Время прочтения
9 мин
Просмотры 145K
Я помню, когда я проходил свою первую зарубежную стажировку в CERN в качестве практиканта, большинство людей все еще говорили об открытии бозона Хиггса после подтверждения того, что он соответствует порогу «пять сигм» (что означает наличие p-значения 0,0000003).

Тогда я ничего не знал о p-значении, проверке гипотез или даже статистической значимости.
Я решил загуглить слово — «p-значение», и то, что я нашел в Википедии, заставило меня еще больше запутаться…
При проверке статистических гипотез p-значение или значение вероятности для данной статистической модели — это вероятность того, что при истинности нулевой гипотезы статистическая сводка (например, абсолютное значение выборочной средней разницы между двумя сравниваемыми группами) будет больше или равна фактическим наблюдаемым результатам.
— Wikipedia
Хорошая работа, Википедия.
Ладно. Я не понял, что на самом деле означает р-значение.
Углубившись в область науки о данных, я наконец начал понимать смысл p-значения и то, где его можно использовать как часть инструментов принятия решений в определенных экспериментах.
Поэтому я решил объяснить р-значение в этой статье, а также то, как его можно использовать при проверке гипотез, чтобы дать вам лучшее и интуитивное понимание р-значений.
Также мы не можем пропустить фундаментальное понимание других концепций и определение p-значения, я обещаю, что сделаю это объяснение интуитивно понятным, не подвергая вас всеми техническими терминами, с которыми я столкнулся.
Всего в этой статье четыре раздела, чтобы дать вам полную картину от построения проверки гипотезы до понимания р-значения и использования его в процессе принятия решений. Я настоятельно рекомендую вам пройтись по всем из них, чтобы получить подробное понимание р-значений:
- Проверка гипотезы
- Нормальное распределение
- Что такое P-значение?
- Статистическая значимость
Это будет весело.
Давайте начнем!
1. Проверка гипотез
Прежде чем мы поговорим о том, что означает р-значение, давайте начнем с разбора проверки гипотез, где р-значение используется для определения статистической значимости наших результатов.
Наша конечная цель — определить статистическую значимость наших результатов.
И статистическая значимость построена на этих 3 простых идеях:
- Проверка гипотезы
- Нормальное распределение
- P-значение
Проверка гипотез используется для проверки обоснованности утверждения (нулевой гипотезы), сделанного в отношении совокупности с использованием выборочных данных. Альтернативная гипотеза — это та, в которую вы бы поверили, если бы нулевая гипотеза оказалась неверной.
Другими словами, мы создадим утверждение (нулевая гипотеза) и используем пример данных, чтобы проверить, является ли утверждение действительным. Если утверждение не соответствует действительности, мы выберем альтернативную гипотезу. Все очень просто.
Чтобы узнать, является ли утверждение обоснованным или нет, мы будем использовать p-значение для взвешивания силы доказательств, чтобы увидеть, является ли оно статистически значимым. Если доказательства подтверждают альтернативную гипотезу, то мы отвергнем нулевую гипотезу и примем альтернативную гипотезу. Это будет объяснено в следующем разделе.
Давайте воспользуемся примером, чтобы сделать эту концепцию более ясной, и этот пример будет использоваться на протяжении всей этой статьи для других концепций.
Пример. Предположим, что в пиццерии заявлено, что время их доставки составляет в среднем 30 минут или меньше, но вы думаете, что оно больше чем заявленное. Таким образом, вы проводите проверку гипотезы и случайным образом выбираете время доставки для проверки утверждения:
- Нулевая гипотеза — среднее время доставки составляет 30 минут или меньше
- Альтернативная гипотеза — среднее время доставки превышает 30 минут
- Цель здесь состоит в том, чтобы определить, какое утверждение — нулевое или альтернативное — лучше подтверждается данными, полученными из наших выборочных данных.
Мы будем использовать односторонний тест в нашем случае, так как нам важно только, чтобы среднее время доставки превышало 30 минут. Мы не будем учитывать эту возможность в другом направлении, поскольку последствия того, что среднее время доставки будет меньше или равно 30 минутам, еще более предпочтительны. Здесь мы хотим проверить, есть ли вероятность того, что среднее время доставки превышает 30 минут. Другими словами, мы хотим посмотреть, не обманула ли нас пиццерия.
Одним из распространенных способов проверки гипотез является использование Z-критерия. Здесь мы не будем вдаваться в подробности, так как хотим лучше понять, что происходит на поверхности, прежде чем погрузиться глубже.
2. Нормальное распределение
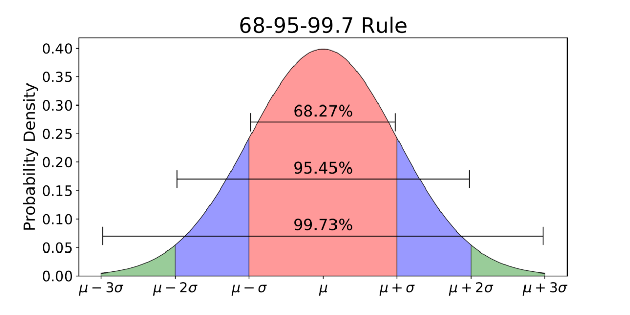
Нормальное распределение — это функция плотности вероятности, используемая для просмотра распределения данных.
Нормальное распределение имеет два параметра — среднее (μ) и стандартное отклонение, также называемое сигма (σ).
Среднее — это центральная тенденция распределения. Оно определяет местоположение пика для нормальных распределений. Стандартное отклонение — это мера изменчивости. Оно определяет, насколько далеко от среднего значения склонны падать значения.
Нормальное распределение обычно связано с правилом 68-95-99.7 (изображение выше).
- 68% данных находятся в пределах 1 стандартного отклонения (σ) от среднего значения (μ)
- 95% данных находятся в пределах 2 стандартных отклонений (σ) от среднего значения (μ)
- 99,7% данных находятся в пределах 3 стандартных отклонений (σ) от среднего значения (μ)
Помните порог «пять сигм» для открытия бозона Хиггса, о котором я говорил в начале? 5 сигм — это около 99,99999426696856% данных, которые должны быть попасть до того, как ученые подтвердили открытие бозона Хиггса. Это был строгий порог, установленный, чтобы избежать любых возможных ложных сигналов.
Классно. Теперь вы можете задаться вопросом: «Как нормальное распределение относится к нашей предыдущей проверке гипотез?»
Поскольку мы использовали Z-тест для проверки нашей гипотезы, нам нужно вычислить Z-баллы (которые будут использоваться в нашей тестовой статистике), которые представляют собой число стандартных отклонений от среднего значения точки данных. В нашем случае каждая точка данных — это время доставки пиццы, которое мы получили.
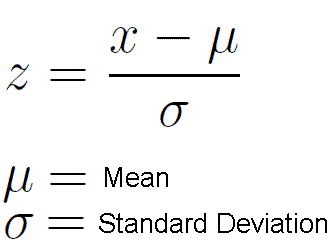
Обратите внимание, что когда мы рассчитали все Z-баллы для каждого времени доставки пиццы и построили стандартную кривую нормального распределения, как показано ниже, единица измерения на оси X изменится с минут на единицу стандартного отклонения, так как мы стандартизировали переменную, вычитая среднее и деля его на стандартное отклонение (см. формулу выше).
Изучение стандартной кривой нормального распределения полезно, потому что мы можем сравнить результаты теста с ”нормальной» популяцией со стандартизированной единицей в стандартном отклонении, особенно когда у нас есть переменная, которая поставляется с различными единицами.
