Материал из Кафедра ИУ5 МГТУ им. Н.Э.Баумана — студенческое сообщество
![]()
В статье пойдёт речь о том, как добиться корректного вывода кириллицы в «консоли» Windows (cmd.exe).
Содержание
- 1 Описание проблемы
- 2 Решение проблемы
- 2.1 Суть
- 2.2 Конкретные действия
- 2.2.1 Супер быстро и просто
- 2.2.2 Быстро и просто
- 2.2.3 Посложнее и подольше
Описание проблемы
В дистрибутив PostgreSQL, помимо всего прочего, для работы с СУБД входит:
- приложение с графическим интерфейсом
pgAdmin; - консольная утилита
psql.
При работе с psql в среде Windows пользователи всегда довольно часто сталкиваются с проблемой вывода кириллицы. Например, при отображении результатов запроса к таблице, в полях которых хранятся строковые данные на русском языке.
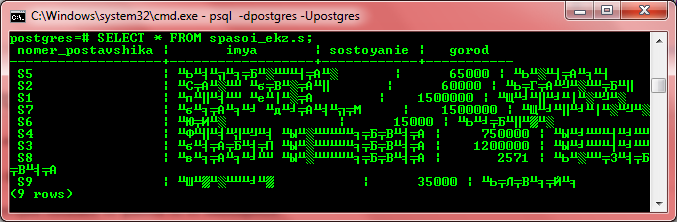
Ну и зачем тогда работать с psql, кому нужно долбить клавиатурой в консольке, когда можно всё сделать красиво и быстро в pgAdmin? Ну, не всегда pgAdmin доступен, особенно если речь идёт об удалённой машине. Кроме того, выполнение SQL-запросов в текстовом режиме консоли — это +10 к хакирству.
Решение проблемы
Версии ПО:
- MS Windows 7 SP1 x64;
- PostgreSQL 8.4.12 x32.
На сервере имеется БД, созданная в кодировке UTF8.
Суть
Суть проблемы в том, что cmd.exe работает (и так будет до скончания времён) в кодировке CP866, а сама Windows — в WIN1251, о чём psql предупреждает при начале работы:
WARNING: Console code page (866) differs from Windows code page (1251)
8-bit characters might not work correctly. See psql reference
page "Notes for Windows users" for details.
Значит, надо как-то добиться, чтобы кодировка была одна.
В разных источниках встречаются разные рецепты, включая правку реестра и подмену файлов в системных папках Windows. Ничего этого делать не нужно, достаточно всего трёх шагов:
- сменить шрифт у
cmd.exe; - сменить текущую кодовую страницу
cmd.exe; - сменить кодировку на стороне клиента в
psql.
Конкретные действия
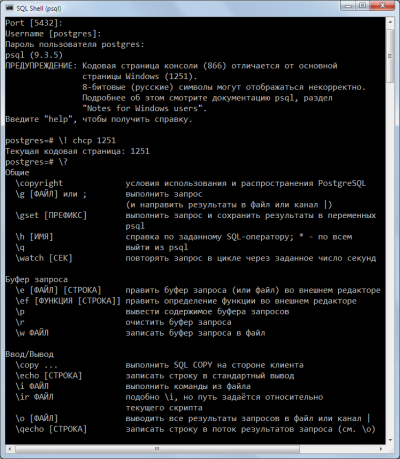
Супер быстро и просто
Запускаете cmd.exe, оттуда psql:
psql -d ВАШАБАЗА -U ВАШЛОГИН
Далее:
psql ! chcp 1251
Быстро и просто
Запускаете cmd.exe, оттуда psql:
psql -d ВАШАБАЗА -U ВАШЛОГИН
Вводите пароль (если установлен) и выполняете команду:
set client_encoding='WIN866';
И всё. Теперь результаты запроса, содержащие кириллицу, будут отображаться нормально. Но есть небольшой косяк:
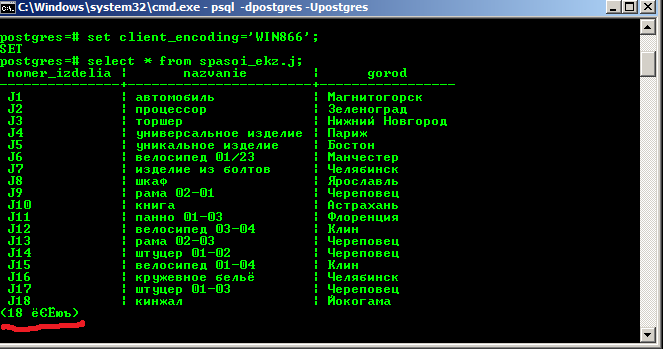
Потому предлагаем ещё способ, который этого недостатка лишён.
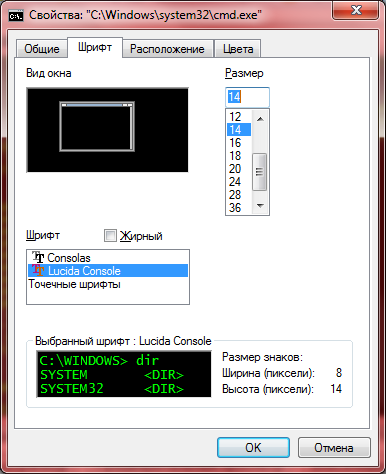
Посложнее и подольше
Запустить cmd.exe, нажать мышью в правом левом верхнем углу окна, там Свойства — Шрифт — выбрать Lucida Console. Нажать ОК.
Выполнить команду:
chcp 1251
В ответ выведет:
Текущая кодовая страница: 1251
Запустить psql;
psql -d ВАШАБАЗА -U ВАШЛОГИН
Кстати, обратите внимание — теперь предупреждения о несовпадении кодировок нет.
Выполнить:
set client_encoding='win1251';
Он выведет:
SET
Всё, теперь кириллица будет нормально отображаться.
Проверяем:
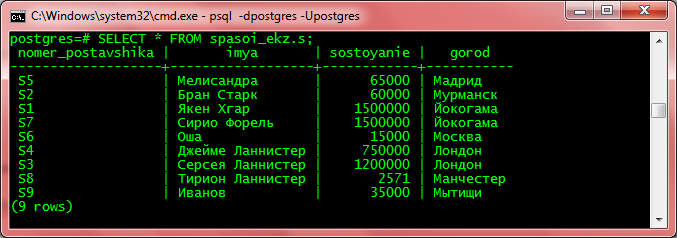
Инструкция по установке PostgreSQL и созданию демонстрационной базы данных для самостоятельного запуска запросов из курса
Если вы хотите не просто смотреть видео курса «Основы SQL», но и самостоятельно экспериментировать с SQL запросами и видеть результаты их выполнения на живой базе данных, то можете установить бесплатную систему управления базами данных PostgreSQL и создать в ней демонстрационную базу с данными, которые показаны в видео. Эта статья содержит подробные инструкции по установке и настройке.
Установка PostgreSQL
В учебном курсе «Основы SQL» для демонстрации работы SQL используется PostgreSQL. Сейчас это самая популярная из бесплатных систем управления базами данных. Все SQL запросы в курсе проверены на работоспособность именно в PostgreSQL. Однако большая часть запросов использует синтаксис стандарта ANSI SQL, поэтому они будут работать и в других системах, включая MySQL, Microsoft SQL Server и Oracle. Вы можете использовать любую систему управления базами данных, которая вам нравится, но я рекомендую PostgreSQL.
1. Загрузите PostgreSQL для вашей операционной системы на странице Downloads официального сайта. Я устанавливал на Windows, если вы используете другую операционную систему, то выбирайте соответствующие ссылки для загрузки. Примеры в курсе проверены на PostgreSQL 13, поэтому рекомендую устанавливать именно эту версию. Однако на предыдущих версиях, начиная с PosgreSQL 10, также все должно работать.
Инсталлятор для Windows и Mac OS загружается с сайта компании EDB, которая предоставляет платную поддержку для PostgreSQL. Однако PostgreSQL, которую вы установите с помощью этого инсталлятора от EDB, будет полностью бесплатной.
2. Запустите скачанный инсталлятор PostgreSQL.
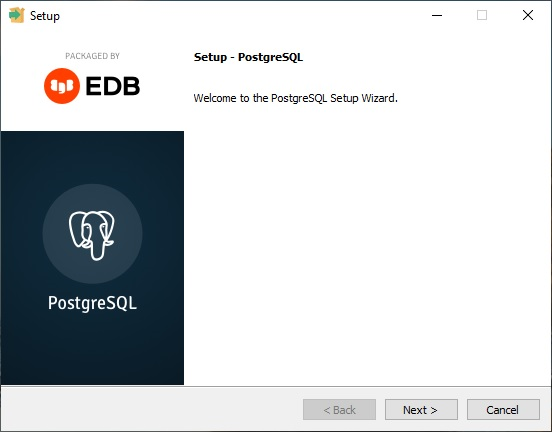
Если вы устанавливаете PostgreSQL только для использования в курсе «Основы SQL», то можете оставить почти все настройки по умолчанию, кроме локали, для которой нужно выбрать «Russian, Russia» (русский язык в стране Россия).
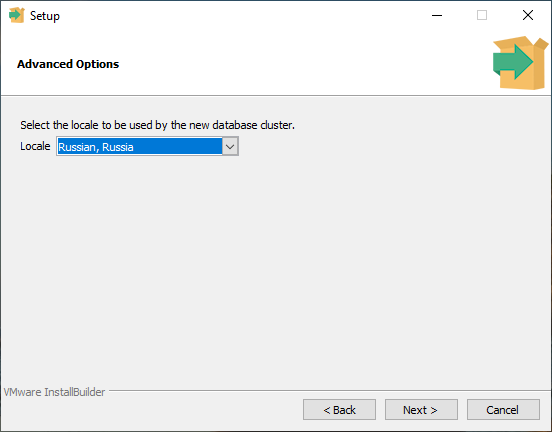
Не забудьте запомнить или записать пароль пользователя postgres, он вам понадобится для подключения к базе и выполнения запросов!
