![]()
ГЛАВА 3. Диагностические тесты. Скрининг
Поэтому существует ряд общепризнанных способов борьбы с систематическими ошибками, характерных для разных этапов исследования. Например, на этапе отбора в группу контроля и основную группу исследования для уменьшения роли таких ошибок используется рандомизация, стратификация, подбор пар и другие аналогичные методы. На этапе вмешательства или воздей ствия эффективным методом борьбы является плацебо-контроль. При этом, понизить систематические ошибки на этапе оценки результатов лечения у отдельного больного призваны различные способы «маскирования» участников исследования: например, слепой перекрестный или двойной слепой метод назначения препарата и плацебо.
Что касается случайной ошибки измерений (другое ее наименование – разброс), то она характеризуется одинаковой вероятностью завышенной или заниженной оценки показателя. Величина случайной ошибки измерения конкретного показателя зависит от объема выборки, а сама ошибка может быть оценена на этапе анализа результатов.
Стандартная ошибка среднего значения как мера точности Как известно, в качестве характеристики «положения» изучаемого показа-
теля можно использовать среднее арифметическое значение (Mean, которое часто обозначают прописной латинской буквой M), а также медиану распределения (Me), моду распределения (Mo) и другие параметры распределения.
Аналогично, в качестве меры случайного разброса индивидуальных значений некоторого показателя относительно параметра «положения» (например, относительно среднего значения) можно использовать среднее квадратическое отклонение или среднее абсолютное отклонение, а также стандартную ошибку среднего значения (Standard Error of Mean, которую часто обозначают строчной латинской буквой m) и другие статистические параметры разброса.
При этом стандартную ошибку среднего значения (вычисляемую как результат деления среднего квадратического отклонения на квадратный корень из числа измерений) можно использовать в качестве меры точности среднего значения показателя. Разумеется, здесь имеются в виду показатели, характер статистического распределения которых можно считать близким к нормальному.
Очевидно, что после вычисления среднего значения показателя исследователь может сохранить в представляемом итоговом результате больше или меньше значащих цифр. Как узнать, сколько их нужно оставить, чтобы не «затемнять» реальную точность оценки среднего значения?
Учебники по биостатистике предлагают использовать для этого ошибку среднего значения (т. е. величину m). Она непосредственно зависит от объема выборки, т. е. уменьшается при увеличении числа отдельных измерений, так что величина этой ошибки позволяет решить, какие цифры в записи величины среднего значения являются верными, а какие – сомнительными или просто бессмысленными.
51

ОСНОВЫ ДОКАЗАТЕЛЬНОЙ МЕДИЦИНЫ
Приведем наглядный пример. Пусть при измерении уровня систолического артериального давления в некоторой группе мужчин в возрасте 50-59 лет было получено приблизительно нормальное распределение показателя со средним значением M = 146,718… мм рт.ст. Какие же цифры нужно оставить в итоговой записи этого среднего результата, а какие следует отбросить?
Если, например, ошибка среднего значения равна m = 0,0267… мм рт.ст., то, будучи округленной до старшей значащей цифры (т. е. до сотых долей) она составит m = 0,03 мм рт.ст.
Таким образом, ошибка среднего проявляется в разряде сотых долей. Поэтому и среднее значение нужно округлить до сотых, т. е. записать итоговое значение M±m в виде 146,72±0,03 мм рт.ст. При этом нужно понимать, что в записи среднего значения цифры 1, 4, 6, 7 являются верными, а цифра 2 – сомнительной, потому что именно в этом десятичном разряде (в сотых долях) проявляется ошибка m.
Если же, например, ошибка среднего m оказалась в десять раз больше
иравна 0,267… (т. е. после округления будет m = 0,3), то в записи среднего значения сомнительная цифра появляется уже в разряде десятых долей. Тогда правильная итоговая запись будет иметь вид M±m = 146,7±0,3 мм рт. ст.
Аесли ошибка среднего m оказалась еще больше (что часто бывает, если число измерений невелико) и равна 2,67… (т. е. после округления будет m = 3 мм рт.ст.), то в записи среднего значения сомнительная цифра появляется уже в разряде целых единиц. Тогда правильная итоговая запись будет иметь вид M±m = 147±3 мм рт.ст. (причем в записи среднего значения 147 последняя цифра 7 – сомнительная).
Таким образом, если автор публикации приводит результат M±m в виде 146,72±2,67 мм рт.ст., то он тем самым как бы скрывает невысокую точность измерения, оставляя в записи среднего значения не только сомнительную цифру единиц, но и совершенно бессмысленные цифры в разрядах десятых
исотых долей.
С другой стороны, если результат M±m приведен в виде 147±0,03 мм рт. ст., то это также неправильно, поскольку ошибка среднего значения появляется только в разряде сотых долей, и значение M оказалось слишком «загрублено». Если же на практике получилось так, что в подобном случае значение M при вычислениях точно равно 147 мм рт.ст., то правильной формой записи будет 147,00±0,03 мм рт.ст. Такая запись укажет, что в среднем значении показателя имеется верная значащая цифра и после запятой.
Разумеется, различные типы клинических исследований предоставляют разные возможности для контроля за систематическими и случайными ошибками, т.е., фактически, за точностью итоговых результатов измерений показателей.
