Механизмы исправления ошибок во время репликации ДНК и ее репарация вследствие повреждений на протяжении всего жизненного цикла клетки.
Основные моменты:
-
Клетки имеют различные механизмы предотвращения возникновения мутаций – необратимых изменений в ДНК
-
В процессе синтеза ДНК, большинство ДНК-полимераз «проверяют свою работу» и проводят замену бо́льшей части ошибочно вставленных нуклеотидов. Этот процесс можно назвать исправлением ошибок.
-
Сразу после синтеза ДНК любые оставшиеся ошибочные нуклеотиды обнаруживаются и заменяются в так называемом процессе репарации ошибочно спаренных нуклеотидов.
-
Если ДНК повреждена, она может быть восстановлена с помощью различных механизмов, например, путём прямой репарации, эксцизионной репарации или путём восстановления двухцепочечных разрывов
- пострепликативной репарации.
Введение
Как ДНК связана с раком? Рак возникает при неконтролируемом делении клеток, когда игнорируются клеточные «стоп»-сигналы, что приводит к образованию опухоли. Это неправильное поведение клеток вызвано накопившимися мутациями — необратимыми изменениями последовательности ДНК клетки.
На самом деле, ошибки в процессе репликации и повреждения ДНК возникают в клетках нашего тела постоянно. Однако в большинстве случаев они не приводят к раку и даже не вызывают мутаций, такие ошибки обычно обнаруживаются и исправляются в процессе репарации ДНК. Если же повреждение исправить не удаётся, то в клетке включается механизм самоуничтожения — (апоптоз), который предотвращает передачу поврежденной ДНК дочерним клеткам.
Мутации возникают и передаются дочерним клеткам только тогда, когда эти механизмы не справляются. В частности, рак возникает в случае накопившихся в одной клетке мутаций генов, связанных с делением.
В этой статье мы подробно рассмотрим механизмы, используемые клетками для исправления ошибок, которые возникают в процессе репликации. К ним относятся:
-
Исправление ошибок – процесс, который возникает во время репликации ДНК.
-
Репарация ошибочно спаренных нуклеотидов, которая происходит сразу же после репликации ДНК.
-
Механизмы репарации, которые выявляют и исправляют повреждения ДНК на протяжении всего клеточного цикла
Исправление ошибок
ДНК-полимеразы — это ферменты, участвующие в репликации ДНК. Во время копирования ДНК большинство ДНК-полимераз «проверяют», корректный ли нуклеотид они добавляют. Этот процесс называется исправлением ошибок. Если полимераза обнаружит, что был добавлен неправильный нуклеотид, она сразу же удалит и заменит его и только после этого продолжит синтез ДНКstart superscript, 1, end superscript.
Репарация ошибочно спаренных нуклеотидов
Процесс исправления избавляет от основной массы ошибок, но не от всех. После создания новой ДНК запускается механизм репарации ошибочно спаренных нуклеотидов — удаления и замены ошибочно спаренных нуклеотидов, оставшихся в результате репликации. Исправление несоответствий между парами оснований также может включать в себя исправление небольших вставок и делеций, возникающих вследствие «соскальзывания» полимеразы с исходной цепи squared.
Как происходит восстановление неправильно спаренных нуклеотидов? Во-первых, белковый комплекс распознаёт неправильно спаренный нуклеотид и связывается с ним. Другой комплекс разрезает ДНК в области несовпадения, а ещё одна группа ферментов отщепляет некорректный нуклеотид вместе с небольшим участком вокруг него. Затем ДНК-полимераза заполняет этот пробел правильными нуклеотидами, а фермент ДНК-лигаза сшивает разрывы в цепиsquared.
Удивительно: как белки, участвующие в восстановлении ДНК, определяют, «кто прав» во время репарации ошибочно спаренных нуклеотидов? То есть, когда два основания неправильно соединены (как G (гуанин) и T (тимин) на рисунке выше), какое из этих двух оснований должно быть удалено и заменено?
У бактерий можно отличить исходную и дочернюю цепи ДНК по метилированным основаниям. На исходной цепи ДНК есть метильные (minus, start text, C, H, end text, start subscript, 3, end subscript) группы, присоединенные к некоторым из ее оснований, а у дочерней цепи таких групп еще нетcubed.
У эукариот процессы, позволяющие идентифицировать исходную цепь при устранении несоответствий, включают распознавание одноцепочечных разрывов, которые обнаруживаются только у дочерней цепи cubed.
Механизмы репарации ДНК
С ДНК может что-нибудь случиться практически в любой момент жизни клетки, а не только во время репликации. Фактически, ДНК постоянно повреждается из-за воздействия внешних факторов: ультрафиолетового излучения и радиации, химических веществ, не говоря уже о спонтанных процессах, которые протекают даже без вмешательства окружающей среды!start superscript, 4, end superscript
К счастью, наши клетки имеют механизмы восстановления, с помощью которых они находят и исправляют большинство повреждений ДНК. Можно выделить несколько типов репарации:
-
Прямая репарация. Некоторые повреждения ДНК, вызванные химическими реакциями, могут быть «исправлены» находящимися в клетке ферментами.
-
Эксцизионная репарация. Повреждение одного или нескольких нуклеотидов ДНК часто исправляется удалением и заменой поврежденного участка. При эксцизионной репарации оснований удаляется только поврежденное основание. В случае эксцизионной репарации нуклеотидов, как и в случае репарации ошибочно спаренных нуклеотидов, которое мы рассмотрели выше, удаляются целиком нуклеотиды.
-
Репарация двухцепочечных разрывов: Существуют два основных способа: негомологичное соединение концов и гомологичная рекомбинация. Они используются для восстановления двухцепочечных разрывов ДНК (когда вся хромосома разделяется на две части).
Прямая репарация
В некоторых случаях клетка может исправить повреждение ДНК, обратив вызвавшую его реакцию. Дело в том, что «повреждение ДНК» — это, как правило, присоединение к ней лишней группы в результате химической реакции.
Например, гуанин (G) может подвергаться реакции с присоединением метильной (minus, start text, C, H, end text, start subscript, 3, end subscript) группы к атому кислорода в азотистом основании. Если это не исправить, метил-содержащий гуанин будет связываться с тимином (Т), а не с цитозином (С) во время репликации ДНК. К счастью, у людей и многих других организмов есть фермент, который может удалить метильную группу, обратив реакцию, и тем самым вернуть азотистое основание в нормальное состояниеstart superscript, 5, end superscript.
Эксцизионная репарация оснований
Эксцизионная репарация оснований — это механизм, используемый для обнаружения и удаления определенных типов поврежденных азотистых оснований. Ключевую роль в нем играет группа ферментов, называемых гликозилазами. Каждая гликозилаза обнаруживает и удаляет определенный вид поврежденных оснований.
Например, в процессе реакции дезаминирования цитозин может превратиться в урацил — основание, обычно встречающееся только в РНК. Во время репликации ДНК урацил будет соединяться с аденином, а не с гуанином (в отличие от цитозина), поэтому такое превращение может привести к возникновению мутацииstart superscript, 5, end superscript.
Для предотвращения подобных изменений гликозилаза, являющаяся частью сигнального пути эксцизионной репарации, обнаруживает и удаляет дезаминированные цитозины. После того, как основание было удалено, удаляется и оставшаяся часть нуклеотида, а другие ферменты заполняют пробелstart superscript, 6, end superscript.
Эксцизионная репарация нуклеотидов
Эксцизионная репарация нуклеотидов — это еще один способ удаления и замены поврежденных оснований. В результате нее обнаруживаются и корректируются повреждения, которые искажают форму двойной спирали ДНК. Например, азотистые основания могут измениться, присоединив к себе громоздкие группы атомов, в частности, в результате воздействия химических веществ, содержащихся в сигаретном дымеstart superscript, 7, end superscript.
Эксцизионная репарация нуклеотидов также используется для устранения повреждений, вызванных ультрафиолетовым излучением, например, при получении солнечного ожога. Под воздействием УФ-излучения цитозин и тимин могут вступать в реакцию с соседними основаниями, которые также являются цитозином или тимином, образуя при этом связи, изменяющие форму двойной спирали и вызывающие ошибки в процессе репликации ДНК. Наиболее распространенный тип таких связей — тиминовый димер — он состоит из двух тиминовых оснований, вступающих в реакцию друг с другом и образующих химическую связьstart superscript, 8, end superscript.
При эксцизионной репарации нуклеотидов поврежденные нуклеотиды удаляются вместе с соседними нуклеотидами. В этом процессе хеликаза (фермент, раскручивающий ДНК) раскрывает ДНК, образуя пузырь, а ферменты, разрезающие ДНК, отсекают поврежденную часть пузыря. Полимераза заполняет пробел, а лигаза сшивает разрыв в цепиstart superscript, 9, end superscript.
Репарация двухцепочечных разрывов
Некоторые факторы окружающей среды, например, радиация, могут вызывать разрывы обеих цепочек ДНК (разделение хромосомы на две части). Такие повреждения ДНК, если верить комиксам, ведут к появлению супергероев, но могут встречаться и после реальных катастроф, например, Чернобыльской.
Двухцепочечные разрывы опасны, потому что большие сегменты хромосом и сотни содержащихся в них генов могут быть потеряны, если разрыв не будет восстановлен. Существует два способа восстановления двухцепочечных разрывов ДНК: негомологичное соединение концов и гомологичная рекомбинация.
При негомологичном соединении концов два разорванных конца хромосомы просто склеиваются обратно. Этот механизм восстановления является «грубым» и неточным, в результате в месте разрыва, как правило, либо теряются нуклеотиды, либо добавляются лишние, что может привести к мутациям. Но это в любом случае лучше потери целого фрагмента хромосомыstart superscript, 10, end superscript.
При гомологичной рекомбинации для восстановления разрыва используется фрагмент из гомологичной хромосомы, который соответствует поврежденной хромосоме (или из сестринской хроматиды, если ДНК была реплицирована). В этом процессе две хромосомы объединяются, и неповрежденная область гомологичной хромосомы или хроматиды используется в качестве матрицы для замены поврежденной области. Гомологичная рекомбинация работает «чище», точнее, чем негомологичное соединение концов, и обычно не приводит к образованию мутацийstart superscript, 11, end superscript.
Репарация ДНК и заболевания человека
Доказательства важности механизмов репарации получены на основе генетических заболеваний человека. Во многих случаях мутации в генах, которые кодируют белки, участвующие в репарации, связаны с наследственным раком. Например:
-
Наследственный неполипозный колоректальный рак (также называемый синдромом Линча) вызван мутациями в генах, кодирующих белки, которые участвуют в репарации ошибочно спаренных нуклеотидовstart superscript, 12, comma, 13, end superscript. Поскольку такие нуклеотиды не восстанавливаются, у людей, страдающих этим синдромом, мутации накапливаются гораздо быстрее, чем у здоровых. Это может привести к развитию опухолей толстой кишки.
-
Люди с пигментной ксеродермой очень чувствительны к ультрафиолетовому излучению. Это вызвано мутациями в белках, участвующих в эксцизионной репарации нуклеотидов. Когда они не функционируют, димеры тимина и другие виды повреждений, вызванные ультрафиолетовым излучением, перестают восстанавливаться. У людей с пигментной ксеродермой после нескольких минут пребывания на солнце могут возникнуть сильные солнечные ожоги, и около половины из них заболевают раком кожи в возрасте до 10 лет, если только они не избегают солнечных лучейstart superscript, 14, end superscript.
Макеты страниц
Было установлено, что частота ошибок при репликации ДНК Е. coli не превышает 1 на  нуклеотидов. Поскольку хромосома Е. coli содержит приблизительно
нуклеотидов. Поскольку хромосома Е. coli содержит приблизительно  пар оснований, на 10000 клеток, претерпевших один цикл деления, встраивается всего один неправильный нуклеотид.
пар оснований, на 10000 клеток, претерпевших один цикл деления, встраивается всего один неправильный нуклеотид.
Долгое время считалось, что столь высокая степень точности воспроизведения генетической информации целиком определяется точностью уотсон-криковского спаривания между матричной и новообразованной (дочерней) цепями, однако в результате последующего анализа выяснилось, что если бы точность репликации зависела исключительно от правильности спаривания оснований, то частота ошибок была бы значительно выше — приблизительно 1 на 104-105 остатков. Следовательно, чтобы объяснить такую низкую частоту ошибок при репликации in vivo, необходимо предположить участие в процессе репликации еще какого-то одного или нескольких факторов.
Более детальное изучение свойств высокоочищенных ДНК-полимераз позволило получить по крайней мере частичный ответ на вопрос о природе этих факторов. Напомним, что ДНК-полимеразы I и III обладают тремя различными ферментативными активностями. Мы уже видели, как фермент функционирует в качестве полимеразы, а также как он может удалять нуклеотидные остатки с 5-конца фрагмента ДНК. Однако 3-экзонуклеазная активность ДНК-полимераз I и III очень озадачивала исследователей, ибо она означала, что эти ферменты способны «пятиться», отщепляя З-концевые нуклеотиды в направлении, противоположном тому, в котором они действуют как полимеразы. З-экзону-клеазная активность ДНК-полимераз I и III — это средство проверки новосинтезированной цепи ДНК и исправления ошибок, сделанных ферментом при его работе в качестве полимеразы. Если ДНК-полимераза встраивает неправильный нуклеотид, то фермент сам может распознать неспособность этого нуклеотида образовать правильную пару с соответствующим нуклеотидом матрицы (рис. 28-15). В этом случае фермент возвращается назад и отщепляет неправильный нуклеотид с З-конца цепи, после чего полимераза продолжает присоединять правильные нуклеотиды, т.е. возобновляет свое обычное продвижение в направлении 

Рис. 28-15. Исправление ошибок с помощью 3-зкзонуклеазной активности ДНК-полимеразы.
Таким образом, по мере перемещения репликативной вилки вдоль матрицы осуществляется проверка каждого встроенного нуклеотида. Корректирующее действие ДНК-полимеразы очень эффективно; благодаря ему точность репликации повышается как минимум в 104 раз. Суммарная ошибка возникает в результате ошибок, допускаемых ферментом в ходе полимеризации и в процессе исправления их при корректировке; она не превышает одной ошибки на  нуклеотидных остатков.
нуклеотидных остатков.
Очень важно отметить, что процесс репликации протекает со значительно более высокой степенью точности, чем процессы транскрипции и трансляции. Частые ошибки в репликации подвергли бы большому риску сохранность видов и их жизнеспособность.
Ошибки же в транскрипции и трансляции гораздо менее опасны, поскольку они влияют на образование РНК или белка только в одной клетке и не изменяют всю последующую родословную вида. Корректировка с помощью ДНК-полимеразы — это, вероятно, лишь один из путей, обеспечивающих высокую точность репликации. Возможно, исключительно сложная организация репликативного процесса и участие в нем множества белков необходимы для достижения именно этой цели. Интересно, что некоторые эукариотические ДНК-полимеразы не осуществляют корректировку. По-видимому, эукариоты обеспечивают точность и надежность процесса репликации с помощью каких-то других средств.
Полимеразная цепная реакция почти для каждого из нас стала обыденностью, даже если этот каждый никогда и слов таких не слышал. Медицинские центры наперебой предлагают диагностировать у вас все мыслимые болезни с помощью «ПЦР-анализа». Но задумывались ли вы о том, что это за анализ? как там всё работает? для чего еще применяют ПЦР? и есть ли какие-то альтернативные, менее дорогие, трудоёмкие и, может быть, более эффективные методы анализа? Нет? А мы вам всё равно об этом расскажем…

12 биологических методов в картинках

Генеральный партнер цикла — компания «Диаэм»: крупнейший поставщик оборудования, реагентов и расходных материалов для биологических исследований и производств.
Партнер этой статьи — Bio-Rad
![]()
Компания Bio-Rad Laboratories, Inc. USA («Био-Рад», США) является одним из мировых лидеров производства оборудования и реагентов для научных исследований. В рамках взаимодействия с научными, медицинскими, биотехнологическими и образовательными организациями «Био-Рад» предлагает современные технологии, оборудование и реагенты.
Одна из главных миссий «Биомолекулы» — докопаться до самых корней. Мы не просто рассказываем, какие новые факты обнаружили исследователи — мы говорим о том, как они их обнаружили, стараемся объяснить принципы биологических методик. Как вытащить ген из одного организма и вставить в другой? Как проследить в огромной клетке за судьбой нескольких крошечных молекул? Как возбудить одну крохотную группу нейронов в огромном мозге?
И вот мы решили рассказать о лабораторных методах более системно, собрать воедино в одной рубрике самые главные, самые современные биологические методики. Чтоб было интереснее и нагляднее, мы густо проиллюстрировали статьи и даже кое-где добавили анимации. Мы хотим, чтобы статьи новой рубрики были интересны и понятны даже случайному прохожему. И с другой стороны — чтобы они были так подробны, что даже профессионал мог бы обнаружить в них что-то новое. Мы собрали методики в 12 больших групп и собираемся сделать на их основе биометодический календарь. Ждите обновлений!
Полимеразная цепная реакция (ПЦР, PCR) — метод молекулярной биологии, позволяющий создать копии определенного фрагмента ДНК из исходного образца, повысив его содержание в пробе на несколько порядков.
Изобретение ПЦР полностью и безвозвратно изменило медицину, науку и нашу жизнь в целом. Появилась возможность быстро и эффективно диагностировать наследственные заболевания и инфекции, определять личность преступников по одному волоску и свободно манипулировать генами. Не будь этого уникального метода, человечество вряд ли оказалось бы на пороге эпохи генной терапии.
История метода

Рисунок 1. История развития метода ПЦР. 1957 г. Американец Артур Корнберг выделил из бактерий Escherichia coli фермент ДНК-полимеразу. 1971 г. Норвежец Хьелль Клеппе опубликовал в Journal of Molecular Biology статью, в которой описал метод, очень похожий на ПЦР. 1976 г. Ученые из США — Эллис Чиен, Дэвид Эдгар и Джон Трела — выделили термостабильную ДНК-полимеразу из бактерии Thermus aquaticus и назвали ее Taq-полимеразой. 1977 г. Англичанин Фредерик Сенгер предложил свой метод секвенирования ДНК. 1983 г. Американец Кэри Мюллис изобрел и протестировал метод ПЦР. 1985 г. Появился первый прототип ПЦР-циклера — Mr. Cycle. 1987 г. Компания Cetus получила патент на метод ПЦР. 1988 г. Первое упоминание о ПЦР с обратной транскрипцией в журнале Science. 1990 г. Компания Cetus получила патент на метод ПЦР с Taq-полимеразой. 1991 г. Права на метод ПЦР и использование Taq-полимеразы купила компания Hoffman-La Roche за $300 млн. 1992 г. Сотрудники Roche Molecular Systems разработали метод ПЦР в реальном времени. 1992 г. Ученые из Калифорнийского университета в Беркли создали технологию иммуно-ПЦР. 1993 г. Кэри Мюллис стал лауреатом Нобелевской премии по химии за изобретение ПЦР. 2000 г. В Японии предложили метод опосредованной образованием петель изотермической амплификации (LAMP) как альтернативу стандартной ПЦР. 2004 г. Сотрудники компании New England Biolabs (NEB) разработали технологию хеликазозависимой амплификации. 2006 г. Британские ученые из TwistDX LTD разработали метод изотермической рекомбиназной полимеразной амплификации. 2011 г. Компания BioRad начала коммерческое использование технологии капельной цифровой ПЦР.
Чтобы увидеть рисунок в полном размере, нажмите на него.
1957 г. Американец Артур Корнберг впервые выделил из бактерий Escherichia coli фермент, который назвал ДНК-полимеразой [1]. Статьи с описанием работы он отправил в Journal of Biological Chemistry, где их отвергли… из-за названия фермента: рецензенты считали, что нужно использовать более точный термин «полидезоксирибонуклеотидполимераза» и что вообще «ДНК» в названии указывает на «генетическую активность» (сущность, составляющую?) фермента, а раз ее нет, то и называть фермент так нельзя [2]. Однако в 1958 году в журнале сменился главный редактор, и статьи наконец увидели свет [3]. А уже в 1959 году Артура Корнберга удостоили Нобелевской премии по физиологии и медицине.
1971 г. Норвежский биохимик Хьелль Клеппе (рис. 2) опубликовал в Journal of Molecular Biology статью, в которой описал метод, очень похожий на ПЦР [4]. С 1968 по 1970 годы Клеппе работал постдоком в Университете Висконсина, в лаборатории Хара Гобинда Кораны — нобелевского лауреата 1968 года за расшифровку генетического кода. Именно в лаборатории знаменитого индийца чуть раньше разработали методики синтеза олигонуклеотидных праймеров — «затравок», необходимых для работы ДНК-полимеразы.

Рисунок 2. Хьелль Клеппе.
Статья, написанная Клеппе в соавторстве с Кораной и посвященная репарационной репликации с помощью ДНК-полимеразы, содержала такие строки: «Можно ожидать, что после охлаждения получатся две структуры, каждая из которых содержит полноразмерную матричную цепь, подобающим образом связанную с праймером. Для завершения процесса репаративной репликации нужно будет добавить ДНК-полимеразу. В результате получатся уже две молекулы исходного дуплекса. Цикл можно повторять, каждый раз добавляя свежую порцию фермента».
К сожалению, эта гипотеза так гипотезой и осталась. Может, Клеппе даже и проводил какие-то эксперименты, но результаты не публиковал.
1976 г. Ученые из США, Эллис Чиен, Дэвид Эдгар и Джон Трела, выделили термостабильную ДНК-полимеразу из бактерии Thermus aquaticus и назвали ее Taq-полимеразой [5]. Этот фермент сохранял активность даже при температурах выше 75 °С.
1977 г. Фредерик Сенгер, английский биохимик и лауреат Нобелевской премии 1958 года за работы по структуре белков [6], предложил метод секвенирования ДНК, сейчас известный как метод Сенгера [7], [8]. Этим он заработал еще одну нобелевскую медаль, в 1980-м, и стал единственным ученым в истории, получившим две «химических» премии [9].
1983 г. Руководитель лаборатории синтеза ДНК в Cetus Corporation (США) Кэри Мюллис (рис. 3) апрельской ночью ехал вдоль побережья из Сан-Франциско в Мендосино, в свой загородный дом. Долгой трехчасовой дорогой он обдумывал отнюдь не проведение выходных, а предстоящий эксперимент по секвенированию ДНК. И тут (по словам Мюллиса) его озарило: он ясно представил процесс амплификации (преумножения) генов, который позже получит название полимеразной цепной реакции.

До работы в Cetus Кэри Мюллис изучал химию в Технологическом институте Джорджии, затем биохимию в Калифорнийском университете в Беркли, а после работал постдоком в Калифорнийском университете Сан-Франциско по направлению «фармацевтическая химия». В 1979 году его пригласили в Cetus синтезировать праймеры для секвенирования, а уже через два года Мюллис возглавил лабораторию синтеза ДНК и автоматизировал производство олигонуклеотидов [10].

Рисунок 3. Кэри Мюллис.
В 1983 году Мюллис участвовал в проекте по изучению серповидноклеточной анемии. Чтобы проанализировать мутации, биологи проводили секвенирование по Сэнгеру, где используется один праймер для синтеза по одной из цепей ДНК. На серпантине по пути в Мендосино Мюллис предположил, что данные будут точнее, если использовать два праймера — для синтеза одновременно по двум цепям. Тогда можно будет сравнить получившиеся фрагменты и исключить неточности. И вот тут-то неожиданное прозрение заставило его вздрогнуть: если повторить цикл несколько раз, то можно получить множество копий нужного фрагмента строго определенной длины — она будет ограничена праймерами, от концов которых навстречу друг другу и будут строиться новые цепи ДНК [11]!
Вернувшись в понедельник в Cetus, Кэри Мюллис сразу направился в библиотеку, где попросил одного из сотрудников найти всю литературу о ДНК-полимеразе. В результате он не обнаружил ничего, касающегося амплификации. Это утверждение — самое слабое место во всей истории, так как в собранной библиотекарем стопке статей просто не могло не быть работы Хьелля Клеппе.
За следующие полгода Мюллис провел два эксперимента для проверки своей гипотезы, но безуспешно. Тогда он предположил, что отрицательный результат связан с большим размером ДНК-матрицы, используемой в опытах, и решил продолжить работу с маленьким вектором pBR322, в который вставил намножаемый ген. И 16 декабря 1983 года Мюллис впервые увидел вожделенные, хоть и слабые, полосы в геле для детекции. Однако другие сотрудники и руководство Cetus не разделили радости Мюллиса: их всё это попросту не интересовало [10].
1984 г. На ежегодной конференции корпорации Cetus в калифорнийском Монтерее Кэри Мюллис представил плакат, рассказывающий об амплификации гена β-глобина. К удивлению автора, и на этот раз его работу обошли вниманием [10].
Чуть позже Мюллису удалось кое-как убедить корпоративных боссов в важности его экспериментов: Cetus, как и многие начинающие компании, вкладывала ресурсы только в те проекты, что сулили прибыль в краткосрочной перспективе. Его освободили от обязанностей главы лаборатории и дали год на исследования ПЦР. И эти эксперименты завершились успешно [10].
1985 г. Мюллис и его группа разработчиков подали заявку на патент, который утвердили 28 июля 1987 года. В том же 1985-м в Cetus начали использовать для ПЦР термостабильную Taq-полимеразу, что значительно упростило работу: раньше перед каждым новым синтетическим циклом в смесь надо было добавлять новую порцию фермента, потому что он быстро выходил из строя от высоких температур. В декабре 1985 года журнал Science опубликовал первую статью Кэри Мюллиса о ПЦР [12].
Тогда же открылось совместное предприятие PerkinElmer Cetus Instruments (PECI), которое выпустило первый прототип ПЦР-циклера — Mr. Cycle (рис. 4). И только в 1987 году в продажу поступил первый общедоступный прибор, PCR-1000 Thermal Cycler.