После завершения установки инсталлятор предложит вам запустить Stack Builder для установки дополнительных утилит и компонентов. Этого можно не делать, просто снимите галочку в пункте «Stack Builder…» и нажмите кнопку «Finish».
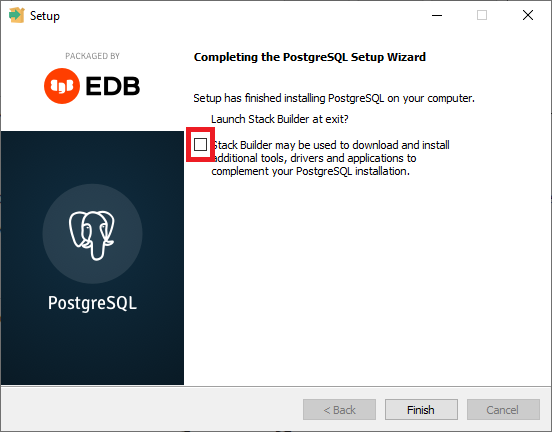
На этом установка PostrgreSQL завершена.
Запуск и настройка pgAdmin
В курсе мы будем работать с PostrgreSQL через Web-интерфейс pgAdmin. Несмотря на Admin в названии, этот инструмент подходит не только администраторам, но и разработчикам.
pgAdmin устанавливается вместе с PostgreSQL. В Windows запустить pgAdmin можно в меню Пуск.
При первом запуске pgAdmin просит задать Master Password. Он будет использоваться для безопасного сохранения паролей к базам данных PosgreSQL, с которыми вы работаете через pgAdmin. Master Password можно выбрать любой, главное, запомните или запишите его.
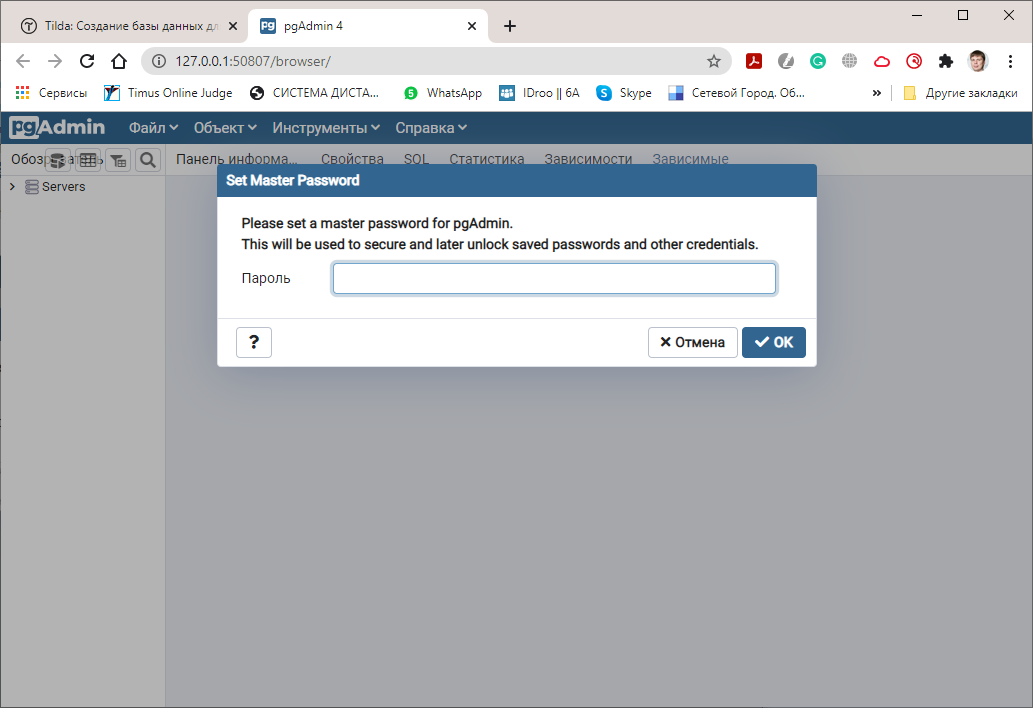
Для удобства можно переключить интерфейс pgAdmin на русский язык. Для этого выберите меню File->Preferences, в появившемся окне в меню слева выберите Miscellaneous -> User Language, а затем в поле User Language справа «Russian».
Для вступления в силу настроек языка интерфейса нужно нажать кнопку «Save» и перезапустить pgAdmin.
После перезапуска выбирайте в левом меню Servers -> PostgreSQL, после чего pgAdmin запросит пароль пользователя postgres, который вы задали в процессе установки PostgreSQL. Введите этот пароль (можете поставить галочку «Save Password» чтобы pgAdmin запомнил пароль) и вы подключитесь к базе PostgreSQL.

Список существующих на сервере баз данных показывается в левом окне pgAdmin. Нас интересует база данных postgres, схема public и таблицы в ней. pgAdmin показывает много другой информации, не пугайтесь, если вы пока не понимаете, что это такое. Многое мы разберем в курсе, но преимущественно все это нужно только администраторам базы данных.
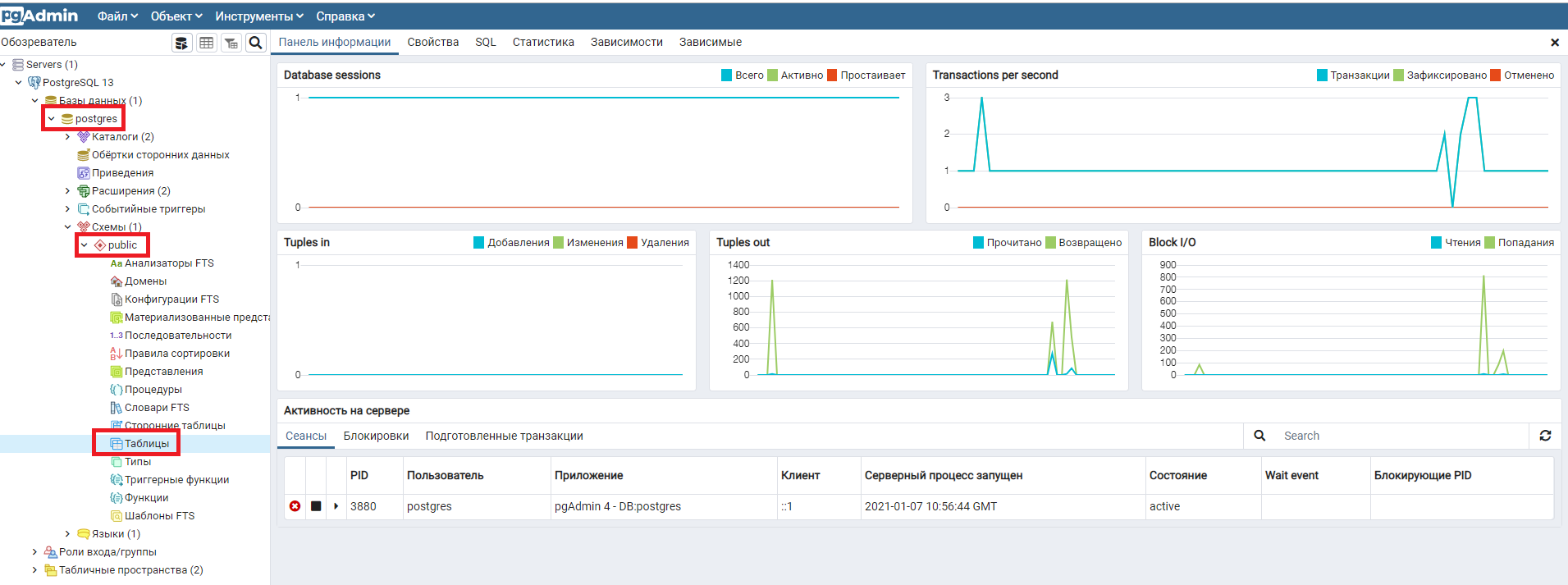
Пока в нашей базе нет никаких таблиц. Давайте создадим демонстрационные таблицы, которые используются в курсе, и заполним их данными.
Создание демонстрационной базы
1. Скачайте файл с демонстрационной базой данных курса «Основы SQL». Файл называется «sql_foundation» и имеет расширение .sql.
Файл содержит набор операторов SQL, которые создают используемые в курсе таблицы и заполняют их данными. Если вы пока не понимаете, что именно делают эти операторы, не расстраивайтесь. В курсе мы подробно рассмотрим работу каждого оператора и все будет понятно. На начальном этапе изучения курса необходимо просто запустить этот файл в pgAdmin.
2. Загрузите скачанный файл в pgAdmin. Для этого в меню pgAdmin выберите Инструменты->Запросник (в английском вариант Query Tool). В панели инструментов Запросника выберите кнопку открытия файла и в появившемся окне выберите путь к загруженному sql файлу с демонстрационной базой курса.
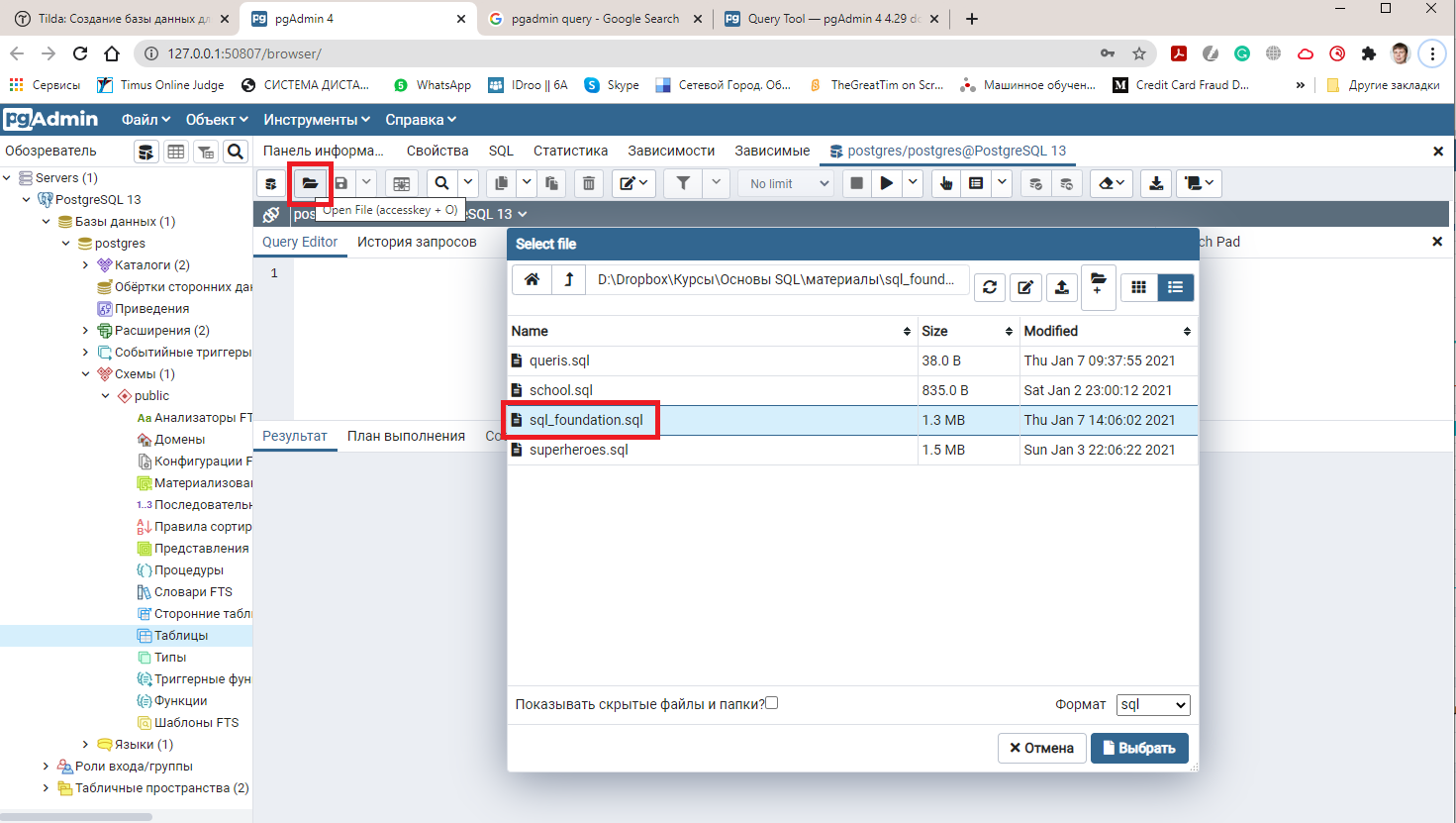
3. Запустите загруженный файл в pgAgmin. Для этого нажмите на кнопку запуска в панели инструментов Запросника или на клавишу F5.
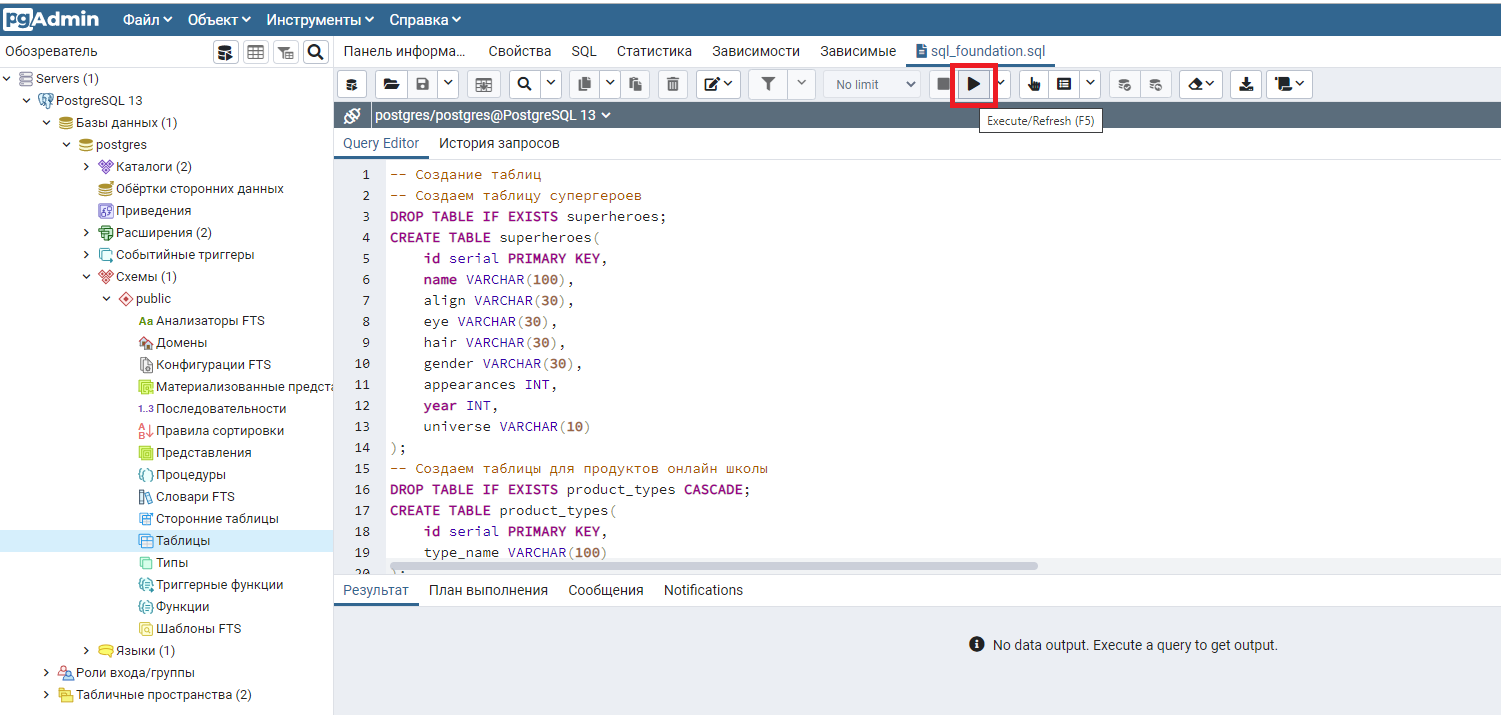
4. Проверьте правильность выполнения запроса. В нижней части экрана pgAdmin, на закладке «Сообщения» должны появиться результаты выполнения.
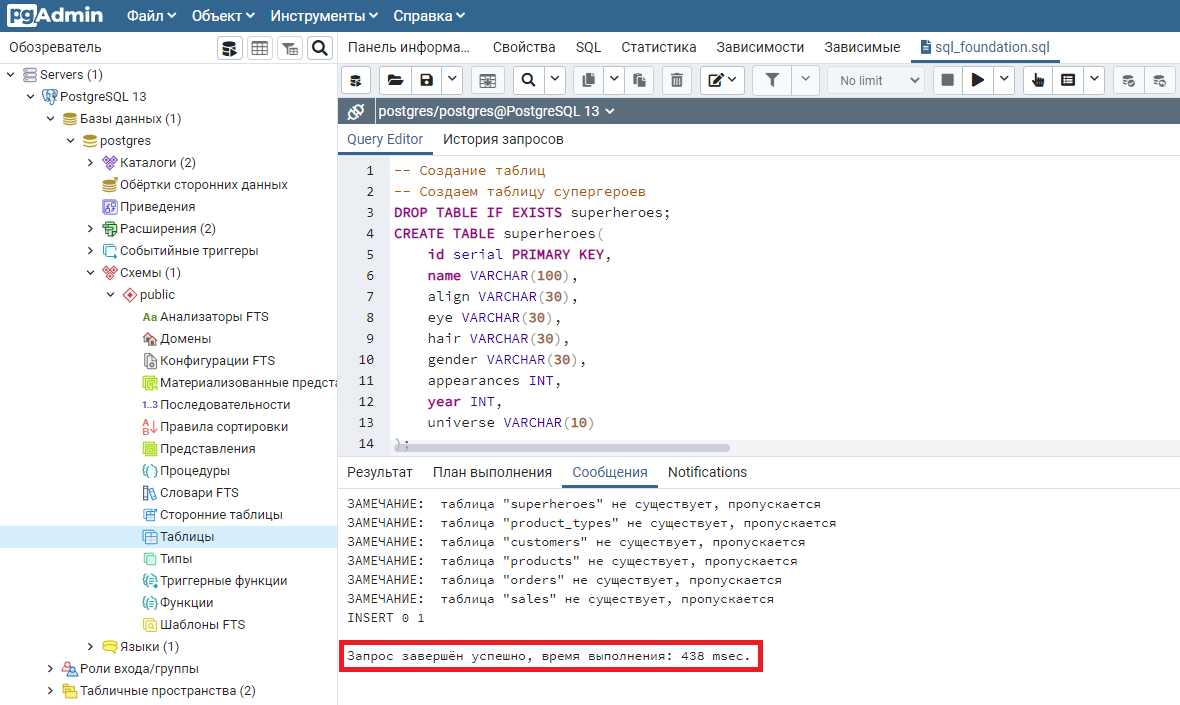
Основное, на что нужно обратить внимание — это сообщение «Запрос завершен успешно». Если такое сообщение появилось, значит все хорошо.
Если вы запускаете файл создания демонстрационной базы курса первый раз, то будет выведено несколько Замечаний, что таблицы не существуют. Их можно игнорировать.
Также в левой части интерфейса pgAdmin появится информация о созданных таблицах.
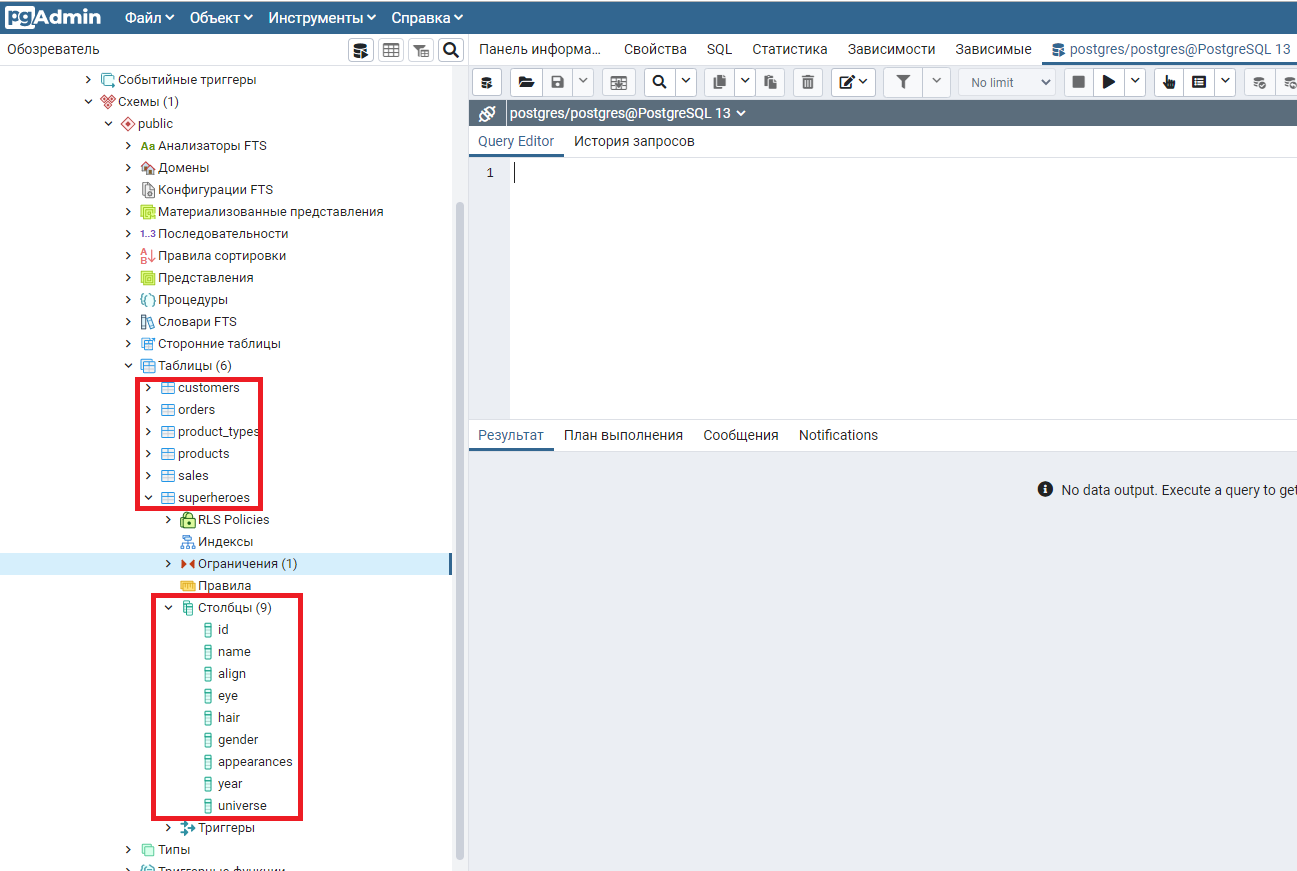
Итак, демонстрационные таблицы для курса «Основы SQL» созданы и заполнены данными, можно запускать SQL запросы.
Запуск SQL запросов в pgAdmin
В pgAdmin для запуска SQL запросов используется уже знакомый нам инструмент Запросник. Давайте откроем окно Запросника и напишем самый первый SQL запрос из видео про Оператор SELECT.
Запрос пишется в среднем окне, закладка Query Editor. Для запуска запроса нажимаем F5 или кнопку Execute в панели инструментов Запросника.
Полученные в ходе выполнения запроса данные показываются в нижней части окна, на закладке «Результат».
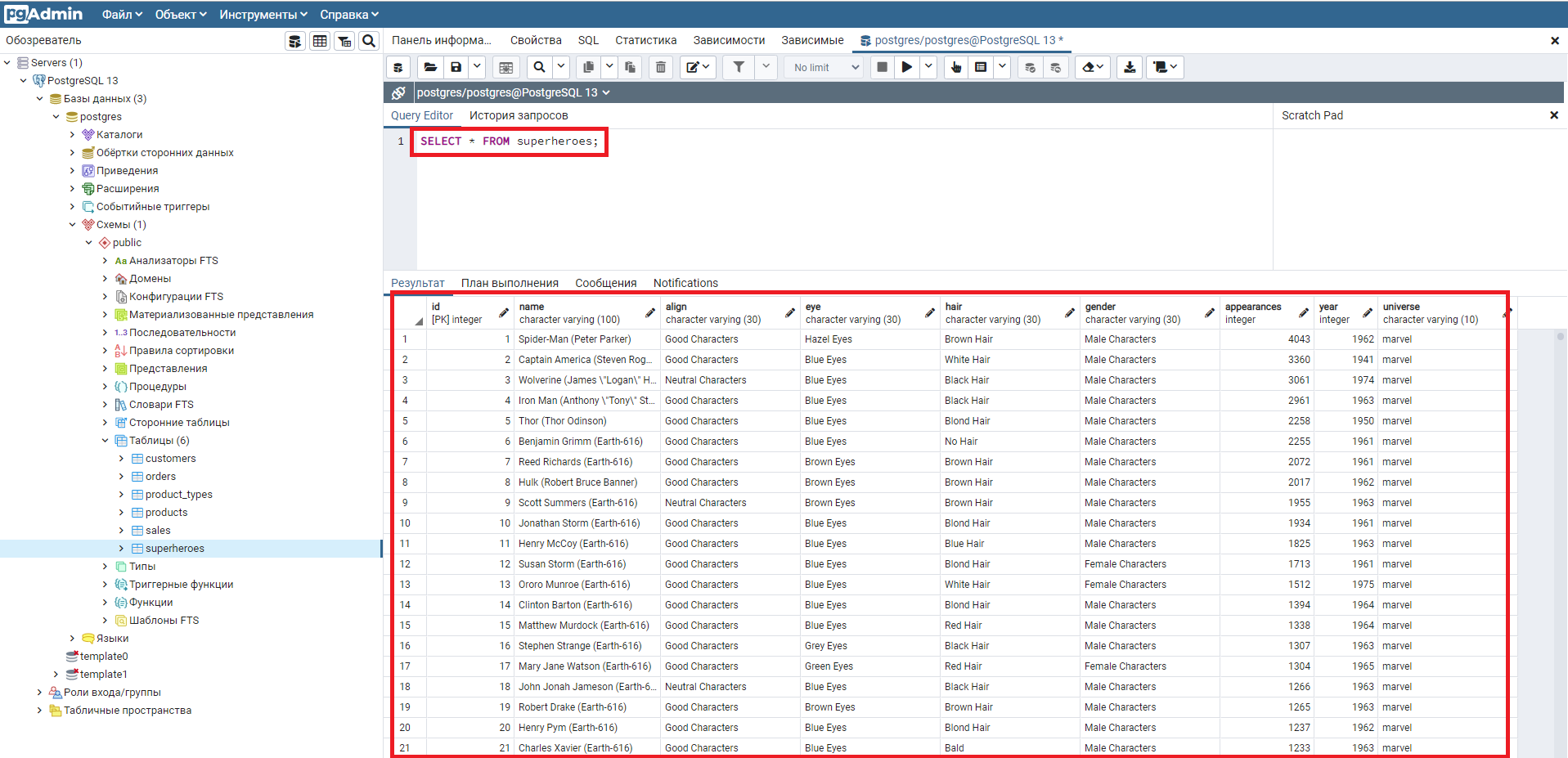
Использование SQL Shell (psql)
Если вы предпочитаете работать в командной строке, а не в громоздких приложениях типа pgAdmin, то можете использовать консольную утилиту для работы с PosgreSQL: SQL Shell (ранее она называлась psql).
SQL Shell, также как и pgAdmin, устанавливается совместно с PostgreSQL. В Windows запустить SQL Shell можно через меню Пуск.
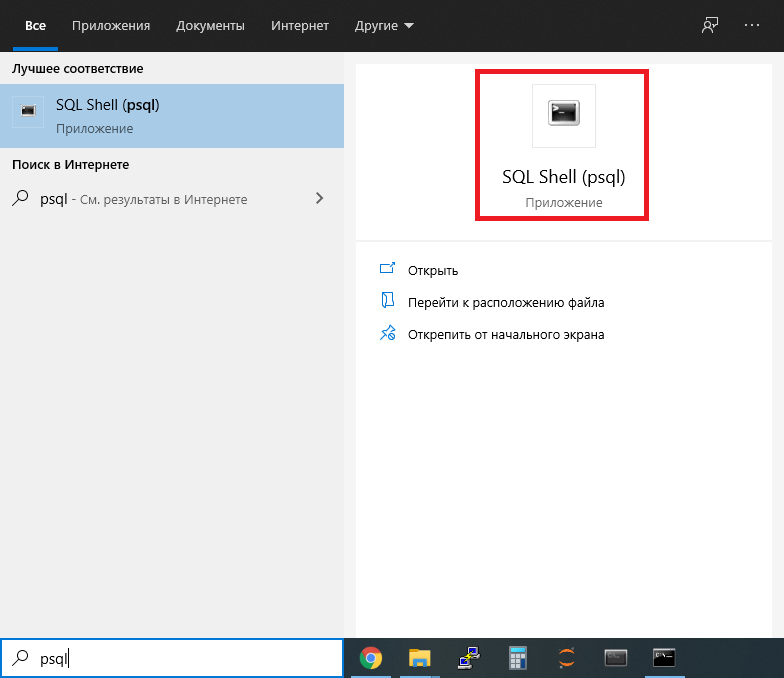
После запуска SQL Shell задаст ряд вопросов о параметрах подключения к PostgreSQL, можно оставить все значения по умолчанию (если вы не меняли настройки при установке). После этого введите пароль пользователя postgres и можете начинать работать с базой данных.
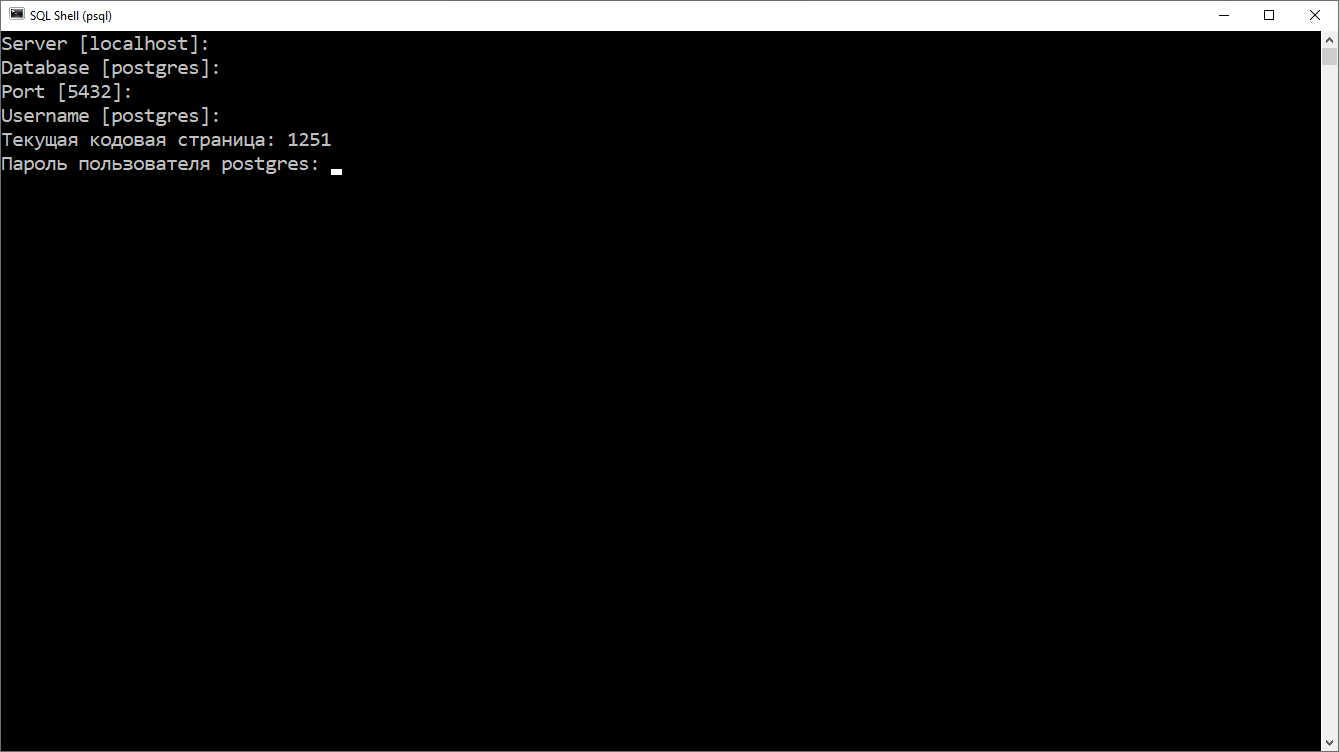
Если вам не повезло, то в Windows SQL Shell запустится с неправильной кодировкой для русского языка, будет выдавать предупреждение и некоторые русские буквы будут выводиться неправильно.
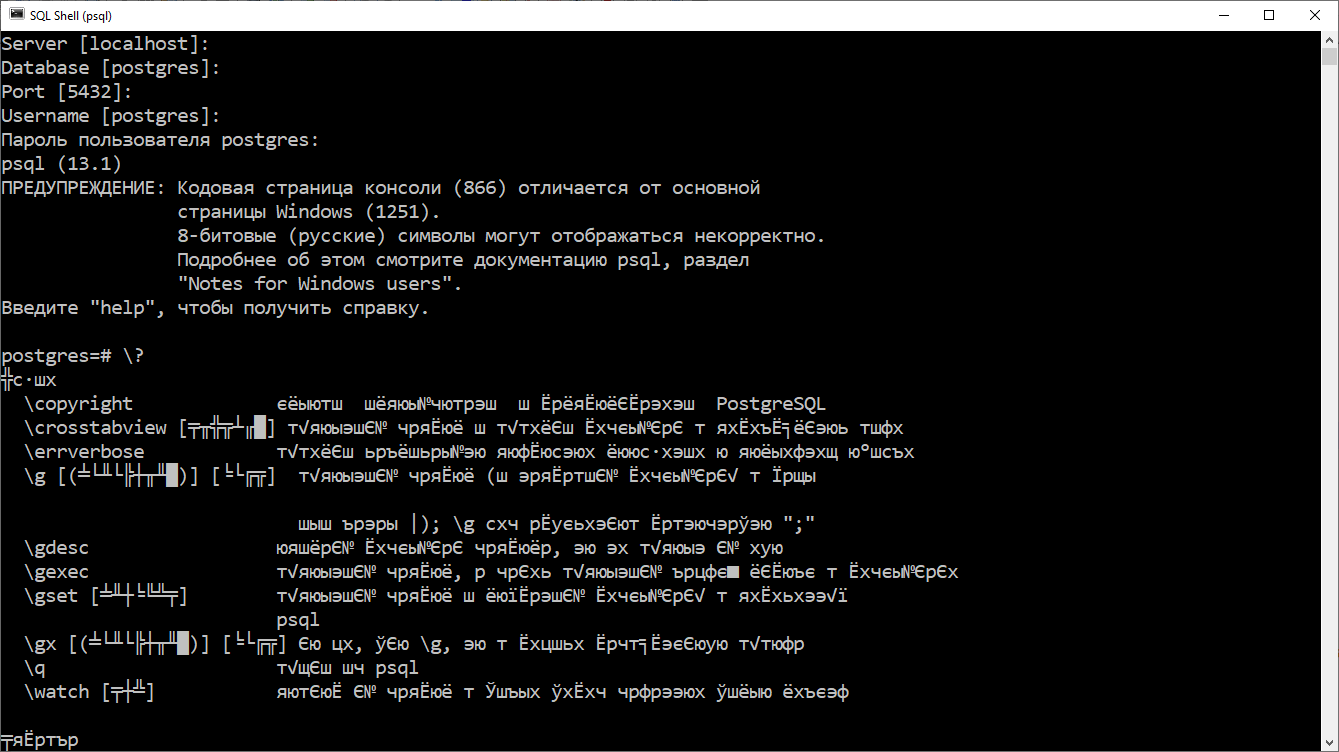
Чтобы решить эту проблему, нужно прописать правильную кодировку в файл для запуска SQL Shell. В моем случае файл называется «C:Program FilesPostgreSQL13scriptsrunpsql.bat». В этот файл нужно добавить строку:
chcp 1251
После добавления строки с установкой правильной кодировки файл runpsql. bat стал выглядеть следующим образом.
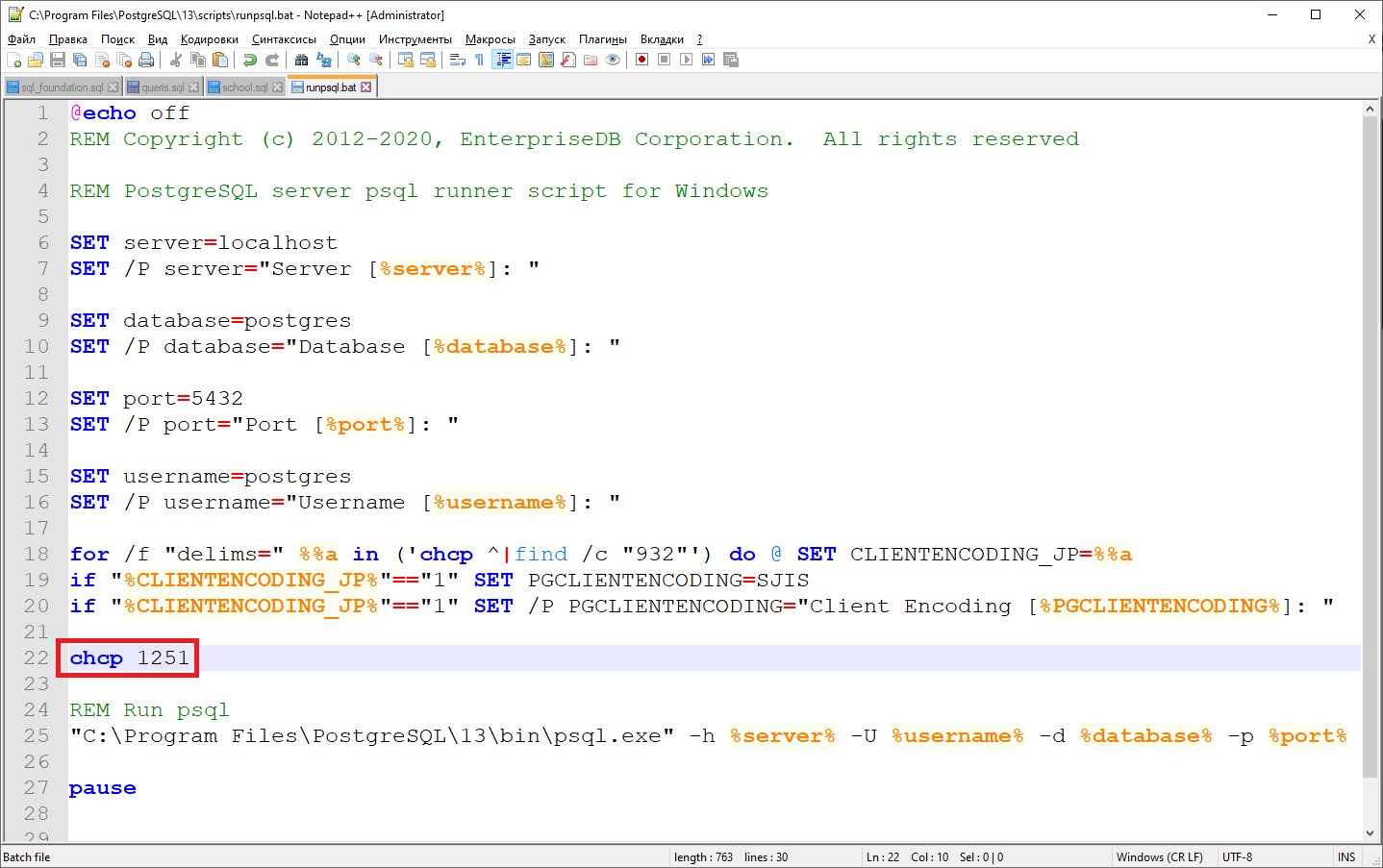
Сохраняем файл runpsql. bat, перезапускаем SQL Shell, после этого проблем с русской кодировкой быть не должно.
Для создания демонстрационной базы курса в SQL Shell выполните следующую команду:
i 'C:/путь/к/файлу/sql_foundation.sql'i означает import — загрузка файла sql в базу данных.
Обратите, пожалуйста, внимание:
1. Путь к файлу sql_foundation.sql нужно указывать в одиночных кавычках. Если будете использовать двойные кавычки, то не заработает.
2. В пути используются прямые слеши (/), как в Linux/Unix, несмотря на то, что мы работаем под Windows. Если писать обратные слеши (), как это принято в Windows, то будет выдаваться ошибка «Permission denied». Не очень информативное поведение SQL Shel.
Запросы в SQL Shell можно писать прямо в командной строке.
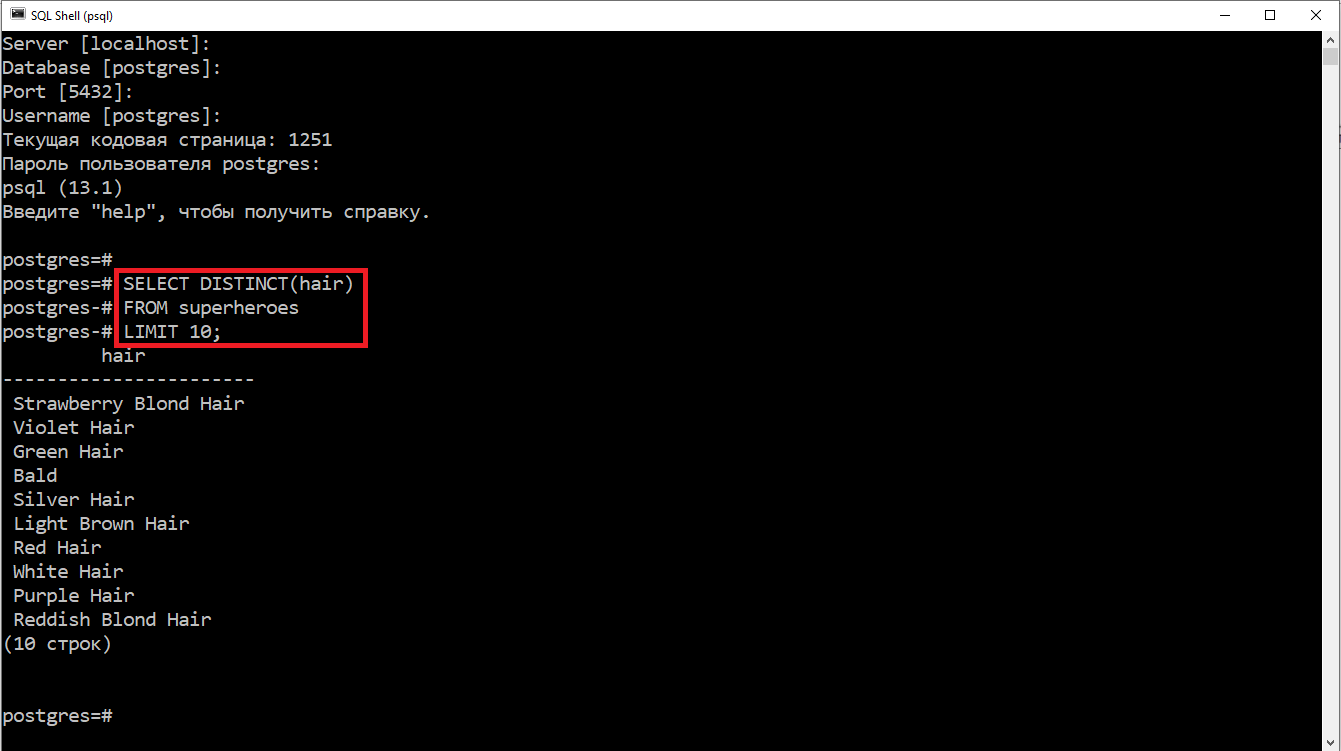
Запрос в SQL Shell может занимать несколько строк, как в примере на рисунке. Запрос запускается после ввода ; (точка с запятой) или команды g.
Результаты выполнения запроса показываются сразу же после него.
Полезная функция SQL Shell — история команд. Если нажимать стрелки вверх или вниз, то можно увидеть, какие команды были запущены ранее и повторить интересующую вас команду.
Итоги
В этой статье вы узнали, как установить PostgreSQL и как создать в нем демонстрационную базу для курса «Основы SQL». Также вы настроили и научились использовать два инструмента работы с PostgreSQL: pgAdmin и SQL Shell. Не обязательно использовать оба, выбирайте тот, который вам больше нравится: pgAdmin с Web-интерфейсом или командную строку SQL Shell.
В процессе экспериментов с SQL запросами в курсе вы можете случайно повредить созданную базу. В этом нет ничего страшного, базу данных можно легко пересоздать повторно запустив sql файл с операторами по созданию базы. При этом все имеющиеся таблицы будут удалены, заново созданы и заполнены данными. Все изменения, которые вы вносили, будут потеряны.
Полезные ссылки
The character set support in PostgreSQL allows you to store text in a variety of character sets (also called encodings), including single-byte character sets such as the ISO 8859 series and multiple-byte character sets such as EUC (Extended Unix Code), UTF-8, and Mule internal code. All supported character sets can be used transparently by clients, but a few are not supported for use within the server (that is, as a server-side encoding). The default character set is selected while initializing your PostgreSQL database cluster using initdb. It can be overridden when you create a database, so you can have multiple databases each with a different character set.
An important restriction, however, is that each database’s character set must be compatible with the database’s LC_CTYPE (character classification) and LC_COLLATE (string sort order) locale settings. For C or POSIX locale, any character set is allowed, but for other libc-provided locales there is only one character set that will work correctly. (On Windows, however, UTF-8 encoding can be used with any locale.) If you have ICU support configured, ICU-provided locales can be used with most but not all server-side encodings.
24.3.1. Supported Character Sets
Table 24.1 shows the character sets available for use in PostgreSQL.
Table 24.1. PostgreSQL Character Sets
| Name | Description | Language | Server? | ICU? | Bytes/Char | Aliases |
|---|---|---|---|---|---|---|
BIG5 |
Big Five | Traditional Chinese | No | No | 1–2 | WIN950, Windows950 |
EUC_CN |
Extended UNIX Code-CN | Simplified Chinese | Yes | Yes | 1–3 | |
EUC_JP |
Extended UNIX Code-JP | Japanese | Yes | Yes | 1–3 | |
EUC_JIS_2004 |
Extended UNIX Code-JP, JIS X 0213 | Japanese | Yes | No | 1–3 | |
EUC_KR |
Extended UNIX Code-KR | Korean | Yes | Yes | 1–3 | |
EUC_TW |
Extended UNIX Code-TW | Traditional Chinese, Taiwanese | Yes | Yes | 1–3 | |
GB18030 |
National Standard | Chinese | No | No | 1–4 | |
GBK |
Extended National Standard | Simplified Chinese | No | No | 1–2 | WIN936, Windows936 |
ISO_8859_5 |
ISO 8859-5, ECMA 113 | Latin/Cyrillic | Yes | Yes | 1 | |
ISO_8859_6 |
ISO 8859-6, ECMA 114 | Latin/Arabic | Yes | Yes | 1 | |
ISO_8859_7 |
ISO 8859-7, ECMA 118 | Latin/Greek | Yes | Yes | 1 | |
ISO_8859_8 |
ISO 8859-8, ECMA 121 | Latin/Hebrew | Yes | Yes | 1 | |
JOHAB |
JOHAB | Korean (Hangul) | No | No | 1–3 | |
KOI8R |
KOI8-R | Cyrillic (Russian) | Yes | Yes | 1 | KOI8 |
KOI8U |
KOI8-U | Cyrillic (Ukrainian) | Yes | Yes | 1 | |
LATIN1 |
ISO 8859-1, ECMA 94 | Western European | Yes | Yes | 1 | ISO88591 |
LATIN2 |
ISO 8859-2, ECMA 94 | Central European | Yes | Yes | 1 | ISO88592 |
LATIN3 |
ISO 8859-3, ECMA 94 | South European | Yes | Yes | 1 | ISO88593 |
LATIN4 |
ISO 8859-4, ECMA 94 | North European | Yes | Yes | 1 | ISO88594 |
LATIN5 |
ISO 8859-9, ECMA 128 | Turkish | Yes | Yes | 1 | ISO88599 |
LATIN6 |
ISO 8859-10, ECMA 144 | Nordic | Yes | Yes | 1 | ISO885910 |
LATIN7 |
ISO 8859-13 | Baltic | Yes | Yes | 1 | ISO885913 |
LATIN8 |
ISO 8859-14 | Celtic | Yes | Yes | 1 | ISO885914 |
LATIN9 |
ISO 8859-15 | LATIN1 with Euro and accents | Yes | Yes | 1 | ISO885915 |
LATIN10 |
ISO 8859-16, ASRO SR 14111 | Romanian | Yes | No | 1 | ISO885916 |
MULE_INTERNAL |
Mule internal code | Multilingual Emacs | Yes | No | 1–4 | |
SJIS |
Shift JIS | Japanese | No | No | 1–2 | Mskanji, ShiftJIS, WIN932, Windows932 |
SHIFT_JIS_2004 |
Shift JIS, JIS X 0213 | Japanese | No | No | 1–2 | |
SQL_ASCII |
unspecified (see text) | any | Yes | No | 1 | |
UHC |
Unified Hangul Code | Korean | No | No | 1–2 | WIN949, Windows949 |
UTF8 |
Unicode, 8-bit | all | Yes | Yes | 1–4 | Unicode |
WIN866 |
Windows CP866 | Cyrillic | Yes | Yes | 1 | ALT |
WIN874 |
Windows CP874 | Thai | Yes | No | 1 | |
WIN1250 |
Windows CP1250 | Central European | Yes | Yes | 1 | |
WIN1251 |
Windows CP1251 | Cyrillic | Yes | Yes | 1 | WIN |
WIN1252 |
Windows CP1252 | Western European | Yes | Yes | 1 | |
WIN1253 |
Windows CP1253 | Greek | Yes | Yes | 1 | |
WIN1254 |
Windows CP1254 | Turkish | Yes | Yes | 1 | |
WIN1255 |
Windows CP1255 | Hebrew | Yes | Yes | 1 | |
WIN1256 |
Windows CP1256 | Arabic | Yes | Yes | 1 | |
WIN1257 |
Windows CP1257 | Baltic | Yes | Yes | 1 | |
WIN1258 |
Windows CP1258 | Vietnamese | Yes | Yes | 1 | ABC, TCVN, TCVN5712, VSCII |
Not all client APIs support all the listed character sets. For example, the PostgreSQL JDBC driver does not support MULE_INTERNAL, LATIN6, LATIN8, and LATIN10.
The SQL_ASCII setting behaves considerably differently from the other settings. When the server character set is SQL_ASCII, the server interprets byte values 0–127 according to the ASCII standard, while byte values 128–255 are taken as uninterpreted characters. No encoding conversion will be done when the setting is SQL_ASCII. Thus, this setting is not so much a declaration that a specific encoding is in use, as a declaration of ignorance about the encoding. In most cases, if you are working with any non-ASCII data, it is unwise to use the SQL_ASCII setting because PostgreSQL will be unable to help you by converting or validating non-ASCII characters.
24.3.2. Setting the Character Set
initdb defines the default character set (encoding) for a PostgreSQL cluster. For example,
initdb -E EUC_JP
sets the default character set to EUC_JP (Extended Unix Code for Japanese). You can use --encoding instead of -E if you prefer longer option strings. If no -E or --encoding option is given, initdb attempts to determine the appropriate encoding to use based on the specified or default locale.
You can specify a non-default encoding at database creation time, provided that the encoding is compatible with the selected locale:
createdb -E EUC_KR -T template0 --lc-collate=ko_KR.euckr --lc-ctype=ko_KR.euckr korean
This will create a database named korean that uses the character set EUC_KR, and locale ko_KR. Another way to accomplish this is to use this SQL command:
CREATE DATABASE korean WITH ENCODING 'EUC_KR' LC_COLLATE='ko_KR.euckr' LC_CTYPE='ko_KR.euckr' TEMPLATE=template0;
Notice that the above commands specify copying the template0 database. When copying any other database, the encoding and locale settings cannot be changed from those of the source database, because that might result in corrupt data. For more information see Section 23.3.
The encoding for a database is stored in the system catalog pg_database. You can see it by using the psql -l option or the l command.
$ psql -l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access Privileges
-----------+----------+-----------+-------------+-------------+-------------------------------------
clocaledb | hlinnaka | SQL_ASCII | C | C |
englishdb | hlinnaka | UTF8 | en_GB.UTF8 | en_GB.UTF8 |
japanese | hlinnaka | UTF8 | ja_JP.UTF8 | ja_JP.UTF8 |
korean | hlinnaka | EUC_KR | ko_KR.euckr | ko_KR.euckr |
postgres | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 |
template0 | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka}
template1 | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka}
(7 rows)
Important
On most modern operating systems, PostgreSQL can determine which character set is implied by the LC_CTYPE setting, and it will enforce that only the matching database encoding is used. On older systems it is your responsibility to ensure that you use the encoding expected by the locale you have selected. A mistake in this area is likely to lead to strange behavior of locale-dependent operations such as sorting.
PostgreSQL will allow superusers to create databases with SQL_ASCII encoding even when LC_CTYPE is not C or POSIX. As noted above, SQL_ASCII does not enforce that the data stored in the database has any particular encoding, and so this choice poses risks of locale-dependent misbehavior. Using this combination of settings is deprecated and may someday be forbidden altogether.
24.3.3. Automatic Character Set Conversion Between Server and Client
PostgreSQL supports automatic character set conversion between server and client for many combinations of character sets (Section 24.3.4 shows which ones).
To enable automatic character set conversion, you have to tell PostgreSQL the character set (encoding) you would like to use in the client. There are several ways to accomplish this:
-
Using the
encodingcommand in psql.encodingallows you to change client encoding on the fly. For example, to change the encoding toSJIS, type:encoding SJIS
-
libpq (Section 34.11) has functions to control the client encoding.
-
Using
SET client_encoding TO. Setting the client encoding can be done with this SQL command:SET CLIENT_ENCODING TO '
value';Also you can use the standard SQL syntax
SET NAMESfor this purpose:SET NAMES '
value';To query the current client encoding:
SHOW client_encoding;
To return to the default encoding:
RESET client_encoding;
-
Using
PGCLIENTENCODING. If the environment variablePGCLIENTENCODINGis defined in the client’s environment, that client encoding is automatically selected when a connection to the server is made. (This can subsequently be overridden using any of the other methods mentioned above.) -
Using the configuration variable client_encoding. If the
client_encodingvariable is set, that client encoding is automatically selected when a connection to the server is made. (This can subsequently be overridden using any of the other methods mentioned above.)
If the conversion of a particular character is not possible — suppose you chose EUC_JP for the server and LATIN1 for the client, and some Japanese characters are returned that do not have a representation in LATIN1 — an error is reported.
If the client character set is defined as SQL_ASCII, encoding conversion is disabled, regardless of the server’s character set. (However, if the server’s character set is not SQL_ASCII, the server will still check that incoming data is valid for that encoding; so the net effect is as though the client character set were the same as the server’s.) Just as for the server, use of SQL_ASCII is unwise unless you are working with all-ASCII data.
24.3.4. Available Character Set Conversions
PostgreSQL allows conversion between any two character sets for which a conversion function is listed in the pg_conversion system catalog. PostgreSQL comes with some predefined conversions, as summarized in Table 24.2 and shown in more detail in Table 24.3. You can create a new conversion using the SQL command CREATE CONVERSION. (To be used for automatic client/server conversions, a conversion must be marked as “default” for its character set pair.)
Table 24.2. Built-in Client/Server Character Set Conversions
| Server Character Set | Available Client Character Sets |
|---|---|
BIG5 |
not supported as a server encoding |
EUC_CN |
EUC_CN, MULE_INTERNAL, UTF8 |
EUC_JP |
EUC_JP, MULE_INTERNAL, SJIS, UTF8 |
EUC_JIS_2004 |
EUC_JIS_2004, SHIFT_JIS_2004, UTF8 |
EUC_KR |
EUC_KR, MULE_INTERNAL, UTF8 |
EUC_TW |
EUC_TW, BIG5, MULE_INTERNAL, UTF8 |
GB18030 |
not supported as a server encoding |
GBK |
not supported as a server encoding |
ISO_8859_5 |
ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
ISO_8859_6 |
ISO_8859_6, UTF8 |
ISO_8859_7 |
ISO_8859_7, UTF8 |
ISO_8859_8 |
ISO_8859_8, UTF8 |
JOHAB |
not supported as a server encoding |
KOI8R |
KOI8R, ISO_8859_5, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
KOI8U |
KOI8U, UTF8 |
LATIN1 |
LATIN1, MULE_INTERNAL, UTF8 |
LATIN2 |
LATIN2, MULE_INTERNAL, UTF8, WIN1250 |
LATIN3 |
LATIN3, MULE_INTERNAL, UTF8 |
LATIN4 |
LATIN4, MULE_INTERNAL, UTF8 |
LATIN5 |
LATIN5, UTF8 |
LATIN6 |
LATIN6, UTF8 |
LATIN7 |
LATIN7, UTF8 |
LATIN8 |
LATIN8, UTF8 |
LATIN9 |
LATIN9, UTF8 |
LATIN10 |
LATIN10, UTF8 |
MULE_INTERNAL |
MULE_INTERNAL, BIG5, EUC_CN, EUC_JP, EUC_KR, EUC_TW, ISO_8859_5, KOI8R, LATIN1 to LATIN4, SJIS, WIN866, WIN1250, WIN1251 |
SJIS |
not supported as a server encoding |
SHIFT_JIS_2004 |
not supported as a server encoding |
SQL_ASCII |
any (no conversion will be performed) |
UHC |
not supported as a server encoding |
UTF8 |
all supported encodings |
WIN866 |
WIN866, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN1251 |
WIN874 |
WIN874, UTF8 |
WIN1250 |
WIN1250, LATIN2, MULE_INTERNAL, UTF8 |
WIN1251 |
WIN1251, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866 |
WIN1252 |
WIN1252, UTF8 |
WIN1253 |
WIN1253, UTF8 |
WIN1254 |
WIN1254, UTF8 |
WIN1255 |
WIN1255, UTF8 |
WIN1256 |
WIN1256, UTF8 |
WIN1257 |
WIN1257, UTF8 |
WIN1258 |
WIN1258, UTF8 |
Table 24.3. All Built-in Character Set Conversions
| Conversion Name [a] | Source Encoding | Destination Encoding |
|---|---|---|
big5_to_euc_tw |
BIG5 |
EUC_TW |
big5_to_mic |
BIG5 |
MULE_INTERNAL |
big5_to_utf8 |
BIG5 |
UTF8 |
euc_cn_to_mic |
EUC_CN |
MULE_INTERNAL |
euc_cn_to_utf8 |
EUC_CN |
UTF8 |
euc_jp_to_mic |
EUC_JP |
MULE_INTERNAL |
euc_jp_to_sjis |
EUC_JP |
SJIS |
euc_jp_to_utf8 |
EUC_JP |
UTF8 |
euc_kr_to_mic |
EUC_KR |
MULE_INTERNAL |
euc_kr_to_utf8 |
EUC_KR |
UTF8 |
euc_tw_to_big5 |
EUC_TW |
BIG5 |
euc_tw_to_mic |
EUC_TW |
MULE_INTERNAL |
euc_tw_to_utf8 |
EUC_TW |
UTF8 |
gb18030_to_utf8 |
GB18030 |
UTF8 |
gbk_to_utf8 |
GBK |
UTF8 |
iso_8859_10_to_utf8 |
LATIN6 |
UTF8 |
iso_8859_13_to_utf8 |
LATIN7 |
UTF8 |
iso_8859_14_to_utf8 |
LATIN8 |
UTF8 |
iso_8859_15_to_utf8 |
LATIN9 |
UTF8 |
iso_8859_16_to_utf8 |
LATIN10 |
UTF8 |
iso_8859_1_to_mic |
LATIN1 |
MULE_INTERNAL |
iso_8859_1_to_utf8 |
LATIN1 |
UTF8 |
iso_8859_2_to_mic |
LATIN2 |
MULE_INTERNAL |
iso_8859_2_to_utf8 |
LATIN2 |
UTF8 |
iso_8859_2_to_windows_1250 |
LATIN2 |
WIN1250 |
iso_8859_3_to_mic |
LATIN3 |
MULE_INTERNAL |
iso_8859_3_to_utf8 |
LATIN3 |
UTF8 |
iso_8859_4_to_mic |
LATIN4 |
MULE_INTERNAL |
iso_8859_4_to_utf8 |
LATIN4 |
UTF8 |
iso_8859_5_to_koi8_r |
ISO_8859_5 |
KOI8R |
iso_8859_5_to_mic |
ISO_8859_5 |
MULE_INTERNAL |
iso_8859_5_to_utf8 |
ISO_8859_5 |
UTF8 |
iso_8859_5_to_windows_1251 |
ISO_8859_5 |
WIN1251 |
iso_8859_5_to_windows_866 |
ISO_8859_5 |
WIN866 |
iso_8859_6_to_utf8 |
ISO_8859_6 |
UTF8 |
iso_8859_7_to_utf8 |
ISO_8859_7 |
UTF8 |
iso_8859_8_to_utf8 |
ISO_8859_8 |
UTF8 |
iso_8859_9_to_utf8 |
LATIN5 |
UTF8 |
johab_to_utf8 |
JOHAB |
UTF8 |
koi8_r_to_iso_8859_5 |
KOI8R |
ISO_8859_5 |
koi8_r_to_mic |
KOI8R |
MULE_INTERNAL |
koi8_r_to_utf8 |
KOI8R |
UTF8 |
koi8_r_to_windows_1251 |
KOI8R |
WIN1251 |
koi8_r_to_windows_866 |
KOI8R |
WIN866 |
koi8_u_to_utf8 |
KOI8U |
UTF8 |
mic_to_big5 |
MULE_INTERNAL |
BIG5 |
mic_to_euc_cn |
MULE_INTERNAL |
EUC_CN |
mic_to_euc_jp |
MULE_INTERNAL |
EUC_JP |
mic_to_euc_kr |
MULE_INTERNAL |
EUC_KR |
mic_to_euc_tw |
MULE_INTERNAL |
EUC_TW |
mic_to_iso_8859_1 |
MULE_INTERNAL |
LATIN1 |
mic_to_iso_8859_2 |
MULE_INTERNAL |
LATIN2 |
mic_to_iso_8859_3 |
MULE_INTERNAL |
LATIN3 |
mic_to_iso_8859_4 |
MULE_INTERNAL |
LATIN4 |
mic_to_iso_8859_5 |
MULE_INTERNAL |
ISO_8859_5 |
mic_to_koi8_r |
MULE_INTERNAL |
KOI8R |
mic_to_sjis |
MULE_INTERNAL |
SJIS |
mic_to_windows_1250 |
MULE_INTERNAL |
WIN1250 |
mic_to_windows_1251 |
MULE_INTERNAL |
WIN1251 |
mic_to_windows_866 |
MULE_INTERNAL |
WIN866 |
sjis_to_euc_jp |
SJIS |
EUC_JP |
sjis_to_mic |
SJIS |
MULE_INTERNAL |
sjis_to_utf8 |
SJIS |
UTF8 |
windows_1258_to_utf8 |
WIN1258 |
UTF8 |
uhc_to_utf8 |
UHC |
UTF8 |
utf8_to_big5 |
UTF8 |
BIG5 |
utf8_to_euc_cn |
UTF8 |
EUC_CN |
utf8_to_euc_jp |
UTF8 |
EUC_JP |
utf8_to_euc_kr |
UTF8 |
EUC_KR |
utf8_to_euc_tw |
UTF8 |
EUC_TW |
utf8_to_gb18030 |
UTF8 |
GB18030 |
utf8_to_gbk |
UTF8 |
GBK |
utf8_to_iso_8859_1 |
UTF8 |
LATIN1 |
utf8_to_iso_8859_10 |
UTF8 |
LATIN6 |
utf8_to_iso_8859_13 |
UTF8 |
LATIN7 |
utf8_to_iso_8859_14 |
UTF8 |
LATIN8 |
utf8_to_iso_8859_15 |
UTF8 |
LATIN9 |
utf8_to_iso_8859_16 |
UTF8 |
LATIN10 |
utf8_to_iso_8859_2 |
UTF8 |
LATIN2 |
utf8_to_iso_8859_3 |
UTF8 |
LATIN3 |
utf8_to_iso_8859_4 |
UTF8 |
LATIN4 |
utf8_to_iso_8859_5 |
UTF8 |
ISO_8859_5 |
utf8_to_iso_8859_6 |
UTF8 |
ISO_8859_6 |
utf8_to_iso_8859_7 |
UTF8 |
ISO_8859_7 |
utf8_to_iso_8859_8 |
UTF8 |
ISO_8859_8 |
utf8_to_iso_8859_9 |
UTF8 |
LATIN5 |
utf8_to_johab |
UTF8 |
JOHAB |
utf8_to_koi8_r |
UTF8 |
KOI8R |
utf8_to_koi8_u |
UTF8 |
KOI8U |
utf8_to_sjis |
UTF8 |
SJIS |
utf8_to_windows_1258 |
UTF8 |
WIN1258 |
utf8_to_uhc |
UTF8 |
UHC |
utf8_to_windows_1250 |
UTF8 |
WIN1250 |
utf8_to_windows_1251 |
UTF8 |
WIN1251 |
utf8_to_windows_1252 |
UTF8 |
WIN1252 |
utf8_to_windows_1253 |
UTF8 |
WIN1253 |
utf8_to_windows_1254 |
UTF8 |
WIN1254 |
utf8_to_windows_1255 |
UTF8 |
WIN1255 |
utf8_to_windows_1256 |
UTF8 |
WIN1256 |
utf8_to_windows_1257 |
UTF8 |
WIN1257 |
utf8_to_windows_866 |
UTF8 |
WIN866 |
utf8_to_windows_874 |
UTF8 |
WIN874 |
windows_1250_to_iso_8859_2 |
WIN1250 |
LATIN2 |
windows_1250_to_mic |
WIN1250 |
MULE_INTERNAL |
windows_1250_to_utf8 |
WIN1250 |
UTF8 |
windows_1251_to_iso_8859_5 |
WIN1251 |
ISO_8859_5 |
windows_1251_to_koi8_r |
WIN1251 |
KOI8R |
windows_1251_to_mic |
WIN1251 |
MULE_INTERNAL |
windows_1251_to_utf8 |
WIN1251 |
UTF8 |
windows_1251_to_windows_866 |
WIN1251 |
WIN866 |
windows_1252_to_utf8 |
WIN1252 |
UTF8 |
windows_1256_to_utf8 |
WIN1256 |
UTF8 |
windows_866_to_iso_8859_5 |
WIN866 |
ISO_8859_5 |
windows_866_to_koi8_r |
WIN866 |
KOI8R |
windows_866_to_mic |
WIN866 |
MULE_INTERNAL |
windows_866_to_utf8 |
WIN866 |
UTF8 |
windows_866_to_windows_1251 |
WIN866 |
WIN |
windows_874_to_utf8 |
WIN874 |
UTF8 |
euc_jis_2004_to_utf8 |
EUC_JIS_2004 |
UTF8 |
utf8_to_euc_jis_2004 |
UTF8 |
EUC_JIS_2004 |
shift_jis_2004_to_utf8 |
SHIFT_JIS_2004 |
UTF8 |
utf8_to_shift_jis_2004 |
UTF8 |
SHIFT_JIS_2004 |
euc_jis_2004_to_shift_jis_2004 |
EUC_JIS_2004 |
SHIFT_JIS_2004 |
shift_jis_2004_to_euc_jis_2004 |
SHIFT_JIS_2004 |
EUC_JIS_2004 |
|
[a] The conversion names follow a standard naming scheme: The official name of the source encoding with all non-alphanumeric characters replaced by underscores, followed by |
24.3.5. Further Reading
These are good sources to start learning about various kinds of encoding systems.
- CJKV Information Processing: Chinese, Japanese, Korean & Vietnamese Computing
-
Contains detailed explanations of
EUC_JP,EUC_CN,EUC_KR,EUC_TW. - https://www.unicode.org/
-
The web site of the Unicode Consortium.
- RFC 3629
-
UTF-8 (8-bit UCS/Unicode Transformation Format) is defined here.