Hi Florant,
This NMI seems to be know issue with RHEL
NMI An Unrecoverable System Error (NMI) has occurred (iLO application watchdog timeout NMI, Service Information: 0x0000002B, 0x00000000)
please see the below adviosry from REDHAT
https://access.redhat.com/solutions/1309033
IML log has the following entry:
An Unrecoverable System Error (NMI) has occurred (System error code 0x0000002B, 0x00000000)
Resolution
By default systemd starts a watchdog timer on shutdown. Disable ShutdownWatchdogSec to resolve this issue. To disable it, please open /etc/systemd/system.conf file and find following line:
#ShutdownWatchdogSec=10min
Change them to:
ShutdownWatchdogSec=0
Save the file and after that run:
# systemctl daemon-reexec
to allow systemd to know about the updated configuration or reboot the system.
NOTE: You may also wish to look at RuntimeWatchdogSec in the same file, it is disabled by default, please do not enable -it without specific reasons for doing so.
—————————————————————————————————————————————
If still issue persist we recommand log a case with REDHAT.
If you need futher troubleshooting from Hardware side kindly log a case with HPE and share all the logs (AHS and SOS report)
Regards,
Sangam.
I am an HPE employee

Содержание
- NMI error occurs after commands run in Linux operating system — Servers
- Troubleshooting
- Problem
- Resolving The Problem
- Source
- Symptom
- Affected configurations
- Solution
- Workaround
- Additional information
- VE 4.0 Kernel Panic on HP Proliant servers
- mensinck
- Roaming hardrives on a HPE Proliant DL380 Gen 9 24FF exact copy?
- 1 Answer 1
- Related
- Hot Network Questions
- Subscribe to RSS
- Исправляем ошибку 0xc0000e9 при загрузке Windows 7, 10
- Описание ошибки
- Отключите функцию защиты ELAM
- Проблемы при установке
- Исправление ситуации с помощью разнообразных программ
- Проблемы в работающей системе
- Windows 7
- Windows 10
- Проверяем шлейфы
- Маловероятные причины и кардинальные решения
- IO Error Symptoms
- Method 5 Cleaning out Windows Registry
- Solution 2 Change your BIOS settings
- Common Causes of the 0xc00000e9 Unable to Boot Error
- Solution 5 Fix the MBR with Windows PE
- Repair your Errors automatically
- Solution 4 Run a disk check
- Windows 10 Boot Error 0xc000000e
- Perform the Automatic repair
- Rebuild the Boot Configuration Data
- Method 1 Checking the Compatibility of your Hardware
NMI error occurs after commands run in Linux operating system — Servers
Troubleshooting
Problem
NMI error occurs after commands run in Linux operating system — Servers
Resolving The Problem
Source
RETAIN tip: H204966
Symptom
When running a «cat» command to read the contents of the ServeRAID controller driver and/or copying files from one folder to another folder, the server may hang and the following message is found in the IBM server Integrated Management Module (IMM) log:
A software NMI has occurred on system «SN# XXXXXXX»
Fault in slot «All PCI Error» on system «SN# XXXXXXX»
Fault in slot «PCI 5» on system «SN# XXXXXXX»
A Uncorrectable Bus Error has occurred on system «SN# XXXXXXX»
A hard boot of the server is required to recover.
For the ServeRAID M5014 and M5015 SAS/SATA Controllers, this issue is found with firmware version 12.12.0-0056 or below.
For the ServeRAID M1015 SAS or SATA Controller, this issue is found with firmware version 20.10.1-0052 or below.
Affected configurations
The system may be any of the following IBM servers:
- System x3400 M3, type 7378, any model
- System x3400 M3, type 7379, any model
- System x3500 M3, type 7380, any model
- System x3500 M4, type 7383, any model
- System x3550 M3, type 4254, any model
- System x3550 M4, type 7914, any model
- System x3650 M3, type 7945, any model
- System x3650 M4, type 7915, any model
The system is configured with at least one of the following:
- Red Hat Enterprise Linux 4, any Update
- Red Hat Enterprise Linux 5, any Update
- Red Hat Enterprise Linux 6, any Update
- SUSE Linux Enterprise Server 10, any Service Pack
- SUSE Linux Enterprise Server 11, any Service Pack
The system is configured with one or more of the following IBM Options:
- ServeRAID M1015 SAS/SATA Controller, Option part number 46M0831, replacement part number (CRU) 46M0861
- ServeRAID M5014 SAS/SATA Controller, Option part number 46M0916, replacement part number (CRU) 46M0918
- ServeRAID M5015 SAS/SATA Controller, Option part number 46M0829, replacement part number (CRU) 46M0851
This tip is not system specific.
The LSI firmware for the ServeRAID M1015 and M5000 series Controllers is affected.
Note: This does not imply that the network operating system will work under all combinations of hardware and software.
Solution
This behavior is corrected in firmware release for the ServeRAID M5014 and M5015 Controllers higher than 12.12.0-0056.
This behavior is corrected in firmware release for the ServeRAID M1015 Controller higher than 20.10.1-0052.
The files are available at the following URL:
Workaround
Avoid running the commands that trigger this issue.
Additional information
A defect was found in the firmware that is causing the operating system to kernel panic and the system to crash.
The issue occurs because the firmware takes too long to complete the cycle in understanding the commands.
A new firmware has been released to correct this behavior.
Источник
VE 4.0 Kernel Panic on HP Proliant servers
mensinck
Member
We have 2 labs setup with Proxmox VE 4.0 from latest ISO Download.
In one lab we have HP proliant servers with massive kernel panic on Module hpwdt.ko.
Unfortunately we do not have the trace due to HP’s dammed ILO 🙁 but I will give mor Info when catched it up.
We have a ceph cluster with 3 hosts, 3 monitors up and running on this lab and erverything seems to be quite good.
We can start VM’s, also migrate them but as soon you activate HA for any VM we receive a kernel panic on the hhwdt.ko module.
We have DL 360 G6 (lates Bios patches) and a DL380 G( running in this lab.
‘This are the versions we are running.
proxmox-ve: 4.0-16 (running kernel: 4.2.2-1-pve)
pve-manager: 4.0-50 (running version: 4.0-50/d3a6b7e5)
pve-kernel-4.2.2-1-pve: 4.2.2-16
lvm2: 2.02.116-pve1
corosync-pve: 2.3.5-1
libqb0: 0.17.2-1
pve-cluster: 4.0-23
qemu-server: 4.0-31
pve-firmware: 1.1-7
libpve-common-perl: 4.0-32
libpve-access-control: 4.0-9
libpve-storage-perl: 4.0-27
pve-libspice-server1: 0.12.5-1
vncterm: 1.2-1
pve-qemu-kvm: 2.4-10
pve-container: 1.0-10
pve-firewall: 2.0-12
pve-ha-manager: 1.0-10
ksm-control-daemon: 1.2-1
glusterfs-client: 3.5.2-2+deb8u1
lxc-pve: 1.1.3-1
lxcfs: 0.9-pve2
cgmanager: 0.37-pve2
criu: 1.6.0-1
zfsutils: 0.6.5-pve4
Anything known about this kernel panics?
I found some hints googling around.
— blacklisting hpwdt was suggested but not the solution for VE, since we need the watchdog interfaces.
— I also tried grub parameters:
— noautogroup and
— intel_idle.max_cstates=0
with no success.
Since we have no debug symbols for the kernel (I did not find any package about this. ), I could not use kdump to catch the panic up.
Any advise which could help or anone having problem like this.
Источник
Roaming hardrives on a HPE Proliant DL380 Gen 9 24FF exact copy?
HPE Proliant DL380 Gen 9 24FF is faulting due to a flashin read light. The ILM files below indicate that the network port is faulty (attached to the system port). The trouble shooting guides recommend switching the system board.
If we have a second Proliant with the exact same stats can we do a full disk set swap? Will this mean that the system will perform as if it is the original server? The following link seems to indicate that it should work https://support.hpe.com/hpsc/doc/public/display?docId=mmr_kc-0112214
Will there be issues with Domain (SSL certificates?) and will we have to take it out of the domain and join the domain again?
1 Answer 1
You can move disks between ProLiant systems with similar Smart Array RAID controllers if you keep the disks in the same positions.
The RAID configuration lives on the disks, not the controller.
And no, your SSL certificates and Active Directory won’t be affected.

Hot Network Questions
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2022 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2022.11.3.43005
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
Исправляем ошибку 0xc0000e9 при загрузке Windows 7, 10
К самым неприятным нюансам при работе с ОС Windows следует отнести те, которые, вообще, не позволяют запустить операционную систему. Именно такой часто является ошибка 0xc000000e. Впервые столкнувшись с ней, понять причины возникновения достаточно трудно. А борьба с неполадками такого характера должна вестись «с нескольких сторон». Это значит, что стоит применить сразу несколько способов исправить проблему. О них и пойдёт речь.

Причины возникновения и методика устранения ошибки Windows 0xc000000e.
Описание ошибки
Большая часть владельцев ПК при возникновении ошибки даже не пытается вникнуть в содержимое ее описания, появившееся на мониторе. Текст на иностранном языке по умолчанию считается непереводимым или бесполезным. Хотя в данном случае Microsoft дает короткое, но емкое описание проблемы и рецепт ее устранения.
Код ошибки 0xc00000e9 означает, что у ОС проблемы с подключением устройства ввода-вывода информации. Понять это можно, использовав переводчик от Google или Яндекс. Далее приводится перечень вероятных «виновников» проблемы и стандартная рекомендация по перезагрузке.
Не будь ошибка столь «универсальной», этой информации пользователю вполне бы хватило, чтобы ее устранить. Беда в том, что причин, приводящих к ее появлению, гораздо больше, чем содержится в описании.
Отключите функцию защиты ELAM
В том случае, если первый и второй метод не помогли решить проблему—попробуйте отключить технологию ранней защиты от вредоносного ПО — ELAM (Early-launch Anti-Malware ), которая по умолчанию активна.
Примечание. Технология ELAM – позволяет сертифицированным антивирусам загружаться до запуска всего стороннего ПО. Антивирус в этом случае может выполнять раннюю антивирусную проверку и контролировать запуск драйверов и загружаемого ПО.
- Выполните шаги 1-2 из 2 способа.
- Перейдите в раздел Troubleshoot->Advancedoptions-> Startupsettings(Диагностика -> Дополнительные параметры -> Восстановление системы).
- И перезагрузите компьютер, нажав кнопку Restart.
- После следующей загрузки, система автоматически откроет меню настройки параметров загрузки — StartupSetting / Параметры загрузки (кстати, именно отсюда можно загрузить Windows 8 или Windows 10 в безопасном режиме).
- Нажмите F8 чтобы выбрать пункт
 Disable early launch anti-malware protection / Отключить автоматическую перезагрузки при сбое системы.
Disable early launch anti-malware protection / Отключить автоматическую перезагрузки при сбое системы.
Проблемы при установке
Проще всего разобраться с тем, как исправить данную ошибку, можно в момент установки операционной системы. Периферия еще не подключена, следовательно, выбор устройств I/O ограничен. Status 0xc00000e9 при установке Windows 7 или 10 может быть вызван следующими причинами:
- неисправностью носителя (флешка, DVD-диск);
- проблемами в работе жесткого диска ПК;
- неисправностью разъема на материнской плате или шлейфа SATA.
Возможных источников проблем не так много, следовательно, «вычислить виновника» достаточно просто:
- попробуйте другой установочный носитель или создайте его самостоятельно. При этом желательно использовать оригинальный образ операционной системы с сайта Microsoft и утилиту Media Creation Tools. Это в равной степени относится к флешкам и DVD. Как вариант можно записать «болванку» на другом компьютере с минимальной скоростью;
- проверьте правильность подключения HDD, открыв корпус десктопа. Иногда, чтобы избавиться от этой ошибки, достаточно включить кабель SATA в другой свободный разъем на материнской плате;
- если первые два способа не помогают, высока вероятность неисправности устройства хранения данных — жесткого диска или твердотельного накопителя.
Исправление ситуации с помощью разнообразных программ
Давайте сразу исключим возможное влияние вирусов: устанавливаем хороший антивирусник, диагностируем систему.
Дальше, если возникла неожиданная ошибка ввода/вывода именно с кодом 0xc00000e9, действуем следующим образом:
- Скачать любое ПО, способное качественно проверить и исправить ошибки с реестром.
- Если есть точки восстановления – откатить систему к нормальному состоянию.
- Запустить командную строку. Выполнить процедуру sfc /scannow.
- При подозрениях на boot bcd, перезагрузиться, перейти в БИОС, вернуть ему первоначальное состояние. То есть, сбросить настройки на начальные.
При продолжении возникновения неприятной ситуации скачиваем Victoria или MHDD. Запускаем проверку. Последний вариант – попытка переустановки операционной системы. Обязательно следует использовать надежный источник. При невозможности завершения установочного процесса, скорее всего, придется распрощаться с жестким диском и бежать в магазин за новым винчестером.
Знаете английский? Тогда вам может помочь это видео:
Проблемы в работающей системе
Уже установленная и работающая ОС может подкинуть «сюрприз», выдав такую ошибку в момент очередной загрузки. В этом случае первым делом следует отключить периферийные устройства, чтобы исключить возможные источники появления проблемы. Если после перезагрузки система не загрузилась в нормальном режиме, следует переходить к более серьезным действиям.
Windows 7
Ошибка 0xc00000e9 при загрузке Windows 7 говорит о возможных проблемах в работе аппаратной конфигурации. Рассмотрим методы ее исправления, сгруппированные по степени сложности и эффективности.
- Выполняем проверку HDD на наличие ошибок. Предназначенные для этой цели средства ОС запускаются в безопасном режиме. Нажимая функциональную клавишу F8 в момент старта ОС, вы откроете расширенное меню загрузки.
Выбираем безопасный режим с поддержкой командной строки, отмеченный на скриншоте. После запуска потребуется ввести команду проверки диска на ошибки и подтвердить свои действия.
Поскольку в этом режиме меню «Пуск» отсутствует, третьей командой ПК отправляется в перезагрузку. В результате Windows выполнит проверку жесткого диска на наличие ошибок и поврежденных секторов с попутным восстановлением данных. Операция выполняется в пять этапов, а скорость ее завершения зависит от состояния и объема HDD.
Если компьютер загрузится без ошибок, для очистки совести можете выполнить проверку целостности системных файлов.
Таким образом, вы дополнительно убедитесь, что ошибка не вызвана проблемами в работе самой Windows.
- Загружаемся с установочного носителя. В настройках BIOS установите приоритет загрузки, чтобы запустить режим установки с флешки или DVD.
Выбираете пункт, отмеченный на скриншоте, чтобы войти в режим восстановления системы.
Здесь можно последовательно опробовать два выделенных варианта. Если не сработает первый, второй восстановит ОС в устойчивом состоянии с использованием точек System Restore.
Windows 10
Сообщение об ошибке 0xc00000e9 при загрузке Windows 10 вызывается теми же причинами, что и в предыдущих версиях. Отличие заключается в технологии ее устранения. Быстрая загрузка исключает использование клавиши F8. Чтобы войти в режим восстановления сразу, потребуется установочный носитель. Исключением из этого правила могут стать ноутбуки. Часть производителей встраивает в свои модели механизм защиты, который при двух неудачных попытках загрузки ОС автоматически запускает режим восстановления. На десктопе такого «подарка» вам никто не сделает.
Проверяем шлейфы
В настройках БИОС можно обнаружить, что жесткий диск не числится в списке устройств. Соответственно, загрузка с него не может быть произведена. В таком случае необходимо проверить подключено ли комплектующее физически, а именно, не отключены ли шлейфы.
В первую очередь понадобится разобрать компьютер или ноутбук. Жесткий диск подключен к материнской плате при помощи шлейфов. Пользователю необходимо убедиться в их работоспособности. Для этого, следует отключить их, а затем, подключить заново. При это рекомендуется убедиться, что сам шлейф не поврежден.
После этого можно включать компьютер. Если проблема возникала именно по этой причине, то она будет устранена, и система загрузится.
Маловероятные причины и кардинальные решения
Незначительная часть пользователей сталкивается с этой ошибкой в результате установки обновлений, нового ПО или заражения вирусами. Если вы точно уверены, что проблемы в программном обеспечении, можете удалить «виновника» в безопасном режиме. Не выходя из Safe Mode, проведите тестирование системы автономной антивирусной утилитой, запустив ее с флешки.
Если аппаратная конфигурация полностью работоспособна, но систему не удается реанимировать ни одним из перечисленных способов, остается только крайняя мера. Придется пожертвовать несохраненными персональными данными и выполнить «чистую» установку Windows.
IO Error Symptoms
This error may occur suddenly.В When you power on your PC, It will show the windows logo. But it won’t bring any login screen. Instead of login screen, You will see the blue screen and messages something like –
«Windows has encountered a problem communicating with a device connected to your pc.This error can be caused by unplagging a removable storage device…,or by faulty hardware such as a hard drive or CD-ROM.Make sure any removable storage is properly connected and then restart your pc. File:BootBcd Status:0xc00000e9 Info an unexpected I/O error has occured.»
Some users may not see any windows logo and they may see these messages in black screen. It completely indicates that it is a boot error.
Method 5 Cleaning out Windows Registry
Before proceeding, remember that the registry is a complex yet sensitive database on Windows. It is essential in ensuring that the system operates smoothly. Moreover, if you modify it and make even a single punctuation error, you may cause more damage to your computer. So, before you try to manually repair damaged Registry files, you have to make sure that you are absolutely confident that you can correctly complete the process.
What we do recommend is opting for a one-click solution like Auslogics Registry Cleaner. This tool automatically scans and repairs corrupted or damaged registry files that may have caused the error 0xc00000e9. It also creates a backup before every scan so you can easily undo the changes.
Another key thing to remember is that Auslogics Registry Cleaner is 100% free. What’s more, it will take care of all the problematic registry files and not just the ones related to the 0xc00000e9 error. After completing the procedure, you can enjoy optimum computer performance and speed.
Solution 2 Change your BIOS settings
You can try to boot your computer with the hard drive to fix 0xc00000e9. Follow the steps below:
1) Shut down your computer, then press the Power button to boot your computer.
2) Press and hold the button to enter the BIOS setting, generally the ESC, F2, F12 or Delete key (please consult your PC manufacturer or go through your user manual).
3) Once you’re in the BIOS Setup Utility screen, go to Boot options.
4) Once you’re in the Boot options, make sure the first boot device is your hard drive. You can press the arrow key to highlight the hard drive and move it to the top of the boot device list.
5) Save your changes, and reboot your computer. This should fix your problem.
Common Causes of the 0xc00000e9 Unable to Boot Error
In most scenarios, this error leads the user to a blank screen when they try to boot their operating system. In other cases, the user may boot Windows in Normal Mode, but the functionalities are available in Safe Mode. There are several reasons why this problem occurs, and we’ll show them to you so you can have a better understanding of how you can resolve 0xc00000e9 error. Here are some of the factors that cause this issue:
- Viruses corrupting the Registry files or data responsible for properly booting your operating system
- The malfunctioning hard drive
- Outdated or incompatible drivers
- Corrupted data due to abruptly shutting down the computer amidst downloading important updates
- Missing system files due to constantly uninstalling and reinstalling various programs
- Incompatible operating system updates
Solution 5 Fix the MBR with Windows PE
The error 0xc00000e9 can occur when you install Windows without setting the Master Boot Record (MBR), so you should set your C drive as the MBR to fix 0xc00000e9.
Note: This is a complicated and difficult process. You should attempt it only if you’re confident in your computer skills.
1) Connect the hard drive or external drive with the Windows PE to your computer.
2) Launch Windows PE, and set your C drive as your Master Boot Record.
3) Reboot your computer to reinstall Windows to see if the problem is solved.
That’s all there is to it. Hope the solutions help you through. If you have any idea, feel free to comment below and let us know.
Repair your Errors automatically
ugetfix.com team is trying to do its best to help users find the best solutions for eliminating their errors. If you don’t want to struggle with manual repair techniques, please use the automatic software. All recommended products have been tested and approved by our professionals. Tools that you can use to fix your error are listed bellow:
Compatible with Microsoft Windows Compatible with OS X
Still having problems?If you failed to fix your error using Reimage, reach our support team for help. Please, let us know all details that you think we should know about your problem.
Reimage – a patented specialized Windows repair program. It will diagnose your damaged PC. It will scan all System Files, DLLs and Registry Keys that have been damaged by security threats.Reimage – a patented specialized Mac OS X repair program. It will diagnose your damaged computer. It will scan all System Files and Registry Keys that have been damaged by security threats.This patented repair process uses a database of 25 million components that can replace any damaged or missing file on user’s computer.To repair damaged system, you have to purchase the licensed version of Reimage malware removal tool.
Reimage Terms of Use | Reimage Privacy Policy | Product Refund Policy | Reimage Terms of Use | Reimage Privacy Policy | Product Refund Policy |
Solution 4 Run a disk check
The error 0xc00000e9 can be caused by the disk problem. You should make sure that your disk works properly.
1) Boot your computer into Safe Mode. (You can check this article for more information about .)
2) In the search box on your desktop, type cmd. Then right click Command PromptВ (right click cmd if you’re using Windows 7) and click Run as administrator. Then click Yes to confirm.
3) Type chkdsk /f /r, then press Enter on your keyboard.
4пј‰ Press Y on your keyboard.
Note: Disk check will start the next time you boot your PC and it might take some time to complete. If you don’t have time to wait for the disk check to complete when restarting your computer, you can skip it or schedule it again.
Windows 10 Boot Error 0xc000000e
Unplug all USB devices and disconnect if possible all other hard drives.В Then unplug power and remove battery, press and hold the Power button down for 30 seconds, plug back in power cable and try starting again.В Check if this helps to boot normally.
Note: As windows wonвЂt start normally to perform troubleshooting steps, we need boot Windows form installation media to access advanced options and perform startup repair and rebuild Boot configuration data. If you donвЂt have check how to create Windows 10 installation media from here.
Perform the Automatic repair
When you are ready with Windows 10 installation media, or UBD put it to your PC. Now follow steps below to access advanced options and perform startup repair that scan and fix problems prevent windows to start normally.
- Forcefully restart windows and wait for theВ manufacturer logoВ to check the option forВ boot menu, it will usually beВ F12.
- RestartВ the computer, when the manufacturer’s logo is displayed,В keep pressing the Boot menu option keyВ to enter the boot menu and change the boot option toВ CDDVD ROM or removable disk (if you are bootable USB)
- A black screen appears with the gray text “Press any key to boot from CD or DVD”. Press any key.
- Select the correct time and Keyboard type.
- ClickВ Repair your computerВ in the lower left corner
- Click onВ Troubleshooting, advanced option and then clickВ Automatic repair.
- This will scan and detect problems prevent windows starting normally.
- During startup repair, this will diagnose your system corrupt files or botched configuration settings and try to fix them.
- Wait until complete the scanning process, this will automatically restart windows and start computer normally.
Rebuild the Boot Configuration Data
If after startupВ repair still getting the same error then its now time to look at the BCD (В Boot Configuration Data ). As discussed before the main reason behind this error 0xc000000e is the invalid or corrupted BCD (Boot Configuration Data) configuration. Lets follow steps below to rebuild the Boot configuration file.
- Again Access Advanced Startup options and select Command prompt.
- If ask for password type the current user login password and click ok.
- Windows restart and you will see a command prompt,
- Here type the following commands one by one and pressВ Enter after each
Also Read: How to secure all your Windows 10 devices and browse anonymously
Bootrec /scanos Bootrec /fixmbr Bootrec /fixboot Bootrec /rebuildbcd
After that restart Windows and check there is no more Boot Error 0xc000000e while start Windows.
Method 1 Checking the Compatibility of your Hardware
As we’ve mentioned, one of the causes of this error can be malfunctioning or incompatible drivers. As such, we recommend disconnecting external devices, such as USB flash drives and external hard drives. However, leave your keyboard and mouse connected. After disconnecting the external devices, restart your computer.
If this method fixes the issue, you can plug back your devices one at a time. Restart your computer after connecting a device. You should be able to determine which of them causes the error. In this case, you would have to update its driver to the latest manufacturer-recommended version. To complete this step, proceed to Method 3.
Источник
Содержание
- VE 4.0 Kernel Panic on HP Proliant servers
- mensinck
- Sometimes HPE Proliant servers crash due to a NMI while the system is shutting down.
- Issue
- Background
- Description
- Environment
- Subscriber exclusive content
- Steam, Civ6, An unrecoverable error has occurred
- пля шо за бред
- HP PROLIANT DL180 GEN9 AND PCI Express error
- fireon
- fireon
- Unrecoverable system error has occurred
- Answered by:
- Question
- Answers
VE 4.0 Kernel Panic on HP Proliant servers
mensinck
Member
We have 2 labs setup with Proxmox VE 4.0 from latest ISO Download.
In one lab we have HP proliant servers with massive kernel panic on Module hpwdt.ko.
Unfortunately we do not have the trace due to HP’s dammed ILO 🙁 but I will give mor Info when catched it up.
We have a ceph cluster with 3 hosts, 3 monitors up and running on this lab and erverything seems to be quite good.
We can start VM’s, also migrate them but as soon you activate HA for any VM we receive a kernel panic on the hhwdt.ko module.
We have DL 360 G6 (lates Bios patches) and a DL380 G( running in this lab.
‘This are the versions we are running.
proxmox-ve: 4.0-16 (running kernel: 4.2.2-1-pve)
pve-manager: 4.0-50 (running version: 4.0-50/d3a6b7e5)
pve-kernel-4.2.2-1-pve: 4.2.2-16
lvm2: 2.02.116-pve1
corosync-pve: 2.3.5-1
libqb0: 0.17.2-1
pve-cluster: 4.0-23
qemu-server: 4.0-31
pve-firmware: 1.1-7
libpve-common-perl: 4.0-32
libpve-access-control: 4.0-9
libpve-storage-perl: 4.0-27
pve-libspice-server1: 0.12.5-1
vncterm: 1.2-1
pve-qemu-kvm: 2.4-10
pve-container: 1.0-10
pve-firewall: 2.0-12
pve-ha-manager: 1.0-10
ksm-control-daemon: 1.2-1
glusterfs-client: 3.5.2-2+deb8u1
lxc-pve: 1.1.3-1
lxcfs: 0.9-pve2
cgmanager: 0.37-pve2
criu: 1.6.0-1
zfsutils: 0.6.5-pve4
Anything known about this kernel panics?
I found some hints googling around.
— blacklisting hpwdt was suggested but not the solution for VE, since we need the watchdog interfaces.
— I also tried grub parameters:
— noautogroup and
— intel_idle.max_cstates=0
with no success.
Since we have no debug symbols for the kernel (I did not find any package about this. ), I could not use kdump to catch the panic up.
Any advise which could help or anone having problem like this.
Источник
Sometimes HPE Proliant servers crash due to a NMI while the system is shutting down.
Issue
Background
The hpwdt driver ships are part of the kernel and is registered as the NMI handler of last resort. When an NMI happens that is not claimed by any other registered NMI handler the hpwdt driver will bring the system down. This is the expected behavior of hpwdt.
This can happen in multiple ways but on HPE Proliant servers primarily this is done by opening /dev/watchdog and then closing it without stopping the watchdog. When this happens the following message is always seen (note that it does not identify the process that closed /dev/watchdog without stopping the watchdog):
Although hp-asrd was not running in this case, if the process was, it can also start a countdown timer (by default at 600 seconds) but it does not use /dev/watchdog by default — it talks directly to the hardware. If the hp-asrd was running, it updates the watchdog (by default) every second which means for hp-asrd to cause an ASR would mean it could not run for at least 10 minutes (when shutdown correctly it should stop its countdown timer).
Description
Systems are crashing with following panic message:
IML log has the following entry:
Environment
- Red Hat Enterprise Linux 7
- kernel-3.10.0-123.13.1.el7.x86_64
- systemd-208-11.el7_0.5.x86_64
- HP ProLiant DL380p Gen8
- HP ProLiant DL380 Gen9
- hp-asrd or ASR related process is not running.
Subscriber exclusive content
A Red Hat subscription provides unlimited access to our knowledgebase, tools, and much more.
Источник
Steam, Civ6, An unrecoverable error has occurred
Не запускал игры больше полугода и тут внезапно при запуске 6ой цивилизации из стима вылетает такое вот сообщение An unrecoverable error has occurred, and Civilization VI can not continue .
Из ошибок в логе только: ERROR: ld.so: object ‘/home/petr/.steam/ubuntu12_32/gameoverlayrenderer.so’ from LD_PRELOAD cannot be preloaded (wrong ELF class: ELFCLASS32): ignored. .
ldd грит что либы на месте
gdb грит что оно не крашится
У кого запускается, дайте lsof?
Апдейт. Попытался запустить через протон с PROTON_USE_WINED3D=1, но эта дрянь хочет directX11/12 а моя карточка не поддерживает вулкан.
Апдейт. У кого нить запускается на видяхе без вулкана?
Апдейт. Я докопался до ошибки рендерера
Апдейт. Случайно заметил что народ в инете писал про опенгл 4.2 для цивы, но т.к. я точно помнил что на моём 3.1 игра раньше работала, то решил запустить с MESA_GL_VERSION_OVERRIDE=4.2 и о чудо, оно завелось.
Шлю лучи поноса рукожопам из аспира, которые не могут выводить нормальные ошибки и проверяют не те версии опенгла.


Куда-куда, поддержку 32 бит в системе верни, в 20.04 по дефолту её убрали.
1. Как тогда у меня стартует стим, который
2. Как именно её можно вернуть если ia32-libs выпилен давно и капитально?
Там в 20.04 специальные костыли для Стима сделали, погугли.

пля шо за бред
и эти люде делают дистры))) может поэтому и…))
секта ламеров блин… $ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04 LTS Release: 20.04 Codename: focal
$ dpkg -l|grep i38|sed ‘s/i386.*/i386/’ ii gcc-10-base:i386 ii libasound2:i386 ii libasyncns0:i386 ii libatomic1:i386 ii libbsd0:i386 ii libc++1-10:i386 ii libc++abi1-10:i386 ii libc6:i386 ii libcrypt1:i386 ii libdbus-1-3:i386 ii libdrm-amdgpu1:i386 ii libdrm-intel1:i386 ii libdrm-nouveau2:i386 ii libdrm-radeon1:i386 ii libdrm2:i386 ii libedit2:i386 ii libelf1:i386 ii libexpat1:i386 ii libffi7:i386 ii libflac8:i386 ii libfreetype6:i386 ii libgcc-s1:i386 ii libgcrypt20:i386 ii libgl1:i386 ii libgl1-mesa-dri:i386 ii libglapi-mesa:i386 ii libglu1-mesa:i386 ii libglvnd0:i386 ii libglx-mesa0:i386 ii libglx0:i386 ii libgpg-error0:i386 ii libice6:i386 ii libidn2-0:i386 ii libllvm9:i386 ii liblz4-1:i386 ii liblzma5:i386 ii libogg0:i386 ii libopenal1:i386 ii libpciaccess0:i386 ii libpng16-16:i386 ii libpulse0:i386 ii libpulsedsp:i386 ii libsdl2-2.0-0:i386 ii libsensors5:i386 ii libsm6:i386 ii libsndfile1:i386 ii libsndio7.0:i386 ii libstdc++6:i386 ii libsystemd0:i386 ii libtinfo6:i386 ii libudev1:i386 ii libunistring2:i386 ii libuuid1:i386 ii libvorbis0a:i386 ii libvorbisenc2:i386 ii libvorbisfile3:i386 ii libvulkan1:i386 ii libwayland-client0:i386 ii libwayland-cursor0:i386 ii libwayland-egl1:i386 ii libwrap0:i386 ii libx11-6:i386 ii libx11-xcb1:i386 ii libxau6:i386 ii libxcb-dri2-0:i386 ii libxcb-dri3-0:i386 ii libxcb-glx0:i386 ii libxcb-present0:i386 ii libxcb-randr0:i386 ii libxcb-sync1:i386 ii libxcb1:i386 ii libxcursor1:i386 ii libxdamage1:i386 ii libxdmcp6:i386 ii libxext6:i386 ii libxfixes3:i386 ii libxi6:i386 ii libxinerama1:i386 ii libxkbcommon0:i386 ii libxrandr2:i386 ii libxrender1:i386 ii libxshmfence1:i386 ii libxss1:i386 ii libxxf86vm1:i386 ii libzstd1:i386 ii mesa-vulkan-drivers:i386 ii zlib1g:i386
Ну стоят у меня *:i386 пакеты, я ж грю, что стартует стим.
И эти костыли прямо в 18.04 подвезли?

Куда-куда, поддержку 32 бит в системе верни, в 20.04 по дефолту её убрали
А так автор скорее всего чего-то напетрушил с архитектурами. Может наставил и ARM. И чего-то напутал.
у меня такая же проблема с doom eternal. протон высрал лог на 3.7 гигабайт, но игра так и не запустилась

Это ни о чём не говорящая ошибка steam, она есть у всех кто 64бит линукс использует. И у меня тоже. И игровой оверлей при этом прекрасно работает кстати, потому что 64битная либа тем не менее прогрузилась. Битность оверлея не зависит от битности игры.
Ты не ту ошибку лечишь. Цива не по этому не запускается.
Та я знаю что она не поэтому отваливается, я написал что это единственный еррор, если б проблема была в нем уже бы починил. Никаких крашей нет, цива сама на что-то напарывается и выводит окно с ошибкой. Я только не могу понять что именно не так.
Если у тебя запускается можешь lsof выложить?
Источник
HP PROLIANT DL180 GEN9 AND PCI Express error
New Member
Hi,
My HP HP Smart Array P440 Controller on PCI Express Slot1 and i am getting below error
Uncorrectable PCI Express Error (Slot 1, Bus 0, Device 3, Function 0, Error status 0x00000020)
Unrecoverable System Error (NMI) has occurred. System Firmware will log additional details in a separate IML entry if possible
PCI Bus Error (Slot 0, Bus 0, Device 3, Function 0)
i want to know that is that about proxmox driver or other than this.
need any advice.

fireon
Famous Member
What says the IML log? You can read this easy with the HPtools.
apt-key adv —recv-keys —keyserver keyserver.ubuntu.com 527BC53A2689B887
apt-key adv —recv-keys —keyserver keyserver.ubuntu.com FADD8D64B1275EA3
apt-get update
apt-get dist-upgrade
apt-get install hp-health hpssacli hponcfg
Or you can read important things in ILO.
Best Regards
Fireon
Deutsch PVE Dokumentation: http://deepdoc.at
DEEPDOC.AT — enjoy your brain
New Member
thanks for your reply.
i wrote what ILO said.
Critical PCI Bus 12/29/2015 18:15 12/29/2015 18:15 1 PCI Bus Error (Slot 0, Bus 0, Device 3, Function 0)
above lines from my HP DL180 GEN9 ILO.
fireon
Famous Member
Sorry, your 3 images are not visible in your post. Is in the ILO generally an HW Error? When yes. You should contact HP Support for warranty. Can you post Screenshot from ILO status and IML?
Does the system is running normaly or is only this message in IML your problem? Or you are not able to install the system?
Best Regards
Fireon
Deutsch PVE Dokumentation: http://deepdoc.at
DEEPDOC.AT — enjoy your brain
New Member
No image inmy post!?
my system works perfectly, but some times 4-5 days period, proxmox and also al my Virtual Apliance down, theni chack ILO i see these error linesa my P440 Smart Array controller and its pci controller
PCI-E Slot 1 HP Smart Array P440 Controller 749797-001 PDNMF0ARH7U2BX B 3.52
error is :
Critical PCI Bus 12/29/2015 18:15 12/29/2015 18:15 1 Uncorrectable PCI Express Error (Slot 1, Bus 0, Device 3, Function 0, Error status 0x00000020)
Critical System Error 12/29/2015 18:15 12/29/2015 18:15 1 Unrecoverable System Error (NMI) has occurred. System Firmware will log additional details in a separate IML entry if possible
Critical PCI Bus 12/29/2015 18:15 12/29/2015 18:15 1 PCI Bus Error (Slot 0, Bus 0, Device 3, Function 0)
Источник
Unrecoverable system error has occurred
This forum has migrated to Microsoft Q&A. Visit Microsoft Q&A to post new questions.
Answered by:
![]()
Question
![]()
![]()
I have the following error when I try to upload a picture in the conversation in the newsfeed.
I am unable to understand why this error come and how to solve this issue.
Thanks for all your suggestions and solutions in advance.
Answers
![]()
![]()
As i mentioned we had the same issue but now we had fixed it!
We have two Webappliations (one Intranet / one MySite). Both worked with different Service Accounts for the Application Pool of the Webapplication. And this was the mess!
After we have changed this and let the Applicationpool work with the same Service account, it worked!
Please check the configuration of your Web-Applications and the App-Pools.
Источник
-
#1
Добрый день! Есть сервер HP DL 560 Gen9, работающий на windows server 2016. Там живет Microsoft SQL server 2016 и сервер 1с предприятия. В выходные на емэйл пришли ошибки от ilo, сервер перестал пинговаться и видимо завис. Ошибки такие:
— PCI Bus 01/26/2021 15:15 01/26/2021 15:15 1 PCI Bus Error (Slot 0, Bus 0, Device 0, Function 0)
— System Error 01/26/2021 15:15 01/26/2021 15:15 1 Unrecoverable System Error (NMI) has occurred. System Firmware will log additional details in a separate IML entry if possible
— PCI Bus 01/26/2021 15:15 01/26/2021 15:15 1 Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 0, Function 0, Error status 0x00000000)
— PCI Bus 01/26/2021 15:15 [NOT SET] 1 Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 0, Function 0, Error status 0x00000000)
Перезагрузил сервер удаленно через ilo — вроде он ожил. Но на долго ли.. Помогите понять что за ошибка и что сломалось ?
-
#2
HP ProLiant Servers — How to Decode Uncorrectable PCI Express Error
Information
This document will help user in decoding the Uncorrectable PCI Express Error.
Ex: Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 8, Function 0, Error status 0x00000000
Details
This particular PCI Express Error could be decoded by using the logs mentioned below.
- Advanced Survey Report.
- lspci Output from a Linux Machine or ESX Machine.
Advanced Survey Report:

NOTE: Use the Vendor ID and the Device ID to determine the hardware device.
LSPCI Output:
If the server is running Linux or ESX, collect the OS logs from the server.
Check the lspci.txt in the OS logs. User should be able to find the information as listed in the screenshot below:
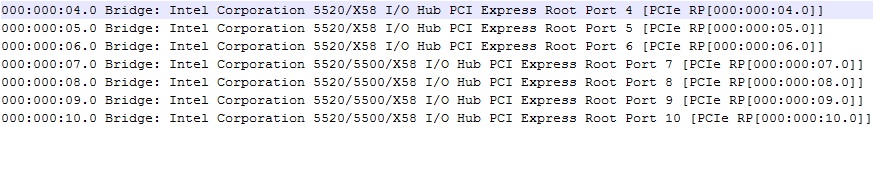
In this Example, check the numbers listed before the word Bridge.
000:000:08.0 Bridge: Intel Corporation 5520/5500/X58 I/O Hub PCI Express Root Port 8.
000 —> Represents PCI Domain (Every PCI Domain could have 256 PCI Buses).
000 —> Bus
08 —> Device
0 —> Function
By using either of these logs, the PCI Express Error could be narrowed down to the hardware device causing the error.
NOTE: The Values mentioned in the IML Logs are Decimal Values. The values in the Advanced Survey Report is in the decimal Value. However the values in the lspci command output is in hexadecimal value. Everytime the values has to be converted to hexadecimal when comparing the values in the lspci output.
-
#3
Если не последняя версия прошивки то можно попробовать вылечить через сервисный пак SPP Gen9 Production Version *: 2021.10.0
Подобного рода алерты как правило часто вызваны устарвшими версиями прошивок таких компонентов как System Rom и ILO.
-
#4
Если не последняя версия прошивки то можно попробовать вылечить через сервисный пак SPP Gen9 Production Version *: 2021.10.0
Подобного рода алерты как правило часто вызваны устарвшими версиями прошивок таких компонентов как System Rom и ILO.
Попробую но не думаю что это поможет, позже напишу. Сейчас нет возможности перезагрузить сервер

-
#5
Если не последняя версия прошивки то можно попробовать вылечить через сервисный пак SPP Gen9 Production Version *: 2021.10.0
Подобного рода алерты как правило часто вызваны устарвшими версиями прошивок таких компонентов как System Rom и ILO.
Хьюлеты при обращении в саппорт или в другой любой непонятной ситуации выдают стандартный ответ — обновите прошивку
-
#6
Обновил все firmware. Пока полет нормальный. Думаю помогло.
Issue
Background
The hpwdt driver ships are part of the kernel and is registered as the NMI handler of last resort. When an NMI happens that is not claimed by any other registered NMI handler the hpwdt driver will bring the system down. This is the expected behavior of hpwdt.
This can happen in multiple ways but on HPE Proliant servers primarily this is done by opening /dev/watchdog and then closing it without stopping the watchdog. When this happens the following message is always seen (note that it does not identify the process that closed /dev/watchdog without stopping the watchdog):
[ 4900.993470] hpwdt: Unexpected close, not stopping watchdog!
Although hp-asrd was not running in this case, if the process was, it can also start a countdown timer (by default at 600 seconds) but it does not use /dev/watchdog by default — it talks directly to the hardware. If the hp-asrd was running, it updates the watchdog (by default) every second which means for hp-asrd to cause an ASR would mean it could not run for at least 10 minutes (when shutdown correctly it should stop its countdown timer).
Description
-
Systems are crashing with following panic message:
[ 5492.146364] Kernel panic - not syncing: An NMI occurred. Depending on your system the reason for the NMI is logged in any one of the following resources: 1. Integrated Management Log (IML) 2. OA Syslog 3. OA Forward Progress Log 4. iLO Event Log [ 5492.505988] CPU: 0 PID: 0 Comm: swapper/0 Not tainted 3.10.0-123.9.2.el7.x86_64 #1 [ 5492.605615] Hardware name: HP ProLiant DL380p Gen8, BIOS P70 08/02/2014 [ 5492.692636] ffffffffa03ae2d8 17844fa82b224426 ffff880fffa06de0 ffffffff815e241b [ 5492.789893] ffff880fffa06e60 ffffffff815db8d9 0000000000000008 ffff880fffa06e70 [ 5492.887146] ffff880fffa06e10 17844fa82b224426 ffffffff8101a6a9 ffffc9001cb22072 [ 5492.984397] Call Trace: [ 5493.016447] <NMI> [<ffffffff815e241b>] dump_stack+0x19/0x1b [ 5493.092031] [<ffffffff815db8d9>] panic+0xd8/0x1e7 [ 5493.155010] [<ffffffff8101a6a9>] ? sched_clock+0x9/0x10 [ 5493.224869] [<ffffffffa03ad8ed>] hpwdt_pretimeout+0xdd/0xe0 [hpwdt] [ 5432188793.308464] [<ffffffff815eb0d9>] nmi_handle.isra.0+0x69/0xb0 [ 5493.384033] [<ffffffff815eb246>] do_nmi+0x126/0x340 [ 5493.449296] [<ffffffff815ea531>] end_repeat_nmi+0x1e/0x2e [ 5493.521458] [<ffffffff8131fa67>] ? intel_idle+0xe7/0x160 [ 5493.592448] [<ffffffff8131fa67>] ? intel_idle+0xe7/0x160 [ 5493.663438] [<ffffffff8131fa67>] ? intel_idle+0xe7/0x160 [ 5493.734432] <<EOE>> [<ffffffff814835a0>] cpuidle_enter_state+0x40/0xc0 [ 5493.822634] [<ffffffff814836e5>] cpuidle_idle_call+0xc5/0x200 [ 5493.899368] [<ffffffff8101bcae>] arch_cpu_idle+0xe/0x30 [ 5493.969241] [<ffffffff810b47e5>] cpu_startup_entry+0xf5/0x290 [ 5494.045960] [<ffffffff815c3cb7>] rest_init+0x77/0x80 [ 5494.112394] [<ffffffff81a08fa7>] start_kernel+0x429/0x44a [ 5494.184531] [<ffffffff81a08987>] ? repair_env_string+0x5c/0x5c [ 5494.262390] [<ffffffff81a08120>] ? early_idt_handlers+0x120/0x120 [ 5494.343686] [<ffffffff81a085ee>] x86_64_start_reservations+0x2a/0x2c [ 5494.428419] [<ffffffff81a08742>] x86_64_start_kernel+0x152/0x175 -
IML log has the following entry:
An Unrecoverable System Error (NMI) has occurred (System error code 0x0000002B, 0x00000000)
Environment
- Red Hat Enterprise Linux 7
- kernel-3.10.0-123.13.1.el7.x86_64
- systemd-208-11.el7_0.5.x86_64
- HP ProLiant DL380p Gen8
- HP ProLiant DL380 Gen9
- hp-asrd or ASR related process is not running.
Subscriber exclusive content
A Red Hat subscription provides unlimited access to our knowledgebase, tools, and much more.
Current Customers and Partners
Log in for full access
Log In
I have a DL380p G8 with 12 drives installed.
Over the last month after a few hours of operation occasionally the server will crash. Checking the iLo it shows:
Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 2, Function 0, Error status 0x00000020)
Unrecoverable System Error (NMI) has occurred. System Firmware will log additional details in a separate IML entry if possible
I have tried the drives with the USB that contains unraid on another DL380p G8 with complete different hardware. And the same issue still occurs. I also did change the USB as that was an old one and was thought to have been the issue but all of the issues persist.
We tried having unraid in Safemode for all testing to ensure only the dockers we have are running with every other plugin/app disabled.
Any help much appreciated as i cannot rebuild the current system as i do not have enough drives to lift some of the data off to a new system.
galar-diagnostics-20220202-0909.zip
-
#1
We have 2 labs setup with Proxmox VE 4.0 from latest ISO Download.
In one lab we have HP proliant servers with massive kernel panic on Module hpwdt.ko.
Unfortunately we do not have the trace due to HP’s dammed ILO  but I will give mor Info when catched it up.
but I will give mor Info when catched it up.
We have a ceph cluster with 3 hosts, 3 monitors up and running on this lab and erverything seems to be quite good.
We can start VM’s, also migrate them but as soon you activate HA for any VM we receive a kernel panic on the hhwdt.ko module.
We have DL 360 G6 (lates Bios patches) and a DL380 G( running in this lab.
‘This are the versions we are running.
proxmox-ve: 4.0-16 (running kernel: 4.2.2-1-pve)
pve-manager: 4.0-50 (running version: 4.0-50/d3a6b7e5)
pve-kernel-4.2.2-1-pve: 4.2.2-16
lvm2: 2.02.116-pve1
corosync-pve: 2.3.5-1
libqb0: 0.17.2-1
pve-cluster: 4.0-23
qemu-server: 4.0-31
pve-firmware: 1.1-7
libpve-common-perl: 4.0-32
libpve-access-control: 4.0-9
libpve-storage-perl: 4.0-27
pve-libspice-server1: 0.12.5-1
vncterm: 1.2-1
pve-qemu-kvm: 2.4-10
pve-container: 1.0-10
pve-firewall: 2.0-12
pve-ha-manager: 1.0-10
ksm-control-daemon: 1.2-1
glusterfs-client: 3.5.2-2+deb8u1
lxc-pve: 1.1.3-1
lxcfs: 0.9-pve2
cgmanager: 0.37-pve2
criu: 1.6.0-1
zfsutils: 0.6.5-pve4~jessie
Anything known about this kernel panics?
I found some hints googling around.
— blacklisting hpwdt was suggested but not the solution for VE, since we need the watchdog interfaces.
— I also tried grub parameters:
— noautogroup and
— intel_idle.max_cstates=0
with no success.
Since we have no debug symbols for the kernel (I did not find any package about this….), I could not use kdump to catch the panic up.
Any advise which could help or anone having problem like this.
-
#2
Hi all.
I investigated a bit more now and found the following:
Kernel modules loaded are:
iTCO_wdt 16384 0
iTCO_vendor_support 16384 1 iTCO_wdt
hpwdt 16384 1
Watchdog-mux service is using this:
Main PID: 1439 (watchdog-mux) CGroup: /system.slice/watchdog-mux.service
└─1439 /usr/sbin/watchdog-muxOct 21 09:25:10 pmx72 watchdog-mux[1439]: Watchdog driver ‘HP iLO2+ HW Watchdog Timer’, version 0
and a
echo «A» | socat — UNIX-CONNECT:/var/rund/watchdog-mux
will instantly generate the kernel panic.
iLO2 firmware is upgraded to 2.29 (07/16/2015)
Maybe this helps someone to assist.
![]()
-
#3
The watchdog-mux successfully starts and opens the watchdog device (/dev/watchdog)?
Can you test if, with no running watchdog-mux, the watchdog works?
This should reset the machine after a bit.
A Kernel panic in the hpwdt.ko module, which is the HP ILO2+ Watchdog, sound more like a bug in the firmware/module, we do nothing special in the watchdog-mux besides accessing the watchdog API of the kernel.
Last edited: Oct 21, 2015
![]()
-
#4
Is the kernel panic looking something like:
Code:
Kernel panic - not syncing: An NMI occurred, please see the Integrated Management Log for details.
[...]
After a bit of investigating I found some bug report regarding your machines, e.g.:
https://bugzilla.redhat.com/show_bug.cgi?id=438741
(very old bug, but still)
Because your firmware is up to date it could be a hardware failure.
Deactivating the module and so falling back to the softdog would help. This Issue is not a Proxmox VE one.
-
#5
Hi t.lamprecht
Is the kernel panic looking something like:
Code:
Kernel panic - not syncing: An NMI occurred, please see the Integrated Management Log for details. [...]
This is exactly, what I got..
After a bit of investigating I found some bug report regarding your machines, e.g.:
https://bugzilla.redhat.com/show_bug.cgi?id=438741
(very old bug, but still)
Because your firmware is up to date it could be a hardware failure.Deactivating the module and so falling back to the softdog would help. This Issue is not a Proxmox VE one.
You are right, I already found this also. Thought it was only related to 3.x kernels.
And blacklisting hpwdt.ko will love the kernel panic.
Doing
with watchdog-service off (kernel module hpwdt.ko blacklisted), as well as
Code:
echo "A" | socat - UNIX-CONNECT:/var/run/watchdog-mux.sockwith service activated will reboot the server now.
So we can conclude, this is related to the kernel bug with hpwdt, since
will produce the kernel panic with hpwdt.ko loaded.
Thank’s a lot for investigating.
Regards Lukas
-
#6
I have the same problem with HP DL320e Gen8 v2. If you blacklist watchdog module server not panic but reset immediatelly. In iLO log you will probably find NMI exception with end of error code 2B.
This issue exists when your server runs out of memory and have much I/O load at the same time. If you use ZFS storage you should have 16 GB RAM, 8GB is total minimum.
-
#7
I setup a fresh 3.4 cluster just for testing out the upgrade procedure. 3.4 has been running on the cluster for a week now with no issues (Before this it was running 3.4 for a few months so I know its solid hardware). Followed the steps to upgrade to 4.0 and overall it went well. The only issue is now 1 of my HP servers throws a NMI and panics as soon as it boots into the OS. I have an identical server which is not having the issue at all.
They are both HP DL380 Gen9’s.
I even tried updating all the firmware/iLO on the node having issues. I find it hard to believe this could be a hardware issue if there are so many of us seeing the issue. We are an HP shop so I have plenty of brand new boxed 380 shells sitting in the warehouse I can test with. Here is what I am seeing in the iLO logs.
An Unrecoverable System Error (NMI) has occurred (iLO application watchdog timeout NMI, Service Information: 0x0000002B, 0x00000000)
I will try to do a shell replacement in the AM and see how it goes.
Last edited: Oct 21, 2015
-
#8
I don’t know if it helps with NMI, but you should try kdump to get more information on what is going bad.
-
#9
I don’t know if it helps with NMI, but you should try kdump to get more information on what is going bad.
I agree, I will dig into that to.
-
#10
I wanted to provide an update. After replacing the shell the issue still persisted. However, I found that the cause is my VM and the large amount of RAM I have assigned. I don’t feel the issue I am seeing is the same one as others in this thread.
-
#11
Try to limit memory to a single NUMA node. (numactl -H to see how much memory is allocated per node)
-
#12
Hello, We have exactly the same issue. We have a cluster on Proxmox V4.0-48 with two Dell R900 and one HP DL380 G9. This occur only on the HP server. With the module hpwdt loaded, a kernel panic happens randomly. Without the module the server reboot. This happens at random, but mostly when we use the live migration. Did you find a workaround ?
-
#13
Hello, We have exactly the same issue. We have a cluster on Proxmox V4.0-48 with two Dell R900 and one HP DL380 G9. This occur only on the HP server. With the module hpwdt loaded, a kernel panic happens randomly. Without the module the server reboot. This happens at random, but mostly when we use the live migration. Did you find a workaround ?
Doesn’t sound quite like the same issue. The kernal panic I see only happens while the VM is starting and CPU load sky rockets. Maybe they are related but they sound a bit different. If you go back to the 4.1 or 3.9 kernel on the HP does the issue go away?
-
#14
I just update the kernel from 4.2.2-1 to 4.2.3-2 to test. The issue occurs most often when we use live migration. In some ways, the VM stop and start… but it’s a bit different, you are right.
-
#15
I just update the kernel from 4.2.2-1 to 4.2.3-2 to test. The issue occurs most often when we use live migration. In some ways, the VM stop and start… but it’s a bit different, you are right.
Still worth trying the older 4.1 or 3.9 kernels. My issue is resolved on the older kernels.
-
#16
Hello everybody! this is my first post on forum.proxmox. Thank you for this post, and the help. i tested this on HP proliant Servers, ILO+Watchdog on linux produces kernel panic,when you use HA on proxmox. But you can solve doing this: the modules what produces this is hpwdt. you must do on each hp node:
Code:
lsmod|grep hpwdt (you check that module is loaded)Stop the service watchdog-mux
Code:
service watchdog-mux stopAdd the module on blacklist:
Code:
nano /etc/modprobe.d/pve-blacklist.confWrite on file the next:
Save the file and reboot
Check again what the module don´t load now.
My configuration: 2 servers Hp proliant + 1 other machine with proxmox 4. HA is working now,
Last edited: Dec 2, 2015
![]()
-
#17
Hello! I’ve got HP DL320e Gen8 v2 and Your solution works for me. Thanks for sharing!
-
#19
I also found a note here:
https://lkml.org/lkml/2014/4/25/184
«hpwdt can not work as expected if hp-asrd is running simultaneously.+Because both hpwdt and hp-asrd update same iLO watchdog timer.»
Do you have an hp-asrd daemon running ? (maybe from some hp management packages ?)
-
#20
Hi,another way could be to disable motherboard watchdog,to use the hp ilo watchdog by default.
Code:
edit: /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="nmi_watchdog=0"
#update-grub
#rebootLast edited: Nov 20, 2015