Рисунок 4. Mr. Cycle — первый прототип ПЦР-амплификатора.
1986 г. Корпорация Cetus выплатила Кэри Мюллису премию $10 000. Остальные члены его группы получили по символическому доллару. Это обострило и так напряженные отношения в коллективе. Осенью Мюллис покинул компанию [13].
После ухода из Cetus он два года возглавлял молекулярно-биологический отдел в Xytronyx, а в 1992-м открыл компанию по продаже ювелирных изделий с амплифицированной ДНК знаменитостей — Элвиса Пресли, Мэрилин Монро и т.п. [14].
В 1993 году Кэри Мюллис стал лауреатом Нобелевской премии по химии за изобретение ПЦР. Его награждение — до сих пор больной вопрос для норвежского научного сообщества, где первооткрывателем метода считают Хьелля Клеппе.
Сейчас Мюллису 72 года, он работает научным сотрудником Научно-исследовательского института детской больницы Окленда и с 2011 года возглавляет предприятие Altermune LLC, занимающееся изучением иммунитета [14].
Кэри Мюллис нередко выступает на конференциях, рассказывает о своей жизни, работе и, конечно, своем открытии (см. видео 1). Он — прекрасный рассказчик, его всегда интересно слушать.
Видео 1. Выступление Кэри Мюллиса на конференции TED2002
Время от времени Мюллис принимает ЛСД. Однажды он рассказал о ночной встрече со светящимся зеленым енотом в лесу рядом со своим загородным домом. А Альберт Хоффман («отец» ЛСД) утверждал, что, по словам Мюллиса, ЛСД помог ему развить идею ПЦР [14].
В 1998 году вышла книга Кэри Мюллиса «Танец обнаженного разума» (Dancing naked in the mind field), где в обрамлении автобиографических историй ученый высказывает своё мнение о глобальном потеплении, СПИДе и других волнующих общество вопросах. Мюллис верит в астрологию и считает, что значительного изменения климата не происходит, между ВИЧ и СПИДом нет никакой связи, а все исследования, говорящие об обратном, — плоды заговора ученых-карьеристов с правительствами их стран.
1987 г. Компания Cetus подала патентную заявку на метод ПЦР с Taq-полимеразой, и ее одобрили в октябре 1990 года.
1989 г. Журнал Science объявил Taq-полимеразу молекулой года, а статья сотрудников Cetus о ПЦР с ее использованием [15] несколько лет поддерживала статус самой цитируемой биологической публикации [16].
В августе химический гигант DuPont подал против Cetus иск, в котором утверждал, что патенты на ПЦР получены неправомерно, поскольку этот процесс еще в 1970-х описал Хьелль Клеппе. В ответ на иск Ведомство по патентам и товарным знакам США (USPTO) решило переосвидетельствовать патенты. Но через год объявило, что они останутся действительными: комиссия нашла метод, описанный в работе Клеппе, слишком «неопределенным и сомнительным». К тому же там не упоминалась возможность экспоненциальной репликации — отличительной черты ПЦР. В суде представители DuPont так и не смогли доказать вторичность изобретения Мюллиса. 28 февраля 1991 года, после двух дней работы, суд вынес решение в пользу Cetus [10].
1991 г. Выигранный суд не помог корпорации Cetus: к ‘91-му году ее убытки превысили $60 млн, и в июле было объявлено о слиянии с биотехнологической компанией Chiron. А права на метод ПЦР и использование Taq-полимеразы в декабре продали компании Hoffman-La Roche за $300 млн [10]. С этой сделки Cetus выплатила Кэри Мюллису неоправданно малую сумму, фактически ограбив его.
С тех пор Hoffman-La Roche и ее «дочка» Roche Molecular Systems развивают метод полимеразной цепной реакции: у них уже более 1000 связанных с ПЦР патентов и заявок.
Принцип метода
Все мы знаем, что ДНК — это двухцепочечная молекула, где каждая цепочка состоит из звеньев-нуклеотидов. Нуклеотиды составлены из трех молекул: остатка фосфорной кислоты, сахара и азотистого основания. Если сахар и фосфат одинаковы у всех нуклеотидов в ДНК (в РНК сахар другой), то азотистых оснований четыре (если не считать редкие модификации): аденин, тимин, цитозин и гуанин, обозначаемые А, Т, Ц и Г соответственно. В молекулах РНК тимин заменен урацилом. Нуклеотиды соединяются в цепочку, образуя связи между фосфатной группой одного нуклеотида и гидроксильной — другого. В результате на одном конце каждой цепи ДНК «висит» фосфатная группа (5ˊ-конец), а на другом — гидроксильная (3ˊ-конец). Две цепи нуклеотидов расположены в молекуле ДНК антипараллельно, то есть напротив 3ˊ-конца одной находится 5ˊ-конец другой. Чтобы молекула была стабильной, цепочки должны как-то взаимодействовать друг с другом. Это обеспечивают водородные связи, образующиеся между азотистыми основаниями противоположных цепей по принципу комплементарности: А соединяется только с Т (или У в РНК), а Г — с Ц (рис. 5, видео 2). И поэтому, имея одну цепь ДНК, в соответствии с этим правилом легко построить ее пару. Собственно, на этом и основана ПЦР.

Рисунок 5. Строение ДНК.
Видео 2. Строение ДНК.
Типичная реакционная смесь
- Анализируемая ДНК. Это может быть как отдельный кусочек молекулы, так и плазмида, хромосома или геном клетки полностью. Для грубой оценки сойдет даже суспензия клеток. ДНК служит матрицей для многократного копирования нужного участка.
- Праймеры.Праймер — это искусственно синтезированная короткая цепочка нуклеотидов (15–30 штук), комплементарная выбранному участку одной из цепей анализируемой ДНК. Один из праймеров обычно соответствует началу амплифицируемого отрезка, другой — его концу, но на противоположной цепи. У праймеров, как и у любого олиго- или полинуклеотида, есть 3ˊ- и 5ˊ-концы.
- Нуклеотиды. А точнее, дезоксинуклеотидтрифосфаты — четыре вида «кирпичиков» для строительства цепей ДНК: дАТФ, дТТФ, дЦТФ и дГТФ.
- ДНК-полимераза. Фермент, строящий комплементарную матричной цепь ДНК. Он может начинать синтез только от 3ˊ-конца праймера. Обычно используют термостабильные полимеразы, изначально выделенные из термофильных бактерий и архей: Thermus aquaticus (Taq-полимераза), Pyrococcus furiosus (Pfu-полимераза) и Pyrococcus woesei (Pwo-полимераза). Первая — самая производительная, а две другие — более точные.
- Буфер. Раствор, содержащий различные ионы для поддержания нужного рН, соли магния, необходимые для работы полимеразы, и неионный детергент Tween-20 в сочетании с BSA (бычьим сывороточным альбумином) для предотвращения налипания компонентов реакции на стенки пробирки. В случае ГЦ-богатых матриц в смесь часто добавляют энхансер — ДМСО (диметилсульфоксид), предотвращающий нежелательные взаимодействия между комплементарными участками матрицы.

Рисунок 6. Состав смеси для ПЦР.
Все компоненты смешивают в нужном объеме деионизованной воды в специальных пробирках для ПЦР и помещают в амплификатор (или ПЦР-циклер) (рис. 7, видео 3).

Рисунок 7. Расходные материалы и оборудование для ПЦР. а — ПЦР-пробирки. б — Амплификатор C1000 Touch™ производства Bio-Rad.
Видео 3. Приготовление смеси для ПЦР.
Этапы реакции
Цель ПЦР — получить множество одинаковых двухцепочечных кусочков ДНК строго определенной длины (обычно не более 2–3 тысяч пар нуклеотидов, т.п.н.). Для этого проводят 20–30 циклов реакции. Каждый цикл состоит из трех этапов.
1. Денатурация
Чтобы полимераза могла работать, две цепи ДНК-матрицы нужно разъединить. Для этого реакционную смесь нагревают до 94–98 °С. В таких условиях разрушаются водородные связи между азотистыми основаниями параллельных цепей.
2. Отжиг праймеров
На этом этапе праймеры специфично присоединяются к освободившимся цепям ДНК-матрицы с разных сторон копируемого участка 3ˊ-концами друг к другу (рис. 8, видео 4). Чтобы праймеры могли комплементарно связаться (отжечься) только с нужными участками, при их конструировании необходимо учитывать такую важную характеристику, как температура плавления (Тm). Это расчетная температура, при которой половина праймеров присоединяется к целевому участку ДНК. Отжиг проводят при температуре на 1–5 °С ниже Tm, но не выше оптимальной температуры работы полимеразы, то есть в пределах 40–72 °С [17].

Рисунок 8. Полимеразная цепная реакция. На стадии денатурации цепи ДНК разъединяются, на следующем этапе (отжиг) к ним присоединяются праймеры, а далее полимераза начинает свою работу — синтез новых цепей ДНК (элонгация). И такой цикл повторяется многократно.
Чтобы увидеть рисунок в полном размере, нажмите на него.
Видео 4. Полимеразная цепная реакция.
В идеале праймеры должны соответствовать следующим критериям:
- температуры плавления двух праймеров не должны различаться более чем на 5 °С;
- ГЦ-состав их должен уложиться в интервал 40–60%;
- в структуре олигонуклеотидов не должно быть шпилек (участков, комплементарных друг другу);
- праймеры не должны образовывать дуплексы (спариваться) друг с другом.
Еще лучше, если на 3ˊ-конце праймера будет гуанин или цитозин: они образуют с комплементарными основаниями три водородные связи (между А и Т образуются две), что делает комплекс праймер—матрица более стабильным.
В реальности редко получается соблюсти все условия из-за множества причин. Однако чем больше критериев соблюдено при создании праймеров, тем выше вероятность правильной их работы.
Чтобы разработать эффективные праймеры, необходимо знать последовательность ДНК у концов целевого участка, и, руководствуясь упомянутыми критериями, выбрать подходящие фрагменты, которым будут комплементарны будущие праймеры. Всё это удобно делать в специальных компьютерных программах — например, PrimerSelect: они и Тm рассчитают, и всякие спаривания изобразят, и вообще вынесут вердикт, удачная это пара праймеров или нет.
3. Элонгация, или синтез ДНК
Однажды ведущий ПЦР-специалист одного ветеринарного диагностического центра, показывая студентам постановку реакции, объяснила, что она потому называется полимеразной, потому что ее результаты наблюдают в полимерном геле. Возможно, есть и другие приверженцы этой гипотезы, однако сразу отметим, что она не верна. Полимеразная эта реакция от того, что в ее ходе фермент ДНК-полимераза последовательно выстраивает цепь ДНК (полимер) из нуклеотидов (мономеров), то есть полимеризует их. И делает она это на третьем этапе ПЦР.
Этот этап чаще проводят при температуре 72 °С — оптимальной для работы Taq-полимеразы. Фермент присоединяется к комплексам праймер—матрица и, выхватывая из раствора нуклеотиды, начинает по принципу комплементарности прилаживать их к 3ˊ-концу праймера (рис. 7). Удлинение, или элонгация, новой цепи ДНК идет с максимальной скоростью 50–60 нуклеотидов в секунду (то есть около 3000 в минуту). Однако при программировании ПЦР-циклера задают время с запасом: по минуте на каждую тысячу пар нуклеотидов.
Каждая вновь синтезированная цепочка ДНК становится, наравне со старой, матрицей для синтеза в следующем цикле. Таким образом, количество нужного продукта в процессе реакции возрастает экспоненциально. После прохождения всех циклов в реакционной смеси образуется столько специфических двухцепочечных продуктов, что их «массив» можно увидеть невооруженным глазом — проведя гель-электрофорез, о котором расскажем ниже.
К сожалению, экспоненциальная амплификация не может длиться вечно. Через 25–30 циклов количество функциональных молекул полимеразы в реакционной смеси истощается. Но чтобы добиться еще большего выхода продукта, содержимое пробирки можно разбавить, например, в 1000 раз и снова использовать для амплификации с уже новыми рабочими компонентами [18].
Визуализация продуктов ПЦР
Чтобы увидеть, намножились ли нужные участки ДНК, после окончания ПЦР содержимое пробирок подвергают электрофорезу в агарозном или полиакриламидном геле с последующим окрашиванием — так молекулы ДНК разной длины разделяются пространственно и становятся видны невооруженным глазом [19]. Полиакриламидный гель намного плотнее, поэтому больше подходит для разделения очень коротких фрагментов (несколько десятков пар нуклеотидов), при этом можно увидеть разницу даже в один нуклеотид!
Расплавленный при 65 °С гель заливают в специальную форму (плашку) с установленной в ней гребенкой, формирующей лунки (рис. 9). Когда гель застывает, гребенку вынимают, ставят форму в камеру для электрофореза и заливают специальным буфером. Затем в лунки микропипеткой вносят раствор из ПЦР-пробирок, смешанный с краской — чаще бромфеноловым синим. Чтобы потом определять размеры амплифицированных фрагментов, в отдельную лунку вносят маркер молекулярных масс (ladder), содержащий набор кусочков ДНК известных размеров. Камеру подключают к источнику питания и наблюдают за бегущими от электродов волшебными пузырьками. Десятки минут или несколько часов, зависит от размера фрагментов ДНК, плотности геля и приложенного напряжения (видео 5).

Рисунок 9. Подготовка геля для горизонтального электрофореза.
Видео 5. Электрофорез в агарозном геле.
Благодаря отрицательно заряженному сахарофосфатному остову ДНК, фрагменты движутся в геле под действием электрического поля от отрицательного катода к положительному аноду. Более короткие молекулы делают это быстрее, чем длинные. Бромфеноловый синий нужен для того, чтобы следить за продвижением фронта проб в геле и не допустить их выхода за его пределы.
После окончания электрофореза гель вынимают из плашки и, чтобы увидеть расположение фрагментов, вымачивают в растворе флюоресцентного красителя, прочно связывающегося с ДНК. Иногда его вводят в гель еще до залития плашки. Если красителем служит бромистый этидий, внедряющийся между нуклеотидами ДНК, визуализацию проводят под ультрафиолетом (рис. 10).

Рисунок 10. Амплифицированные участки ДНК в агарозном геле после электрофореза. Показаны результаты BOX-PCR — варианта rep-PCR (repetitive extragenic palindromic PCR), в котором с праймером BOX-A1R намножаются повторяющиеся внегенные палиндромы (BOX-мотивы) бактерий. Метод BOX-ПЦР — один из видов геномной дактилоскопии. Он обладает высокой разрешающей способностью, позволяя различать бактерии на уровне штаммов: картина распределения амплифицированных фрагментов в геле уникальна для каждого штамма. Вертикальные дорожки — отдельные пробы, соответствующие разным бактериальным штаммам; горизонтальные полоски на каждой дорожке — фрагменты ДНК разной длины.
фото автора статьи
Если экспериментатор преследовал цель просто понять, есть ли нужная последовательность нуклеотидов в ДНК-матрице, то после визуализации гель выбрасывают. Но нужные фрагменты несложно из геля выделить для дальнейшей работы: чтобы резать их на кусочки для сравнения с другими фрагментами, вставлять в плазмиды для дальнейшего изучения, секвенировать и т.д.
Типы ПЦР
Мы описали типичную качественную ПЦР, позволяющую узнать, есть нужная последовательность в анализируемом образце или нет. В качестве матрицы мы всегда упоминали ДНК, но бывают случаи, когда в распоряжении экспериментатора есть лишь РНК (при исследовании РНК-вирусов) или только она может дать необходимую информацию (при определении уровня экспрессии генов). Тогда используют ПЦР с обратной транскрипцией, или ОТ-ПЦР (RT-PCR; не путать с real-time PCR!).
Помимо качественной, существует количественная ПЦР — для определения количества исходной матрицы в образце. Это ПЦР в реальном времени, или real-time PCR. Ее тоже можно проводить в двух вариантах: с ДНК-матрицей и РНК-матрицей.
ПЦР с обратной транскрипцией
Полимеразная цепная реакция может идти исключительно на матрице ДНК, поэтому если у экспериментатора есть мРНК (матричная РНК, на основе которой строятся клеточные белки), то сначала ее надо как-то «переписать» в ДНК. Для этого применяют реакцию обратной транскрипции, в которой фермент обратная транскриптаза по матрице РНК строит комплементарную ДНК (кДНК) [20]. А потом с этой ДНК проводят обычную ПЦР, как описано выше (рис. 11).

Рисунок 11. Схема ОТ-ПЦР. К одноцепочечной РНК-матрице присоединяется праймер, и обратная транскриптаза синтезирует цепь ДНК, которая потом сама уже служит матрицей для синтеза ДНК в процессе обычной ПЦР.
Впервые ОТ-ПЦР упомянули в 1988 году в журнале Science, в статье о синтезе факторов роста макрофагами [21].
Эту реакцию обычно осуществляют с помощью двух ферментов — обратной транскриптазы и ДНК-полимеразы — либо в двух пробирках (в первой при 37 °С по матрице РНК синтезируют кДНК, затем во второй проводят стандартную ПЦР), либо в одной (все реагенты смешивают вместе, дают отстояться 1 час при 37 °С и помещают в циклер). У каждого из подходов есть свои недостатки и достоинства. В первом случае высока вероятность ошибок при пипетировании и загрязнения образца при переносе во вторую пробирку. Но при этом, однажды проведя обратную транскрипцию, полученную кДНК можно использовать в нескольких экспериментах с разными целями. Во втором случае в ПЦР участвует вся синтезированная кДНК, и повторить реакцию уже невозможно. Однако время проведения эксперимента существенно сокращается. Первый вариант применяют для исследования некоторого набора генов, а второй — при большом количестве образцов, но малом количестве изучаемых генов.
Но ОТ-ПЦР можно проводить и с одним ферментом — Tth-полимеразой. Эту термостабильную полимеразу выделили в 1985 году из бактерии Thermus thermophilus HB-8 [22]. Фермент обладает двойной активностью: в присутствии ионов магния — полимеразной, а в присутствии ионов марганца — обратнотранскриптазной. Причем обе реакции могут идти при 70 °С, что очень важно в случае ГЦ-богатых РНК, которые охотно образуют «шпильки»: высокая температура поддерживает матрицу в денатурированном состоянии, повышает специфичность отжига праймеров и позволяет эффективно копировать сложные молекулы [17].
Однако здесь есть и проблема: в присутствии марганца точность полимеразы сильно снижается, и кДНК содержит множество ошибок. Чтобы этого избежать, после реакции обратной транскрипции в пробирку вносят EDTA, которая образует с марганцем устойчивый комплекс, тем самым выводя его из реакции. Затем добавляют магний и проводят ПЦР [17].
ОТ-ПЦР незаменима при работе с вирусами, геном которых представлен молекулой РНК, в диагностике некоторых видов рака по специфическим транскриптам опухолевых клеток, а также в генной инженерии, если нужно экспрессировать эукариотический ген в бактериальных клетках.
ПЦР (и ОТ-ПЦР) в реальном времени
Этот метод еще называют qPCR (quantitative PCR, или количественная ПЦР), поскольку он позволяет не только обнаружить в пробе целевую нуклеотидную последовательность, но и измерить количество ее копий, а значит, и рассчитать, сколько же было исходной матрицы. Этой матрицей может быть как ДНК (qPCR), так и РНК (RT-qPCR). Понятно, что в последнем случае первой стадией будет обратная транскрипция.
ПЦР в реальном времени разработали в 1992 году в Калифорнии сотрудники Roche Molecular Systems [23]. Они добавили в смесь для ПЦР флуоресцентный краситель бромистый этидий (EtBr) и запустили реакцию под ультрафиолетовым светом, который заставлял EtBr светиться. Весь процесс, а следовательно, и усиление свечения при накоплении копий ДНК, исследователи записали на видеокамеру. Затем они смогли подсчитать исходное число копий целевого фрагмента в реакционной смеси.
Метод real-time PCR не требует визуализации продуктов реакции с помощью гель-электрофореза — их накопление фиксируют в реальном времени оптические датчики, вмонтированные в амплификатор и настроенные на определенную длину волны, испускаемую флуоресцирующими метками (рис. 12). При этом используют два типа меток: интеркалирующие агенты («коллеги» EtBr) и зонды с флуорофорами [24].

Рисунок 12. Амплификатор для qPCR CFX384 Touch™ от Bio-Rad.
Самый популярный интеркалирующий агент — SYBR Green, флуорофор, резко увеличивающий флуоресценцию (в 1000 раз) после связывания с двухцепочечной ДНК (рис. 13). Таким образом, увеличение флуоресценции будет пропорционально увеличению количества ДНК в каждом цикле ПЦР. К сожалению, интеркалирующие агенты обладают низкой специфичностью: они могут связываться и с «побочными» продуктами реакции, и с димерами праймеров. Однако тщательный подбор праймеров и условий ПЦР минимизируют этот недостаток [24].

Рисунок 13. Некоторые виды меток для ПЦР в реальном времени.
Систем зондов с флуорофорами достаточно много (рис. 13). Подробно разберем лишь три самых распространенных.
- TaqMan. Этот небольшой олигонуклеотид, комплементарный внутреннему участку амплифицируемого фрагмента ДНК, содержит два флуорофора: репортер и гаситель. Когда они находятся на одном зонде, то есть близко друг к другу, гаситель поглощает сигнал от репортера. Во время амплификации движущаяся по ДНК полимераза разрушает зонд, репортер и гаситель отдаляются друг от друга, и флуоресценция репортера становится заметной [25].
- Молекулярные маяки. Если в вышеописанном случае детекция свечения происходит на стадии элонгации, то здесь свечение фиксируют на этапе отжига праймеров. Молекулярные маяки — это короткие одноцепочечные фрагменты ДНК, образующие петлю со шпилькой, на концах которой «пришиты» репортер и гаситель (рис. 13). Пока шпилька существует, гаситель находится рядом с репортером, подавляя его свечение. Как только зонд соединяется петлей с комплементарным участком ДНК, репортер и гаситель оказываются достаточно далеко друг от друга, чтобы началась флуоресценция [25].
- Скорпионы. Это структуры, подобные молекулярным маякам, только на 3ˊ-конце после гасителя к ним пришит праймер, с которого и начинается амплификация ДНК. Сигнал от репортера фиксируют в следующем цикле реакции: двухцепочечная ДНК денатурирует, на этапе отжига праймеров раскрывается шпилька зонда, и он, изгибаясь как хвост скорпиона, комплементарно соединяется с цепочкой ДНК, синтезированной как продолжение его праймера (рис. 13). Таким образом репортер с гасителем разносятся в пространстве, и появляется свечение [24].
Применяют ПЦР в реальном времени для анализа экспрессии генов, одиночных нуклеотидных полиморфизмов (SNP) и хромосомных аберраций, для обнаружения конкретных патогенов и, в последние годы, белков (иммуно-ПЦР в реальном времени) [26].
Иммуно-ПЦР в реальном времени

Рисунок 14. Схема иммуно-ПЦР в реальном времени.
ПЦР служит для качественного и количественного определения в пробе нуклеиновых кислот. Но во многих случаях необходимо детектировать ферменты, гормоны, токсины, антитела и другие молекулы. В большинстве случаев для этого используют метод ИФА (иммуноферментный анализ). Чувствительность метода позволяет определять даже несколько нанограммов антигена в пробе, однако отдельные молекулы ИФА выявить не в состоянии [27].
Чтобы устранить такой недостаток, ученые решили попробовать соединить ИФА и ПЦР. Технологию иммуно-ПЦР (иПЦР, IPCR) разработали сотрудники Калифорнийского университета в Беркли в 1992 году [28]. Сначала для визуализации результатов использовали гель-электрофорез, но сегодня в большинстве случаев применяют ПЦР в реальном времени.
Суть метода заключается в следующем. Пробы, где ищут нужную молекулу (гормон, токсин и т.п.), помещают в специальные пробирки, материал которых обладает высокой антигенсвязывающей способностью и термостойкостью. Далее к пробам добавляют специфические антитела с «пришитыми» к ним ДНК-метками длиной 150–300 п.н. (существует множество вариантов таких систем, но здесь разберем самый простой). Когда антитела присоединятся к искомым молекулам (антигенам), иммобилизованным на стенках пробирок, производят многократную промывку, чтобы удалить непрореагировавшие меченые антитела (рис. 14). Затем в эти же пробирки заливают смесь для qPCR (с интеркалирующим агентом или зондом), помещают их в циклер и проводят реакцию, во время которой амплифицируются ДНК-метки на антителах, связанных с антигенами. Так получают сведения не только о наличии антигенов в пробе, но и об их количестве [29], [30].
Иммуно-ПЦР по разрешающей способности превосходит ИФА на 2–5 порядков и выявляет антиген даже когда невозможно сконцентрировать пробу либо на ранних стадиях бактериальной или вирусной инфекции. Не менее полезно и то, что иПЦР позволяет одновременно обнаруживать много разных антигенов, так как к антителам «пришиты» разные ДНК, амплифицируемые с уникальными праймерами, для которых можно использовать зонды разных конструкций [27], [30].
Применяют иммуно-ПЦР для поиска в пробах вирусных антигенов (например, ВИЧ), опухолеассоциированных антигенов (например, фактора роста эндотелия сосудов), прионов, бактериальных белков, токсинов (в том числе и небелковых, например, диэтилфталата) и других веществ [31].
Варианты проведения реакции
Сегодня существуют десятки вариантов проведения ПЦР для разных целей, для повышения специфичности и эффективности. Разберем лишь несколько наиболее популярных и интересных.
ПЦР с горячим стартом
Известно, что Taq-полимераза может проявлять небольшую активность при комнатной температуре и даже когда пробирка с реакционной смесью находится во льду. Поэтому фермент всегда добавляют в смесь непосредственно перед запуском реакции. Но если, например, проб много, то какие-то из них некоторое время будут стоять уже с полимеразой, пока экспериментатор внесет ее во все пробирки. В этом случае есть вероятность получения неспецифически амплифицированных фрагментов.
Чтобы избежать такой неприятности, используют ПЦР с горячим стартом (hot start PCR), где в смесь добавляют полимеразу в комплексе с антителами, блокирующими ее активность. На первой стадии ПЦР (при 95 °С) антитела денатурируют, полимераза освобождается и только тогда начинает работу.
Ступенчатая ПЦР
При оптимальной температуре отжига праймеры иногда могут связываться и с не идеально комплементарными им участками, а вот если эту температуру немного повысить (например, до 72 °С), то специфичность гибридизации праймеров с матрицей можно существенно увеличить. На этом и основана ступенчатая ПЦР (touchdown PCR): первые циклы проводят при повышенной температуре отжига, постепенно снижая ее до оптимальной в следующих циклах. В результате поначалу вероятность неспецифичной амплификации снижается до минимума, а далее уже размноженные копии нужного фрагмента будут успешно конкурировать за праймеры с не полностью комплементарными им участками ДНК-матрицы.
«Холодная» ПЦР
COLD-PCR (CO-amplification at Lower Denaturation temperature-PCR) используют, когда необходимо выявить, например, однонуклеотидную мутацию гена, но при этом проба содержит ДНК-матрицу как с мутантным геном, так и с геном «дикого типа». Такая смесь типична для биоптатов или образцов крови онкологических больных, и потому этот анализ востребован в медицине для ранней диагностики рака или его рецидивов, а также для назначения индивидуальной терапии на основе молекулярного профилирования. Если делать стандартную ПЦР, то амплифицируются и мутантные, и немутантные аллели интересующего гена, причем последних будет значительно больше, и выявить мутацию будет очень трудно.
Принцип «холодной» ПЦР основан на том, что замена даже одного нуклеотида в одной из цепей ДНК-фрагмента приводит к изменению его температуры плавления, то есть температуры, при которой две цепи ДНК отсоединяются друг от друга. Это изменение составляет обычно 0,2–1,5 °С для фрагментов длиной до 200 п.н. Такая пониженная температура называется критической температурой денатурации (Тс): при ней эффективность ПЦР резко падает из-за малого числа денатурированных матриц [32]. То есть при Тс матрицы «дикого типа» денатурировать уже не будут, но будут те, в которых одна из цепей содержит нуклеотидную замену, отчего их Tm снижается до значения Тс. Для получения таких коротких диагностических матриц интересующий фрагмент вначале выделяют из тотальной ДНК биоматериала с помощью стандартной ПЦР. Мутантные формы среди этих фрагментов ищут уже с помощью COLD-PCR, которая проходит в несколько этапов (рис. 15):
- Стандартная денатурация при 94 °С.
- Гибридизация при 70 °С, во время которой образуются гомодуплексы (обе цепи ДНК «дикого типа» или же обе мутантных, что маловероятно из-за их низкого содержания в исходной пробе) и гетеродуплексы целевых фрагментов (одна цепь «дикого типа», вторая — мутантная). В гетеродуплексе как минимум один нуклеотид (измененный) не может образовать водородных связей со своим «правильным» визави, что выражается в понижении температуры плавления такого дуплекса.
- Критическая денатурация при Тс. Денатурируют лишь гетеродуплексы; гомодуплексы остаются в двухцепочечном состоянии.
- Отжиг праймеров. Может идти только на разошедшихся цепях гетеродуплекса.
- Элонгация.
После окончания всех циклов реакции полученные копии интересующего фрагмента секвенируют, чтобы точно установить место и тип мутации.