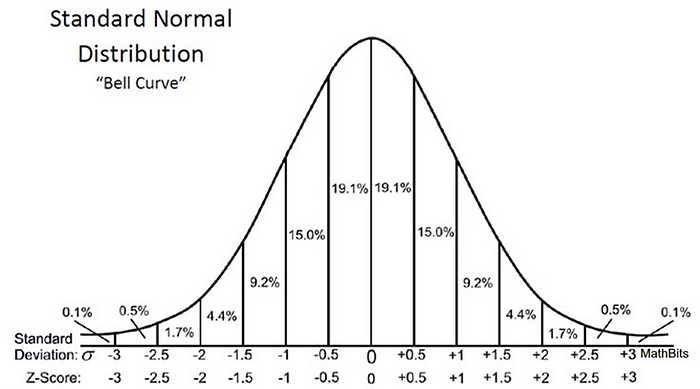
Z-оценка может сказать нам, где лежат общие данные по сравнению со средней популяцией.
Мне нравится, как Уилл Кёрсен выразился: чем выше или ниже Z-показатель, тем менее вероятным будет случайный результат и тем более вероятным будет значимый результат.
Но насколько высокий (или низкий) показатель считается достаточно убедительным, чтобы количественно оценить, насколько значимы наши результаты?
Кульминация
Здесь нам нужен последний элемент для решения головоломки — p-значение, и проверить, являются ли наши результаты статистически значимыми на основе уровня значимости (также известного как альфа), который мы установили перед началом нашего эксперимента.
3. Что такое P-значение?
Наконец… Здесь мы говорим о р-значении!
Все предыдущие объяснения предназначены для того, чтобы подготовить почву и привести нас к этому P-значению. Нам нужен предыдущий контекст и шаги, чтобы понять это таинственное (на самом деле не столь таинственное) р-значение и то, как оно может привести к нашим решениям для проверки гипотезы.
Если вы зашли так далеко, продолжайте читать. Потому что этот раздел — самая захватывающая часть из всех!
Вместо того чтобы объяснять p-значения, используя определение, данное Википедией (извини Википедия), давайте объясним это в нашем контексте — время доставки пиццы!
Напомним, что мы произвольно отобрали некоторые сроки доставки пиццы, и цель состоит в том, чтобы проверить, превышает ли время доставки 30 минут. Если окончательные доказательства подтверждают утверждение пиццерии (среднее время доставки составляет 30 минут или меньше), то мы не будем отвергать нулевую гипотезу. В противном случае мы опровергаем нулевую гипотезу.
Поэтому задача p-значения — ответить на этот вопрос:
Если я живу в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), насколько неожиданными являются мои доказательства в реальной жизни?
Р-значение отвечает на этот вопрос числом — вероятностью.
Чем ниже значение p, тем более неожиданными являются доказательства, тем более нелепой выглядит наша нулевая гипотеза.
И что мы делаем, когда чувствуем себя нелепо с нашей нулевой гипотезой? Мы отвергаем ее и выбираем нашу альтернативную гипотезу.
Если р-значение ниже заданного уровня значимости (люди называют его альфа, я называю это порогом нелепости — не спрашивайте, почему, мне просто легче понять), тогда мы отвергаем нулевую гипотезу.
Теперь мы понимаем, что означает p-значение. Давайте применим это в нашем случае.
P-значение в расчете времени доставки пиццы
Теперь, когда мы собрали несколько выборочных данных о времени доставки, мы выполнили расчет и обнаружили, что среднее время доставки больше на 10 минут с p-значением 0,03.
Это означает, что в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), есть 3% шанс, что мы увидим, что среднее время доставки, по крайней мере, на 10 минут больше, из-за случайного шума.
Чем меньше p-значение, тем более значимым будет результат, потому что он с меньшей вероятностью будет вызван шумом.
В нашем случае большинство людей неправильно понимают р-значение:
Р-значение 0,03 означает, что есть 3% (вероятность в процентах), что результат обусловлен случайностью — что не соответствует действительности.
Люди часто хотят получить определенный ответ (в том числе и я), и именно поэтому я долго путался с интерпретацией p-значений.
Р-значение ничего не *доказывает*. Это просто способ использовать неожиданность в качестве основы для принятия разумного решения.
— Кэсси Козырков
Вот как мы можем использовать p-значение 0,03, чтобы помочь нам принять разумное решение (ВАЖНО):
- Представьте, что мы живем в мире, где среднее время доставки всегда составляет 30 минут или меньше — потому что мы верим в пиццерию (наше первоначальное убеждение)!
- После анализа времени доставки собранных образцов р-значение на 0,03 ниже, чем уровень значимости 0,05 (предположим, что мы установили это значение перед нашим экспериментом), и мы можем сказать, что результат является статистически значимым.
- Поскольку мы всегда верили пиццерии, что она может выполнить свое обещание доставить пиццу за 30 минут или меньше, нам теперь нужно подумать, имеет ли это убеждение смысл, поскольку результат говорит нам о том, что пиццерия не выполняет свое обещание и результат является статистически значимым.
- Так что же нам делать? Сначала мы пытаемся придумать любой возможный способ сделать наше первоначальное убеждение (нулевая гипотеза) верным. Но поскольку пиццерия постепенно получает плохие отзывы от других людей и часто приводит плохие оправдания, которые привели к задержке доставки, даже мы сами чувствуем себя нелепо, чтобы оправдать пиццерию, и, следовательно, мы решаем отвергнуть нулевую гипотезу.
- Наконец, следующее разумное решение — не покупать больше пиццы в этом месте.
К настоящему времени вы, возможно, уже что-то поняли… В зависимости от нашего контекста, p-значения не используются, чтобы что-либо доказать или оправдать.
По моему мнению, p-значения используются в качестве инструмента для оспаривания нашего первоначального убеждения (нулевая гипотеза), когда результат является статистически значимым. В тот момент, когда мы чувствуем себя нелепо с нашим собственным убеждением (при условии, что р-значение показывает, что результат статистически значим), мы отбрасываем наше первоначальное убеждение (отвергаем нулевую гипотезу) и принимаем разумное решение.
4. Статистическая значимость
Наконец, это последний этап, когда мы собираем все вместе и проверяем, является ли результат статистически значимым.
Недостаточно иметь только р-значение, нам нужно установить порог (уровень значимости — альфа). Альфа всегда должна быть установлена перед экспериментом, чтобы избежать смещения. Если наблюдаемое р-значение ниже, чем альфа, то мы заключаем, что результат является статистически значимым.
Основное правило — установить альфа равным 0,05 или 0,01 (опять же, значение зависит от вашей задачи).
Как упоминалось ранее, предположим, что мы установили альфа равным 0,05, прежде чем мы начали эксперимент, полученный результат является статистически значимым, поскольку р-значение 0,03 ниже, чем альфа.
Для справки ниже приведены основные этапы всего эксперимента:
- Сформулируйте нулевую гипотезу
- Сформулируйте альтернативную гипотезу
- Определите значение альфа для использования
- Найдите Z-показатель, связанный с вашим альфа-уровнем
- Найдите тестовую статистику, используя эту формулу
- Если значение тестовой статистики меньше Z-показателя альфа-уровня (или p-значение меньше альфа-значения), отклоните нулевую гипотезу. В противном случае не отвергайте нулевую гипотезу.
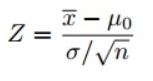
Если вы хотите узнать больше о статистической значимости, не стесняйтесь посмотреть эту статью — Объяснение статистической значимости, написанная Уиллом Керсеном.
Последующие размышления
Здесь много чего нужно переваривать, не так ли?
Я не могу отрицать, что p-значения по своей сути сбивают с толку многих людей, и мне потребовалось довольно много времени, чтобы по-настоящему понять и оценить значение p-значений и то, как они могут быть применены в рамках нашего процесса принятия решений в качестве специалистов по данным.
Но не слишком полагайтесь на p-значения, поскольку они помогают только в небольшой части всего процесса принятия решений.
Я надеюсь, что мое объяснение p-значений стало интуитивно понятным и полезным в вашем понимании того, что в действительности означают p-значения и как их можно использовать при проверке ваших гипотез.
Сам по себе расчет р-значений прост. Трудная часть возникает, когда мы хотим интерпретировать p-значения в проверке гипотез. Надеюсь, что теперь трудная часть станет для вас немного легче.
