Относительная ошибка аппроксимации
Оценивает отклонение
теоретических оценок от реальных. Ошибка
аппроксимации ε. Формула 17.
Значение этой ошибки,
не превышающее 8-10% говорит о хорошем
качестве уравнения регрессии.
Εср=2,62/30*100%=8,7%.
В регрессионном
анализе общая колеблемость результата
представляется следующим образом:
∑=
*100%
∑(y—
)2=∑(yi—
)2+∑(
—yi)2
∑(y-
)2-общая
колеблемость результата, ∑(y-
)2
–от фактических данных отнимаем
теоретические = остаточная колеблемость,
∑(
-yi)2
– колеблемость результата, объясненная
уравнением регрессии
Это разложение вариации
зависимой переменной лежит в основе
качества полученного уравнения регрессии,
т.е. чем бОльшая часть вариации у
объясняется уравнением регрессии, тем
лучше качество уравнения, т.е. правильно
выбран тип функции для описания
зависимости результата и фактора y=f(x)
и правильно выбрана сама объясняющая
переменная х. отношение объясненной
вариации к общей позволяет найти индекс
детерминации η2.
η2=
Он определяет степень
детерминации регрессией вариации у.
Корень квадратный из индекса детерминации
называется теоретическим корреляционным
отношением, оно показывает тесноту
связи между результатом и фактором, как
при линейной, так и при нелинейной связи.
Измеряется η [0,1].
В нашем примере
∑(
—
)2=∑(yi—
))2+∑(
)2
= 7,5-1,094=6,064,
η2=6,406/7,5=0,85
(85%)
Оценка значимости
производится на основе F-критерия
Фишера, которому предшествует дисперсионный
анализ, применяемый как вспомогательное
средство для изучения качества
регрессионной модели. Схему дисперсионного
анализа представим в таблице, где
n-число наблюдений, а
m-число параметров при х.
Таблица
дисперсионного анализа
|
Компоненты ди сперсии |
Сумма квадратов (SS) |
Число степеней свободы (df) |
Дисперсия на одну степень свободы |
|
Общая дисперсия |
|
n-1 |
|
|
Факторная |
|
m |
|
|
Остаточная |
|
n-m-1 |
|






Дисперсия на одну
степень свободы приводит дисперсии к
сопоставимому виду. Поэтому, сопоставляя
факторную и остаточную дисперсии,
получают фактическое значение F-критерия
Фишера.
F=MSФАКТ/MSОСТ
Фактическое значение
F-критерия Фишера
сравнивается с табличным значением
F-критерия Фишера Fтабл(α,
k1, k2),
которое зависит от уровня значимости
α и степеней свободы k1
(факторная), k2
(остаточная).
Если фактическое
значение F-критерия Фишера
больше табличного, то уравнение регрессии
является статистически значимым в целом
Для парной линейной
регрессии этот пример может быть записан
следующим образом:
Fфакт=
,
Fфакт=
F-критерий
Фишера говорит о статистической
значимости уравнения. В парной линейной
регрессии оценивается значимость
отдельных параметров уравнения регрессии
a и b. С этой
целью определяется его стандартная
ошибка:
mb=MSост/σx
t-критерий
Стьюдента. Для оценки существенности
коэф-та регрессии определяется фактическое
значение t-критерия
Стьюдента: фактическое значение
t-критерия Стьюдента для
параметра b:
tb=b/mb
Далее это фактическое
значение сравнивается с табличным
значением t-критерия
Стьюдента, которое зависит от уровня
значимости α и числа степеней свободы
df (n-2).
Если фактическое
значение больше табличного, то параметр
регрессии статистически значим. Кроме
того, можно определить границы
доверительного интервала коэф-та
регрессии b.

=a+bx
b ±∆
(предельная ошибка)
b-∆b≤b≤b+∆b
∆b=tтабл*m*b,
где ∆b –предельная
ошибка коэф-та регрессии b.
Если -2≤b≤3,
значит, b-статистически
незначим.
Стандартной ошибкой
для параметра а ma
= MSост

.
Значимость параметра
а определяется аналогично параметру
b.
ta=a/∆ma
ta=a/ma
>ta(α,
df)
Если фактическое
больше табличного – параметр статистически
значим.
Аналогичным образом
проверяется статистическая значимость
линейного коэф-та кореляции.
mσyx=
И это значение
сравнивается с табличным значением
t-критерия Стьюдента.
При прогнозировании
по уравнению регрессии вычисляется
прогнозное значение результата
(
подстановкой
в уравнение регрессии прогнозного или
желаемого значения фактора.

=a+bxnp
Полученное по этому
уравнению значение результат называется
точечным прогнозом.
Здесь также считаются
доверительные интервалы прогноза. Они
считаются следующим образом:
yp-∆y≤
≤yp+∆p,
где ∆p –
предельная ошибка прогноза.
∆y=tтабл*my,
где my—
стандартная ошибка прогноза
mУp=MSост
*

,
где
—
фактическое значение исходных данных.
Выполнить
корреляционно-регрессионный анализ
можно, воспользовавшись пакетами
прикладных программ. Самый простой –
Excel.
Нужно в закладке
«Данные» — «Анализ данных» — «Регрессия»
— «Входной интервал у»
|
х |
у |
|
1 |
5 |
|
2 |
7 |
|
3 |
8 |
Поставить флажок
«Метки», «Const 0» – флажка
не должно быть, иначе параметр а = 0.
Дальше «Выходной интервал» номер
свободной ячейки на рабочем листе –
Ок.
Вывод итогов представляет
собой 3 таблички:
-
Регрессионная
статистика
-
Множественный R (парный
линейный коэф-т корреляции)R-квадрат (коэф-т
детерминации)Нормированный R-квадрат
(скорректированный коэф-т корреляции)Стандартная ошибка коэф-та корреляции
Наблюдение
-
Дисперсионный
анализ
-
df
SS
MS
F
F значимое
Регрессия (факторная)
Остаток
Итого:
-
Коэф-ты
Стандартная ошибка параметров
t-статистика (факт.
значения t-критерия для
параметров а и b)Нижняя 95%
Верхняя 95% (границы доверительного
интервала)У — пересечение
Параметр а
Число
х
b
Число
95% -означает,
что уровень значимости α = 5% (вероятность
– 95%).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Подборка по базе: Круговорот азота в природе. Особенности и последствия.pptx, Вулканизм на Земле и его последствия.doc, Афганская война причины и последствия. Реферат.docx, Монгольское завоевание руси и его последствия.docx, БЕЗРАБОТИЦА, ЕЕ ВИДЫ И ПРИЧИНЫ.docx, Государственный долг сущность, виды, последствия..docx, домашнее задание-глаголы изменения и причины.docx, Гражданская война причины, этапы, последствия.docx, Церковный раскол и его последствия.doc, реферат дисбактериоз и его причины.docx
Относительная ошибка прогноза, вычисляемая по формуле:
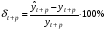 или
или 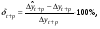
Чем больше значение ошибки (выраженное в процентах), тем хуже качество прогноза.
- Стандартная среднеквадратическая ошибка, рассчитываемая по формуле:

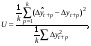
где 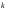 – количество прогнозных периодов.
– количество прогнозных периодов.
Значения показателя 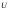 лежат в интервале от нуля до единицы.
лежат в интервале от нуля до единицы.
При 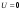 прогноз абсолютно точен. Таким образом, чем ближе значение к нулю, тем точнее прогноз.
прогноз абсолютно точен. Таким образом, чем ближе значение к нулю, тем точнее прогноз.
- Точечный прогноз осуществляется путем подстановки требуемого значения в полученное уравнение регрессии.
Интервальная оценка для линейной парной регрессии находится из условия:
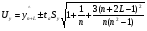
где L — период упреждения;
уn+L — точечный прогноз по модели на (n + L)-й момент времени;
n — количество наблюдений во временном ряду;
Sy -стандартная ошибка прогнозируемого показателя, рассчитанная по ранее приведенной формуле;
ta — табличное значение критерия Стьюдента для уровня значимости а и для числа степеней свободы, равного n — 2.
72.Характеристики сервиса «Описательная статистика».
Инструмент «Описательная статистика» автоматически вычисляет наиболее широко используемые в практическом анализе характеристики распределений. При этом значения могут быть определены сразу для нескольких исследуемых переменных.
Определим параметры описательной статистики для переменных(а,б,в,г,д…). Для этого необходимо выполнить следующие шаги.
1.Выберите в главном меню тему «Сервис» пункт «Анализ данных». Результатом выполнения этих действий будет появление диалогового окна «Анализ данных», содержащего список инструментов анализа.
2.Выберите из списка «Инструменты анализа» пункт «Описательная статистика» и нажмите кнопку «ОК». Результатом будет появление окна диалога инструмента «Описательная статистика».
3.Заполнить поля диалогового окна и нажать кнопку «ОК».
Результатом выполнения указанных действий будет формирование отдельного листа, содержащего вычисленные характеристики описательной статистики для исследуемых переменных.
Получаем данные на листе «Результаты анализа». Вторая строка содержит значения стандартных ошибок e для средних величин распределений. Другими словами среднее или ожидаемое значение случайной величины М(Е) определено с погрешностью ± e .
Медиана – это середина численного ряда или интервала. Как и математическое ожидание, медиана является одной из характеристик центра распределения случайной величины. В симметричных распределениях значение медианы должно быть равным или достаточно близким к математическому ожиданию.
Мода – наиболее часто встречающееся значение в интервале данных. Для симметричных распределений мода равна математическому ожиданию. Иногда мода может отсутствовать.
Эксцесс характеризует остроконечность (положительное значение) или пологость (отрицательное значение) распределения по сравнению с нормальной кривой. Теоретически, эксцесс нормального распределения должен быть равен 0. Однако на практике для генеральных совокупностей больших объемов его малыми значениями можно пренебречь.
Асимметричность (коэффициент асимметрии) характеризует смещение распределения относительно математического ожидания. При положительном значении коэффициента распределение скошено вправо, т.е. его более длинная часть лежит правее центра (математического ожидания) и обратно. Для нормального распределения коэффициент асимметрии равен 0. На практике, его малыми значениями можно пренебречь.
Величина «Интервал» определяется как разность между максимальным и минимальным значением случайной величины (численного ряда).
Параметры «Счет» и «Сумма» представляют собой число значений в заданном интервале и их сумму соответственно.
Последняя характеристика «Уровень надежности» показывает величину доверительного интервала для математического ожидания согласно заданному уровню надежности или доверия. По умолчанию уровень надежности принят равным 95%. Чем выше принятый уровень надежности, тем больше будет величина доверительного интервала для среднего.
Расчет доверительного интервала для среднего значения можно также осуществить с помощью специальной статистической функции ДОВЕРИТ()
73. Метод наибольшего прадоподобия
МНП позволяет получить по крайней мере асимптотически несмещенные и эффективные оценки параметров распределения.
В основе ММП лежит понятие функции правдоподобия выборки
Определение. Пусть имеем случайную величину Y, которая имеет функцию плотности вероятностей Py(t, a1,a2,…,ak) и случайную выборку Y(y1,y2,…,yn )наблюдений за поведением этой величины. Тогда функцией правдоподобия выборки Y(y1,y2,…,yn) называется функция L, зависящая от аргументов а={a1,a2,…,ak}, и от элементов выборки как от параметров и определяется равенством
Метод наибольшего правдоподобия — метод поиска модели, наилучшим в каком-то смысле образом описывающей обучающую выборку, полученную с некоторым неизвестным распределением.
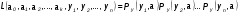
Функция правдоподобия
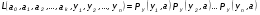
Идея метода.
В качестве оценки неизвестного параметра принимается такое, которое обеспечивает максимум функции правдоподобия при всех возможных значениях случайной величины Y
Математически это выражается так:
ãj= argmax(L(a1,a2,…,ak, y1,y2,…,yn)
Очевидно, что оценка ãj зависит от случайной выборки, следовательно, ãj= f(y1,y2,…,yn), где f есть процедура вычисления оценки ãj по результатам выборки
Алгоритм решения задачи
Предполагается:
1. Вид закона распределения известен;
2. Функция плотности вероятности гладкая во всей области определения
Последовательность решения:
1. Составляется функция правдоподобия
2. Вычисляется логарифм функции правдоподобия
3. Оценки параметров получаются в результате решения системы уравнений вида:
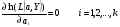
4. Проверяется условие максимума функции правдоподобия
74. Что такое стационарный процесс
Стационарный случайный процесс, важный специальный класс случайных процессов, часто встречающийся в приложениях теории вероятностей к различным разделам естествознания и техники. Случайный процесс X (t) называется стационарным, если все его вероятностные характеристики не меняются с течением времени t (так что, например, распределение вероятностей величины X (t)при всех t является одним и тем же, а совместное распределение вероятностей величин X (t1) и X (t2) зависит только от продолжительности промежутка времени t2—t1, т. е. распределения пар величин {X (t1), X (t2)} и {X (t1 + s), X (t2 + s)} одинаковы при любых t1, t2 и s и т.д.
75. Эконометрика, её задача и метод.
Эконометрика – наука, изучающая конкретные количественные закономерности и взаимосвязи экономических объектов и процессов с помощью математических методов и моделей.
Задача эконометрики состоит в выявлении связей между количественными характеристиками экономических объектов. Целью выявления связей является построение математических правил прогноза, недоступных для наблюдения количественных характеристик изучаемых объектов по наблюденным или заданным значениям других количественных характеристик этих объектов.
Эконометрика служит инструментом решения прогнозных экономических задач методом математического моделирования.
76.Экспоненциальное сглаживание временного ряда
Выявление и анализ тенденции временного ряда часто производится с помощью его выравнивания или сглаживания. Экспоненциальное сглаживание — один из простейших и распространенных приемов выравнивания ряда. Экспоненциальное сглаживание можно представить как фильтр, на вход которого последовательно поступают члены исходного ряда, а на выходе формируются текущие значения экспоненциальной средней.
Пусть 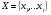 — временной ряд.
— временной ряд.
Экспоненциальное сглаживание ряда осуществляется по рекуррентной формуле: 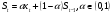 .
.
Чем меньше α, тем в большей степени фильтруются, подавляются колебания исходного ряда и шума.
Если последовательно использовать рекуррентное это соотношение, то экспоненциальную среднюю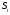 можно выразить через значения временного ряда X.
можно выразить через значения временного ряда X.
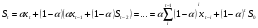
Если к моменту начала сглаживания существуют более ранние данные, то в качестве начального значения 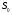 можно использовать арифметическую среднюю всех имеющихся данных или какой-то их части.
можно использовать арифметическую среднюю всех имеющихся данных или какой-то их части.
77. Этапы построения эконометрических моделей
1.Спецификация эконометрической модели;
2.Сбор статистической информации об объекте-оригинале в виде конкретных значений экзогенных и эндогенных переменных, включенных в спецификацию модели;
3.Оценивание неизвестных параметров модели (настройка, оценивание или идентификация модели);
4.Проверка адекватности оцененной модели (проверка соответствия настроенной модели объекту-оригиналу).
78. Этапы решения экономико-математических задач.
Решение экономико-математической задачи включает следующие этапы:
- Предварительное построение упрощенной схемы задачи, составленной математическим языком (эта схема именуется математической моделью объекта)
- Расчет по этой схеме искомых данных
- Выводы
Наиболее сложным и трудоемким этапом в решение экономико-математической задачи является построение экономической модели. Рассмотрим этапы построения экономической модели:
1)Спецификация модели
2)Подготовка исходной информации(сбор статистической информации об объекте-оригинале в виде конкретных значений экзогенных и эндогенных переменных, включенных в спецификацию модели)
3)Оценивание параметров модели (настройка, оценивание или идентификация модели)
4)Тестирование качества параметров модели:
— гомоскедастичность
— автокорреляция
5)Проверка адекватности (проверка соответствия настроенной модели объекту-оригиналу)
Клуб Студентов и Молодежи – http://nashuniver.ru
В зависимости от контекста термин «прогнозирование» в эконометрике может трактоваться по-разному. Применительно к данным временных рядов речь обычно идет о прогнозировании будущего значения зависимой переменной, например, курса рубля или ВВП. Когда же речь идет о пространственных выборках, под прогнозированием понимают предсказание значения зависимой переменной для заданных значений объясняющих переменных. Например, предсказание цены квартиры с заданной жилой площадью.
Формально задачу построения прогноза можно представить следующим образом. Имеется модель, для которой выполнены все предпосылки КЛМПР:
begin{equation*} y_i=beta _1+beta _2x_i+varepsilon _i end{equation*}
Представим, что мы уже воспользовались МНК и получили оцененную на основе n наблюдений линию регрессии:
begin{equation*} widehat y_i=widehat {beta }_1+widehat {beta }_2x_i end{equation*}
Теперь пусть у нас есть известное (n+1)-ое наблюдение регрессора (x_{n+1}), но неизвестно соответствующее значение зависимой переменной (y_{n+1}) и нужно построить его прогноз. Естественной идеей будет подставить известное значение в оцененную регрессию:
begin{equation*} widehat y_{n+1}=widehat {beta }_1+widehat {beta }_2x_{n+1} end{equation*}
Оказывается, что это хорошая мысль: такой прогноз будет несмещенным и эффективным (то есть будет характеризоваться минимальной ожидаемой квадратичной ошибкой прогноза).
Докажем несмещенность этого прогноза.
Вычислим математическое ожидание фактического значения (y_{n+1}) и нашего прогноза (widehat y_{n+1}). Если прогноз несмещенный, то эти математические ожидания будут совпадать.
Воспользуемся тем, что, как мы доказали выше, (widehat {beta }_1) и (widehat {beta }_2) — несмещенные оценки коэффициентов (beta _1) и (beta _2):
begin{equation*} Eleft(widehat y_{n+1}right)=Eleft(widehat {beta }_1+widehat {beta }_2x_{n+1}right)=Eleft(widehat {beta }_1right)+Eleft(widehat {beta }_2right)x_{n+1}=beta _1+beta _2x_{n+1} end{equation*}
Кроме того:
begin{equation*} Eleft(y_{n+1}right)=Eleft(beta _1+beta _2x_{n+1}+varepsilon _{n+1}right)=end{equation*}
begin{equation*} =beta _1+beta _2x_{n+1}+Eleft(varepsilon _{n+1}right)=beta _1+beta _2x_{n+1} end{equation*}
Следовательно, (Eleft(y_{n+1}right)=Eleft(widehat y_{n+1}right)).
Кроме самого прогноза нас интересует его точность. Чтобы её оценить, целесообразно вычислить математические ожидания квадрата ошибки прогноза:
begin{equation*} Eleft(widehat y_{n+1}-y_{n+1}right)^2=Eleft(widehat {beta }_1+widehat {beta }_2x_{n+1}-beta _1-beta _2x_{n+1}-varepsilon _{n+1}right)^2= end{equation*}
begin{equation*} =Eleft(left(widehat {beta }_1-beta _1right)+left(widehat {beta }_2-beta _2right)x_{n+1}-varepsilon _{n+1}right)^2= end{equation*}
begin{equation*} =Eleft(widehat {beta }_1-beta _1right)^2+x_{n+1}^2Eleft(widehat {beta }_2-beta _2right)^2+Eleft(varepsilon _{n+1}right)^2+ end{equation*}
begin{equation*} +2x_{n+1}Eleft(left(widehat {beta }_1-beta _1right)left(widehat {beta }_2-beta _2right)right)-2Eleft(left(widehat {beta }_1-beta _1right)varepsilon _{n+1}right)-end{equation*}
begin{equation*}-2x_{n+1}Eleft(left(widehat {beta }_2-beta _2right)varepsilon _{n+1}right)= end{equation*}
begin{equation*} mathit{var}left(widehat {beta }_1right)+x_{n+1}^2mathit{var}left(widehat {beta }_2right)+sigma ^2+2x_{n+1}mathit{cov}left(widehat {beta }_1,widehat {beta }_2right)-0-0= end{equation*}
begin{equation*} frac{frac{sigma ^2} n{ast}sum x_i^2}{sum left(x_i-overline xright)^2}+x_{n+1}^2frac{sigma ^2}{Sigma left(x_i-overline xright)^2}+sigma ^2-2x_{n+1}frac{overline x{ast}sigma ^2}{Sigma left(x_i-overline xright)^2}= end{equation*}
begin{equation*} =sigma ^2{ast}left(1+frac 1 n+frac{left(x_{n+1}-overline xright)^2}{sum left(x_i-overline xright)^2}right)end{equation*}
Здесь в предпоследнем равенстве мы воспользовались формулами для (mathit{var}left(widehat {beta }_1right)), (mathit{var}left(widehat {beta }_2right)) и (mathit{cov}left(widehat {beta }_1,widehat {beta }_2right)), представленными выше.
Дисперсия ошибки прогноза (sigma ^2), неизвестная нам в реальности, может быть заменена несмещенной оценкой (S^2.) Если проделать эту замену, а затем извлечь из полученного результата корень, то получим стандартную ошибку прогноза:
begin{equation*} delta =sqrt{s^2{ast}left(1+frac 1 n+frac{left(x_{n+1}-overline xright)^2}{sum left(x_i-overline xright)^2}right)}end{equation*}
Эту стандартную ошибку прогноза можно использовать для построения доверительного интервала прогноза.
95-процентный доверительный интервал для прогноза — это такой интервал, который накрывает истинное прогнозное значение зависимой переменной с вероятностью 95%. Он имеет вид:
begin{equation*} left(widehat y_{n+1}-delta {ast}t_{n-2}^{alpha },widehat y_{n+1}+delta {ast}t_{n-2}^{alpha }right.) end{equation*}
Обратите внимание, что величина стандартной ошибки прогноза зависит от соотношения (x_{n+1}) и (overline x). Если (x_{n+1}=overline x), то последняя дробь в этой большой формуле окажется равной нулю, и стандартная ошибка прогноза будет минимальной. Чем сильнее (x_{n+1}) отличается от (overline x), тем больше будет эта дробь. Таким образом, чем меньше наблюдение, для которого вы строите прогноз, похоже на вашу исходную выборку, тем менее точным этот прогноз окажется.
Пример 2.6. Построение прогноза
Рассматривается классическая линейная модель парной регрессии (y_i=beta _1+beta _2{ast}x_i+varepsilon _i.) Имеется следующая информация о 10 наблюдениях анализируемых переменных:
begin{equation*} sum _{i=1}^{10}x_i=20,sum _{i=1}^{10}x_i^2=50,sum _{i=1}^{10}y_i=8,sum _{i=1}^{10}y_i^2=26, end{equation*}
begin{equation*} sum _{i=1}^{10}x_i{ast}y_i=10 end{equation*}
Для одиннадцатого наблюдения дано (x_{11}=5). Предполагая, что это наблюдение удовлетворяет исходной модели, вычислите наилучший линейный несмещенный прогноз (y_{11}) и оцените его точность, построив для него 95-процентный доверительный интервал.
Решение:
begin{equation*} widehat {beta _2}=frac{overline{mathit{xy}}-overline x{ast}overline y}{overline{x^2}-overline x^2}=-0,6 end{equation*}
begin{equation*} widehat {beta _1}=overline y-widehat {beta _2}{ast}overline x=2 end{equation*}
Прогноз (widehat y_{11}=widehat {beta _1}+widehat {beta _2}{ast}x_{11}=2-0,6{ast}5=-1).
Сумма квадратов остатков равна:
begin{equation*} sum _{i=1}^{10}e_i^2=sum _{i=1}^{10}e_i{ast}left(y_i-widehat {beta _1}-widehat {beta _2}{ast}x_iright)= end{equation*}
begin{equation*} sum _{i=1}^{10}e_iy_i-widehat {beta _1}sum _{i=1}^{10}e_i-widehat {beta _2}sum _{i=1}^{10}e_ix_i=sum _{i=1}^{10}e_iy_i-widehat {beta _1}{ast}0-widehat {beta _2}{ast}0 end{equation*}
Последнее равенство верно в силу свойств остатков регрессии. Таким образом:
begin{equation*} sum _{i=1}^{10}e_i^2=sum _{i=1}^{10}e_iy_i=sum _{i=1}^{10}left(y_i-widehat {beta _1}-widehat {beta _2}{ast}x_iright)y_i= end{equation*}
begin{equation*} sum _{i=1}^{10}y_i^2-widehat {beta _1}sum _{i=1}^{10}y_i-widehat {beta _2}{ast}sum _{i=1}^{10}x_iy_i=26-2{ast}8+0,6{ast}10=16 end{equation*}
begin{equation*} delta =sqrt{s^2{ast}left(1+frac 1 n+frac{left(x_{11}-overline xright)^2}{sum left(x_i-overline xright)^2}right)}=end{equation*}
begin{equation*}=sqrt{frac{sum e_i^2}{n-2}{ast}left(1+frac 1 n+frac{left(x_{11}-overline xright)^2}{sum left(x_i-overline xright)^2}right)}= end{equation*}
begin{equation*} =sqrt{frac{16}{10-2}{ast}left(1+frac 1{10}+frac{left(5-2right)^2}{10}right)}=2 end{equation*}
Теперь можно посчитать доверительный интервал прогноза:
begin{equation*} left(widehat y_{11}-delta {ast}t_8,widehat y_{11}+delta {ast}t_8right) end{equation*}
begin{equation*} left(-1-2{ast}2,306,-1+2{ast}2,306right) end{equation*}
begin{equation*} left(-5,612,3,612right) end{equation*}
Заметим, что в этом примере точность прогноза не слишком высока, что объясняется маленьким количеством наблюдений и тем, что (x_{11}) довольно далек от среднего по выборке значения переменной (x).
Для получения более точного прогноза лучше, конечно, использовать больше данных.
Ответ: (widehat y_{11}=-1,) доверительный интервал: (left(-5,612,3,612right))