В частности, рандомизированное контролируемое исследование (Randomized Controlled Trial) – при правильной его организации – позволяет свести к минимуму систематические ошибки и учесть величины случайных
52

ГЛАВА 3. Диагностические тесты. Скрининг
ошибок. Этот тип клинических исследований наиболее близок к классическому экспериментальному исследованию, для которого характерны, так называемые, эталонные методы тестирования.
Если же проводимое клиническое исследование относится не к типу рандомизированных контролируемых исследований, а является проспективным когортным исследованием (Cohort Study), то для него характерны некоторые дополнительные источники систематических ошибок (например, на этапе формирования когорт, а также вследствие миграции пациентов в течение исследования). Тем не менее, проспективное когортное исследование считается лучшим видом клинических исследований для таких ситуаций, когда классический эксперимент невозможен (например, при исследовании факторов риска, а также прогноза заболевания).
Разумеется, для изучения редких исходов заболевания в когортных исследованиях потребовалось бы наблюдать в течение очень длительного времени большие группы обследованных. Общеизвестный пример – Фремингемское исследование, проведенное в США для установления связи ряда факторов риска с развитием ИБС, когда в течение 30 лет наблюдали когорту, состоящую более чем из 5 тысяч человек.
Если же клиническое исследование относится к типу «случай-контроль» (Case-control study), то особенности его организации (прежде всего, несколько «искусственный» подбор групп сравнения, а также ретроспективный характер исследования, не позволяющий достоверно регистрировать точные временные интервалы между событиями) определяют и возникновение некоторых характерных ошибок, для учета которых приходится применять специальные методы. Тем не менее, такой тип исследования хорошо подходит для изучения редких событий, тогда как в случае рандомизированного контролируемого исследования или проспективного когортного исследования это потребовало бы гораздо больших временных и финансовых затрат.
Разумеется, после определения того типа клинического исследования, который будет принят в конкретном случае, организатору потребуется выяснить, сколько (минимально) пациентов должно быть включено в группы сравнения, чтобы по завершении исследования можно было рассчитывать на статистически значимые результаты. Более того, потребуется выбрать одну из процедур рандомизации (стратификации), чтобы обеспечить одинаковую структуру групп сравнения по ряду важных признаков (с учетом их комбинаций).
Рассмотрим вышеназванные задачи более подробно и на наглядных примерах.
Планирование необходимых размеров групп сравнения Несомненно, каждому исследователю еще на этапе планирования кли-
нического исследования полезно использовать некоторые простые методы расчета требуемого объема групп сравнения, при котором обеспечивается получение статистически значимых различий между частотами ожидаемых событий (в контрольной и основной группах соответственно).
53

ОСНОВЫ ДОКАЗАТЕЛЬНОЙ МЕДИЦИНЫ
В частности, если планируется сделать обе группы сравнения одинаковыми (по N обследованных в каждой из двух групп), а частота изучаемого показателя (например, исхода заболевания или наличия фактора риска) предполагается равной P1% одной группе сравнения и P2% в другой, то для получения значимого различия между указанными частотами P1% и P2% нужно, чтобы число N обследованных в каждой из двух групп было не меньше, чем результат вычисления по следующей формуле:
N = 0,5 * χ2 * (P1 + P2) * (200 – P1 – P2) / (P1 – P2)2
Здесь χ2 – это значение «Хи-квадрат» критерия Пирсона, которое равно 3,84 для случая статистической значимости различий на уровне 95% (т. е. p < 0,05). Если же исследователь хочет добиться значимости различия этих же частот P1% и P2% на более высоком уровне 99% (т. е. при p < 0,01), то он должен подставить в вышеприведенную формулу более высокое значение χ2, равное 6,64. А чтобы те же самые P1% и P2% различались на уровне значимости 99,9% (т. е. при p < 0,001), в качестве значения χ2 в эту же самую формулу следует подставить число 10,84.
Приведем пример использования указанной формулы для расчета требуемого числа обследованных в каждой из двух групп сравнения для некоторых конкретных частот изучаемого показателя. Пусть, скажем, планируется за счет изучаемого воздействия на фоне лечения снизить частоту некоторых неблагоприятных исходов течения заболевания с 35% в контрольной группе до 20% в основной группе. Таким образом, P1 = 35%, а P2 = 20%. Тогда для того, чтобы подобное снижение оказалось статистически значимым при p < 0,05, в каждую из двух групп сравнения нужно включить более, чем
N = 0,5 * 3,84 * (35 + 20) * (200 – 35 – 20) / (35 – 20)2 = 69 человек.
Если нужно, чтобы эти же самые частоты P1 = 35% и P2 = 20% различались более значимо (например, на уровне p < 0,01), то необходимое число N обследованных в каждой из двух групп сравнения должно превышать:
N = 0,5 * 6,64 * (35 + 20) * (200 – 35 – 20) / (35 – 20)2 = 118 человек.
А если включить в каждую из двух групп сравнения больше больных, чем
N = 0,5 * 10,84 * (35 + 20) * (200 – 35 – 20) / (35 – 20)2 = 192 человека,
то те же самые ожидаемые частоты неблагоприятных исходов течения заболевания (35% и 20%) будут различаться уже на уровне p < 0,001.