Рисунок 15. Схема «холодной» ПЦР.
Чтобы увидеть рисунок в полном размере, нажмите на него.
ПЦР длинных фрагментов
Применяют, когда нужно амплифицировать очень длинные фрагменты — более 5 т.п.н. В long-range PCR часто используют две полимеразы: Taq и Pfu. Первая может за один проход синтезировать длинную цепь ДНК, но при этом «застревает», совершив ошибку, потому что не умеет вырезать только что вставленные нуклеотиды. Вторая полимераза менее процессивна, зато способна исправлять ошибки. Так они друг другу и помогают: Taq ошибается, а Pfu исправляет, давая возможность «подружке» закончить синтез.
Мультиплексная ПЦР
Бывают случаи, когда в одной пробе необходимо выявить сразу несколько последовательностей. Например, при инфекции несколькими патогенами, при диагностике комплекса заболеваний или при выявлении мутаций (рис. 16). И чтобы не проводить много реакций, экономят время и реактивы — применяют мультиплексную ПЦР (multiplex PCR), то есть ПЦР со множеством праймеров. Суть ее в том, что в одну пробирку с ДНК-матрицей добавляют целый набор праймеров для одновременной амплификации нескольких интересующих фрагментов [24], [33].

Рисунок 16. Результаты мультиплексной ПЦР ДНК пациента с миодистрофией Дюшенна. К дистрофии приводят различные мутации экзонов гена белка дистрофина. На дорожке 7 нет полосы, соответствующей экзону 48 (длиной 506 п.н.) этого гена.
Однако при этом надо соблюдать такие условия:
- температуры отжига праймеров не должны сильно разниться (то есть длина каждого праймера должна быть 18–28 нуклеотидов, а ГЦ-состав — 45–60%);
- каждый набор праймеров должен давать фрагмент, отличный от других по размеру, чтобы после электрофореза в геле полосы не совпадали.
RAPD
Это ПЦР случайных полиморфных фрагментов ДНК — Random Amplification of Polymorphic DNA. К RAPD прибегают, когда нужно различить сходные геномы: виды бактерий, сорта растений, породы собак и т.д. Используют небольшой праймер (до 10 н.), который может гибридизоваться со многими случайными участками генома. Если правильно подобрать последовательность праймера и условия реакции, то в геле после электрофореза пробы будут отличаться друг от друга количеством и (или) расположением полос.
При всей схожести метода с rep-PCR, описанной под рисунком 10, последнюю всё-таки считают независимой техникой, отличающейся от RAPD своими характеристиками [34]. Так, RAPD менее специфична и хуже воспроизводится: любая мутация в комплементарном праймеру участке матрицы приводит к тому, что короткий праймер не гибридизуется с ним, и соответствующей полосы в геле не будет. Удлинение праймеров в rep-PCR до 20–22 н. сильно повышает воспроизводимость результатов.
Асимметричная ПЦР
Асимметричную реакцию (asymmetric PCR) проводят при желании получить амплифицированную копию участка только одной из цепей ДНК — например, для последующей гибридизации. В таком случае в реакционной смеси концентрация одного праймера должна быть намного выше, чем другого, и тогда на выходе будут превалировать фрагменты нужной цепи.
Метилспецифичная ПЦР
Геномная ДНК живых организмов, как правило, метилирована: после синтеза ДНК к небольшому проценту цитозинов и аденинов фермент ДНК-метилтрансфераза присоединяет метильную группу. Цели метилирования разнообразны: от регуляции экспрессии отдельных генов до регуляции целых процессов, таких как старение или канцерогенез.
Это свойство геномной ДНК эксплуатирует метилспецифичная ПЦР (methylation-specific PCR). Такой вариант ПЦР применяют, чтобы понять, метилирован ли определенный участок ДНК по цитозину.
Перед постановкой реакции ДНК-матрицу обрабатывают бисульфитом. Он преобразует неметилированные цитозины в урацилы, которые распознаются праймерами и полимеразой как тимины, а метилированные цитозины не трогает. Затем проводят две реакции с разными праймерами: в одну пробирку вносят праймеры, специфичные к последовательности с цитозинами, а в другую — к последовательности с урацилами. Если амплификация прошла в первой пробирке, значит ДНК на этом участке метилирована, если во второй — не метилирована.
ПЦР со вложенной парой праймеров
Она же — вложенная или гнездовая ПЦР (nested PCR). Полезна для уменьшения вероятности амплификации неспецифических фрагментов. Если, например, какие-то из праймеров «сядут» на незапланированные участки, после электрофореза в геле можно получить несколько полос — целевого фрагмента и побочных. Чтобы повысить специфичность реакции, используют два набора праймеров: первый — для амплификации более длинного фрагмента, второй — для амплификации внутреннего участка этого фрагмента (рис. 17). Несколько раундов ПЦР проводят с первым набором, а затем добавляют второй. Чтобы избежать продолжения амплификации с первыми праймерами, оба набора разрабатывают для отжига при разных температурах [24].

Рисунок 17. Схема вложенной ПЦР.
Инвертированная ПЦР
Этот вариант используют, когда известна последовательность (сиквенс) какого-то участка ДНК, но нужно амплифицировать вовсе не его, а то неизвестное, что его окружает. Например, необходимо узнать, в какое место генома встроился вирус с известным сиквенсом. Тогда-то и приходит на помощь инвертированная ПЦР (inverse PCR), которая состоит из нескольких этапов (рис. 18):
- ДНК, где есть участок с известной последовательностью, разрезают крупнощепящей рестриктазой. Такие эндонуклеазы распознают сайты длиной 6–8 нуклеотидов, а поскольку таких мест в геноме не может быть слишком много, ДНК режется на крупные куски — фрагменты длиной несколько т.п.н. Важно учесть, чтобы сайта узнавания выбранной рестриктазы не было внутри известного нам участка: он должен войти целиком в один из крупных рестрикционных фрагментов.
- Ферментом лигазой полученные фрагменты закольцовывают.
- Используя праймеры к известной последовательности, но ориентированные кнаружи от нее, амплифицируют ту самую, неизвестную, которую потом можно, например, секвенировать.

Рисунок 18. Схема инвертированной ПЦР.
ПЦР с перекрывающимися праймерами
Чаще всего для соединения двух фрагментов двухцепочечной ДНК используют метод рестрикции/лигирования, когда края этих фрагментов разрезают одинаковыми эндонуклеазами с образованием «липких» концов, а потом соединяют их с помощью лигазы. Однако с этой целью можно применять и метод ПЦР.
ПЦР с перекрывающимися праймерами, или продлением перекрывания (overlap extension PCR), выполняется в несколько этапов (рис. 19):
- Для каждого фрагмента ДНК-матрицы конструируют два праймера: один обычный, а второй (гибридизующийся со стороны будущей сшивки фрагментов) на 5ˊ-конце несет небольшую последовательность, соответствующую концу другого фрагмента, того, что будут пришивать.
- Проводят две раздельные ПЦР — для каждого из фрагментов. В результате последовательность, содержащаяся на 5ˊ-концах «стыковочных» праймеров, уже входит в состав новообразованных амплифицированных фрагментов.
- Содержимое обеих пробирок смешивают и используют уже только два праймера — для дальних (внешних) концов. Поскольку оба фрагмента содержат на одном конце последовательности, комплементарные друг другу, во время отжига праймеров фрагменты гибридизуются, а их перекрывающиеся 3ˊ-концы служат праймерами. Таким образом получаются длинные молекулы, состоящие из двух фрагментов.
Этот же вариант ПЦР, но с небольшими модификациями, используют и для внесения мутаций, например, если из длинного фрагмента ДНК надо удалить какой-то участок.

Рисунок 19. Схема ПЦР с перекрывающимися праймерами.
Сборочная ПЦР
Этот вариант похож на предыдущий. Его используют для сборки синтетических молекул ДНК из отдельных фрагментов, например, чтобы получить синтетические гены или даже целые геномы.
В сборочной ПЦР (assembly PCR) используют одноцепочечные олигонуклеотиды длиной до 50 н., одна часть которых предназначена для образования одной цепи ДНК, а другая — для образования другой (рис. 20). Важно, чтобы эти олигонуклеотиды частично перекрывались концами (примерно на 20 нуклеотидов) с «соседями» на будущей противоположной цепи, поскольку они сами будут работать и праймерами, и матрицей. Во время первых 30 циклов ПЦР концы олигонуклеотидов удлиняются по матрице фрагментов противоположной цепи. К концу процесса каждый олигонуклеотид удлинится настолько, что превратится в отдельную цепочку будущей синтетической ДНК. Тогда в реакцию добавляют пару праймеров, комплементарных концам этой ДНК, и проводят дополнительные 23 цикла, получая на выходе множество копий синтетической ДНК.

Рисунок 20. Схема сборочной ПЦР.

Рисунок 21. Схема твердофазной ПЦР.
Твердофазная ПЦР
Ее применяют, например, для получения ДНК-микрочипов или при секвенировании на платформе Illumina. К твердой поверхности 5ˊ-концами пришивают праймеры, добавляют реакционную смесь и проводят твердофазную ПЦР (solid phase PCR, рис. 21). В первом цикле удлиняется некоторое количество праймеров, затем проводят промывку, чтобы удалить свободно плавающие в растворе ДНК-матрицы, добавляют новый раствор (но уже без матриц) и продолжают ПЦР. Одноцепочечные ДНК, торчащие над поверхностью, на этапе отжига изгибаются и гибридизуются с какими-то из соседних праймеров, становясь матрицами для удлинения этих праймеров. На этапе денатурации обе цепи расходятся, но всё равно остаются прикрепленными к поверхности, так как представляют собой продолжения праймеров [35].
In situ ПЦР
Это реакция, которую проводят непосредственно в клетках или тканях, например, для изучения внутриклеточного развития вирусов. Сначала клетки или ткань фиксируют на предметном стекле и обрабатывают протеазой, чтобы расщепить белки и освободить ДНК (или РНК, если собираются проводить ОТ-ПЦР). Затем прямо на стекло добавляют смесь для ПЦР и ставят препарат в амплификатор. Выявляют получившиеся фрагменты либо ДНК-гибридизацией, либо иммунологическими методами.
Капельная цифровая ПЦР
Цифровая ПЦР (digital PCR) — более точный и воспроизводимый метод количественного определения ДНК, чем ПЦР в реальном времени. Стандартная ПЦР проходит во всём объеме образца, а при цифровой пробу делят на большое количество маленьких субъединиц (компартментов) и проводят ПЦР в каждой из них отдельно. Методы разделения на компартменты в различных технологиях цифровой ПЦР отличаются друг от друга (используют масляную эмульсию, капилляры и т.д.), а реакцию проводят в планшетах с микролунками. Результаты визуализируют чаще всего с помощью системы TaqMan, но иногда применяют и интеркалирующие агенты, например, зеленую флуоресцирующую краску EvaGreen.
Метод цПЦР разработали австралийцы Алек Морли и Памела Сайкс в 1992 году, когда исследовали больных лейкемией [36]. В последующие годы разные исследовательские группы разрабатывали свои варианты, в том числе и варианты компартментализации. К сожалению, все они имели существенный недостаток — высокую трудоемкость: пробу надо было разделять на сотни (а то и тысячи) реакций объемом по нескольку микролитров каждая или проводить дополнительные реакции (например, иммобилизацию праймеров на магнитных шариках и гибридизацию продуктов ПЦР с флуоресцентными пробами, как в технологии BEAMing), а затем отдельно анализировать результаты.
От этих проблем экспериментаторов избавила капельная цифровая ПЦР (кцПЦР), или по-английски droplet digital PCR (ddPCR). Общепризнанным лидером в этой области является система цифровой капельной ПЦР — QX200 производства компании Bio-Rad. Эту методику разработала компания QuantaLife, а в 2011 году Bio-Rad приобрела права на технологию [37]. На рынке существует еще несколько систем капельной цифровой ПЦР: QuantStudio 3D и QuantStudio 12K Flex (обе производства Thermo Fisher Scientific), Biomark HD (от Fluidigm), а также RainDrop Plus (от RainDance Technologies), недавно купленный компанией Bio-Rad, но QX200 явно доминирует — за последние несколько лет систему упоминали в более чем 600 публикациях.
В ddPCR из 20 мкл образца, в котором требуется определить количество исследуемой ДНК, создают водно-маслянную эмульсию. Реакционную смесь разделяют на приблизительно 20 000 капель-реакций объемом около 1 нл каждая с помощью автоматического генератора капель (рис. 22). При этом генетический материал распределяется по каплям случайным образом: в них попадают как ДНК-мишени, так и фоновая ДНК. Процесс распределения целевой ДНК по каплям чисто случайный и подчиняется закону распределения малых чисел Пуассона. Перед разделением образца на капли не обязательно разводить его до концентрации, чтобы в каждой капле было либо 0, либо 1 копия ДНК-мишени: при анализе результатов учитываются ситуации, когда в одной капле находится более одной копии мишени.

Рисунок 22. Схема цифровой ПЦР с использованием системы QX200™ от Bio-Rad.
Капли вносят в 96-луночный планшет для ПЦР и помещают в циклер. Реакция проходит независимо в каждой капле (подробное руководство по капельной цифровой ПЦР на английском языке доступно на сайте Bio-Rad: Droplet DigitalTM PCR Applications Guide). В тех каплях, куда попала ДНК-мишень, образуется ПЦР-продукт, что приводит к увеличению уровня флуоресцентного сигнала от флуоресцентной метки: либо TaqMan-зондов, либо интеркалирующего красителя. После ПЦР капли независимо друг от друга проверяют в специальном устройстве (ридере) на наличие или отсутствие в них флуоресцентного сигнала (рис. 23). Количество капель с положительным и отрицательным сигналами подсчитывают для каждого образца, а программное обеспечение выдает концентрацию ДНК-мишени в виде числа копий в микролитре. Анализ продукта проходит в конечной точке после проведения ПЦР [38].

Рисунок 23. Автоматическая шприц-пипетка ридера капель извлекает капли из каждой лунки планшета для ПЦР.
В кцПЦР определение количества ДНК-мишени проводят не относительно, используя калибровочную кривую, как в случае с ПЦР в реальном времени, а прямым подсчетом капель с наличием или отсутствием в них ДНК-мишени. Это существенно увеличивает стабильность системы и ее устойчивость к ингибиторам ПЦР.
При наличии только двух флуоресцентных каналов (FAM и HEX/VIC) система позволяет запускать 4–5-плексные реакции за счет использования смеси зондов с одной нуклеотидной последовательностью, но меченных красителями FAM и HEX/VIC в различных пропорциях. Возможно также проводить 2–3-плексные реакции с интеркалирующим красителем EvaGreen, используя различную «емкость» разноразмерных ПЦР-продуктов для интеркалятора, что позволяет независимо подсчитать количество этих продуктов по разнице уровня их флуоресценции.
С помощью капельной цифровой ПЦР можно определять:
- количество интересующих молекул ДНК в образце;
- до 0,01% минорного, например мутантного, генома в присутствии генома нормальной ткани;
- вариации числа копий гена (copy namber variation, CNV);
- уровень экспрессии генов и микроРНК, включая детекцию небольших (до 10%) изменений уровня экспрессии;
- различия в геномном контенте и экспрессии между единичными клетками.
Метод активно используют в различных областях, но наиболее часто при:
- проведении онкоисследований, включая анализ свободной циркулирующей ДНК и образцов жидкой биопсии (EGFR, BRAF, KRAS и т.д.);
- детекции нужных вариантов в экспериментах по геномному редактированию (CRISPR/Cas9, ZFN, TALEN);
- изучении геномики единичных клеток (single cell).
Несмотря на сходство применения цифровой ПЦР и ПЦР в реальном времени, скорее всего, в будущем ddPCR будет постепенно вытеснять real-time PCR как основной ПЦР-метод количественного определения ДНК.
Альтернативы ПЦР
В этой главе опишем наиболее интересные и перспективные методы изотермической амплификации, которые могут составить конкуренцию стандартной ПЦР, если нужно узнать, есть ли в пробе та или иная последовательность. Эти методы особенно полезны для медицины и сельского хозяйства в полевых условиях, когда нужно обнаружить патогены в образцах растительного или животного происхождения. Если же перед экспериментатором стоят генно-инженерные цели, например, клонирование генов, то здесь, конечно, ПЦР вне конкуренции.
Опосредованная образованием петель изотермическая амплификация
Метод описали японские ученые в 2000 году [39]. LAMP (loop-mediated isothermal amplification) использует Bst-полимеразу из Geobacillus stearothermophilus, совмещающую полимеразную и хеликазную активности, что дает возможность исключить фазу денатурации и проводить реакцию при 60–65 °С. Подробно о методе написано в статье «Поиск иголки в стоге сена за 10 минут — подсвети себе LAMPой» [40].
LAMP, в отличие от обычной ПЦР, использует не два, а четыре или шесть праймеров, что увеличивает специфичность реакции, но в то же время повышает вероятность артефактов и эффекта множественности полос в электрофорезном геле. Однако это, по сути, не недостаток, так как метод рассчитан на детектирование результата невооруженным глазом («позитив»/«негатив») без электрофореза.
Хеликазозависимая амплификация
В 2004 году сотрудники компании New England Biolabs (NEB) предложили свою альтернативу полимеразной цепной реакции — хеликазозависимую амплификацию (helicase-dependent amplification, HDA). В реакции авторы предложили использовать хеликазу UvrD Escherichia coli, SSB-белки gp32 фага Т4 и фрагмент Клёнова exo− (рис. 24). Хеликаза раскручивает ДНК, SSB-белки стабилизируют цепи в разделенном состоянии, а фрагмент Клёнова синтезирует новую ДНК от 3ˊ-конца праймеров. Реакция проходит при 37 °С. Однако если перед ее постановкой провести денатурацию ДНК при 95 °С, эффективность повышается в 1,5–2 раза [41], [42]. Коммерческие наборы, выпускаемые сейчас NEB, вместо фрагмента Клёнова содержат Bst-полимеразу, а вместо UvrD E. coli — термостабильную хеликазу UvrD Thermoanaerobacter tengcongensis (Tte-UvrD), что позволяет проводить реакцию при 65 °С [43].

Рисунок 24. Схема хеликазозависимой амплификации.
К сожалению, у этого метода есть и недостатки. Для получения результатов, сравнимых с результатами стандартной ПЦР, всё-таки необходимо провести предварительную денатурацию образца. К тому же максимальный размер амплифицируемого фрагмента не превышает 120 п.н. Однако по некоторым данным, HDA улавливает в пробе меньшую концентрацию целевой ДНК, чем LAMP [44]. А если использовать хелимеразу (особым образом сшитые Tte-UvrD и Bst-полимеразу), созданную компанией BioHelix, то размер амплифицируемого фрагмента увеличивается до 1,5 т.п.н. [45].
Рекомбиназная полимеразная амплификация
В 2006 году британские ученые из биотехнологической компании TwistDX LTD разработали метод изотермической рекомбиназной полимеразной амплификации (РПА), который может составить сильную конкуренцию как обычной ПЦР, так и ПЦР в реальном времени [46].
Главное отличие РПА от обычной ПЦР в том, что реакция может проходить при комнатной температуре (25 °С), а оптимально — при 37–40 °С. В РПА используют большой фрагмент Bsu-полимеразы, SSB-белки gp32 фага Т4 и его же рекомбиназу uvsX. Часть молекул рекомбиназы связывают с одним праймером, часть — с другим. После внесения в реакционную смесь такие молекулы сканируют ДНК в поисках комплементарных праймеру участков и, найдя их, инициируют процесс расплетения двухцепочечной молекулы и присоединения праймера (рис. 25). Расплетенную ДНК стабилизируют SSB-белки, а полимераза начинает синтез. Процесс АТФ-зависимый, поскольку энергия нужна для освобождения 3ˊ-конца праймера от молекул рекомбиназы. Размер амплифицируемого фрагмента ограничивается тысячей пар нуклеотидов, а минимальная длина праймера должна быть 30 н. для повышения его специфичности [46].

Рисунок 25. Схема рекомбиназной полимеразной амплификации.
Процесс может длиться 15–30 минут, включая экстракцию образцов, что намного быстрее стандартной ПЦР [47]. Этот метод амплификации лишен значительных недостатков (кроме требования строгого соблюдения условий реакции) и может легко модифицироваться в РПА с обратной транскрипцией и РПА в реальном времени — как с интеркалирующими агентами, так и с флуоресцентными зондами.
Весной 2017 года американские ученые предложили на основе рекомбиназной полимеразной амплификации в сочетании с технологией CRISPR-Cas новый метод диагностики — SHERLOCK. О нем «Биомолекула» уже рассказывала в статье «SHERLOCK — молекулярный сыщик спешит на помощь!» [48].
Применение ПЦР
1. Клиническая медицина
- Анализ клинических образцов на наличие инфекционных агентов бактериальной и вирусной природы: ВИЧ, вирусов гепатита и герпеса, хламидий, хеликобактера, туберкулезных микобактерий и т.д.
- Диагностика лейкемии, лимфомы и других видов неоплазий, которые можно определить по мутациям в определенных генах. Мониторинг опухолевых заболеваний после терапии.
- Диагностика наследственных заболеваний, причина которых — мутации отдельных генов: серповидноклеточной анемии, бокового амиотрофического склероза, фенилкетонурии, муковисцидоза, мышечной дистрофии и т.п.
- Персонализированная медицина. Далеко не все лекарства одинаково действуют на всех людей. Одно и то же вещество может помогать одному пациенту и быть токсичным или аллергенным для другого из-за особенностей метаболических процессов у разных людей. Поэтому наиболее эффективны индивидуально подобранные дозировки индивидуально подобранных препаратов. Различия метаболизма обычно обусловлены генетически. Сделав пациенту своеобразный «генетический паспорт» таких особенностей, можно на его основе подбирать правильное лечение [49].
- Тканевая типизация перед трансплантацией органов.
- Обнаружение хромосомных кроссинговеров, делеций, инсерций, транслокаций и инверсий в отдельных сперматозоидах до оплодотворения.
2. Криминалистика и судебная медицина
- Установление личности преступников и жертв по ДНК из капель крови, волос и спермы с места преступления.
- Установление отцовства и иного родства.
- Расследование причин необъяснимой смерти («молекулярная аутопсия») — в комплексе с морфологическими и физиологическими данными [24].
3. Генная инженерия
- Клонирование ДНК для исследования функций генов, их взаимодействия, создания синтетических ДНК, генетически модифицированных организмов и пр. [50].
- Секвенирование ДНК [8], основанное на ПЦР, в ходе которой в синтезируемую цепь включается меченный флуоресцентной меткой или радиоактивным изотопом дидезоксинуклеотид, что приводит к терминации синтеза и позволяет определить положение конкретных нуклеотидов после разделения в геле (то есть пошагово прочитать их последовательность).
- Мутагенез, основанный на внесении изменений в ДНК посредством ПЦР.
- Создание гибридизационных зондов для различных видов блоттинга.
- Анализ экспрессии генов в тканях и отдельных клетках в разных условиях.
4. Антропология, палеонтология
- Изучение взаимосвязей между видами в эволюционной биологии.
- Исследование миграции людей и связи различных этносов, национальностей и рас.
- Изучение вымерших животных и предков человека.
- Исследование ДНК исторических личностей, например, Николая II [51], английского короля Ричарда III [52], египетских фараонов [53] и т.д.
5. Сельское хозяйство
- Обнаружение патогенов (бактерий, грибов, вирусов) у растений и животных.
- Диагностика наследственных заболеваний домашних и сельскохозяйственных животных.
- Анализ пищевых продуктов на содержание генетических модификаций.
- Обнаружение Х-хромосомы у животных, пол которых трудно определить невооруженным глазом: например, рыб, рептилий, попугаев.
Полимеразная цепная реакция — один из самых мощных и дешевых лабораторных методов. Его появление привело к воистину революционным изменениям в науке и медицине. И если сейчас для генетических экспресс-анализов появляются альтернативные техники, не требующие сложной аппаратуры, то в генетической инженерии ПЦР по-прежнему просто незаменима. Пожалуй, самые ценные свойства этого метода — совместимость с другими техниками и невероятная пластичность: они позволяют биологам и врачам с минимальными усилиями решать совершенно разные задачи. А главное, метод пока не исчерпал свой потенциал: до сих пор появляются всё новые его варианты, и, возможно, нас еще не раз удивят остроумные и неожиданные протоколы экспериментов, основанных на ПЦР.
Календарь
На основе статей спецпроекта мы решили сделать календарь «12 методов биологии» на 2019 год. Эта статья представляет февраль.