Если вы хотите узнать больше о статистике, я настоятельно рекомендую вам прочитать эту книгу (которую я сейчас читаю!) — Практическая статистика для специалистов по данным, специально написанная для data scientists, чтобы разобраться с фундаментальными концепциями статистики.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Обучение профессии Data Science с нуля (12 месяцев)
- Профессия аналитика с любым стартовым уровнем (9 месяцев)
- Курс по Machine Learning (12 недель)
- Курс «Python для веб-разработки» (9 месяцев)
- Курс по DevOps (12 месяцев)
- Профессия Веб-разработчик (8 месяцев)
Читать еще
- Тренды в Data Scienсe 2020
- Data Science умерла. Да здравствует Business Science
- Крутые Data Scientist не тратят время на статистику
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Data Science для гуманитариев: что такое «data»
- Data Scienсe на стероидах: знакомство с Decision Intelligence
Что такое p-value?
P-значение (англ. P-value) — величина, используемая при тестировании статистических гипотез. Фактически это вероятность ошибки при отклонении нулевой гипотезы (ошибки первого рода). Проверка гипотез с помощью P-значения является альтернативой классической процедуре проверки через критическое значение распределения.
Обычно P-значение равно вероятности того, что случайная величина с данным распределением (распределением тестовой статистики при нулевой гипотезе) примет значение, не меньшее, чем фактическое значение тестовой статистики. Википедия.
Иначе говоря, p-значение – это наименьшее значение уровня значимости (т.е. вероятности отказа от справедливой гипотезы), для которого вычисленная проверочная статистика ведет к отказу от нулевой гипотезы. Обычно p-значение сравнивают с общепринятыми стандартными уровнями значимости 0,005 или 0,01.
Например, если вычисленное по выборке значение проверочной статистики соответствует p = 0,005, это указывает на вероятность справедливости гипотезы 0,5%. Таким образом, чем p-значение меньше, тем лучше, поскольку при этом увеличивается «сила» отклонения нулевой гипотезы и увеличивается ожидаемая значимость результата.
Интересное объяснение этого есть на Хабре.
Статистический анализ начинает напоминать черный ящик: на вход подаются данные, на выход — таблица основных результатов и значение p-уровня значимости (p-value).
О чём говорит p-value?
Предположим, мы решили выяснить, существует ли взаимосвязь между пристрастием к кровавым компьютерным играм и агрессивностью в реальной жизни. Для этого были случайным образом сформированы две группы школьников по 100 человек в каждой (1 группа — фанаты стрелялок, вторая группа — не играющие в компьютерные игры). В качестве показателя агрессивности выступает, например, число драк со сверстниками. В нашем воображаемом исследовании оказалось, что группа школьников-игроманов действительно заметно чаще конфликтует с товарищами. Но как нам выяснить, насколько статистически достоверны полученные различия? Может быть, мы получили наблюдаемую разницу совершенно случайно? Для ответа на эти вопросы и используется значение p-уровня значимости (p-value) — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет. Иными словами, это вероятность получить такие или еще более сильные различия между нашими группами, при условии, что, на самом деле, компьютерные игры никак не влияют на агрессивность. Звучит не так уж и сложно. Однако, именно этот статистический показатель очень часто интерпретируется неправильно.
Примеры про p-value

Итак, мы сравнили две группы школьников между собой по уровню агрессивности при помощи стандартного t-теста (или непараметрического критерия Хи — квадрат более уместного в данной ситуации) и получили, что заветный p-уровень значимости меньше 0.05 (например 0.04). Но о чем в действительности говорит нам полученное значение p-уровня значимости? Итак, если p-value — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет, то какое, на ваш взгляд, верное утверждение:
1.Компьютерные игры — причина агрессивного поведения с вероятностью 96%.
2. Вероятность того, что агрессивность и компьютерные игры не связаны, равна 0.04.
3. Если бы мы получили p-уровень значимости больше, чем 0.05, это означало бы, что агрессивность и компьютерные игры никак не связаны между собой.
4. Вероятность случайно получить такие различия равняется 0.04.
5. Все утверждения неверны.
Если вы выбрали пятый вариант, то абсолютно правы! Но, как показывают многочисленные исследования, даже люди со значительным опытом в анализе данных часто некорректно интерпретируют значение p-value.
Давайте разберём все ответы по порядку:
Первое утверждение — пример ошибки корреляции: факт значимой взаимосвязи двух переменных ничего не говорит нам о причинах и следствиях. Может быть, это более агрессивные люди предпочитают проводить время за компьютерными играми, а вовсе не компьютерные игры делают людей агрессивнее.
Это уже более интересное утверждение. Всё дело в том, что мы изначально принимаем за данное, что никаких различий на самом деле нет. И, держа это в уме как факт, рассчитываем значение p-value. Поэтому правильная интерпретация: «Если предположить, что агрессивность и компьютерные игры никак не связаны, то вероятность получить такие или еще более выраженные различия составила 0.04».
А что делать, если мы получили незначимые различия? Значит ли это, что никакой связи между исследуемыми переменными нет? Нет, это означает лишь то, что различия, может быть, и есть, но наши результаты не позволили их обнаружить.
Это напрямую связано с самим определением p-value. 0.04 — это вероятность получить такие или ещё более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!
Вот такие подводные камни могут скрываться в интерпретации такого показателя, как p-value. Поэтому очень важно понимать механизмы, заложенные в основании методов анализа и расчета основных статистических показателей.
Как найти p-value?
Источник.
1. Определите ожидаемые в вашем эксперименте результаты
Обычно когда ученые проводят эксперимент, у них уже есть идея того, какие результаты считать «нормальными» или «типичными». Это может быть основано на экспериментальных результатах прошлых опытов, на достоверных наборах данных, на данных из научной литературы, либо ученый может основываться на каких-либо других источниках. Для вашего эксперимента определите ожидаемые результаты, и выразите их в виде чисел.
Пример: Например, более ранние исследования показали, что в вашей стране красные машины чаще получают штрафы за превышение скорости, чем синие машины. Например, средние результаты показывают предпочтение 2:1 красных машин перед синими. Мы хотим определить, относится ли полиция точно так же предвзято к цвету машин в вашем городе. Для этого мы будем анализировать штрафы, выданные за превышение скорости. Если мы возьмем случайный набор из 150 штрафов за превышение скорости, выданных либо красным, либо синим автомобилям, мы ожидаем, что 100 штрафов будет выписано красным автомобилям, а 50 синим, если полиция в нашем городе так же предвзято относится к цвету машин, как это наблюдается по всей стране.
2. Определите наблюдаемые результаты вашего эксперимента
Теперь, когда вы опредили ожидаемые результаты, необходимо провести эксперимент, и найти действительные (или «наблюдаемые») значения. Вам снова необходимо представить эти результаты в виде чисел. Если мы создаем экспериментальные условия, и наблюдаемые результаты отличаются от ожидаемых, то у нас есть две возможности – либо это произошло случайно, либо это вызвано именно нашим экспериментом. Цель нахождения p-значения как раз и состоит в том, чтобы определить, отличаются ли наблюдаемые результаты от ожидаемых настолько, чтобы можно было не отвергать «нулевую гипотезу» – гипотезу о том, что между экспериментальными переменными и наблюдаемыми результатами нет никакой связи.
Пример: Например, в нашем городе мы случайно выбрали 150 штрафов за превышение скорости, которые были выданы либо красным, либо синим автомобилям. Мы определили, что 90 штрафов были выписаны красным автомобилям, и 60 синим. Это отличается от ожидаемых результатов, которые равны 100 и 50, соответственно. Действительно ли наш эксперимент (в данном случае, изменение источника данных с национального на городской) привел к данному изменению в результатах, или наша городская полиция относится предвзято точно так же, как и в среднем по стране, а мы видим просто случайное отклонение? P-значение поможет нам это определить.
3. Определите число степеней свободы вашего эксперимента
Число степеней свободы — это степень изменяемости вашего эксперимента, которая определяется числом категорий, которые вы исследуете. Уравнение для числа степеней свободы – Число степеней свободы = n-1, где «n» это число категорий или переменных, которые вы анализируете в своем эксперименте.
