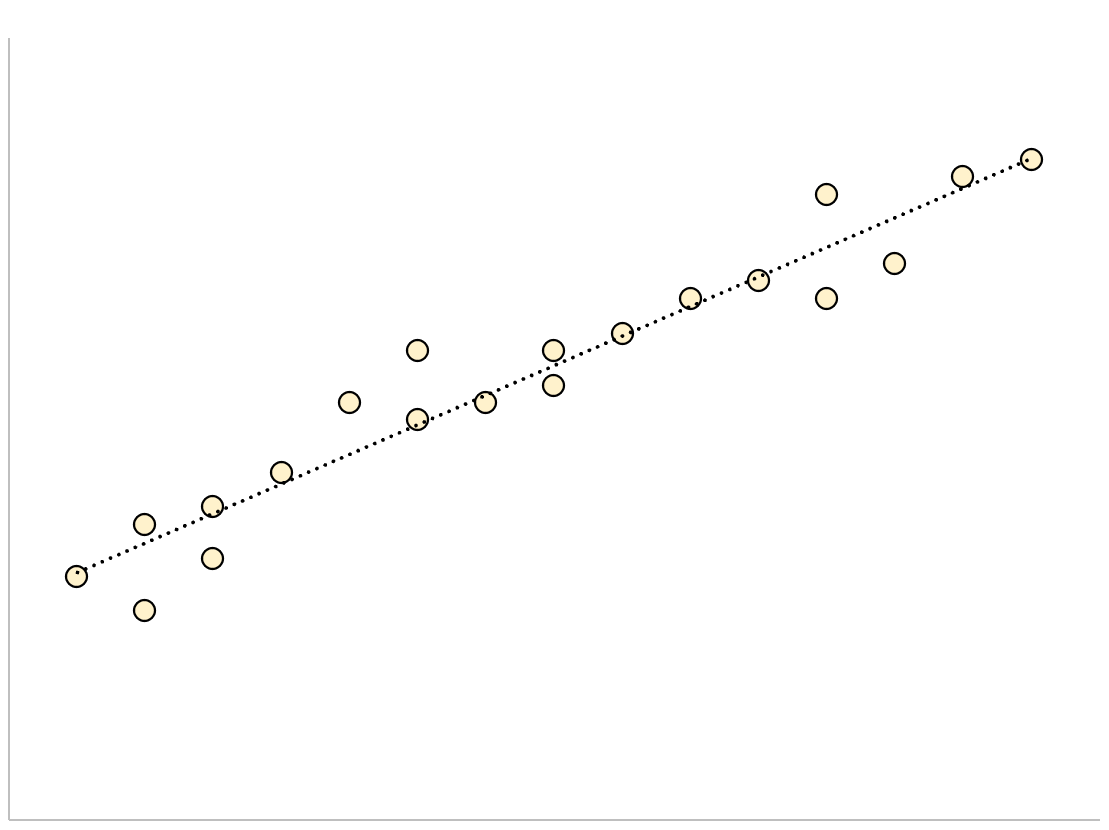
И наоборот, для регрессионной модели с большой стандартной ошибкой оценки точки данных будут более свободно разбросаны по линии регрессии:
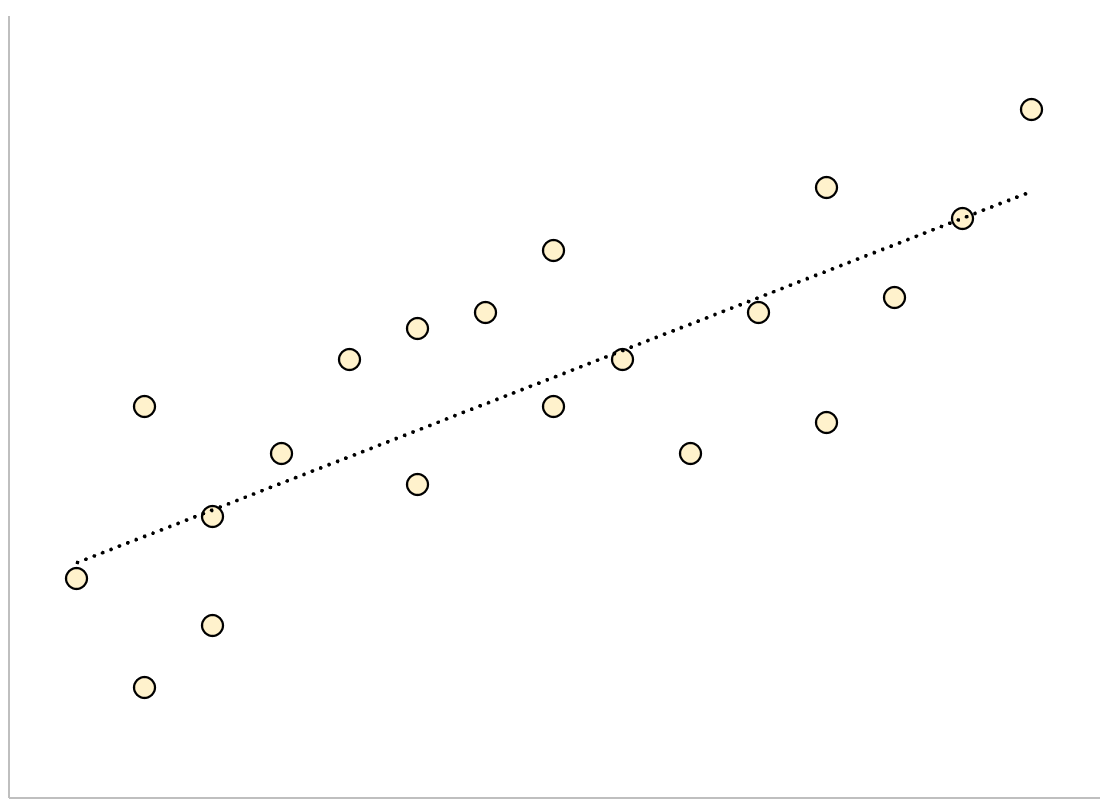
В следующем примере показано, как рассчитать и интерпретировать стандартную ошибку оценки для регрессионной модели в Excel.
Пример: стандартная ошибка оценки в Excel
Используйте следующие шаги, чтобы вычислить стандартную ошибку оценки для регрессионной модели в Excel.
Шаг 1: введите данные
Сначала введите значения для набора данных:

Шаг 2: выполните линейную регрессию
Затем щелкните вкладку « Данные » на верхней ленте. Затем выберите параметр « Анализ данных» в группе « Анализ ».

Если вы не видите эту опцию, вам нужно сначала загрузить пакет инструментов анализа .
В появившемся новом окне нажмите « Регрессия », а затем нажмите « ОК ».

В появившемся новом окне заполните следующую информацию:

Как только вы нажмете OK , появится вывод регрессии:

Мы можем использовать коэффициенты из таблицы регрессии для построения оценочного уравнения регрессии:
ŷ = 13,367 + 1,693 (х)
И мы видим, что стандартная ошибка оценки для этой регрессионной модели оказывается равной 6,006.Проще говоря, это говорит нам о том, что средняя точка данных отклоняется от линии регрессии на 6,006 единицы.
Мы можем использовать оценочное уравнение регрессии и стандартную ошибку оценки, чтобы построить 95% доверительный интервал для прогнозируемого значения определенной точки данных.
Например, предположим, что x равно 10. Используя оценочное уравнение регрессии, мы можем предсказать, что y будет равно:
ŷ = 13,367 + 1,693 * (10) = 30,297
И мы можем получить 95% доверительный интервал для этой оценки, используя следующую формулу:
- 95% ДИ = [ŷ – 1,96*σ расч ., ŷ + 1,96*σ расч .]
Для нашего примера доверительный интервал 95% будет рассчитываться как:
- 95% ДИ = [ŷ – 1,96*σ расч ., ŷ + 1,96*σ расч .]
- 95% ДИ = [30,297 – 1,96*6,006, 30,297 + 1,96*6,006]
- 95% ДИ = [18,525, 42,069]
Дополнительные ресурсы
Как выполнить простую линейную регрессию в Excel
Как выполнить множественную линейную регрессию в Excel
Как создать остаточный график в Excel
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартная ошибка оценки служит для того, чтобы выяснить, как линия регрессии соответствует набору данных. Если у вас есть набор данных, полученных в результате измерения, эксперимента, опроса или из другого источника, создайте линию регрессии, чтобы оценить дополнительные данные. Стандартная ошибка оценки характеризует, насколько верна линия регрессии.
-

1
Создайте таблицу с данными. Таблица должна состоять из пяти столбцов, и призвана облегчить вашу работу с данными. Чтобы вычислить стандартную ошибку оценки, понадобятся пять величин. Поэтому разделите таблицу на пять столбцов. Обозначьте эти столбцы так:[1]
-
2
Введите данные в таблицу. Когда вы проведете эксперимент или опрос, вы получите пары данных — независимую переменную обозначим как
, а зависимую или конечную переменную как . Введите эти значения в первые два столбца таблицы.
- Не перепутайте данные. Помните, что определенному значению независимой переменной должно соответствовать конкретное значение зависимой переменной.
- Например, рассмотрим следующий набор пар данных:
- (1,2)
- (2,4)
- (3,5)
- (4,4)
- (5,5)
-
3
Вычислите линию регрессии. Сделайте это на основе представленных данных. Эта линия также называется линией наилучшего соответствия или линией наименьших квадратов. Расчет можно сделать вручную, но это довольно утомительно. Поэтому рекомендуем воспользоваться графическим калькулятором или онлайн-сервисом, которые быстро вычислят линию регрессии по вашим данным.[2]
- В этой статье предполагается, что уравнение линии регрессии дано (известно).
- В нашем примере линия регрессии описывается уравнением .
-
4
Вычислите прогнозируемые значения по линии регрессии. С помощью уравнения линии регрессии можно вычислить прогнозируемые значения «y» для значений «x», которые есть и которых нет в наборе данных.
Реклама







-
1
Вычислите ошибку каждого прогнозируемого значения. В четвертом столбце таблицы запишите ошибку каждого прогнозируемого значения. В частности, вычтите прогнозируемое значение (
) из фактического (наблюдаемого) значения ().[3]
- В нашем примере вычисления будут выглядеть так:
-
2
Вычислите квадраты ошибок. Возведите в квадрат каждое значение четвертого столбца, а результаты запишите в последнем (пятом) столбце таблицы.
- В нашем примере вычисления будут выглядеть так:
-
3
Найдите сумму квадратов ошибок. Она пригодится для вычисления стандартного отклонения, дисперсии и других величин. Чтобы найти сумму квадратов ошибок, сложите все значения пятого столбца. [4]
- В нашем примере вычисления будут выглядеть так:
- В нашем примере вычисления будут выглядеть так:
-
4
Завершите расчеты. Стандартная ошибка оценки — это квадратный корень из среднего значения суммы квадратов ошибок. Обычно ошибка оценки обозначается греческой буквой
. Поэтому сначала разделите сумму квадратов ошибок на число пар данных. А потом из полученного значения извлеките квадратный корень.[5]
- Если рассматриваемые данные представляют всю совокупность, среднее значение находится так: сумму нужно разделить на N (количество пар данных). Если же рассматриваемые данные представляют некоторую выборку, вместо N подставьте N-2.
- В нашем примере, скорее всего, имеет место выборка, потому что мы рассматриваем всего 5 пар данных. Поэтому стандартную ошибку оценки вычислите следующим образом:
-
5
Интерпретируйте полученный результат. Стандартная ошибка оценки — это статистический показатель, которые оценивает, насколько близко измеренные данные лежат к линии регрессии. Ошибка оценка «0» означает, что каждая точка лежит непосредственно на линии. Чем выше ошибка оценки, тем дальше от линии регрессии лежат точки.[6]
- В нашем примере выборка достаточно маленькая, поэтому стандартная оценка ошибки 0,894 является довольно низкой и характеризует близко расположенные данные.
Реклама