Получаемые с помощью приведенной формулы необходимые размеры групп сравнения для клинического исследования указывают то значение N, меньше которого исследователь не должен включать в контрольную и основную группы сравнения, если он хочет, чтобы ожидаемые частоты P1% и P2% различались статистически значимо. Разумеется, для надежности всегда лучше несколько увеличить реальный объем каждой группы сравнения, хотя это может и не понадобиться, если фактические значения P1 и P2 окажутся более «благоприятными» для получения достоверных различий: например, они составят не 35% и 20%, а 37% и 19%, т. е. фактические различия окажутся более серьезными, чем это ожидалось до начала исследования.
54

ГЛАВА 3. Диагностические тесты. Скрининг
Необходимость рандомизации (стратификации) исходного материала исследования
Однако совершенно неверно было бы думать, что само по себе включение в группы сравнения достаточного числа больных сделает правомерным сравнение результатов, полученных в этих группах. Необходимо обеспечить одинаковую структуру сравниваемых групп не только по отдельным существенным показателям, но и по различным комбинациям таких показателей. Под существенными показателями следует понимать такие, которые способны оказать выраженное самостоятельное влияние на изучаемое явление (особенно в сочетании с другими наличествующими факторами), т. е. исказить результаты сравнения контрольной и основной группы, если статистические характеристики (например, частоты выявления, средние значения и т. п.) этих показателей значительно различаются в сравниваемых группах больных.
Именно такие показатели должны быть включены в список рандомизирующих (стратифицирующих) факторов и участвовать в соответствующей рандомизационной схеме еще на этапе формирования групп больных, сравнение которых планируется по результатам исследования.
Если, например, изучается динамика течения и прогноз острого инфаркта миокарда в двух группах больных, получающих разные бета-адреноблока- торы, то такие дополнительные факторы, как наличие выраженного стеноза коронарных артерий и наличие нарушений свертывания крови (высокая свертываемость и связанная с этим наклонность к спонтанному тромбообразованию) могут потенцировать влияние друг друга при их одновременном наличии, что приведет к увеличению риска повторного ИМ.
Поэтому при сопоставлении исходного состояния больных в сравниваемых группах совершенно недостаточно указывать, что частота каждого из этих двух факторов по отдельности была совершенно одинаковой в обеих группах.
Ведь при этом могло оказаться так, что в одной из групп было много больных с сочетанием обоих неблагоприятных факторов, тогда как в другой группе все случаи высокой свертываемости крови имели место только у больных без выраженного стеноза коронарных артерий, а все случаи выраженного стеноза сочетались с нормальными данными системы свертывания крови (результатами тромбоэластографии, коагулографии и др.).
Тогда межгрупповые различия в частоте случаев повторного инфаркта миокарда нельзя было бы ассоциировать с применением разных методов лечения, поскольку серьезное неконтролируемое влияние на прогноз течения заболевания могло оказать кумулятивное воздействие выраженного стеноза коронарных артерий и повышенной склонности к тромбообразованию в одной из групп больных.
Иными словами, для проведения адекватного сопоставления разных групп больных в динамике необходимо было заранее (еще на этапе формирования сравниваемых групп больных) гарантировать то, что не будет различаться структура групп по различным комбинациям неблагоприятных факторов.
55

ОСНОВЫ ДОКАЗАТЕЛЬНОЙ МЕДИЦИНЫ
Более того, даже при недоучете одного-единственного важного фактора результаты исследования может оказаться невозможно интерпретировать однозначно.
Пример структурной несогласованности материала при отсутствии рандомизации
Проиллюстрируем подобную несогласованность, которой можно было бы легко избежать, применяя подходящую рандомизационную схему на этапе формирования сравниваемых групп больных.
Например, в одной группе из 2000 больных АГ оценивалась эффективность некоторого давно применяемого антигипертензивного препарата, а в другой группе, также включавшей 2000 больных АГ – эффективность нового препарата.
Получилось так, что у больных с большей давностью заболевания (и, соответственно, с несколько большей выраженностью АГ) намного чаще назначали известный препарат, тогда как у больных с недавно выявленной АГ имелся противоположный «перекос»: там чаще назначали новый препарат.
Подобная несогласованность могла быть следствием того, что исследователи «пошли на поводу» больных, которые давно уже лечились известным препаратом, демонстрировали приверженность к нему и тем самым повлияли на решение организаторов включить их именно в ту группу больных («контрольную»), где им назначили этот традиционный препарат. А «недавним» больным АГ легче удавалось назначать незнакомый им препарат, так что для формирования равных по объему групп больных (т. е. на каждом из двух препаратов) организаторам пришлось у таких больных пойти на противоположный структурный перекос.
И хотя критерии эффективности лечения были вполне адекватными (они учитывали разные целевые значения АД при наличии или отсутствии сахарного диабета, а также включали регистрацию полной и частичной нормализации АД на фоне лечения и пр.), полученные результаты оказались противоречивыми.
Вот конкретные цифры (округленные для наглядности):
1). «Традиционный» препарат получали 1600 больных с более длительным заболеванием в анамнезе и всего 400 человек, у которых АГ была выявлена недавно. Новый препарат, наоборот, получали только 400 больных с более длительным заболеванием и 1600 человек, у которых АГ была выявлена недавно. Таким образом, обе группы больных включали по 2000 человек, однако структура каждой группы по давности заболевания АГ оказалась совершенно разной.