- Артур Корнберг (1918–2007);
- Peter M. Burgers. (2007). Arthur Kornberg (1918–2007). Molecular Cell. 28, 530-532;
- Lehman I.R., Bessman M.J., Simms E.S., Kornberg A. (1958). Enzymatic synthesis of deoxyribonucleic acid. I. Preparation of substrates and partial purification of an enzyme from Escherichia coli. J. Biol. Chem. 233, 163–170;
- K. Kleppe, E. Ohtsuka, R. Kleppe, I. Molineux, H.G. Khorana. (1971). Studies on polynucleotides. Journal of Molecular Biology. 56, 341-361;
- Chien A., Edgar D.B., Trela J.M. (1976). Deoxyribonucleic acid polymerase from the extreme thermophile Thermus aquaticus. J. Bacteriol. 127, 1550–1557;
- The Nobel Prize in Chemistry 1958. (2014). Nobelprize.org;
- Sanger F., Nicklen S., Coulson A.R. (1977). DNA sequencing with chain-terminating inhibitors. Proc. Natl. Acad. Sci. USA. 74, 5463–5467;
- 12 методов в картинках: секвенирование нуклеиновых кислот;
- The Nobel Prize in Chemistry 1980. (2014). Nobelprize.org;
- Fore J.Jr., Wiechers I.R., Cook-Deegan R. (2006). The effects of business practices, licensing, and intellectual property on development and dissemination of the polymerase chain reaction: case study. J. Biomed. Discov. Collab. 1, 7;
- Mullis K.B. (1990). The unusual origin of the polymerase chain reaction. Scientific American. 4, 56–61;
- R. Saiki, S Scharf, F Faloona, K. Mullis, G. Horn, et. al.. (1985). Enzymatic amplification of beta-globin genomic sequences and restriction site analysis for diagnosis of sickle cell anemia. Science. 230, 1350-1354;
- Bartlett J.M. and Stirling D. (2003). A short history of the polymerase chain reaction. Methods Mol. Biol. 226, 3–6;
- Википедия: Kary Mullis (англ.);
- R. Saiki, D. Gelfand, S Stoffel, S. Scharf, R Higuchi, et. al.. (1988). Primer-directed enzymatic amplification of DNA with a thermostable DNA polymerase. Science. 239, 487-491;
- Википедия: History of polymerase chain reaction (англ.);
- M. J. McPherson and S. G. Moller. PCR (The dasics). 2nd edition. NY: Taylor & Francis Group, 2006. — 292 p.;
- Vondrejs V. a Storchová Z. Genové inženýrsrví I. Praha: Nakladatelství University Karlovy, 1997;
- 12 методов в картинках: очистка молекул и разделение смесей;
- Мода на ретро. Где встречается обратная транскрипция, и как она эволюционировала;
- D. Rappolee, D Mark, M. Banda, Z Werb. (1988). Wound macrophages express TGF-alpha and other growth factors in vivo: analysis by mRNA phenotyping. Science. 241, 708-712;
- Carmen RUTTIMANN, Milena COTORAS, Josefina ZALDIA, Rafael VICUNA. (1985). DNA polymerases from the extremely thermophilic bacterium Thermus thermophilus HB-8. Eur J Biochem. 149, 41-46;
- Russell Higuchi, Gavin Dollinger, P. Sean Walsh, Robert Griffith. (1992). Simultaneous Amplification and Detection of Specific DNA Sequences. Nat Biotechnol. 10, 413-417;
- Hernandez-Rodriguez P. and Ramirez A.G. Polymerase chain reaction: types, utilities and limitations. In: Polymerase chain reaction / ed. by Hernandez-Rodriguez P. Rijeka, Croatia: InTech, 2012. — 566 p.;
- Seifi M., Ghasemi A., Heidarzadeh S., Khosravi M., Namipashaki A., Soofiany V.M. et al. Overview of real-time PCR principles. In: Polymerase chain reaction / ed. by Hernandez-Rodriguez P. Rijeka, Croatia: InTech, 2012. — 566 p.;
- Mikael Kubista, José Manuel Andrade, Martin Bengtsson, Amin Forootan, Jiri Jonák, et. al.. (2006). The real-time polymerase chain reaction. Molecular Aspects of Medicine. 27, 95-125;
- Маерле А.В., Сергеев И.В., Алексеев Л.П. (2014). Метод иммуно-ПЦР: перспективы использования. Иммунология. 1, 44–48;
- T Sano, C. Smith, C. Cantor. (1992). Immuno-PCR: very sensitive antigen detection by means of specific antibody-DNA conjugates. Science. 258, 120-122;
- Рязанцев Д.Ю., Воронина Д.В., Завриев С.К. (2016). Иммуно-ПЦР: достижения и перспективы. Успехи биологической химии. 56, 377–410;
- Michael Adler, Ron Wacker, Christof M. Niemeyer. (2003). A real-time immuno-PCR assay for routine ultrasensitive quantification of proteins. Biochemical and Biophysical Research Communications. 308, 240-250;
- Christof M. Niemeyer, Michael Adler, Ron Wacker. (2005). Immuno-PCR: high sensitivity detection of proteins by nucleic acid amplification. Trends in Biotechnology. 23, 208-216;
- Coren A Milbury, Jin Li, Pingfang Liu, G Mike Makrigiorgos. (2011). COLD-PCR: improving the sensitivity of molecular diagnostics assays. Expert Review of Molecular Diagnostics. 11, 159-169;
- P. Markoulatos, N. Siafakas, M. Moncany. (2002). Multiplex polymerase chain reaction: A practical approach. J. Clin. Lab. Anal.. 16, 47-51;
- Baldy-Chudzik K. (2001). Rep-PCR — a variant to RAPD or an independent technique of bacteria genotyping? A comparison of the typing properties of rep-PCR with other recognised methods of genotyping of microorganisms. Acta Microbiol. Pol. 50, 189–204;
- Jean-Francois Mercier, Gary W. Slater, Pascal Mayer. (2003). Solid Phase DNA Amplification: A Simple Monte Carlo Lattice Model. Biophysical Journal. 85, 2075-2086;
- Sykes P.J., Neoh S.H., Brisco M.J., Hughes E., Condon J., Morley A.A. (1992). Quantitation of targets for PCR by use of limiting dilution. Biotechniques. 13, 444–449;
- Benjamin J. Hindson, Kevin D. Ness, Donald A. Masquelier, Phillip Belgrader, Nicholas J. Heredia, et. al.. (2011). High-Throughput Droplet Digital PCR System for Absolute Quantitation of DNA Copy Number. Anal. Chem.. 83, 8604-8610;
- Киселева Я.Ю., Птицин К.Г., Радько С.П., Згода В.Г., Арчаков А.И. (2016). Цифровая капельная ПЦР — перспективный технологический подход к количественному профилированию микроРНК. Биомедицинская химия. 4, 403–410;
- Notomi T., Okayama H., Masubuchi H., Yonekawa T., Watanabe K., Amino N., Hase T. (2000). Loop-mediated isothermal amplification of DNA. Nucleic Acids Res. 28, e63;
- Поиск иголки в стоге сена за 10 минут — подсвети себе LAMPой;
- Myriam Vincent, Yan Xu, Huimin Kong. (2004). Helicase-dependent isothermal DNA amplification. EMBO Rep. 5, 795-800;
- Lei Yan, Jie Zhou, Yue Zheng, Adam S. Gamson, Benjamin T. Roembke, et. al.. (2014). Isothermal amplified detection of DNA and RNA. Mol. BioSyst.. 10, 970;
- Fei Ma, Meng Liu, Bo Tang, Chun-yang Zhang. (2017). Sensitive Quantification of MicroRNAs by Isothermal Helicase-Dependent Amplification. Anal. Chem.. 89, 6182-6187;
- Celine Zahradnik, Claudia Kolm, Roland Martzy, Robert L. Mach, Rudolf Krska, et. al.. (2014). Detection of the 35S promoter in transgenic maize via various isothermal amplification techniques: a practical approach. Anal Bioanal Chem. 406, 6835-6842;
- Aurélie Motré, Ying Li, Huimin Kong. (2008). Enhancing helicase-dependent amplification by fusing the helicase with the DNA polymerase. Gene. 420, 17-22;
- Olaf Piepenburg, Colin H Williams, Derek L Stemple, Niall A Armes. (2006). DNA Detection Using Recombination Proteins. PLoS Biol. 4, e204;
- Binoy Babu, Brian K. Washburn, Tülin Sarigül Ertek, Steven H. Miller, Charles B. Riddle, et. al.. (2017). A field based detection method for Rose rosette virus using isothermal probe-based Reverse transcription-recombinase polymerase amplification assay. Journal of Virological Methods. 247, 81-90;
- SHERLOCK — молекулярный сыщик спешит на помощь!;
- От медицины для всех — к медицине для каждого!;
- Молекулярное клонирование, или как засунуть в клетку чужеродный генетический материал;
- Фишман Р. (2016). Как идентифицировали останки Николая II и его семьи по ДНК. «Популярная механика»;
- Антонов Е. (2014). «Дело» короля Ричарда III «закрыли» спустя 529 лет. «Наука и жизнь»;
- Власова Е. (2017). Палеогенетики секвенировали ДНК древних египтян. N+1.
Исправление ошибок. ДНК-полимеразы могут выявлять и исправлять ошибки, тогда как РНК-полимеразы такой способностью, по-видимому, не обладают. Поскольку ошибка даже в одном основании как при репликации, так и при транскрипции может привести к ошибке в синтезе белка, можете ли вы дать биологическое объяснение этому поразительному различию [c.925]
З-Ю п. н. Оказывается, у всех организмов точность работы репликативной машины (включающей не только ДНК-полимеразы, но и другие белки см. ниже) как раз такова, чтобы обеспечить безошибочное воспроизведение всего генома или допустить лишь малое число ошибок. Так, у бактерий ошибки синтеза ДНК происходят не чаще чем один раз на много миллионов нуклеотидов. Молекулярные взаимодействия, на которых основаны ферментативные реакции, в частности синтез ДНК, не могут быть абсолютно надежными, кроме того, точность процесса связана с его скоростью. Для того чтобы обеспечить высокую точность наряду с высокой скоростью репликации, природе пришлось прибегнуть к специальным механизмам, один из которых — механизм коррекции. [c.47]
Смещение в комплементарности пар, или ошибка репликации может происходить по другой схеме [c.219]
Нормальное размножение клеток требует высокой точности копирования ДНК-матрицы. Генетический материал живых организмов имеет огромные размеры. Даже у бактерий ДНК-полимераза должна практически безошибочно скопировать молекулу ДНК длиной около 3-10 п. н. Оказывается, у всех организмов точность работы репликативной машины (включаюш.ей не только ДНК-полимеразы, но и другие белки см. ниже) как раз такова, чтобы обеспечить безошибочное воспроизведение всего генома или допустить лишь малое число ошибок. Так, у бактерий ошибки синтеза ДНК происходят не чаще чем один раз на много миллионов нуклеотидов. Молекулярные взаимодействия, на которых основаны ферментативные реакции, в частности синтез ДНК, не могут быть абсолютно надежными, кроме того, точность процесса связана с его скоростью. Для того чтобы обеспечить высокую точность наряду с высокой скоростью репликации, природе пришлось прибегнуть к специальным механизмам, один из которых — механизм коррекции. [c.47]
Очень важно отметить, что процесс репликации протекает со значительно более высокой степенью точности, чем процессы транскрипции и трансляции. Частые ошибки в репликации подвергли бы большому риску сохранность видов [c.908]
ДНК-полимеразы проверяют комплементарность каждого нуклеотида матрице дважды один раз перед включением его в состав растущей цепи и второй раз перед тем, как включить следующий нуклеотид. Очередная фосфодиэфирная связь образуется лишь в том случае, если последний (З -концевой) нуклеотид затравки комплементарен матрице. Если же на предыдущей стадии полимеризации произошла ошибка (например, из-за того, что нуклеотид в момент полимеризации находился в необычной таутомерной форме), то репликация останавливается до тех пор, пока неправильный нуклеотид не будет удален. Некоторые ДНК-полимеразы обладают не только полимеризующей, но и 3 -экзонуклеазной активностью, «Которая отщепляет не спаренный с матрицей нуклеотид затравки. После чего полимеризация восстанавливается, от механизм, коррекция, заметно увеличивает точность работы ДНК-полимераз. Мутации, нарушающие З -экзонуклеазную активность ДНК-полимеразы, существенно повышают частоту возникновения прочих мутаций. Напротив, мутации, приводящие к усилению экзонуклеазной актив- ности относительно полимеризующей, снижают темп мутирования Генетического материала. [c.47]
Спонтанные генные мутации определяются ошибками при репликации ДНК, возникающими вследствие теплового движе-иия атомов и молекул. Очевидно, что ошибки транскрипции и трансляции не наследуются. [c.283]
Процесс транскрипции находится в клетке под строгим контролем, поэтому имеет место как неодинаковое транскрибирование во времени разных участков ДНК (генов), так и неодинаковая скорость, с которой гены могут транскрибироваться. В результате количество молекул иРНК в клетке, комплементарных разным генам, сильно различается. Хотя в целом механизмы синтеза ДНК и РНК сходны, процесс транскрипции не обладает той степенью точности, которая характерна для репликации ДНК. Однако поскольку иРНК не способна к самовоспроизведению, возникающие при ее синтезе ошибки в последующих клеточных генерациях не воспроизводятся и, следовательно, не могут наследоваться. [c.142]
Если ошибка синтеза не устраняется системами репарации, то неизбежна деформация дуплекса и искажение генетической программы. Такие сохраняющиеся при репликации изменения ДНК носят название мутации. Они могут быть спонтанными и индуцированными. Частота спонтанных мутаций невелика и составляет всего 10 —10 на клетку. В основном имеют место мутации, обусловленные действием внешних факторов физических (радиация), биологических (вирусы) и чужеродных химических веществ на генетический аппарат клеток. Наиболее многочисленными и опасными являются мутагены окружающей среды. Загрязнение воды и воздуха различными химическими отходами промышленных предприятий, химическими средствами защиты растений отрицательно сказывается на генетической программе всех живых организмов. В последние годы установлено, что ряд пищевых красителей, стабилизаторов и вкусовых добавок обладает выраженной мутагенной активностью, что привело к значительному ужесточению требований, связанных с применением химических веществ в пищевой промышленности. Многие лекарственные вещества также воздействуют на генетический аппарат клеток и должны подвергаться специальным генетическим испытаниям. [c.455]
Химическое изменение оснований. Некоторые мутагенные вещества действуют путем химического изменения содержащихся в ДНК оснований, что приводит к ошибкам репликации. Вполне понятное изменение вызывает нитрит. Азотистая кислота дезаминирует аденин, гуанин или цитозин без разрыва или каких-либо других изменений полинуклеотидной цепи. В результате замещения аминогруппы гидроксильной группой аденин превращается в гипоксантин и спаривается с цитозином вместо тимина, что приводит к мутации АТ СС. Если цитозин дезаминируется в урацил, то он спаривается с аденином вместо гуанина, и это ведет к мутации СС -АТ. Будучи превращен в ксантин, гуанин по-прежнему спаривается с цитозином, т. е. дезаминирование С не вызывает мутации. Гидроксиламин вступает в реакцию главным образом с цитозином и изменяет его так, что тот спаривается с аденином значит, он тоже вызывает мутации СС ТА. [c.444]
Из уровня спонтанных мутаций у бактерий в расчете на одно поколение рассчитано, что вероятность одной репликационной ошибки при синтезе ДНК составляет порядка 10 . Эту величину можно рассматривать как отношение скоростей реакций правильной репликации [c.194]
ВЫВОД, ЧТО, по-видимому, код действительно является триплет-ным, причем кодирование начинается от определенной точки нуклеиновой кислоты. При этом большая часть трехбуквенных комбинаций соответствует определенным аминокислотам и лишь небольшая часть триплетов относится к бессмысленным. Число триплетов равно 4-4-4 = 64, т. е. значительно больше числа аминокислот. Некоторые из них, по-видимому, кодируют одну и ту же аминокислоту, т. е. код является вырожденным. Этот вывод согласуется с обнаружением в настоящее время двух и более типов растворимых РНК, специфичных к одной и той же аминокислоте. Вырожденность генетического кода может способствовать выживанию организма. Действительно, в случае невырожденного кода ошибка при репликации ДНК или при транскрипции должна скорее приводить к появлению бессмысленного триплета, чем в случае вырожденного кода. Следовательно, при невырожденном коде ошибки чаще вызывали бы прекращение синтеза соответствующего белка или образование незаконченных белковых цепей. Напротив, в случае вырожденного кода ошибки должны чаще приводить просто к замене одной аминокислоты на другую, что, как правило, не имеет серьезных последствий. [c.376]
Как в прокариотических, так и в эукариотических клетках содержатся ферментные системы, способные исправлять ошибки репликации и различные формы повреждения ДНК, вызываемые гидро- [c.990]
Г. Е. Фрадкин. После обработки фаговой популяции гидроксиламино.м последний при помощи диализа удалялся из вирусной суспензии. Следовательно, во время облучения гидроксиламин в среде отсутствовал. Предварительная модификация цитозиновых остатков в ДНК фага лямбда, вызываемая гидроксиламином (предположительно образование 4—5-дигидро-4-гидро-ксиламиноцитозина), действительно повышает радиочувствительность фаговой популяции в условиях преобладания непрямого эффекта излучения. Мы полагаем, что механизм повышения радиочувствительности сводится к нарушению специфического процесса комплементарного спаривания азотистых оснований во время репликации фаговой ДНК внутри клетки. В последних рабо тах Брауна, Филипса с соавторами химическими методами установлено, что цитозин, предварительно обработанный гидроксиламином, спаривается не с гуанином, а с аденином. Вследствие этого во вновь образованной ДНК происходят единичные замены гуанина на аденин. До тех пор, пока эти замены не выходят за пределы связанных серий однозначных кодонов, они не сказываются на информационных свойствах ДНК фага. Однако эти единичные замены понижают эффективность механизма, исправляющего ошибки включения, за счет уменьшения резерва однозначны кодонов или, иными словами, за счет уменьшения степени вырожденности структурного кода. Мы не видим большой сложности в этом объяснении, к которому мы сознательно прибегли для освещения возмол<ных молекулярных механизмов, лежащих в основе скрытых повреждений, связанных с тонкими сдвигами в величинах водородных сил в химически модифицированных азотистых основаниях. Как известно, сенсибилизация может обусловливаться уменьшением степени прочности первичной структуры ДНК вследствие лабилизации эфирно-фосфатных связей. Однако при использовании в качестве модифицирующего агента гидроксиламина этот второй механизм отсутствует, так как химическими исслг- [c.173]
Включение или утрата отдельных пар оснований. Профлавин и другие акридиновые красители действуют по-иному. Вероятно, молекула акридина внедряется между соседними основаниями цепи ДНК и увеличивает расстояние между ними (интеркаляция). Такое пространственное изменение при репликации ДНК может вызывать ошибки двух типов- [c.444]
НО редко, он может образовать пару не с аденином, а с гуанином. Это в свою очередь приведет к ошибке при включении или при репликации, заключающейся в замене пары А — Т на Г — Ц и наоборот. [c.218]
В 1959 г. Д. Пратт сумел показать, что большинство, если не все бромурациловые ревертанты г+, образуемые мутантами гП (которые были индуцированы аналогами оснований), возникают в виде гетерозигот гП/г» , которые позднее расщепляются на гомозиготные ревертанты г» «. Чтобы продемонстрировать это, к бактериям, зараженным мутантным фагом Т4гП, непосредственно перед окончанием скрытого периода внутриклеточного развития фага добавляли бромурацил и первые инфекционные частицы, появившиеся в клетках непосредственно после окончания скрытого периода, высвобождали путем искусственного лизиса клеток. Такая методика постановки опыта гарантировала, что все ревертанты / +, возникшие и извлеченные из фонда предшественников фаговой ДНК во время короткого воздействия мутагена, образовались исключительно в самом последнем цикле репликации. Ошибка копирования, восстановившая у них в соответствующем участке ДНК генетическую информацию дикого типа г+, произошла настолько поздно, что больше и и одного цикла репликации произойти уже не могло (а это значит, что не могло произойти и расщепления на гомозиготные мутантные структуры). Такого рода опыты показали, что свыше 80% всех ревертантов г, возникших в результате кратковременного контакта с бромурацилом, действительно представляет собой мутационные гетерозиготы, несущие как исходный аллель г, так и ревертировавщий к дикому типу аллель г» . Следовательно, в полном соответствии с механизмом Уотсона и Крика и вопреки механизмам, предусматривающим консервативное распределе- [c.325]
Нетрудно видеть, что в тонком механизме репликации и синтеза белков произвол в расположении частиц сведен к минимуму. Этот матричный процесс является низкоэнтропийным. Ошибки в размещении аминокислот в пептидных цепочках составляют по приблизительной оценке 1 на 10 . В то же время, если бы синтез белков происходил на примитивной матрице, на которой концентрация тех или иных компонентов и их относительное расположение в значительной мере определялись бы случайностями окружающей обстановки, нельзя было бы ожидать воспроизводимости синтеза того или иного белка и, в частности, того белка, от структуры ко- [c.393]
Репликаза фага Q способна in vitro синтезировать цепи, полностью комплементарные как плюс-, так и минус-молекулам вирусной РНК. Система, однако, специфична для вирусной РНК и не может копировать никаких других полинуклеотидов. Возможно, что для инициации процесса репликации нужно, чтобы на З -конце имелись определенные последовательности. В пробирке репликация протекает с ошибками, такими, в частности, как преждевременная терминация цепи и неправильное спаривание оснований. В результате происходит образование мутантных форм РНК, что дает возможность получать молекулы РНК, размеры которой будут значительно меньше, чем у вирусной РНК, и которые будут при этом легко реплицироваться репликазной системой фага Q . Была установлена нуклеотидная последовательность одного из таких фрагментов, включающего всего лишь 114 нуклеотидов . [c.245]
Разные аллели одного и того же Г. возникают благодаря мутациям-илслецуемьш изменениям в структуре исходного Г. В норме Г. чрезвычайно стабилен и при удвоении хромосом во время репликации ДНК воспроизводится совершенно точно вероятность ошибки не превышает 10″ . Мутации происходят редко и обычно влекут за собой неблагоприятные последствия для организма, т. к. нарушается его способность синтезировать нормальный белок. Однако в целом это явление играет положит, роль накопление редких полезных мутаций создает основу генетич. изменчивости, необходимой для эволюции. [c.517]
Особый класс М. составляют соед., представляющие собой аналоги оснований ДНК-5-галогенурацилы, 2-амино-и 6-метиламинопурины н др. Галогенурацилы включаются в ДНК при матричном синтезе вместо тимина, 2-амино-пурин-вместо аденина. Вследствие различий в положении кетоенольного равновесия у тимина и галогенурацилов (при включении последних в ДНК) увеличивается частота ошибочных спариваний оснований и возникают ошибки при репликации. [c.152]
Равновесие между созидательными возможностями выбора среди специфических оснований в ДНК (созидательные мутации) и точностью синтеза белков (поддерживающих жизнь организма) является основой эволюции. Ферменты, которые заряжают тРНК специфической аминокислотой, обладают очень низкой вероятностью ошибки, порядка 1 Ю» для гомологичных аминокислот. При репликации точность даже выше, и величина ошибки редко превышает 1 на 10. [c.212]
К настоящему времени у эукариот, как и у бактерий (см. ранее), открыто несколько ДНК-полимераз. В репликации ДНК эукариот участвуют два главных типа полимераз — а и б. Показано, что ДНК-полимераза а состоит из 4 субъединиц и является идентичной по структуре и свойствам во всех клетках млекопитающих, причем одна из субъединиц оказалась наделенной праймазной активностью. Самая крупная субъединица ДНК-полимеразы а (мол. масса 180000) катализирует реакцию полимеризации, преимущественно синтез отстающей цепи ДНК, являясь составной частью праймасомы. ДНК-полимераза б состоит из 2 субъединиц и преимущественно катализирует синтез ведущей цепи ДНК (см. далее). Открыта также ДНК-полимераза г, которая в ряде случаев заменяет б-фермент, в частности при репарации ДНК (исправление нарушений ДНК, вызванных ошибками репликации или повреждающими агентами). Следует отметить, что в эукариотических клетках открыты два белковых фактора репликации, обозначаемых RFA и RF . Фактор репликации А выполняет функцию белка—связывание одноцепочечной ДНК (наподобие белковых факторов связывания разъединенных цепей ДНК при [c.480]
Этап HI — терминация синтеза ДНК —наступает, скорее всего, когда исчерпана ДПК-матрица и трансферазные реакции прекращаются. Точность репликации ДНК чрезвычайно высока, возможна одна ошибка на 10 трансферазных реакций, однако подобная ошибка обычно легко исправляется за счет процессов репарации. [c.486]
Такие системы, достигшие определенного уровня сложности, наталкиваются на границу генетически переносимого количества информации. Оно составляет около 10 бит. Оптимальное значение ошибки при репликации нуклеиновой кислоты — 10 . Это — системно-обусловленная граница. Ее преодоление было достигнуто в нрироде созданием пола и геыегической рекомоина- [c.549]
Приближенная модель репликации ДНКизображена на рис. 2.11. Из приведенной схемы видно, что репликация точно воспроизводит прежнюю (исходную) структуру ДНК. Но если произошла ошибка в процессе копирования (мутация), то она будет с предельной точностью копироваться при последующих репликациях изменившейся ДНК. Показано, что участки ДНК, содержащие скопления нуклеотидов, обладают повышенной склонностью к спонтанным мутациям [22]. [c.94]
По происхождению мутации делятся на спонтанные (неконтролируемые) и индуцированные (контролируемые). Первые возникают в результате неконтролируемого влияния каких-то естественных факторов (радиация, температура и т. д.). Направленное использование мутагенов приводит к возникновению индуцированных мутаций. Многими экспериментами четко показано, что мутации возникают независимо от условий среды обитания, т. е. не направленно. Мутации возникают в основном как ошибки репликации ДНК. Выделяют следующие типы мутаций перестройка хромосом, перестройка генома клетки грибов и водорослей (полиплоидия, гаплоидия, гетероплоидия), внутригенные изменения (прямые мутации, реверсии, обратные мутации). [c.102]
Ошибка в одном основании при репликации ДНК, если она не исправлена, приведет к тому, что одна из двух дочерних клеток, а также все ее потомки будут содержать измененную хромосому. Ошибка в одном основании, совершенная РНК-полимеразой, повлечет за собой синтез некоторого количества неправильных копий одного белка. При этом, поскольку пул мРНК в клетке быстро обновляется, большинство молекул этого белка будет нормальным. Потомство такой клетки тоже будет нормальным. [c.1004]
Анализ приведенных выше результатов дает возможность написать для преобладающих таутомерных форм оснований нуклеиновых кислот формулы, изображенные на фиг. 55. Минорные таутомерные формы, возможно, играют существенную роль в возникновении спонтанных мутаций, поскольку спаривание несоответствующих оснований (см. гл. ХУП1) должно привести к ошибке при включении оснований и при последующей репликации цепи. Можно показать, что если скорость включения основания в цепь нуклеиновой кислоты меньше скорости перехода минорного таутомера в доминирующую форму, то скорость спонтанных мутаций, обусловленных данным основанием, приблизительно равна константе равновесия между минорным и доминирующим таутомерами. К сожалению, для азо- [c.308]
Если ДНК представляет собой генетический материал, то возникает весьма важный вопрос каким образом ДНК реплицируется столь точно, что при передаче генетических признаков очень редко возникают ошибки Так как количество ДНК, приходящееся на гаплоидный набор хромосом, есть величина постоянная, делящаяся клетка должна синтезировать ДНК- Для того чтобы наследственная информация, содерлсащаяс в ДНК, была передана без ошибок, вновь синтезированная ДНК должна представлять собой точную копию исходной. На фиг. 61 изображены схемы двух предполагаемых типов репликации ДНК консервативного и полуконсервативного. [c.327]
Задание 189. Напишите программу для моделирования самоорганизации ДНК в качестве примера самоорганизуюшихся систем. Используйте для этого следующую простую модель. Пусть имеется 100 молекул ДНК, состоящих из 12 нуклеотидов четырех видов (их обозначим буквами А, Т, С и G). Последовательность нуклеотидов в этих 100 молекулах ДНК случайная. Назовем одну из последовательностей идеальной она имеет некоторые преимущества перед остальными. Из 100 молекул ДНК в результате репликации получается еще 100 молекул. Однако при репликации встречаются ошибки (мутации), например в количестве 1%. Теперь из 200 молекул 100 погибает. При этом имеет значение преимущество, которым обладают молекулы с последовательностью нуклеотидов, похожей на идеальную . (Например, при каждом совпадении нуклеотида и его положения в цепи с идеальной последовательностью вероятность гибели уменьшается в два раза.) Процессы репликации и гибели протекают очень быстро. В конце концов все молекулы ДНК должны получить идеальную последовательность нуклеотидов, хотя вероятность ее образования в результате случайного процесса составляет 1 16777216. Что будет, если мутации будут возникать чаще или реже [c.330]
Нетрудно видеть, что в тонком механизме репликации и синтеза белков произвол в расположении частиц сведен к минимуму. Этот матричный процесс является низкоэнтропийным. Ошибки в размещении аминокислот в пептидных цепочках составляют по приблизительной оценке 1 на 10 . В то же время, если бы синтез белков происходил на примитивной матрице, на которой концентрация тех или иных компонентов и их относительное расположение в значительной мере определялись бы случайностями окружающей обстановки, нельзя было бы ожидать воспроизводимости синтеза того или иного белка и, в частности, того белка, от структуры которого зависят жизненно важные свойства системы. Здесь кодирование матричного синтеза обусловлено целым рядом низших кодов кодом, отвечающим соответствию т-РНК и аминокислоты кодом, соответствующим отношению между т-РНК, рибосомой и м-РНК кодом ферментов, производящих замыкание пептидных связей, и т. д. Это — кодированный перенос массы, обусловливающий возникновение структуры, обладающей исключительными свойствами их исключительность состоит в том, что они необходимы для стабилизации синтеза этой же структуры на уровне всех не только низших, но и многих высших кодов, которые возникнут, когда белки сложатся в клетки, клетки в органы, а органы в организм. [c.205]
| DNA-directed DNA polymerase | |||||||
|---|---|---|---|---|---|---|---|

3D structure of the DNA-binding helix-turn-helix motifs in human DNA polymerase beta (based on PDB file 7ICG) |
|||||||
| Identifiers | |||||||
| EC no. | 2.7.7.7 | ||||||
| CAS no. | 9012-90-2 | ||||||
| Databases | |||||||
| IntEnz | IntEnz view | ||||||
| BRENDA | BRENDA entry | ||||||
| ExPASy | NiceZyme view | ||||||
| KEGG | KEGG entry | ||||||
| MetaCyc | metabolic pathway | ||||||
| PRIAM | profile | ||||||
| PDB structures | RCSB PDB PDBe PDBsum | ||||||
| Gene Ontology | AmiGO / QuickGO | ||||||
|
A DNA polymerase is a member of a family of enzymes that catalyze the synthesis of DNA molecules from nucleoside triphosphates, the molecular precursors of DNA. These enzymes are essential for DNA replication and usually work in groups to create two identical DNA duplexes from a single original DNA duplex. During this process, DNA polymerase «reads» the existing DNA strands to create two new strands that match the existing ones.[1][2][3][4][5][6]
These enzymes catalyze the chemical reaction
- deoxynucleoside triphosphate + DNAn ⇌ pyrophosphate + DNAn+1.
DNA polymerase adds nucleotides to the three prime (3′)-end of a DNA strand, one nucleotide at a time. Every time a cell divides, DNA polymerases are required to duplicate the cell’s DNA, so that a copy of the original DNA molecule can be passed to each daughter cell. In this way, genetic information is passed down from generation to generation.
Before replication can take place, an enzyme called helicase unwinds the DNA molecule from its tightly woven form, in the process breaking the hydrogen bonds between the nucleotide bases. This opens up or «unzips» the double-stranded DNA to give two single strands of DNA that can be used as templates for replication in the above reaction.
History[edit]
In 1956, Arthur Kornberg and colleagues discovered DNA polymerase I (Pol I), in Escherichia coli. They described the DNA replication process by which DNA polymerase copies the base sequence of a template DNA strand. Kornberg was later awarded the Nobel Prize in Physiology or Medicine in 1959 for this work.[7] DNA polymerase II was discovered by Thomas Kornberg (the son of Arthur Kornberg) and Malcolm E. Gefter in 1970 while further elucidating the role of Pol I in E. coli DNA replication.[8] Three more DNA polymerases have been found in E. coli, including DNA polymerase III (discovered in the 1970s) and DNA polymerases IV and V (discovered in 1999).[9]
Function[edit]
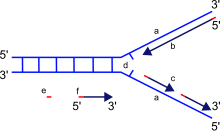
DNA polymerase moves along the old strand in the 3’–5′ direction, creating a new strand having a 5’–3′ direction.

DNA polymerase with proofreading ability
The main function of DNA polymerase is to synthesize DNA from deoxyribonucleotides, the building blocks of DNA. The DNA copies are created by the pairing of nucleotides to bases present on each strand of the original DNA molecule. This pairing always occurs in specific combinations, with cytosine along with guanine, and thymine along with adenine, forming two separate pairs, respectively. By contrast, RNA polymerases synthesize RNA from ribonucleotides from either RNA or DNA.
When synthesizing new DNA, DNA polymerase can add free nucleotides only to the 3′ end of the newly forming strand. This results in elongation of the newly forming strand in a 5’–3′ direction.
It is important to note that the directionality of the newly forming strand (the daughter strand) is opposite to the direction in which DNA polymerase moves along the template strand. Since DNA polymerase requires a free 3′ OH group for initiation of synthesis, it can synthesize in only one direction by extending the 3′ end of the preexisting nucleotide chain. Hence, DNA polymerase moves along the template strand in a 3’–5′ direction, and the daughter strand is formed in a 5’–3′ direction. This difference enables the resultant double-strand DNA formed to be composed of two DNA strands that are antiparallel to each other.
The function of DNA polymerase is not quite perfect, with the enzyme making about one mistake for every billion base pairs copied. Error correction is a property of some, but not all DNA polymerases. This process corrects mistakes in newly synthesized DNA. When an incorrect base pair is recognized, DNA polymerase moves backwards by one base pair of DNA. The 3’–5′ exonuclease activity of the enzyme allows the incorrect base pair to be excised (this activity is known as proofreading). Following base excision, the polymerase can re-insert the correct base and replication can continue forwards. This preserves the integrity of the original DNA strand that is passed onto the daughter cells.
Fidelity is very important in DNA replication. Mismatches in DNA base pairing can potentially result in dysfunctional proteins and could lead to cancer. Many DNA polymerases contain an exonuclease domain, which acts in detecting base pair mismatches and further performs in the removal of the incorrect nucleotide to be replaced by the correct one.[10] The shape and the interactions accommodating the Watson and Crick base pair are what primarily contribute to the detection or error. Hydrogen bonds play a key role in base pair binding and interaction. The loss of an interaction, which occurs at a mismatch, is said to trigger a shift in the balance, for the binding of the template-primer, from the polymerase, to the exonuclease domain. In addition, an incorporation of a wrong nucleotide causes a retard in DNA polymerization. This delay gives time for the DNA to be switched from the polymerase site to the exonuclease site. Different conformational changes and loss of interaction occur at different mismatches. In a purine:pyrimidine mismatch there is a displacement of the pyrimidine towards the major groove and the purine towards the minor groove. Relative to the shape of DNA polymerase’s binding pocket, steric clashes occur between the purine and residues in the minor groove, and important van der Waals and electrostatic interactions are lost by the pyrimidine.[11] Pyrimidine:pyrimidine and purine:purine mismatches present less notable changes since the bases are displaced towards the major groove, and less steric hindrance is experienced. However, although the different mismatches result in different steric properties, DNA polymerase is still able to detect and differentiate them so uniformly and maintain fidelity in DNA replication.[12] DNA polymerization is also critical for many mutagenesis processes and is widely employed in biotechnologies.
Structure[edit]
The known DNA polymerases have highly conserved structure, which means that their overall catalytic subunits vary very little from species to species, independent of their domain structures. Conserved structures usually indicate important, irreplaceable functions of the cell, the maintenance of which provides evolutionary advantages. The shape can be described as resembling a right hand with thumb, finger, and palm domains. The palm domain appears to function in catalyzing the transfer of phosphoryl groups in the phosphoryl transfer reaction. DNA is bound to the palm when the enzyme is active. This reaction is believed to be catalyzed by a two-metal-ion mechanism. The finger domain functions to bind the nucleoside triphosphates with the template base. The thumb domain plays a potential role in the processivity, translocation, and positioning of the DNA.[13]
Processivity[edit]
DNA polymerase’s rapid catalysis is due to its processive nature. Processivity is a characteristic of enzymes that function on polymeric substrates. In the case of DNA polymerase, the degree of processivity refers to the average number of nucleotides added each time the enzyme binds a template. The average DNA polymerase requires about one second locating and binding a primer/template junction. Once it is bound, a nonprocessive DNA polymerase adds nucleotides at a rate of one nucleotide per second.[14]: 207–208 Processive DNA polymerases, however, add multiple nucleotides per second, drastically increasing the rate of DNA synthesis. The degree of processivity is directly proportional to the rate of DNA synthesis. The rate of DNA synthesis in a living cell was first determined as the rate of phage T4 DNA elongation in phage infected E. coli. During the period of exponential DNA increase at 37 °C, the rate was 749 nucleotides per second.[15]
DNA polymerase’s ability to slide along the DNA template allows increased processivity. There is a dramatic increase in processivity at the replication fork. This increase is facilitated by the DNA polymerase’s association with proteins known as the sliding DNA clamp. The clamps are multiple protein subunits associated in the shape of a ring. Using the hydrolysis of ATP, a class of proteins known as the sliding clamp loading proteins open up the ring structure of the sliding DNA clamps allowing binding to and release from the DNA strand. Protein–protein interaction with the clamp prevents DNA polymerase from diffusing from the DNA template, thereby ensuring that the enzyme binds the same primer/template junction and continues replication.[14]: 207–208 DNA polymerase changes conformation, increasing affinity to the clamp when associated with it and decreasing affinity when it completes the replication of a stretch of DNA to allow release from the clamp.
Variation across species[edit]
| DNA polymerase family A | |||||||
|---|---|---|---|---|---|---|---|

c:o6-methyl-guanine pair in the polymerase-2 basepair position |
|||||||
| Identifiers | |||||||
| Symbol | DNA_pol_A | ||||||
| Pfam | PF00476 | ||||||
| InterPro | IPR001098 | ||||||
| SMART | — | ||||||
| PROSITE | PDOC00412 | ||||||
| SCOP2 | 1dpi / SCOPe / SUPFAM | ||||||
|
| DNA polymerase family B | |||||||
|---|---|---|---|---|---|---|---|

crystal structure of rb69 gp43 in complex with dna containing thymine glycol |
|||||||
| Identifiers | |||||||
| Symbol | DNA_pol_B | ||||||
| Pfam | PF00136 | ||||||
| Pfam clan | CL0194 | ||||||
| InterPro | IPR006134 | ||||||
| PROSITE | PDOC00107 | ||||||
| SCOP2 | 1noy / SCOPe / SUPFAM | ||||||
|
| DNA polymerase type B, organellar and viral | |||||||
|---|---|---|---|---|---|---|---|

phi29 dna polymerase, orthorhombic crystal form, ssdna complex |
|||||||
| Identifiers | |||||||
| Symbol | DNA_pol_B_2 | ||||||
| Pfam | PF03175 | ||||||
| Pfam clan | CL0194 | ||||||
| InterPro | IPR004868 | ||||||
|
Based on sequence homology, DNA polymerases can be further subdivided into seven different families: A, B, C, D, X, Y, and RT.
Some viruses also encode special DNA polymerases, such as Hepatitis B virus DNA polymerase. These may selectively replicate viral DNA through a variety of mechanisms. Retroviruses encode an unusual DNA polymerase called reverse transcriptase, which is an RNA-dependent DNA polymerase (RdDp). It polymerizes DNA from a template of RNA.
| Family[16] | Types of DNA polymerase | Taxa | Examples | Feature |
|---|---|---|---|---|
| A | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | T7 DNA polymerase, Pol I, Pol γ, θ, and ν | Two exonuclease domains (3′-5′ and 5′-3′) |
| B | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | Pol II, Pol B, Pol ζ, Pol α, δ, and ε | 3′-5 exonuclease (proofreading); viral ones use protein primer |
| C | Replicative Polymerases | Prokaryotic | Pol III | 3′-5 exonuclease (proofreading) |
| D | Replicative Polymerases | Euryarchaeota | PolD (DP1/DP2 heterodimer)[17] | No «hand» feature, double barrel RNA polymerase-like; 3′-5 exonuclease (proofreading) |
| X | Replicative and Repair Polymerases | Eukaryotic | Pol β, Pol σ, Pol λ, Pol μ, and terminal deoxynucleotidyl transferase | template optional; 5′ phosphatase (only Pol β); weak «hand» feature |
| Y | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | Pol ι, Pol κ, Pol η,[18] Pol IV, and Pol V | Translesion synthesis[19] |
| RT | Replicative and Repair Polymerases | Viruses, Retroviruses, and Eukaryotic | Telomerase, Hepatitis B virus | RNA-dependent |
Prokaryotic polymerase[edit]
Prokaryotic polymerases exist in two forms: core polymerase and holoenzyme. Core polymerase synthesizes DNA from the DNA template but it cannot initiate the synthesis alone or accurately. Holoenzyme accurately initiates synthesis.
Pol I[edit]
Prokaryotic family A polymerases include the DNA polymerase I (Pol I) enzyme, which is encoded by the polA gene and ubiquitous among prokaryotes. This repair polymerase is involved in excision repair with both 3’–5′ and 5’–3′ exonuclease activity and processing of Okazaki fragments generated during lagging strand synthesis.[20] Pol I is the most abundant polymerase, accounting for >95% of polymerase activity in E. coli; yet cells lacking Pol I have been found suggesting Pol I activity can be replaced by the other four polymerases. Pol I adds ~15-20 nucleotides per second, thus showing poor processivity. Instead, Pol I starts adding nucleotides at the RNA primer:template junction known as the origin of replication (ori). Approximately 400 bp downstream from the origin, the Pol III holoenzyme is assembled and takes over replication at a highly processive speed and nature.[21]
Taq polymerase is a heat-stable enzyme of this family that lacks proofreading ability.[22]
Pol II[edit]
DNA polymerase II is a family B polymerase encoded by the polB gene. Pol II has 3’–5′ exonuclease activity and participates in DNA repair, replication restart to bypass lesions, and its cell presence can jump from ~30-50 copies per cell to ~200–300 during SOS induction. Pol II is also thought to be a backup to Pol III as it can interact with holoenzyme proteins and assume a high level of processivity. The main role of Pol II is thought to be the ability to direct polymerase activity at the replication fork and help stalled Pol III bypass terminal mismatches.[23]
Pfu DNA polymerase is a heat-stable enzyme of this family found in the hyperthermophilic archaeon Pyrococcus furiosus.[24] Detailed classification divides family B in archaea into B1, B2, B3, in which B2 is a group of pseudoenzymes. Pfu belongs to family B3. Others PolBs found in archaea are part of «Casposons», Cas1-dependent transposons.[25] Some viruses (including Φ29 DNA polymerase) and mitochondrial plasmids carry polB as well.[26]
Pol III[edit]
DNA polymerase III holoenzyme is the primary enzyme involved in DNA replication in E. coli and belongs to family C polymerases. It consists of three assemblies: the pol III core, the beta sliding clamp processivity factor, and the clamp-loading complex. The core consists of three subunits: α, the polymerase activity hub, ɛ, exonucleolytic proofreader, and θ, which may act as a stabilizer for ɛ. The beta sliding clamp processivity factor is also present in duplicate, one for each core, to create a clamp that encloses DNA allowing for high processivity.[27] The third assembly is a seven-subunit (τ2γδδ′χψ) clamp loader complex.
The old textbook «trombone model» depicts an elongation complex with two equivalents of the core enzyme at each replication fork (RF), one for each strand, the lagging and leading.[23] However, recent evidence from single-molecule studies indicates an average of three stoichiometric equivalents of core enzyme at each RF for both Pol III and its counterpart in B. subtilis, PolC.[28] In-cell fluorescent microscopy has revealed that leading strand synthesis may not be completely continuous, and Pol III* (i.e., the holoenzyme α, ε, τ, δ and χ subunits without the ß2 sliding clamp) has a high frequency of dissociation from active RFs.[29] In these studies, the replication fork turnover rate was about 10s for Pol III*, 47s for the ß2 sliding clamp, and 15m for the DnaB helicase. This suggests that the DnaB helicase may remain stably associated at RFs and serve as a nucleation point for the competent holoenzyme. In vitro single-molecule studies have shown that Pol III* has a high rate of RF turnover when in excess, but remains stably associated with replication forks when concentration is limiting.[29] Another single-molecule study showed that DnaB helicase activity and strand elongation can proceed with decoupled, stochastic kinetics.[29]
Pol IV[edit]
In E. coli, DNA polymerase IV (Pol IV) is an error-prone DNA polymerase involved in non-targeted mutagenesis.[30] Pol IV is a Family Y polymerase expressed by the dinB gene that is switched on via SOS induction caused by stalled polymerases at the replication fork. During SOS induction, Pol IV production is increased tenfold and one of the functions during this time is to interfere with Pol III holoenzyme processivity. This creates a checkpoint, stops replication, and allows time to repair DNA lesions via the appropriate repair pathway.[31] Another function of Pol IV is to perform translesion synthesis at the stalled replication fork like, for example, bypassing N2-deoxyguanine adducts at a faster rate than transversing undamaged DNA. Cells lacking the dinB gene have a higher rate of mutagenesis caused by DNA damaging agents.[32]
Pol V[edit]
DNA polymerase V (Pol V) is a Y-family DNA polymerase that is involved in SOS response and translesion synthesis DNA repair mechanisms.[33] Transcription of Pol V via the umuDC genes is highly regulated to produce only Pol V when damaged DNA is present in the cell generating an SOS response. Stalled polymerases causes RecA to bind to the ssDNA, which causes the LexA protein to autodigest. LexA then loses its ability to repress the transcription of the umuDC operon. The same RecA-ssDNA nucleoprotein posttranslationally modifies the UmuD protein into UmuD’ protein. UmuD and UmuD’ form a heterodimer that interacts with UmuC, which in turn activates umuC’s polymerase catalytic activity on damaged DNA.[34] In E. coli, a polymerase «tool belt» model for switching pol III with pol IV at a stalled replication fork, where both polymerases bind simultaneously to the β-clamp, has been proposed.[35] However, the involvement of more than one TLS polymerase working in succession to bypass a lesion has not yet been shown in E. coli. Moreover, Pol IV can catalyze both insertion and extension with high efficiency, whereas pol V is considered the major SOS TLS polymerase. One example is the bypass of intra strand guanine thymine cross-link where it was shown on the basis of the difference in the mutational signatures of the two polymerases, that pol IV and pol V compete for TLS of the intra-strand crosslink.[35]
Family D[edit]

Structures of archaeal polD and eukaryotic Polα. Not only is the general topology conserved, the two also share a bifunctional primase-and-PCNA-binding PIP-box sequence on the C-terminus, similar to both eukaryotic Polα and Polε.[36]
In 1998, the family D of DNA polymerase was discovered in Pyrococcus furiosus and Methanococcus jannaschii.[37] The PolD complex is a heterodimer of two chains, each encoded by DP1 (small proofreading) and DP2 (large catalytic). Unlike other DNA polymerases, the structure and mechanism of the DP2 catalytic core resemble that of multi-subunit RNA polymerases. The DP1-DP2 interface resembles that of Eukaryotic Class B polymerase zinc finger and its small subunit.[17] DP1, a Mre11-like exonuclease,[38] is likely the precursor of small subunit of Pol α and ε, providing proofreading capabilities now lost in Eukaryotes.[25] Its N-terminal HSH domain is similar to AAA proteins, especially Pol III subunit δ and RuvB, in structure.[39] DP2 has a Class II KH domain.[17] Pyrococcus abyssi polD is more heat-stable and more accurate than Taq polymerase, but has not yet been commercialized.[40] It has been proposed that family D DNA polymerase was the first to evolve in cellular organisms and that the replicative polymerase of the Last Universal Cellular Ancestor (LUCA) belonged to family D.[41]
Eukaryotic DNA polymerase[edit]
Polymerases β, λ, σ, μ (beta, lambda, sigma, mu) and TdT[edit]
Family X polymerases contain the well-known eukaryotic polymerase pol β (beta), as well as other eukaryotic polymerases such as Pol σ (sigma), Pol λ (lambda), Pol μ (mu), and Terminal deoxynucleotidyl transferase (TdT). Family X polymerases are found mainly in vertebrates, and a few are found in plants and fungi. These polymerases have highly conserved regions that include two helix-hairpin-helix motifs that are imperative in the DNA-polymerase interactions. One motif is located in the 8 kDa domain that interacts with downstream DNA and one motif is located in the thumb domain that interacts with the primer strand. Pol β, encoded by POLB gene, is required for short-patch base excision repair, a DNA repair pathway that is essential for repairing alkylated or oxidized bases as well as abasic sites. Pol λ and Pol μ, encoded by the POLL and POLM genes respectively, are involved in non-homologous end-joining, a mechanism for rejoining DNA double-strand breaks due to hydrogen peroxide and ionizing radiation, respectively. TdT is expressed only in lymphoid tissue, and adds «n nucleotides» to double-strand breaks formed during V(D)J recombination to promote immunological diversity.[42]
Polymerases α, δ and ε (alpha, delta, and epsilon)[edit]
Pol α (alpha), Pol δ (delta), and Pol ε (epsilon) are members of Family B Polymerases and are the main polymerases involved with nuclear DNA replication. Pol α complex (pol α-DNA primase complex) consists of four subunits: the catalytic subunit POLA1, the regulatory subunit POLA2, and the small and the large primase subunits PRIM1 and PRIM2 respectively. Once primase has created the RNA primer, Pol α starts replication elongating the primer with ~20 nucleotides.[43] Due to its high processivity, Pol δ takes over the leading and lagging strand synthesis from Pol α.[14]: 218–219 Pol δ is expressed by genes POLD1, creating the catalytic subunit, POLD2, POLD3, and POLD4 creating the other subunits that interact with Proliferating Cell Nuclear Antigen (PCNA), which is a DNA clamp that allows Pol δ to possess processivity.[44] Pol ε is encoded by the POLE1, the catalytic subunit, POLE2, and POLE3 gene. It has been reported that the function of Pol ε is to extend the leading strand during replication,[45][46] while Pol δ primarily replicates the lagging strand; however, recent evidence suggested that Pol δ might have a role in replicating the leading strand of DNA as well.[47] Pol ε’s C-terminus «polymerase relic» region, despite being unnecessary for polymerase activity,[48] is thought to be essential to cell vitality. The C-terminus region is thought to provide a checkpoint before entering anaphase, provide stability to the holoenzyme, and add proteins to the holoenzyme necessary for initiation of replication.[49] Pol ε has a larger «palm» domain that provides high processivity independently of PCNA.[48]
Compared to other Family B polymerases, the DEDD exonuclease family responsible for proofreading is inactivated in Pol α.[25] Pol ε is unique in that it has two zinc finger domains and an inactive copy of another family B polymerase in its C-terminal. The presence of this zinc finger has implications in the origins of Eukaryota, which in this case is placed into the Asgard group with archaeal B3 polymerase.[50]
Polymerases η, ι and κ (eta, iota, and kappa)[edit]
Pol η (eta), Pol ι (iota), and Pol κ (kappa), are Family Y DNA polymerases involved in the DNA repair by translation synthesis and encoded by genes POLH, POLI, and POLK respectively. Members of Family Y have five common motifs to aid in binding the substrate and primer terminus and they all include the typical right hand thumb, palm and finger domains with added domains like little finger (LF), polymerase-associated domain (PAD), or wrist. The active site, however, differs between family members due to the different lesions being repaired. Polymerases in Family Y are low-fidelity polymerases, but have been proven to do more good than harm as mutations that affect the polymerase can cause various diseases, such as skin cancer and Xeroderma Pigmentosum Variant (XPS). The importance of these polymerases is evidenced by the fact that gene encoding DNA polymerase η is referred as XPV, because loss of this gene results in the disease Xeroderma Pigmentosum Variant. Pol η is particularly important for allowing accurate translesion synthesis of DNA damage resulting from ultraviolet radiation. The functionality of Pol κ is not completely understood, but researchers have found two probable functions. Pol κ is thought to act as an extender or an inserter of a specific base at certain DNA lesions. All three translesion synthesis polymerases, along with Rev1, are recruited to damaged lesions via stalled replicative DNA polymerases. There are two pathways of damage repair leading researchers to conclude that the chosen pathway depends on which strand contains the damage, the leading or lagging strand.[51]
Polymerases Rev1 and ζ (zeta)[edit]
Pol ζ another B family polymerase, is made of two subunits Rev3, the catalytic subunit, and Rev7 (MAD2L2), which increases the catalytic function of the polymerase, and is involved in translesion synthesis. Pol ζ lacks 3′ to 5′ exonuclease activity, is unique in that it can extend primers with terminal mismatches. Rev1 has three regions of interest in the BRCT domain, ubiquitin-binding domain, and C-terminal domain and has dCMP transferase ability, which adds deoxycytidine opposite lesions that would stall replicative polymerases Pol δ and Pol ε. These stalled polymerases activate ubiquitin complexes that in turn disassociate replication polymerases and recruit Pol ζ and Rev1. Together Pol ζ and Rev1 add deoxycytidine and Pol ζ extends past the lesion. Through a yet undetermined process, Pol ζ disassociates and replication polymerases reassociate and continue replication. Pol ζ and Rev1 are not required for replication, but loss of REV3 gene in budding yeast can cause increased sensitivity to DNA-damaging agents due to collapse of replication forks where replication polymerases have stalled.[52]
Telomerase[edit]
Telomerase is a ribonucleoprotein which functions to replicate ends of linear chromosomes since normal DNA polymerase cannot replicate the ends, or telomeres. The single-strand 3′ overhang of the double-strand chromosome with the sequence 5′-TTAGGG-3′ recruits telomerase. Telomerase acts like other DNA polymerases by extending the 3′ end, but, unlike other DNA polymerases, telomerase does not require a template. The TERT subunit, an example of a reverse transcriptase, uses the RNA subunit to form the primer–template junction that allows telomerase to extend the 3′ end of chromosome ends. The gradual decrease in size of telomeres as the result of many replications over a lifetime are thought to be associated with the effects of aging.[14]: 248–249
Polymerases γ, θ and ν (gamma, theta and nu)[edit]
Pol γ (gamma), Pol θ (theta), and Pol ν (nu) are Family A polymerases. Pol γ, encoded by the POLG gene, was long thought to be the only mitochondrial polymerase. However, recent research shows that at least Pol β (beta), a Family X polymerase, is also present in mitochondria.[53][54] Any mutation that leads to limited or non-functioning Pol γ has a significant effect on mtDNA and is the most common cause of autosomal inherited mitochondrial disorders.[55] Pol γ contains a C-terminus polymerase domain and an N-terminus 3’–5′ exonuclease domain that are connected via the linker region, which binds the accessory subunit. The accessory subunit binds DNA and is required for processivity of Pol γ. Point mutation A467T in the linker region is responsible for more than one-third of all Pol γ-associated mitochondrial disorders.[56] While many homologs of Pol θ, encoded by the POLQ gene, are found in eukaryotes, its function is not clearly understood. The sequence of amino acids in the C-terminus is what classifies Pol θ as Family A polymerase, although the error rate for Pol θ is more closely related to Family Y polymerases. Pol θ extends mismatched primer termini and can bypass abasic sites by adding a nucleotide. It also has Deoxyribophosphodiesterase (dRPase) activity in the polymerase domain and can show ATPase activity in close proximity to ssDNA.[57] Pol ν (nu) is considered to be the least effective of the polymerase enzymes.[58] However, DNA polymerase nu plays an active role in homology repair during cellular responses to crosslinks, fulfilling its role in a complex with helicase.[58]
Plants use two Family A polymerases to copy both the mitochondrial and plastid genomes. They are more similar to bacterial Pol I than they are to mammalian Pol γ.[59]
Reverse transcriptase[edit]
Retroviruses encode an unusual DNA polymerase called reverse transcriptase, which is an RNA-dependent DNA polymerase (RdDp) that synthesizes DNA from a template of RNA. The reverse transcriptase family contain both DNA polymerase functionality and RNase H functionality, which degrades RNA base-paired to DNA. An example of a retrovirus is HIV.[14] Reverse transcriptase is commonly employed in amplification of RNA for research purposes. Using an RNA template, PCR can utilize reverse transcriptase, creating a DNA template. This new DNA template can then be used for typical PCR amplification. The products of such an experiment are thus amplified PCR products from RNA.[9]
Each HIV retrovirus particle contains two RNA genomes, but, after an infection, each virus generates only one provirus.[60] After infection, reverse transcription is accompanied by template switching between the two genome copies (copy choice recombination).[60] From 5 to 14 recombination events per genome occur at each replication cycle.[61] Template switching (recombination) appears to be necessary for maintaining genome integrity and as a repair mechanism for salvaging damaged genomes.[62][60]
Bacteriophage T4 DNA polymerase[edit]
Bacteriophage (phage) T4 encodes a DNA polymerase that catalyzes DNA synthesis in a 5′ to 3′ direction.[63] The phage polymerase also has an exonuclease activity that acts in a 3′ to 5′ direction,[64] and this activity is employed in the proofreading and editing of newly inserted bases.[65] A phage mutant with a temperature sensitive DNA polymerase, when grown at permissive temperatures, was observed to undergo recombination at frequencies that are about two-fold higher than that of wild-type phage.[66]
It was proposed that a mutational alteration in the phage DNA polymerase can stimulate template strand switching (copy choice recombination) during replication.[66]
See also[edit]
- Biological machines
- DNA sequencing
- Enzyme catalysis
- Genetic recombination
- Molecular cloning
- Polymerase chain reaction
- Protein domain dynamics
- Reverse transcription
- RNA polymerase
- Taq DNA polymerase
References[edit]
- ^ Bollum FJ (August 1960). «Calf thymus polymerase». The Journal of Biological Chemistry. 235 (8): 2399–403. doi:10.1016/S0021-9258(18)64634-4. PMID 13802334.
- ^ Falaschi A, Kornberg A (April 1966). «Biochemical studies of bacterial sporulation. II. Deoxy- ribonucleic acid polymerase in spores of Bacillus subtilis». The Journal of Biological Chemistry. 241 (7): 1478–82. doi:10.1016/S0021-9258(18)96736-0. PMID 4957767.
- ^ Lehman IR, Bessman MJ, Simms ES, Kornberg A (July 1958). «Enzymatic synthesis of deoxyribonucleic acid. I. Preparation of substrates and partial purification of an enzyme from Escherichia coli». The Journal of Biological Chemistry. 233 (1): 163–70. doi:10.1016/S0021-9258(19)68048-8. PMID 13563462.
- ^ Richardson CC, Schildkraut CL, Aposhian HV, Kornberg A (January 1964). «Enzymatic synthesis of deoxyribonucleic acid. XIV. Further purification and properties of deoxyribonucleic acid polymerase of Escherichia coli«. The Journal of Biological Chemistry. 239: 222–32. doi:10.1016/S0021-9258(18)51772-5. PMID 14114848.
- ^ Schachman HK, Adler J, Radding CM, Lehman IR, Kornberg A (November 1960). «Enzymatic synthesis of deoxyribonucleic acid. VII. Synthesis of a polymer of deoxyadenylate and deoxythymidylate». The Journal of Biological Chemistry. 235 (11): 3242–9. doi:10.1016/S0021-9258(20)81345-3. PMID 13747134.
- ^ Zimmerman BK (May 1966). «Purification and properties of deoxyribonucleic acid polymerase from Micrococcus lysodeikticus». The Journal of Biological Chemistry. 241 (9): 2035–41. doi:10.1016/S0021-9258(18)96662-7. PMID 5946628.
- ^ «The Nobel Prize in Physiology or Medicine 1959». Nobel Foundation. Retrieved December 1, 2012.
- ^ Tessman I, Kennedy MA (February 1994). «DNA polymerase II of Escherichia coli in the bypass of abasic sites in vivo». Genetics. 136 (2): 439–48. doi:10.1093/genetics/136.2.439. PMC 1205799. PMID 7908652.
- ^ a b Lehninger AL, Cox MM, Nelson DL (2013). Lehninger principles of biochemistry (6th ed.). New York: W.H. Freeman and Company. ISBN 978-1-4292-3414-6. OCLC 824794893.
- ^ Garrett G (2013). Biochemistry. Mary Finch.
- ^ Hunter WN, Brown T, Anand NN, Kennard O (1986). «Structure of an adenine-cytosine base pair in DNA and its implications for mismatch repair». Nature. 320 (6062): 552–5. Bibcode:1986Natur.320..552H. doi:10.1038/320552a0. PMID 3960137. S2CID 4319887.
- ^ Swan MK, Johnson RE, Prakash L, Prakash S, Aggarwal AK (September 2009). «Structural basis of high-fidelity DNA synthesis by yeast DNA polymerase delta». Nature Structural & Molecular Biology. 16 (9): 979–86. doi:10.1038/nsmb.1663. PMC 3055789. PMID 19718023.
- ^ Steitz TA (June 1999). «DNA polymerases: structural diversity and common mechanisms». The Journal of Biological Chemistry. 274 (25): 17395–8. doi:10.1074/jbc.274.25.17395. PMID 10364165.
- ^ a b c d e Losick R, Watson JD, Baker TA, Bell S, Gann A, Levine MW (2008). Molecular biology of the gene (6th ed.). San Francisco: Pearson/Benjamin Cummings. ISBN 978-0-8053-9592-1.
- ^ McCarthy D, Minner C, Bernstein H, Bernstein C (October 1976). «DNA elongation rates and growing point distributions of wild-type phage T4 and a DNA-delay amber mutant». Journal of Molecular Biology. 106 (4): 963–81. doi:10.1016/0022-2836(76)90346-6. PMID 789903.
- ^ Filée J, Forterre P, Sen-Lin T, Laurent J (June 2002). «Evolution of DNA polymerase families: evidences for multiple gene exchange between cellular and viral proteins» (PDF). Journal of Molecular Evolution. 54 (6): 763–73. Bibcode:2002JMolE..54..763F. CiteSeerX 10.1.1.327.4738. doi:10.1007/s00239-001-0078-x. PMID 12029358. S2CID 15852365. Archived from the original (PDF) on 2020-07-29. Retrieved 2019-09-23.
- ^ a b c Raia P, Carroni M, Henry E, Pehau-Arnaudet G, Brûlé S, Béguin P, Henneke G, Lindahl E, Delarue M, Sauguet L (January 2019). «Structure of the DP1-DP2 PolD complex bound with DNA and its implications for the evolutionary history of DNA and RNA polymerases». PLOS Biology. 17 (1): e3000122. doi:10.1371/journal.pbio.3000122. PMC 6355029. PMID 30657780.
- ^ Boehm EM, Powers KT, Kondratick CM, Spies M, Houtman JC, Washington MT (April 2016). «The Proliferating Cell Nuclear Antigen (PCNA)-interacting Protein (PIP) Motif of DNA Polymerase η Mediates Its Interaction with the C-terminal Domain of Rev1». The Journal of Biological Chemistry. 291 (16): 8735–44. doi:10.1074/jbc.M115.697938. PMC 4861442. PMID 26903512.
- ^ Yang W (May 2014). «An overview of Y-Family DNA polymerases and a case study of human DNA polymerase η». Biochemistry. 53 (17): 2793–803. doi:10.1021/bi500019s. PMC 4018060. PMID 24716551.
- ^ Maga G, Hubscher U, Spadari S, Villani G (2010). DNA Polymerases: Discovery, Characterization Functions in Cellular DNA Transactions. World Scientific Publishing Company. ISBN 978-981-4299-16-9.
- ^ Choi CH, Burton ZF, Usheva A (February 2004). «Auto-acetylation of transcription factors as a control mechanism in gene expression». Cell Cycle. 3 (2): 114–5. doi:10.4161/cc.3.2.651. PMID 14712067.
- ^ Chien A, Edgar DB, Trela JM (September 1976). «Deoxyribonucleic acid polymerase from the extreme thermophile Thermus aquaticus». Journal of Bacteriology. 127 (3): 1550–7. doi:10.1128/JB.127.3.1550-1557.1976. PMC 232952. PMID 8432.
- ^ a b Banach-Orlowska M, Fijalkowska IJ, Schaaper RM, Jonczyk P (October 2005). «DNA polymerase II as a fidelity factor in chromosomal DNA synthesis in Escherichia coli». Molecular Microbiology. 58 (1): 61–70. doi:10.1111/j.1365-2958.2005.04805.x. PMID 16164549. S2CID 12002486.
- ^ InterPro protein view: P61875
- ^ a b c Makarova KS, Krupovic M, Koonin EV (2014). «Evolution of replicative DNA polymerases in archaea and their contributions to the eukaryotic replication machinery». Frontiers in Microbiology. 5: 354. doi:10.3389/fmicb.2014.00354. PMC 4104785. PMID 25101062.
- ^ Rohe M, Schrage K, Meinhardt F (December 1991). «The linear plasmid pMC3-2 from Morchella conica is structurally related to adenoviruses». Current Genetics. 20 (6): 527–33. doi:10.1007/BF00334782. PMID 1782679. S2CID 35072924.
- ^ Olson MW, Dallmann HG, McHenry CS (December 1995). «DnaX complex of Escherichia coli DNA polymerase III holoenzyme. The chi psi complex functions by increasing the affinity of tau and gamma for delta.delta’ to a physiologically relevant range». The Journal of Biological Chemistry. 270 (49): 29570–7. doi:10.1074/jbc.270.49.29570. PMID 7494000.
- ^ Liao Y, Li Y, Schroeder JW, Simmons LA, Biteen JS (December 2016). «Single-Molecule DNA Polymerase Dynamics at a Bacterial Replisome in Live Cells». Biophysical Journal. 111 (12): 2562–2569. Bibcode:2016BpJ…111.2562L. doi:10.1016/j.bpj.2016.11.006. PMC 5192695. PMID 28002733.
- ^ a b c Xu ZQ, Dixon NE (December 2018). «Bacterial replisomes». Current Opinion in Structural Biology. 53: 159–168. doi:10.1016/j.sbi.2018.09.006. PMID 30292863.
- ^ Goodman MF (2002). «Error-prone repair DNA polymerases in prokaryotes and eukaryotes». Annual Review of Biochemistry. 71: 17–50. doi:10.1146/annurev.biochem.71.083101.124707. PMID 12045089. S2CID 1979429.
- ^ Mori T, Nakamura T, Okazaki N, Furukohri A, Maki H, Akiyama MT (2012). «Escherichia coli DinB inhibits replication fork progression without significantly inducing the SOS response». Genes & Genetic Systems. 87 (2): 75–87. doi:10.1266/ggs.87.75. PMID 22820381.
- ^ Jarosz DF, Godoy VG, Walker GC (April 2007). «Proficient and accurate bypass of persistent DNA lesions by DinB DNA polymerases». Cell Cycle. 6 (7): 817–22. doi:10.4161/cc.6.7.4065. PMID 17377496.
- ^ Patel M, Jiang Q, Woodgate R, Cox MM, Goodman MF (June 2010). «A new model for SOS-induced mutagenesis: how RecA protein activates DNA polymerase V». Critical Reviews in Biochemistry and Molecular Biology. 45 (3): 171–84. doi:10.3109/10409238.2010.480968. PMC 2874081. PMID 20441441.
- ^ Sutton MD, Walker GC (July 2001). «Managing DNA polymerases: coordinating DNA replication, DNA repair, and DNA recombination». Proceedings of the National Academy of Sciences of the United States of America. 98 (15): 8342–9. Bibcode:2001PNAS…98.8342S. doi:10.1073/pnas.111036998. PMC 37441. PMID 11459973.
- ^ a b Raychaudhury P, Basu AK (March 2011). «Genetic requirement for mutagenesis of the G[8,5-Me]T cross-link in Escherichia coli: DNA polymerases IV and V compete for error-prone bypass». Biochemistry. 50 (12): 2330–8. doi:10.1021/bi102064z. PMC 3062377. PMID 21302943.
- ^ Madru C, Henneke G, Raia P, Hugonneau-Beaufet I, Pehau-Arnaudet G, England P, et al. (March 2020). «Structural basis for the increased processivity of D-family DNA polymerases in complex with PCNA». Nature Communications. 11 (1): 1591. doi:10.1038/s41467-020-15392-9. PMID 32221299.
- ^ Ishino Y, Komori K, Cann IK, Koga Y (April 1998). «A novel DNA polymerase family found in Archaea». Journal of Bacteriology. 180 (8): 2232–6. doi:10.1128/JB.180.8.2232-2236.1998. PMC 107154. PMID 9555910.
- ^ Sauguet L, Raia P, Henneke G, Delarue M (2016). «Shared active site architecture between archaeal PolD and multi-subunit RNA polymerases revealed by X-ray crystallography». Nature Communications. 7: 12227. Bibcode:2016NatCo…712227S. doi:10.1038/ncomms12227. PMC 4996933. PMID 27548043.
- ^ Yamasaki K, Urushibata Y, Yamasaki T, Arisaka F, Matsui I (August 2010). «Solution structure of the N-terminal domain of the archaeal D-family DNA polymerase small subunit reveals evolutionary relationship to eukaryotic B-family polymerases». FEBS Letters. 584 (15): 3370–5. doi:10.1016/j.febslet.2010.06.026. PMID 20598295. S2CID 11229530.
- ^ Ishino S, Ishino Y (2014). «DNA polymerases as useful reagents for biotechnology — the history of developmental research in the field». Frontiers in Microbiology. 5: 465. doi:10.3389/fmicb.2014.00465. PMC 4148896. PMID 25221550.
- ^ Koonin EV, Krupovic M, Ishino S, Ishino Y (June 2020). «The replication machinery of LUCA: common origin of DNA replication and transcription». BMC Biology. 18 (1): 61. doi:10.1186/s12915-020-00800-9. PMC 7281927. PMID 32517760.
- ^ Yamtich J, Sweasy JB (May 2010). «DNA polymerase family X: function, structure, and cellular roles». Biochimica et Biophysica Acta (BBA) — Proteins and Proteomics. 1804 (5): 1136–50. doi:10.1016/j.bbapap.2009.07.008. PMC 2846199. PMID 19631767.
- ^ Chansky ML, Marks A, Peet A (2012). Marks’ Basic Medical Biochemistry: a clinical approach (4th ed.). Philadelphia: Wolter Kluwer Health/Lippincott Williams & Wilkins. p. chapter13. ISBN 978-1608315727.
- ^ Chung DW, Zhang JA, Tan CK, Davie EW, So AG, Downey KM (December 1991). «Primary structure of the catalytic subunit of human DNA polymerase delta and chromosomal location of the gene». Proceedings of the National Academy of Sciences of the United States of America. 88 (24): 11197–201. Bibcode:1991PNAS…8811197C. doi:10.1073/pnas.88.24.11197. PMC 53101. PMID 1722322.
- ^ Pursell ZF, Isoz I, Lundström EB, Johansson E, Kunkel TA (July 2007). «Yeast DNA polymerase epsilon participates in leading-strand DNA replication». Science. 317 (5834): 127–30. Bibcode:2007Sci…317..127P. doi:10.1126/science.1144067. PMC 2233713. PMID 17615360.
- ^ Lujan SA, Williams JS, Kunkel TA (September 2016). «DNA Polymerases Divide the Labor of Genome Replication». Trends in Cell Biology. 26 (9): 640–654. doi:10.1016/j.tcb.2016.04.012. PMC 4993630. PMID 27262731.
- ^ Johnson RE, Klassen R, Prakash L, Prakash S (July 2015). «A Major Role of DNA Polymerase δ in Replication of Both the Leading and Lagging DNA Strands». Molecular Cell. 59 (2): 163–175. doi:10.1016/j.molcel.2015.05.038. PMC 4517859. PMID 26145172.
- ^ a b Doublié S, Zahn KE (2014). «Structural insights into eukaryotic DNA replication». Frontiers in Microbiology. 5: 444. doi:10.3389/fmicb.2014.00444. PMC 4142720. PMID 25202305.
- ^ Edwards S, Li CM, Levy DL, Brown J, Snow PM, Campbell JL (April 2003). «Saccharomyces cerevisiae DNA polymerase epsilon and polymerase sigma interact physically and functionally, suggesting a role for polymerase epsilon in sister chromatid cohesion». Molecular and Cellular Biology. 23 (8): 2733–48. doi:10.1128/mcb.23.8.2733-2748.2003. PMC 152548. PMID 12665575.
- ^ Zaremba-Niedzwiedzka K, Caceres EF, Saw JH, Bäckström D, Juzokaite L, Vancaester E, Seitz KW, Anantharaman K, Starnawski P, Kjeldsen KU, Stott MB, Nunoura T, Banfield JF, Schramm A, Baker BJ, Spang A, Ettema TJ (January 2017). «Asgard archaea illuminate the origin of eukaryotic cellular complexity». Nature. 541 (7637): 353–358. Bibcode:2017Natur.541..353Z. doi:10.1038/nature21031. OSTI 1580084. PMID 28077874. S2CID 4458094.
- ^ Ohmori H, Hanafusa T, Ohashi E, Vaziri C (2009). Separate roles of structured and unstructured regions of Y-family DNA polymerases. Advances in Protein Chemistry and Structural Biology. Vol. 78. pp. 99–146. doi:10.1016/S1876-1623(08)78004-0. ISBN 9780123748270. PMC 3103052. PMID 20663485.
- ^ Gan GN, Wittschieben JP, Wittschieben BØ, Wood RD (January 2008). «DNA polymerase zeta (pol zeta) in higher eukaryotes». Cell Research. 18 (1): 174–83. doi:10.1038/cr.2007.117. PMID 18157155.
- ^ Bienstock R, Beard W, Wilson S (August 2014). «Phylogenetic analysis and evolutionary origins of DNA polymerase X-family members». DNA Repair. 22: 77–88. doi:10.1016/j.dnarep.2014.07.003. PMC 4260717. PMID 25112931.
- ^ Prasad R, et al. (October 2017). «DNA polymerase β: A missing link of the base excision repair machinery in mammalian mitochondria». DNA Repair. 60: 77–88. doi:10.1016/j.dnarep.2017.10.011. PMC 5919216. PMID 29100041.
- ^ Zhang L, Chan SS, Wolff DJ (July 2011). «Mitochondrial disorders of DNA polymerase γ dysfunction: from anatomic to molecular pathology diagnosis». Archives of Pathology & Laboratory Medicine. 135 (7): 925–34. doi:10.5858/2010-0356-RAR.1. PMC 3158670. PMID 21732785.
- ^ Stumpf JD, Copeland WC (January 2011). «Mitochondrial DNA replication and disease: insights from DNA polymerase γ mutations». Cellular and Molecular Life Sciences. 68 (2): 219–33. doi:10.1007/s00018-010-0530-4. PMC 3046768. PMID 20927567.
- ^ Hogg M, Sauer-Eriksson AE, Johansson E (March 2012). «Promiscuous DNA synthesis by human DNA polymerase θ». Nucleic Acids Research. 40 (6): 2611–22. doi:10.1093/nar/gkr1102. PMC 3315306. PMID 22135286.
- ^ a b «UniProtKB — Q7Z5Q5 (DPOLN_HUMAN)». Uniprot. Retrieved 5 July 2018.
- ^ Cupp JD, Nielsen BL (November 2014). «Minireview: DNA replication in plant mitochondria». Mitochondrion. 19 Pt B: 231–7. doi:10.1016/j.mito.2014.03.008. PMC 417701. PMID 24681310.
- ^ a b c Rawson JM, Nikolaitchik OA, Keele BF, Pathak VK, Hu WS (November 2018). «Recombination is required for efficient HIV-1 replication and the maintenance of viral genome integrity». Nucleic Acids Research. 46 (20): 10535–10545. doi:10.1093/nar/gky910. PMC 6237782. PMID 30307534.
- ^ Cromer D, Grimm AJ, Schlub TE, Mak J, Davenport MP (January 2016). «Estimating the in-vivo HIV template switching and recombination rate». AIDS. 30 (2): 185–92. doi:10.1097/QAD.0000000000000936. PMID 26691546. S2CID 20086739.
- ^ Hu WS, Temin HM (November 1990). «Retroviral recombination and reverse transcription». Science. 250 (4985): 1227–33. Bibcode:1990Sci…250.1227H. doi:10.1126/science.1700865. PMID 1700865.
- ^ Goulian M, Lucas ZJ, Kornberg A (February 1968). «Enzymatic synthesis of deoxyribonucleic acid. XXV. Purification and properties of deoxyribonucleic acid polymerase induced by infection with phage T4». The Journal of Biological Chemistry. 243 (3): 627–38. doi:10.1016/S0021-9258(18)93650-1. PMID 4866523.
- ^ Huang WM, Lehman IR (May 1972). «On the exonuclease activity of phage T4 deoxyribonucleic acid polymerase». The Journal of Biological Chemistry. 247 (10): 3139–46. doi:10.1016/S0021-9258(19)45224-1. PMID 4554914.
- ^ Gillin FD, Nossal NG (September 1976). «Control of mutation frequency by bacteriophage T4 DNA polymerase. I. The CB120 antimutator DNA polymerase is defective in strand displacement». The Journal of Biological Chemistry. 251 (17): 5219–24. doi:10.1016/S0021-9258(17)33149-6. PMID 956182.
- ^ a b Bernstein H (August 1967). «The effect on recombination of mutational defects in the DNA-polymerase and deoxycytidylate hydroxymethylase of phage T4D». Genetics. 56 (4): 755–69. doi:10.1093/genetics/56.4.755. PMC 1211652. PMID 6061665.
Further reading[edit]
- Burgers PM, Koonin EV, Bruford E, Blanco L, Burtis KC, Christman MF, Copeland WC, Friedberg EC, Hanaoka F, Hinkle DC, Lawrence CW, Nakanishi M, Ohmori H, Prakash L, Prakash S, Reynaud CA, Sugino A, Todo T, Wang Z, Weill JC, Woodgate R (November 2001). «Eukaryotic DNA polymerases: proposal for a revised nomenclature». The Journal of Biological Chemistry. 276 (47): 43487–90. doi:10.1074/jbc.R100056200. PMID 11579108.
External links[edit]
- DNA+polymerases at the US National Library of Medicine Medical Subject Headings (MeSH)
- PDB Molecule of the Month DNA polymerase
- Unusual repair mechanism in DNA polymerase lambda, Ohio State University, July 25, 2006.
- A great animation of DNA Polymerase from WEHI at 1:45 minutes in
- 3D macromolecular structures of DNA polymerase from the EM Data Bank(EMDB)
| DNA-directed DNA polymerase | |||||||
|---|---|---|---|---|---|---|---|
|
3D structure of the DNA-binding helix-turn-helix motifs in human DNA polymerase beta (based on PDB file 7ICG) |
|||||||
| Identifiers | |||||||
| EC no. | 2.7.7.7 | ||||||
| CAS no. | 9012-90-2 | ||||||
| Databases | |||||||
| IntEnz | IntEnz view | ||||||
| BRENDA | BRENDA entry | ||||||
| ExPASy | NiceZyme view | ||||||
| KEGG | KEGG entry | ||||||
| MetaCyc | metabolic pathway | ||||||
| PRIAM | profile | ||||||
| PDB structures | RCSB PDB PDBe PDBsum | ||||||
| Gene Ontology | AmiGO / QuickGO | ||||||
|
A DNA polymerase is a member of a family of enzymes that catalyze the synthesis of DNA molecules from nucleoside triphosphates, the molecular precursors of DNA. These enzymes are essential for DNA replication and usually work in groups to create two identical DNA duplexes from a single original DNA duplex. During this process, DNA polymerase «reads» the existing DNA strands to create two new strands that match the existing ones.[1][2][3][4][5][6]
These enzymes catalyze the chemical reaction
- deoxynucleoside triphosphate + DNAn ⇌ pyrophosphate + DNAn+1.
DNA polymerase adds nucleotides to the three prime (3′)-end of a DNA strand, one nucleotide at a time. Every time a cell divides, DNA polymerases are required to duplicate the cell’s DNA, so that a copy of the original DNA molecule can be passed to each daughter cell. In this way, genetic information is passed down from generation to generation.
Before replication can take place, an enzyme called helicase unwinds the DNA molecule from its tightly woven form, in the process breaking the hydrogen bonds between the nucleotide bases. This opens up or «unzips» the double-stranded DNA to give two single strands of DNA that can be used as templates for replication in the above reaction.
History[edit]
In 1956, Arthur Kornberg and colleagues discovered DNA polymerase I (Pol I), in Escherichia coli. They described the DNA replication process by which DNA polymerase copies the base sequence of a template DNA strand. Kornberg was later awarded the Nobel Prize in Physiology or Medicine in 1959 for this work.[7] DNA polymerase II was discovered by Thomas Kornberg (the son of Arthur Kornberg) and Malcolm E. Gefter in 1970 while further elucidating the role of Pol I in E. coli DNA replication.[8] Three more DNA polymerases have been found in E. coli, including DNA polymerase III (discovered in the 1970s) and DNA polymerases IV and V (discovered in 1999).[9]
Function[edit]
DNA polymerase moves along the old strand in the 3’–5′ direction, creating a new strand having a 5’–3′ direction.
DNA polymerase with proofreading ability
The main function of DNA polymerase is to synthesize DNA from deoxyribonucleotides, the building blocks of DNA. The DNA copies are created by the pairing of nucleotides to bases present on each strand of the original DNA molecule. This pairing always occurs in specific combinations, with cytosine along with guanine, and thymine along with adenine, forming two separate pairs, respectively. By contrast, RNA polymerases synthesize RNA from ribonucleotides from either RNA or DNA.
When synthesizing new DNA, DNA polymerase can add free nucleotides only to the 3′ end of the newly forming strand. This results in elongation of the newly forming strand in a 5’–3′ direction.
It is important to note that the directionality of the newly forming strand (the daughter strand) is opposite to the direction in which DNA polymerase moves along the template strand. Since DNA polymerase requires a free 3′ OH group for initiation of synthesis, it can synthesize in only one direction by extending the 3′ end of the preexisting nucleotide chain. Hence, DNA polymerase moves along the template strand in a 3’–5′ direction, and the daughter strand is formed in a 5’–3′ direction. This difference enables the resultant double-strand DNA formed to be composed of two DNA strands that are antiparallel to each other.
The function of DNA polymerase is not quite perfect, with the enzyme making about one mistake for every billion base pairs copied. Error correction is a property of some, but not all DNA polymerases. This process corrects mistakes in newly synthesized DNA. When an incorrect base pair is recognized, DNA polymerase moves backwards by one base pair of DNA. The 3’–5′ exonuclease activity of the enzyme allows the incorrect base pair to be excised (this activity is known as proofreading). Following base excision, the polymerase can re-insert the correct base and replication can continue forwards. This preserves the integrity of the original DNA strand that is passed onto the daughter cells.
Fidelity is very important in DNA replication. Mismatches in DNA base pairing can potentially result in dysfunctional proteins and could lead to cancer. Many DNA polymerases contain an exonuclease domain, which acts in detecting base pair mismatches and further performs in the removal of the incorrect nucleotide to be replaced by the correct one.[10] The shape and the interactions accommodating the Watson and Crick base pair are what primarily contribute to the detection or error. Hydrogen bonds play a key role in base pair binding and interaction. The loss of an interaction, which occurs at a mismatch, is said to trigger a shift in the balance, for the binding of the template-primer, from the polymerase, to the exonuclease domain. In addition, an incorporation of a wrong nucleotide causes a retard in DNA polymerization. This delay gives time for the DNA to be switched from the polymerase site to the exonuclease site. Different conformational changes and loss of interaction occur at different mismatches. In a purine:pyrimidine mismatch there is a displacement of the pyrimidine towards the major groove and the purine towards the minor groove. Relative to the shape of DNA polymerase’s binding pocket, steric clashes occur between the purine and residues in the minor groove, and important van der Waals and electrostatic interactions are lost by the pyrimidine.[11] Pyrimidine:pyrimidine and purine:purine mismatches present less notable changes since the bases are displaced towards the major groove, and less steric hindrance is experienced. However, although the different mismatches result in different steric properties, DNA polymerase is still able to detect and differentiate them so uniformly and maintain fidelity in DNA replication.[12] DNA polymerization is also critical for many mutagenesis processes and is widely employed in biotechnologies.
Structure[edit]
The known DNA polymerases have highly conserved structure, which means that their overall catalytic subunits vary very little from species to species, independent of their domain structures. Conserved structures usually indicate important, irreplaceable functions of the cell, the maintenance of which provides evolutionary advantages. The shape can be described as resembling a right hand with thumb, finger, and palm domains. The palm domain appears to function in catalyzing the transfer of phosphoryl groups in the phosphoryl transfer reaction. DNA is bound to the palm when the enzyme is active. This reaction is believed to be catalyzed by a two-metal-ion mechanism. The finger domain functions to bind the nucleoside triphosphates with the template base. The thumb domain plays a potential role in the processivity, translocation, and positioning of the DNA.[13]
Processivity[edit]
DNA polymerase’s rapid catalysis is due to its processive nature. Processivity is a characteristic of enzymes that function on polymeric substrates. In the case of DNA polymerase, the degree of processivity refers to the average number of nucleotides added each time the enzyme binds a template. The average DNA polymerase requires about one second locating and binding a primer/template junction. Once it is bound, a nonprocessive DNA polymerase adds nucleotides at a rate of one nucleotide per second.[14]: 207–208 Processive DNA polymerases, however, add multiple nucleotides per second, drastically increasing the rate of DNA synthesis. The degree of processivity is directly proportional to the rate of DNA synthesis. The rate of DNA synthesis in a living cell was first determined as the rate of phage T4 DNA elongation in phage infected E. coli. During the period of exponential DNA increase at 37 °C, the rate was 749 nucleotides per second.[15]
DNA polymerase’s ability to slide along the DNA template allows increased processivity. There is a dramatic increase in processivity at the replication fork. This increase is facilitated by the DNA polymerase’s association with proteins known as the sliding DNA clamp. The clamps are multiple protein subunits associated in the shape of a ring. Using the hydrolysis of ATP, a class of proteins known as the sliding clamp loading proteins open up the ring structure of the sliding DNA clamps allowing binding to and release from the DNA strand. Protein–protein interaction with the clamp prevents DNA polymerase from diffusing from the DNA template, thereby ensuring that the enzyme binds the same primer/template junction and continues replication.[14]: 207–208 DNA polymerase changes conformation, increasing affinity to the clamp when associated with it and decreasing affinity when it completes the replication of a stretch of DNA to allow release from the clamp.
Variation across species[edit]
| DNA polymerase family A | |||||||
|---|---|---|---|---|---|---|---|
|
c:o6-methyl-guanine pair in the polymerase-2 basepair position |
|||||||
| Identifiers | |||||||
| Symbol | DNA_pol_A | ||||||
| Pfam | PF00476 | ||||||
| InterPro | IPR001098 | ||||||
| SMART | — | ||||||
| PROSITE | PDOC00412 | ||||||
| SCOP2 | 1dpi / SCOPe / SUPFAM | ||||||
|
| DNA polymerase family B | |||||||
|---|---|---|---|---|---|---|---|
|
crystal structure of rb69 gp43 in complex with dna containing thymine glycol |
|||||||
| Identifiers | |||||||
| Symbol | DNA_pol_B | ||||||
| Pfam | PF00136 | ||||||
| Pfam clan | CL0194 | ||||||
| InterPro | IPR006134 | ||||||
| PROSITE | PDOC00107 | ||||||
| SCOP2 | 1noy / SCOPe / SUPFAM | ||||||
|
| DNA polymerase type B, organellar and viral | |||||||
|---|---|---|---|---|---|---|---|
|
phi29 dna polymerase, orthorhombic crystal form, ssdna complex |
|||||||
| Identifiers | |||||||
| Symbol | DNA_pol_B_2 | ||||||
| Pfam | PF03175 | ||||||
| Pfam clan | CL0194 | ||||||
| InterPro | IPR004868 | ||||||
|
Based on sequence homology, DNA polymerases can be further subdivided into seven different families: A, B, C, D, X, Y, and RT.
Some viruses also encode special DNA polymerases, such as Hepatitis B virus DNA polymerase. These may selectively replicate viral DNA through a variety of mechanisms. Retroviruses encode an unusual DNA polymerase called reverse transcriptase, which is an RNA-dependent DNA polymerase (RdDp). It polymerizes DNA from a template of RNA.
| Family[16] | Types of DNA polymerase | Taxa | Examples | Feature |
|---|---|---|---|---|
| A | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | T7 DNA polymerase, Pol I, Pol γ, θ, and ν | Two exonuclease domains (3′-5′ and 5′-3′) |
| B | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | Pol II, Pol B, Pol ζ, Pol α, δ, and ε | 3′-5 exonuclease (proofreading); viral ones use protein primer |
| C | Replicative Polymerases | Prokaryotic | Pol III | 3′-5 exonuclease (proofreading) |
| D | Replicative Polymerases | Euryarchaeota | PolD (DP1/DP2 heterodimer)[17] | No «hand» feature, double barrel RNA polymerase-like; 3′-5 exonuclease (proofreading) |
| X | Replicative and Repair Polymerases | Eukaryotic | Pol β, Pol σ, Pol λ, Pol μ, and terminal deoxynucleotidyl transferase | template optional; 5′ phosphatase (only Pol β); weak «hand» feature |
| Y | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | Pol ι, Pol κ, Pol η,[18] Pol IV, and Pol V | Translesion synthesis[19] |
| RT | Replicative and Repair Polymerases | Viruses, Retroviruses, and Eukaryotic | Telomerase, Hepatitis B virus | RNA-dependent |
Prokaryotic polymerase[edit]
Prokaryotic polymerases exist in two forms: core polymerase and holoenzyme. Core polymerase synthesizes DNA from the DNA template but it cannot initiate the synthesis alone or accurately. Holoenzyme accurately initiates synthesis.
Pol I[edit]
Prokaryotic family A polymerases include the DNA polymerase I (Pol I) enzyme, which is encoded by the polA gene and ubiquitous among prokaryotes. This repair polymerase is involved in excision repair with both 3’–5′ and 5’–3′ exonuclease activity and processing of Okazaki fragments generated during lagging strand synthesis.[20] Pol I is the most abundant polymerase, accounting for >95% of polymerase activity in E. coli; yet cells lacking Pol I have been found suggesting Pol I activity can be replaced by the other four polymerases. Pol I adds ~15-20 nucleotides per second, thus showing poor processivity. Instead, Pol I starts adding nucleotides at the RNA primer:template junction known as the origin of replication (ori). Approximately 400 bp downstream from the origin, the Pol III holoenzyme is assembled and takes over replication at a highly processive speed and nature.[21]
Taq polymerase is a heat-stable enzyme of this family that lacks proofreading ability.[22]
Pol II[edit]
DNA polymerase II is a family B polymerase encoded by the polB gene. Pol II has 3’–5′ exonuclease activity and participates in DNA repair, replication restart to bypass lesions, and its cell presence can jump from ~30-50 copies per cell to ~200–300 during SOS induction. Pol II is also thought to be a backup to Pol III as it can interact with holoenzyme proteins and assume a high level of processivity. The main role of Pol II is thought to be the ability to direct polymerase activity at the replication fork and help stalled Pol III bypass terminal mismatches.[23]
Pfu DNA polymerase is a heat-stable enzyme of this family found in the hyperthermophilic archaeon Pyrococcus furiosus.[24] Detailed classification divides family B in archaea into B1, B2, B3, in which B2 is a group of pseudoenzymes. Pfu belongs to family B3. Others PolBs found in archaea are part of «Casposons», Cas1-dependent transposons.[25] Some viruses (including Φ29 DNA polymerase) and mitochondrial plasmids carry polB as well.[26]
Pol III[edit]
DNA polymerase III holoenzyme is the primary enzyme involved in DNA replication in E. coli and belongs to family C polymerases. It consists of three assemblies: the pol III core, the beta sliding clamp processivity factor, and the clamp-loading complex. The core consists of three subunits: α, the polymerase activity hub, ɛ, exonucleolytic proofreader, and θ, which may act as a stabilizer for ɛ. The beta sliding clamp processivity factor is also present in duplicate, one for each core, to create a clamp that encloses DNA allowing for high processivity.[27] The third assembly is a seven-subunit (τ2γδδ′χψ) clamp loader complex.
The old textbook «trombone model» depicts an elongation complex with two equivalents of the core enzyme at each replication fork (RF), one for each strand, the lagging and leading.[23] However, recent evidence from single-molecule studies indicates an average of three stoichiometric equivalents of core enzyme at each RF for both Pol III and its counterpart in B. subtilis, PolC.[28] In-cell fluorescent microscopy has revealed that leading strand synthesis may not be completely continuous, and Pol III* (i.e., the holoenzyme α, ε, τ, δ and χ subunits without the ß2 sliding clamp) has a high frequency of dissociation from active RFs.[29] In these studies, the replication fork turnover rate was about 10s for Pol III*, 47s for the ß2 sliding clamp, and 15m for the DnaB helicase. This suggests that the DnaB helicase may remain stably associated at RFs and serve as a nucleation point for the competent holoenzyme. In vitro single-molecule studies have shown that Pol III* has a high rate of RF turnover when in excess, but remains stably associated with replication forks when concentration is limiting.[29] Another single-molecule study showed that DnaB helicase activity and strand elongation can proceed with decoupled, stochastic kinetics.[29]
Pol IV[edit]
In E. coli, DNA polymerase IV (Pol IV) is an error-prone DNA polymerase involved in non-targeted mutagenesis.[30] Pol IV is a Family Y polymerase expressed by the dinB gene that is switched on via SOS induction caused by stalled polymerases at the replication fork. During SOS induction, Pol IV production is increased tenfold and one of the functions during this time is to interfere with Pol III holoenzyme processivity. This creates a checkpoint, stops replication, and allows time to repair DNA lesions via the appropriate repair pathway.[31] Another function of Pol IV is to perform translesion synthesis at the stalled replication fork like, for example, bypassing N2-deoxyguanine adducts at a faster rate than transversing undamaged DNA. Cells lacking the dinB gene have a higher rate of mutagenesis caused by DNA damaging agents.[32]
Pol V[edit]
DNA polymerase V (Pol V) is a Y-family DNA polymerase that is involved in SOS response and translesion synthesis DNA repair mechanisms.[33] Transcription of Pol V via the umuDC genes is highly regulated to produce only Pol V when damaged DNA is present in the cell generating an SOS response. Stalled polymerases causes RecA to bind to the ssDNA, which causes the LexA protein to autodigest. LexA then loses its ability to repress the transcription of the umuDC operon. The same RecA-ssDNA nucleoprotein posttranslationally modifies the UmuD protein into UmuD’ protein. UmuD and UmuD’ form a heterodimer that interacts with UmuC, which in turn activates umuC’s polymerase catalytic activity on damaged DNA.[34] In E. coli, a polymerase «tool belt» model for switching pol III with pol IV at a stalled replication fork, where both polymerases bind simultaneously to the β-clamp, has been proposed.[35] However, the involvement of more than one TLS polymerase working in succession to bypass a lesion has not yet been shown in E. coli. Moreover, Pol IV can catalyze both insertion and extension with high efficiency, whereas pol V is considered the major SOS TLS polymerase. One example is the bypass of intra strand guanine thymine cross-link where it was shown on the basis of the difference in the mutational signatures of the two polymerases, that pol IV and pol V compete for TLS of the intra-strand crosslink.[35]
Family D[edit]
Structures of archaeal polD and eukaryotic Polα. Not only is the general topology conserved, the two also share a bifunctional primase-and-PCNA-binding PIP-box sequence on the C-terminus, similar to both eukaryotic Polα and Polε.[36]
In 1998, the family D of DNA polymerase was discovered in Pyrococcus furiosus and Methanococcus jannaschii.[37] The PolD complex is a heterodimer of two chains, each encoded by DP1 (small proofreading) and DP2 (large catalytic). Unlike other DNA polymerases, the structure and mechanism of the DP2 catalytic core resemble that of multi-subunit RNA polymerases. The DP1-DP2 interface resembles that of Eukaryotic Class B polymerase zinc finger and its small subunit.[17] DP1, a Mre11-like exonuclease,[38] is likely the precursor of small subunit of Pol α and ε, providing proofreading capabilities now lost in Eukaryotes.[25] Its N-terminal HSH domain is similar to AAA proteins, especially Pol III subunit δ and RuvB, in structure.[39] DP2 has a Class II KH domain.[17] Pyrococcus abyssi polD is more heat-stable and more accurate than Taq polymerase, but has not yet been commercialized.[40] It has been proposed that family D DNA polymerase was the first to evolve in cellular organisms and that the replicative polymerase of the Last Universal Cellular Ancestor (LUCA) belonged to family D.[41]
Eukaryotic DNA polymerase[edit]
Polymerases β, λ, σ, μ (beta, lambda, sigma, mu) and TdT[edit]
Family X polymerases contain the well-known eukaryotic polymerase pol β (beta), as well as other eukaryotic polymerases such as Pol σ (sigma), Pol λ (lambda), Pol μ (mu), and Terminal deoxynucleotidyl transferase (TdT). Family X polymerases are found mainly in vertebrates, and a few are found in plants and fungi. These polymerases have highly conserved regions that include two helix-hairpin-helix motifs that are imperative in the DNA-polymerase interactions. One motif is located in the 8 kDa domain that interacts with downstream DNA and one motif is located in the thumb domain that interacts with the primer strand. Pol β, encoded by POLB gene, is required for short-patch base excision repair, a DNA repair pathway that is essential for repairing alkylated or oxidized bases as well as abasic sites. Pol λ and Pol μ, encoded by the POLL and POLM genes respectively, are involved in non-homologous end-joining, a mechanism for rejoining DNA double-strand breaks due to hydrogen peroxide and ionizing radiation, respectively. TdT is expressed only in lymphoid tissue, and adds «n nucleotides» to double-strand breaks formed during V(D)J recombination to promote immunological diversity.[42]
Polymerases α, δ and ε (alpha, delta, and epsilon)[edit]
Pol α (alpha), Pol δ (delta), and Pol ε (epsilon) are members of Family B Polymerases and are the main polymerases involved with nuclear DNA replication. Pol α complex (pol α-DNA primase complex) consists of four subunits: the catalytic subunit POLA1, the regulatory subunit POLA2, and the small and the large primase subunits PRIM1 and PRIM2 respectively. Once primase has created the RNA primer, Pol α starts replication elongating the primer with ~20 nucleotides.[43] Due to its high processivity, Pol δ takes over the leading and lagging strand synthesis from Pol α.[14]: 218–219 Pol δ is expressed by genes POLD1, creating the catalytic subunit, POLD2, POLD3, and POLD4 creating the other subunits that interact with Proliferating Cell Nuclear Antigen (PCNA), which is a DNA clamp that allows Pol δ to possess processivity.[44] Pol ε is encoded by the POLE1, the catalytic subunit, POLE2, and POLE3 gene. It has been reported that the function of Pol ε is to extend the leading strand during replication,[45][46] while Pol δ primarily replicates the lagging strand; however, recent evidence suggested that Pol δ might have a role in replicating the leading strand of DNA as well.[47] Pol ε’s C-terminus «polymerase relic» region, despite being unnecessary for polymerase activity,[48] is thought to be essential to cell vitality. The C-terminus region is thought to provide a checkpoint before entering anaphase, provide stability to the holoenzyme, and add proteins to the holoenzyme necessary for initiation of replication.[49] Pol ε has a larger «palm» domain that provides high processivity independently of PCNA.[48]
Compared to other Family B polymerases, the DEDD exonuclease family responsible for proofreading is inactivated in Pol α.[25] Pol ε is unique in that it has two zinc finger domains and an inactive copy of another family B polymerase in its C-terminal. The presence of this zinc finger has implications in the origins of Eukaryota, which in this case is placed into the Asgard group with archaeal B3 polymerase.[50]
Polymerases η, ι and κ (eta, iota, and kappa)[edit]
Pol η (eta), Pol ι (iota), and Pol κ (kappa), are Family Y DNA polymerases involved in the DNA repair by translation synthesis and encoded by genes POLH, POLI, and POLK respectively. Members of Family Y have five common motifs to aid in binding the substrate and primer terminus and they all include the typical right hand thumb, palm and finger domains with added domains like little finger (LF), polymerase-associated domain (PAD), or wrist. The active site, however, differs between family members due to the different lesions being repaired. Polymerases in Family Y are low-fidelity polymerases, but have been proven to do more good than harm as mutations that affect the polymerase can cause various diseases, such as skin cancer and Xeroderma Pigmentosum Variant (XPS). The importance of these polymerases is evidenced by the fact that gene encoding DNA polymerase η is referred as XPV, because loss of this gene results in the disease Xeroderma Pigmentosum Variant. Pol η is particularly important for allowing accurate translesion synthesis of DNA damage resulting from ultraviolet radiation. The functionality of Pol κ is not completely understood, but researchers have found two probable functions. Pol κ is thought to act as an extender or an inserter of a specific base at certain DNA lesions. All three translesion synthesis polymerases, along with Rev1, are recruited to damaged lesions via stalled replicative DNA polymerases. There are two pathways of damage repair leading researchers to conclude that the chosen pathway depends on which strand contains the damage, the leading or lagging strand.[51]
Polymerases Rev1 and ζ (zeta)[edit]
Pol ζ another B family polymerase, is made of two subunits Rev3, the catalytic subunit, and Rev7 (MAD2L2), which increases the catalytic function of the polymerase, and is involved in translesion synthesis. Pol ζ lacks 3′ to 5′ exonuclease activity, is unique in that it can extend primers with terminal mismatches. Rev1 has three regions of interest in the BRCT domain, ubiquitin-binding domain, and C-terminal domain and has dCMP transferase ability, which adds deoxycytidine opposite lesions that would stall replicative polymerases Pol δ and Pol ε. These stalled polymerases activate ubiquitin complexes that in turn disassociate replication polymerases and recruit Pol ζ and Rev1. Together Pol ζ and Rev1 add deoxycytidine and Pol ζ extends past the lesion. Through a yet undetermined process, Pol ζ disassociates and replication polymerases reassociate and continue replication. Pol ζ and Rev1 are not required for replication, but loss of REV3 gene in budding yeast can cause increased sensitivity to DNA-damaging agents due to collapse of replication forks where replication polymerases have stalled.[52]
Telomerase[edit]
Telomerase is a ribonucleoprotein which functions to replicate ends of linear chromosomes since normal DNA polymerase cannot replicate the ends, or telomeres. The single-strand 3′ overhang of the double-strand chromosome with the sequence 5′-TTAGGG-3′ recruits telomerase. Telomerase acts like other DNA polymerases by extending the 3′ end, but, unlike other DNA polymerases, telomerase does not require a template. The TERT subunit, an example of a reverse transcriptase, uses the RNA subunit to form the primer–template junction that allows telomerase to extend the 3′ end of chromosome ends. The gradual decrease in size of telomeres as the result of many replications over a lifetime are thought to be associated with the effects of aging.[14]: 248–249
Polymerases γ, θ and ν (gamma, theta and nu)[edit]
Pol γ (gamma), Pol θ (theta), and Pol ν (nu) are Family A polymerases. Pol γ, encoded by the POLG gene, was long thought to be the only mitochondrial polymerase. However, recent research shows that at least Pol β (beta), a Family X polymerase, is also present in mitochondria.[53][54] Any mutation that leads to limited or non-functioning Pol γ has a significant effect on mtDNA and is the most common cause of autosomal inherited mitochondrial disorders.[55] Pol γ contains a C-terminus polymerase domain and an N-terminus 3’–5′ exonuclease domain that are connected via the linker region, which binds the accessory subunit. The accessory subunit binds DNA and is required for processivity of Pol γ. Point mutation A467T in the linker region is responsible for more than one-third of all Pol γ-associated mitochondrial disorders.[56] While many homologs of Pol θ, encoded by the POLQ gene, are found in eukaryotes, its function is not clearly understood. The sequence of amino acids in the C-terminus is what classifies Pol θ as Family A polymerase, although the error rate for Pol θ is more closely related to Family Y polymerases. Pol θ extends mismatched primer termini and can bypass abasic sites by adding a nucleotide. It also has Deoxyribophosphodiesterase (dRPase) activity in the polymerase domain and can show ATPase activity in close proximity to ssDNA.[57] Pol ν (nu) is considered to be the least effective of the polymerase enzymes.[58] However, DNA polymerase nu plays an active role in homology repair during cellular responses to crosslinks, fulfilling its role in a complex with helicase.[58]
Plants use two Family A polymerases to copy both the mitochondrial and plastid genomes. They are more similar to bacterial Pol I than they are to mammalian Pol γ.[59]
Reverse transcriptase[edit]
Retroviruses encode an unusual DNA polymerase called reverse transcriptase, which is an RNA-dependent DNA polymerase (RdDp) that synthesizes DNA from a template of RNA. The reverse transcriptase family contain both DNA polymerase functionality and RNase H functionality, which degrades RNA base-paired to DNA. An example of a retrovirus is HIV.[14] Reverse transcriptase is commonly employed in amplification of RNA for research purposes. Using an RNA template, PCR can utilize reverse transcriptase, creating a DNA template. This new DNA template can then be used for typical PCR amplification. The products of such an experiment are thus amplified PCR products from RNA.[9]
Each HIV retrovirus particle contains two RNA genomes, but, after an infection, each virus generates only one provirus.[60] After infection, reverse transcription is accompanied by template switching between the two genome copies (copy choice recombination).[60] From 5 to 14 recombination events per genome occur at each replication cycle.[61] Template switching (recombination) appears to be necessary for maintaining genome integrity and as a repair mechanism for salvaging damaged genomes.[62][60]
Bacteriophage T4 DNA polymerase[edit]
Bacteriophage (phage) T4 encodes a DNA polymerase that catalyzes DNA synthesis in a 5′ to 3′ direction.[63] The phage polymerase also has an exonuclease activity that acts in a 3′ to 5′ direction,[64] and this activity is employed in the proofreading and editing of newly inserted bases.[65] A phage mutant with a temperature sensitive DNA polymerase, when grown at permissive temperatures, was observed to undergo recombination at frequencies that are about two-fold higher than that of wild-type phage.[66]
It was proposed that a mutational alteration in the phage DNA polymerase can stimulate template strand switching (copy choice recombination) during replication.[66]
See also[edit]
- Biological machines
- DNA sequencing
- Enzyme catalysis
- Genetic recombination
- Molecular cloning
- Polymerase chain reaction
- Protein domain dynamics
- Reverse transcription
- RNA polymerase
- Taq DNA polymerase
References[edit]
- ^ Bollum FJ (August 1960). «Calf thymus polymerase». The Journal of Biological Chemistry. 235 (8): 2399–403. doi:10.1016/S0021-9258(18)64634-4. PMID 13802334.
- ^ Falaschi A, Kornberg A (April 1966). «Biochemical studies of bacterial sporulation. II. Deoxy- ribonucleic acid polymerase in spores of Bacillus subtilis». The Journal of Biological Chemistry. 241 (7): 1478–82. doi:10.1016/S0021-9258(18)96736-0. PMID 4957767.
- ^ Lehman IR, Bessman MJ, Simms ES, Kornberg A (July 1958). «Enzymatic synthesis of deoxyribonucleic acid. I. Preparation of substrates and partial purification of an enzyme from Escherichia coli». The Journal of Biological Chemistry. 233 (1): 163–70. doi:10.1016/S0021-9258(19)68048-8. PMID 13563462.
- ^ Richardson CC, Schildkraut CL, Aposhian HV, Kornberg A (January 1964). «Enzymatic synthesis of deoxyribonucleic acid. XIV. Further purification and properties of deoxyribonucleic acid polymerase of Escherichia coli«. The Journal of Biological Chemistry. 239: 222–32. doi:10.1016/S0021-9258(18)51772-5. PMID 14114848.
- ^ Schachman HK, Adler J, Radding CM, Lehman IR, Kornberg A (November 1960). «Enzymatic synthesis of deoxyribonucleic acid. VII. Synthesis of a polymer of deoxyadenylate and deoxythymidylate». The Journal of Biological Chemistry. 235 (11): 3242–9. doi:10.1016/S0021-9258(20)81345-3. PMID 13747134.
- ^ Zimmerman BK (May 1966). «Purification and properties of deoxyribonucleic acid polymerase from Micrococcus lysodeikticus». The Journal of Biological Chemistry. 241 (9): 2035–41. doi:10.1016/S0021-9258(18)96662-7. PMID 5946628.
- ^ «The Nobel Prize in Physiology or Medicine 1959». Nobel Foundation. Retrieved December 1, 2012.
- ^ Tessman I, Kennedy MA (February 1994). «DNA polymerase II of Escherichia coli in the bypass of abasic sites in vivo». Genetics. 136 (2): 439–48. doi:10.1093/genetics/136.2.439. PMC 1205799. PMID 7908652.
- ^ a b Lehninger AL, Cox MM, Nelson DL (2013). Lehninger principles of biochemistry (6th ed.). New York: W.H. Freeman and Company. ISBN 978-1-4292-3414-6. OCLC 824794893.
- ^ Garrett G (2013). Biochemistry. Mary Finch.
- ^ Hunter WN, Brown T, Anand NN, Kennard O (1986). «Structure of an adenine-cytosine base pair in DNA and its implications for mismatch repair». Nature. 320 (6062): 552–5. Bibcode:1986Natur.320..552H. doi:10.1038/320552a0. PMID 3960137. S2CID 4319887.
- ^ Swan MK, Johnson RE, Prakash L, Prakash S, Aggarwal AK (September 2009). «Structural basis of high-fidelity DNA synthesis by yeast DNA polymerase delta». Nature Structural & Molecular Biology. 16 (9): 979–86. doi:10.1038/nsmb.1663. PMC 3055789. PMID 19718023.
- ^ Steitz TA (June 1999). «DNA polymerases: structural diversity and common mechanisms». The Journal of Biological Chemistry. 274 (25): 17395–8. doi:10.1074/jbc.274.25.17395. PMID 10364165.
- ^ a b c d e Losick R, Watson JD, Baker TA, Bell S, Gann A, Levine MW (2008). Molecular biology of the gene (6th ed.). San Francisco: Pearson/Benjamin Cummings. ISBN 978-0-8053-9592-1.
- ^ McCarthy D, Minner C, Bernstein H, Bernstein C (October 1976). «DNA elongation rates and growing point distributions of wild-type phage T4 and a DNA-delay amber mutant». Journal of Molecular Biology. 106 (4): 963–81. doi:10.1016/0022-2836(76)90346-6. PMID 789903.
- ^ Filée J, Forterre P, Sen-Lin T, Laurent J (June 2002). «Evolution of DNA polymerase families: evidences for multiple gene exchange between cellular and viral proteins» (PDF). Journal of Molecular Evolution. 54 (6): 763–73. Bibcode:2002JMolE..54..763F. CiteSeerX 10.1.1.327.4738. doi:10.1007/s00239-001-0078-x. PMID 12029358. S2CID 15852365. Archived from the original (PDF) on 2020-07-29. Retrieved 2019-09-23.
- ^ a b c Raia P, Carroni M, Henry E, Pehau-Arnaudet G, Brûlé S, Béguin P, Henneke G, Lindahl E, Delarue M, Sauguet L (January 2019). «Structure of the DP1-DP2 PolD complex bound with DNA and its implications for the evolutionary history of DNA and RNA polymerases». PLOS Biology. 17 (1): e3000122. doi:10.1371/journal.pbio.3000122. PMC 6355029. PMID 30657780.
- ^ Boehm EM, Powers KT, Kondratick CM, Spies M, Houtman JC, Washington MT (April 2016). «The Proliferating Cell Nuclear Antigen (PCNA)-interacting Protein (PIP) Motif of DNA Polymerase η Mediates Its Interaction with the C-terminal Domain of Rev1». The Journal of Biological Chemistry. 291 (16): 8735–44. doi:10.1074/jbc.M115.697938. PMC 4861442. PMID 26903512.
- ^ Yang W (May 2014). «An overview of Y-Family DNA polymerases and a case study of human DNA polymerase η». Biochemistry. 53 (17): 2793–803. doi:10.1021/bi500019s. PMC 4018060. PMID 24716551.
- ^ Maga G, Hubscher U, Spadari S, Villani G (2010). DNA Polymerases: Discovery, Characterization Functions in Cellular DNA Transactions. World Scientific Publishing Company. ISBN 978-981-4299-16-9.
- ^ Choi CH, Burton ZF, Usheva A (February 2004). «Auto-acetylation of transcription factors as a control mechanism in gene expression». Cell Cycle. 3 (2): 114–5. doi:10.4161/cc.3.2.651. PMID 14712067.
- ^ Chien A, Edgar DB, Trela JM (September 1976). «Deoxyribonucleic acid polymerase from the extreme thermophile Thermus aquaticus». Journal of Bacteriology. 127 (3): 1550–7. doi:10.1128/JB.127.3.1550-1557.1976. PMC 232952. PMID 8432.
- ^ a b Banach-Orlowska M, Fijalkowska IJ, Schaaper RM, Jonczyk P (October 2005). «DNA polymerase II as a fidelity factor in chromosomal DNA synthesis in Escherichia coli». Molecular Microbiology. 58 (1): 61–70. doi:10.1111/j.1365-2958.2005.04805.x. PMID 16164549. S2CID 12002486.
- ^ InterPro protein view: P61875
- ^ a b c Makarova KS, Krupovic M, Koonin EV (2014). «Evolution of replicative DNA polymerases in archaea and their contributions to the eukaryotic replication machinery». Frontiers in Microbiology. 5: 354. doi:10.3389/fmicb.2014.00354. PMC 4104785. PMID 25101062.
- ^ Rohe M, Schrage K, Meinhardt F (December 1991). «The linear plasmid pMC3-2 from Morchella conica is structurally related to adenoviruses». Current Genetics. 20 (6): 527–33. doi:10.1007/BF00334782. PMID 1782679. S2CID 35072924.
- ^ Olson MW, Dallmann HG, McHenry CS (December 1995). «DnaX complex of Escherichia coli DNA polymerase III holoenzyme. The chi psi complex functions by increasing the affinity of tau and gamma for delta.delta’ to a physiologically relevant range». The Journal of Biological Chemistry. 270 (49): 29570–7. doi:10.1074/jbc.270.49.29570. PMID 7494000.
- ^ Liao Y, Li Y, Schroeder JW, Simmons LA, Biteen JS (December 2016). «Single-Molecule DNA Polymerase Dynamics at a Bacterial Replisome in Live Cells». Biophysical Journal. 111 (12): 2562–2569. Bibcode:2016BpJ…111.2562L. doi:10.1016/j.bpj.2016.11.006. PMC 5192695. PMID 28002733.
- ^ a b c Xu ZQ, Dixon NE (December 2018). «Bacterial replisomes». Current Opinion in Structural Biology. 53: 159–168. doi:10.1016/j.sbi.2018.09.006. PMID 30292863.
- ^ Goodman MF (2002). «Error-prone repair DNA polymerases in prokaryotes and eukaryotes». Annual Review of Biochemistry. 71: 17–50. doi:10.1146/annurev.biochem.71.083101.124707. PMID 12045089. S2CID 1979429.
- ^ Mori T, Nakamura T, Okazaki N, Furukohri A, Maki H, Akiyama MT (2012). «Escherichia coli DinB inhibits replication fork progression without significantly inducing the SOS response». Genes & Genetic Systems. 87 (2): 75–87. doi:10.1266/ggs.87.75. PMID 22820381.
- ^ Jarosz DF, Godoy VG, Walker GC (April 2007). «Proficient and accurate bypass of persistent DNA lesions by DinB DNA polymerases». Cell Cycle. 6 (7): 817–22. doi:10.4161/cc.6.7.4065. PMID 17377496.
- ^ Patel M, Jiang Q, Woodgate R, Cox MM, Goodman MF (June 2010). «A new model for SOS-induced mutagenesis: how RecA protein activates DNA polymerase V». Critical Reviews in Biochemistry and Molecular Biology. 45 (3): 171–84. doi:10.3109/10409238.2010.480968. PMC 2874081. PMID 20441441.
- ^ Sutton MD, Walker GC (July 2001). «Managing DNA polymerases: coordinating DNA replication, DNA repair, and DNA recombination». Proceedings of the National Academy of Sciences of the United States of America. 98 (15): 8342–9. Bibcode:2001PNAS…98.8342S. doi:10.1073/pnas.111036998. PMC 37441. PMID 11459973.
- ^ a b Raychaudhury P, Basu AK (March 2011). «Genetic requirement for mutagenesis of the G[8,5-Me]T cross-link in Escherichia coli: DNA polymerases IV and V compete for error-prone bypass». Biochemistry. 50 (12): 2330–8. doi:10.1021/bi102064z. PMC 3062377. PMID 21302943.
- ^ Madru C, Henneke G, Raia P, Hugonneau-Beaufet I, Pehau-Arnaudet G, England P, et al. (March 2020). «Structural basis for the increased processivity of D-family DNA polymerases in complex with PCNA». Nature Communications. 11 (1): 1591. doi:10.1038/s41467-020-15392-9. PMID 32221299.
- ^ Ishino Y, Komori K, Cann IK, Koga Y (April 1998). «A novel DNA polymerase family found in Archaea». Journal of Bacteriology. 180 (8): 2232–6. doi:10.1128/JB.180.8.2232-2236.1998. PMC 107154. PMID 9555910.
- ^ Sauguet L, Raia P, Henneke G, Delarue M (2016). «Shared active site architecture between archaeal PolD and multi-subunit RNA polymerases revealed by X-ray crystallography». Nature Communications. 7: 12227. Bibcode:2016NatCo…712227S. doi:10.1038/ncomms12227. PMC 4996933. PMID 27548043.
- ^ Yamasaki K, Urushibata Y, Yamasaki T, Arisaka F, Matsui I (August 2010). «Solution structure of the N-terminal domain of the archaeal D-family DNA polymerase small subunit reveals evolutionary relationship to eukaryotic B-family polymerases». FEBS Letters. 584 (15): 3370–5. doi:10.1016/j.febslet.2010.06.026. PMID 20598295. S2CID 11229530.
- ^ Ishino S, Ishino Y (2014). «DNA polymerases as useful reagents for biotechnology — the history of developmental research in the field». Frontiers in Microbiology. 5: 465. doi:10.3389/fmicb.2014.00465. PMC 4148896. PMID 25221550.
- ^ Koonin EV, Krupovic M, Ishino S, Ishino Y (June 2020). «The replication machinery of LUCA: common origin of DNA replication and transcription». BMC Biology. 18 (1): 61. doi:10.1186/s12915-020-00800-9. PMC 7281927. PMID 32517760.
- ^ Yamtich J, Sweasy JB (May 2010). «DNA polymerase family X: function, structure, and cellular roles». Biochimica et Biophysica Acta (BBA) — Proteins and Proteomics. 1804 (5): 1136–50. doi:10.1016/j.bbapap.2009.07.008. PMC 2846199. PMID 19631767.
- ^ Chansky ML, Marks A, Peet A (2012). Marks’ Basic Medical Biochemistry: a clinical approach (4th ed.). Philadelphia: Wolter Kluwer Health/Lippincott Williams & Wilkins. p. chapter13. ISBN 978-1608315727.
- ^ Chung DW, Zhang JA, Tan CK, Davie EW, So AG, Downey KM (December 1991). «Primary structure of the catalytic subunit of human DNA polymerase delta and chromosomal location of the gene». Proceedings of the National Academy of Sciences of the United States of America. 88 (24): 11197–201. Bibcode:1991PNAS…8811197C. doi:10.1073/pnas.88.24.11197. PMC 53101. PMID 1722322.
- ^ Pursell ZF, Isoz I, Lundström EB, Johansson E, Kunkel TA (July 2007). «Yeast DNA polymerase epsilon participates in leading-strand DNA replication». Science. 317 (5834): 127–30. Bibcode:2007Sci…317..127P. doi:10.1126/science.1144067. PMC 2233713. PMID 17615360.
- ^ Lujan SA, Williams JS, Kunkel TA (September 2016). «DNA Polymerases Divide the Labor of Genome Replication». Trends in Cell Biology. 26 (9): 640–654. doi:10.1016/j.tcb.2016.04.012. PMC 4993630. PMID 27262731.
- ^ Johnson RE, Klassen R, Prakash L, Prakash S (July 2015). «A Major Role of DNA Polymerase δ in Replication of Both the Leading and Lagging DNA Strands». Molecular Cell. 59 (2): 163–175. doi:10.1016/j.molcel.2015.05.038. PMC 4517859. PMID 26145172.
- ^ a b Doublié S, Zahn KE (2014). «Structural insights into eukaryotic DNA replication». Frontiers in Microbiology. 5: 444. doi:10.3389/fmicb.2014.00444. PMC 4142720. PMID 25202305.
- ^ Edwards S, Li CM, Levy DL, Brown J, Snow PM, Campbell JL (April 2003). «Saccharomyces cerevisiae DNA polymerase epsilon and polymerase sigma interact physically and functionally, suggesting a role for polymerase epsilon in sister chromatid cohesion». Molecular and Cellular Biology. 23 (8): 2733–48. doi:10.1128/mcb.23.8.2733-2748.2003. PMC 152548. PMID 12665575.
- ^ Zaremba-Niedzwiedzka K, Caceres EF, Saw JH, Bäckström D, Juzokaite L, Vancaester E, Seitz KW, Anantharaman K, Starnawski P, Kjeldsen KU, Stott MB, Nunoura T, Banfield JF, Schramm A, Baker BJ, Spang A, Ettema TJ (January 2017). «Asgard archaea illuminate the origin of eukaryotic cellular complexity». Nature. 541 (7637): 353–358. Bibcode:2017Natur.541..353Z. doi:10.1038/nature21031. OSTI 1580084. PMID 28077874. S2CID 4458094.
- ^ Ohmori H, Hanafusa T, Ohashi E, Vaziri C (2009). Separate roles of structured and unstructured regions of Y-family DNA polymerases. Advances in Protein Chemistry and Structural Biology. Vol. 78. pp. 99–146. doi:10.1016/S1876-1623(08)78004-0. ISBN 9780123748270. PMC 3103052. PMID 20663485.
- ^ Gan GN, Wittschieben JP, Wittschieben BØ, Wood RD (January 2008). «DNA polymerase zeta (pol zeta) in higher eukaryotes». Cell Research. 18 (1): 174–83. doi:10.1038/cr.2007.117. PMID 18157155.
- ^ Bienstock R, Beard W, Wilson S (August 2014). «Phylogenetic analysis and evolutionary origins of DNA polymerase X-family members». DNA Repair. 22: 77–88. doi:10.1016/j.dnarep.2014.07.003. PMC 4260717. PMID 25112931.
- ^ Prasad R, et al. (October 2017). «DNA polymerase β: A missing link of the base excision repair machinery in mammalian mitochondria». DNA Repair. 60: 77–88. doi:10.1016/j.dnarep.2017.10.011. PMC 5919216. PMID 29100041.
- ^ Zhang L, Chan SS, Wolff DJ (July 2011). «Mitochondrial disorders of DNA polymerase γ dysfunction: from anatomic to molecular pathology diagnosis». Archives of Pathology & Laboratory Medicine. 135 (7): 925–34. doi:10.5858/2010-0356-RAR.1. PMC 3158670. PMID 21732785.
- ^ Stumpf JD, Copeland WC (January 2011). «Mitochondrial DNA replication and disease: insights from DNA polymerase γ mutations». Cellular and Molecular Life Sciences. 68 (2): 219–33. doi:10.1007/s00018-010-0530-4. PMC 3046768. PMID 20927567.
- ^ Hogg M, Sauer-Eriksson AE, Johansson E (March 2012). «Promiscuous DNA synthesis by human DNA polymerase θ». Nucleic Acids Research. 40 (6): 2611–22. doi:10.1093/nar/gkr1102. PMC 3315306. PMID 22135286.
- ^ a b «UniProtKB — Q7Z5Q5 (DPOLN_HUMAN)». Uniprot. Retrieved 5 July 2018.
- ^ Cupp JD, Nielsen BL (November 2014). «Minireview: DNA replication in plant mitochondria». Mitochondrion. 19 Pt B: 231–7. doi:10.1016/j.mito.2014.03.008. PMC 417701. PMID 24681310.
- ^ a b c Rawson JM, Nikolaitchik OA, Keele BF, Pathak VK, Hu WS (November 2018). «Recombination is required for efficient HIV-1 replication and the maintenance of viral genome integrity». Nucleic Acids Research. 46 (20): 10535–10545. doi:10.1093/nar/gky910. PMC 6237782. PMID 30307534.
- ^ Cromer D, Grimm AJ, Schlub TE, Mak J, Davenport MP (January 2016). «Estimating the in-vivo HIV template switching and recombination rate». AIDS. 30 (2): 185–92. doi:10.1097/QAD.0000000000000936. PMID 26691546. S2CID 20086739.
- ^ Hu WS, Temin HM (November 1990). «Retroviral recombination and reverse transcription». Science. 250 (4985): 1227–33. Bibcode:1990Sci…250.1227H. doi:10.1126/science.1700865. PMID 1700865.
- ^ Goulian M, Lucas ZJ, Kornberg A (February 1968). «Enzymatic synthesis of deoxyribonucleic acid. XXV. Purification and properties of deoxyribonucleic acid polymerase induced by infection with phage T4». The Journal of Biological Chemistry. 243 (3): 627–38. doi:10.1016/S0021-9258(18)93650-1. PMID 4866523.
- ^ Huang WM, Lehman IR (May 1972). «On the exonuclease activity of phage T4 deoxyribonucleic acid polymerase». The Journal of Biological Chemistry. 247 (10): 3139–46. doi:10.1016/S0021-9258(19)45224-1. PMID 4554914.
- ^ Gillin FD, Nossal NG (September 1976). «Control of mutation frequency by bacteriophage T4 DNA polymerase. I. The CB120 antimutator DNA polymerase is defective in strand displacement». The Journal of Biological Chemistry. 251 (17): 5219–24. doi:10.1016/S0021-9258(17)33149-6. PMID 956182.
- ^ a b Bernstein H (August 1967). «The effect on recombination of mutational defects in the DNA-polymerase and deoxycytidylate hydroxymethylase of phage T4D». Genetics. 56 (4): 755–69. doi:10.1093/genetics/56.4.755. PMC 1211652. PMID 6061665.
Further reading[edit]
- Burgers PM, Koonin EV, Bruford E, Blanco L, Burtis KC, Christman MF, Copeland WC, Friedberg EC, Hanaoka F, Hinkle DC, Lawrence CW, Nakanishi M, Ohmori H, Prakash L, Prakash S, Reynaud CA, Sugino A, Todo T, Wang Z, Weill JC, Woodgate R (November 2001). «Eukaryotic DNA polymerases: proposal for a revised nomenclature». The Journal of Biological Chemistry. 276 (47): 43487–90. doi:10.1074/jbc.R100056200. PMID 11579108.
External links[edit]
- DNA+polymerases at the US National Library of Medicine Medical Subject Headings (MeSH)
- PDB Molecule of the Month DNA polymerase
- Unusual repair mechanism in DNA polymerase lambda, Ohio State University, July 25, 2006.
- A great animation of DNA Polymerase from WEHI at 1:45 minutes in
- 3D macromolecular structures of DNA polymerase from the EM Data Bank(EMDB)