Об этой статье
Эту страницу просматривали 4327 раз.
Была ли эта статья полезной?
Имея
прямую регрессии, необходимо оценить
насколько сильно точки исходных данных
отклоняются от прямой регрессии. Можно
выполнить оценку разброса, аналогичную
стандартному отклонению выборки. Этот
показатель, называемый стандартной
ошибкой оценки, демонстрирует величину
отклонения точек исходных данных от
прямой регрессии в направлении оси Y.
Стандартная ошибка оценки (![]() )
)
вычисляется по следующей формуле.
![]()
Стандартная
ошибка оценки измеряет степень отличия
реальных значений Y от оцененной величины.
Для сравнительно больших выборок следует
ожидать, что около 67% разностей по модулю
не будет превышать
![]()
и около 95% модулей разностей будет не
больше 2![]() .
.
Стандартная
ошибка оценки подобна стандартному
отклонению. Ее можно использовать для
оценки стандартного отклонения
совокупности. Фактически
![]()
оценивает стандартное отклонение
![]()
слагаемого ошибки
![]()
в статистической модели простой линейной
регрессии. Другими словами,
![]()
оценивает общее стандартное отклонение
![]()
нормального распределения значений Y,
имеющих математические ожидания
![]()
для каждого X.
Малая
стандартная ошибка оценки, полученная
при регрессионном анализе, свидетельствует,
что все точки данных находятся очень
близко к прямой регрессии. Если стандартная
ошибка оценки велика, точки данных могут
значительно удаляться от прямой.
2.3 Прогнозирование величины y
Регрессионную
прямую можно использовать для оценки
величины переменной Y
при данных значениях переменной X. Чтобы
получить точечный прогноз, или предсказание
для данного значения X, просто вычисляется
значение найденной функции регрессии
в точке X.
Конечно
реальные значения величины Y,
соответствующие рассматриваемым
значениям величины X, к сожалению, не
лежат в точности на регрессионной
прямой. Фактически они разбросаны
относительно прямой в соответствии с
величиной
![]() .
.
Более того, выборочная регрессионная
прямая является оценкой регрессионной
прямой генеральной совокупности,
основанной на выборке из определенных
пар данных. Другая случайная выборка
даст иную выборочную прямую регрессии;
это аналогично ситуации, когда различные
выборки из одной и той же генеральной
совокупности дают различные значения
выборочного среднего.
Есть
два источника неопределенности в
точечном прогнозе, использующем уравнение
регрессии.
-
Неопределенность,
обусловленная отклонением точек данных
от выборочной прямой регрессии. -
Неопределенность,
обусловленная отклонением выборочной
прямой регрессии от регрессионной
прямой генеральной совокупности.
Интервальный
прогноз значений переменной Y
можно построить так, что при этом будут
учтены оба источника неопределенности.
Стандартная
ошибка прогноза
![]()
дает меру вариативности предсказанного
значения Y
около истинной величины Y
для данного значения X.
Стандартная ошибка прогноза равна:

Стандартная
ошибка прогноза зависит от значения X,
для которого прогнозируется величина
Y.
![]()
минимально, когда
![]() ,
,
поскольку тогда числитель в третьем
слагаемом под корнем в уравнении будет
0. При прочих неизменных величинах
большему отличию соответствует большее
значение стандартной ошибки прогноза.
Если
статистическая модель простой линейной
регрессии соответствует действительности,
границы интервала прогноза величины Y
равны:
![]()
где
![]()
— квантиль распределения Стьюдента с
n-2 степенями свободы (![]() ).
).
Если выборка велика (![]() ),
),
этот квантиль можно заменить соответствующим
квантилем нормального распределения.
Например, для большой выборки 95%-ный
интервал прогноза задается следующими
значениями:
![]()
Завершим
раздел обзором предположений, положенных
в основу статистической модели линейной
регрессии.
-
Для
заданного значения X генеральная
совокупность значений Y имеет нормальное
распределение относительно регрессионной
прямой совокупности. На практике
приемлемые результаты получаются
и
тогда, когда значения Y имеют
нормальное распределение лишь
приблизительно. -
Разброс
генеральной совокупности точек данных
относительно регрессионной прямой
совокупности остается постоянным всюду
вдоль этой прямой. Иными словами, при
возрастании значений X в точках данных
дисперсия генеральной совокупности
не увеличивается и не уменьшается.
Нарушение этого предположения называется
гетероскедастичностью. -
Слагаемые
ошибок

независимы между собой. Это предположение
определяет случайность выборки точек
Х-Y.
Если точки данных X-Y
записывались в течение некоторого
времени, данное предположение часто
нарушается. Вместо независимых данных,
такие последовательные наблюдения
будут давать серийно коррелированные
значения. -
В
генеральной совокупности существует
линейная зависимость между X и Y.
По аналогии с простой линейной регрессией
может рассматриваться и нелинейная
зависимость между X и У. Некоторые такие
случаи будут обсуждаться ниже.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Стандартная ошибка оценки по уравнению регрессии
Стандартная ошибка оценки, также известная как стандартная ошибка уравнения регрессии, определяется следующим образом (см. (6.23)) [c.280]
Стандартная ошибка уравнения регрессии, Эта статистика SEE представляет собой стандартное отклонение фактических значений теоретических значений У. [c.650]
Что такое стандартная ошибка уравнения регрессии ).Какие допущения лежат в основе парной регрессии 10. Что такое множественная регрессия [c.679]
Следующий этап корреляционного анализа — расчет уравнения связи (регрессии). Решение проводится обычно шаговым способом. Сначала в расчет принимается один фактор, который оказывает наиболее значимое влияние на результативный показатель, потом второй, третий и т.д. И на каждом шаге рассчитываются уравнение связи, множественный коэффициент корреляции и детерминации, /»»-отношение (критерий Фишера), стандартная ошибка и другие показатели, с помощью которых оценивается надежность уравнения связи. Величина их на каждом шаге сравнивается с предыдущей. Чем выше величина коэффициентов множественной корреляции, детерминации и критерия Фишера и чем ниже величина стандартной ошибки, тем точнее уравнение связи описывает зависимости, сложившиеся между исследуемыми показателями. Если добавление следующих факторов не улучшает оценочных показателей связи, то надо их отбросить, т.е. остановиться на том уравнении, где эти показатели наиболее оптимальны. [c.149]
Прогнозное значение ур определяется путем подстановки в уравнение регрессии ух =а + Ьх соответствующего (прогнозного) значения хр. Вычисляется средняя стандартная ошибка прогноза [c.9]
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка ть и та. [c.53]
В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур) значение как точечный прогноз ух при хр =хь т. е. путем подстановки в уравнение регрессии 5 = а + b х соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ух, т. е. Шух, и соответственно интервальной оценкой прогнозного значения (у ) [c.57]
Чтобы понять, как строится формула для определения величин стандартной ошибки ух, обратимся к уравнению линейной регрессии ух = а + b х. Подставим в это уравнение выражение параметра а [c.57]
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора. [c.61]
В скобках указаны стандартные ошибки параметров уравнения регрессии. [c.327]
В скобках указаны стандартные ошибки параметров уравнения регрессии. Определим по этому уравнению расчетные значения >>, ,, а затем параметры уравнения регрессии (7.44). Получим следующие результаты [c.328]
На каждом шаге рассматриваются уравнение регрессии, коэффициенты корреляции и детерминации, F-критерий, стандартная ошибка оценки и другие оценочные показатели. После каждого шага перечисленные оценочные показатели сравниваются с [c.39]
Проблемы с методологией регрессии. Методология регрессии — это традиционный способ уплотнения больших массивов данных и их сведения в одно уравнение, отражающее связь между мультипликаторами РЕ и финансовыми фундаментальными переменными. Но данный подход имеет свои ограничения. Во-первых, независимые переменные коррелируют друг с другом . Например, как видно из таблицы 18,2, обобщающей корреляцию между коэффициентами бета, ростом и коэффициентами выплат для всех американских фирм, быстрорастущие фирмы обычно имеют большой риск и низкие коэффициенты выплат. Обратите внимание на отрицательную корреляцию между коэффициентами выплат и ростом, а также на положительную корреляцию между коэффициентами бета и ростом. Эта мультиколлинеарность делает мультипликаторы регрессии ненадежными (увеличивает стандартную ошибку) и, возможно, объясняет ошибочные знаки при коэффициентах и крупные изменения этих мультипликаторов в разные периоды. Во-вторых, регрессия основывается на линейной связи между мультипликаторами РЕ и фундаментальными переменными, и данное свойство, по всей вероятности, неадекватно. Анализ остаточных явлений, связанных с корреляцией, может привести к трансформациям независимых переменных (их квадратов или натуральных логарифмов), которые в большей степени подходят для объяснения мультипликаторов РЕ. В-третьих, базовая связь между мультипликаторами РЕ и финансовыми переменными сама по себе не является стабильной. Если же эта связь смещается из года в год, то прогнозы, полученные из регрессионного уравнения, могут оказаться ненадежными для более длительных периодов времени. По всем этим причинам, несмотря на полезность регрессионного анализа, его следует рассматривать только как еще один инструмент поиска подлинного значения ценности. [c.649]
На рисунке 16.6 явно просматривается четкая линейная зависимость объема частного потребления от величины располагаемого дохода. Уравнение парной линейной регрессии, оцененное по этим данным, имеет вид С= -217,6 + 1,007 Yf Стандартные ошибки для свободного члена и коэффициента парной регрессии равны, соответственно, 28,4 и 0,012, а -статистики — -7,7 и 81 9. Обе они по модулю существенно превышают 3, следовательно, их статистическая значимость весьма высока. Впрочем, несмотря на то, что здесь удалось оценить статистически значимую линейную функцию потребления, в ней нарушены сразу две предпосылки Кейнса — уровень автономного потребления С0 оказался отрицательным, а предель- [c.304]
Стандартные ошибки свободного члена и коэффициента регрессии равны, соответственно, 84,7 и 0,46 их /-статистики — (-21,4 и 36,8). По абсолютной величине /-статистики намного превышают 3, и это свидетельствует о высокой надежности оцененных коэффициентов. Коэффициент детерминации /Р уравнения равен 0,96, то есть объяснено 96% дисперсии объема потребления. И в то же время уже по рисунку видно, что оцененная рефессия не очень хоро- [c.320]
Эта стандартная ошибка S у, равная 0,65, указывает отклонение фактических данных от прогнозируемых на основании использования воздействующих факторов j i и Х2 (влияние среди покупателей бабушек с внучками и высокопрофессионального вклада Шарика). В то же время мы располагаем обычным стандартным отклонением Sn, равным 1,06 (см. табл.8), которое было рассчитано для одной переменной, а именно сами текущие значения уги величина среднего арифметического у, которое равно 6,01. Легко видеть, что S у tTa6n. В противном случае доверять полученной оценке параметра нет оснований. [c.139]
Для определения профиля посетителей магазинов местного торгового центра, не имеющих определенной цели (browsers), маркетологи использовали три набора независимых переменных демографические, покупательское поведение психологические. Зависимая переменная представляет собой индекс посещения магазина без определенной цели, индекс (browsing index). Методом ступенчатой включающей все три набора переменных, выявлено, что демографические факторы — наиболее сильные предикторы, определяющие поведение покупателей, не преследующих конкретных целей. Окончательное уравнение регрессии, 20 из 36 возможных переменных, включало все демографические переменные. В следующей таблице приведены коэффициенты регрессии, стандартные ошибки коэффициентов, а также их уровни значимости. [c.668]
Смотреть страницы где упоминается термин Стандартная ошибка уравнения регрессии
Маркетинговые исследования Издание 3 (2002) — [ c.650 ]
Лекции по дисциплине «Эконометрика» (заочное отделение) (стр. 2 )
 |
Из за большого объема этот материал размещен на нескольких страницах: 1 2 3 4 |

Параметр формально является значением Y при X = 0. Он может не иметь экономического содержания. Интерпретировать можно лишь знак при параметре . Если > 0, то относительное изменение результата происходит медленнее, чем изменение фактора. Иными словами, вариация по фактору X выше вариации для результата Y. Также считают, что включает в себя неучтенные в модели факторы.
По итогам 2008 года были собраны данные по прибыли и оборачиваемости оборотных средств 500 торговых предприятий г. Челябинска. Результаты наблюдения сведены в таблицу.
Годовая прибыль предприятия, млн. руб.
Годовая оборачиваемость оборотных средств, раз
Требуется построить зависимость прибыли предприятий от оборачиваемости оборотных средств и оценить качество полученного уравнения.
Пусть y – прибыль предприятия, x – оборачиваемость оборотных средств.
На основе исходных данных были рассчитаны следующие показатели:
Уровень доверия возьмем q=0,95 или 95%.