Пример: В нашем эксперименте две категории результатов: одна категория для красных машин, и одна для синих машин. Поэтому в нашем эксперименте у нас 2-1 = 1 степень свободы. Если бы мы сравнивали красные, синие и зеленые машины, у нас было бы 2 степени свободы, и так далее.
4. Сравните ожидаемые и наблюдаемые результаты с помощью критерия хи-квадрат
Хи-квадрат (пишется «x2») это числовое значение, которое измеряет разницу между ожидаемыми и наблюдаемыми значениями эксперимента. Уравнение для хи-квадрата следующее x2 = Σ((o-e)2/e), где «o» это наблюдаемое значение, а «e» это ожидаемое значение. Суммируйте результаты данного уравнения для всех возможных результатов (смотри ниже).
Заметьте, что данное уравнение включает оператор суммирования Σ (сигма). Другими словами, вам необходимо подсчитать ((|o-e|-.05)2/e) для каждого возможного результата, и сложить полученные числа, чтобы получить значение критерия хи-квадрат. В нашем примере у нас два возможных результата – либо машина, получившая штраф красная, либо синяя. Поэтому мы должны посчитать ((o-e)2/e) дважды – один раз для красных машин, и один раз для синих машин.
Пример: Давайте подставим наши ожидаемые и наблюдаемые значения в уравнение x2 = Σ((o-e)2/e). Помните, что из-за оператора суммирования нам необходимо посчитать ((o-e)2/e) дважды – один раз для красных автомобилей, и один раз для синих автомобилей. Мы выполним эту работу следующим образом:
x2 = ((90-100)2/100) + (60-50)2/50)
x2 = ((-10)2/100) + (10)2/50)
x2 = (100/100) + (100/50) = 1 + 2 = 3.
5. Выберите уровень значимости
Теперь, когда мы знаем число степеней свободы нашего эксперимента, и узнали значение критерия хи-квадрат, нам нужно сделать еще одну вещь перед тем, как мы найдем наше p-значение. Нам нужно определить уровень значимости. Говоря простым языком, уровень значимости показывает, насколько мы уверены в наших результатах. Низкое значение для значимости соответствует низкой вероятности того, что экспериментальные результаты получились случайно, и наоборот. Уровни значимости записываются в виде десятичных дробей (таких как 0.01), что соответствует вероятности того, что экспериментальные результаты мы получили случайно (в данном случае вероятность этого 1%).
По соглашению, ученые обычно устанавливают уровень значимости своих экспериментов равным 0.05, или 5%.[2] Это означает, что экспериментальные результаты, которые соответствуют такому критерию значимости, только с вероятностью 5% могли получиться чисто случайно. Другими словами, существует 95% вероятность, что результаты были вызваны тем, как ученый манипулировал экспериментальными переменными, а не случайно. Для большинства экспериментов 95% уверенности наличия связи между двумя переменными достаточно, чтобы считать, что они «действительно» связаны друг с другом.
Пример: для нашего примера с красными и синими машинами, давайте последуем соглашению между учеными, и установим уровень значимости в 0.05.
6. Используйте таблицу с данными распределения хи-квадрат, чтобы найти ваше p-значение
Ученые и статисты используют большие таблицы для вычисления p-значения своих экспериментов. Данные таблицы обычно имеют вертикальную ось слева, соответствующую числу степеней свободы, и горизонтальную ось сверху, соответствующую p-значению. Используйте данные таблицы, чтобы сначала найти число ваших степеней свободы, затем посмотрите на ваш ряд слева направо, пока не найдете первое значение, большее вашего значения хи-квадрат. Посмотрите на соответствующее p-значение вверху вашего столбца. Ваше p-значение находится между этим числом и следующим за ним (тем, которое находится левее вашего).
Таблицы с распределением хи-квадрат можно получить из множества источников (вот по этой ссылке можно найти одну из них).
Пример: Наше значение критерия хи-квадрат было равно 3. Так как мы знаем, что в нашем эксперименте всего 1 степень свободы, выберем самую первую строку. Идем слева направо по данной строке, пока не встретим значение, большее 3, нашего значения критерия хи-квадрат. Первое, которое мы находим это 3.84. Смотрим вверх нашего столбца, и видим, что соответствующее p-значение равно 0.05. Это означает, что наше p-значение между 0.05 и 0.1 (следующее p-значение в таблице по возрастанию).
7. Решите, отклонить или оставить вашу нулевую гипотезу
Так как вы определили приблизительное p-значение для вашего эксперимента, вам необходимо решить, отклонять ли нулевую гипотезу вашего эксперимента или нет (напоминаем, это гипотеза о том, что экспериментальные переменные, которыми вы манипулировали не повлияли на наблюдаемые вами результаты). Если ваше p-значение меньше, чем ваш уровень значимости – поздравляем, вы доказали, что очень вероятна связь между переменными, которыми вы манипулировали и результатами, которые вы наблюдали. Если ваше p-значение выше, чем ваш уровень значимости, вы не можете с уверенностью сказать, были ли наблюдаемые вами результаты результатом чистой случайности или манипуляцией вашими переменными.
Пример: Наше p-значение находится между 0,05 и 0,1. Это явно не меньше, чем 0,05, поэтому, к сожалению, мы не можем отклонить нашу нулевую гипотезу. Это означает, что мы не достигли минимум 95% вероятности того, чтобы сказать, что полиция в нашем городе выдает штрафы красным и синим автомобилям с такой вероятностью, которая достаточно сильно отличается от средней по стране.
Другими словами, существует 5-10% шанс, что наблюдаемые нами результаты – это не последствия смены места (анализа города, а не всей страны), а просто случайность. Так как мы потребовали точности меньше чем 5%, мы не можем сказать что мы уверены в том, что полиция нашего города менее предвзято относится к красным автомобилям – существует небольшая (но статистически значимая) вероятность, что это не так.
В статистике p-значения обычно используются при проверке гипотез для t-тестов, тестов хи-квадрат, регрессионного анализа, дисперсионного анализа и множества других статистических методов.
Несмотря на то, что это так распространено, люди часто неправильно интерпретируют p-значения, что может привести к ошибкам при интерпретации результатов анализа или исследования.
В этом посте объясняется, как понять и интерпретировать p-значения понятным и практичным способом.
Проверка гипотезы
Чтобы понять p-значения, нам сначала нужно понять концепцию проверки гипотез .
Проверка гипотезы — это формальный статистический тест, который мы используем, чтобы отвергнуть или не отвергнуть какую-либо гипотезу. Например, мы можем предположить, что новое лекарство, метод или процедура дает некоторые преимущества по сравнению с текущим лекарством, методом или процедурой.
Чтобы проверить это, мы можем провести проверку гипотезы, в которой мы используем нулевую и альтернативную гипотезы:
Нулевая гипотеза.Между новым и старым методом нет никакого эффекта или разницы.
Альтернативная гипотеза.Между новым и старым методом существует некоторый эффект или разница.
Значение p показывает, насколько правдоподобна нулевая гипотеза с учетом данных выборки. В частности, если предположить, что нулевая гипотеза верна, p-значение говорит нам о вероятности получения эффекта, по крайней мере, такого же большого, как тот, который мы фактически наблюдали в выборке данных.
Если p-значение проверки гипотезы достаточно низкое, мы можем отклонить нулевую гипотезу. В частности, когда мы проводим проверку гипотезы, мы должны с самого начала выбрать уровень значимости. Обычный выбор уровней значимости: 0,01, 0,05 и 0,10.
Если p-значения меньше нашего уровня значимости, мы можем отклонить нулевую гипотезу.
В противном случае, если p-значение равно или превышает наш уровень значимости, мы не можем отвергнуть нулевую гипотезу.
Как интерпретировать P-значение
Определение p-значения в учебнике:
P-значение — это вероятность наблюдения выборочной статистики, которая по крайней мере столь же экстремальна, как и ваша выборочная статистика, при условии, что нулевая гипотеза верна.