2). При «давней» АГ эффективное лечение традиционным препаратом отмечено у 400 больных из 1600 (25%), а лечение новым препаратом оказалось эффективно у 80 из 400 больных (20%, что значимо меньше, чем для традиционного препарата, при p < 0,05).
3). При «недавней» АГ эффективное лечение традиционным препаратом
56

ГЛАВА 3. Диагностические тесты. Скрининг
отмечено у 200 больных из 400 (50%), тогда как лечение новым препаратом оказалось эффективно у 720 из 1600 больных (45%, что также значимо меньше, чем для традиционного препарата, при p < 0,05).
4). Таким образом, вроде бы можно было констатировать, что новый препарат достоверно менее эффективен, чем традиционно применяемый, как у больных с более давней АГ, так и в группе, где заболевание было выявлено недавно. При этом больные с большей давностью заболевания в целом характеризовались меньшей эффективностью лечения, чем больные с недавно выявленной АГ.
5). Однако, если посмотреть суммарные цифры эффективности лечения обоими препаратами, то оказывается, что из 2000 больных, получавших традиционный препарат, гипотензивный эффект отмечали у 600 больных (вышеуказанные 400 случаев эффективного лечения среди лиц с давней АГ и 200 случаев среди больных с недавней АГ). А вот из 2000 больных, получавших новый препарат, эффективное лечение имело место у 800 больных (т.е, соответственно, 80 случаев среди лиц с давней АГ и еще 720 случаев среди больных с недавней АГ).
Получается, что в целом (без учета давности заболевания) эффективность антигипертензивного лечения новым препаратом составляла 40%, а аналогичная эффективность традиционного лечения – только 30% (различия значимы при p < 0,001, т. е. новый препарат не менее, а более эффективен, чем традиционно применяемый).
Конечно, вышеописанный пример для наглядности сильно упрощен, но он ясно демонстрирует, что при формировании групп сравнения больных неразумно обходиться без рандомизации (стратификации), обеспечивающей идентичность этих сравниваемых групп – с учетом комбинаций таких дополнительных важных факторов, которые оказывают собственное влияние на ожидаемые результаты исследования.
Пример рандомизационной (стратификационной) схемы Приведем один из примеров схемы рандомизации (или стратификации),
которая призвана обеспечить формирование двух равных по численности групп больных (контрольной и основной), на материале которых предполагается сравнить эффективность программы обучения больных АГ по борьбе с такими факторами риска, как наличие абдоминального ожирения и гиперхолестеринемия. Соответственно, в каждую из двух групп сравнения будут включаться больные АГ (1-й или 2-й степени), обязательно имеющие на момент включения абдоминальное ожирение (но разный уровень общего индекса массы тела) и уровень общего холестерина не менее 4,5 ммоль/л.
В качестве рандомизирующих факторов можно выбрать, например, степень АГ (1-я или 2-я), индекс массы тела – как показатель наличия или отсутствия общего ожирения (т. е. ИМТ менее 30 кг/м2 – или, наоборот, ИМТ = 30 кг/м2 и более), а также уровень ОХС (менее 6 ммоль/л – или, наоборот, 6 ммоль/л и более).
57

ОСНОВЫ ДОКАЗАТЕЛЬНОЙ МЕДИЦИНЫ
Таким образом, три вышеописанных фактора обеспечивают наличие восьми различных комбинаций – т. е. восьми «виртуальных» рандомизационных групп, различающихся хотя бы по одному из трех факторов. Виртуальными их можно назвать потому, что фактически эти восемь групп будут существовать только «на бумаге», обеспечивая при этом по ходу набора больных
висследование процесс адекватного формирования всего двух групп больных – контрольной и основной (однако – с учетом трех выбранных рандомизирующих факторов).
Как это осуществляется на практике? Достаточно заготовить 8 чистых листов бумаги (или, соответственно, 8 листов таблицы в программе Excel) и озаглавить эти листы с учетом комбинации рандомизирующих факторов.
Тогда заголовком 1-го листа будет: «Группа 1: больные АГ 1-й степени, с ИМТ менее 30 кг/м2 и при уровне общего холестерина менее 6 ммоль/л (однако не менее 4,5 ммоль/л, поскольку такой уровень был выбран в качестве обязательного для включения больных в исследование).
Заголовок 2-го листа: «Группа 2: больные АГ 1-й степени, с ИМТ менее 30 кг/м2 и при уровне общего холестерина 6 ммоль/л и более (т. е. 2-я рандомизационная группа отличается от первой только исходным уровнем общего холестерина).
Заголовок 3-го листа: «Группа 3: больные АГ 1-й степени, с ИМТ 30 кг/м2 и более, но при уровне общего холестерина менее 6 ммоль/л (т. е. 3-я рандомизационная группа отличается от первой только исходным уровнем ИМТ).
Заголовок 4-го листа: «Группа 4: больные АГ 1-й степени, с ИМТ 30 кг/м2 и более, при уровне общего холестерина 6 ммоль/л и более (т. е. 4-я рандомизационная группа отличается от первой и уровнем ИМТ, и уровнем общего холестерина).
Оставшиеся четыре рандомизационные группы формируются по аналогичной схеме, но для больных с АГ 2-й степени на момент включения
висследование.
Таким образом, последняя, 8-я «виртуальная» рандомизационная группа будет иметь заголовок: «Группа 8: больные АГ 2-й степени, с ИМТ 30 кг/м2
иболее, при уровне общего холестерина 6 ммоль/л и более (т. е. 8-я рандомизационная группа отличается от 1-й группы и степенью АГ, и уровнем ИМТ,
иуровнем общего холестерина).
Каким же образом будут использоваться эти восемь виртуальных групп при наборе больных АГ в исследование? Очень просто: первый же больной, попадающий по комбинации своего холестерина, ИМТ и степени АГ в любую конкретную рандомизационную группу, автоматически должен быть включен в контрольную группу общего исследования. Но как только в эту же рандомизационную группу попадет второй человек, он должен быть включен в основную группу исследования. Через некоторое время по мере прихода больных (попадающих в другие рандомизационные группы по такому же правилу) в эту же конкретную рандомизационную группу попадет третий по счету больной – снова «контрольный». Четвертый больной с тем же набором трех
58

ГЛАВА 3. Диагностические тесты. Скрининг
рандомизирующих факторов – снова «основной», и т. д.
Таким образом, каждая из восьми «виртуальных» рандомизационных групп обеспечит к концу исследования одинаковое поступление своих больных (т. е. имеющих одну и ту же конкретную комбинацию трех рандомизирующих факторов) и в контрольную, и в основную группы исследования.
Естественно, некоторые комбинации трех факторов будут встречаться чаще, чем другие (т. е. перечень больных на одном из восьми листов окажется более длинным, чем на другом листе). Но при этом схема рандомизации позволяет обеспечить то, что для каждой комбинации факторов ровно половина носителей этой комбинации станет «контрольными» больными, а другая половина – «основными».
3.1.2. «Золотой стандарт» и информативность клинического теста
Как правило, оценка информативности клинических (в частности, диагностических) тестов основана на сравнении их результатов с результатом некоторого точного способа определения наличия или отсутствия заболевания (или фактора риска и т. п.), т. е. с некоторым показателем, заслуживающим полного доверия исследователей. Указанный точный способ диагностики – это и есть «золотой стандарт», называемый также референтным или эталонным методом. Подробнее статистические показатели информативности теста (его чувствительность и специфичность, прогностическая ценность и отношение правдоподобия) будут описаны ниже.
Конечно, в действительности «золотой стандарт» нельзя, как правило, считать абсолютным эталоном. Кроме того, с развитием применяемых клиникоинструментальных и лабораторных методик прежние эталонные методы могут быть заменены более совершенными «золотыми стандартами». Поэтому в конкретном клиническом исследовании при оценке информативности применяемых тестов всегда указывается, какие именно методы в том или ином случае использовались в качестве референтных.
Чувствительность и специфичность теста В качестве характеристик информативности применяемых тестов (клини-
ческих, лабораторных, опросных и др.) чаще всего вычисляют чувствительность и специфичность этих тестов при выявлении некоторого изучаемого фактора (наличия заболевания, наличия фактора риска и т. п.).
Вообще говоря, чувствительность теста – это вероятность положительного результата диагностического теста при наличии болезни (т. е. доля истинно положительных результатов теста).
Например, чувствительность, оцениваемая в 85%, предполагает, что только 85% из числа истинно больных будут на основании данного теста признаны таковыми, а у остальных 15% результаты теста будут ложноотрицательными.
Аналогично, специфичность теста – это вероятность отрицательного результата диагностического теста в отсутствие болезни (т. е. доля истинно
59

ОСНОВЫ ДОКАЗАТЕЛЬНОЙ МЕДИЦИНЫ
отрицательных результатов теста). Таким образом, специфичность, оцениваемая в 90%, означает, что 10% лиц, не страдающих данным заболеванием, на основании результата анализа будут расценены как больные, т. е. у 10% результаты анализа будут ложноположительными.
Поэтому выборочные оценки чувствительности и специфичности применяемых методов в конкретном исследовании можно получить только в том случае, если весь изучаемый выборочный материал был также протестирован с помощью эталонного метода («золотого стандарта»), позволившего указать для каждого обследованного, имеется или отсутствует у него изучаемое заболевание на самом деле.
Тогда показатели чувствительности и специфичности данного теста будут отражать его способность верно указывать, соответственно, на наличие и отсутствие изучаемого фактора (например, заболевания).
Приведем пример соотношения между результатами используемого в некотором конкретном исследовании клинического (диагностического) теста и данными «золотого стандарта», дающего эталонные, т. е. истинные результаты по выявлению изучаемого заболевания (см. таблицу):
|
Положительный ре- |
Отрицательный резуль- |
||
|
зультат теста |
тат теста |
||
|
Болезнь име- |
Истинно- |
Ложно-отрицательный |
Суммарное число истинно |
|
ется |
положительный |
результат («пропуск |
имеющих заболевание = |
|
(по данным |
результат |
цели») |
|
|
«золотого |
a + b |
||
|
стандарта») |
a |
b |
|
|
Болезнь отсут |
c |
d |
Суммарное число истинно |
|
ствует |
не имеющих заболевания = |
||
|
(по данным |
Ложно- |
Истинно- |
|
|
«золотого |
положительный |
отрицательный |
c + d |
|
стандарта») |
результат («ложная |
результат |
|
|
тревога») |
|||
|
Суммарное число |
Суммарное число отри- |
Общее число обследован- |
|
|
положительных |
цательных результатов |
ных = |
|
|
результатов теста |
теста = b + d |
||
|
= a + c |
a + b + c + d |
Таким образом, в соответствии с данными вышеприведенной таблицы, чувствительность применяемого теста (в процентах) составляет 100 * a / (a + b). Аналогично, специфичность теста (в процентах) равна 100 * d / (c + d). Как видно из этих формул, для получения значений чувствительности и специфичности применяемого теста проценты вычисляются «по строке» – т. е. от эталонных оценок, данных «золотым стандартом». Если в этих формулах не использовать множитель 100, то чувствительность и специфичность будут вычислены в долях единицы – как вероятности соответствующих событий.
Подчеркнем, что диагностический тест с низкой чувствительностью часто пропускает болезнь из-за ложно-отрицательных результатов (при этом больным людям дается информация об отсутствии у них болезни). В то же время,
60
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Standard Error of the Mean vs. Standard Deviation: An Overview
Standard deviation (SD) measures the amount of variability, or dispersion, from the individual data values to the mean. SD is a frequently-cited statistic in many applications from math and statistics to finance and investing.
Standard error of the mean (SEM) measures how far the sample mean (average) of the data is likely to be from the true population mean. The SEM is always smaller than the SD.
Standard deviation and standard error are both used in statistical studies, including those in finance, medicine, biology, engineering, and psychology. In these studies, the SD and the estimated SEM are used to present the characteristics of sample data and explain statistical analysis results.
However, even some researchers occasionally confuse the SD and the SEM. Such researchers should remember that the calculations for SD and SEM include different statistical inferences, each of them with its own meaning. SD is the dispersion of individual data values. In other words, SD indicates how accurately the mean represents sample data.
However, the meaning of SEM includes statistical inference based on the sampling distribution. SEM is the SD of the theoretical distribution of the sample means (the sampling distribution).
Key Takeaways
- Standard deviation (SD) measures the dispersion of a dataset relative to its mean.
- SD is used frequently in statistics, and in finance is often used as a proxy for the volatility or riskiness of an investment.
- The standard error of the mean (SEM) measures how much discrepancy is likely in a sample’s mean compared with the population mean.
- The SEM takes the SD and divides it by the square root of the sample size.
- The SEM will always be smaller than the SD.
Click Play to Learn the Difference Between Standard Error and Standard Deviation
Standard error estimates the likely accuracy of a number based on the sample size.
Standard error of the mean, or SEM, indicates the size of the likely discrepancy compared to that of the larger population.
Calculating SD and SEM
standard deviation
σ
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
n
−
1
variance
=
σ
2
standard error
(
σ
x
ˉ
)
=
σ
n
where:
x
ˉ
=
the sample’s mean
n
=
the sample size
begin{aligned} &text{standard deviation } sigma = sqrt{ frac{ sum_{i=1}^n{left(x_i — bar{x}right)^2} }{n-1} } \ &text{variance} = {sigma ^2 } \ &text{standard error }left( sigma_{bar x} right) = frac{{sigma }}{sqrt{n}} \ &textbf{where:}\ &bar{x}=text{the sample’s mean}\ &n=text{the sample size}\ end{aligned}
standard deviation σ=n−1∑i=1n(xi−xˉ)2variance=σ2standard error (σxˉ)=nσwhere:xˉ=the sample’s meann=the sample size
Standard Deviation
The formula for the SD requires a few steps:
- First, take the square of the difference between each data point and the sample mean, finding the sum of those values.
- Next, divide that sum by the sample size minus one, which is the variance.
- Finally, take the square root of the variance to get the SD.
Standard Error of the Mean
SEM is calculated simply by taking the standard deviation and dividing it by the square root of the sample size.
Standard error gives the accuracy of a sample mean by measuring the sample-to-sample variability of the sample means. The SEM describes how precise the mean of the sample is as an estimate of the true mean of the population.
As the size of the sample data grows larger, the SEM decreases vs. the SD. As the sample size increases, the sample mean estimates the true mean of the population with greater precision.
Increasing the sample size does not make the SD necessarily larger or smaller; it just becomes a more accurate estimate of the population SD.
A sampling distribution is a probability distribution of a sample statistic taken from a greater population. Researchers typically use sample data to estimate the population data, and the sampling distribution explains how the sample mean will vary from sample to sample. The standard error of the mean is the standard deviation of the sampling distribution of the mean.
Standard Error and Standard Deviation in Finance
In finance, the SEM daily return of an asset measures the accuracy of the sample mean as an estimate of the long-run (persistent) mean daily return of the asset.
On the other hand, the SD of the return measures deviations of individual returns from the mean. Thus, SD is a measure of volatility and can be used as a risk measure for an investment.
Assets with greater day-to-day price movements have a higher SD than assets with lesser day-to-day movements. Assuming a normal distribution, around 68% of daily price changes are within one SD of the mean, with around 95% of daily price changes within two SDs of the mean.