1. Стандартные ошибки оценок , . намного больше =0,39, следовательно, низкая точность коэффициента . очень мала по сравнению с , следовательно, высокая точность коэффициента .
2. Интервальные оценки коэффициентов уравнения регрессии.
n – 2 = 500 – 2 = 498;
α:  →
→  → очень низкая точность коэффициента;
→ очень низкая точность коэффициента;
β:  →
→  → высокая точность коэффициента.
→ высокая точность коэффициента.
3. Значимость коэффициентов регрессии.
 = >1,96 → коэффициент значим;
= >1,96 → коэффициент значим;
 = >1,96 → коэффициент значим.
= >1,96 → коэффициент значим.
4. Стандартная ошибка регрессии. Se=0,91, по сравнению со средним значением =34,5 ошибка невысокая, точность уравнения хорошая.
5. Коэффициент детерминации. R2 = rxy2=0,782=0,6084 не очень близко к 1, качество подгонки среднее.
6. Средняя ошибка аппроксимации. A=11%, качество подгонки уравнения среднее.
Экономическая интерпретация: при увеличении оборачиваемости оборотных средств предприятия на 1 раз в год средняя годовая прибыль увеличится на 5,86 млн. руб.
Тема 6. Нелинейная парная регрессия
Часто на практике между зависимой и независимыми переменными существует нелинейная форма взаимосвязи. В этом случае существует два выхода:
1) подобрать к анализируемым переменным преобразование, которое бы позволило представить существующую зависимость в виде линейной функции;
2) применить нелинейный метод наименьших квадратов.
Основные нелинейные регрессионные модели и приведение их к линейной форме
1. Экспоненциальное уравнение  .
.
Если прологарифмировать левую и правую части данного уравнения, то получится
 .
.
Это уравнение является линейным, но вместо y в левой части стоит ln y.
В данном случае параметр β1 имеет следующий экономический смысл: при увеличении переменной x на единицу переменная y в среднем увеличится примерно на 100·β% (более точно: y увеличится в  раз).
раз).
2. Логарифмическое уравнение  .
.
Переход к линейному уравнению осуществляется заменой переменной x на X=lnx..
Параметр β1 имеет следующий экономический смысл: для увеличения y на единицу необходимо увеличить переменную x в  раз, т. е. примерно на
раз, т. е. примерно на  .
.
3. Гиперболическое уравнение  .
.
В этом случае необходимо сделать замену переменных x на  . Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
. Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
4. Степенное уравнение  .
.
Прологарифмировав левую и правую части данного уравнения, получим
 .
.
Заменив соответствующие ряды их логарифмами, получится линейная регрессия.
Экономический смысл параметра β1: если значение переменной x увеличить на 1%, то y увеличится на β1%.
5. Показательное уравнение  (β1>0, β1≠1).
(β1>0, β1≠1).
Прологарифмировав левую и правую части уравнения, получим
 .
.
Проведя замены Y=ln y и B1=ln β1, получится линейная регрессия.
Экономический смысл параметра β1: при увеличении переменной x на единицу переменная y в среднем увеличится в β1 раз.
Тема 7. Множественная линейная регрессия: определение и оценка параметров
1. Понятие множественной линейной регрессии
Модель множественной линейной регрессии является обобщением парной линейной регрессии и представляет собой следующее выражение:
 , t=1. n,
, t=1. n,
где yt – значение зависимой переменной для наблюдения t,
xit – значение i-й независимой переменной для наблюдения t,
εt – значение случайной ошибки для наблюдения t,
n – число наблюдений,
m – число независимых переменных x.
2. Матричная форма записи множественной линейной регрессии
Уравнение множественной линейной регрессии можно записать в матричной форме:
 ,
,
где  ,
,  ,
,  ,
,  .
.
3. Основные предположения
2.  для всех наблюдений;
для всех наблюдений;
3.  = const для всех наблюдений;
= const для всех наблюдений;
4.  ;
;
В случае выполнения вышеперечисленных гипотез модель называется нормальной линейной регрессионной.
4. Метод наименьших квадратов
Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК):  .
.
Чтобы найти минимум этой функции необходимо вычислить производные по каждому из параметров и приравнять их к нулю, в результате получается система уравнений, решение которой в матричном виде следующее:
 →
→  .
.
 ,
,

5. Теорема Гаусса-Маркова
Если выполнены предположения 1-5 из пункта 3, то оценки , полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе линейных несмещенных оценок, то есть являются несмещенными, состоятельными и эффективными.
Тема 8. Множественная линейная регрессия: оценка качества
1. Общая схема проверки качества парной регрессии
Адекватность модели – остатки должны удовлетворять условиям теоремы Гаусса-Маркова.
Основные показатели качества коэффициентов регрессии:
1. Стандартные ошибки оценок (анализ точности определения оценок).
2. Интервальные оценки коэффициентов уравнения регрессии (построение доверительных интервалов).
3. Значимость коэффициентов регрессии (проверка гипотез относительно коэффициентов регрессии).
Основные показатели качества уравнения регрессии в целом:
1. Стандартная ошибка регрессии Se (анализ точности уравнения регрессии).
2. Значимость уравнения регрессии в целом (проверка гипотезы относительно всех коэффициентов регрессии).
3. Коэффициент детерминации R2 (проверка качества подгонки уравнения к исходным данным).
4. Скорректированный коэффициент детерминации R2adj (проверка качества подгонки уравнения к исходным данным).
5. Средняя ошибка аппроксимации (проверка качества подгонки уравнения к эмпирическим данным).
2. Стандартные ошибки оценок
Стандартные ошибки коэффициентов регрессии – это средние квадратические отклонения коэффициентов регрессии от их истинных значений.
 ,
,
где 
 — диагональные элементы матрицы
— диагональные элементы матрицы  ,
,
 .
.
Стандартная ошибка является оценкой среднего квадратического отклонения коэффициента регрессии от его истинного значения. Чем меньше стандартная ошибка тем точнее оценка.
3. Интервальные оценки коэффициентов множественной линейной регрессии
Доверительные интервалы для коэффициентов регрессии определяются следующим образом:
1. Выбирается уровень доверия q (0,9; 0,95 или 0,99).
2. Рассчитывается уровень значимости g = 1 – q.
3. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
4. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
5. Рассчитывается доверительный интервал для параметра  :
:
 .
.
Доверительный интервал показывает, что истинное значение параметра с вероятностью q находится в данных пределах.
Чем меньше доверительный интервал относительно коэффициента, тем точнее полученная оценка.
4. Значимость коэффициентов регрессии
Процедура оценки значимости коэффициентов осуществляется аналогичной парной регрессии следующим образом:
1. Рассчитывается значение t-статистики для коэффициента регрессии по формуле  .
.
2. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
3. Рассчитывается уровень значимости g = 1 – q.
4. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
5. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
6. Если  , то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
, то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
t-тесты обеспечивают проверку значимости предельного вклада каждой переменной при допущении, что все остальные переменные уже включены в модель.
5. Стандартная ошибка регрессии
Стандартная ошибка регрессии Se показывает, насколько в среднем фактические значения зависимой переменной y отличаются от ее расчетных значений
 .
.
Используется как основная величина для измерения качества модели (чем она меньше, тем лучше).
Значения Se в однотипных моделях с разным числом наблюдений и (или) переменных сравнимы.
6. Оценка значимости уравнения регрессии в целом
Уравнение значимо, если есть достаточно высокая вероятность того, что существует хотя бы один коэффициент, отличный от нуля.
Имеются альтернативные гипотезы:
Если принимается гипотеза H0, то уравнение статистически незначимо. В противном случае говорят, что уравнение статистически значимо.
Значимость уравнения регрессии в целом осуществляется с помощью F-статистики.
Оценка значимости уравнения регрессии в целом основана на тождестве дисперсионного анализа:
 Þ
Þ
TSS – общая сумма квадратов отклонений
ESS – объясненная сумма квадратов отклонений
RSS – необъясненная сумма квадратов отклонений
F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы)

n – число выборочных наблюдений, m – число независимых переменных.
При отсутствии линейной зависимости между зависимой и независимой переменными F-статистика имеет F-распределение Фишера-Снедекора со степенями свободы k1 = m, k2 = n – m –1.
Процедура оценки значимости уравнения осуществляется следующим образом:
7. Рассчитывается значение F-статистики по формуле  .
.
8. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
9. Рассчитывается уровень значимости g = 1 – q.
10. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
11. Определяется критическое значение F-статистики (Fкр) по таблицам распределения Фишера на основе g и n – m – 1.
12. Если  , то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
, то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
В парной регрессии F-статистика равна квадрату t-статистики:  , а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
, а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
Качество оценки уравнения можно проверить путем расчета коэффициента детерминации R2, который показывает степень соответствия найденного уравнения экспериментальным данным.
 .
.
Коэффициент R2 показывает долю дисперсии переменной y, объясненную регрессией, в общей дисперсии y.
Коэффициент детерминации лежит в пределах 0 £ R2 £ 1.
Чем ближе R2 к 1, тем выше качество подгонки уравнения к статистическим данным.
Чем ближе R2 к 0, тем ниже качество подгонки уравнения к статистическим данным.
Коэффициенты R2 в разных моделях с разным числом наблюдений и переменных несравнимы.
8. Скорректированный коэффициент детерминации R2adj
Низкое значение R2 не свидетельствует о плохом качестве модели, и может объясняться наличием существенных факторов, не включенных в модель
R2 всегда увеличивается с включением новой переменной. Поэтому его необходимо корректировать, и рассчитывают скорректированный коэффициент детерминации

Если R2adj выходит за пределы интервала [0;1], то его использовать нельзя.
Если при добавлении новой переменной в модель увеличивается не только R2, но и R2adj, то можно считать, что вклад этой переменной в повышение качества модели существенен.
9. Средняя ошибка аппроксимации
Средняя ошибка аппроксимации (средняя абсолютная процентная ошибка) – показывает в процентах среднее отклонение расчетных значений зависимой переменной от фактических значений yi