Например, предположим, что завод заявляет, что производит шины, средний вес которых составляет 200 фунтов. Аудитор выдвигает гипотезу о том, что истинный средний вес шин, произведенных на этом заводе, отличается от 200 фунтов, поэтому он проводит проверку гипотезы и обнаруживает, что p-значение теста равно 0,04. Вот как интерпретировать это p-значение:
Если фабрика действительно производит шины со средним весом 200 фунтов, то 4% всех аудитов получат эффект, наблюдаемый в выборке, или больше из-за случайной ошибки выборки. Это говорит нам о том, что получение выборочных данных, которые сделал аудитор, было бы довольно редким, если бы завод действительно производил шины, средний вес которых составлял 200 фунтов.
В зависимости от уровня значимости, используемого в этой проверке гипотезы, аудитор, скорее всего, отклонит нулевую гипотезу о том, что истинный средний вес шин, произведенных на этом заводе, действительно составляет 200 фунтов. Выборочные данные, полученные им в ходе аудита, не очень согласуются с нулевой гипотезой.
Как не следует интерпретировать P-значение
Самое большое заблуждение относительно p-значений состоит в том, что они эквивалентны вероятности совершить ошибку, отклонив истинную нулевую гипотезу (известную как ошибка типа I).
Есть две основные причины, по которым p-значения не могут быть частотой ошибок:
1. P-значения рассчитываются на основе предположения, что нулевая гипотеза верна и что разница между данными выборки и нулевой гипотезой просто вызвана случайностью. Таким образом, p-значения не могут сказать вам вероятность того, что ноль является истинным или ложным, поскольку он на 100% верен, исходя из точки зрения вычислений.
2. Хотя низкое значение p указывает на то, что ваши выборочные данные маловероятны при условии, что нулевое значение истинно, значение p по-прежнему не может сказать вам, какой из следующих случаев более вероятен:
- Нуль является ложным
- Нуль верен, но вы получили нечетную выборку
Что касается предыдущего примера, вот правильный и неправильный способ интерпретации p-значения:
- Правильная интерпретация: если предположить, что завод производит шины со средним весом 200 фунтов, вы получите наблюдаемую разницу, которую вы получили в своей выборке, или более значительную разницу в 4% аудитов из-за ошибки случайной выборки.
- Неверная интерпретация: если вы отвергаете нулевую гипотезу, существует 4%-ная вероятность того, что вы делаете ошибку.
Примеры интерпретации P-значений
Следующие примеры иллюстрируют правильные способы интерпретации p-значений в контексте проверки гипотез.
Пример 1
Телефонная компания утверждает, что 90% ее клиентов довольны их услугами. Чтобы проверить это утверждение, независимый исследователь собрал простую случайную выборку из 200 клиентов и спросил их, довольны ли они своим сервисом, на что 85% ответили утвердительно. Значение p, связанное с данными выборки, оказалось равным 0,018.
Правильная интерпретация p-значения: если предположить, что 90% клиентов действительно удовлетворены их обслуживанием, исследователь получит наблюдаемую разницу, которую он действительно получил в своей выборке, или более экстремальную разницу в 1,8% аудитов из-за ошибки случайной выборки. .
Пример 2
Компания изобретает новый аккумулятор для телефонов. Компания утверждает, что эта новая батарея будет работать как минимум на 10 минут дольше, чем старая. Чтобы проверить это утверждение, исследователь берет простую случайную выборку из 80 новых батарей и 80 старых батарей. Новые батареи работают в среднем 120 минут при стандартном отклонении 12 минут, а старые батареи работают в среднем 115 минут при стандартном отклонении 15 минут. Значение p, полученное в результате теста на разницу в средних значениях населения, равно 0,011.
Правильная интерпретация p-значения: если предположить, что новая батарея работает столько же или меньше времени, чем старая батарея, исследователь получит наблюдаемую разницу или более крайнюю разницу в 1,1% исследований из-за случайной ошибки выборки.
![]()
Загрузить PDF
![]()
Загрузить PDF
P-значение — это статистическая величина, которая помогает ученым определить, корректны ли их гипотезы. P-значения используются для определения того, подпадают ли результаты эксперимента в диапазон значений, нормальный для наблюдаемой величины. Обычно если P-значение для набора данных меньше, чем заранее определенное число (например 0,05), то ученые должны отклонить «нулевую гипотезу» своего эксперимента. Другими словами, они сделают вывод, что переменные в их эксперименте не оказывают достаточного эффекта на результаты. В настоящее время p-значения обычно можно найти в справочнике, если сначала посчитать значение хи-квадрат.
Шаги
-

1
Определите ожидаемые в вашем эксперименте результаты. Обычно когда ученые проводят эксперимент, у них уже есть идея того, какие результаты считать «нормальными» или «типичными». Это может быть основано на экспериментальных результатах прошлых опытов, на достоверных наборах данных, на данных из научной литературы, либо ученый может основываться на каких-либо других источниках. Для вашего эксперимента определите ожидаемые результаты и выразите их в виде чисел.
- Пример: допустим, более ранние исследования показали, что в вашей стране владельцы красных машин чаще получают штрафы за превышение скорости, чем владельцы синих. Например, средние результаты показывают предпочтение 2:1 красных машин перед синими. Наша задача — определить, относится ли полиция точно так же предвзято к цвету машин в вашем городе. Для этого мы будем анализировать штрафы, выданные за превышение скорости. Если мы возьмем случайный набор из 150 штрафов за превышение скорости, выданных либо владельцам красных, либо синих автомобилей, мы ожидаем, что 100 штрафов будет выписано владельцам красных автомобилей, а 50 — владельцам синих, если полиция в нашем городе так же предвзято относится к цвету машин, как это наблюдается по всей стране.
-
2
Определите наблюдаемые результаты вашего эксперимента. Теперь, когда вы определили ожидаемые результаты, необходимо провести эксперимент и найти действительные (или «наблюдаемые») значения. Вам снова необходимо представить эти результаты в виде чисел. Если мы создаем экспериментальные условия, и наблюдаемые результаты отличаются от ожидаемых, то у нас есть две возможности — либо это произошло случайно, либо это вызвано именно нашим экспериментом. Цель нахождения p-значения как раз и состоит в том, чтобы определить, отличаются ли наблюдаемые результаты от ожидаемых настолько, чтобы можно было не отвергать «нулевую гипотезу» — гипотезу о том, что между экспериментальными переменными и наблюдаемыми результатами нет никакой связи.
- Пример: допустим, в нашем городе мы случайно выбрали 150 штрафов за превышение скорости, которые были выданы либо владельцам красных, либо владельцам синих автомобилей. Мы определили, что 90 штрафов были выписаны владельцам красных автомобилей, и 60 — владельцам синих. Это отличается от ожидаемых результатов, которые равны 100 и 50, соответственно. Действительно ли наш эксперимент (в данном случае изменение источника данных с государственного уровня на городской) привел к данному изменению в результатах, или наша городская полиция относится к автомобилистам предвзято точно так же, как и в среднем по стране, а мы видим просто случайное отклонение? P-значение поможет нам это определить.
-
3
Определите число степеней свободы вашего эксперимента. Число степеней свободы — это степень изменяемости вашего эксперимента, которая определяется числом категорий, которые вы исследуете. Уравнение для числа степеней свободы — Число степеней свободы = n-1, где «n» — число категорий или переменных, которые вы анализируете в своем эксперименте.
- Пример: в нашем эксперименте две категории результатов: одна категория для владельцев красных машин и другая — для владельцев синих машин. Поэтому в нашем эксперименте у нас 2-1 = 1 степень свободы. Если бы мы сравнивали красные, синие и зеленые машины, у нас было бы 2 степени свободы и так далее.