How Are Standard Deviation and Standard Error of the Mean Different?
Standard deviation measures the variability from specific data points to the mean. Standard error of the mean measures the precision of the sample mean to the population mean that it is meant to estimate.
Is the Standard Error Equal to the Standard Deviation?
No, the standard deviation (SD) will always be larger than the standard error (SE). This is because the standard error divides the standard deviation by the square root of the sample size.
If the sample size is one, they will be the same, but a sample size of one is rarely useful.
How Can You Compute the SE From the SD?
If you have the standard error (SE) and want to compute the standard deviation (SD) from it, simply multiply it by the square root of the sample size.
Why Do We Use Standard Error Instead of Standard Deviation?
What Is the Empirical Rule, and How Does It Relate to Standard Deviation?
A normal distribution is also known as a standard bell curve, since it looks like a bell in graph form. According to the empirical rule, or the 68-95-99.7 rule, 68% of all data observed under a normal distribution will fall within one standard deviation of the mean. Similarly, 95% falls within two standard deviations and 99.7% within three.
The Bottom Line
Investors and analysts measure standard deviation as a way to estimate the potential volatility of a stock or other investment. It helps determine the level of risk to the investor that is involved. When reading an analyst’s report, the level of riskiness of an investment may be labeled «standard deviation.»
Standard error of the mean is an indication of the likely accuracy of a number. The larger the sample size, the more accurate the number should be.
Standard Error of the Mean vs. Standard Deviation: An Overview
Standard deviation (SD) measures the amount of variability, or dispersion, from the individual data values to the mean. SD is a frequently-cited statistic in many applications from math and statistics to finance and investing.
Standard error of the mean (SEM) measures how far the sample mean (average) of the data is likely to be from the true population mean. The SEM is always smaller than the SD.
Standard deviation and standard error are both used in statistical studies, including those in finance, medicine, biology, engineering, and psychology. In these studies, the SD and the estimated SEM are used to present the characteristics of sample data and explain statistical analysis results.
However, even some researchers occasionally confuse the SD and the SEM. Such researchers should remember that the calculations for SD and SEM include different statistical inferences, each of them with its own meaning. SD is the dispersion of individual data values. In other words, SD indicates how accurately the mean represents sample data.
However, the meaning of SEM includes statistical inference based on the sampling distribution. SEM is the SD of the theoretical distribution of the sample means (the sampling distribution).
Key Takeaways
- Standard deviation (SD) measures the dispersion of a dataset relative to its mean.
- SD is used frequently in statistics, and in finance is often used as a proxy for the volatility or riskiness of an investment.
- The standard error of the mean (SEM) measures how much discrepancy is likely in a sample’s mean compared with the population mean.
- The SEM takes the SD and divides it by the square root of the sample size.
- The SEM will always be smaller than the SD.
Click Play to Learn the Difference Between Standard Error and Standard Deviation
Standard error estimates the likely accuracy of a number based on the sample size.
Standard error of the mean, or SEM, indicates the size of the likely discrepancy compared to that of the larger population.
Calculating SD and SEM
standard deviation
σ
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
n
−
1
variance
=
σ
2
standard error
(
σ
x
ˉ
)
=
σ
n
where:
x
ˉ
=
the sample’s mean
n
=
the sample size
begin{aligned} &text{standard deviation } sigma = sqrt{ frac{ sum_{i=1}^n{left(x_i — bar{x}right)^2} }{n-1} } \ &text{variance} = {sigma ^2 } \ &text{standard error }left( sigma_{bar x} right) = frac{{sigma }}{sqrt{n}} \ &textbf{where:}\ &bar{x}=text{the sample’s mean}\ &n=text{the sample size}\ end{aligned}
standard deviation σ=n−1∑i=1n(xi−xˉ)2variance=σ2standard error (σxˉ)=nσwhere:xˉ=the sample’s meann=the sample size
Standard Deviation
The formula for the SD requires a few steps:
- First, take the square of the difference between each data point and the sample mean, finding the sum of those values.
- Next, divide that sum by the sample size minus one, which is the variance.
- Finally, take the square root of the variance to get the SD.
Standard Error of the Mean
SEM is calculated simply by taking the standard deviation and dividing it by the square root of the sample size.
Standard error gives the accuracy of a sample mean by measuring the sample-to-sample variability of the sample means. The SEM describes how precise the mean of the sample is as an estimate of the true mean of the population.
As the size of the sample data grows larger, the SEM decreases vs. the SD. As the sample size increases, the sample mean estimates the true mean of the population with greater precision.
Increasing the sample size does not make the SD necessarily larger or smaller; it just becomes a more accurate estimate of the population SD.
A sampling distribution is a probability distribution of a sample statistic taken from a greater population. Researchers typically use sample data to estimate the population data, and the sampling distribution explains how the sample mean will vary from sample to sample. The standard error of the mean is the standard deviation of the sampling distribution of the mean.
Standard Error and Standard Deviation in Finance
In finance, the SEM daily return of an asset measures the accuracy of the sample mean as an estimate of the long-run (persistent) mean daily return of the asset.
On the other hand, the SD of the return measures deviations of individual returns from the mean. Thus, SD is a measure of volatility and can be used as a risk measure for an investment.
