From Wikipedia, the free encyclopedia
In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement. MAE is calculated as the sum of absolute errors divided by the sample size:[1]

It is thus an arithmetic average of the absolute errors  , where
, where  is the prediction and
is the prediction and  the true value. Note that alternative formulations may include relative frequencies as weight factors. The mean absolute error uses the same scale as the data being measured. This is known as a scale-dependent accuracy measure and therefore cannot be used to make comparisons between series using different scales.[2] The mean absolute error is a common measure of forecast error in time series analysis,[3] sometimes used in confusion with the more standard definition of mean absolute deviation. The same confusion exists more generally.
the true value. Note that alternative formulations may include relative frequencies as weight factors. The mean absolute error uses the same scale as the data being measured. This is known as a scale-dependent accuracy measure and therefore cannot be used to make comparisons between series using different scales.[2] The mean absolute error is a common measure of forecast error in time series analysis,[3] sometimes used in confusion with the more standard definition of mean absolute deviation. The same confusion exists more generally.
Quantity disagreement and allocation disagreement[edit]
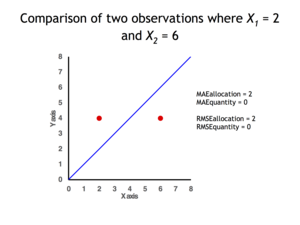
2 data points for which Quantity Disagreement is 0 and Allocation Disagreement is 2 for both MAE and RMSE
It is possible to express MAE as the sum of two components: Quantity Disagreement and Allocation Disagreement. Quantity Disagreement is the absolute value of the Mean Error given by:[4]

Allocation Disagreement is MAE minus Quantity Disagreement.
It is also possible to identify the types of difference by looking at an  plot. Quantity difference exists when the average of the X values does not equal the average of the Y values. Allocation difference exists if and only if points reside on both sides of the identity line.[4][5]
plot. Quantity difference exists when the average of the X values does not equal the average of the Y values. Allocation difference exists if and only if points reside on both sides of the identity line.[4][5]
[edit]
The mean absolute error is one of a number of ways of comparing forecasts with their eventual outcomes. Well-established alternatives are the mean absolute scaled error (MASE) and the mean squared error. These all summarize performance in ways that disregard the direction of over- or under- prediction; a measure that does place emphasis on this is the mean signed difference.
Where a prediction model is to be fitted using a selected performance measure, in the sense that the least squares approach is related to the mean squared error, the equivalent for mean absolute error is least absolute deviations.
MAE is not identical to root-mean square error (RMSE), although some researchers report and interpret it that way. MAE is conceptually simpler and also easier to interpret than RMSE: it is simply the average absolute vertical or horizontal distance between each point in a scatter plot and the Y=X line. In other words, MAE is the average absolute difference between X and Y. Furthermore, each error contributes to MAE in proportion to the absolute value of the error. This is in contrast to RMSE which involves squaring the differences, so that a few large differences will increase the RMSE to a greater degree than the MAE.[4] See the example above for an illustration of these differences.
Optimality property[edit]
The mean absolute error of a real variable c with respect to the random variable X is

Provided that the probability distribution of X is such that the above expectation exists, then m is a median of X if and only if m is a minimizer of the mean absolute error with respect to X.[6] In particular, m is a sample median if and only if m minimizes the arithmetic mean of the absolute deviations.[7]
More generally, a median is defined as a minimum of

as discussed at Multivariate median (and specifically at Spatial median).
This optimization-based definition of the median is useful in statistical data-analysis, for example, in k-medians clustering.
Proof of optimality[edit]
Statement: The classifier minimising  is
is  .
.
Proof:
The Loss functions for classification is
![{displaystyle {begin{aligned}L&=mathbb {E} [|y-a||X=x]\&=int _{-infty }^{infty }|y-a|f_{Y|X}(y),dy\&=int _{-infty }^{a}(a-y)f_{Y|X}(y),dy+int _{a}^{infty }(y-a)f_{Y|X}(y),dy\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e953e54457072620a7c2764db0801f69c4e883d)
Differentiating with respect to a gives

This means

Hence

See also[edit]
- Least absolute deviations
- Mean absolute percentage error
- Mean percentage error
- Symmetric mean absolute percentage error
References[edit]
- ^ Willmott, Cort J.; Matsuura, Kenji (December 19, 2005). «Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance». Climate Research. 30: 79–82. doi:10.3354/cr030079.
- ^ «2.5 Evaluating forecast accuracy | OTexts». www.otexts.org. Retrieved 2016-05-18.
- ^ Hyndman, R. and Koehler A. (2005). «Another look at measures of forecast accuracy» [1]
- ^ a b c Pontius Jr., Robert Gilmore; Thontteh, Olufunmilayo; Chen, Hao (2008). «Components of information for multiple resolution comparison between maps that share a real variable». Environmental and Ecological Statistics. 15 (2): 111–142. doi:10.1007/s10651-007-0043-y. S2CID 21427573.
- ^ Willmott, C. J.; Matsuura, K. (January 2006). «On the use of dimensioned measures of error to evaluate the performance of spatial interpolators». International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976. S2CID 15407960.
- ^ Stroock, Daniel (2011). Probability Theory. Cambridge University Press. pp. 43. ISBN 978-0-521-13250-3.
- ^ Nicolas, André (2012-02-25). «The Median Minimizes the Sum of Absolute Deviations (The $ {L}_{1} $ Norm)». StackExchange.
From Wikipedia, the free encyclopedia
In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement. MAE is calculated as the sum of absolute errors divided by the sample size:[1]
It is thus an arithmetic average of the absolute errors , where is the prediction and the true value. Note that alternative formulations may include relative frequencies as weight factors. The mean absolute error uses the same scale as the data being measured. This is known as a scale-dependent accuracy measure and therefore cannot be used to make comparisons between series using different scales.[2] The mean absolute error is a common measure of forecast error in time series analysis,[3] sometimes used in confusion with the more standard definition of mean absolute deviation. The same confusion exists more generally.
Quantity disagreement and allocation disagreement[edit]
2 data points for which Quantity Disagreement is 0 and Allocation Disagreement is 2 for both MAE and RMSE
It is possible to express MAE as the sum of two components: Quantity Disagreement and Allocation Disagreement. Quantity Disagreement is the absolute value of the Mean Error given by:[4]
Allocation Disagreement is MAE minus Quantity Disagreement.
It is also possible to identify the types of difference by looking at an plot. Quantity difference exists when the average of the X values does not equal the average of the Y values. Allocation difference exists if and only if points reside on both sides of the identity line.[4][5]
[edit]
The mean absolute error is one of a number of ways of comparing forecasts with their eventual outcomes. Well-established alternatives are the mean absolute scaled error (MASE) and the mean squared error. These all summarize performance in ways that disregard the direction of over- or under- prediction; a measure that does place emphasis on this is the mean signed difference.
Where a prediction model is to be fitted using a selected performance measure, in the sense that the least squares approach is related to the mean squared error, the equivalent for mean absolute error is least absolute deviations.
MAE is not identical to root-mean square error (RMSE), although some researchers report and interpret it that way. MAE is conceptually simpler and also easier to interpret than RMSE: it is simply the average absolute vertical or horizontal distance between each point in a scatter plot and the Y=X line. In other words, MAE is the average absolute difference between X and Y. Furthermore, each error contributes to MAE in proportion to the absolute value of the error. This is in contrast to RMSE which involves squaring the differences, so that a few large differences will increase the RMSE to a greater degree than the MAE.[4] See the example above for an illustration of these differences.
Optimality property[edit]
The mean absolute error of a real variable c with respect to the random variable X is
Provided that the probability distribution of X is such that the above expectation exists, then m is a median of X if and only if m is a minimizer of the mean absolute error with respect to X.[6] In particular, m is a sample median if and only if m minimizes the arithmetic mean of the absolute deviations.[7]
More generally, a median is defined as a minimum of
as discussed at Multivariate median (and specifically at Spatial median).
This optimization-based definition of the median is useful in statistical data-analysis, for example, in k-medians clustering.
Proof of optimality[edit]
Statement: The classifier minimising is .
Proof:
The Loss functions for classification is
Differentiating with respect to a gives
This means
Hence
See also[edit]
- Least absolute deviations
- Mean absolute percentage error
- Mean percentage error
- Symmetric mean absolute percentage error
References[edit]
- ^ Willmott, Cort J.; Matsuura, Kenji (December 19, 2005). «Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance». Climate Research. 30: 79–82. doi:10.3354/cr030079.
- ^ «2.5 Evaluating forecast accuracy | OTexts». www.otexts.org. Retrieved 2016-05-18.
- ^ Hyndman, R. and Koehler A. (2005). «Another look at measures of forecast accuracy» [1]
- ^ a b c Pontius Jr., Robert Gilmore; Thontteh, Olufunmilayo; Chen, Hao (2008). «Components of information for multiple resolution comparison between maps that share a real variable». Environmental and Ecological Statistics. 15 (2): 111–142. doi:10.1007/s10651-007-0043-y. S2CID 21427573.
- ^ Willmott, C. J.; Matsuura, K. (January 2006). «On the use of dimensioned measures of error to evaluate the performance of spatial interpolators». International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976. S2CID 15407960.
- ^ Stroock, Daniel (2011). Probability Theory. Cambridge University Press. pp. 43. ISBN 978-0-521-13250-3.
- ^ Nicolas, André (2012-02-25). «The Median Minimizes the Sum of Absolute Deviations (The $ {L}_{1} $ Norm)». StackExchange.
Перевод
Ссылка на автора
Каждая модель машинного обучения пытается решить проблему с другой целью, используя свой набор данных, и, следовательно, важно понять контекст, прежде чем выбрать метрику. Обычно ответы на следующий вопрос помогают нам выбрать подходящий показатель:
- Тип задачи: регрессия? Классификация?
- Бизнес цель?
- Каково распределение целевой переменной?
Ну, в этом посте я буду обсуждать полезность каждой метрики ошибки в зависимости от цели и проблемы, которую мы пытаемся решить. Часть 1 фокусируется только на показателях оценки регрессии.

Метрики регрессии
- Средняя квадратическая ошибка (MSE)
- Среднеквадратическая ошибка (RMSE)
- Средняя абсолютная ошибка (MAE)
- R в квадрате (R²)
- Скорректированный R квадрат (R²)
- Среднеквадратичная ошибка в процентах (MSPE)
- Средняя абсолютная ошибка в процентах (MAPE)
- Среднеквадратичная логарифмическая ошибка (RMSLE)
Средняя квадратическая ошибка (MSE)
Это, пожалуй, самый простой и распространенный показатель для оценки регрессии, но, вероятно, наименее полезный. Определяется уравнением

гдеyᵢфактический ожидаемый результат иŷᵢэто прогноз модели.
MSE в основном измеряет среднеквадратичную ошибку наших прогнозов. Для каждой точки вычисляется квадратная разница между прогнозами и целью, а затем усредняются эти значения.
Чем выше это значение, тем хуже модель. Он никогда не бывает отрицательным, поскольку мы возводим в квадрат отдельные ошибки прогнозирования, прежде чем их суммировать, но для идеальной модели это будет ноль.
Преимущество:Полезно, если у нас есть неожиданные значения, о которых мы должны заботиться. Очень высокое или низкое значение, на которое мы должны обратить внимание.
Недостаток:Если мы сделаем один очень плохой прогноз, возведение в квадрат сделает ошибку еще хуже, и это может исказить метрику в сторону переоценки плохости модели. Это особенно проблематичное поведение, если у нас есть зашумленные данные (то есть данные, которые по какой-либо причине не совсем надежны) — даже в «идеальной» модели может быть высокий MSE в этой ситуации, поэтому становится трудно судить, насколько хорошо модель выполняет. С другой стороны, если все ошибки малы или, скорее, меньше 1, то ощущается противоположный эффект: мы можем недооценивать недостатки модели.
Обратите внимание, чтоесли мы хотим иметь постоянный прогноз, лучшим будетсреднее значение целевых значений.Его можно найти, установив производную нашей полной ошибки по этой константе в ноль, и найти ее из этого уравнения.
Среднеквадратическая ошибка (RMSE)
RMSE — это просто квадратный корень из MSE. Квадратный корень введен, чтобы масштаб ошибок был таким же, как масштаб целей.

Теперь очень важно понять, в каком смысле RMSE похож на MSE, и в чем разница.
Во-первых, они похожи с точки зрения их минимизаторов, каждый минимизатор MSE также является минимизатором для RMSE и наоборот, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора предсказаний, A и B, и скажем, что MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. И это также работает в противоположном направлении. ,

Что это значит для нас?
Это означает, что, если целевым показателем является RMSE, мы все равно можем сравнивать наши модели, используя MSE, поскольку MSE упорядочит модели так же, как RMSE. Таким образом, мы можем оптимизировать MSE вместо RMSE.
На самом деле, с MSE работать немного проще, поэтому все используют MSE вместо RMSE. Также есть небольшая разница между этими двумя моделями на основе градиента.

Это означает, что путешествие по градиенту MSE эквивалентно путешествию по градиенту RMSE, но с другой скоростью потока, и скорость потока зависит от самой оценки MSE.
Таким образом, хотя RMSE и MSE действительно схожи с точки зрения оценки моделей, они не могут быть сразу взаимозаменяемыми для методов на основе градиента. Возможно, нам нужно будет настроить некоторые параметры, такие как скорость обучения.
Средняя абсолютная ошибка (MAE)
В MAE ошибка рассчитывается как среднее абсолютных разностей между целевыми значениями и прогнозами. MAE — это линейная оценка, которая означает, чтовсе индивидуальные различия взвешены одинаковов среднем. Например, разница между 10 и 0 будет вдвое больше разницы между 5 и 0. Однако то же самое не верно для RMSE. Математически он рассчитывается по следующей формуле:

Что важно в этой метрике, так это то, что онанаказывает огромные ошибки, которые не так плохо, как MSE.Таким образом, он не так чувствителен к выбросам, как среднеквадратическая ошибка.
MAE широко используется в финансах, где ошибка в 10 долларов обычно в два раза хуже, чем ошибка в 5 долларов. С другой стороны, метрика MSE считает, что ошибка в 10 долларов в четыре раза хуже, чем ошибка в 5 долларов. MAE легче обосновать, чем RMSE.
Еще одна важная вещь в MAE — это его градиенты относительно прогнозов. Gradiend — это пошаговая функция, которая принимает -1, когда Y_hat меньше цели, и +1, когда она больше.
Теперь градиент не определен, когда предсказание является совершенным, потому что, когда Y_hat равен Y, мы не можем оценить градиент. Это не определено.