-
4
Сравните ожидаемые и наблюдаемые результаты с помощью критерия хи-квадрат. Хи-квадрат (пишется «x2») — это числовое значение, которое измеряет разницу между ожидаемыми и наблюдаемыми значениями эксперимента. Уравнение для хи-квадрата следующее: x2 = Σ((o-e)2/e), где «o» — это наблюдаемое значение, а «e» — это ожидаемое значение.[1]
Суммируйте результаты данного уравнения для всех возможных результатов (смотри ниже).- Заметьте, что данное уравнение включает оператор суммирования Σ (сигма). Другими словами, вам необходимо подсчитать ((|o-e|-.05)2/e) для каждого возможного результата и сложить полученные числа, чтобы получить значение критерия хи-квадрат. В нашем примере у нас два возможных результата — либо машина, получившая штраф красная, либо синяя. Поэтому мы должны посчитать ((o-e)2/e) дважды — один раз для красных машин и один раз для синих машин.
- Пример: давайте подставим наши ожидаемые и наблюдаемые значения в уравнение x2 = Σ((o-e)2/e). Помните, что из-за оператора суммирования нам необходимо посчитать ((o-e)2/e) дважды — один раз для красных автомобилей и один раз — для синих. Мы выполним эту работу следующим образом:
- x2 = ((90-100)2/100) + (60-50)2/50)
- x2 = ((-10)2/100) + (10)2/50)
- x2 = (100/100) + (100/50) = 1 + 2 = 3 .
-
5
Выберите уровень значимости. Теперь, когда мы знаем число степеней свободы нашего эксперимента и узнали значение критерия хи-квадрат, нам нужно сделать еще одну вещь перед тем, как мы найдем наше p-значение. Нам нужно определить уровень значимости. Говоря простым языком, уровень значимости показывает, насколько мы уверены в наших результатах. Низкое значение для значимости соответствует низкой вероятности того, что экспериментальные результаты вышли случайными и наоборот. Уровни значимости записываются в виде десятичных дробей (таких как 0,01), что соответствует вероятности того, что экспериментальные результаты мы получили случайно (в данном случае вероятность этого 1 %).
- По соглашению, ученые обычно устанавливают уровень значимости своих экспериментов равным 0,05, или 5 %.[2]
Это означает, что экспериментальные результаты, которые соответствуют такому критерию значимости, только с вероятностью 5 % могли получиться чисто случайно. Другими словами, существует 95 % вероятность, что результаты были вызваны тем, как ученый манипулировал экспериментальными переменными, а не случайно. Для большинства экспериментов 95 % уверенности наличия связи между двумя переменными достаточно, чтобы считать, что они «действительно» связаны друг с другом. - Пример: для нашего примера с красными и синими машинами, давайте последуем соглашению между учеными и установим уровень значимости в 0.05.
- По соглашению, ученые обычно устанавливают уровень значимости своих экспериментов равным 0,05, или 5 %.[2]
-
6
Используйте таблицу с данными распределения хи-квадрат, чтобы найти p-значение. Ученые и статисты используют большие таблицы для вычисления p-значения своих экспериментов. Данные таблицы обычно имеют вертикальную ось слева, соответствующую числу степеней свободы, и горизонтальную ось сверху, соответствующую p-значению. Используйте данные таблицы, чтобы сначала найти число ваших степеней свободы, затем посмотрите на ваш ряд слева направо, пока не найдете первое значение, большее вашего значения хи-квадрат. Посмотрите на соответствующее p-значение вверху вашего столбца. Нужное вам p-значение находится между этим числом и следующим за ним (тем, которое находится левее вашего).
- Таблицы с распределением хи-квадрат можно получить из множества источников — их можно просто найти онлайн, либо посмотреть в научных книгах или книгах по статистике. Если у вас нет под рукой таких книг, используйте картинку выше или какую-нибудь таблицу онлайн, которую можно просматривать бесплатно, например на сайте medcalc.org. Она расположена здесь.
- Пример: наше значение критерия хи-квадрат было равно 3. Поэтому давайте используем таблицу распределения хи-квадрат на изображении выше, чтобы найти приблизительное p-значение. Так как мы знаем, что в нашем эксперименте всего 1 степень свободы, выберем самую первую строку. Идем слева направо по данной строке, пока не встретим значение, большее 3, нашего значения критерия хи-квадрат. Первое, которое мы находим, это 3,84. Смотрим вверх нашего столбца и видим, что соответствующее p-значение равно 0,05. Это означает, что наше p-значение между 0,05 и 0,1 (следующее p-значение в таблице по возрастанию).
-
7
Решите, отклонить или оставить нулевую гипотезу. Так как вы определили приблизительное p-значение для вашего эксперимента, вам необходимо решить, отклонять ли нулевую гипотезу вашего эксперимента или нет (напоминаем, это гипотеза о том, что экспериментальные переменные, которыми вы манипулировали не повлияли на наблюдаемые вами результаты). Если p-значение меньше, чем уровень значимости — поздравляем, вы доказали, что очень вероятна связь между переменными, которыми вы манипулировали, и результатами, которые вы наблюдали. Если p-значение выше, чем уровень значимости, нельзя с уверенностью сказать, были ли наблюдаемые вами результаты результатом чистой случайности или манипуляцией данными переменными.
- Пример: наше p-значение находится между 0,05 и 0,1. Это явно не меньше, чем 0,05, поэтому, к сожалению, мы не можем отклонить нашу нулевую гипотезу. Это означает, что мы не достигли минимум 95 % вероятности того, чтобы сказать, что полиция в нашем городе выдает штрафы владельцам красных и синих автомобилей с такой вероятностью, которая достаточно сильно отличается от средней по стране.
- Другими словами, существует 5–10 % шанс, что наблюдаемые нами результаты — это не последствия смены места (анализа города, а не всей страны), а просто случайность. Так как заявленная нами точность не должна превышать 5 %, мы не можем сказать с уверенностью, что полиция нашего города менее предвзято относится к владельцам красных автомобилей — существует небольшая (но статистически значимая) вероятность, что это не так.
Реклама







Советы
- Научный калькулятор позволяет облегчить вычисления. Вы также можете использовать калькуляторы онлайн.
- Вы можете подсчитать p-значение с использованием некоторых компьютерных программ, включая как часто используемые программы электронных таблиц, так и более специализированное программное обеспечение.
Реклама
Об этой статье
Эту страницу просматривали 112 505 раз.
Была ли эта статья полезной?
Уровень
значимости
— это вероятность того, что мы сочли
различия
существенными, а они на самом деле
случайны.
Когда
мы указываем, что различия достоверны
на 5%-ом уровне значимости,
или при р<0,05,
то мы имеем виду, что вероятность того,
что
они все-таки недостоверны, составляет
0,05.
Когда
мы указываем, что различия достоверны
на 1%-ом уровне значимости,
или при р<0,01,
то мы имеем в виду, что вероятность того,
что
они все-таки недостоверны, составляет
0,01.
Если
перевести все это на более формализованный
язык, то уровень
значимости — это вероятность отклонения
нулевой гипотезы, в то время
как она верна.
Ошибка,
состоящая
в той,
что
мы отклонили
нулевую
гипотезу, в
то время как она верна, называется
ошибкой 1 рода. (См.
Табл. 1)
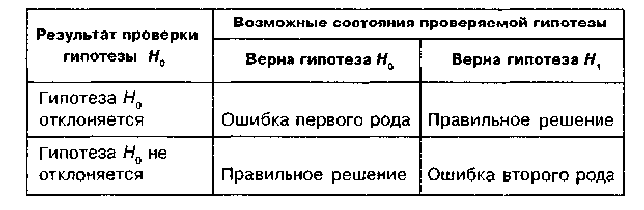 Табл.
Табл.
1. Нулевая и альтернативные гипотезы и
возможные состояния проверки.
Вероятность
такой ошибки обычно обозначается как
α.
В сущности,
мы должны были бы указывать в скобках
не р<0,05
или р<0,01,
а α<0,05
или α<0,01.
Если
вероятность ошибки — это α,
то вероятность правильного решения:
1—α. Чем меньше α, тем больше вероятность
правильного решения.
