Стандартная ошибка точечной оценки –
среднее квадратическое отклонение от
точечной оценки.
S=σ(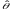
).
![]()
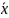
=1/n*Σxi.
![]()
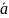
=
,
D(
)=1/n2*ΣD(xi)
= 
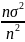
=σ2/n.
M(xi)=a;
D(xi)=
σ2;
![]()

2=1/n-1*Σ(xi—
)2;
![]()

(
)=1/n(n-1)*
Σ(xi—
)2
S=

32. Доверительные интервалы.
Оценка
неизвестного параметра, которая задается
двумя числами (концами интервала),
называется интервальной.
Пусть по выборке
получена точечная оценка θˆ неизвестного
параметра .
Это оценка
чем точнее, чем меньше |-
|.
Пусть |
—
|<
,
>0.
Методы математической
статистики не позволяют на наверняка
утверждать, что выполняется это
неравенство. Можно лишь говорить о
вероятности его выполнения.
P(|
—
|<
)=
-доверительная
вероятность
или надежность.
В качестве
выбирается
число близкре к 1: 0,95; 0,99;0,995 (выбирается
исследователем самостоятельно).
Раскрыв знак
модуля получим определение доверительного
интервала
P(
—
<
<
+
)=
Доверительным
называется интервал (
—
;
+
),
который покрывает неизвестный параметр
с заданной надежностью
.
При этом
— называется точность оценки.
Замечание:
Неверно говорить,
что
попадает в интервал. Задача состоит в
том, чтобы построить такой интервал,
который бы заключал в себе
.
Доверительные
интервалы строятся (нужно знать закон
распределения оценки



.
Затем поступают
следующим образом:
1. вычисляется
точечная оценка
2. выбирается
надежность
3. вычисляется
точность оценки
33. Распределение х2 Стьюдента и Фишера.
1.Распределение
(хи-квадрат)
пусть

независимы и имеют стандартное нормальное
распределение. Тогда случайная величина

называется распределенной по
закону
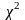
с n
степенями свободы.


M0
M


При
n
распределение

медленно стремится к нормальному.
2.Распределение
Стьюдента
Пусть

независимы и 1
стандартное нормальное распределение,
а 2—
распределение 2
с k
степенями свободы. Тогда случайная
величина

называется распределенной по закону
Стьюдента
с k
степенями свободы.
.
При
k
распределение
Стьюдента быстро стремится к нормальному.
МТ=0
DT=
3.
Распределение Фишера.
Пусть
независимы и имеют распределение
с k1
и k2
числом степеней свободы соответственно.
Тогда
случайная величина

называется распределением по закону
Фишера с k1
и k2
числом степеней свободы.
Замечание.
1)Табличные значения cлучайной
величины Фишера всегда больше 1.
.
34. Доверительные интервалы для оценки математического ожидания при известном .
Пусть
изучаемый признак Х имеет нормальное
распределение. Построим по выборке
(x1,
x2,…,xn)
доверительный интервал для оценки мат.
Ожидания а при заданной надежности
Несмещенной
и состоятельной оценкой мат ожидания
явл выборочное среднее значение

в
Значение
параметра
известно. В результате доверительный
интервал будет иметь вид

Здесь
n-объем выборки. Точность оценки

Где
значение числа t находится с пом.
Таблиц функции Лапласа на основании
выбранной надежности из уровнения

=
,
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
18.02.20166.32 Mб16Uchebnik_Kniga1.pdf
- #
18.02.20167.59 Mб6Uchebnik_Kniga2.pdf
- #
18.02.20166.16 Mб8Uchebnik_Kniga3.pdf
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартная ошибка оценки служит для того, чтобы выяснить, как линия регрессии соответствует набору данных. Если у вас есть набор данных, полученных в результате измерения, эксперимента, опроса или из другого источника, создайте линию регрессии, чтобы оценить дополнительные данные. Стандартная ошибка оценки характеризует, насколько верна линия регрессии.
-

1
Создайте таблицу с данными. Таблица должна состоять из пяти столбцов, и призвана облегчить вашу работу с данными. Чтобы вычислить стандартную ошибку оценки, понадобятся пять величин. Поэтому разделите таблицу на пять столбцов. Обозначьте эти столбцы так:[1]
-
2
Введите данные в таблицу. Когда вы проведете эксперимент или опрос, вы получите пары данных — независимую переменную обозначим как
, а зависимую или конечную переменную как . Введите эти значения в первые два столбца таблицы.
- Не перепутайте данные. Помните, что определенному значению независимой переменной должно соответствовать конкретное значение зависимой переменной.
- Например, рассмотрим следующий набор пар данных:
- (1,2)
- (2,4)
- (3,5)
- (4,4)
- (5,5)
-
3
Вычислите линию регрессии. Сделайте это на основе представленных данных. Эта линия также называется линией наилучшего соответствия или линией наименьших квадратов. Расчет можно сделать вручную, но это довольно утомительно. Поэтому рекомендуем воспользоваться графическим калькулятором или онлайн-сервисом, которые быстро вычислят линию регрессии по вашим данным.[2]
- В этой статье предполагается, что уравнение линии регрессии дано (известно).
- В нашем примере линия регрессии описывается уравнением .
-
4
Вычислите прогнозируемые значения по линии регрессии. С помощью уравнения линии регрессии можно вычислить прогнозируемые значения «y» для значений «x», которые есть и которых нет в наборе данных.
Реклама







-
1
Вычислите ошибку каждого прогнозируемого значения. В четвертом столбце таблицы запишите ошибку каждого прогнозируемого значения. В частности, вычтите прогнозируемое значение (
) из фактического (наблюдаемого) значения ().[3]
- В нашем примере вычисления будут выглядеть так:
-
2
Вычислите квадраты ошибок. Возведите в квадрат каждое значение четвертого столбца, а результаты запишите в последнем (пятом) столбце таблицы.
- В нашем примере вычисления будут выглядеть так:
-
3
Найдите сумму квадратов ошибок. Она пригодится для вычисления стандартного отклонения, дисперсии и других величин. Чтобы найти сумму квадратов ошибок, сложите все значения пятого столбца. [4]
- В нашем примере вычисления будут выглядеть так:
- В нашем примере вычисления будут выглядеть так:
-
4
Завершите расчеты. Стандартная ошибка оценки — это квадратный корень из среднего значения суммы квадратов ошибок. Обычно ошибка оценки обозначается греческой буквой
. Поэтому сначала разделите сумму квадратов ошибок на число пар данных. А потом из полученного значения извлеките квадратный корень.[5]
- Если рассматриваемые данные представляют всю совокупность, среднее значение находится так: сумму нужно разделить на N (количество пар данных). Если же рассматриваемые данные представляют некоторую выборку, вместо N подставьте N-2.
- В нашем примере, скорее всего, имеет место выборка, потому что мы рассматриваем всего 5 пар данных. Поэтому стандартную ошибку оценки вычислите следующим образом:
-
5
Интерпретируйте полученный результат. Стандартная ошибка оценки — это статистический показатель, которые оценивает, насколько близко измеренные данные лежат к линии регрессии. Ошибка оценка «0» означает, что каждая точка лежит непосредственно на линии. Чем выше ошибка оценки, тем дальше от линии регрессии лежат точки.[6]
- В нашем примере выборка достаточно маленькая, поэтому стандартная оценка ошибки 0,894 является довольно низкой и характеризует близко расположенные данные.
Реклама







Об этой статье
Эту страницу просматривали 4342 раза.
Была ли эта статья полезной?
Что такое стандартная ошибка оценки? (Определение и пример)
17 авг. 2022 г.
читать 3 мин
Стандартная ошибка оценки — это способ измерения точности прогнозов, сделанных регрессионной моделью.
Часто обозначаемый σ est , он рассчитывается как:
σ est = √ Σ(y – ŷ) 2 /n
куда:
- y: наблюдаемое значение
- ŷ: Прогнозируемое значение
- n: общее количество наблюдений
Стандартная ошибка оценки дает нам представление о том, насколько хорошо регрессионная модель соответствует набору данных. Особенно:
- Чем меньше значение, тем лучше соответствие.
- Чем больше значение, тем хуже соответствие.
Для регрессионной модели с небольшой стандартной ошибкой оценки точки данных будут плотно сгруппированы вокруг предполагаемой линии регрессии:
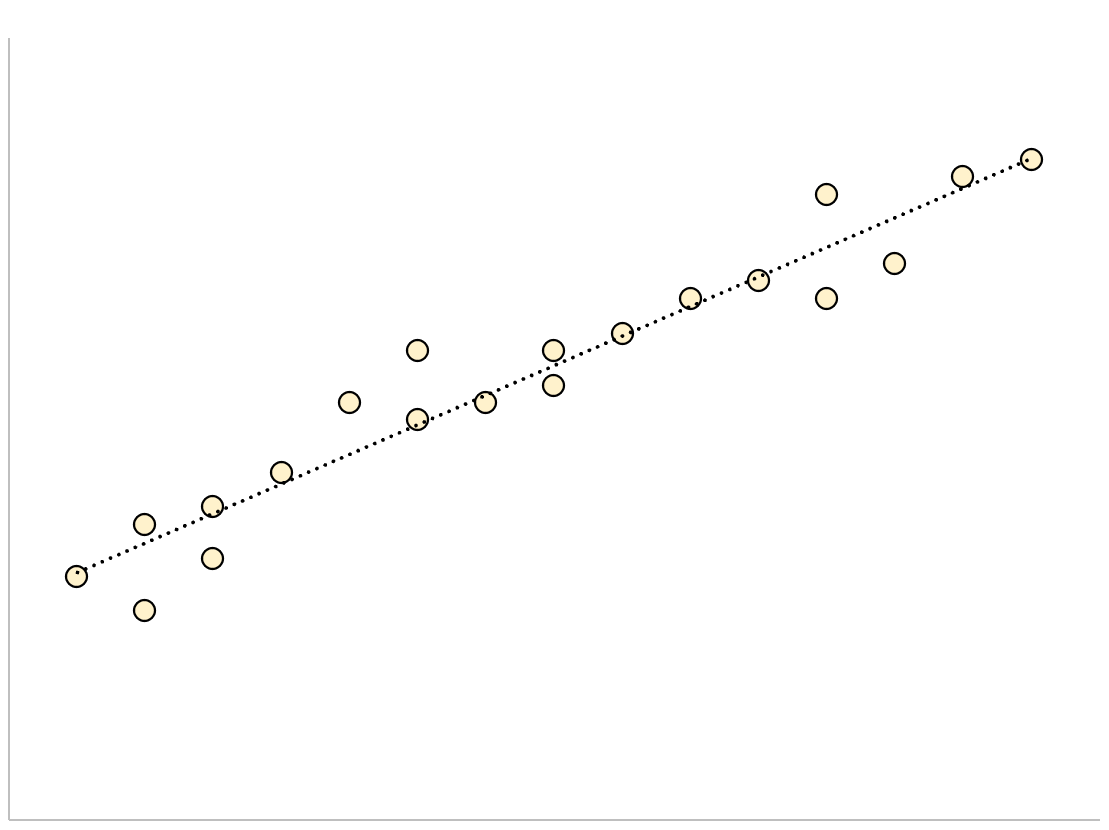
И наоборот, для регрессионной модели с большой стандартной ошибкой оценки точки данных будут более свободно разбросаны по линии регрессии:
В следующем примере показано, как рассчитать и интерпретировать стандартную ошибку оценки для регрессионной модели в Excel.
Пример: стандартная ошибка оценки в Excel
Используйте следующие шаги, чтобы вычислить стандартную ошибку оценки для регрессионной модели в Excel.
Шаг 1: введите данные
Сначала введите значения для набора данных:

Шаг 2: выполните линейную регрессию
Затем щелкните вкладку « Данные » на верхней ленте. Затем выберите параметр « Анализ данных» в группе « Анализ ».

Если вы не видите эту опцию, вам нужно сначала загрузить пакет инструментов анализа .
В появившемся новом окне нажмите « Регрессия », а затем нажмите « ОК ».

В появившемся новом окне заполните следующую информацию:

Как только вы нажмете OK , появится вывод регрессии:

Мы можем использовать коэффициенты из таблицы регрессии для построения оценочного уравнения регрессии:
ŷ = 13,367 + 1,693 (х)
И мы видим, что стандартная ошибка оценки для этой регрессионной модели оказывается равной 6,006.Проще говоря, это говорит нам о том, что средняя точка данных отклоняется от линии регрессии на 6,006 единицы.
Мы можем использовать оценочное уравнение регрессии и стандартную ошибку оценки, чтобы построить 95% доверительный интервал для прогнозируемого значения определенной точки данных.
Например, предположим, что x равно 10. Используя оценочное уравнение регрессии, мы можем предсказать, что y будет равно:
ŷ = 13,367 + 1,693 * (10) = 30,297
И мы можем получить 95% доверительный интервал для этой оценки, используя следующую формулу:
- 95% ДИ = [ŷ – 1,96*σ расч ., ŷ + 1,96*σ расч .]
Для нашего примера доверительный интервал 95% будет рассчитываться как:
- 95% ДИ = [ŷ – 1,96*σ расч ., ŷ + 1,96*σ расч .]
- 95% ДИ = [30,297 – 1,96*6,006, 30,297 + 1,96*6,006]
- 95% ДИ = [18,525, 42,069]
Дополнительные ресурсы
Как выполнить простую линейную регрессию в Excel
Как выполнить множественную линейную регрессию в Excel
Как создать остаточный график в Excel
Когда нам нужно получить одно число в качестве оценки параметра совокупности, мы используем точечную оценку. Тем не менее, из-за ошибки выборки, точечная оценка не будет в точности равняться параметру совокупности при любом размере данной выборки.
Часто, вместо точечной оценки, более полезным подходом будет найти диапазон значений, в рамках которого, как мы ожидаем, может находится значение искомого параметра с заданным уровнем вероятности.
Этот подход называется интервальной оценкой параметра (англ. ‘interval estimate of parameter’), а доверительный интервал выполняет роль этого диапазона значений.
Определение доверительного интервала.
Доверительный интервал (англ. ‘confidence interval’) представляет собой диапазон, для которого можно утверждать, с заданной вероятностью (1 — alpha ), называемой степенью доверия (или степенью уверенности, англ. ‘degree of confidence’), что он будет содержать оцениваемый параметр.
Этот интервал часто упоминается как (100 (1 — alpha)% ) доверительный интервал для параметра.
Конечные значения доверительного интервала называются нижним и верхним доверительными пределами (или доверительными границами или предельной погрешностью, англ. ‘lower/upper confidence limits’).
В этом чтении, мы имеем дело только с двусторонними доверительными интервалами — доверительные интервалами, для которых мы вычисляем и нижние и верхние пределы.
Кроме того, можно определить два типа односторонних доверительных интервалов для параметра совокупности.
Нижний односторонний доверительный интервал устанавливает только нижний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности равен или превышает нижний предел.
Верхний односторонний доверительный интервал устанавливает только верхний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности меньше или равен верхнему пределу.
Инвестиционные аналитики редко используют односторонние доверительные интервалы.
Доверительные интервалы часто дают либо вероятностную интерпретацию, либо практическую интерпретацию.
При вероятностной интерпретации, мы интерпретируем 95%-ный доверительный интервал для среднего значения совокупности следующим образом.
При повторяющейся выборке, 95% таких доверительных интервалов будут, в конечном счете, включать в себя среднее значение совокупности.
Например, предположим, что мы делаем выборку из совокупности 1000 раз, и на основании каждой выборки мы построим 95%-ный доверительный интервал, используя вычисленное выборочное среднее.
Из-за случайного характера выборок, эти доверительные интервалы отличаются друг от друга, но мы ожидаем, что 95% (или 950) этих интервалов включают неизвестное значение среднего по совокупности.
На практике мы обычно не делаем такие повторяющиеся выборки. Поэтому в практической интерпретации, мы утверждаем, что мы 95% уверены в том, что один 95%-ный доверительный интервал содержит среднее по совокупности.
Мы вправе сделать это заявление, потому что мы знаем, что 95% всех возможных доверительных интервалов, построенных аналогичным образом, будут содержать среднее по совокупности.
Доверительные интервалы, которые мы обсудим в этом чтении, имеют структуры, подобные описанной ниже базовой структуре.
Построение доверительных интервалов.
Доверительный интервал (100 (1 — alpha)% ) для параметра имеет следующую структуру.
Точечная оценка (pm) Фактор надежности (times) Стандартная ошибка
где
- Точечная оценка = точечная оценка параметра (значение выборочной статистики).
- Фактор надежности (англ. ‘reliability factor’) = коэффициент, основанный на предполагаемом распределении точечной оценки и степени доверия ((1 — alpha)) для доверительного интервала.
- Стандартная ошибка = стандартная ошибка выборочной статистики, значение которой получено с помощью точечной оценки.
Величину (Фактор надежности) (times) (Cтандартная ошибка) иногда называют точностью оценки (англ. ‘precision of estimator’). Большие значения этой величины подразумевают более низкую точность оценки параметра совокупности.
Самый базовый доверительный интервал для среднего значения по совокупности появляется тогда, когда мы делаем выборку из нормального распределения с известной дисперсией. Фактор надежности в данном случае на основан стандартном нормальном распределении, которое имеет среднее значение, равное 0 и дисперсию 1.
Стандартная нормальная случайная величина обычно обозначается как (Z). Обозначение (z_alpha ) обозначает такую точку стандартного нормального распределения, в которой (alpha) вероятности остается в правом хвосте.
Например, 0.05 или 5% возможных значений стандартной нормальной случайной величины больше, чем ( z_{0.05} = 1.65 ).
Предположим, что мы хотим построить 95%-ный доверительный интервал для среднего по совокупности, и для этой цели, мы сделали выборку размером 100 из нормально распределенной совокупности с известной дисперсией (sigma^2) = 400 (значит, (sigma) = 20).
Мы рассчитываем выборочное среднее как ( overline X = 25 ). Наша точечная оценка среднего по совокупности, таким образом, 25.
Если мы перемещаем 1.96 стандартных отклонений выше среднего значения нормального распределения, то 0.025 или 2.5% вероятности остается в правом хвосте. В силу симметрии нормального распределения, если мы перемещаем 1.96 стандартных отклонений ниже среднего, то 0.025 или 2.5% вероятности остается в левом хвосте.
В общей сложности, 0.05 или 5% вероятности лежит в двух хвостах и 0.95 или 95% вероятности лежит между ними.
Таким образом, ( z_{0.025} = 1.96) является фактором надежности для этого 95%-ного доверительного интервала. Обратите внимание на связь (100 (1 — alpha)% ) для доверительного интервала и (z_{alpha/2}) для фактора надежности.
Стандартная ошибка среднего значения выборки, заданная Формулой 1, равна:
( sigma_{overline X} = 20 Big / sqrt{100} = 2 )
Доверительный интервал, таким образом, имеет нижний предел:
( overline X — 1.96 sigma_{overline X} ) = 25 — 1.96(2) = 25 — 3.92 = 21.08.
Верхний предел доверительного интервала равен:
( overline X + 1.96sigma_{overline X} ) = 25 + 1.96(2) = 25 + 3.92 = 28.92
95%-ный доверительный интервал для среднего по совокупности охватывает значения от 21.08 до 28.92.
Доверительные интервалы для среднего по совокупности (нормально распределенная совокупность с известной дисперсией).
Доверительный интервал (100 (1 — alpha)% ) для среднего по совокупности ( mu ), когда мы делаем выборку из нормального распределения с известной дисперсией ( sigma^2 ) задается формулой:
( Large dst overline X pm z_{alpha /2}{sigma over sqrt n} ) (Формула 4)
Факторы надежности для наиболее часто используемых доверительных интервалов приведены ниже.
Факторы надежности для доверительных интервалов на основе стандартного нормального распределения.
Мы используем следующие факторы надежности при построении доверительных интервалов на основе стандартного нормального распределения:
- 90%-ные доверительные интервалы: используется (z_{0.05}) = 1.65
- 95%-ные доверительные интервалы: используется (z_{0.025}) = 1.96
- 99%-ные доверительные интервалы: используется (z_{0.005}) = 2.58
На практике, большинство финансовых аналитиков используют значения для (z_{0.05}) и (z_{0.005}), округленные до двух знаков после запятой.
Для справки, более точными значениями для (z_{0.05}) и (z_{0.005}) являются 1.645 и 2.575, соответственно.
Для быстрого расчета 95%-ного доверительного интервала (z_{0.025}) иногда округляют 1.96 до 2.
Эти факторы надежности подчеркивают важный факт о всех доверительных интервалах. По мере того, как мы повышаем степень доверия, доверительный интервал становится все шире и дает нам менее точную информацию о величине, которую мы хотим оценить.
«Чем уверенней мы хотим быть, тем меньше мы должны быть уверены»
см. Freund и Williams (1977), стр. 266.
На практике, допущение о том, что выборочное распределение выборочного среднего, по меньшей мере, приблизительно нормальное, часто является обоснованным, либо потому, что исходное распределение приблизительно нормальное, либо потому что мы имеем большую выборку и поэтому к ней применима центральная предельная теорема.
Однако, на практике, мы редко знаем дисперсию совокупности. Когда дисперсия генеральной совокупности неизвестна, но выборочное среднее, по меньшей мере, приблизительно нормально распределено, у нас есть два приемлемых пути чтобы вычислить доверительные интервалы для среднего значения совокупности.
Вскоре мы обсудим более консервативный подход, который основан на t-распределении Стьюдента (t-распределение, для краткости).
Распределение статистики (t) называется t-распределением Стьюдента (англ. «Student’s t-distribution») из-за псевдонима «Студент» (Student), использованного британским математиком Уильямом Сили Госсеттом, который опубликовал свою работу в 1908 году.
В финансовой литературе, это наиболее часто используемый подход для статистической оценки и проверки статистических гипотез, касающихся среднего значения, когда дисперсия генеральной совокупности не известна, как для малого, так и для большого размер выборки.
Второй подход к доверительным интервалам для среднего по совокупности, основанного на стандартном нормальном распределении, — это z-альтернатива (англ. ‘z-alternative’). Он может быть использован только тогда, когда размер выборки является большим (в общем случае, размер выборки 30 или больше, можно считать большим).
В отличии от доверительного интервала, приведенного в Формуле 4, этот доверительный интервал использует стандартное отклонение выборки (s) при вычислении стандартной ошибки выборочного среднего (по Формуле 2).
Доверительные интервалы для среднего по совокупности — z-альтернатива (большая выборка, дисперсия совокупности неизвестна).
Доверительный интервал (100 (1 — alpha)% ) для среднего по совокупности ( mu ) при выборке из любого распределения с неизвестной дисперсией, когда размер выборки большой, задается формулой:
( Large dst overline X pm z_{alpha /2}{s over sqrt n} ) (Формула 5)
Поскольку этот тип доверительного интервала применяется довольно часто, мы проиллюстрируем его вычисление в Примере 4.
Пример (4) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием z-статистики.
Предположим, что инвестиционный аналитик делает случайную выборку акций взаимных фондов США и рассчитывает средний коэффициент Шарпа.
[см. также: CFA — Коэффициент Шарпа]
Размер выборки равен 100, а средний коэффициент Шарпа составляет 0.45. Выборка имеет стандартное отклонение 0.30.
Рассчитайте и интерпретируйте 90-процентный доверительный интервал для среднего по совокупности всех акций взаимных фондов США с использованием фактора надежности на основе стандартного нормального распределения.
Фактор надежности для 90-процентного доверительного интервала, как указано ранее, составляет ( z_{0.05} = 1.65 ).
Доверительный интервал будет равен:
( begin{aligned} & overline X pm z_{0.05}{s over sqrt n } \ &= 0.45 pm 1.65{0.30 over sqrt {100}} \ &= 0.45 pm 1.65(0.03) = 0.45 pm 0.0495 end{aligned} )
Доверительный интервал охватывает значения 0.4005 до 0.4995, или от 0.40 до 0.50, с округлением до двух знаков после запятой. Аналитик может сказать с 90-процентной уверенностью, что интервал включает среднее по совокупности.
В этом примере аналитик не делает никаких конкретных предположений о распределении вероятностей, характеризующем совокупность. Скорее всего, аналитик опирается на центральную предельную теорему для получения приближенного нормального распределения для выборочного среднего.
Как показывает Пример 4, даже если мы не уверены в характере распределения совокупности, мы все еще можем построить доверительные интервалы для среднего по совокупности, если размер выборки достаточно большой, поскольку можем применить центральную предельную теорему.
Концепция степеней свободы.
Обратимся теперь к консервативной альтернативе и используем t-распределение Стьюдента, чтобы построить доверительные интервалы для среднего по совокупности, когда дисперсия генеральной совокупности не известна.
Для доверительных интервалов на основе выборок из нормально распределенных совокупностей с неизвестной дисперсией, теоретически правильный фактор надежности основан на t-распределении. Использование фактора надежности, основанного на t-распределении, имеет важное значение для выборок небольшого размера.
Применение фактора надежности (t) уместно, когда дисперсия генеральной совокупности неизвестна, даже если у нас есть большая выборка и мы можем использовать центральную предельную теорему для обоснования использования фактора надежности (z). В этом случае большой выборки, t-распределение обеспечивает более консервативные (широкие) доверительные интервалы.
t-распределение является симметричным распределением вероятностей и определяется одним параметром, известным как степени свободы (DF, от англ. ‘degrees of freedom’). Каждое значение для числа степеней свободы определяет одно распределение в этом семействе распределений.
Далее мы сравним t-распределения со стандартным нормальным распределением, но сначала мы должны понять концепцию степеней свободы. Мы можем сделать это путем изучения расчета выборочной дисперсии.
Формула 3 дает несмещенную оценку выборочной дисперсии, которую мы используем. Выражение в знаменателе, ( n — 1 ), означающее размер выборки минус 1, это число степеней свободы при расчете дисперсии совокупности с использованием Формулы 3.
Мы также используем ( n — 1 ) как число степеней свободы для определения факторов надежности на основе распределения Стьюдента. Термин «степени свободы» используются, так как мы предполагаем, что в случайной выборке наблюдения отобраны независимо друг от друга. Числитель выборочной дисперсии, однако, использует выборочное среднее.
Каким образом использование выборочного среднего влияет на количество наблюдений, отобранных независимо, для формулы выборочной дисперсии?
При выборке размера 10 и среднем значении в 10%, к примеру, мы можем свободно отобрать только 9 наблюдений. Независимо от отобранных 9 наблюдений, мы всегда можем найти значение для 10-го наблюдения, которое дает среднее значение, равное 10%. С точки зрения формулы выборочной дисперсии, здесь есть 9 степеней свободы.
Учитывая, что мы должны сначала вычислить выборочное среднее от общего числа (n) независимых наблюдений, только (n — 1) наблюдений могут быть отобраны независимо друг от друга для расчета выборочной дисперсии.
Концепция степеней свободы часто применяется в финансовой статистике, и вы встретите ее в последующих чтениях.
t-распределение Стьюдента.
Предположим, что мы делаем выборку из нормального распределения.
Коэффициент (z = (overline X — mu) Big / (sigma big / sqrt n) ) нормально распределен со средним значением 0 и стандартным отклонением 1, однако, коэффициент (t = (overline X — mu) Big / (s big / sqrt n) ) следует t-распределению со средним 0 и (n — 1) степеней свободы.
Коэффициент (t) не является нормальным, поскольку представляет собой отношение двух случайных величин, выборочного среднего и стандартного отклонения выборки.
Определение стандартной нормальной случайной величины включает в себя только одну случайную величину, выборочное среднее. По мере увеличения степеней свободы, однако, t-распределение приближается к стандартному нормальному распределению.
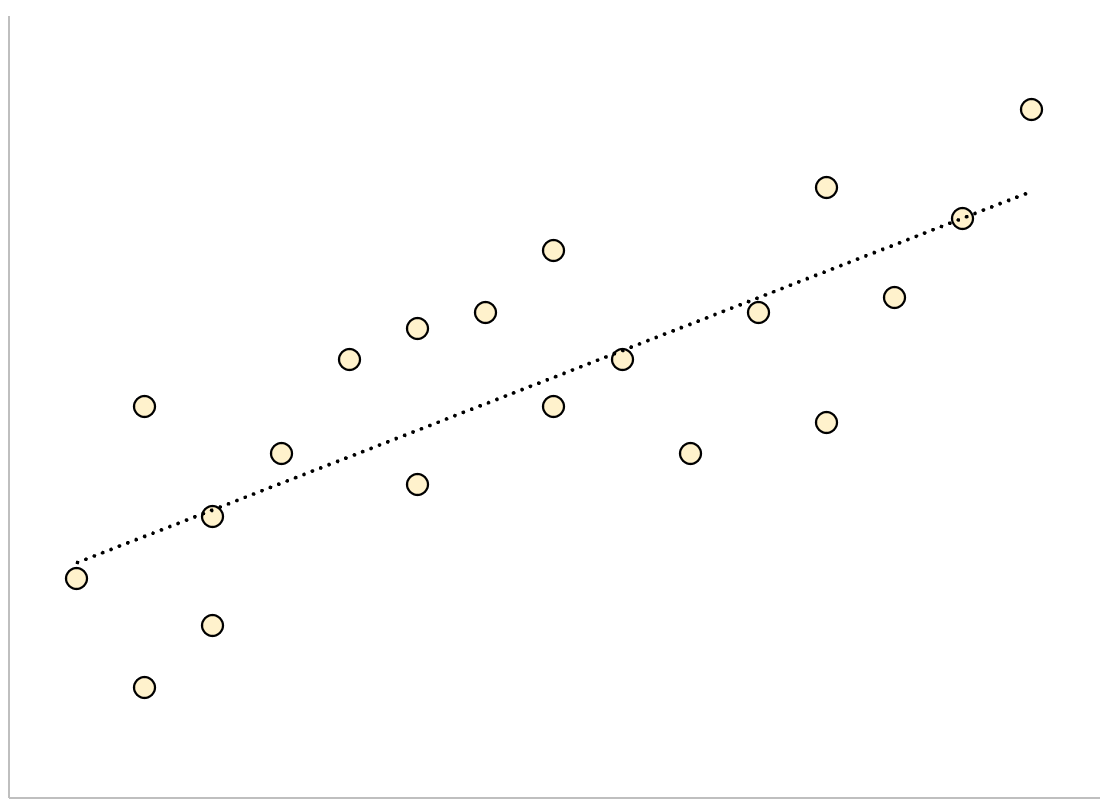
На Рисунке 1 показано стандартное нормальное распределение и два t-распределения, одно с DF = 2 и одно с DF = 8.
 Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Из трех распределений, показанных на Рисунке 1, стандартное нормальное распределение имеет хвосты, которые стремятся к нулю быстрее, чем хвосты двух t-распределений. t-распределение симметрично распределено вокруг среднего нулевого значения, так же как и нормальное распределение.
По мере увеличения степеней свободы, t-распределение приближается к стандартному нормальному распределению. t-распределение с DF = 8 ближе к стандартному нормальному, чем t-распределение с DF = 2.
Помимо области плюс и минус четырех стандартных отклонений от среднего значения, остальная область под стандартным нормальным распределением, как представляется, близка к 0. Однако, оба t-распределения содержать некоторую площадь под каждой кривой за пределом четырех стандартных отклонений.
t-распределения имеют более толстые хвосты, но хвосты t-распределения Стьюдента с DF = 8 сильнее напоминают хвосты нормального распределения. По мере увеличения степеней свободы, хвосты распределения Стьюдента становятся менее толстыми.
Для часто используемых значений распределения Стьюдента составлены таблицы. Например, для каждой степени свободы (t_{0.10}), (t_{0.05}), (t_{0.025}), (t_{0.01}) и (t_{0.005}) значения будут такими, что соответственно, 0.10, 0.05, 0.025, 0.01 и 0.005 вероятности останется в правом хвосте для заданного числа степеней свободы.
Значения (t_{0.10}), (t_{0.05}), (t_{0.025}), (t_{0.01}) и (t_{0.005}) также называют односторонними критическими значениями t на значимых уровнях 0.10, 0.05, 0.025, 0.01 и 0.005, для указанного числа степеней свободы.
Например,
для DF = 30,
(t_{0.10}) = 1.310,
(t_{0.05}) = 1.697,
(t_{0.025}) = 2.042,
(t_{0.01}) = 2.457,
(t_{0.005}) = 2.750.
Приведем форму доверительных интервалов для среднего по совокупности, используя распределение Стьюдента.
Доверительные интервалы для среднего по совокупности (дисперсия совокупности неизвестна) — t-распределение.
Если мы делаем выборку из генеральной совокупности с неизвестной дисперсией и соблюдается одно из перечисленных ниже условий:
- выборка является большой, или
- выборка небольшая, но совокупность имеет нормальное распределение, или приблизительно нормально распределена,
то доверительный интервал (100 (1 — alpha)% ) для среднего совокупности ( mu ) задается формулой:
( Large dst overline X pm t_{alpha /2}{s over sqrt n} ) (Формула 6)
где число степеней свободы для ( t_{alpha /2}) равно ( n-1 ), а ( n ) — это размер выборки.
Пример 5 использует данные Примера 4, но применяет t-статистику, а не z-статистику, чтобы рассчитать доверительный интервал для среднего значения совокупности коэффициентов Шарпа.
Пример (5) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием t-статистики.
Как и в Примере 4, инвестиционный аналитик стремится вычислить 90-процентный доверительный интервал для среднего по совокупности коэффициентов Шарпа, основанных на случайной выборке из 100 взаимных фондов США.
Выборочное среднее коэффициентов Шарпа составляет 0.45, а выборочное стандартное отклонение — 0.30.
Теперь, признав, что дисперсия генеральной совокупности распределения коэффициентов Шарпа неизвестна, аналитик решает вычислить доверительный интервал, используя теоретически правильную t-статистику.
Поскольку размер выборки равен 100, DF = 99. Используя таблицу степеней свободы, мы находим, что (t_{0.05}) = 1.66.
Этот фактор надежности немного больше, чем фактор надежности (z_{0.05}) = 1.65, который был использован в Примере 4.
Доверительный интервал будет:
( begin{aligned} & overline X pm t_{0.05}{s over sqrt n } \ &= 0.45 pm 1.66{0.30 over sqrt {100}} \ &= 0.45 pm 1.66(0.03) = 0.45 pm 0.0498 end{aligned} )
Доверительный интервал охватывает значения 0.4002 до 0.4998, или 0.40 до 0.50, с двумя знаками после запятой. При округлении до двух знаков после запятой, доверительный интервал не изменился по сравнению с Примером 4.
В Таблице 3 приведены различные факторы надежности, которые мы использовали.
|
Выборка из: |
Статистика для выборки малого размера |
Статистика для выборки большого размера |
|---|---|---|
|
Нормальное распределение с известной дисперсией |
(z) |
(z) |
|
Нормальное распределение с неизвестной дисперсией |
(t) |
(t)* |
|
Ненормальное распределение с известной дисперсией |
недоступно |
(z) |
|
Ненормальное распределение с неизвестной дисперсией |
недоступно |
(t)* |
* Использование (z) также приемлемо.
Надежна ли ваша стандартная ошибка?
Перевод
Ссылка на автора
Практическое руководство по выбору правильной спецификации
Управляющее резюме
- Проблема:Стандартные ошибки по умолчанию (SE), сообщаемые Stata, R и Python, являются правильными только при очень ограниченных обстоятельствах. В частности, эти программы предполагают, что ваша ошибка регрессии распределена независимо и одинаково. На самом деле это не так, что приводит к серьезным ошибкам типа 1 и типа 2 в тестах гипотез.
- Лечение 1:если вы используете OLS, вы должны кластеризовать SE по двум параметрам: индивидуально по годам.
- Лечение 2:если вы используете FE (фиксированный эффект), вы должны кластеризовать SE только на 1 измерение: индивидуальное.
- коды: Вот это ссылка на коды Stata, R и SAS для реализации кластеризации SE.
Если вам интересно об этой проблеме, пожалуйста, продолжайте читать. В противном случае, увидимся в следующий раз 
План на день
В этом посте я собрал бы 69-страничный документ о здравой стандартной ошибке в чит-лист. Эта бумага Опубликованный профессором Митчеллом Петерсеном в 2009 году, на сегодняшний день собрал более 7 879 ссылок. Это остается библией для выбора правильной здравой стандартной ошибки.
Проблема
Обычная практика
В любом классе Stats 101 ваш профессор мог бы научить вас набирать «reg Y X» в Stata или R:

Вы приступаете к проверке своей гипотезы с указанными точечными оценками и стандартной ошибкой. Но в 99% случаев это было бы неправильно.
Ловушка
Чтобы OLS давал объективные и непротиворечивые оценки, нам нужно, чтобы термин ошибки epsilon был распределен независимо и одинаково:
Независимый означает, что никакие серийные или взаимные корреляции не допускаются:
- Последовательные корреляции:для одного и того же человека остатки в разные периоды времени коррелируют;
- Кросс-корреляция:различные индивидуальные остатки коррелируются внутри и / или между периодами.
Одинаковый означает, что все остатки имеют одну и ту же дисперсию (например, гомоскедастичность).
Визуализация проблемы
Давайте визуализируем i.i.d. предположение в дисперсионно-ковариационной матрице.
- Нет последовательной корреляции:все недиагональные записи в красных пузырьках должны быть 0;
- Нет взаимной корреляции:все диагональные записи должны быть одинаковыми — все записи в зеленых прямоугольниках должны быть 0;
- гомоскедастичность:диагональные записи должны быть одинаковыми константами.

Что не так, если вы используете SE по умолчанию без I.I.D. Ошибки?
Вывод выражения SE:

Стандартная ошибка по умолчанию — последняя строка в (3). Но чтобы получить от 1-й до последней строки, нам нужно сделать дополнительные предположения:
- Нам нужно предположение о независимости, чтобы переместить нас с 1-й строки на 2-ю в (3). Визуально все записи в зеленых прямоугольниках И все недиагональные записи в красных пузырьках должны быть 0.
- Нам нужно одинаково распределенное предположение, чтобы переместить нас со 2-й строки на 3-ю. Визуально все диагональные элементы должны быть точно такими же.
По умолчанию SE прав в ОЧЕНЬ ограниченных обстоятельствах!
Цена неправильного
Мы не знаем, будет ли заявленная SE переоценена или недооценена истинная SE. Таким образом, мы можем получить:
- Статистически значимый результат, когда эффекта нет в реальности. В результате команде разработчиков программного обеспечения и продукта может потребоваться несколько часов работы над каким-либо прототипом, который никак не повлияет на итоговую прибыль компании.
- Статистически незначимый результат, когда в действительности наблюдается значительный эффект. Это могло быть для тебя перерывом. Упущенная возможность Очень плохо

На самом деле ложный позитив более вероятен.Там нет недостатка в новичках машинного обучения студентов, заявляющих, что они нашли какой-то шаблон / сигнал, чтобы побить рынок. Однако после развертывания их модели работают катастрофически. Частично причина в том, что они никогда не думали о последовательной или взаимной корреляции остатков.
Когда это происходит, стандартная ошибка по умолчанию может быть в 11 раз меньше, чем истинная стандартная ошибка, что приводит к серьезной переоценке статистической значимости их сигнала.
Надежная стандартная ошибка на помощь!
Правильно заданная надежная стандартная ошибка избавит от смещения или, по крайней мере, улучшит его. Вооружившись серьезной стандартной ошибкой, вы можете безопасно перейти к этапу вывода.
Есть много надежных стандартных ошибок. Выбор неправильного средства может усугубить проблему!
Какую робастную стандартную ошибку я должен использовать?
Это зависит от дисперсионно-ковариантной структуры. Спросите себя, страдает ли ваш остаток от взаимной корреляции, последовательной корреляции или от того и другого? Напомним, что:
- Кросс-корреляция:в течение одного и того же периода времени разные индивидуальные остатки могут быть коррелированы;
- Последовательная корреляция:для одного и того же лица остатки за разные периоды времени могут быть коррелированы
Случай 1: Термин ошибки имеет отдельный конкретный компонент
Предположим, что это истинное состояние мира:



При условии независимости от отдельных лиц, правильная стандартная ошибка будет:

Сравните это с (3), у нас есть дополнительный член, который обведен красным. Превышение или недооценка сообщаемой стандартной ошибки OLS истинной стандартной ошибки зависит от знака коэффициентов корреляции, который затем увеличивается на число периодов времени T.

Где практическое руководство?
Основываясь на большем количестве теории и результатов моделирования, Петерсен показывает, что:
Вы не должны использовать:
- Стандартные ошибки Fama-MacBeth:он предназначен для работы с последовательной корреляцией, а не с перекрестной корреляцией между отдельными фирмами.
- Стандартные ошибки Ньюи-Уэста:он предназначен для учета последовательной корреляции неизвестной формы в остатках одного временного ряда.
Вы должны использовать:
- Стандартные кластерные ошибки:в частности, вы должны объединить вашу стандартную ошибку по фирмам. Обратитесь к концу поста для кодов.
Случай 2: Термин ошибки имеет компонент, зависящий от времени
Предположим, что это истинное состояние мира:

Правильная стандартная ошибка по существу такая же, как (7), если вы поменяете N и T.
Вы должны использовать:
- Стандартные ошибки Fama-MacBeth:так как это то, что он создан для Обратитесь к концу поста для кода Stata.
Случай 3: Термин «ошибка» имеет как твердое, так и временное влияние
Предположим, что это истинное состояние мира:

Вы должны использовать:
- Кластерная стандартная ошибка:кластеризацию следует проводить по двум параметрам — по годам. Обратите внимание, что это не настоящие стандартные ошибки, они просто создают менее предвзятую стандартную ошибку. Смещение становится более выраженным, когда в одном измерении всего несколько кластеров.
коды
Подробные инструкции и тестовые данные Stata, R и SAS от Petersen можно найти Вот, Для моей собственной записи я собираю список кода Stata здесь:
Случай 1: кластеризация по 1 измерению
Регресс зависимая_вариантная независимая_вариабельная, надежный кластер (cluster_variable)
Случай 2: Фама-Макбет
tsset firm_identifier time_identifier
fm independent_variable independent_variables, byfm (by_variable)
Случай 3: кластеризация по двум измерениям
cluster2 зависимая_ переменная independent_variables, fcluster (cluster_variable_one) tcluster (cluster_variable_two)
Случай 4: фиксированный эффект + кластеризация
xtreg variable_variable independent_variables, надежный кластер (cluster_variable_one)
Наслаждайтесь своим недавно найденным крепким миром!

До следующего раза
From Wikipedia, the free encyclopedia

For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of  observations
observations  is taken from a statistical population with a standard deviation of
is taken from a statistical population with a standard deviation of  . The mean value calculated from the sample,
. The mean value calculated from the sample,  , will have an associated standard error on the mean,
, will have an associated standard error on the mean,  , given by:[1]
, given by:[1]
- .

Practically this tells us that when trying to estimate the value of a population mean, due to the factor  , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
, reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation  instead:
instead:
- .

As this is only an estimator for the true «standard error», it is common to see other notations here such as:
- or alternately .


A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If are independent samples from a population with mean and standard deviation , then we can define the total

which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by
- .

The variance of the mean is then

The standard error is, by definition, the standard deviation of which is simply the square root of the variance:
- .

For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size  is a random variable whose variation adds to the variation of
is a random variable whose variation adds to the variation of  such that,
such that,
- [6]

If has a Poisson distribution, then  with estimator
with estimator  . Hence the estimator of
. Hence the estimator of  becomes
becomes  , leading the following formula for standard error:
, leading the following formula for standard error:

(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how  is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
- Upper 95% limit and
- Lower 95% limit


In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]

which, for large N:

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]

Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
From Wikipedia, the free encyclopedia
For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of observations is taken from a statistical population with a standard deviation of . The mean value calculated from the sample, , will have an associated standard error on the mean, , given by:[1]
- .
Practically this tells us that when trying to estimate the value of a population mean, due to the factor , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation instead:
- .
As this is only an estimator for the true «standard error», it is common to see other notations here such as:
- or alternately .
A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If are independent samples from a population with mean and standard deviation , then we can define the total
which due to the Bienaymé formula, will have variance
where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by
- .
The variance of the mean is then
The standard error is, by definition, the standard deviation of which is simply the square root of the variance:
- .
For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size is a random variable whose variation adds to the variation of such that,
- [6]
If has a Poisson distribution, then with estimator . Hence the estimator of becomes , leading the following formula for standard error:
(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
- Upper 95% limit and
- Lower 95% limit
In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]
which, for large N:
to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]
Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:
where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
The first part of my question, is how do you calculate this specific Standard Error at a specific point estimate?
You don’t specify if you mean simple linear or multiple regression. I’ll assume the general case. Let’s do it at a point $x^* = (1,x_1^*,x_2^*,…,x_p^*)$
$$text{Var}(hat y^*) = text{Var}(x^*hatbeta)= text{Var}(x^*(X^TX)^{-1}X^T y)$$
$$= x^*(X^TX)^{-1}X^T text{Var}(y) X(X^TX)^{-1}x^{*T}$$
$$ = sigma^2 x^*(X^TX)^{-1}X’ I X(X^TX)^{-1}x^{*T} $$
$$= sigma^2 x^*(X^TX)^{-1}x^{*T}$$
If $h^*_{ii} = [x^*(X^TX)^{-1}x^{*T}]_{ii}$ then $text{Var}(hat y_i) = sigma^2 h^*_{ii}$.
Of course, $sigma^2$ is unknown and must be estimated.
The standard error is the square root of that estimated variance up above.
Could one provide a link to a numerical example to facilitate my interpretation of the formula?
I’ll try to dig one up.
My second part to this overall question is: How come the resulting hourglass shape of the resulting Confidence Interval as depicted does not break the linear regression assumption that the variance of residuals remain constant across observations (the heteroskedasticity thing)?
1) it’s a confidence interval for where the mean is, not the variance of the data; it reflects our uncertainty in the parameters as they feed through (via the design, $X$) to the the estimate of the mean. Something assumed true for one thing not being true for a different thing doesn’t violate the assumption for the first thing.
2) Your statement «the linear regression assumption that the variance of residuals remain constant across observations» is factually incorrect (though I know what you’re getting at). That is not an assumption of regression — in fact, outside specific cases, it’s untrue for regression. What is assumed constant is the variance of the unobserved errors. The variance of the residuals is not constant. In fact it ‘bows in’ in opposite fashion to the way the variance above ‘bows out’, both due to the phenomenon of leverage.
Edits in response to followup questions:
Why would the variance bow in?
I’ll do it algebraically and then expand on the explanation in the text above:
begin{eqnarray}
text{Var}(y-hat y) &=& text{Var}(y) + text{Var}(hat y) — 2 text{Cov}(y,hat y)\
&=&sigma^2 I + text{Var}(X hat beta) — 2 text{Cov}(y,X hat beta)\
&=&sigma^2 I + text{Var}(X (X^TX)^{-1}X^T y) — 2 text{Cov}(y,X (X^TX)^{-1}X^T y)\
&=&sigma^2 I + X (X^TX)^{-1}X^Ttext{Var}(y) X (X^TX)^{-1}X^T — 2 text{Cov}(y, y)X (X^TX)^{-1}X^T\
&=&sigma^2 I + X (X^TX)^{-1}X^T(sigma^2 I) X (X^TX)^{-1}X^T — 2 sigma^2 I X (X^TX)^{-1}X^T\
&=&sigma^2 I + sigma^2 X (X^TX)^{-1}X^T X (X^TX)^{-1}X^T — 2 sigma^2 I X (X^TX)^{-1}X^T\
&=&sigma^2 I + sigma^2 X (X^TX)^{-1}X^T — 2 sigma^2 X (X^TX)^{-1}X^T\
&=&sigma^2 [I + X (X^TX)^{-1}X^T — 2 X (X^TX)^{-1}X^T]\
&=&sigma^2 [I — X (X^TX)^{-1}X^T]\
&=& sigma^2(I-H)
end{eqnarray}
where $H = X(X^TX)^{-1}X^T$. Therefore the variance of the $i^{tt{th}}$ residual is $sigma^2(1-h_{ii})$ where $h_{ii}$ is $H(i,i)$ (some texts will write that as $h_i$ instead).
As you see, it’s smaller, when $h$ is larger… which is when the pattern of $x$-values
is further from the center of the $x$’s. In simple regression $h$ is larger when
$(x-bar x)$ is larger.
Now as to why, note that $hat y = Hy$ ($H$ is called the hat-matrix for this reason).
That is, the fit at the $i^{tt{th}}$ observation responds to movements in $y_i$ in proportion to $h_{ii}$, or $frac{partial hat{y}_i}{partial y_i} = h_{ii}$. So when $h$ is
larger, $y$ pulls the line more toward itself, making its residual smaller.
There’s a more intuitive discussion in the context of simple linear regression here that may help motivate it for you.
I interpret that as large errors near the Mean with smaller errors away from the Mean.
No, we’re not discussing errors, they have constant variance. We’re discussing residuals. They are not the errors and don’t have constant variance; they’re related but different.
The bit of material I have read on the subject, suggests just the opposite…
Can you point me to something that does this? Recall that we’re discussing the residual variability here.
Additionally, how would you define heteroskedasticity?
Having non-constant variance. That is, when the regression assumption about the variance being constant doesn’t hold, you have heteroskedasticity.
See Wikipedia: http://en.wikipedia.org/wiki/Heteroscedasticity
And, what do you mean by the variance of unobserved errors?
You don’t observe the errors, but the model assumes they have constant variance, $sigma^2$. The «variance of unobserved errors» is thus simply «$sigma^2$».
How can you measure those since they are unobserved?
Individually, you can’t, at least not very well. You can roughly estimate them by the residuals, but they don’t even have the same variance, as we saw. However, you can estimate their variance reasonably well from the residuals, if you appropriately adjust for the fact that the residuals are on average smaller than the errors.
The first part of my question, is how do you calculate this specific Standard Error at a specific point estimate?
You don’t specify if you mean simple linear or multiple regression. I’ll assume the general case. Let’s do it at a point $x^* = (1,x_1^*,x_2^*,…,x_p^*)$
$$text{Var}(hat y^*) = text{Var}(x^*hatbeta)= text{Var}(x^*(X^TX)^{-1}X^T y)$$
$$= x^*(X^TX)^{-1}X^T text{Var}(y) X(X^TX)^{-1}x^{*T}$$
$$ = sigma^2 x^*(X^TX)^{-1}X’ I X(X^TX)^{-1}x^{*T} $$
$$= sigma^2 x^*(X^TX)^{-1}x^{*T}$$
If $h^*_{ii} = [x^*(X^TX)^{-1}x^{*T}]_{ii}$ then $text{Var}(hat y_i) = sigma^2 h^*_{ii}$.
Of course, $sigma^2$ is unknown and must be estimated.
The standard error is the square root of that estimated variance up above.
Could one provide a link to a numerical example to facilitate my interpretation of the formula?
I’ll try to dig one up.
My second part to this overall question is: How come the resulting hourglass shape of the resulting Confidence Interval as depicted does not break the linear regression assumption that the variance of residuals remain constant across observations (the heteroskedasticity thing)?
1) it’s a confidence interval for where the mean is, not the variance of the data; it reflects our uncertainty in the parameters as they feed through (via the design, $X$) to the the estimate of the mean. Something assumed true for one thing not being true for a different thing doesn’t violate the assumption for the first thing.
2) Your statement «the linear regression assumption that the variance of residuals remain constant across observations» is factually incorrect (though I know what you’re getting at). That is not an assumption of regression — in fact, outside specific cases, it’s untrue for regression. What is assumed constant is the variance of the unobserved errors. The variance of the residuals is not constant. In fact it ‘bows in’ in opposite fashion to the way the variance above ‘bows out’, both due to the phenomenon of leverage.
Edits in response to followup questions:
Why would the variance bow in?
I’ll do it algebraically and then expand on the explanation in the text above:
begin{eqnarray}
text{Var}(y-hat y) &=& text{Var}(y) + text{Var}(hat y) — 2 text{Cov}(y,hat y)\
&=&sigma^2 I + text{Var}(X hat beta) — 2 text{Cov}(y,X hat beta)\
&=&sigma^2 I + text{Var}(X (X^TX)^{-1}X^T y) — 2 text{Cov}(y,X (X^TX)^{-1}X^T y)\
&=&sigma^2 I + X (X^TX)^{-1}X^Ttext{Var}(y) X (X^TX)^{-1}X^T — 2 text{Cov}(y, y)X (X^TX)^{-1}X^T\
&=&sigma^2 I + X (X^TX)^{-1}X^T(sigma^2 I) X (X^TX)^{-1}X^T — 2 sigma^2 I X (X^TX)^{-1}X^T\
&=&sigma^2 I + sigma^2 X (X^TX)^{-1}X^T X (X^TX)^{-1}X^T — 2 sigma^2 I X (X^TX)^{-1}X^T\
&=&sigma^2 I + sigma^2 X (X^TX)^{-1}X^T — 2 sigma^2 X (X^TX)^{-1}X^T\
&=&sigma^2 [I + X (X^TX)^{-1}X^T — 2 X (X^TX)^{-1}X^T]\
&=&sigma^2 [I — X (X^TX)^{-1}X^T]\
&=& sigma^2(I-H)
end{eqnarray}
where $H = X(X^TX)^{-1}X^T$. Therefore the variance of the $i^{tt{th}}$ residual is $sigma^2(1-h_{ii})$ where $h_{ii}$ is $H(i,i)$ (some texts will write that as $h_i$ instead).
As you see, it’s smaller, when $h$ is larger… which is when the pattern of $x$-values
is further from the center of the $x$’s. In simple regression $h$ is larger when
$(x-bar x)$ is larger.
Now as to why, note that $hat y = Hy$ ($H$ is called the hat-matrix for this reason).
That is, the fit at the $i^{tt{th}}$ observation responds to movements in $y_i$ in proportion to $h_{ii}$, or $frac{partial hat{y}_i}{partial y_i} = h_{ii}$. So when $h$ is
larger, $y$ pulls the line more toward itself, making its residual smaller.
There’s a more intuitive discussion in the context of simple linear regression here that may help motivate it for you.
I interpret that as large errors near the Mean with smaller errors away from the Mean.
No, we’re not discussing errors, they have constant variance. We’re discussing residuals. They are not the errors and don’t have constant variance; they’re related but different.
The bit of material I have read on the subject, suggests just the opposite…
Can you point me to something that does this? Recall that we’re discussing the residual variability here.
Additionally, how would you define heteroskedasticity?
Having non-constant variance. That is, when the regression assumption about the variance being constant doesn’t hold, you have heteroskedasticity.
See Wikipedia: http://en.wikipedia.org/wiki/Heteroscedasticity
And, what do you mean by the variance of unobserved errors?
You don’t observe the errors, but the model assumes they have constant variance, $sigma^2$. The «variance of unobserved errors» is thus simply «$sigma^2$».
How can you measure those since they are unobserved?
Individually, you can’t, at least not very well. You can roughly estimate them by the residuals, but they don’t even have the same variance, as we saw. However, you can estimate their variance reasonably well from the residuals, if you appropriately adjust for the fact that the residuals are on average smaller than the errors.