Таким образом, формально, MAE не дифференцируемо, но на самом деле, как часто ваши прогнозы точно измеряют цель. Даже если они это сделают, мы можем написать простое условие IF и вернуть ноль, если это так, и через градиент в противном случае. Также известно, что вторая производная везде нулевая и не определена в нулевой точке.
Обратите внимание, чтоесли мы хотим иметь постоянный прогноз, лучшим будетсрединное значение целевых значений.Его можно найти, установив производную нашей полной ошибки по этой константе в ноль, и найти ее из этого уравнения.
R в квадрате (R²)
А что если я скажу вам, что MSE для моих моделей предсказаний составляет 32? Должен ли я улучшить свою модель или она достаточно хороша? Или что, если мой MSE был 0,4? На самом деле, трудно понять, хороша наша модель или нет, посмотрев на абсолютные значения MSE или RMSE. Мы, вероятно, захотим измерить, как Во многом наша модель лучше, чем постоянная базовая линия.
Коэффициент детерминации, или R² (иногда читаемый как R-два), является еще одним показателем, который мы можем использовать для оценки модели, и он тесно связан с MSE, но имеет преимущество в том, чтобезмасштабное— не имеет значения, являются ли выходные значения очень большими или очень маленькими,R² всегда будет между -∞ и 1.
Когда R² отрицательно, это означает, что модель хуже, чем предсказание среднего значения.

MSE модели рассчитывается, как указано выше, в то время как MSE базовой линии определяется как:

гдеYс чертой означает среднее из наблюдаемогоyᵢ.
Чтобы сделать это более ясным, этот базовый MSE можно рассматривать как MSE, чтопростейшиймодель получит. Простейшей возможной моделью было бывсегдапредсказать среднее по всем выборкам. Значение, близкое к 1, указывает на модель с ошибкой, близкой к нулю, а значение, близкое к нулю, указывает на модель, очень близкую к базовой линии.
В заключение, R² — это соотношение между тем, насколько хороша наша модель, и тем, насколько хороша модель наивного среднего.
Распространенное заблуждение:Многие статьи в Интернете утверждают, что диапазон R² лежит между 0 и 1, что на самом деле не соответствует действительности. Максимальное значение R² равно 1, но минимальное может быть минус бесконечность.
Например, рассмотрим действительно дрянную модель, предсказывающую крайне отрицательное значение для всех наблюдений, даже если y_actual положительно. В этом случае R² будет меньше 0. Это крайне маловероятный сценарий, но возможность все еще существует.
MAE против MSE
Я заявил, что MAE более устойчив (менее чувствителен к выбросам), чем MSE, но это не значит, что всегда лучше использовать MAE. Следующие вопросы помогут вам решить:

Взять домой сообщение
В этой статье мы обсудили несколько важных метрик регрессии. Сначала мы обсудили среднеквадратичную ошибку и поняли, что наилучшей константой для нее является среднее целевое значение. Среднеквадратичная ошибка и R² очень похожи на MSE с точки зрения оптимизации. Затем мы обсудили среднюю абсолютную ошибку и когда люди предпочитают использовать MAE вместо MSE.

Спасибо за чтение, и я с нетерпением жду, чтобы услышать ваши вопросы  Наслаждайтесь!
Наслаждайтесь!
P.SСледите за моей следующей статьей, которая изучает другие более продвинутые метрики регрессии. Если вы хотите больше узнать о мире машинного обучения, вы также можете подписаться на меня в Instagram, напишите мне напрямую или найди меня на linkedin, Я хотел бы услышать от вас.
Ресурсы:
[1] https://dmitryulyanov.github.io/about
7
ответов
Я думаю, что от вас хотят услышать распределение Лапласа.
11:35 27.12.2021
а это точно ответ на тот же вопрос?
11:41 27.12.2021
Andrey
а это точно ответ на тот же вопрос?
Ну как бы нет, но это моя догадка. :))
11:43 27.12.2021
тоже ощущение что слегка глухой телефон… потому что в исходной постановке нетривиально
11:45 27.12.2021
Egorische The Cupcake.
![]()
Большое спасибо за развёрнутый ответ, нужно было лишь написать название распределения)
11:59 27.12.2021
Такой вопрос и был, в текстовом формате без никаких подкреплённых изображений
12:01 27.12.2021
Похожие вопросы
17 авг. 2022 г.
читать 3 мин
Модели регрессии используются для количественной оценки взаимосвязи между одной или несколькими переменными-предикторами и переменной отклика .
Всякий раз, когда мы подбираем регрессионную модель, мы хотим понять, насколько хорошо модель может использовать значения переменных-предикторов для прогнозирования значения переменной отклика.
Две метрики, которые мы часто используем для количественной оценки того, насколько хорошо модель соответствует набору данных, — это средняя абсолютная ошибка (MAE) и среднеквадратическая ошибка (RMSE), которые рассчитываются следующим образом:
MAE : метрика, которая сообщает нам среднюю абсолютную разницу между прогнозируемыми значениями и фактическими значениями в наборе данных. Чем ниже MAE, тем лучше модель соответствует набору данных.
MAE = 1/n * Σ|y i – ŷ i |
куда:
- Σ — это символ, который означает «сумма»
- y i — наблюдаемое значение для i -го наблюдения
- ŷ i — прогнозируемое значение для i -го наблюдения
- n — размер выборки
RMSE : метрика, которая сообщает нам квадратный корень из средней квадратичной разницы между прогнозируемыми значениями и фактическими значениями в наборе данных. Чем ниже RMSE, тем лучше модель соответствует набору данных.
Он рассчитывается как:
СКО = √ Σ(y i – ŷ i ) 2 / n
куда:
- Σ — это символ, который означает «сумма»
- ŷ i — прогнозируемое значение для i -го наблюдения
- y i — наблюдаемое значение для i -го наблюдения
- n — размер выборки
Пример: Расчет RMSE и MAE
Предположим, мы используем регрессионную модель, чтобы предсказать количество очков, которое 10 игроков наберут в баскетбольном матче.
В следующей таблице показаны прогнозируемые очки по модели и фактические очки, набранные игроками:

Используя калькулятор MAE , мы можем рассчитать MAE как 3,2.
Это говорит нам о том, что средняя абсолютная разница между прогнозируемыми значениями модели и фактическими значениями составляет 3,2.
Используя Калькулятор RMSE , мы можем рассчитать RMSE, чтобы он был равен 4 .
Это говорит нам о том, что квадратный корень из среднеквадратичной разницы между предсказанными набранными очками и фактическими набранными очками равен 4.
Обратите внимание, что каждая метрика дает нам представление о типичной разнице между прогнозируемым значением, сделанным моделью, и фактическим значением в наборе данных, но интерпретация каждой метрики немного отличается.
RMSE против MAE: какую метрику следует использовать?
Если вы хотите придать больший вес наблюдениям, которые находятся дальше от среднего (т. е. если «отклонение» на 20 более чем в два раза хуже, чем отклонение на 10 дюймов), то лучше использовать RMSE для измерения ошибки, потому что RMSE более чувствителен к наблюдениям, которые далеки от среднего.
Однако, если «выключиться» в 20 раз хуже, чем в 10, то лучше использовать MAE.
Чтобы проиллюстрировать это, предположим, что у нас есть один игрок, который явно отличается по количеству набранных очков:

Используя онлайн-калькуляторы, упомянутые ранее, мы можем рассчитать MAE и RMSE следующим образом:
- МАЭ : 8
- Среднеквадратичное значение : 16,4356
Обратите внимание, что RMSE увеличивается намного больше, чем MAE.
Это связано с тем, что в формуле RMSE используются квадраты разницы, а квадрат разницы между наблюдаемым значением 76 и прогнозируемым значением 22 довольно велик. Это приводит к значительному увеличению значения RMSE.
На практике мы обычно подгоняем несколько моделей регрессии к набору данных и вычисляем только одну из этих метрик для каждой модели.
Например, мы можем подобрать три разные регрессионные модели и рассчитать RMSE для каждой модели. Затем мы выберем модель с самым низким значением RMSE в качестве «лучшей» модели, потому что именно она делает прогнозы, наиболее близкие к фактическим значениям из набора данных.
В любом случае просто убедитесь, что вы вычисляете одну и ту же метрику для каждой модели. Например, не рассчитывайте MAE для одной модели и RMSE для другой модели, а затем сравнивайте эти две метрики.
Дополнительные ресурсы
В следующих руководствах объясняется, как рассчитать MAE с помощью различных статистических программ:
Как рассчитать среднюю абсолютную ошибку в Excel
Как рассчитать среднюю абсолютную ошибку в R
Как рассчитать среднюю абсолютную ошибку в Python
В следующих руководствах объясняется, как рассчитать RMSE с помощью различных статистических программ:
Как рассчитать среднеквадратичную ошибку в Excel
Как рассчитать среднеквадратичную ошибку в R
Как рассчитать среднеквадратичную ошибку в Python
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
- Среднеквадратичная ошибка (Mean Squared Error)
- Корень из среднеквадратичной ошибки (Root Mean Squared Error)
- Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error)
- Cредняя абсолютная ошибка (Mean Absolute Error)
- Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error)
- Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error)
- Средняя абсолютная масштабированная ошибка (Mean absolute scaled error)
- Средняя относительная ошибка (Mean Relative Error)
- Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error
- R-квадрат
- Скорректированный R-квадрат
- Сравнение метрик
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
frac{partial RMSE}{partial widehat{y}_{i}}=frac{1}{2sqrt{MSE}}frac{partial MSE}{partial widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=frac{100}{n}sumlimits_{i=1}^{n}left ( frac{y_{i}-widehat{y}_{i}}{y_{i}} right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=frac{1}{n}sumlimits_{i=1}^{n}left | y_{i}-widehat{y}_{i} right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{left | y_{i} right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{(left | y_{i} right |+left | widehat{y}_{i} right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=frac{1}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y}_{i}right |}{left | y_{i} right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(log(widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}/(n-k)}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат
Вот мы проанализировали данные, вот мы сгладили временной ряд, выявили связи между переменными и решили построить некоторую математическую прогнозную модель. Давайте допустим, что мы пока решили ограничиться какой-нибудь простой моделью парной регрессии, например, такой вот:
begin{equation} label{eq:estim_linreg}
y_t = a + b x_t + e_t ,
end{equation}
где (y_t) — объём продаж мороженого, (x_t) — температура воздуха, а (e_t) — случайная ошибка модели.
Вроде бы ничего особенного и ничего сложного, но откуда же нам взять коэффициенты (a) и (b)? Надо их как-то рассчитать (или, как это говорят в статистике, «оценить»). Для этого существует множество различных методов, но все они преследуют одну и ту же цель — оптимизировать какую-нибудь функцию (минимизировать или максимизировать) путём подбора этих самых значений (a) и (b). По сути вся задача сводится к тому, чтобы провести некоторым образом линию через «облако» значений (x) и (y) так, чтобы минимизировать целевую функцию. На рисунке ниже показан пример такого облака и нескольких линий, проходящих через него.