Исторически
сложилось так, что в психологии принято
считать низшим уровнем статистической
значимости 5%-ый уровень (р≤0,05): достаточным
– 1%-ый уровень (р≤0,01) и высшим 0,1%-ый
уровень (р≤0,001),
поэтому в таблицах критических значений
обычно приводятся
значения критериев, соответствующих
уровням статистической значимости
р≤0,05 и р≤0,01, иногда — р≤0,001. Для некоторых
критериев в
таблицах указан точный уровень значимости
их разных эмпирических значений.
Например, для φ*=1,56
р=О,06.
До
тех пор, однако, пока уровень статистической
значимости не достигнет
р=0,05, мы еще не имеем права отклонить
нулевую гипотезу.
Мы будем придерживаться
следующего правила отклонения гипотезы
об отсутствии
различий (Но) и принятия гипотезы о
статистической достоверности
различий (Н1).
Правило отклонения Hо и принятия h1
Если
эмпирическое значение критерия равняется
критическому значению,
соответствующему р≤0,05 или превышает
его, то H0
отклоняется,
но мы еще не можем определенно принять
H1.
Если
эмпирическое значение критерия равняется
критическому значению,
соответствующему р≤0,01 или превышает
его, то H0
отклоняется
и
принимается Н1.
Исключения:
критерий
знаков G,
критерий Т Вилкоксона и критерий U
Манна-Уитни. Для них устанавливаются
обратные соотношения.

Рис.
4. Пример «оси значимости» для критерия
Q
Розенбаума.
Критические
значения критерия обозначены как Qо,о5
и Q0,01,
эмпирическое значение критерия как
Qэмп.
Оно заключено в эллипс.
Вправо
от критического значения Q0,01
простирается «зона значимости» —
сюда попадают эмпирические значения,
превышающие Q
0,01
и,
следовательно, безусловно, значимые.
Влево
от критического значения Q
0,05,
простирается «зона незначимости»,
— сюда попадают эмпирические значения
Q,
которые ниже Q
0,05,
и,
следовательно, безусловно незначимы.
Мы
видим, что Q0,05=6;
Q0,01=9;
Qэмп.=8;
Эмпирическое
значение критерия попадает в область
между Q0,05
и Q0,01.
Это зона «неопределенности»: мы
уже можем отклонить гипотезу
о недостоверности различий (Н0),
но еще не можем принять гипотезы
об их достоверности (H1).
Практически,
однако, исследователь может считать
достоверными уже
те различия, которые не попадают в зону
незначимости, заявив, что они
достоверны при р<0,05,
или указав точный уровень значимости
полученного эмпирического значения
критерия, например: р=0,02. С помощью
стандартных таблиц, которые есть во
всех учебниках по математическим методам
это
можно сделать по отношению к критериям
Н Крускала-Уоллиса, χ2r
Фридмана,
L
Пейджа, φ* Фишера.
Уровень
статистической значимости или
критические значения критериев
определяются по-разному при проверке
направленных и ненаправленных
статистических гипотез.
При
направленной статистической гипотезе
используется односторонний
критерий, при ненаправленной гипотезе
— двусторонний критерий.
Двусторонний критерий более строг,
поскольку он проверяет различия
в обе стороны, и поэтому то эмпирическое
значение критерия, которое ранее
соответствовало уровню значимости
р<0,05,
теперь соответствует
лишь уровню р<0,10.
Нам
не придется всякий раз самостоятельно
решать, использует ли он односторонний
или двухсторонний
критерий. Таблицы критических значений
критериев подобраны таким
образом, что направленным гипотезам
соответствует односторонний,
а ненаправленным — двусторонний критерий,
и приведенные значения
удовлетворяют тем требованиям, которые
предъявляются к каждому из
них. Исследователю необходимо лишь
следить за тем, чтобы его гипотезы
совпадали по смыслу и по форме с
гипотезами, предлагаемыми в описании
каждого из критериев.
Соседние файлы в папке МатМетоды в Психологии (литература)
- #
- #
13.02.201616.87 Mб1461Наследов А.Д. IBM SPSS Statistics 20 профессиональный анализ данных.pdf
- #
5.6. Вероятность ошибки р
Если следовать подразделению статистики на описательную и аналитическую, то задача аналитической статистики — предоставить методы, с помощью которых можно было бы объективно выяснить,
например, является ли наблюдаемая разница в средних значениях или взаимосвязь (корреляция) выборок случайной или нет.
Например, если сравниваются два средних значения выборок, то можно сформулировать две предварительных гипотезы:
-
Гипотеза 0 (нулевая): Наблюдаемые различия между средними значениями выборок находятся в пределах случайных отклонений.
-
Гипотеза 1 (альтернативная): Наблюдаемые различия между средними значениями нельзя объяснить случайными отклонениями.
В аналитической статистике разработаны методы вычисления так называемых тестовых (контрольных) величин, которые рассчитываются по определенным формулам на основе данных,
содержащихся в выборках или полученных из них характеристик. Эти тестовые величины соответствуют определенным теоретическим распределениям
(t-pacnpeлелению, F-распределению, распределению X2 и т.д.), которые позволяют вычислить так называемую вероятность ошибки. Это вероятность равна проценту ошибки,
которую можно допустить отвергнув нулевую гипотезу и приняв альтернативную.
Вероятность определяется в математике, как величина, находящаяся в диапазоне от 0 до 1. В практической статистике она также часто выражаются в процентах. Обычно вероятность обозначаются буквой р:
0 < р < 1
Вероятности ошибки, при которой допустимо отвергнуть нулевую гипотезу и принять альтернативную гипотезу, зависит от каждого конкретного случая.
В значительной степени эта вероятность определяется характером исследуемой ситуации. Чем больше требуемая вероятность, с которой надо избежать ошибочного решения,
тем более узкими выбираются границы вероятности ошибки, при которой отвергается нулевая гипотеза, так называемый доверительный интервал вероятности.
Обычно в исследованиях используют 5% вероятность ошибки.
Существует общепринятая терминология, которая относится к доверительным интервалам вероятности:
- Высказывания, имеющие вероятность ошибки р <= 0,05 — называются значимыми.
- Высказывания с вероятностью ошибки р <= 0,01 — очень значимыми,
- А высказывания с вероятностью ошибки р <= 0,001 — максимально значимыми.
В литературе такие ситуации иногда обозначают одной, двумя или тремя звездочками.
| Вероятность ошибки | Значимость | Обозначение |
| р > 0.05 | Не значимая | ns |
| р <= 0.05 | Значимая | * |
| р <= 0.01 | Очень значимая | ** |
| р <= 0.001 | Максимально значимая | *** |
В SPSS вероятность ошибки р имеет различные обозначения; звездочки для указания степени значимости применяются лишь в немногих случаях. Обычно в SPSS значение р обозначается Sig. (Significant).
Времена, когда не было компьютеров, пригодных для статистического анализа, давали практикам по крайней мере одно преимущество. Так как все вычисления надо было выполнять вручную,
статистик должен был сначала тщательно обдумать, какие вопросы можно решить с помощью того или иного теста. Кроме того, особое значение придавалось точной формулировке нулевой гипотезы.
Но с помощью компьютера и такой мощной программы, как SPSS, очень легко можно провести множество тестов за очень короткое время. К примеру, если в таблицу сопряженности свести 50 переменных
с другими 20 переменными и выполнить тест X2, то получится 1000 результатов проверки значимости или 1000 значений р. Некритический подбор значимых величин может
дать бессмысленный результат, так как уже при граничном уровне значимости р = 0,05 в пяти процентах наблюдений, то есть в 50 возможных наблюдениях, можно ожидать значимые результаты.
Этим ошибкам первого рода (когда нулевая гипотеза отвергается, хотя она верна) следует уделять достаточно внимания. Ошибкой второго рода называется ситуация,
когда нулевая гипотеза принимается, хотя она ложна. Вероятность допустить ошибку первого рода равна вероятности ошибки р. Вероятность ошибки второго рода тем меньше, чем больше вероятность ошибки р.