Если A ≤ 10%, то качество подгонки уравнения считается хорошим. Чем меньше значение A, тем лучше.
10. Использование показателей качества коэффициентов и уравнения регрессии для интерпретации и корректировки модели
В случае незначимости уравнения, необходимо устранить ошибки модели. Наиболее распространенными являются следующие ошибки:
— неправильно выбран вид функции регрессии;
— в модель включены незначимые регрессоры;
— в модели отсутствуют значимые регрессоры.
После устранения ошибок требуется заново оценить параметры уравнения и его качество, продолжая этот процесс до тех пор, пока качество уравнения не станет удовлетворительным. Если после поделанных процедур, мы не достигли требуемого уровня значимости, то необходимо устранять другие ошибки (спецификации, классификации, наблюдения и т. д., см. тему 3, п. 6).
11. Интерпретация множественной линейной регрессии
Коэффициент регрессии при переменной xi показывает, на сколько увеличится среднее значение зависимой переменной y при увеличении xi на 1, при условии постоянства других переменных.
В апреле 2006 года были собраны данные по стоимости 200 двухкомнатных квартир в Металлургическом районе г. Челябинска, их жилой площади, площади кухни и расстоянии до центра города (пл. Революции). Результаты наблюдения сведены в таблицу.
Оценка результатов линейной регрессии
Введение
Модель линейной регрессии
Итак, пусть есть несколько независимых случайных величин X1, X2, . Xn (предикторов) и зависящая от них величина Y (предполагается, что все необходимые преобразования предикторов уже сделаны). Более того, мы предполагаем, что зависимость линейная, а ошибки рапределены нормально, то есть 
где I — единичная квадратная матрица размера n x n.
Итак, у нас есть данные, состоящие из k наблюдений величин Y и Xi и мы хотим оценить коэффициенты. Стандартным методом для нахождения оценок коэффициентов является метод наименьших квадратов. И аналитическое решение, которое можно получить, применив этот метод, выглядит так: 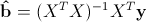
где b с крышкой — оценка вектора коэффициентов, y — вектор значений зависимой величины, а X — матрица размера k x n+1 (n — количество предикторов, k — количество наблюдений), у которой первый столбец состоит из единиц, второй — значения первого предиктора, третий — второго и так далее, а строки соответствуют имеющимся наблюдениям.
Функция summary.lm() и оценка получившихся результатов
Теперь рассмотрим пример построения модели линейной регрессии в языке R:
Таблица gala содержит некоторые данные о 30 Галапагосских островах. Мы будем рассматривать модель, где Species — количество разных видов растений на острове линейно зависит от нескольких других переменных.
Рассмотрим вывод функции summary.lm().
Сначала идет строка, которая напоминает, как строилась модель.
Затем идет информация о распределении остатков: минимум, первая квартиль, медиана, третья квартиль, максимум. В этом месте было бы полезно не только посмотреть на некоторые квантили остатков, но и проверить их на нормальность, например тестом Шапиро-Уилка.
Далее — самое интересное — информация о коэффициентах. Здесь потребуется немного теории.
Сначала выпишем следующий результат: 
при этом сигма в квадрате с крышкой является несмещенной оценкой для реальной сигмы в квадрате. Здесь b — реальный вектор коэффициентов, а эпсилон с крышкой — вектор остатков, если в качестве коэффициентов взять оценки, полученные методом наименьших квадратов. То есть при предположении, что ошибки распределены нормально, вектор коэффициентов тоже будет распределен нормально вокруг реального значения, а его дисперсию можно несмещенно оценить. Это значит, что можно проверять гипотезу на равенство коэффициентов нулю, а следовательно проверять значимость предикторов, то есть действительно ли величина Xi сильно влияет на качество построенной модели.
Для проверки этой гипотезы нам понадобится следующая статистика, имеющая распределение Стьюдента в том случае, если реальное значение коэффициента bi равно 0: 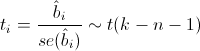
где
 — стандартная ошибка оценки коэффициента, а t(k-n-1) — распределение Стьюдента с k-n-1 степенями свободы.
— стандартная ошибка оценки коэффициента, а t(k-n-1) — распределение Стьюдента с k-n-1 степенями свободы.
Теперь все готово для продолжения разбора вывода функции summary.lm().
Итак, далее идут оценки коэффициентов, полученные методом наименьших квадратов, их стандартные ошибки, значения t-статистики и p-значения для нее. Обычно p-значение сравнивается с каким-нибудь достаточно малым заранее выбранным порогом, например 0.05 или 0.01. И если значение p-статистики оказывается меньше порога, то гипотеза отвергается, если же больше, ничего конкретного, к сожалению, сказать нельзя. Напомню, что в данном случае, так как распределение Стьюдента симметричное относительно 0, то p-значение будет равно 1-F(|t|)+F(-|t|), где F — функция распределения Стьюдента с k-n-1 степенями свободы. Также, R любезно обозначает звездочками значимые коэффициенты, для которых p-значение достаточно мало. То есть, те коэффициенты, которые с очень малой вероятностью равны 0. В строке Signif. codes как раз содержится расшифровка звездочек: если их три, то p-значение от 0 до 0.001, если две, то оно от 0.001 до 0.01 и так далее. Если никаких значков нет, то р-значение больше 0.1.
В нашем примере можно с большой уверенностью сказать, что предикторы Elevation и Adjacent действительно с большой вероятностью влияют на величину Species, а вот про остальные предикторы ничего определенного сказать нельзя. Обычно, в таких случаях предикторы убирают по одному и смотрят, насколько изменяются другие показатели модели, например BIC или Adjusted R-squared, который будет разобран далее.
Значение Residual standart error соответствует просто оценке сигмы с крышкой, а степени свободы вычисляются как k-n-1.
А теперь самая важные статистики, на которые в первую очередь стоит смотреть: R-squared и Adjusted R-squared: 
где Yi — реальные значения Y в каждом наблюдении, Yi с крышкой — значения, предсказанные моделью, Y с чертой — среднее по всем реальным значениям Yi. 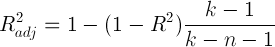
Начнем со статистики R-квадрат или, как ее иногда называют, коэффициента детерминации. Она показывает, насколько условная дисперсия модели отличается от дисперсии реальных значений Y. Если этот коэффициент близок к 1, то условная дисперсия модели достаточно мала и весьма вероятно, что модель неплохо описывает данные. Если же коэффициент R-квадрат сильно меньше, например, меньше 0.5, то, с большой долей уверенности модель не отражает реальное положение вещей.
Однако, у статистики R-квадрат есть один серьезный недостаток: при увеличении числа предикторов эта статистика может только возрастать. Поэтому, может показаться, что модель с большим количеством предикторов лучше, чем модель с меньшим, даже если все новые предикторы никак не влияют на зависимую переменную. Тут можно вспомнить про принцип бритвы Оккама. Следуя ему, по возможности, стоит избавляться от лишних предикторов в модели, поскольку она становится более простой и понятной. Для этих целей была придумана статистика скорректированный R-квадрат. Она представляет собой обычный R-квадрат, но со штрафом за большое количество предикторов. Основная идея: если новые независимые переменные дают большой вклад в качество модели, значение этой статистики растет, если нет — то наоборот уменьшается.
Для примера рассмотрим ту же модель, что и раньше, но теперь вместо пяти предикторов оставим два:
Как можно увидеть, значение статистики R-квадрат снизилось, однако значение скорректированного R-квадрат даже немного возросло.
Теперь проверим гипотезу о равенстве нулю всех коэффициентов при предикторах. То есть, гипотезу о том, зависит ли вообще величина Y от величин Xi линейно. Для этого можно использовать следующую статистику, которая, если гипотеза о равенстве нулю всех коэффициентов верна, имеет распределение Фишера c n и k-n-1 степенями свободы: 
Значение F-статистики и p-значение для нее находятся в последней строке вывода функции summary.lm().
Заключение
В этой статье были описаны стандартные методы оценки значимости коэффициентов и некоторые критерии оценки качества построенной линейной модели. К сожалению, я не касался вопроса рассмотрения распределения остатков и проверки его на нормальность, поскольку это увеличило бы статью еще вдвое, хотя это и достаточно важный элемент проверки адекватности модели.
Очень надеюсь что мне удалось немного расширить стандартное представление о линейной регрессии, как об алгоритме который просто оценивает некоторый вид зависимости, и показать, как можно оценить его результаты.
источники:
http://pandia.ru/text/78/101/1285-2.php
http://habr.com/ru/post/195146/
Correlation and Regression
Andrew F. Siegel, Michael R. Wagner, in Practical Business Statistics (Eighth Edition), 2022
The Standard Error of Estimate: How Large Are the Prediction Errors?
The standard error of estimate, denoted Se here (but often denoted S in computer printouts), tells you approximately how large the prediction errors (residuals) are for your data set in the same units as Y. How well can you predict Y? The answer is to within about Se above or below.16 Because you usually want your forecasts and predictions to be as accurate as possible, you would be glad to find a small value for Se. You can interpret Se as a standard deviation in the sense that if you have a normal distribution for the prediction errors, then you will expect about two-thirds of the data points to fall within a distance Se either above or below the regression line. Also, about 95% of the data values should fall within 2Se, and so forth. This is illustrated in Fig. 11.2.10 for the production cost example.

Fig. 11.2.10. The standard error of estimate, Se, indicates approximately how much error you make when you use the predicted value for Y (on the least-squares line) instead of the actual value of Y. You may expect about two-thirds of the data points to be within Se above or below the least-squares line for a data set with a normal linear relationship, such as this one.
The standard error of estimate may be found using the following formulas:
Standard Error of Estimate
Se=SY(1−r2)n−1n−2(forcomputation)=1n−2∑i=1n[Yi−(a+bXi)]2(forinterpretation)
The first formula shows how Se is computed by reducing SY according to the correlation and sample size. Indeed, Se will usually be smaller than SY because the line a + bX summarizes the relationship and therefore comes closer to the Y values than does the simpler summary, Y¯. The second formula shows how Se can be interpreted as the estimated standard deviation of the residuals: The squared prediction errors are averaged by dividing by n − 2 (the appropriate number of degrees of freedom when two numbers, a and b, have been estimated), and the square root undoes the earlier squaring, giving you an answer in the same measurement units as Y.
For the production cost data, the correlation was found to be r = 0.869193, the variability in the individual cost numbers is SY = $389.6131, and the sample size is n = 18. The standard error of estimate is therefore
Se=SY(1−r2)n−1n−2=389.6131(1−0.8691932)18−118−2=389.6131(0.0244503)1716=389.61310.259785=$198.58
This tells you that, for a typical week, the actual cost was different from the predicted cost (on the least-squares line) by about $198.58. Although the least-squares prediction line takes full advantage of the relationship between cost and number produced, the predictions are far from perfect.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128200254000117
Detection of a Trend in Population Estimates
William L. Thompson, … Charles Gowan, in Monitoring Vertebrate Populations, 1998
5.2 VARIANCE COMPONENTS
In this section, we discuss sources of variation that must be considered to make inferences from data when trying to detect trends. Three sources of variation must be considered: sampling variation, temporal variation in the population dynamics process, and spatial variation in the dynamics of the population across space. The latter two sources often are referred to as process variation, i.e., variation in the population dynamics process associated with environmental variation (such as rainfall, temperature, community succession, fires, or elevation). Methods to separate process variation from sampling variation will be presented.
Detection of a trend in a population’s size requires at least two abundance estimates. For example, if the population size of Mexican spotted owls in Mesa Verde National Park is determined as 50 pairs in 1990, and as only 10 pairs in 1995, we would be concerned that a significant negative trend in the population exists during this time period, and that action must be taken to alleviate the trend. However, if the 1995 estimate was 40 pairs, we might still be concerned, but would be less confident that immediate action is required. Two sources of variation must be assessed before we are confident of our inference from these estimates.
The first source of variation is the uncertainty we have in our population estimates. We want to be sure that the two estimates are different, i.e., the difference between the two estimates is greater than would be expected from chance alone because of the sampling errors associated with each estimate. Typically, we present our uncertainty in our estimate as its variance, and use this variance to generate a confidence interval for our estimate. Suppose that the 1990 estimate of Nˆ90 = 50 pairs has a sampling variance of Vaˆr(Nˆ90)=25. Then, under the assumption of the estimate being normally distributed with a large sample size (i.e., large degrees of freedom), we would compute a 95% confidence interval as 50 ± 1.96 25, or 40.2–59.8. If the 1995 estimate was Nˆ95 = 40 with a sampling variance of Vâr(Nˆ95) = 20, then the 95% confidence interval for this estimate is 40 ± 1.96 20, or 31.2–48.8. Based on the overlap of the two confidence intervals (Fig. 5.2), we would conclude that by chance alone, these two estimates are probably not different. We also could compute a simple test as

Figure 5.2. The 95% confidence intervals plotted with the 1990 and 1995 population estimates.
(5.3)z=Nˆ90−Nˆ95Vaˆr(Nˆ90)+Vaˆr(Nˆ95),
which for this example results in z = 1.491, with a probability of observing a z statistic this large or larger of P = 0.136. Although we might be alarmed, the chances are that 13.6 times out of 100 we would observe this large of a change just by random chance.
A variation of the previous test is commonly conducted for several reasons: (1) we often are interested in the ratio of two population estimates (rather than the difference) because a ratio represents the rate of change of the population, (2) the variance of Nˆ is usually linked to its estimate by Vaˆr(Nˆ)=NˆC (e.g., Skalski and Robson, 1992, pp. 28–29), and (3) ln(Nˆ) is more likely to be normally distributed than Nˆ. Fortuitously, a log transformation provides some correction to all three of the above reasons and results in a more efficient statistical procedure. Because
(5.4)Var[ln(Nˆ)]=Var(Nˆ)Nˆ2,
we construct the z test as
(5.5)z=ln(Nˆ90)−ln(Nˆ95)Vaˆr[ln(Nˆ90)]+Vaˆr[ln(Nˆ95)]
to provide a more efficient (i.e., more powerful) test.
Suppose we had made a much more intensive effort in sampling the owl population, so that the sampling variances were one-half of the values observed (which would generally take about 4 times the effort). Thus, Vâr(Nˆ90) = 12.5 and Vâr(Nˆ95) = 10, giving a z statistic of 2.108 with probability value of P = 0.035. Now, we would conclude that the owl population was lower in 1995 than in 1990, and that this difference is unlikely due to variation in our samples, i.e., that an actual reduction in population size has taken place.
This leads us to the second variance component associated with determining whether a trend in the population is important. We would expect the size of the owl population (and any other population, for that matter) to fluctuate through time. How can we determine if this reduction is important? The answer lies in determining what the variation in the owl population has been for some period of time in the past, and then if the observed reduction is outside the range expected from this past fluctuation. Consider the example in Fig. 5.3, where the true population size (no sampling variation) is plotted. The population fluctuates around a mean of 50, but values more extreme than the range 40 to 60 are common. Note that a decline from 76 to 29 pairs occurred from 1984 to 1985, and that declines from over 50 pairs to under 40 pairs are fairly common occurrences. Thus, based on our previous example, a decline from 50 to 40 is not at all unreasonable given the past population dynamics of this hypothetical population.

Figure 5.3. Actual number of pairs of owls that exist each year. In reality, we never know these values, and can only estimate them.
To determine the level of change in population size that should receive our attention and suggest management action, we need to know something about the temporal variation in the population. The only way to estimate this variance component is to observe the population across a number of years. The exact number of years will depend on the magnitude of the temporal variation. Thus, if the population does not change much from year to year, a few observations will show this consistency. On the other hand, if the population fluctuates a lot, as in Fig. 5.3, many years of observations are needed to estimate the temporal variance. For the example in Fig. 5.3, we could compute the temporal variance as the variance of the 15 years. We find a variance of 265.7, or a standard deviation of 16.3 (Example 5.1). With a SD of 16.3, we would expect roughly 95% of the population values to be in the range of ±2 SD of the mean population size. This inference is based on the population being stable, i.e., not having an upward or downward trend, and being roughly normally distributed. For a normal distribution, 95% of the values lie in the interval ±2 SD of the mean. Therefore, a change of 2 SD, or 32.6, is not a particularly big change given the temporal variation observed over the 15-year period. Such a change should occur with probability greater than 1/20, or 0.05.
A complicating problem with estimating the temporal variance of a population’s size is that we are seldom allowed to observe the true value of the population size. Rather, we are required to sample the population, and hence only obtain an estimate of the population size each year, with its associated sampling variance. Thus, we would need to include the 95% confidence bars on the annual estimates. As a result of this uncertainty from our sampling procedure, we would conclude that many of the year-to-year changes were not really changes because the estimates were not different. This complication leads to a further problem. If we compute the variance with the usual formula when estimates of population size replace the actual population size shown in Fig. 5.3, we obtain a variance estimate larger than the true temporal variance because our sampling uncertainty is included in the variance. For low levels of sampling effort each year, we would have a high sampling variance associated with each estimate, and as a result, we would have a high variance across years. The noise associated with our low sampling intensity would suggest that the population is fluctuating widely, when in fact the population could be constant (i.e., temporal variance is zero), and the estimated changes in the population are just due to sampling variance.
This mixture of sampling and temporal variation becomes particularly important in population viability analysis (PVA). The objective of a PVA is to estimate the probability of extinction for a population, given current size, and some idea of the variation in the population dynamics (i.e., temporal variation). If our estimate of temporal variation includes sampling variation, and the level of effort to obtain the estimates is relatively low, the high sampling variation causes our naive estimate of temporal variation to be much too large. When we apply our PVA analysis with this inflated estimate of temporal variance, we conclude that the population is much more likely to go extinct than it really is, and hence the importance of separating sampling variation from process variation.
Typically, we estimate variance components with analysis of variance (ANOVA) procedures. For the example considered here, we would have to have at least two estimates of population size for a series of years to obtain valid estimates of sampling and temporal variation. Further, typical ANOVA techniques assume that the sampling variation is constant, and so do not account for differences in levels of effort, or the fact that sampling variance is usually a function of population size. For our example, we have an estimate of sampling variance for each of our estimates, obtained from the population estimation methods considered in this manual. That is, capture–recapture, mark–resight, line transects, removal methods, and quadrat counts all produce estimates of sampling variation. Thus, we do not want to estimate sampling variation by obtaining replicate estimates, but want to use the available estimate. Therefore, we present a method of moments estimator developed in Burnham et al. (1987, Part 5). Skalski and Robson (1992, Chapter 2) also present a similar procedure, but do not develop the weighted estimator presented here.
Example 5.1 Population Size, Estimates, Standard Error of the Estimates, and Confidence Intervals for Owl Pairs in Fig. 5.3
| Standard | |||||
|---|---|---|---|---|---|
| Year | Population | Estimate | error | Lower 95% CI | Upper 95% CI |
| 1980 | 44 | 40.04 | 5.926 | 28.42 | 51.66 |
| 1981 | 48 | 50.51 | 11.004 | 28.94 | 72.08 |
| 1982 | 61 | 61.36 | 15.278 | 31.42 | 91.31 |
| 1983 | 48 | 47.6 | 11.062 | 25.92 | 69.28 |
| 1984 | 76 | 95.51 | 18.988 | 58.3 | 132.72 |
| 1985 | 29 | 33.81 | 8.803 | 16.56 | 51.06 |
| 1986 | 60 | 34.39 | 5.804 | 23.01 | 45.76 |
| 1987 | 59 | 38.52 | 11.168 | 16.63 | 60.41 |
| 1988 | 76 | 84.57 | 21.312 | 42.8 | 126.34 |
| 1989 | 42 | 30.04 | 6.918 | 16.48 | 43.6 |
| 1990 | 29 | 20.29 | 7.529 | 5.54 | 35.05 |
| 1991 | 68 | 68.42 | 17.969 | 33.2 | 103.64 |
| 1992 | 42 | 45.51 | 13.225 | 19.6 | 71.44 |
| 1993 | 27 | 27.01 | 6.137 | 14.98 | 39.04 |
| 1994 | 72 | 71.12 | 14.511 | 42.67 | 99.56 |
| 1995 | 54 | 51.45 | 8.054 | 35.66 | 67.24 |
The variance of the n = 16 populations is 265.628, whereas the variance of the 16 estimates is 450.376. Sampling variation causes the estimates to have a larger variance than the actual population. The difference of these two variances is an estimate of the sampling variation, i.e., 450.376 – 265.628 = 184.748. The square root of 184.748 is 13.592, and is the approximate mean of the 16 reported standard errors.
To obtain an unbiased estimate of the temporal variance, we must remove the sampling variation from the estimate of the total variance. Define σtotal2 as the total variance, estimated for n = 16 estimates of owl pairs (Nˆi, i = 1980, …, 1995) as
(5.6)σˆtotal2=Σi=19801995(Nˆi−N¯)2(n−1)=Σi=19801995Nˆi2(Σi−19801985Nˆi)2n(n−1),
where the symbol indicates the estimate of the parameter. Thus, Nˆi are the estimates of the actual populations, Ni, and σˆtotal2 is an estimate of the total variance σˆi2 For each estimate, Nˆi, we also have an associated sampling variance, σˆi2. Then, a simple estimator of the temporal variance, σ2time, is given by
(5.7)σˆtime2=σˆtotal2−Σi=19801995σˆi2n,
when we can assume that all of the sampling variances, σˆi2, are equal. The above equation corresponds to Eq. (2.6) of Skalski and Robson (1992). When the σˆi2 cannot all be assumed to be equal, a more complex calculation is required (Burnham et al., 1987, Section 4.3) because each estimate must be weighted by its sampling variance. We take as the weight of each estimate the reciprocal of the sum of temporal variance plus the sampling variance, 1/(σˆtime2+σˆi2). That is, Var(Nˆi)=σˆtime2+σˆi2, so wi=1/Var(Nˆi)=1/(σˆtime2+σˆi2). Then, the weighted total variance is computed as
(5.8)σˆtotal2=Σi=19801995wi(Nˆi−N¯)2(n−1)Σi=19801995wi
with the mean of the estimates now computed as a weighted mean,
(5.9)N¯=Σi=19801995wiNˆiΣi=19801995wi.
We now know that the theoretical variance N¯ is
(5.10)Var(N¯)=Var(Σi=19801995wiNˆiΣi=19801995wi)=1Σi=19801995wi
and the empirical variance estimator is Eq. (5.8). Setting these two equations equal,
(5.11)1Σi=19801995wi=Σi=19801995wi(Nˆi−N¯)2(n−1)Σi=19801995wi
or
(5.12)1=Σi=19801995wi(Nˆi−N¯)2(n−1).
Because we cannot solve for σˆtime2 directly, we have to use an iterative numerical approach to estimate σˆtime2 This procedure involves substituting values of σˆtime2 into Eq. (5.12) via the wi until the two sides are equal. When both sides are the same, we have our estimate of σˆtime2. Using this estimate of σˆtime2, we can now decide what level of change in Nˆi to Nˆi+1 is important and deserves attention. If the change from a series of estimates is greater than 2σˆtime2, we may want to take action.
Typically, we do not have the luxury of enough background data to estimate σˆtime2, so we end up trying to evaluate whether a series of estimated population sizes is in fact signaling a decline in the population when both sampling and process variance are present. Note that just because we see a decline of the estimates for 3–4 consecutive years, we cannot be sure that the population is actually in a serious decline without knowledge of the mean population size and the temporal variation prior to the decline. Usually, however, we do not have good knowledge of the population size prior to some observed decline, and make a decision to act based on biological perceptions. Keep in mind the kinds of trends displayed in Fig. 5.1. Is the suggested trend part of a cycle, or are we observing a real change in population size? In this discussion, we have only considered temporal variation. A similar procedure can be used to separate spatial variation from sampling variation.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780126889604500058
Multiple Regression
Andrew F. Siegel, Michael R. Wagner, in Practical Business Statistics (Eighth Edition), 2022
Typical Prediction Error: Standard Error of Estimate
Just as for simple regression, with only one X, the standard error of estimate indicates the approximate size of the prediction errors. For the magazine ads example, Se = $106,072. This tells you that actual page costs for these magazines are typically within about $106,072 from the predicted page costs, in the sense of a standard deviation. That is, if the error distribution is normal, then you would expect about two-thirds of the actual page costs to be within Se of the predicted page costs, about 95% to be within 2Se, and so forth.
The standard error of estimate, Se = $106,072, indicates the remaining variation in page costs after you have used the X variables (audience, percent male, and median income) in the regression equation to predict page costs for each magazine. Compare this to the ordinary univariate standard deviation, SY = $163,549, for the page costs, computed by ignoring all the other variables. This standard deviation, SY, indicates the remaining variation in page costs after you have used only Y¯ to predict the page costs for each magazine. Note that Se = $106,072 is smaller than SY = $163,549; your errors are typically smaller if you use the regression equation instead of just Y¯ to predict page costs. This suggests that the X variables are helpful in explaining page costs.
Think of the situation this way. If you knew nothing of the X variables, you would use the average page costs (Y¯=$187,628) as your best guess, and you would be wrong by about SY = $163,549. But if you knew the audience, percent male readership, and median reader income, you could use the regression equation to find a prediction for page costs that would be wrong by only Se = $106,072. This reduction in prediction error (from $163,549 to $106,072) is one of the helpful payoffs from running a regression analysis.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128200254000129
Multiple Regression
Gary Smith, in Essential Statistics, Regression, and Econometrics, 2012
Confidence Intervals for the Coefficients
If the error term is normally distributed and satisfies the four assumptions detailed in the simple regression chapter, the estimators are normally distributed with expected values equal to the parameters they estimate:
a∼N[α, standard deviation of a]bi∼N[βi, standard deviation of bi]
To compute the standard errors (the estimated standard deviations) of these estimators, we need to use the standard error of estimate (SEE) to estimate the standard deviation of the error term:
(10.3)SEE=∑(Y−Y^)2n−(k+1)
Because n observations are used to estimate k + 1 parameters, we have n − (k + 1) degrees of freedom. After choosing a confidence level, such as 95 percent, we use the t distribution with n − (k + 1) degrees of freedom to determine the value t* that corresponds to this probability. The confidence interval for each coefficient is equal to the estimate plus or minus the requisite number of standard errors:
(10.4)a±t*(standard error ofa)bi±t*(standard error ofbi)
For our consumption function, statistical software calculates SEE = 59.193 and these standard errors:
standard error ofa=27.327standard error ofb1=0.019standard error ofb2=0.003
With 49 observations and 2 explanatory variables, we have 49 − (2 + 1) = 46 degrees of freedom. Table A.2 gives t* = 2.013 for a 95 percent confidence interval, so that 95 percent confidence intervals are
α:a±t*(standard error ofa)=−110.126±2.013(27.327)=−110.126±55.010β1:b1±t*(standard error ofb1)=0.798±2.013(0.019)=0.798±0.039β2:b2±t*(standard error ofb2)=0.026±2.013(0.003)=0.026±0.006
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123822215000106
Multiple Regression
Gary Smith, in Essential Statistics, Regression, and Econometrics (Second Edition), 2015
Confidence Intervals for the Coefficients
If the error term is normally distributed and satisfies the four assumptions detailed in the simple regression chapter, the estimators are normally distributed with expected values equal to the parameters they estimate:
a∼N[α,standarddeviationofa]bi∼N[βistandarddeviationofbi]
To compute the standard errors (the estimated standard deviations) of these estimators, we need to use the standard error of estimate (SEE) to estimate the standard deviation of the error term:
(10.5)SEE=∑(y−yˆ)2n−(k+1)
Because n observations are used to estimate k + 1 parameters, we have n − (k + 1) degrees of freedom. After choosing a confidence level, such as 95 percent, we use the t distribution with n − (k + 1) degrees of freedom to determine the value t∗ that corresponds to this probability. The confidence interval for each coefficient is equal to the estimate plus or minus the requisite number of standard errors:
(10.6)a±t∗(standarderrorofa)bi±t∗(standarderrorofbi)
For our consumption function, statistical software calculates SEE = 59.193 and these standard errors:
standarderrorofa=27.327standarderrorofb1=0.019standarderrorofb2=0.003
With 49 observations and two explanatory variables, we have 49 − (2 + 1) = 46 degrees of freedom. Table A.2 gives t∗ = 2.013 for a 95 percent confidence interval, so that 95 percent confidence intervals are:
α:a±t∗(standarderrorofa)=−110.126±2.013(27.327)=−110.126±55.010β1:b1±t∗(standarderrorofb1)=0.798±2.013(0.019)=0.798±0.039β2:b2±t∗(standarderrorofb2)=0.026±2.013(0.003)=0.026±0.006
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128034590000108
Simple Regression
Gary Smith, in Essential Statistics, Regression, and Econometrics (Second Edition), 2015
Abstract
The simple regression model assumes a linear relationship, Y = α + βX + ε, between a dependent variable Y and an explanatory variable X, with the error term ε encompassing omitted factors. The least squares estimates a and b minimize the sum of squared errors when the fitted line is used to predict the observed values of Y. The standard error of estimate (SEE) is our estimate of the standard deviation of the error term. The standard errors of the estimates a and b can be used to construct confidence intervals for α and β and test null hypotheses, most often that the value of β is zero (Y and X are not linearly related). The coefficient of determination R2 compares the model’s sum of the squared prediction errors to the sum of the squared deviations of Y about its mean, and can be interpreted as the fraction of the variation in the dependent variable that is explained by the regression model. The correlation coefficient is equal to the square root of R2.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978012803459000008X
Bootstrap Method
K. Singh, M. Xie, in International Encyclopedia of Education (Third Edition), 2010
Approximating Standard Error of a Sample Estimate
Let us suppose, information is sought about a population parameter θ. Suppose θˆ is a sample estimator of θ based on a random sample of size n, that is, θˆ is a function of the data (X1, X2, …,Xn). In order to estimate standard error of θˆ, as the sample varies over the class of all possible samples, one has the following simple bootstrap approach.
Computeθ1*,θ2*,…,θN*, using the same computing formula as the one used for θˆ, but now base it on N different bootstrap samples (each of size n). A crude recommendation for the size N could be N = n2 (in our judgment), unless n2 is too large. In that case, it could be reduced to an acceptable size, say nlogen. One defines
SEB(θˆ)=[(1/N)∑i=1N(θi*−θˆ)2]1/2
following the philosophy of bootstrap: replace the population by the empirical population.
An older resampling technique used for this purpose is Jackknife, though bootstrap is more widely applicable. The famous example where Jackknife fails while bootstrap is still useful is that of θˆ = the sample median.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780080448947013099
Pearson, Karl
M. Eileen Magnello, in Encyclopedia of Social Measurement, 2005
The Biometric School
Although Pearson’s success in attracting such large audiences in his Gresham lectures may have played a role in encouraging him to further develop his work in biometry, he resigned from the Gresham Lectureship due to his doctor’s recommendation. Following the success of his Gresham lectures, Pearson began to teach statistics to students at UCL in October 1894. Not only did Galton’s work on his law of ancestral heredity enable Pearson to devise the mathematical properties of the product– moment correlation coefficient (which measures the relationship between two continuous variables) and simple regression (used for the linear prediction between two continuous variables) but also Galton’s ideas led to Pearson’s introduction of multiple correlation and part correlation coefficients, multiple regression and the standard error of estimate (for regression), and the coefficient of variation. By then, Galton had determined graphically the idea of correlation and regression for the normal distribution only. Because Galton’s procedure for measuring correlation involved measuring the slope of the regression line (which was a measure of regression instead), Pearson kept Galton’s “r” to symbolize correlation. Pearson later used the letter b (from the equation for a straight line) to symbolize regression. After Weldon had seen a copy of Pearson’s 1896 paper on correlation, he suggested to Pearson that he should extend the range for correlation from 0 to +1 (as used by Galton) so that it would include all values from −1 to +1.
Pearson achieved a mathematical resolution of multiple correlation and multiple regression, adumbrated in Galton’s law of ancestral heredity in 1885, in his seminal paper Regression, Heredity, and Panmixia in 1896, when he introduced matrix algebra into statistical theory. (Arthur Cayley, who taught at Cambridge when Pearson was a student, created matrix algebra by his discovery of the theory of invariants during the mid-19th century.) Pearson’s theory of multiple regression became important to his work on Mendel in 1904 when he advocated a synthesis of Mendelism and biometry. In the same paper, Pearson also introduced the following statistical methods: eta (η) as a measure for a curvilinear relationship, the standard error of estimate, multiple regression, and multiple and part correlation. He also devised the coefficient of variation as a measure of the ratio of a standard deviation to the corresponding mean expressed as a percentage.
By the end of the 19th century, he began to consider the relationship between two discrete variables, and from 1896 to 1911 Pearson devised more than 18 methods of correlation. In 1900, he devised the tetrachoric correlation and the phi coefficient for dichotomous variables. The tetrachoric correlation requires that both X and Y represent continuous, normally distributed, and linearly related variables, whereas the phi coefficient was designed for so-called point distributions, which implies that the two classes have two point values or merely represent some qualitative attribute. Nine years later, he devised the biserial correlation, where one variable is continuous and the other is discontinuous. With his son Egon, he devised the polychoric correlation in 1922 (which is very similar to canonical correlation today). Although not all of Pearson’s correlational methods have survived him, a number of these methods are still the principal tools used by psychometricians for test construction. Following the publication of his first three statistical papers in Philosophical Transactions of the Royal Society, Pearson was elected a fellow of the Royal Society in 1896. He was awarded the Darwin Medal from the Royal Society in 1898.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0123693985002280
Correlation and Regression
Andrew F. Siegel, Michael R. Wagner, in Practical Business Statistics (Eighth Edition), 2022
The Standard Error of Estimate: How Large Are the Prediction Errors?
The standard error of estimate, denoted Se here (but often denoted S in computer printouts), tells you approximately how large the prediction errors (residuals) are for your data set in the same units as Y. How well can you predict Y? The answer is to within about Se above or below.16 Because you usually want your forecasts and predictions to be as accurate as possible, you would be glad to find a small value for Se. You can interpret Se as a standard deviation in the sense that if you have a normal distribution for the prediction errors, then you will expect about two-thirds of the data points to fall within a distance Se either above or below the regression line. Also, about 95% of the data values should fall within 2Se, and so forth. This is illustrated in Fig. 11.2.10 for the production cost example.
Fig. 11.2.10. The standard error of estimate, Se, indicates approximately how much error you make when you use the predicted value for Y (on the least-squares line) instead of the actual value of Y. You may expect about two-thirds of the data points to be within Se above or below the least-squares line for a data set with a normal linear relationship, such as this one.
The standard error of estimate may be found using the following formulas:
Standard Error of Estimate
Se=SY(1−r2)n−1n−2(forcomputation)=1n−2∑i=1n[Yi−(a+bXi)]2(forinterpretation)
The first formula shows how Se is computed by reducing SY according to the correlation and sample size. Indeed, Se will usually be smaller than SY because the line a + bX summarizes the relationship and therefore comes closer to the Y values than does the simpler summary, Y¯. The second formula shows how Se can be interpreted as the estimated standard deviation of the residuals: The squared prediction errors are averaged by dividing by n − 2 (the appropriate number of degrees of freedom when two numbers, a and b, have been estimated), and the square root undoes the earlier squaring, giving you an answer in the same measurement units as Y.
For the production cost data, the correlation was found to be r = 0.869193, the variability in the individual cost numbers is SY = $389.6131, and the sample size is n = 18. The standard error of estimate is therefore
Se=SY(1−r2)n−1n−2=389.6131(1−0.8691932)18−118−2=389.6131(0.0244503)1716=389.61310.259785=$198.58
This tells you that, for a typical week, the actual cost was different from the predicted cost (on the least-squares line) by about $198.58. Although the least-squares prediction line takes full advantage of the relationship between cost and number produced, the predictions are far from perfect.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128200254000117
Detection of a Trend in Population Estimates
William L. Thompson, … Charles Gowan, in Monitoring Vertebrate Populations, 1998
5.2 VARIANCE COMPONENTS
In this section, we discuss sources of variation that must be considered to make inferences from data when trying to detect trends. Three sources of variation must be considered: sampling variation, temporal variation in the population dynamics process, and spatial variation in the dynamics of the population across space. The latter two sources often are referred to as process variation, i.e., variation in the population dynamics process associated with environmental variation (such as rainfall, temperature, community succession, fires, or elevation). Methods to separate process variation from sampling variation will be presented.
Detection of a trend in a population’s size requires at least two abundance estimates. For example, if the population size of Mexican spotted owls in Mesa Verde National Park is determined as 50 pairs in 1990, and as only 10 pairs in 1995, we would be concerned that a significant negative trend in the population exists during this time period, and that action must be taken to alleviate the trend. However, if the 1995 estimate was 40 pairs, we might still be concerned, but would be less confident that immediate action is required. Two sources of variation must be assessed before we are confident of our inference from these estimates.
The first source of variation is the uncertainty we have in our population estimates. We want to be sure that the two estimates are different, i.e., the difference between the two estimates is greater than would be expected from chance alone because of the sampling errors associated with each estimate. Typically, we present our uncertainty in our estimate as its variance, and use this variance to generate a confidence interval for our estimate. Suppose that the 1990 estimate of Nˆ90 = 50 pairs has a sampling variance of Vaˆr(Nˆ90)=25. Then, under the assumption of the estimate being normally distributed with a large sample size (i.e., large degrees of freedom), we would compute a 95% confidence interval as 50 ± 1.96 25, or 40.2–59.8. If the 1995 estimate was Nˆ95 = 40 with a sampling variance of Vâr(Nˆ95) = 20, then the 95% confidence interval for this estimate is 40 ± 1.96 20, or 31.2–48.8. Based on the overlap of the two confidence intervals (Fig. 5.2), we would conclude that by chance alone, these two estimates are probably not different. We also could compute a simple test as
Figure 5.2. The 95% confidence intervals plotted with the 1990 and 1995 population estimates.
(5.3)z=Nˆ90−Nˆ95Vaˆr(Nˆ90)+Vaˆr(Nˆ95),
which for this example results in z = 1.491, with a probability of observing a z statistic this large or larger of P = 0.136. Although we might be alarmed, the chances are that 13.6 times out of 100 we would observe this large of a change just by random chance.
A variation of the previous test is commonly conducted for several reasons: (1) we often are interested in the ratio of two population estimates (rather than the difference) because a ratio represents the rate of change of the population, (2) the variance of Nˆ is usually linked to its estimate by Vaˆr(Nˆ)=NˆC (e.g., Skalski and Robson, 1992, pp. 28–29), and (3) ln(Nˆ) is more likely to be normally distributed than Nˆ. Fortuitously, a log transformation provides some correction to all three of the above reasons and results in a more efficient statistical procedure. Because
(5.4)Var[ln(Nˆ)]=Var(Nˆ)Nˆ2,
we construct the z test as
(5.5)z=ln(Nˆ90)−ln(Nˆ95)Vaˆr[ln(Nˆ90)]+Vaˆr[ln(Nˆ95)]
to provide a more efficient (i.e., more powerful) test.
Suppose we had made a much more intensive effort in sampling the owl population, so that the sampling variances were one-half of the values observed (which would generally take about 4 times the effort). Thus, Vâr(Nˆ90) = 12.5 and Vâr(Nˆ95) = 10, giving a z statistic of 2.108 with probability value of P = 0.035. Now, we would conclude that the owl population was lower in 1995 than in 1990, and that this difference is unlikely due to variation in our samples, i.e., that an actual reduction in population size has taken place.
This leads us to the second variance component associated with determining whether a trend in the population is important. We would expect the size of the owl population (and any other population, for that matter) to fluctuate through time. How can we determine if this reduction is important? The answer lies in determining what the variation in the owl population has been for some period of time in the past, and then if the observed reduction is outside the range expected from this past fluctuation. Consider the example in Fig. 5.3, where the true population size (no sampling variation) is plotted. The population fluctuates around a mean of 50, but values more extreme than the range 40 to 60 are common. Note that a decline from 76 to 29 pairs occurred from 1984 to 1985, and that declines from over 50 pairs to under 40 pairs are fairly common occurrences. Thus, based on our previous example, a decline from 50 to 40 is not at all unreasonable given the past population dynamics of this hypothetical population.
Figure 5.3. Actual number of pairs of owls that exist each year. In reality, we never know these values, and can only estimate them.
To determine the level of change in population size that should receive our attention and suggest management action, we need to know something about the temporal variation in the population. The only way to estimate this variance component is to observe the population across a number of years. The exact number of years will depend on the magnitude of the temporal variation. Thus, if the population does not change much from year to year, a few observations will show this consistency. On the other hand, if the population fluctuates a lot, as in Fig. 5.3, many years of observations are needed to estimate the temporal variance. For the example in Fig. 5.3, we could compute the temporal variance as the variance of the 15 years. We find a variance of 265.7, or a standard deviation of 16.3 (Example 5.1). With a SD of 16.3, we would expect roughly 95% of the population values to be in the range of ±2 SD of the mean population size. This inference is based on the population being stable, i.e., not having an upward or downward trend, and being roughly normally distributed. For a normal distribution, 95% of the values lie in the interval ±2 SD of the mean. Therefore, a change of 2 SD, or 32.6, is not a particularly big change given the temporal variation observed over the 15-year period. Such a change should occur with probability greater than 1/20, or 0.05.
A complicating problem with estimating the temporal variance of a population’s size is that we are seldom allowed to observe the true value of the population size. Rather, we are required to sample the population, and hence only obtain an estimate of the population size each year, with its associated sampling variance. Thus, we would need to include the 95% confidence bars on the annual estimates. As a result of this uncertainty from our sampling procedure, we would conclude that many of the year-to-year changes were not really changes because the estimates were not different. This complication leads to a further problem. If we compute the variance with the usual formula when estimates of population size replace the actual population size shown in Fig. 5.3, we obtain a variance estimate larger than the true temporal variance because our sampling uncertainty is included in the variance. For low levels of sampling effort each year, we would have a high sampling variance associated with each estimate, and as a result, we would have a high variance across years. The noise associated with our low sampling intensity would suggest that the population is fluctuating widely, when in fact the population could be constant (i.e., temporal variance is zero), and the estimated changes in the population are just due to sampling variance.
This mixture of sampling and temporal variation becomes particularly important in population viability analysis (PVA). The objective of a PVA is to estimate the probability of extinction for a population, given current size, and some idea of the variation in the population dynamics (i.e., temporal variation). If our estimate of temporal variation includes sampling variation, and the level of effort to obtain the estimates is relatively low, the high sampling variation causes our naive estimate of temporal variation to be much too large. When we apply our PVA analysis with this inflated estimate of temporal variance, we conclude that the population is much more likely to go extinct than it really is, and hence the importance of separating sampling variation from process variation.
Typically, we estimate variance components with analysis of variance (ANOVA) procedures. For the example considered here, we would have to have at least two estimates of population size for a series of years to obtain valid estimates of sampling and temporal variation. Further, typical ANOVA techniques assume that the sampling variation is constant, and so do not account for differences in levels of effort, or the fact that sampling variance is usually a function of population size. For our example, we have an estimate of sampling variance for each of our estimates, obtained from the population estimation methods considered in this manual. That is, capture–recapture, mark–resight, line transects, removal methods, and quadrat counts all produce estimates of sampling variation. Thus, we do not want to estimate sampling variation by obtaining replicate estimates, but want to use the available estimate. Therefore, we present a method of moments estimator developed in Burnham et al. (1987, Part 5). Skalski and Robson (1992, Chapter 2) also present a similar procedure, but do not develop the weighted estimator presented here.
Example 5.1 Population Size, Estimates, Standard Error of the Estimates, and Confidence Intervals for Owl Pairs in Fig. 5.3
| Standard | |||||
|---|---|---|---|---|---|
| Year | Population | Estimate | error | Lower 95% CI | Upper 95% CI |
| 1980 | 44 | 40.04 | 5.926 | 28.42 | 51.66 |
| 1981 | 48 | 50.51 | 11.004 | 28.94 | 72.08 |
| 1982 | 61 | 61.36 | 15.278 | 31.42 | 91.31 |
| 1983 | 48 | 47.6 | 11.062 | 25.92 | 69.28 |
| 1984 | 76 | 95.51 | 18.988 | 58.3 | 132.72 |
| 1985 | 29 | 33.81 | 8.803 | 16.56 | 51.06 |
| 1986 | 60 | 34.39 | 5.804 | 23.01 | 45.76 |
| 1987 | 59 | 38.52 | 11.168 | 16.63 | 60.41 |
| 1988 | 76 | 84.57 | 21.312 | 42.8 | 126.34 |
| 1989 | 42 | 30.04 | 6.918 | 16.48 | 43.6 |
| 1990 | 29 | 20.29 | 7.529 | 5.54 | 35.05 |
| 1991 | 68 | 68.42 | 17.969 | 33.2 | 103.64 |
| 1992 | 42 | 45.51 | 13.225 | 19.6 | 71.44 |
| 1993 | 27 | 27.01 | 6.137 | 14.98 | 39.04 |
| 1994 | 72 | 71.12 | 14.511 | 42.67 | 99.56 |
| 1995 | 54 | 51.45 | 8.054 | 35.66 | 67.24 |
The variance of the n = 16 populations is 265.628, whereas the variance of the 16 estimates is 450.376. Sampling variation causes the estimates to have a larger variance than the actual population. The difference of these two variances is an estimate of the sampling variation, i.e., 450.376 – 265.628 = 184.748. The square root of 184.748 is 13.592, and is the approximate mean of the 16 reported standard errors.
To obtain an unbiased estimate of the temporal variance, we must remove the sampling variation from the estimate of the total variance. Define σtotal2 as the total variance, estimated for n = 16 estimates of owl pairs (Nˆi, i = 1980, …, 1995) as
(5.6)σˆtotal2=Σi=19801995(Nˆi−N¯)2(n−1)=Σi=19801995Nˆi2(Σi−19801985Nˆi)2n(n−1),
where the symbol indicates the estimate of the parameter. Thus, Nˆi are the estimates of the actual populations, Ni, and σˆtotal2 is an estimate of the total variance σˆi2 For each estimate, Nˆi, we also have an associated sampling variance, σˆi2. Then, a simple estimator of the temporal variance, σ2time, is given by
(5.7)σˆtime2=σˆtotal2−Σi=19801995σˆi2n,
when we can assume that all of the sampling variances, σˆi2, are equal. The above equation corresponds to Eq. (2.6) of Skalski and Robson (1992). When the σˆi2 cannot all be assumed to be equal, a more complex calculation is required (Burnham et al., 1987, Section 4.3) because each estimate must be weighted by its sampling variance. We take as the weight of each estimate the reciprocal of the sum of temporal variance plus the sampling variance, 1/(σˆtime2+σˆi2). That is, Var(Nˆi)=σˆtime2+σˆi2, so wi=1/Var(Nˆi)=1/(σˆtime2+σˆi2). Then, the weighted total variance is computed as
(5.8)σˆtotal2=Σi=19801995wi(Nˆi−N¯)2(n−1)Σi=19801995wi
with the mean of the estimates now computed as a weighted mean,
(5.9)N¯=Σi=19801995wiNˆiΣi=19801995wi.
We now know that the theoretical variance N¯ is
(5.10)Var(N¯)=Var(Σi=19801995wiNˆiΣi=19801995wi)=1Σi=19801995wi
and the empirical variance estimator is Eq. (5.8). Setting these two equations equal,
(5.11)1Σi=19801995wi=Σi=19801995wi(Nˆi−N¯)2(n−1)Σi=19801995wi
or
(5.12)1=Σi=19801995wi(Nˆi−N¯)2(n−1).
Because we cannot solve for σˆtime2 directly, we have to use an iterative numerical approach to estimate σˆtime2 This procedure involves substituting values of σˆtime2 into Eq. (5.12) via the wi until the two sides are equal. When both sides are the same, we have our estimate of σˆtime2. Using this estimate of σˆtime2, we can now decide what level of change in Nˆi to Nˆi+1 is important and deserves attention. If the change from a series of estimates is greater than 2σˆtime2, we may want to take action.
Typically, we do not have the luxury of enough background data to estimate σˆtime2, so we end up trying to evaluate whether a series of estimated population sizes is in fact signaling a decline in the population when both sampling and process variance are present. Note that just because we see a decline of the estimates for 3–4 consecutive years, we cannot be sure that the population is actually in a serious decline without knowledge of the mean population size and the temporal variation prior to the decline. Usually, however, we do not have good knowledge of the population size prior to some observed decline, and make a decision to act based on biological perceptions. Keep in mind the kinds of trends displayed in Fig. 5.1. Is the suggested trend part of a cycle, or are we observing a real change in population size? In this discussion, we have only considered temporal variation. A similar procedure can be used to separate spatial variation from sampling variation.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780126889604500058
Multiple Regression
Andrew F. Siegel, Michael R. Wagner, in Practical Business Statistics (Eighth Edition), 2022
Typical Prediction Error: Standard Error of Estimate
Just as for simple regression, with only one X, the standard error of estimate indicates the approximate size of the prediction errors. For the magazine ads example, Se = $106,072. This tells you that actual page costs for these magazines are typically within about $106,072 from the predicted page costs, in the sense of a standard deviation. That is, if the error distribution is normal, then you would expect about two-thirds of the actual page costs to be within Se of the predicted page costs, about 95% to be within 2Se, and so forth.
The standard error of estimate, Se = $106,072, indicates the remaining variation in page costs after you have used the X variables (audience, percent male, and median income) in the regression equation to predict page costs for each magazine. Compare this to the ordinary univariate standard deviation, SY = $163,549, for the page costs, computed by ignoring all the other variables. This standard deviation, SY, indicates the remaining variation in page costs after you have used only Y¯ to predict the page costs for each magazine. Note that Se = $106,072 is smaller than SY = $163,549; your errors are typically smaller if you use the regression equation instead of just Y¯ to predict page costs. This suggests that the X variables are helpful in explaining page costs.
Think of the situation this way. If you knew nothing of the X variables, you would use the average page costs (Y¯=$187,628) as your best guess, and you would be wrong by about SY = $163,549. But if you knew the audience, percent male readership, and median reader income, you could use the regression equation to find a prediction for page costs that would be wrong by only Se = $106,072. This reduction in prediction error (from $163,549 to $106,072) is one of the helpful payoffs from running a regression analysis.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128200254000129
Multiple Regression
Gary Smith, in Essential Statistics, Regression, and Econometrics, 2012
Confidence Intervals for the Coefficients
If the error term is normally distributed and satisfies the four assumptions detailed in the simple regression chapter, the estimators are normally distributed with expected values equal to the parameters they estimate:
a∼N[α, standard deviation of a]bi∼N[βi, standard deviation of bi]
To compute the standard errors (the estimated standard deviations) of these estimators, we need to use the standard error of estimate (SEE) to estimate the standard deviation of the error term:
(10.3)SEE=∑(Y−Y^)2n−(k+1)
Because n observations are used to estimate k + 1 parameters, we have n − (k + 1) degrees of freedom. After choosing a confidence level, such as 95 percent, we use the t distribution with n − (k + 1) degrees of freedom to determine the value t* that corresponds to this probability. The confidence interval for each coefficient is equal to the estimate plus or minus the requisite number of standard errors:
(10.4)a±t*(standard error ofa)bi±t*(standard error ofbi)
For our consumption function, statistical software calculates SEE = 59.193 and these standard errors:
standard error ofa=27.327standard error ofb1=0.019standard error ofb2=0.003
With 49 observations and 2 explanatory variables, we have 49 − (2 + 1) = 46 degrees of freedom. Table A.2 gives t* = 2.013 for a 95 percent confidence interval, so that 95 percent confidence intervals are
α:a±t*(standard error ofa)=−110.126±2.013(27.327)=−110.126±55.010β1:b1±t*(standard error ofb1)=0.798±2.013(0.019)=0.798±0.039β2:b2±t*(standard error ofb2)=0.026±2.013(0.003)=0.026±0.006
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123822215000106
Multiple Regression
Gary Smith, in Essential Statistics, Regression, and Econometrics (Second Edition), 2015
Confidence Intervals for the Coefficients
If the error term is normally distributed and satisfies the four assumptions detailed in the simple regression chapter, the estimators are normally distributed with expected values equal to the parameters they estimate:
a∼N[α,standarddeviationofa]bi∼N[βistandarddeviationofbi]
To compute the standard errors (the estimated standard deviations) of these estimators, we need to use the standard error of estimate (SEE) to estimate the standard deviation of the error term:
(10.5)SEE=∑(y−yˆ)2n−(k+1)
Because n observations are used to estimate k + 1 parameters, we have n − (k + 1) degrees of freedom. After choosing a confidence level, such as 95 percent, we use the t distribution with n − (k + 1) degrees of freedom to determine the value t∗ that corresponds to this probability. The confidence interval for each coefficient is equal to the estimate plus or minus the requisite number of standard errors:
(10.6)a±t∗(standarderrorofa)bi±t∗(standarderrorofbi)
For our consumption function, statistical software calculates SEE = 59.193 and these standard errors:
standarderrorofa=27.327standarderrorofb1=0.019standarderrorofb2=0.003
With 49 observations and two explanatory variables, we have 49 − (2 + 1) = 46 degrees of freedom. Table A.2 gives t∗ = 2.013 for a 95 percent confidence interval, so that 95 percent confidence intervals are:
α:a±t∗(standarderrorofa)=−110.126±2.013(27.327)=−110.126±55.010β1:b1±t∗(standarderrorofb1)=0.798±2.013(0.019)=0.798±0.039β2:b2±t∗(standarderrorofb2)=0.026±2.013(0.003)=0.026±0.006
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128034590000108
Simple Regression
Gary Smith, in Essential Statistics, Regression, and Econometrics (Second Edition), 2015
Abstract
The simple regression model assumes a linear relationship, Y = α + βX + ε, between a dependent variable Y and an explanatory variable X, with the error term ε encompassing omitted factors. The least squares estimates a and b minimize the sum of squared errors when the fitted line is used to predict the observed values of Y. The standard error of estimate (SEE) is our estimate of the standard deviation of the error term. The standard errors of the estimates a and b can be used to construct confidence intervals for α and β and test null hypotheses, most often that the value of β is zero (Y and X are not linearly related). The coefficient of determination R2 compares the model’s sum of the squared prediction errors to the sum of the squared deviations of Y about its mean, and can be interpreted as the fraction of the variation in the dependent variable that is explained by the regression model. The correlation coefficient is equal to the square root of R2.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978012803459000008X
Bootstrap Method
K. Singh, M. Xie, in International Encyclopedia of Education (Third Edition), 2010
Approximating Standard Error of a Sample Estimate
Let us suppose, information is sought about a population parameter θ. Suppose θˆ is a sample estimator of θ based on a random sample of size n, that is, θˆ is a function of the data (X1, X2, …,Xn). In order to estimate standard error of θˆ, as the sample varies over the class of all possible samples, one has the following simple bootstrap approach.
Computeθ1*,θ2*,…,θN*, using the same computing formula as the one used for θˆ, but now base it on N different bootstrap samples (each of size n). A crude recommendation for the size N could be N = n2 (in our judgment), unless n2 is too large. In that case, it could be reduced to an acceptable size, say nlogen. One defines
SEB(θˆ)=[(1/N)∑i=1N(θi*−θˆ)2]1/2
following the philosophy of bootstrap: replace the population by the empirical population.
An older resampling technique used for this purpose is Jackknife, though bootstrap is more widely applicable. The famous example where Jackknife fails while bootstrap is still useful is that of θˆ = the sample median.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780080448947013099
Pearson, Karl
M. Eileen Magnello, in Encyclopedia of Social Measurement, 2005
The Biometric School
Although Pearson’s success in attracting such large audiences in his Gresham lectures may have played a role in encouraging him to further develop his work in biometry, he resigned from the Gresham Lectureship due to his doctor’s recommendation. Following the success of his Gresham lectures, Pearson began to teach statistics to students at UCL in October 1894. Not only did Galton’s work on his law of ancestral heredity enable Pearson to devise the mathematical properties of the product– moment correlation coefficient (which measures the relationship between two continuous variables) and simple regression (used for the linear prediction between two continuous variables) but also Galton’s ideas led to Pearson’s introduction of multiple correlation and part correlation coefficients, multiple regression and the standard error of estimate (for regression), and the coefficient of variation. By then, Galton had determined graphically the idea of correlation and regression for the normal distribution only. Because Galton’s procedure for measuring correlation involved measuring the slope of the regression line (which was a measure of regression instead), Pearson kept Galton’s “r” to symbolize correlation. Pearson later used the letter b (from the equation for a straight line) to symbolize regression. After Weldon had seen a copy of Pearson’s 1896 paper on correlation, he suggested to Pearson that he should extend the range for correlation from 0 to +1 (as used by Galton) so that it would include all values from −1 to +1.
Pearson achieved a mathematical resolution of multiple correlation and multiple regression, adumbrated in Galton’s law of ancestral heredity in 1885, in his seminal paper Regression, Heredity, and Panmixia in 1896, when he introduced matrix algebra into statistical theory. (Arthur Cayley, who taught at Cambridge when Pearson was a student, created matrix algebra by his discovery of the theory of invariants during the mid-19th century.) Pearson’s theory of multiple regression became important to his work on Mendel in 1904 when he advocated a synthesis of Mendelism and biometry. In the same paper, Pearson also introduced the following statistical methods: eta (η) as a measure for a curvilinear relationship, the standard error of estimate, multiple regression, and multiple and part correlation. He also devised the coefficient of variation as a measure of the ratio of a standard deviation to the corresponding mean expressed as a percentage.
By the end of the 19th century, he began to consider the relationship between two discrete variables, and from 1896 to 1911 Pearson devised more than 18 methods of correlation. In 1900, he devised the tetrachoric correlation and the phi coefficient for dichotomous variables. The tetrachoric correlation requires that both X and Y represent continuous, normally distributed, and linearly related variables, whereas the phi coefficient was designed for so-called point distributions, which implies that the two classes have two point values or merely represent some qualitative attribute. Nine years later, he devised the biserial correlation, where one variable is continuous and the other is discontinuous. With his son Egon, he devised the polychoric correlation in 1922 (which is very similar to canonical correlation today). Although not all of Pearson’s correlational methods have survived him, a number of these methods are still the principal tools used by psychometricians for test construction. Following the publication of his first three statistical papers in Philosophical Transactions of the Royal Society, Pearson was elected a fellow of the Royal Society in 1896. He was awarded the Darwin Medal from the Royal Society in 1898.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0123693985002280
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.