Мороженое и палочки
Каждая из линий на рисунке соответствует одной и той же линейной функции eqref{eq:estim_linreg}, но с разными коэффициентами. Фактически любая такая линия — это последовательность некоторых расчётных значений (hat{y}_t), позволяющая оценить, какими будут продажи мороженного в среднем если температура будет принимать значения (x_t) (отложенные по оси абсцисс). Очевидно, что таких прямых на плоскости можно провести сколько угодно, и каждая из них будет минимизировать либо максимизировать какой-нибудь свой критерий. Обычно это происходит путём подбора коэффициентов с использованием различных оптимизационных методов, путём решения задач программирования (линейного, нелинейного, целочисленного) либо с использованием эвристических методов (генетические и эволюционные алгоритмы). В достаточно редких случаях для расчёта коэффициентов в нашем распоряжении могут быть формулы, гарантирующие получения оптимума (такие формулы даёт, например, Метод Наименьших Квадратов, который мы обсудим в главе про регрессии).
Очевидно, что рассмотреть все возможные целевые функции в рамках одной статьи невозможно, да и не имеет никакого смысла. Чаще всего нас интересует минимальное расстояние между точками и линиями, которое, очевидно, можно оценить по-разному.
Рассмотрим подробней самые простые и популярные в прогнозировании методы оценки коэффициентов моделей.
Но вначале R!
Прежде чем двигаться дальше, создадим в R две переменные, с которыми мы будем далее работать:
x <- rnorm(100,100,15)
y <- rep(NA,100)
y[1:95] <- 50 + 0.9 * x[1:95] + rnorm(95,0,5)
y[96:100] <- 190 + 0.2 * x[96:100] + rnorm(5,0,2)
data <- as.data.frame(matrix(NA,100,2))
colnames(data) <- c("x","y")
data[,1] <- x
data[,2] <- y
C <- rep(NA,2)
Первой строкой мы создаём нормально распределённую величину, состоящую из 100 наблюдений. Второй строкой мы создаём вторую переменную, состоящую из значений «NA» — «Np (то есть никак не заданных). Третьей и четвёртой строками мы заполняем вторую переменную так, что первые 95 наблюдений сгенерированы исходя из одной зависимости от x, а последние 5 — исходя из другой. Следующими четырьмя строками мы создаём из этих двух переменных объект с данными. Строкой за ними мы создаём вектор остатков. Пока что он пустой. Последней строкой мы создаём вектор для двух коэффициентов нашей будущей модели. Они тоже пока пустые.
MSE
MSE расшифровывается как «Mean Squared Error» и переводится как «Средняя квадратическая ошибка». Суть метода заключается по сути в том, чтобы минимизировать сумму квадратов отклонений фактических значений от расчётных (SSE — «Sum of Squared Errors»). Если полученную сумму разделить на число наблюдений, то получится та самая MSE. Формула целевой функции в этом случае выглядит следующим образом:
begin{equation} label{eq:estim_MSE}
MSE = frac{1}{T} sum_{t=1}^T e_t^2 = frac{1}{T} sum_{t=1}^T (y_t -hat{y}_t)^2 .
end{equation}
Если бы в формуле eqref{eq:estim_MSE} не было квадрата, то положительные и отрицательные отклонения друг друга погашали, из-за чего минимизировалось бы не расстояние между фактическими и расчётными значениями, а чёрт знает что. То есть наличие квадратов позволяет получить некоторую оценку расстояния от фактических значений до линии (расчётных значений).
Стоит отметить, что, как мы помним из «Статистического анализа», возведение в квадрат существенно увеличивает те значения, которые лежат далеко от всех остальных. Например, если продажи мороженого колеблются в основном в районе ста штук, но есть наблюдение в 200, то это наблюдение будет тянуть на себя одеяло — влиять существенно на оценки коэффициентов. То есть MSE является не робастной величиной и вообще позволяет получить некоторую среднюю оценку (в среднем фактическое значение (y_t) будет соответствовать (hat{y}_t) при данном значении (x_t)).
В случае с регрессиями использование MSE соответствует расчёту коэффициентов методом наименьших квадратов, к которому мы обратимся позже.
И ещё R!
Напишем в R простую функцию, которая позволит нам оценивать коэффициенты парной регрессии. Назовём её «CF» — «Cost Function»:
CF <- function(C){
residuals <- data[,2] - (C[1] + C[2] * data[,1])
return(mean(residuals^2))
}
Самой первой строкой мы определяем, что «CF» это объект типа «функция». Далее мы указываем, как рассчитать остатки модели: это фактические значения (второй столбец наших данных) минус расчётные, полученные по формуле eqref{eq:estim_linreg} (здесь (C[1] = a text{, } C[2] = b text{, } data[,1] = x)). Третьей строкой мы определяем нашу целевую функцию. В данном случае это средняя, взятая по остаткам, возведённым в квадрат (MSE).
Теперь проведём оптимизацию и запишем полученные коэффициенты:
result <- nlminb(c(1,1),CF) C <- result$par
Функция «nlminb» позволяет подбирать оптимальные параметры путём минимизации некой функции. c(1,1) в данном случае задаёт функции вектор стартовых параметров для поиска. Вместо этих значений можно было бы задать и что-нибудь другое. Второй строкой мы записываем найденные параметры в наш вектор C.
Построим теперь точечную диаграмму по ряду данных и проведём на том же графике полученную линию:
plot(data) abline(a=C[1], b=C[2], col="red")
С первой функцией мы уже сталкивались ранее, а вот со второй — пока нет. Она позволяет провести прямую линию с заданными параметрами на уже имеющемся графике. a и b соответствуют тем самым коэффициентам той самой функции eqref{eq:estim_linreg}.
MAE
MAE расшифровывается как «Mean Absolute Error», что с зарубежного на отечественный переводится как «Средняя абсолютная ошибка». Рассчитывается она так:
begin{equation} label{eq:estim_MAE}
MAE = frac{1}{T} sum_{t=1}^T |e_t| = frac{1}{T} sum_{t=1}^T |y_t -hat{y}_t| .
end{equation}
Модули в формуле eqref{eq:estim_MAE} всё так же позволяют избавиться от знаков и получить некоторую оценку расстояния от фактических до расчётных значений, которое нужно будет потом минимизировать. Несомненным преимуществом MAE является то, что модули не увеличивают в разы отклонения, считающиеся выбросами. Поэтому эта оценка является более робастной, чем MSE и фактически соответствует медиане (в 50% случаев при данном значении (x_t) зависимая величина (y_t) будет не меньше полученной (hat{y}_t)).
Разница между оценками коэффициентов, полученными при использовании MSE и MAE, наглядно показана на следующем рисунке:

Модели, оценённые с использованием MSE и MAE.
Из-за наличия аномального объёма продаж мороженного при 40 градусах по цельсию, красная линия (соответствующая регрессии, оценённой с помощью MSE) задирается и хуже описывает все остальные нормальные значения. Синяя же линия (соответствующая MAE) демонстрирует больше адекватности, так как в значительно меньшей степени реагирует на творящееся во время такой дикой жары безобразие на улицах города.
А теперь то же самое, только в R!
В R для получения оценок с помощью этого критерия нам достаточно изменить критерий в нашей функции «CF»:
CF <- function(C){
residuals <- data[,2] - (C[1] + C[2] * data[,1])
return(mean(abs(residuals)))
}
Теперь функция возвращает средние абсолютные ошибки (функция «abs» возвращает значения по модулю), а не квадратические.
Ещё раз проведём оптимизацию, запишем коэффициенты и построим график:
result <- nlminb(c(1,1),CF) C <- result$par abline(a=C[1], b=C[2], col="blue")
Если вы проделали всё это, то теперь можете сравнить полученные линии в случае с MSE и в случае с MAE. Здесь я специально опустил функцию «plot» для того, чтобы новая линия для наглядности была нанесена на тот же график.
Квантильные оценки
Прозорливые читатели уже, наверно, догадались, что помимо получения средней и медианной величин, можно так же получить и квантильные. В статистическом анализе регрессии, оценённые таким методом, называются «квантильными регрессиями».
Целевая функция, соответствующая таким квантильным оценкам, имеет вид:
begin{equation} label{eq:estim_Quantiles}
CF_alpha = (1 — alpha) sum_{y_t < hat{y}_t } |e_t| + alpha sum_{y_t geq hat{y}_t } |e_t| .
end{equation}
где (alpha) — это выбранная частота для квантиля (см. «Статистический анализ»), которая в данном случае выступает в роли веса, задаваемому тем или иным суммам. Если (alpha>0.5), то вторая сумма в правой части eqref{eq:estim_Quantiles}, соответствующая ситуации, когда фактические значения оказываются больше расчётных, будет получать больший вес. Первая же сумма (в которой все фактические значения меньше расчётных) получит меньший вес. Минимизируя такую сумму мы фактически сдвинем расчётные значения вправо — так, чтобы вторая сумма была как можно меньше. В полученных ошибках модели это будет соответствовать заданному квантилю (alpha).
Условие (y_t < hat{y}_t) может быть заменено на (e_t < 0), так как остатки модели связаны с фактическими и расчётными значениями уравнением: (e_t = y_t — hat{y}_t).
Для того, чтобы лучше понять, что происходит, когда мы используем такую функцию, рассмотрим пример с (alpha=0.5). В этом случае формула eqref{eq:estim_Quantiles} будет преобразована в:
begin{equation} label{eq:estim_Quantilesexample_1}
CF_{0.5} = 0.5 sum_{y_t < hat{y}_t } |e_t| + 0.5 sum_{y_t geq hat{y}_t } |e_t| .
end{equation}
Получается, что суммы имеют одинаковый вес, а значит данная формула может быть легко заменена на следующую:
begin{equation} label{eq:estim_Quantilesexample_2}
CF_{0.5} = sum_{t=1}^T |e_t| .
end{equation}
Минимизация функции eqref{eq:estim_Quantilesexample_2}, как легко заметить, соответствует минимизации MAE eqref{eq:estim_MAE}. Просто в MAE мы ещё и делим полученную сумму на число наблюдений, что никак на оценки во время оптимизации не влияет.
В результате использования метода квантильных оценок полученная линия регрессии пройдёт не по середине облака, а выше или ниже него, в зависимости от выбранного значения частоты квантиля (alpha). Использование этого критерия при оценке функций в прогнозировании может быть полезным, например, для построения прогнозных интервалов.
Единственная проблема метода — это сложность его использования в случае малого количества наблюдений в выборке. Действительно, нет никакой возможности однозначно определить, например, 2,5% эмпирический квантиль, если в твоём распоряжении 10 наблюдений, потому что в этой малой выборке ниже этого квантиля будет лежать только ( 10 cdot 0.025 = 0.25 ) наблюдений. Для того, чтобы методом можно было воспользоваться, в распоряжении исследователя должно быть хотя бы (frac{1}{alpha}) наблюдений, где (alpha) соответствует левому хвосту распределения (для нашего примера это ( frac{1}{0.025} = 40 )).
И опять R!
Модифицируем в R нашу многострадальную функцию «CF» следующим образом:
CF <- function(C){
residuals <- data[,2] - (C[1] + C[2] * data[,1])
return((1-alpha) * sum(abs(residuals[residuals<0])) +
alpha * sum(abs(residuals[residuals>=0])))
}
В возвращении функции у нас теперь есть параметра `alpha`, который мы будем задавать в общем окружении программы чуть позже. Часть `residuals[residuals<0]` — это те остатки модели, которые оказались отрицательными.
Для примера зададим (alpha=0.05), проведём оптимизацию и построим полученную модель на том же графике, что и раньше:
alpha <- 0.05 result <- nlminb(c(1,1),CF) C <- result$par abline(a=C[1], b=C[2], col="darkgreen")
Теперь для полноты картины задайте (alpha=0.95) и проделайте всё то же самое с оптимизацией и построением графика:
alpha <- 0.95
В результате всего этого на ваш график должно быть добавлено две тёмно-зелёные линии, соответствующие 5% и 95% квантилям.
На следующем рисунке изображены линии, соответствующие моделям, оценённым MSE, MAE и 5% и 95% квантилям.