Проверка гипотез
Общий обзор
Определение нулевой и альтернативной гипотезы, уровня статистической значимости
Получение статистики критерия, определение критической области
Получение значения р (достигнутого уровня значимости)
Применение значения р
Проверка гипотез против доверительных интервалов
Общий обзор
Часто делают выборку, чтобы определить аргументы против гипотезы относительно популяции (генеральной совокупности). Этот процесс известен как проверка гипотез (проверка статистических гипотез или проверка значимости), он представляет количественную меру аргументов против определенной гипотезы.
Установлено 5 стадий при проверке гипотез:
- Определение нулевой (
 ) и альтернативной гипотезы (
) и альтернативной гипотезы ( ) при исследовании. Определение уровня значимости критерия.
) при исследовании. Определение уровня значимости критерия.
- Отбор необходимых данных из выборки.
- Вычисление значения статистики критерия, отвечающей .
- Вычисление критической области, проверка статистики критерия на предмет попадания в критическую область.
- Интерпретация достигнутого уровня значимости р и результатов.
Определение нулевой и альтернативной гипотез, уровня статистической значимости
При проверке значимости гипотезу следует формулировать независимо от используемых при ее проверке данных (до проведения проверки). В таком случае можно получить действительно продуктивный результат.
Всегда проверяют нулевую гипотезу (![]() ), которая отвергает эффект (например, разница средних равняется нулю) в популяции.
), которая отвергает эффект (например, разница средних равняется нулю) в популяции.
Например, при сравнении показателей курения у мужчин и женщин в популяции нулевая гипотеза ![]() означала бы, что показатели курения одинаковые у женщин и мужчин в популяции.
означала бы, что показатели курения одинаковые у женщин и мужчин в популяции.
Затем определяют альтернативную гипотезу (![]() ), которая принимается, если нулевая гипотеза неверна. Альтернативная гипотеза больше относится к той теории, которую собираются исследовать. Итак, на этом примере альтернативная гипотеза
), которая принимается, если нулевая гипотеза неверна. Альтернативная гипотеза больше относится к той теории, которую собираются исследовать. Итак, на этом примере альтернативная гипотеза ![]() заключается в утверждении, что показатели курения различны у женщин и мужчин в популяции.
заключается в утверждении, что показатели курения различны у женщин и мужчин в популяции.
Разницу в показателях курения не уточнили, т.е. не установили, имеют ли в популяции мужчины более высокие или более низкие показатели, чем женщины. Такой подход известен как двусторонний критерий, потому что учитывают любую возможность, он рекомендуется постольку, поскольку редко есть уверенность заранее в направлении какого-либо различия, если таковое существует.
В некоторых случаях можно использовать односторонний критерий для гипотезы ![]() , в котором направление эффекта задано. Его можно применить, например, если рассматривать заболевание, от которого умерли все пациенты, не получившие лечения; новый препарат не мог бы ухудшить положение дел.
, в котором направление эффекта задано. Его можно применить, например, если рассматривать заболевание, от которого умерли все пациенты, не получившие лечения; новый препарат не мог бы ухудшить положение дел.
Уровень значимости. Важным этапом проверки статистических гипотез является определение уровня статистической значимости ![]() , т.е. максимально допускаемой исследователем вероятности ошибочного отклонения нулевой гипотезы.
, т.е. максимально допускаемой исследователем вероятности ошибочного отклонения нулевой гипотезы.
Получение статистики критерия, определение критической области
После того как данные будут собраны, значения из выборки подставляют в формулу для вычисления статистики критерия (примеры различных статистик критериев см. ниже). Эта величина количественно отражает аргументы в наборе данных против нулевой гипотезы.
Критическая область. Для принятия решения об отклонении или не отклонении нулевой гипотезы необходимо также определить критическую область проверки гипотезы.
Выделяют 3 вида критических областей:
- двусторонняя:


Рис. 1 Двусторонняя критическая область
- левосторонняя:


Рис. 2 Левосторонняя критическая область
- правосторонняя:


Рис. 3 Правосторонняя критическая область
![]() — заданный исследователем уровень значимости.
— заданный исследователем уровень значимости.
Если наблюдаемое значение критерия (K) принадлежит критической области (Kкр, заштрихованная область на рис.1-3), гипотезу ![]() отвергают, если не принадлежит — не отвергают.
отвергают, если не принадлежит — не отвергают.
Для краткости можно записать и так:
| K | > Kкр — отклоняем H0
| K | < Kкр — не отклоняем H0
Получение значения р (достигнутого уровня значимости)
Все статистики критерия подчиняются известным теоретическим распределениям вероятности. Значение статистики критерия, полученное из выборки, связывают с уже известным распределением, которому она подчиняется, чтобы получить значение р, площадь обоих «хвостов» (или одного «хвоста», в случае односторонней гипотезы) распределения вероятности.
Большинство компьютерных пакетов обеспечивают автоматическое вычисление двустороннего значения р.
Значение р — это вероятность получения нашего вычисленного значения критерия или его еще большего значения, если нулевая гипотеза верна.
Иными словами, p — это вероятность отвергнуть нулевую гипотезу при условии, что она верна.
Нулевая гипотеза всегда относится к популяции, представляющей больший интерес, нежели выборка. В рамках проверки гипотезы мы либо отвергаем нулевую гипотезу и принимаем альтернативу, либо не отвергаем нулевую гипотезу. Подробнее об ошибках при проверке гипотез
Применение значения р
Следует решить, сколько аргументов позволят отвергнуть нулевую гипотезу в пользу альтернативной. Чем меньше значение р, тем сильнее аргументы против нулевой гипотезы.
-
Традиционно полагают, если р < 0,05, (
 =0,05) то аргументов достаточно, чтобы отвергнуть нулевую гипотезу, хотя есть небольшой шанс против этого. Тогда можно отвергнуть нулевую гипотезу и сказать, что результаты значимы на 5% уровне.
=0,05) то аргументов достаточно, чтобы отвергнуть нулевую гипотезу, хотя есть небольшой шанс против этого. Тогда можно отвергнуть нулевую гипотезу и сказать, что результаты значимы на 5% уровне. -
Напротив, если р > 0,05, то аргументов недостаточно, чтобы отвергнуть нулевую гипотезу. Не отвергая нулевую гипотезу, можно заявить, что результаты не значимы на 5% уровне. Данное заключение не означает, что нулевая гипотеза истинна, просто недостаточно аргументов (возможно, маленький объем выборки), чтобы ее отвергнуть.
Уровень значимости (т.е. выбранная «граница отсечки») 5% задается произвольно. На уровне 5% можно отвергнуть нулевую гипотезу, когда она верна. Если это может привести к серьезным последствиям, необходимо потребовать более веских аргументов, прежде чем отвергнуть нулевую гипотезу, например, выбрать значение ![]() = 0,01 (или 0,001).
= 0,01 (или 0,001).
Определение результата только как значимого на определенном уровне граничного значения (например 0, 05) может ввести в заблуждение. Например, если р = 0,04, то нулевую гипотезу отвергаем, но если р = 0,06, то ее не отвергли бы. Действительно ли они различны? Мы рекомендуем всегда указывать точное значение р, обычно получаемое путем компьютерного анализа.
Проверка гипотез против доверительных интервалов
Доверительные интервалы и проверка гипотез тесно связаны. Первоначальная цель проверки гипотезы состоит в том, чтобы принять решение и предоставить точное значение р.
Доверительный интервал (ДИ) количественно определяет изучаемый эффект (например, разницу в средних) и дает возможность оценить значение результатов. ДИ предоставляют интервал вероятных значений для истинного эффекта, поэтому его также можно использовать для принятия решения даже без точных значений р.
Например, если бы гипотетическое значение для данного эффекта (например, значение, равное нулю) находилось вне 95% ДИ, можно было бы счесть гипотетическое значение неправдоподобным и отвергнуть ![]() . В этом случае станет известно, что р < 0,05, но не станет известно его точное значение
. В этом случае станет известно, что р < 0,05, но не станет известно его точное значение
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала