Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Характеристики рассеяния результатов измерений
Для
математико-статистического анализа
результатов выборки знать только
характеристики положения недостаточно.
Одна и та же величина среднего значения
может характеризовать совершенно
различные выборки.
Поэтому
кроме них в статистике рассматривают
также характеристики
рассеяния (вариации,
или
колеблемости)
результатов.
1. Размах вариации
Определение.
Размахом
вариации называется разница между
наибольшим и наименьшим результатами
выборки, обозначается R
и определяется
R=Xmax
— Xmin
.
Информативность
этого показателя невелика, хотя при
малых объёмах выборки по размаху
легко оценить разницу между лучшим и
худшим результатами спортсменов.
2. Дисперсия
Определение.
Дисперсией
называется
средний квадрат отклонения значений
признака от среднего арифметического.
Для
несгруппированных данных дисперсия
определяется по формуле
2
=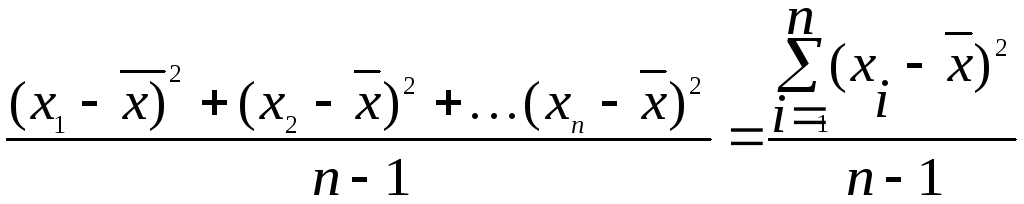 ,
,
(1)
где
Хi
– значение признака,
![]() —
—
среднее арифметическое.
Для данных,
сгруппированных в интервалы, дисперсия
определяется по формуле
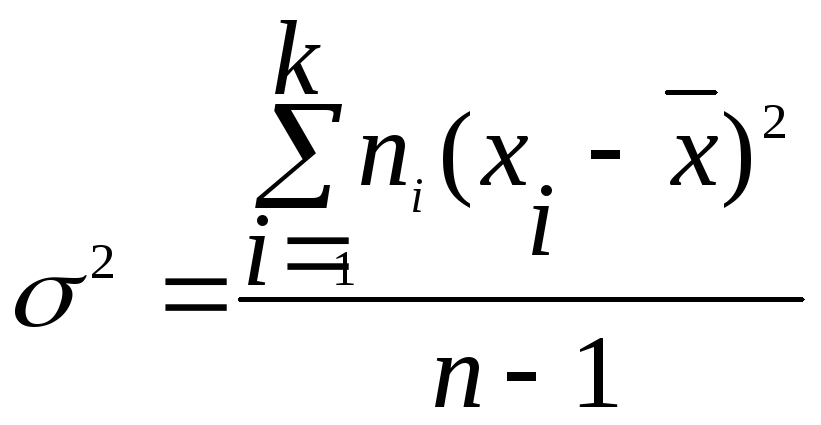 ,
,
где
хi
– среднее значение i
интервала
группировки, ni
– частоты интервалов.
Для
упрощения расчётов и во избежание
погрешностей вычисления при округлении
результатов (особенно при увеличении
объёма выборки) используются также
другие формулы для определения дисперсии.
Если среднее арифметическое уже
вычислено, то для несгруппированных
данных используется следующая формула:
2
=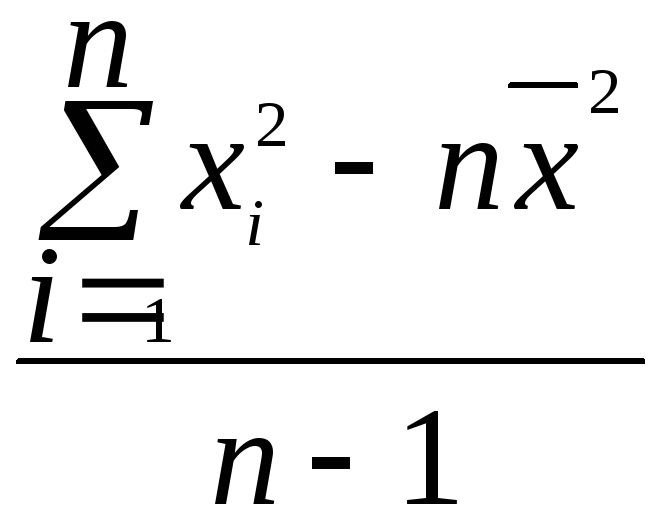 ,
,
для
сгруппированных данных:
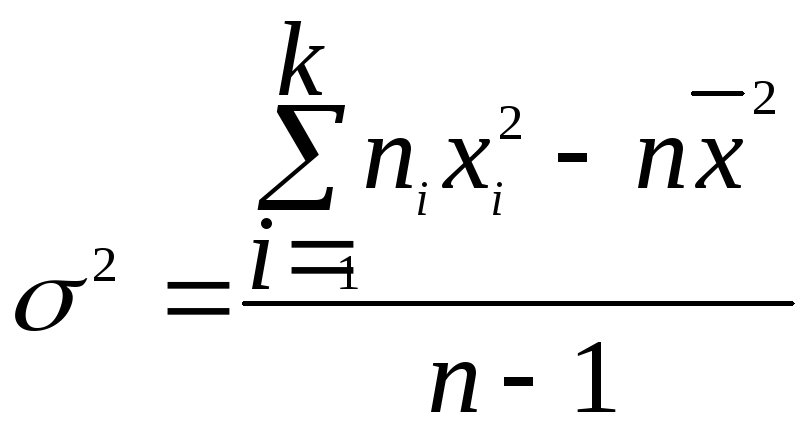 .
.
Эти
формулы получаются из предыдущих
раскрытием квадрата разности под знаком
суммы.
В
тех случаях, когда среднее арифметическое
и дисперсия вычисляются одновременно,
используются формулы:
для
несгруппированных данных:
2
=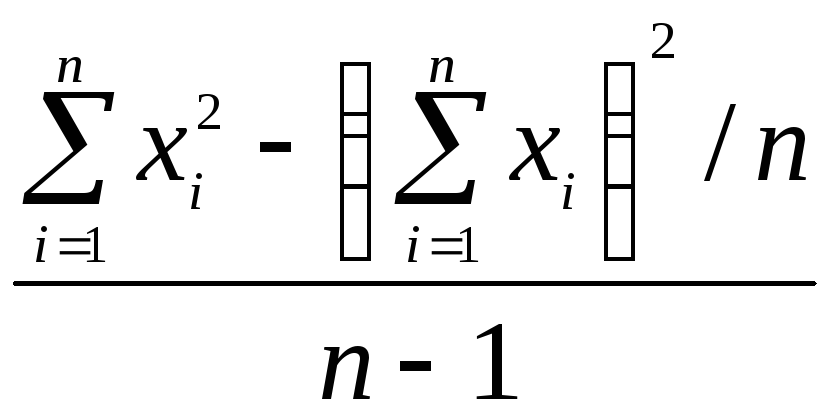 ,
,
для
сгруппированных данных:
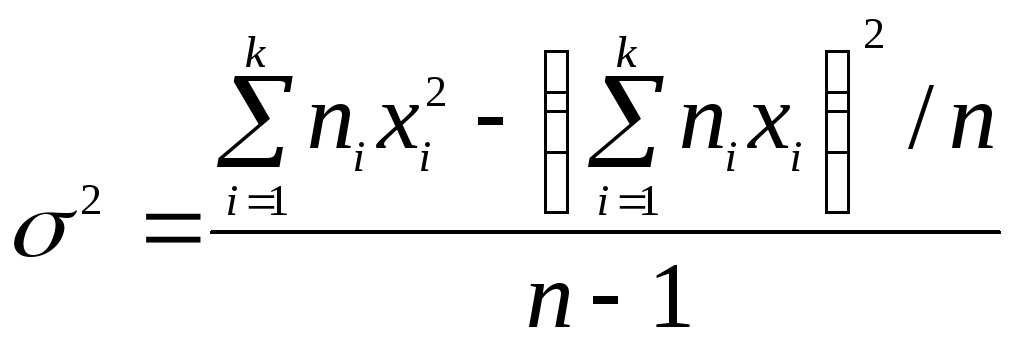 .
.
3.
Среднее квадратическое (стандартное)
отклонение
Определение.
Среднее
квадратическое
(стандартное)
отклонение
характеризует степень отклонения
результатов от среднего значения в
абсолютных единицах, т. к. в отличие от
дисперсии имеет те же единицы измерения,
что и результаты измерения. Иначе говоря,
стандартное отклонение показывает
плотность распределения результатов
в группе около среднего значения, или
однородность группы.
Для
несгруппированных данных стандартное
отклонение можно определить по формулам
=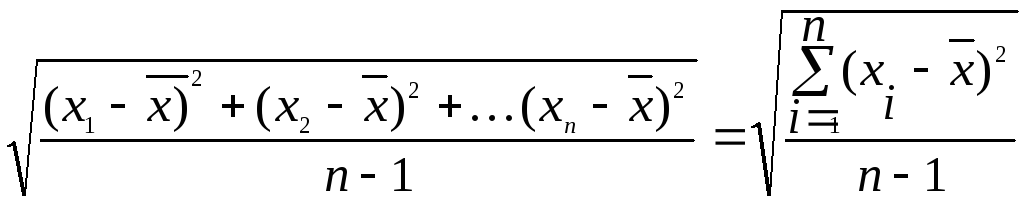 ,
,
=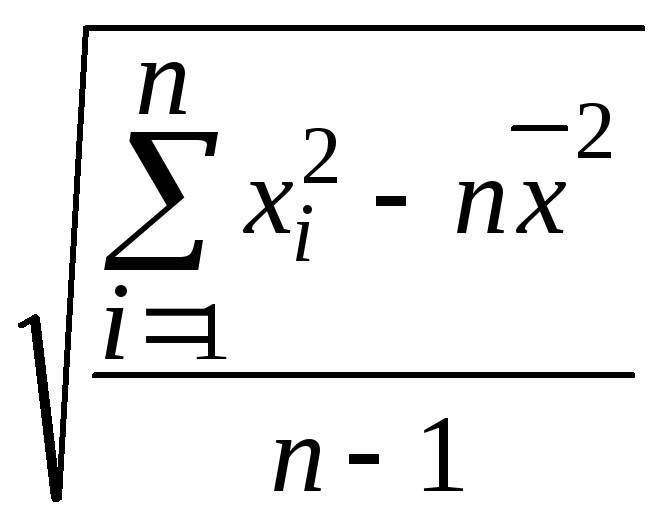 или
или
=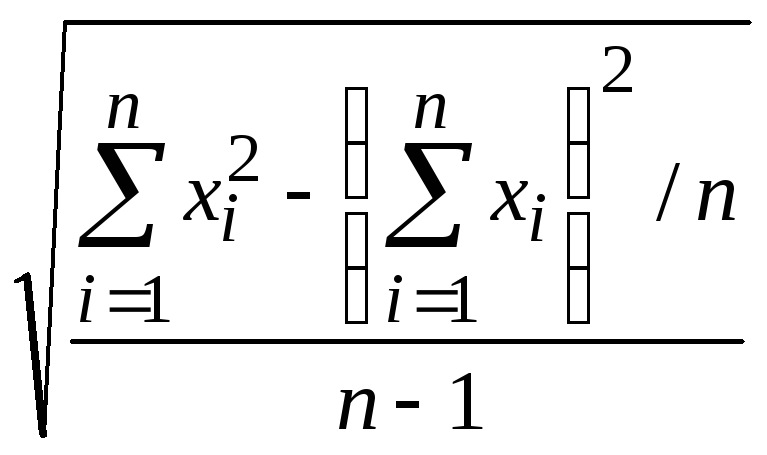 .
.
Для
данных, сгруппированных в интервалы,
стандартное отклонение определяется
по формулам:
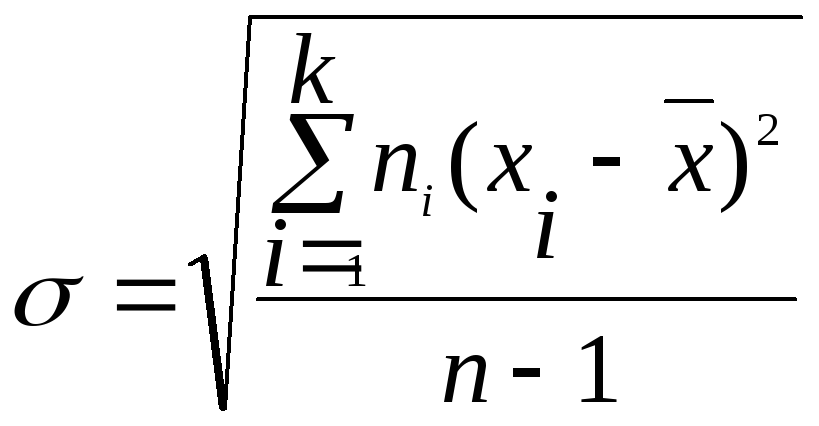 ,
,
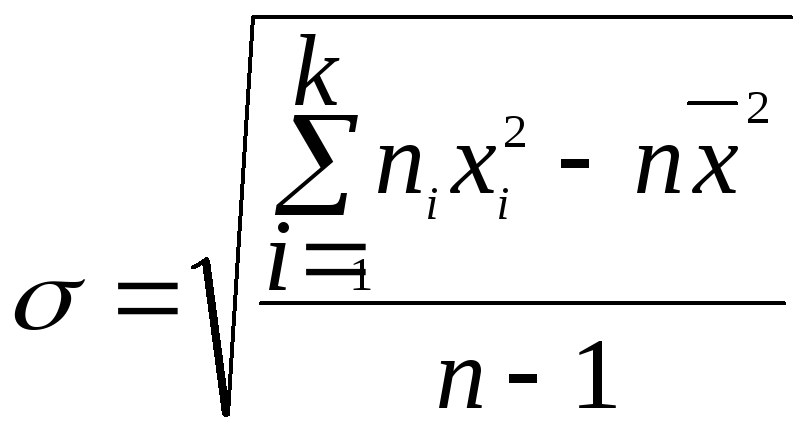 или
или
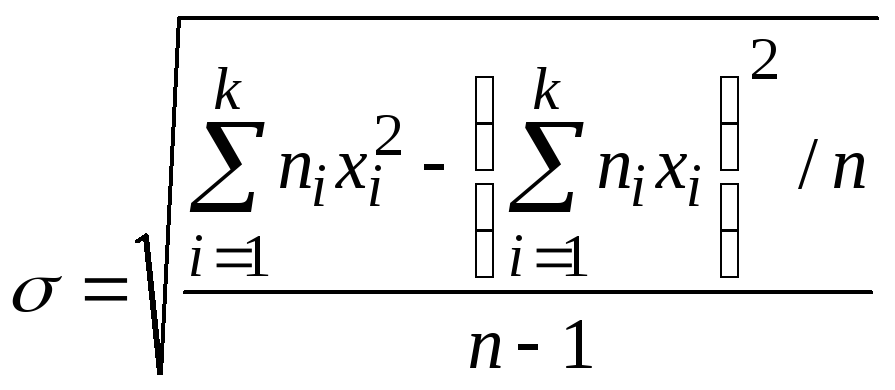 .
.
4. Ошибка средней арифметической (ошибка средней)
Ошибка
средней арифметической
характеризует колеблемость средней и
вычисляется по формуле:
![]() .
.
Как
видно из формулы, с увеличением объёма
выборки ошибка средней уменьшается
пропорционально корню квадратному из
объёма выборки.
5. Коэффициент вариации
Коэффициент
вариации
определяется
как отношение среднего квадратического
отклонения к среднему арифметическому,
выраженное в процентах:
![]() .
.
Считается,
что если коэффициент вариации не
превышает 10 %, то выборку можно считать
однородной, то есть полученной из одной
генеральной совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Описательные статистики
Среднее арифметическое
Медиана
Мода
Среднее геометрическое
Взвешенное среднее
Размах (интервал изменения)
Размах, полученный из процентилей
Что такое процентили
Применение процентилей
Дисперсия
Cреднеквадратическое отклонение, стандартное отклонение выборки
Вариация в пределах субъектов и между субъектами
Пусть Х1, Х2 … Xn — выборка независимых случайных величин.
Упорядочим эти величины по возрастанию, иными словами, построим вариационный ряд:
Х(1) < Х(2) < … < X (n) , (*)
где Х(1) = min ( Х1, Х2 … Xn),
Х(n) = max ( Х1, Х2 … Xn).
Элементы вариационного ряда (*) называются порядковыми статистиками.
Величины d(i) = X(i+1) — X(i) называются спейсингами или расстояниями между порядковыми статистиками.
Размахом выборки называется величина
R = X(n) — X(1)
Иными словами, размах это расстояние между максимальным и минимальным членом вариационного ряда.
Выборочное среднее равно: ![]() = (Х1 + Х2 + … + Xn) / n
= (Х1 + Х2 + … + Xn) / n
Среднее арифметическое
Вероятно, большинство из вас использовало такую важную описательную статистику, как среднее.
Среднее — очень информативная мера «центрального положения» наблюдаемой переменной, особенно если сообщается ее доверительный интервал. Исследователю нужны такие статистики, которые позволяют сделать вывод относительно популяции в целом. Одной из таких статистик является среднее.
Доверительный интервал для среднего представляет интервал значений вокруг оценки, где с данным уровнем доверия, находится «истинное» (неизвестное) среднее популяции.
Например, если среднее выборки равно 23, а нижняя и верхняя границы доверительного интервала с уровнем p=.95 равны 19 и 27 соответственно, то можно заключить, что с вероятностью 95% интервал с границами 19 и 27 накрывает среднее популяции.
Если вы установите больший уровень доверия, то интервал станет шире, поэтому возрастает вероятность, с которой он «накрывает» неизвестное среднее популяции, и наоборот.
Хорошо известно, например, что чем «неопределенней» прогноз погоды (т.е. шире доверительный интервал), тем вероятнее он будет верным. Заметим, что ширина доверительного интервала зависит от объема или размера выборки, а также от разброса (изменчивости) данных. Увеличение размера выборки делает оценку среднего более надежной. Увеличение разброса наблюдаемых значений уменьшает надежность оценки.
Вычисление доверительных интервалов основывается на предположении нормальности наблюдаемых величин. Если это предположение не выполнено, то оценка может оказаться плохой, особенно для малых выборок.
При увеличении объема выборки, скажем, до 100 или более, качество оценки улучшается и без предположения нормальности выборки.
Довольно трудно «ощутить» числовые измерения, пока данные не будут содержательно обобщены. Диаграмма часто полезна в качестве отправной точки. Мы можем также сжать информацию, используя важные характеристики данных. В частности, если бы мы знали, из чего состоит представленная величина, или если бы мы знали, насколько широко рассеяны наблюдения, то мы бы смогли сформировать образ этих данных.
Среднее арифметическое, которое очень часто называют просто «среднее», получают путем сложения всех значений и деления этой суммы на число значений в наборе.
Это можно показать с помощью алгебраической формулы. Набор n наблюдений переменной X можно изобразить как X1, X2, X3, …, Xn. Например, за X можно обозначить рост индивидуума (см), X1 обозначит рост 1-го индивидуума, а Xi — рост i-го индивидуума. Формула для определения среднего арифметического наблюдений ![]() (произносится «икс с чертой»):
(произносится «икс с чертой»):
![]() = (Х1 + Х2 + … + Xn) / n
= (Х1 + Х2 + … + Xn) / n
Можно сократить это выражение:

где ![]() (греческая буква «сигма») означает «суммирование», а индексы внизу и вверху этой буквы означают, что суммирование производится от i = 1 до i = n. Это выражение часто сокращают еще больше:
(греческая буква «сигма») означает «суммирование», а индексы внизу и вверху этой буквы означают, что суммирование производится от i = 1 до i = n. Это выражение часто сокращают еще больше:
![]() или
или ![]()
Медиана
Если упорядочить данные по величине, начиная с самой маленькой величины и заканчивая самой большой, то медиана также будет характеристикой усреднения в упорядоченном наборе данных.
Медиана делит ряд упорядоченных значений пополам с равным числом этих значений как выше, так и ниже ее (левее и правее медианы на числовой оси).
Вычислить медиану легко, если число наблюдений n нечетное. Это будет наблюдение номер (n + 1)/2 в нашем упорядоченном наборе данных.
Например, если n = 11, то медиана — это (11 + 1)/2, т. е. 6-е наблюдение в упорядоченном наборе данных.
Если n четное, то, строго говоря, медианы нет. Однако обычно мы вычисляем ее как среднее арифметическое двух соседних средних наблюдений в упорядоченном наборе данных (т. е. наблюдений номер (n/2) и (n/2 + 1)).
Так, например, если n = 20, то медиана — это среднее арифметическое наблюдений номер 20/2 = 10 и (20/2 + 1) = 11 в упорядоченном наборе данных.
Мода
Мода — это значение, которое встречается наиболее часто в наборе данных; если данные непрерывные, то мы обычно группируем их и вычисляем модальную группу.
Некоторые наборы данных не имеют моды, потому что каждое значение встречается только 1 раз. Иногда бывает более одной моды; это происходит тогда, когда 2 значения или больше встречаются одинаковое число раз и встречаемость каждого из этих значений больше, чем любого другого значения.
Как обобщающую характеристику моду используют редко.
Среднее геометрическое
При несимметричном распределении данных среднее арифметическое не будет обобщающим показателем распределения.
Если данные скошены вправо, то можно создать более симметричное распределение, если взять логарифм (по основанию 10 или по основанию е) каждого значения переменной в наборе данных. Среднее арифметическое значений этих логарифмов — характеристика распределения для преобразованных данных.
Чтобы получить меру с теми же единицами измерения, что и первоначальные наблюдения, нужно осуществить обратное преобразование — потенцирование (т. е. взять антилогарифм) средней логарифмированных данных; мы называем такую величину среднее геометрическое.
Если распределение данных логарифма приблизительно симметричное, то среднее геометрическое подобно медиане и меньше, чем среднее необработанных данных.
Взвешенное среднее
Взвешенное среднее используют тогда, когда некоторые значения интересующей нас переменной x более важны, чем другие. Мы присоединяем вес wi к каждому из значений xi в нашей выборке для того, чтобы учесть эту важность.
Если значения x1, x2 … xn имеют соответствующий вес w1, w2 … wn, то взвешенное арифметическое среднее выглядит следующим образом:

Например, предположим, что мы заинтересованы в определении средней продолжительности госпитализации в каком-либо районе и знаем средний реабилитационный период больных в каждой больнице. Учитываем количество информации, в первом приближении принимая за вес каждого наблюдения число больных в больнице.
Взвешенное среднее и среднее арифметическое идентичны, если каждый вес равен единице.
Размах (интервал изменения)
Размах — это разность между максимальным и минимальным значениями переменной в наборе данных; этими двумя величинами обозначают их разность. Обратите внимание, что размах вводит в заблуждение, если одно из значений есть выброс (см. раздел 3).
Размах, полученный из процентилей
Что такое процентили
Предположим, что мы расположим наши данные упорядоченно от самой маленькой величины переменной X и до самой большой величины. Величина X, до которой расположен 1% наблюдений (и выше которой расположены 99% наблюдений), называется первым процентилем.
Величина X, до которой находится 2% наблюдений, называется 2-м процентилем, и т. д.
Величины X, которые делят упорядоченный набор значений на 10 равных групп, т. е. 10-й, 20-й, 30-й,…, 90 и процентили, называются децилями. Величины X, которые делят упорядоченный набор значений на 4 равные группы, т.е. 25-й, 50-й и 75-й процентили, называются квартилями. 50-й процентиль — это медиана.
Применение процентилей
Мы можем добиться такой формы описания рассеяния, на которую не повлияет выброс (аномальное значение), исключая экстремальные величины и определяя размах остающихся наблюдений.
Межквартильный размах — это разница между 1-м и 3-м квартилями, т.е. между 25-м и 75-м процентилями. В него входят центральные 50% наблюдений в упорядоченном наборе, где 25% наблюдений находятся ниже центральной точки и 25% — выше.
Интердецильный размах содержит в себе центральные 80% наблюдений, т. е. те наблюдения, которые располагаются между 10-м и 90-м процентилями.
Мы часто используем размах, который содержит 95% наблюдений, т.е. он исключает 2,5% наблюдений снизу и 2,5% сверху. Указание такого интервала актуально, например, для осуществления диагностики болезни. Такой интервал называется референтный интервал, референтный размах или нормальный размах.
Дисперсия
Один из способов измерения рассеяния данных заключается в том, чтобы определить степень отклонения каждого наблюдения от средней арифметической. Очевидно, что чем больше отклонение, тем больше изменчивость, вариабельность наблюдений.
Однако мы не можем использовать среднее этих отклонений как меру рассеяния, потому что положительные отклонения компенсируют отрицательные отклонения (их сумма равна нулю). Чтобы решить эту проблему, мы возводим в квадрат каждое отклонение и находим среднее возведенных в квадрат отклонений; эта величина называется вариацией, или дисперсией.
Возьмем n наблюдений x1, x2, х3, …, xn, среднее которых равняется ![]() .
.
Вычисляем дисперсию:
![]()
В случае, если мы имеем дело не с генеральной совокупностью, а с выборкой, то вычисляется выборочная дисперсия:
![]()
Теоретически можно показать, что получится более точная дисперсия по выборке, если разделить не на n, а на (n-1).
Единицы измерения (размерность) вариации — это квадрат единиц измерения первоначальных наблюдений.
Например, если измерения производятся в килограммах, то единица измерения вариации будет килограмм в квадрате.
Среднеквадратическое отклонение, стандартное отклонение выборки
Среднеквадратическое отклонение — это положительный квадратный корень из дисперсии.
Стандартное отклонение выборки — корень из выборочной дисперсии:

Мы можем представить себе стандартное отклонение как своего рода среднее отклонение наблюдений от среднего. Оно вычисляется в тех же единицах (размерностях), что и исходные данные.
Если разделить стандартное отклонение на среднее арифметическое и выразить результат в процентах, получится коэффициент вариации.
Он является мерой рассеяния, не зависит от единиц измерения (безразмерный), но имеет некоторые теоретические неудобства и поэтому не очень одобряется статистиками.
Вариация в пределах субъектов и между субъектами
Если провести повторные измерения непрерывной переменной у исследуемого объекта, то можно увидеть ее изменения (внутрисубъектные изменения). Это можно объяснить тем, что объект не всегда может дать точные и те же самые ответы, и/или ошибкой, погрешностью измерения. Однако при измерениях у одного объекта вариация обычно меньше, чем вариация единичного измерения в группе (межсубъектные изменения).
Например, вместимость легкого 17-летнего мальчика составляет от 3,60 до 3,87 л, когда измерения повторяются не менее 10 раз; если провести однократное измерение у 10 мальчиков того же возраста, то объем будет между 2,98 и 4,33 л. Эти концепции важны в плане исследования.
Связанные определения:
Выборочное среднее, среднее значение выборки
Выброс
Дисперсия (рассеяние, разброс)
Дисперсия выборки (выборочная дисперсия)
Коэффициент вариации
Максимум
Математическое ожидание дискретной случайной величины
Математическое ожидание непрерывной случайной величины
Медиана
Меры дисперсии, меры разброса
Минимум
Мода
Описательные статистики
Описательный анализ
Параметры рассеяния
Параметры центральной тенденции
Среднее значение
Среднеквадратичное отклонение популяции
Стандартная ошибка среднего
Стандартное отклонение
В начало
Содержание портала
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.