Модели, построенные с помощью MSE, MAE и квантильных оценок
Функция правдоподобия
Все перечисленные выше методы хороши, но сами по себе не имеют этакого статистического обоснования: мы понимаем, как себя будет вести полученная функция, как примерно она пройдёт через наши фактические значения, понимаем, чего можно ожидать в будущем, но мы не можем особо ничего сказать о том, какими будут оценки коэффициентов моделей со статистической точки зрения. Будут ли они получены случайно? Будут ли они стремиться к каким-то значениям, если мы построим модель по другой выборке из тех же данных? А как же быть, если перед нами несколько моделей, описывающих одни и те же данные по-разному? Например, несколько моделей экспоненциального сглаживания, из которых нужно выбрать одну. Или ряд регрессионных моделей… Какой же из них отдать предпочтение и как?
Для ответа на некоторые / все из этих вопросов, нужно обратиться к математической функции под названием «функция правдоподобия» (за бугром эту функцию называют «Likelihood function»). Но сначала нужно немного вспомнить теорию вероятностей. Не переживайте, много вспоминать не придётся. Нужно совсем чуть-чуть.
Итак, предположим, что мы всё ещё имеем дело с мороженным (тем более, что же может быть лучше мороженого? Разве только два мороженых!). В четверг мы замерили уровень продаж и увидели, что он составил 78.5 штук. Любой другой человек просто плюнул бы и продолжил работать дальше. Но пытливому уму статистика может стать интересно, какова вероятность получить такое значение либо значение, лежащее в некоторой области (скажем, от 70 до 80 штук) в случае, если мы предполагаем, что процесс продаж описывается некоторой математической функцией с заданными параметрами (например, простой парной регрессией eqref{eq:estim_linreg}). Такая вероятность называется условной — то есть вероятность получить определённое значение при выполнении некоторого ряда условий — и записать её математически можно так:
begin{equation} label{eq:estim_conditionalprobability}
P(y_t | theta, sigma^2)
end{equation}
где (theta) — это вектор всех наших параметров, (sigma^2) — дисперсия модели. В нашем примере с моделью eqref{eq:estim_linreg} имеем (theta = begin{pmatrix} a \ b end{pmatrix}).
Зачем же нам эта вероятность, когда нам нужна величина правдоподобия? Всё очень просто. Это самое правдоподобие фактически равно условной вероятности eqref{eq:estim_conditionalprobability}, но имеет другой смысл: оно показывает, насколько правдоподобны полученные значения параметров при имеющемся фактическом значении продаж. Математически это выражается следующим равенством:
begin{equation} label{eq:estim_probabilityandlikelihood}
L(theta, sigma^2 | y_t) = P(y_t | theta, sigma^2)
end{equation}
То есть это взгляд на тот же самый процесс, но с другой стороны.
Если теперь рассмотреть совместную вероятность получения параметров при всех имеющихся наблюдениях от (1 text{ до } T), то мы получим следующую функцию правдоподобия (здесь нужно иметь в виду, что при этом предполагается независимость наблюдений):
begin{equation} label{eq:estim_generallikelihood}
L(theta, sigma^2 | Y) = prod_{t=1}^T P(y_t | theta, sigma^2) ,
end{equation}
где (Y) — это вектор всех фактических значений: (Y = begin{pmatrix}y_1 \ y_2 \ vdots \ y_T end{pmatrix})
Теперь мы можем подставлять в eqref{eq:estim_generallikelihood} разные значения параметров модели (theta text{ и } sigma^2 ) и получать разные вероятности. Естественно, обычно мы заинтересованы в том, чтобы вероятность была максимальной, так что функцию правдоподобия eqref{eq:estim_generallikelihood} можно максимизировать, задавая разные значения параметров, и получить какие-нибудь оптимальные оценки коэффициентов.
Всё. Счастье есть! Можно откинуться на спинку стула и потягивать чай / мохито / виски / ром — в зависимости от времени года и предпочтений прогнозиста.
Однако теперь возникает другой вопрос: как же нам получить условные вероятности, использующиеся в eqref{eq:estim_generallikelihood}? А здесь как раз вступают в силу различные предположения, которые исследователь обычно накладывает относительно модели. Одно из самых популярных предположений — это то, что остатки модели распределены нормально. Оно теоретически оправдано в тех случаях, когда в нашей модели учтены все существенные переменные, а сама модель правильно специфицирована. То есть по сути мы говорим о том, что смогли угадать, что собой представляет идеальная модель. В этом случае вместо вероятности мы можем спокойно использовать функцию плотности нормального закона распределения вероятностей (который так любят все: и взрослые, и дети). Напоминаю, сама функция нормального распределения выглядит примерно так:
begin{equation} label{eq:estim_normaldensity}
P(y_t | theta, sigma^2) = frac{1}{sqrt{2 pi sigma^2}} e ^{-frac{e_t^2}{2sigma^2}},
end{equation}
где (e_t = y_t — hat{y}_t).
Подставляя eqref{eq:estim_normaldensity} в eqref{eq:estim_generallikelihood}, мы получим следующую функцию правдоподобия на основе нормального распределения:
begin{equation} label{eq:estim_likelihoodnormal}
L(theta, sigma^2 | Y) = prod_{t=1}^T frac{1}{sqrt{2 pi sigma^2}} e ^{-frac{e_t^2}{2sigma^2}} = left( 2 pi sigma^2 right)^{-frac{T}{2}} e ^ {left( -frac{1}{2} sum_{t=1}^T frac{e_t^2}{sigma^2}right)} .
end{equation}
Очевидно, что функцию eqref{eq:estim_likelihoodnormal} неудобно максимизировать в таком её виде, так как приходится сталкиваться с произведениями и экспонированием. Однако оптимальное значение коэффициентов не изменится, если мы линеаризуем эту функцию (например, прологарифмируем левую и правую части, используя натуральный логарифм). В этом случае мы получим следующую функцию (которая у них там на западе называется «log-likelihood»):
begin{equation} label{eq:estim_loglikelihoodnormal}
ell(theta, sigma^2 | Y) = ln ( L(theta, sigma^2 | Y) ) = -frac{T}{2} ln left( 2 pi sigma^2 right) -frac{1}{2} sum_{t=1}^T frac{e_t^2}{sigma^2} .
end{equation}
В правой части eqref{eq:estim_loglikelihoodnormal} дисперсию можно вынести за знак суммы, так как она представлена константой, тогда получим:
begin{equation} label{eq:estim_loglikelihoodnormal1}
ell(theta, sigma^2 | Y) = -frac{T}{2} ln left( 2 pi sigma^2 right) -frac{1}{2 sigma^2} sum_{t=1}^T e_t^2 .
end{equation}
Теперь можно попытаться математически вывести при каком значении параметров функция будет максимизироваться. Проще всего это сделать вначале с дисперсией. Для этого возьмём первую производную eqref{eq:estim_loglikelihoodnormal1} по (sigma^2) и приравняем её к нулю:
begin{equation} label{eq:estim_loglikelihoodnormaldsigma1}
frac{d ell(theta, sigma^2 | Y)}{d sigma^2} = -frac{T}{2} frac{2 pi 2 sigma}{ 2 pi sigma^2 } + 2 frac{1}{2 sigma^3} sum_{t=1}^T e_t^2 = 0.
end{equation}
Если теперь в eqref{eq:estim_loglikelihoodnormaldsigma1} сократить то, что сокращается и перенести правое слагаемое в правую часть, то получим:
begin{equation} label{eq:estim_loglikelihoodnormaldsigma2}
frac{T}{sigma} = frac{1}{sigma^3} sum_{t=1}^T e_t^2.
end{equation}
Умножим теперь левую и правую части eqref{eq:estim_loglikelihoodnormaldsigma2} на (sigma^3) и разделим на (T):
begin{equation} label{eq:estim_loglikelihoodnormalsigma}
sigma^2 = frac{1}{T} sum_{t=1}^T e_t^2.
end{equation}
Полученная формула позволяет нам оценить дисперсию ошибок по выборке с помощью статистически выверенного и корректного метода — путём максимизации функции правдоподобия на основе нормального закона распределения вероятностей. Ничего нового нам эта формула, вроде бы, не даёт, потому что мы итак знаем, как рассчитать дисперсию ошибок, но нам она полезна как раз с точки зрения статистического обоснования. Однако, чтобы не перепутать, что мы вообще-то имеем дело не с истинной дисперсией (существующей в генеральной совокупности и воображении статистиков), а с оценённой по выборке, мы будем полученную с помощью eqref{eq:estim_loglikelihoodnormalsigma} дисперсию обозначать (hat{sigma}^2). Кроме того, отметим, что мы только что показали, что дисперсия, оценённая по формуле eqref{eq:estim_loglikelihoodnormalsigma} является некой оптимальной оценкой только в случае, если мы имеем дело с нормальным распределение ошибок!
Что ж, продолжим наши пляски с бубном и подставим эту оценённую дисперсию в eqref{eq:estim_loglikelihoodnormal1}. Пойдём ещё дальше и подставим сразу значение из формулы eqref{eq:estim_loglikelihoodnormalsigma}:
begin{equation} label{eq:estim_concentratedloglikelihoodnormal}
ell(theta | Y) = -frac{T}{2} ln left( 2 pi frac{1}{T} sum_{t=1}^T e_t^2 right) -left({2 frac{1}{T} sum_{t=1}^T e_t^2}right)^{-1} sum_{t=1}^T e_t^2 .
end{equation}
Заметим, пока не поздно, что функция правдоподобия, в которой используется оценённая дисперсия, называется «концентрированной» («concentrated log-likelihood»).
В eqref{eq:estim_concentratedloglikelihoodnormal} суммы в правой части легко сокращаются, а произведение под знаком логарифма легко преобразуется в сумму логарифмов таким вот образом:
begin{equation} label{eq:estim_concentratedloglikelihoodnormal1}
ell(theta | Y) = -frac{T}{2} ln left( 2 pi right) -frac{T}{2} ln left( frac{1}{T} sum_{t=1}^T e_t^2 right) — frac{T}{2} .
end{equation}
После ряда элементарных перестановок можно получить следующую, ещё более простую, логарифмированную концетрированную функцию правдоподобия:
begin{equation} label{eq:estim_concentratedloglikelihoodnormal2}
ell(theta | Y) = -frac{T}{2} left( ln left( 2 pi e right) + ln left( frac{1}{T} sum_{t=1}^T e_t^2 right) right) .
end{equation}
Максимизировать функцию eqref{eq:estim_concentratedloglikelihoodnormal2} теперь очень просто. На самом деле ещё легче — минимизировать (-frac{2}{T} ell(theta | Y)), так как размер выборки у нас фиксирован. eqref{eq:estim_concentratedloglikelihoodnormal2} тогда преобразуется в:
begin{equation} label{eq:estim_concentratedloglikelihoodnormalnegative}
-frac{2}{T} ell(theta | Y) = ln left( 2 pi e right) + ln left( frac{1}{T} sum_{t=1}^T e_t^2 right) .
end{equation}
Ну, и в качестве финального аккорда, можно избавиться от константы (ln left( 2 pi e right)), так как она никак не влияет на получение оптимальных коэффициентов. А полученное в итоге число можно вообще проэкспонировать, для того, чтобы прийти к следующей целевой функции, минимизируя которую мы будем получать оценки максимального правдоподобия (не забываем про допущение о нормальном распределении остатков модели):
begin{equation} label{eq:estim_concentratedloglikelihoodnormal4}
CF = frac{1}{T} sum_{t=1}^T e_t^2 .
end{equation}
Удивительным образом эта целевая функция целиком и полностью соответствует MSE (формула eqref{eq:estim_MSE}).
В этом месте может возникнуть вопрос: зачем же все эти выводы и сложные процедуры, если мы в итоге получили всего лишь известный нам критерий MSE? Ответов на этот вопрос несколько:
- Путём простых математических выкладок мы доказали, что MSE является эффективным критерием оценки коэффициентов моделей в том случае, если остатки модели распределены нормально. Например, для наших примеров в предыдущих параграфах (см. рисунок с MSE и MAE) эта предпосылка нарушается, поэтому MSE не является эффективным критерием.
- Используя логарифмированную концентрированную функцию правдоподобия eqref{eq:estim_concentratedloglikelihoodnormal2} можно осуществлять выбор наилучшей модели из ряда имеющихся в распоряжении исследователя. Эту тему мы обсудим подробней в одном из следующих параграфов.
- Кроме того, всё та же функция позволяет нам получать оценки дисперсий коэффициентов любой модели. Они нам могут понадобиться для проверки всяких статистических гипотез или построения доверительных интервалов. Для получения этих дисперсий нужно обратиться к некой вещи под названием «Информация Фишера», но здесь мы вдаваться в детали пока не будем.
- Если нам не нравится предположение о нормальности распределения остатков, мы можем использовать любую другую функцию распределения в eqref{eq:estim_generallikelihood}. Конечно же, придётся произвести все последующие выводы аналогично тем, что мы произвели только что (а в некоторых случаях ничего такого сделать и не получится, функцию придётся максимизировать как есть), но зато это даст нам красивые, статистически выверенные оценки.
- Используя этот подход, можно показать, что минимизация MAE является оптимальным методом оценки в случае, если остатки имеют распределение Лапласа, а квантиальные оценки дают максимум функции правдоподобия для асимметричного распределения Лапласа.
На этом простые методы оценки параметров моделей заканчиваются. В следующей статье мы перейдём к продвинутым.
Выбор функции потерь для задач построения нейронных сетей
Время прочтения: 4 мин.
При построении нейронных сетей перед нами часто встаёт вопрос правильного выбора функции потерь, используемой для формирования соответствий между входными и выходными параметрами. Функция потерь отвечает за оценку того, насколько хорошо модель предсказывает реальное значение, и построение модели сводится к решению задачи минимизации значения этой функции на каждом этапе. И в зависимости от того, как выглядят наши данные, требуется использовать разные подходы.
В рамках данной статьи мы рассмотрим три функции потерь для нейронных сетей, решающих регрессионные задачи.
Mean Squared Error
Среднеквадратичная ошибка (MSE) — одна из основных функций расчёта отклонения. Для каждой точки вычисляется квадрат отклонения, после чего полученные значения суммируются и делятся на общее количество точек. Чем ближе полученное значение к нулю, тем точнее наша модель. Данный метод расчёта в значительной мере чувствителен к выбросам в выборке, или к выборкам где разброс значений очень большой. В основном, данная функция применяется для переменных, распределение которых близко к распределению Гаусса.
Mean Absolute Error
Средняя абсолютная ошибка (MAE) – это усреднённая сумма модулей разницы между реальным и предсказанным значениями. MAE во многом похожа на MSE, но она отличается меньшей чувствительностью к выбросам значений (так как не берётся квадрат отклонения).
Mean Squared Logarithmic Error
Среднеквадратичная логарифмическая ошибка (MSLE) – усреднённая сумма квадратов разностей между логарифмами значений. Благодаря большому гасящему эффекту логарифма она более применима к моделям, строящимся на данных, которые имеют большой разброс значений на несколько порядков.
Продемонстрируем как выбор функции потерь влияет на процесс построения нейронной сети. Для генерации данных будем использовать встроенную в scikit-learn функцию make_regression, а в качестве нейронной сети будет выступать многослойный перцептрон.
Код используемый для демонстрации:
from sklearn.datasets import make_regression
from sklearn.preprocessing import StandardScaler
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
from matplotlib import pyplot
# формирование датасета
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=1)
# нормализация
X = StandardScaler().fit_transform(X)
y = StandardScaler().fit_transform(y.reshape(len(y),1))[:,0]
# разделение
n_train = 500
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# определение для модели
model = Sequential()
model.add(Dense(25, input_dim=20, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(1, activation='linear'))
opt = SGD(lr=0.01, momentum=0.9)
model.compile(loss=вид функции потерь, optimizer=opt)
# расчёт
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=100, verbose=0)
# Оценка качества
train_mse = model.evaluate(trainX, trainy, verbose=0)
test_mse = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_mse, test_mse))
# plot Демонстрация результата
pyplot.title('Loss / Mean Squared Error')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
pyplot.show()
В данном коде мы будем заменять только указанный вид функции потерь.
Результат для MSE:
model.compile(loss='mean_squared_error', optimizer=opt)Полученное отклонение для модели:
Train: 0.000, Test: 0.001
Как видно из графика, модель показывает хорошую сходимость и низкое отклонение.
Результат для MSLE:
model.compile(loss=' mean_squared_logarithmic_error', optimizer=opt)Полученное отклонение для модели:
Train: 0.165, Test: 0.184
По графику видно, что для данного набора данных MSLE сходится медленней чем MSE. С одной стороны, это может привести к тому что модель будет строиться медленней и получится хуже, с другой – использование MSE может привести к переобучению. Результат для MAE:
model.compile(loss='mean_absolute_error', optimizer=opt)Полученное отклонение для модели:
Train: 0.002, Test: 0.002
Здесь мы можем увидеть, что результат сходится очень эффективно, но ошибка имеет нерегулярный характер. Так как используемый нами генератор строит гауссово распределение без выбросов, использование MAE не даёт значительных преимуществ.
Очевидно, что от выбора правильной функции потерь сильно зависит точность, качество и скорость построения модели, поэтому следует внимательно подходить к выбору опираясь как на используемую модель, так и на характеристики входных данных.
Гораздо легче что-то измерить, чем понять, что именно вы измеряете
Джон Уильям Салливан
Задачи машинного обучения с учителем как правило состоят в восстановлении зависимости между парами (признаковое описание, целевая переменная) по данным, доступным нам для анализа. Алгоритмы машинного обучения (learning algorithm), со многими из которых вы уже успели познакомиться, позволяют построить модель, аппроксимирующую эту зависимость. Но как понять, насколько качественной получилась аппроксимация?
Почти наверняка наша модель будет ошибаться на некоторых объектах: будь она даже идеальной, шум или выбросы в тестовых данных всё испортят. При этом разные модели будут ошибаться на разных объектах и в разной степени. Задача специалиста по машинному обучению – подобрать подходящий критерий, который позволит сравнивать различные модели.
Перед чтением этой главы мы хотели бы ещё раз напомнить, что качество модели нельзя оценивать на обучающей выборке. Как минимум, это стоит делать на отложенной (тестовой) выборке, но, если вам это позволяют время и вычислительные ресурсы, стоит прибегнуть и к более надёжным способам проверки – например, кросс-валидации (о ней вы узнаете в отдельной главе).
Выбор метрик в реальных задачах
Возможно, вы уже участвовали в соревнованиях по анализу данных. На таких соревнованиях метрику (критерий качества модели) организатор выбирает за вас, и она, как правило, довольно понятным образом связана с результатами предсказаний. Но на практике всё бывает намного сложнее.
Например, мы хотим:
- решить, сколько коробок с бананами нужно завтра привезти в конкретный магазин, чтобы минимизировать количество товара, который не будет выкуплен и минимизировать ситуацию, когда покупатель к концу дня не находит желаемый продукт на полке;
- увеличить счастье пользователя от работы с нашим сервисом, чтобы он стал лояльным и обеспечивал тем самым стабильный прогнозируемый доход;
- решить, нужно ли направить человека на дополнительное обследование.
В каждом конкретном случае может возникать целая иерархия метрик. Представим, например, что речь идёт о стриминговом музыкальном сервисе, пользователей которого мы решили порадовать сгенерированными самодельной нейросетью треками – не защищёнными авторским правом, а потому совершенно бесплатными. Иерархия метрик могла бы иметь такой вид:
- Самый верхний уровень: будущий доход сервиса – невозможно измерить в моменте, сложным образом зависит от совокупности всех наших усилий;
- Медианная длина сессии, возможно, служащая оценкой радости пользователей, которая, как мы надеемся, повлияет на их желание продолжать платить за подписку – её нам придётся измерять в продакшене, ведь нас интересует реакция настоящих пользователей на новшество;
- Доля удовлетворённых качеством сгенерированной музыки асессоров, на которых мы потестируем её до того, как выставить на суд пользователей;
- Функция потерь, на которую мы будем обучать генеративную сеть.
На этом примере мы можем заметить сразу несколько общих закономерностей. Во-первых, метрики бывают offline и online (оффлайновыми и онлайновыми). Online метрики вычисляются по данным, собираемым с работающей системы (например, медианная длина сессии). Offline метрики могут быть измерены до введения модели в эксплуатацию, например, по историческим данным или с привлечением специальных людей, асессоров. Последнее часто применяется, когда метрикой является реакция живого человека: скажем, так поступают поисковые компании, которые предлагают людям оценить качество ранжирования экспериментальной системы еще до того, как рядовые пользователи увидят эти результаты в обычном порядке. На самом же нижнем этаже иерархии лежат оптимизируемые в ходе обучения функции потерь.
В данном разделе нас будут интересовать offline метрики, которые могут быть измерены без привлечения людей.
Функция потерь $neq$ метрика качества
Как мы узнали ранее, методы обучения реализуют разные подходы к обучению:
- обучение на основе прироста информации (как в деревьях решений)
- обучение на основе сходства (как в методах ближайших соседей)
- обучение на основе вероятностной модели данных (например, максимизацией правдоподобия)
- обучение на основе ошибок (минимизация эмпирического риска)
И в рамках обучения на основе минимизации ошибок мы уже отвечали на вопрос: как можно штрафовать модель за предсказание на обучающем объекте.
Во время сведения задачи о построении решающего правила к задаче численной оптимизации, мы вводили понятие функции потерь и, обычно, объявляли целевой функцией сумму потерь от предсказаний на всех объектах обучающей выборке.
Важно понимать разницу между функцией потерь и метрикой качества. Её можно сформулировать следующим образом:
-
Функция потерь возникает в тот момент, когда мы сводим задачу построения модели к задаче оптимизации. Обычно требуется, чтобы она обладала хорошими свойствами (например, дифференцируемостью).
-
Метрика – внешний, объективный критерий качества, обычно зависящий не от параметров модели, а только от предсказанных меток.
В некоторых случаях метрика может совпадать с функцией потерь. Например, в задаче регрессии MSE играет роль как функции потерь, так и метрики. Но, скажем, в задаче бинарной классификации они почти всегда различаются: в качестве функции потерь может выступать кросс-энтропия, а в качестве метрики – число верно угаданных меток (accuracy). Отметим, что в последнем примере у них различные аргументы: на вход кросс-энтропии нужно подавать логиты, а на вход accuracy – предсказанные метки (то есть по сути argmax логитов).
Бинарная классификация: метки классов
Перейдём к обзору метрик и начнём с самой простой разновидности классификации – бинарной, а затем постепенно будем наращивать сложность.
Напомним постановку задачи бинарной классификации: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_iin{0, 1}$ построить модель, которая по объекту $x$ предсказывает метку класса $f(x)in{0, 1}$.
Первым критерием качества, который приходит в голову, является accuracy – доля объектов, для которых мы правильно предсказали класс:
$$ color{#348FEA}{text{Accuracy}(y, y^{pred}) = frac{1}{N} sum_{i=1}^N mathbb{I}[y_i = f(x_i)]} $$
Или же сопряженная ей метрика – доля ошибочных классификаций (error rate):
$$text{Error rate} = 1 — text{Accuracy}$$
Познакомившись чуть внимательнее с этой метрикой, можно заметить, что у неё есть несколько недостатков:
- она не учитывает дисбаланс классов. Например, в задаче диагностики редких заболеваний классификатор, предсказывающий всем пациентам отсутствие болезни будет иметь достаточно высокую accuracy просто потому, что больных людей в выборке намного меньше;
- она также не учитывает цену ошибки на объектах разных классов. Для примера снова можно привести задачу медицинской диагностики: если ошибочный положительный диагноз для здорового больного обернётся лишь ещё одним обследованием, то ошибочно отрицательный вердикт может повлечь роковые последствия.
Confusion matrix (матрица ошибок)
Исторически задача бинарной классификации – это задача об обнаружении чего-то редкого в большом потоке объектов, например, поиск человека, больного туберкулёзом, по флюорографии. Или задача признания пятна на экране приёмника радиолокационной станции бомбардировщиком, представляющем угрозу охраняемому объекту (в противовес стае гусей).
Поэтому класс, который представляет для нас интерес, называется «положительным», а оставшийся – «отрицательным».
Заметим, что для каждого объекта в выборке возможно 4 ситуации:
- мы предсказали положительную метку и угадали. Будет относить такие объекты к true positive (TP) группе (true – потому что предсказали мы правильно, а positive – потому что предсказали положительную метку);
- мы предсказали положительную метку, но ошиблись в своём предсказании – false positive (FP) (false, потому что предсказание было неправильным);
- мы предсказали отрицательную метку и угадали – true negative (TN);
- и наконец, мы предсказали отрицательную метку, но ошиблись – false negative (FN). Для удобства все эти 4 числа изображают в виде таблицы, которую называют confusion matrix (матрицей ошибок):
Не волнуйтесь, если первое время эти обозначения будут сводить вас с ума (будем откровенны, даже профи со стажем в них порой путаются), однако логика за ними достаточно простая: первая часть названия группы показывает угадали ли мы с классом, а вторая – какой класс мы предсказали.

Пример
Попробуем воспользоваться введёнными метриками в боевом примере: сравним работу нескольких моделей классификации на Breast cancer wisconsin (diagnostic) dataset.
Объектами выборки являются фотографии биопсии грудных опухолей. С их помощью было сформировано признаковое описание, которое заключается в характеристиках ядер клеток (таких как радиус ядра, его текстура, симметричность). Положительным классом в такой постановке будут злокачественные опухоли, а отрицательным – доброкачественные.
Модель 1. Константное предсказание.
Решение задачи начнём с самого простого классификатора, который выдаёт на каждом объекте константное предсказание – самый часто встречающийся класс.
Зачем вообще замерять качество на такой модели?При разработке модели машинного обучения для проекта всегда желательно иметь некоторую baseline модель. Так нам будет легче проконтролировать, что наша более сложная модель действительно дает нам прирост качества.
from sklearn.datasets
import load_breast_cancer
the_data = load_breast_cancer()
# 0 – "доброкачественный"
# 1 – "злокачественный"
relabeled_target = 1 - the_data["target"]
from sklearn.model_selection import train_test_split
X = the_data["data"]
y = relabeled_target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.dummy import DummyClassifier
dc_mf = DummyClassifier(strategy="most_frequent")
dc_mf.fit(X_train, y_train)
from sklearn.metrics import confusion_matrix
y_true = y_test y_pred = dc_mf.predict(X_test)
dc_mf_tn, dc_mf_fp, dc_mf_fn, dc_mf_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 0 | FN = 53 |
| Истинный класс — | FP = 0 | TN = 90 |
Обучающие данные таковы, что наш dummy-классификатор все объекты записывает в отрицательный класс, то есть признаёт все опухоли доброкачественными. Такой наивный подход позволяет нам получить минимальный штраф за FP (действительно, нельзя ошибиться в предсказании, если положительный класс вообще не предсказывается), но и максимальный штраф за FN (в эту группу попадут все злокачественные опухоли).
Модель 2. Случайный лес.
Настало время воспользоваться всем арсеналом моделей машинного обучения, и начнём мы со случайного леса.
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
y_true = y_test
y_pred = rfc.predict(X_test)
rfc_tn, rfc_fp, rfc_fn, rfc_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 52 | FN = 1 |
| Истинный класс — | FP = 4 | TN = 86 |
Можно сказать, что этот классификатор чему-то научился, т.к. главная диагональ матрицы стала содержать все объекты из отложенной выборки, за исключением 4 + 1 = 5 объектов (сравните с 0 + 53 объектами dummy-классификатора, все опухоли объявляющего доброкачественными).
Отметим, что вычисляя долю недиагональных элементов, мы приходим к метрике error rate, о которой мы говорили в самом начале:
$$text{Error rate} = frac{FP + FN}{ TP + TN + FP + FN}$$
тогда как доля объектов, попавших на главную диагональ – это как раз таки accuracy:
$$text{Accuracy} = frac{TP + TN}{ TP + TN + FP + FN}$$
Модель 3. Метод опорных векторов.
Давайте построим еще один классификатор на основе линейного метода опорных векторов.
Не забудьте привести признаки к единому масштабу, иначе численный алгоритм не сойдется к решению и мы получим гораздо более плохо работающее решающее правило. Попробуйте проделать это упражнение.
from sklearn.svm import LinearSVC
from sklearn.preprocessing import StandardScaler
ss = StandardScaler() ss.fit(X_train)
scaled_linsvc = LinearSVC(C=0.01,random_state=42)
scaled_linsvc.fit(ss.transform(X_train), y_train)
y_true = y_test
y_pred = scaled_linsvc.predict(ss.transform(X_test))
tn, fp, fn, tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 50 | FN = 3 |
| Истинный класс — | FP = 1 | TN = 89 |
Сравним результаты
Легко заметить, что каждая из двух моделей лучше классификатора-пустышки, однако давайте попробуем сравнить их между собой. С точки зрения error rate модели практически одинаковы: 5/143 для леса против 4/143 для SVM.
Посмотрим на структуру ошибок чуть более внимательно: лес – (FP = 4, FN = 1), SVM – (FP = 1, FN = 3). Какая из моделей предпочтительнее?
Замечание: Мы сравниваем несколько классификаторов на основании их предсказаний на отложенной выборке. Насколько ошибки данных классификаторов зависят от разбиения исходного набора данных? Иногда в процессе оценки качества мы будем получать модели, чьи показатели эффективности будут статистически неразличимыми.
Пусть мы учли предыдущее замечание и эти модели действительно статистически значимо ошибаются в разную сторону. Мы встретились с очевидной вещью: на матрицах нет отношения порядка. Когда мы сравнивали dummy-классификатор и случайный лес с помощью Accuracy, мы всю сложную структуру ошибок свели к одному числу, т.к. на вещественных числах отношение порядка есть. Сводить оценку модели к одному числу очень удобно, однако не стоит забывать, что у вашей модели есть много аспектов качества.
Что же всё-таки важнее уменьшить: FP или FN? Вернёмся к задаче: FP – доля доброкачественных опухолей, которым ошибочно присваивается метка злокачественной, а FN – доля злокачественных опухолей, которые классификатор пропускает. В такой постановке становится понятно, что при сравнении выиграет модель с меньшим FN (то есть лес в нашем примере), ведь каждая не обнаруженная опухоль может стоить человеческой жизни.
Рассмотрим теперь другую задачу: по данным о погоде предсказать, будет ли успешным запуск спутника. FN в такой постановке – это ошибочное предсказание неуспеха, то есть не более, чем упущенный шанс (если вас, конечно не уволят за срыв сроков). С FP всё серьёзней: если вы предскажете удачный запуск спутника, а на деле он потерпит крушение из-за погодных условий, то ваши потери будут в разы существеннее.
Итак, из примеров мы видим, что в текущем виде введенная нами доля ошибочных классификаций не даст нам возможности учесть неравную важность FP и FN. Поэтому введем две новые метрики: точность и полноту.
Точность и полнота
Accuracy — это метрика, которая характеризует качество модели, агрегированное по всем классам. Это полезно, когда классы для нас имеют одинаковое значение. В случае, если это не так, accuracy может быть обманчивой.
Рассмотрим ситуацию, когда положительный класс это событие редкое. Возьмем в качестве примера поисковую систему — в нашем хранилище хранятся миллиарды документов, а релевантных к конкретному поисковому запросу на несколько порядков меньше.
Пусть мы хотим решить задачу бинарной классификации «документ d релевантен по запросу q». Благодаря большому дисбалансу, Accuracy dummy-классификатора, объявляющего все документы нерелевантными, будет близка к единице. Напомним, что $text{Accuracy} = frac{TP + TN}{TP + TN + FP + FN}$, и в нашем случае высокое значение метрики будет обеспечено членом TN, в то время для пользователей более важен высокий TP.
Поэтому в случае ассиметрии классов, можно использовать метрики, которые не учитывают TN и ориентируются на TP.
Если мы рассмотрим долю правильно предсказанных положительных объектов среди всех объектов, предсказанных положительным классом, то мы получим метрику, которая называется точностью (precision)
$$color{#348FEA}{text{Precision} = frac{TP}{TP + FP}}$$
Интуитивно метрика показывает долю релевантных документов среди всех найденных классификатором. Чем меньше ложноположительных срабатываний будет допускать модель, тем больше будет её Precision.
Если же мы рассмотрим долю правильно найденных положительных объектов среди всех объектов положительного класса, то мы получим метрику, которая называется полнотой (recall)
$$color{#348FEA}{text{Recall} = frac{TP}{TP + FN}}$$
Интуитивно метрика показывает долю найденных документов из всех релевантных. Чем меньше ложно отрицательных срабатываний, тем выше recall модели.
Например, в задаче предсказания злокачественности опухоли точность показывает, сколько из определённых нами как злокачественные опухолей действительно являются злокачественными, а полнота – какую долю злокачественных опухолей нам удалось выявить.
Хорошее понимание происходящего даёт следующая картинка: 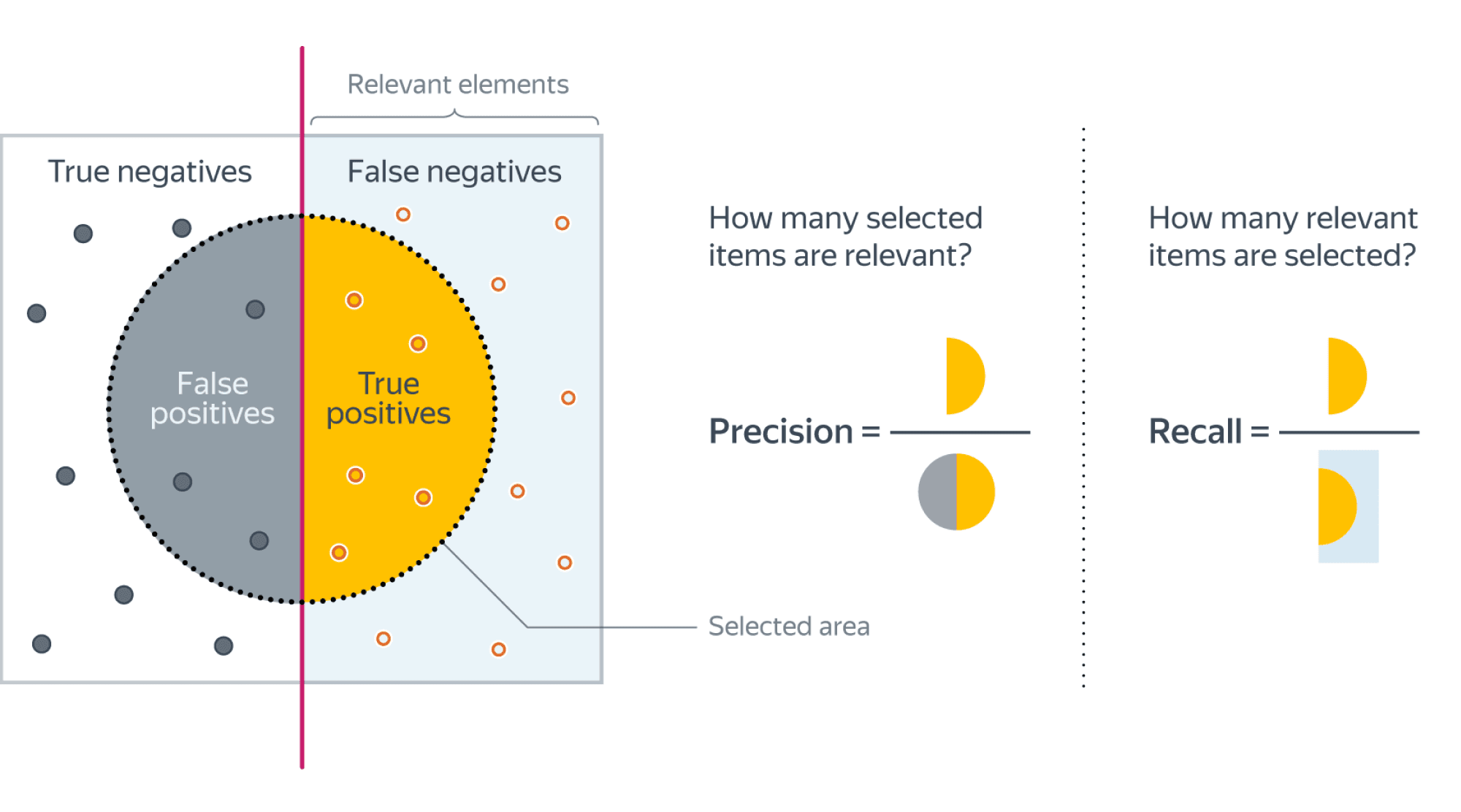 (источник картинки)
(источник картинки)
Recall@k, Precision@k
Метрики Recall и Precision хорошо подходят для задачи поиска «документ d релевантен запросу q», когда из списка рекомендованных алгоритмом документов нас интересует только первый. Но не всегда алгоритм машинного обучения вынужден работать в таких жестких условиях. Может быть такое, что вполне достаточно, что релевантный документ попал в первые k рекомендованных. Например, в интерфейсе выдачи первые три подсказки видны всегда одновременно и вообще не очень понятно, какой у них порядок. Тогда более честной оценкой качества алгоритма будет «в выдаче D размера k по запросу q нашлись релевантные документы». Для расчёта метрики по всей выборке объединим все выдачи и рассчитаем precision, recall как обычно подокументно.
F1-мера
Как мы уже отмечали ранее, модели очень удобно сравнивать, когда их качество выражено одним числом. В случае пары Precision-Recall существует популярный способ скомпоновать их в одну метрику — взять их среднее гармоническое. Данный показатель эффективности исторически носит название F1-меры (F1-measure).
$$
color{#348FEA}{F_1 = frac{2}{frac{1}{Recall} + frac{1}{Precision}}} = $$
$$ = 2 frac{Recall cdot Precision }{Recall + Precision} = frac
{TP} {TP + frac{FP + FN}{2}}
$$
Стоит иметь в виду, что F1-мера предполагает одинаковую важность Precision и Recall, если одна из этих метрик для вас приоритетнее, то можно воспользоваться $F_{beta}$ мерой:
$$
F_{beta} = (beta^2 + 1) frac{Recall cdot Precision }{Recall + beta^2Precision}
$$
Бинарная классификация: вероятности классов
Многие модели бинарной классификации устроены так, что класс объекта получается бинаризацией выхода классификатора по некоторому фиксированному порогу:
$$fleft(x ; w, w_{0}right)=mathbb{I}left[g(x, w) > w_{0}right].$$
Например, модель логистической регрессии возвращает оценку вероятности принадлежности примера к положительному классу. Другие модели бинарной классификации обычно возвращают произвольные вещественные значения, но существуют техники, называемые калибровкой классификатора, которые позволяют преобразовать предсказания в более или менее корректную оценку вероятности принадлежности к положительному классу.
Как оценить качество предсказываемых вероятностей, если именно они являются нашей конечной целью? Общепринятой мерой является логистическая функция потерь, которую мы изучали раньше, когда говорили об устройстве некоторых методов классификации (например уже упоминавшейся логистической регрессии).
Если же нашей целью является построение прогноза в терминах метки класса, то нам нужно учесть, что в зависимости от порога мы будем получать разные предсказания и разное качество на отложенной выборке. Так, чем ниже порог отсечения, тем больше объектов модель будет относить к положительному классу. Как в этом случае оценить качество модели?
AUC
Пусть мы хотим учитывать ошибки на объектах обоих классов. При уменьшении порога отсечения мы будем находить (правильно предсказывать) всё большее число положительных объектов, но также и неправильно предсказывать положительную метку на всё большем числе отрицательных объектов. Естественным кажется ввести две метрики TPR и FPR:
TPR (true positive rate) – это полнота, доля положительных объектов, правильно предсказанных положительными:
$$ TPR = frac{TP}{P} = frac{TP}{TP + FN} $$
FPR (false positive rate) – это доля отрицательных объектов, неправильно предсказанных положительными:
$$FPR = frac{FP}{N} = frac{FP}{FP + TN}$$
Обе эти величины растут при уменьшении порога. Кривая в осях TPR/FPR, которая получается при варьировании порога, исторически называется ROC-кривой (receiver operating characteristics curve, сокращённо ROC curve). Следующий график поможет вам понять поведение ROC-кривой.
Желтая и синяя кривые показывают распределение предсказаний классификатора на объектах положительного и отрицательного классов соответственно. То есть значения на оси X (на графике с двумя гауссианами) мы получаем из классификатора. Если классификатор идеальный (две кривые разделимы по оси X), то на правом графике мы получаем ROC-кривую (0,0)->(0,1)->(1,1) (убедитесь сами!), площадь под которой равна 1. Если классификатор случайный (предсказывает одинаковые метки положительным и отрицательным объектам), то мы получаем ROC-кривую (0,0)->(1,1), площадь под которой равна 0.5. Поэкспериментируйте с разными вариантами распределения предсказаний по классам и посмотрите, как меняется ROC-кривая.
Чем лучше классификатор разделяет два класса, тем больше площадь (area under curve) под ROC-кривой – и мы можем использовать её в качестве метрики. Эта метрика называется AUC и она работает благодаря следующему свойству ROC-кривой:
AUC равен доле пар объектов вида (объект класса 1, объект класса 0), которые алгоритм верно упорядочил, т.е. предсказание классификатора на первом объекте больше:
$$
color{#348FEA}{operatorname{AUC} = frac{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j] I^{prime}[f(x_{i}) < f(x_{j})]}{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j]}}
$$
$$
I^{prime}left[f(x_{i}) < f(x_{j})right]=
left{
begin{array}{ll}
0, & f(x_{i}) > f(x_{j}) \
0.5 & f(x_{i}) = f(x_{j}) \
1, & f(x_{i}) < f(x_{j})
end{array}
right.
$$
$$
Ileft[y_{i}< y_{j}right]=
left{
begin{array}{ll}
0, & y_{i} geq y_{j} \
1, & y_{i} < y_{j}
end{array}
right.
$$
Чтобы детальнее разобраться, почему это так, советуем вам обратиться к материалам А.Г.Дьяконова.
В каких случаях лучше отдать предпочтение этой метрике? Рассмотрим следующую задачу: некоторый сотовый оператор хочет научиться предсказывать, будет ли клиент пользоваться его услугами через месяц. На первый взгляд кажется, что задача сводится к бинарной классификации с метками 1, если клиент останется с компанией и $0$ – иначе.
Однако если копнуть глубже в процессы компании, то окажется, что такие метки практически бесполезны. Компании скорее интересно упорядочить клиентов по вероятности прекращения обслуживания и в зависимости от этого применять разные варианты удержания: кому-то прислать скидочный купон от партнёра, кому-то предложить скидку на следующий месяц, а кому-то и новый тариф на особых условиях.
Таким образом, в любой задаче, где нам важна не метка сама по себе, а правильный порядок на объектах, имеет смысл применять AUC.
Утверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.
ПодробнееУтверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.» details=»Продемонстрируем это на следующем примере: пусть наша выборка состоит из $9100$ объектов класса $0$ и $10$ объектов класса $1$, и модель расположила их следующим образом:
$$underbrace{0 dots 0}_{9000} ~ underbrace{1 dots 1}_{10} ~ underbrace{0 dots 0}_{100}$$
Тогда AUC будет близка к единице: количество пар правильно расположенных объектов будет порядка $90000$, в то время как общее количество пар порядка $91000$.
Однако самыми высокими по вероятности положительного класса будут совсем не те объекты, которые мы ожидаем.
Average Precision
Будем постепенно уменьшать порог бинаризации. При этом полнота будет расти от $0$ до $1$, так как будет увеличиваться количество объектов, которым мы приписываем положительный класс (а количество объектов, на самом деле относящихся к положительному классу, очевидно, меняться не будет). Про точность же нельзя сказать ничего определённого, но мы понимаем, что скорее всего она будет выше при более высоком пороге отсечения (мы оставим только объекты, в которых модель «уверена» больше всего). Варьируя порог и пересчитывая значения Precision и Recall на каждом пороге, мы получим некоторую кривую примерно следующего вида:
 (источник картинки)
(источник картинки)
Рассмотрим среднее значение точности (оно равно площади под кривой точность-полнота):
$$ text { AP }=int_{0}^{1} p(r) d r$$
Получим показатель эффективности, который называется average precision. Как в случае матрицы ошибок мы переходили к скалярным показателям эффективности, так и в случае с кривой точность-полнота мы охарактеризовали ее в виде числа.
Многоклассовая классификация
Если классов становится больше двух, расчёт метрик усложняется. Если задача классификации на $K$ классов ставится как $K$ задач об отделении класса $i$ от остальных ($i=1,ldots,K$), то для каждой из них можно посчитать свою матрицу ошибок. Затем есть два варианта получения итогового значения метрики из $K$ матриц ошибок:
- Усредняем элементы матрицы ошибок (TP, FP, TN, FN) между бинарными классификаторами, например $TP = frac{1}{K}sum_{i=1}^{K}TP_i$. Затем по одной усреднённой матрице ошибок считаем Precision, Recall, F-меру. Это называют микроусреднением.
- Считаем Precision, Recall для каждого классификатора отдельно, а потом усредняем. Это называют макроусреднением.
Порядок усреднения влияет на результат в случае дисбаланса классов. Показатели TP, FP, FN — это счётчики объектов. Пусть некоторый класс обладает маленькой мощностью (обозначим её $M$). Тогда значения TP и FN при классификации этого класса против остальных будут не больше $M$, то есть тоже маленькие. Про FP мы ничего уверенно сказать не можем, но скорее всего при дисбалансе классов классификатор не будет предсказывать редкий класс слишком часто, потому что есть большая вероятность ошибиться. Так что FP тоже мало. Поэтому усреднение первым способом сделает вклад маленького класса в общую метрику незаметным. А при усреднении вторым способом среднее считается уже для нормированных величин, так что вклад каждого класса будет одинаковым.
Рассмотрим пример. Пусть есть датасет из объектов трёх цветов: желтого, зелёного и синего. Желтого и зелёного цветов почти поровну — 21 и 20 объектов соответственно, а синих объектов всего 4.
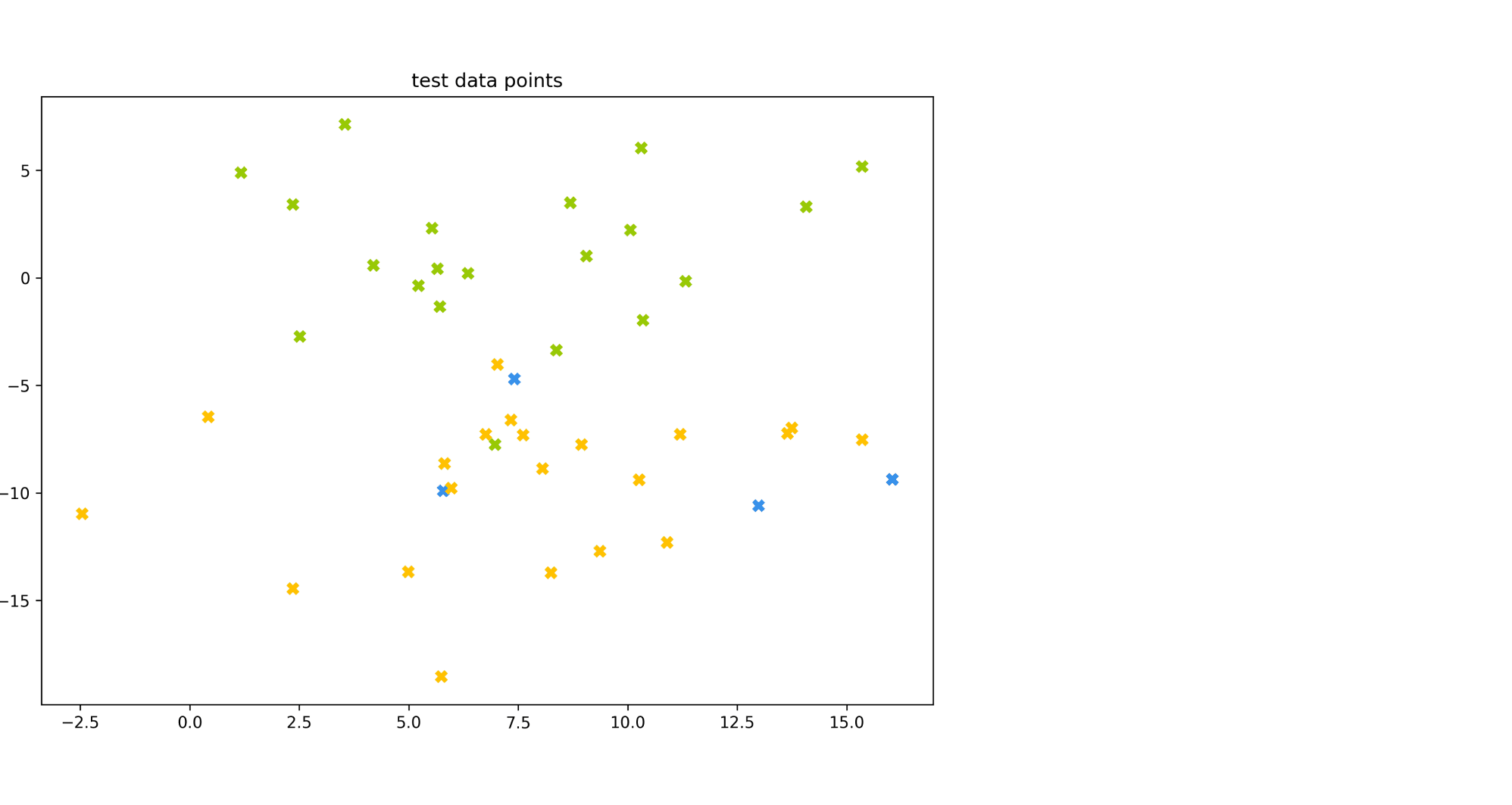
Модель по очереди для каждого цвета пытается отделить объекты этого цвета от объектов оставшихся двух цветов. Результаты классификации проиллюстрированы матрицей ошибок. Модель «покрасила» в жёлтый 25 объектов, 20 из которых были действительно жёлтыми (левый столбец матрицы). В синий был «покрашен» только один объект, который на самом деле жёлтый (средний столбец матрицы). В зелёный — 19 объектов, все на самом деле зелёные (правый столбец матрицы).
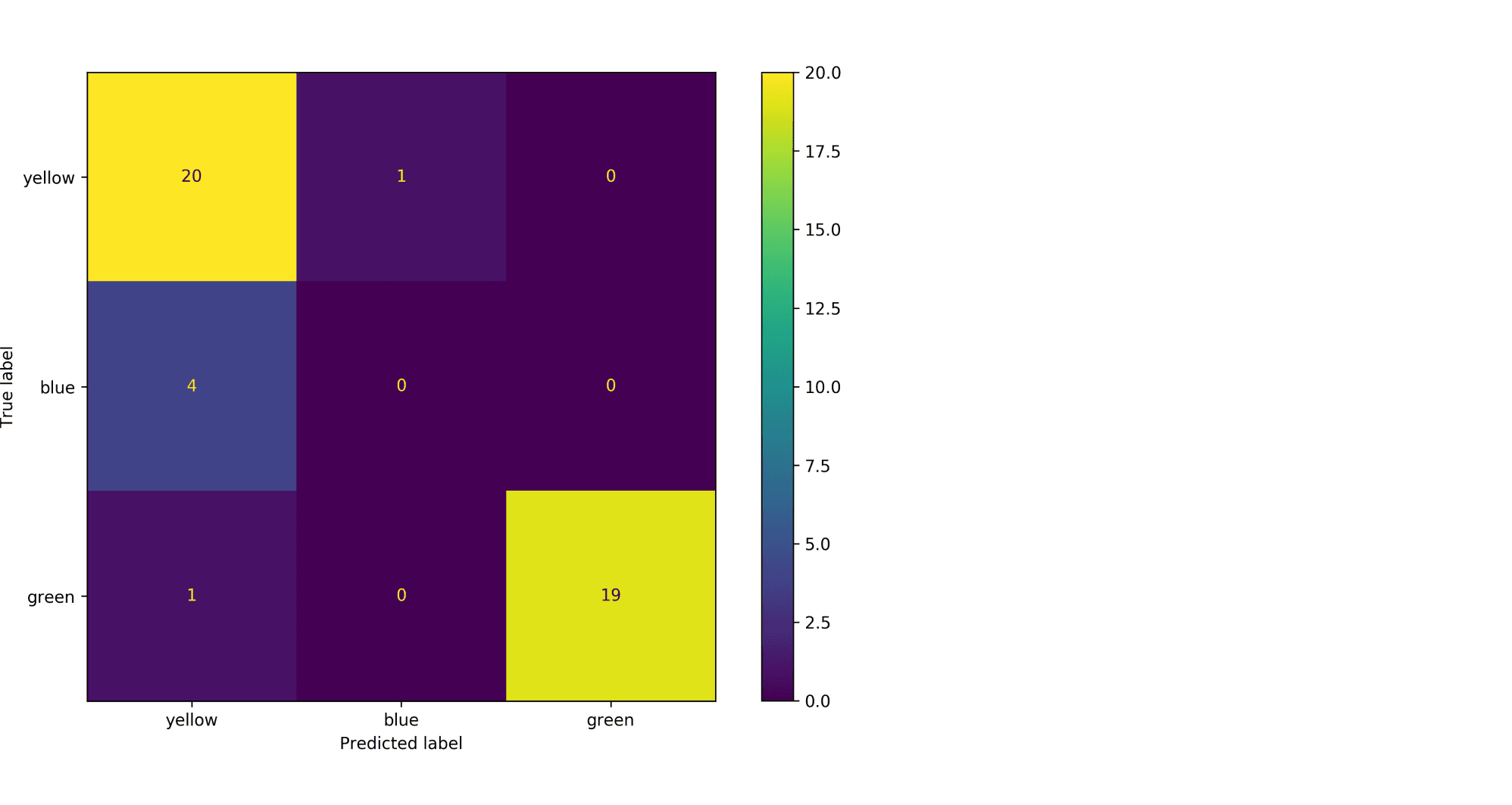
Посчитаем Precision классификации двумя способами:
- С помощью микроусреднения получаем $$
text{Precision} = frac{dfrac{1}{3}left(20 + 0 + 19right)}{dfrac{1}{3}left(20 + 0 + 19right) + dfrac{1}{3}left(5 + 1 + 0right)} = 0.87
$$ - С помощью макроусреднения получаем $$
text{Precision} = dfrac{1}{3}left( frac{20}{20 + 5} + frac{0}{0 + 1} + frac{19}{19 + 0}right) = 0.6
$$
Видим, что макроусреднение лучше отражает тот факт, что синий цвет, которого в датасете было совсем мало, модель практически игнорирует.
Как оптимизировать метрики классификации?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы $F$ на валидационной выборке была минимальная/максимальная. Лучший способ добиться минимизации метрики $F$ — оптимизировать её напрямую, то есть выбрать в качестве функции потерь ту же $F(a(X), Y)$. К сожалению, это не всегда возможно. Рассмотрим, как оптимизировать метрики иначе.
Метрики precision и recall невозможно оптимизировать напрямую, потому что эти метрики нельзя рассчитать на одном объекте, а затем усреднить. Они зависят от того, какими были правильная метка класса и ответ алгоритма на всех объектах. Чтобы понять, как оптимизировать precision, recall, рассмотрим, как расчитать эти метрики на отложенной выборке. Пусть модель обучена на стандартную для классификации функцию потерь (LogLoss). Для получения меток класса специалист по машинному обучению сначала применяет на объектах модель и получает вещественные предсказания модели ($p_i in left(0, 1right)$). Затем предсказания бинаризуются по порогу, выбранному специалистом: если предсказание на объекте больше порога, то метка класса 1 (или «положительная»), если меньше — 0 (или «отрицательная»). Рассмотрим, что будет с метриками precision, recall в крайних положениях порога.
- Пусть порог равен нулю. Тогда всем объектам будет присвоена положительная метка. Следовательно, все объекты будут либо TP, либо FP, потому что отрицательных предсказаний нет, $TP + FP = N$, где $N$ — размер выборки. Также все объекты, у которых метка на самом деле 1, попадут в TP. По формуле точность $text{Precision} = frac{TP}{TP + FP} = frac1N sum_{i = 1}^N mathbb{I} left[ y_i = 1 right]$ равна среднему таргету в выборке. А полнота $text{Recall} = frac{TP}{TP + FN} = frac{TP}{TP + 0} = 1$ равна единице.
- Пусть теперь порог равен единице. Тогда ни один объект не будет назван положительным, $TP = FP = 0$. Все объекты с меткой класса 1 попадут в FN. Если есть хотя бы один такой объект, то есть $FN ne 0$, будет верна формула $text{Recall} = frac{TP}{TP + FN} = frac{0}{0+ FN} = 0$. То есть при пороге единица, полнота равна нулю. Теперь посмотрим на точность. Формула для Precision состоит только из счётчиков положительных ответов модели (TP, FP). При единичном пороге они оба равны нулю, $text{Precision} = frac{TP}{TP + FP} = frac{0}{0 + 0}$то есть при единичном пороге точность неопределена. Пусть мы отступили чуть-чуть назад по порогу, чтобы хотя бы несколько объектов были названы моделью положительными. Скорее всего это будут самые «простые» объекты, которые модель распознает хорошо, потому что её предсказание близко к единице. В этом предположении $FP approx 0$. Тогда точность $text{Precision} = frac{TP}{TP + FP} approx frac{TP}{TP + 0} approx 1$ будет близка к единице.
Изменяя порог, между крайними положениями, получим графики Precision и Recall, которые выглядят как-то так:
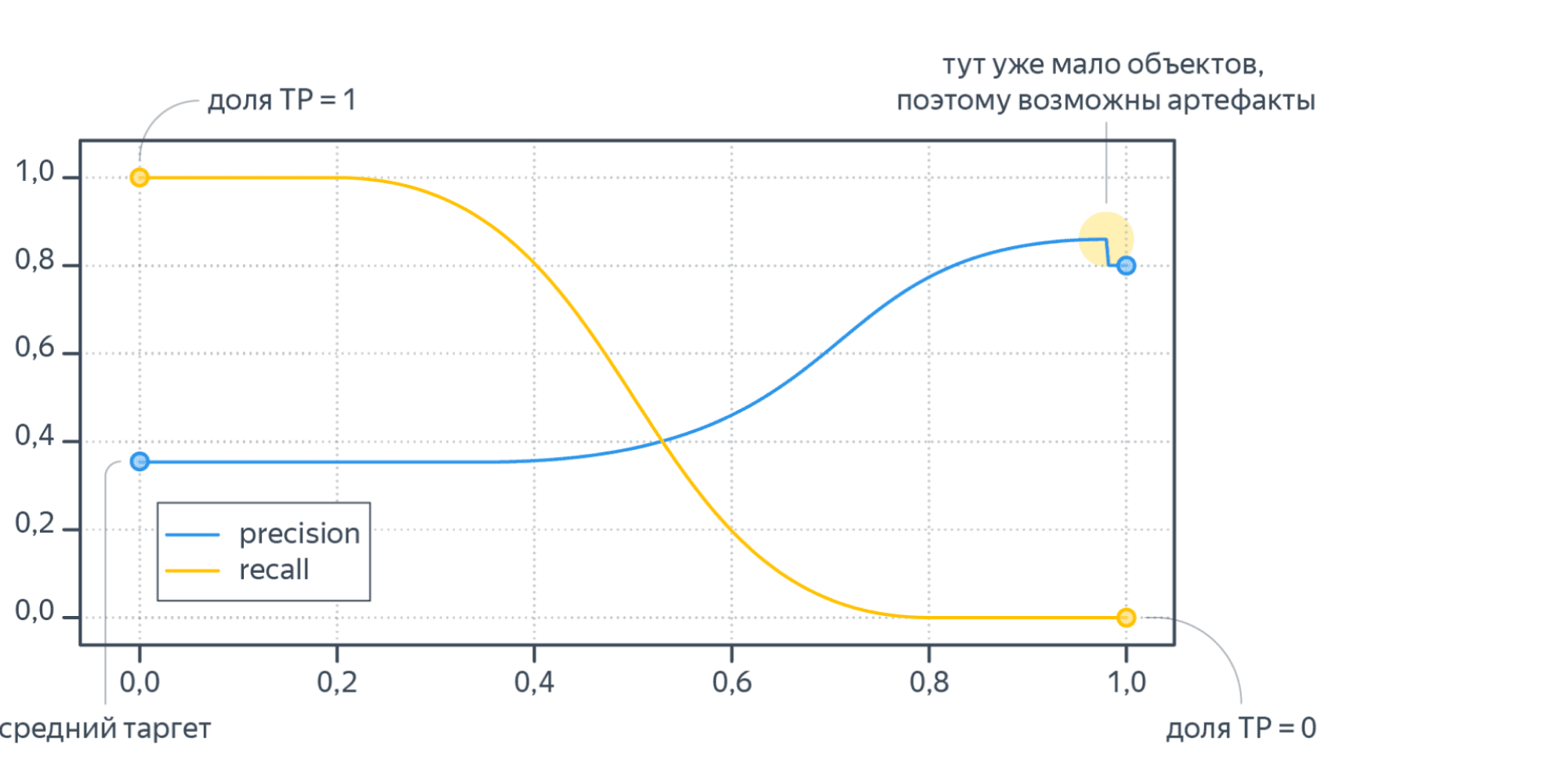
Recall меняется от единицы до нуля, а Precision от среднего тагрета до какого-то другого значения (нет гарантий, что график монотонный).
Итого оптимизация precision и recall происходит так:
- Модель обучается на стандартную функцию потерь (например, LogLoss).
- Используя вещественные предсказания на валидационной выборке, перебирая разные пороги от 0 до 1, получаем графики метрик в зависимости от порога.
- Выбираем нужное сочетание точности и полноты.
Пусть теперь мы хотим максимизировать метрику AUC. Стандартный метод оптимизации, градиентный спуск, предполагает, что функция потерь дифференцируема. AUC этим качеством не обладает, то есть мы не можем оптимизировать её напрямую. Поэтому для метрики AUC приходится изменять оптимизационную задачу. Метрика AUC считает долю верно упорядоченных пар. Значит от исходной выборки можно перейти к выборке упорядоченных пар объектов. На этой выборке ставится задача классификации: метка класса 1 соответствует правильно упорядоченной паре, 0 — неправильно. Новой метрикой становится accuracy — доля правильно классифицированных объектов, то есть доля правильно упорядоченных пар. Оптимизировать accuracy можно по той же схеме, что и precision, recall: обучаем модель на LogLoss и предсказываем вероятности положительной метки у объекта выборки, считаем accuracy для разных порогов по вероятности и выбираем понравившийся.
Регрессия
В задачах регрессии целевая метка у нас имеет потенциально бесконечное число значений. И природа этих значений, обычно, связана с каким-то процессом измерений:
- величина температуры в определенный момент времени на метеостанции
- количество прочтений статьи на сайте
- количество проданных бананов в конкретном магазине, сети магазинов или стране
- дебит добывающей скважины на нефтегазовом месторождении за месяц и т.п.
Мы видим, что иногда метка это целое число, а иногда произвольное вещественное число. Обычно случаи целочисленных меток моделируют так, словно это просто обычное вещественное число. При таком подходе может оказаться так, что модель A лучше модели B по некоторой метрике, но при этом предсказания у модели A могут быть не целыми. Если в бизнес-задаче ожидается именно целочисленный ответ, то и оценивать нужно огрубление.
Общая рекомендация такова: оценивайте весь каскад решающих правил: и те «внутренние», которые вы получаете в результате обучения, и те «итоговые», которые вы отдаёте бизнес-заказчику.
Например, вы можете быть удовлетворены, что стали ошибаться не во втором, а только в третьем знаке после запятой при предсказании погоды. Но сами погодные данные измеряются с точностью до десятых долей градуса, а пользователь и вовсе может интересоваться лишь целым числом градусов.
Итак, напомним постановку задачи регрессии: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_i in mathbb{R}$ построить модель f(x).
Величину $ e_i = f(x_i) — y_i $ называют ошибкой на объекте i или регрессионным остатком.
Весь набор ошибок на отложенной выборке может служить аналогом матрицы ошибок из задачи классификации. А именно, когда мы рассматриваем две разные модели, то, глядя на то, как и на каких объектах они ошиблись, мы можем прийти к выводу, что для решения бизнес-задачи нам выгоднее взять ту или иную модель. И, аналогично со случаем бинарной классификации, мы можем начать строить агрегаты от вектора ошибок, получая тем самым разные метрики.
MSE, RMSE, $R^2$
MSE – одна из самых популярных метрик в задаче регрессии. Она уже знакома вам, т.к. применяется в качестве функции потерь (или входит в ее состав) во многих ранее рассмотренных методах.
$$ MSE(y^{true}, y^{pred}) = frac1Nsum_{i=1}^{N} (y_i — f(x_i))^2 $$
Иногда для того, чтобы показатель эффективности MSE имел размерность исходных данных, из него извлекают квадратный корень и получают показатель эффективности RMSE.
MSE неограничен сверху, и может быть нелегко понять, насколько «хорошим» или «плохим» является то или иное его значение. Чтобы появились какие-то ориентиры, делают следующее:
-
Берут наилучшее константное предсказание с точки зрения MSE — среднее арифметическое меток $bar{y}$. При этом чтобы не было подглядывания в test, среднее нужно вычислять по обучающей выборке
-
Рассматривают в качестве показателя ошибки:
$$ R^2 = 1 — frac{sum_{i=1}^{N} (y_i — f(x_i))^2}{sum_{i=1}^{N} (y_i — bar{y})^2}.$$
У идеального решающего правила $R^2$ равен $1$, у наилучшего константного предсказания он равен $0$ на обучающей выборке. Можно заметить, что $R^2$ показывает, какая доля дисперсии таргетов (знаменатель) объяснена моделью.
MSE квадратично штрафует за большие ошибки на объектах. Мы уже видели проявление этого при обучении моделей методом минимизации квадратичных ошибок – там это проявлялось в том, что модель старалась хорошо подстроиться под выбросы.
Пусть теперь мы хотим использовать MSE для оценки наших регрессионных моделей. Если большие ошибки для нас действительно неприемлемы, то квадратичный штраф за них — очень полезное свойство (и его даже можно усиливать, повышая степень, в которую мы возводим ошибку на объекте). Однако если в наших тестовых данных присутствуют выбросы, то нам будет сложно объективно сравнить модели между собой: ошибки на выбросах будет маскировать различия в ошибках на основном множестве объектов.
Таким образом, если мы будем сравнивать две модели при помощи MSE, у нас будет выигрывать та модель, у которой меньше ошибка на объектах-выбросах, а это, скорее всего, не то, чего требует от нас наша бизнес-задача.
История из жизни про бананы и квадратичный штраф за ошибкуИз-за неверно введенных данных метка одного из объектов оказалась в 100 раз больше реального значения. Моделировалась величина при помощи градиентного бустинга над деревьями решений. Функция потерь была MSE.
Однажды уже во время эксплуатации случилось ч.п.: у нас появились предсказания, в 100 раз превышающие допустимые из соображений физического смысла значения. Представьте себе, например, что вместо обычных 4 ящиков бананов система предлагала поставить в магазин 400. Были распечатаны все деревья из ансамбля, и мы увидели, что постепенно число ящиков действительно увеличивалось до прогнозных 400.
Было решено проверить гипотезу, что был выброс в данных для обучения. Так оно и оказалось: всего одна точка давала такую потерю на объекте, что алгоритм обучения решил, что лучше переобучиться под этот выброс, чем смириться с большим штрафом на этом объекте. А в эксплуатации у нас возникли точки, которые плюс-минус попадали в такие же листья ансамбля, что и объект-выброс.
Избежать такого рода проблем можно двумя способами: внимательнее контролируя качество данных или адаптировав функцию потерь.
Аналогично, можно поступать и в случае, когда мы разрабатываем метрику качества: менее жёстко штрафовать за большие отклонения от истинного таргета.
MAE
Использовать RMSE для сравнения моделей на выборках с большим количеством выбросов может быть неудобно. В таких случаях прибегают к также знакомой вам в качестве функции потери метрике MAE (mean absolute error):
$$ MAE(y^{true}, y^{pred}) = frac{1}{N}sum_{i=1}^{N} left|y_i — f(x_i)right| $$
Метрики, учитывающие относительные ошибки
И MSE и MAE считаются как сумма абсолютных ошибок на объектах.
Рассмотрим следующую задачу: мы хотим спрогнозировать спрос товаров на следующий месяц. Пусть у нас есть два продукта: продукт A продаётся в количестве 100 штук, а продукт В в количестве 10 штук. И пусть базовая модель предсказывает количество продаж продукта A как 98 штук, а продукта B как 8 штук. Ошибки на этих объектах добавляют 4 штрафных единицы в MAE.
И есть 2 модели-кандидата на улучшение. Первая предсказывает товар А 99 штук, а товар B 8 штук. Вторая предсказывает товар А 98 штук, а товар B 9 штук.
Обе модели улучшают MAE базовой модели на 1 единицу. Однако, с точки зрения бизнес-заказчика вторая модель может оказаться предпочтительнее, т.к. предсказание продажи редких товаров может быть приоритетнее. Один из способов учесть такое требование – рассматривать не абсолютную, а относительную ошибку на объектах.
MAPE, SMAPE
Когда речь заходит об относительных ошибках, сразу возникает вопрос: что мы будем ставить в знаменатель?
В метрике MAPE (mean absolute percentage error) в знаменатель помещают целевое значение:
$$ MAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ left|y_i — f(x_i)right|}{left|y_iright|} $$
С особым случаем, когда в знаменателе оказывается $0$, обычно поступают «инженерным» способом: или выдают за непредсказание $0$ на таком объекте большой, но фиксированный штраф, или пытаются застраховаться от подобного на уровне формулы и переходят к метрике SMAPE (symmetric mean absolute percentage error):
$$ SMAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ 2 left|y_i — f(x_i)right|}{y_i + f(x_i)} $$
Если же предсказывается ноль, штраф считаем нулевым.
Таким переходом от абсолютных ошибок на объекте к относительным мы сделали объекты в тестовой выборке равнозначными: даже если мы делаем абсурдно большое предсказание, на фоне которого истинная метка теряется, мы получаем штраф за этот объект порядка 1 в случае MAPE и 2 в случае SMAPE.
WAPE
Как и любая другая метрика, MAPE имеет свои границы применимости: например, она плохо справляется с прогнозом спроса на товары с прерывистыми продажами. Рассмотрим такой пример:
| Понедельник | Вторник | Среда | |
|---|---|---|---|
| Прогноз | 55 | 2 | 50 |
| Продажи | 50 | 1 | 50 |
| MAPE | 10% | 100% | 0% |
Среднее MAPE – 36.7%, что не очень отражает реальную ситуацию, ведь два дня мы предсказывали с хорошей точностью. В таких ситуациях помогает WAPE (weighted average percentage error):
$$ WAPE(y^{true}, y^{pred}) = frac{sum_{i=1}^{N} left|y_i — f(x_i)right|}{sum_{i=1}^{N} left|y_iright|} $$
Если мы предсказываем идеально, то WAPE = 0, если все предсказания отдаём нулевыми, то WAPE = 1.
В нашем примере получим WAPE = 5.9%
RMSLE
Альтернативный способ уйти от абсолютных ошибок к относительным предлагает метрика RMSLE (root mean squared logarithmic error):
$$ RMSLE(y^{true}, y^{pred}| c) = sqrt{ frac{1}{N} sum_{i=1}^N left(vphantom{frac12}log{left(y_i + c right)} — log{left(f(x_i) + c right)}right)^2 } $$
где нормировочная константа $c$ вводится искусственно, чтобы не брать логарифм от нуля. Также по построению видно, что метрика пригодна лишь для неотрицательных меток.
Веса в метриках
Все вышеописанные метрики легко допускают введение весов для объектов. Если мы из каких-то соображений можем определить стоимость ошибки на объекте, можно брать эту величину в качестве веса. Например, в задаче предсказания спроса в качестве веса можно использовать стоимость объекта.
Доля предсказаний с абсолютными ошибками больше, чем d
Еще одним способом охарактеризовать качество модели в задаче регрессии является доля предсказаний с абсолютными ошибками больше заданного порога $d$:
$$frac{1}{N} sum_{i=1}^{N} mathbb{I}left[ left| y_i — f(x_i) right| > d right] $$
Например, можно считать, что прогноз погоды сбылся, если ошибка предсказания составила меньше 1/2/3 градусов. Тогда рассматриваемая метрика покажет, в какой доле случаев прогноз не сбылся.
Как оптимизировать метрики регрессии?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы F на валидационной выборке была минимальная/максимальная. Аналогично задачам классификации лучший способ добиться минимизации метрики $F$ — выбрать в качестве функции потерь ту же $F(a(X), Y)$. К счастью, основные метрики для регрессии: MSE, RMSE, MAE можно оптимизировать напрямую. С формальной точки зрения MAE не дифференцируема, так как там присутствует модуль, чья производная не определена в нуле. На практике для этого выколотого случая в коде можно возвращать ноль.
Для оптимизации MAPE придётся изменять оптимизационную задачу. Оптимизацию MAPE можно представить как оптимизацию MAE, где объектам выборки присвоен вес $frac{1}{vert y_ivert}$.