Assets with greater day-to-day price movements have a higher SD than assets with lesser day-to-day movements. Assuming a normal distribution, around 68% of daily price changes are within one SD of the mean, with around 95% of daily price changes within two SDs of the mean.
How Are Standard Deviation and Standard Error of the Mean Different?
Standard deviation measures the variability from specific data points to the mean. Standard error of the mean measures the precision of the sample mean to the population mean that it is meant to estimate.
Is the Standard Error Equal to the Standard Deviation?
No, the standard deviation (SD) will always be larger than the standard error (SE). This is because the standard error divides the standard deviation by the square root of the sample size.
If the sample size is one, they will be the same, but a sample size of one is rarely useful.
How Can You Compute the SE From the SD?
If you have the standard error (SE) and want to compute the standard deviation (SD) from it, simply multiply it by the square root of the sample size.
Why Do We Use Standard Error Instead of Standard Deviation?
What Is the Empirical Rule, and How Does It Relate to Standard Deviation?
A normal distribution is also known as a standard bell curve, since it looks like a bell in graph form. According to the empirical rule, or the 68-95-99.7 rule, 68% of all data observed under a normal distribution will fall within one standard deviation of the mean. Similarly, 95% falls within two standard deviations and 99.7% within three.
The Bottom Line
Investors and analysts measure standard deviation as a way to estimate the potential volatility of a stock or other investment. It helps determine the level of risk to the investor that is involved. When reading an analyst’s report, the level of riskiness of an investment may be labeled «standard deviation.»
Standard error of the mean is an indication of the likely accuracy of a number. The larger the sample size, the more accurate the number should be.
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартной ошибкой называется величина, которая характеризует стандартное (среднеквадратическое) отклонение выборочного среднего. Другими словами, эту величину можно использовать для оценки точности выборочного среднего. Множество областей применения стандартной ошибки по умолчанию предполагают нормальное распределение. Если вам нужно рассчитать стандартную ошибку, перейдите к шагу 1.
-

1
Запомните определение среднеквадратического отклонения. Среднеквадратическое отклонение выборки – это мера рассеянности значения. Среднеквадратическое отклонение выборки обычно обозначается буквой s. Математическая формула среднеквадратического отклонения приведена выше.
-
2
Узнайте, что такое истинное среднее значение. Истинное среднее является средним группы чисел, включающим все числа всей группы – другими словами, это среднее всей группы чисел, а не выборки.
-
3
Научитесь рассчитывать среднеарифметическое значение. Среднеаримфетическое означает попросту среднее: сумму значений собранных данных, разделенную на количество значений этих данных.
-
4
Узнайте, что такое выборочное среднее. Когда среднеарифметическое значение основано на серии наблюдений, полученных в результате выборок из статистической совокупности, оно называется “выборочным средним”. Это среднее выборки чисел, которое описывает среднее значение лишь части чисел из всей группы. Его обозначают как:
-
5
Усвойте понятие нормального распределения. Нормальные распределения, которые используются чаще других распределений, являются симметричными, с единичным максимумом в центре – на среднем значении данных. Форма кривой подобна очертаниям колокола, при этом график равномерно опускается по обе стороны от среднего. Пятьдесят процентов распределения лежит слева от среднего, а другие пятьдесят процентов – справа от него. Рассеянность значений нормального распределения описывается стандартным отклонением.
-
6
Запомните основную формулу. Формула для вычисления стандартной ошибки приведена выше.
Реклама






-
1
Рассчитайте выборочное среднее. Чтобы найти стандартную ошибку, сначала нужно определить среднеквадратическое отклонение (поскольку среднеквадратическое отклонение s входит в формулу для вычисления стандартной ошибки). Начните с нахождения средних значений. Выборочное среднее выражается как среднее арифметическое измерений x1, x2, . . . , xn. Его рассчитывают по формуле, приведенной выше.
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
Вы сможете рассчитать выборочное среднее, подставив значения массы в формулу:
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
-
2
Вычтите выборочное среднее из каждого измерения и возведите полученное значение в квадрат. Как только вы получите выборочное среднее, вы можете расширить вашу таблицу, вычтя его из каждого измерения и возведя результат в квадрат.
- Для нашего примера расширенная таблица будет иметь следующий вид:
-
3
Найдите суммарное отклонение ваших измерений от выборочного среднего. Общее отклонение – это сумма возведенных в квадрат разностей от выборочного среднего. Чтобы определить его, сложите ваши новые значения.
- В нашем примере нужно будет выполнить следующий расчет:
Это уравнение дает сумму квадратов отклонений измерений от выборочного среднего.
- В нашем примере нужно будет выполнить следующий расчет:
-
4
Рассчитайте среднеквадратическое отклонение ваших измерений от выборочного среднего. Как только вы будете знать суммарное отклонение, вы сможете найти среднее отклонение, разделив ответ на n -1. Обратите внимание, что n равно числу измерений.
- В нашем примере было сделано 5 измерений, следовательно n – 1 будет равно 4. Расчет нужно вести следующим образом:
-
5
Найдите среднеквадратичное отклонение. Сейчас у вас есть все необходимые значения для того, чтобы воспользоваться формулой для нахождения среднеквадратичного отклонения s.
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:
Следовательно, среднеквадратичное отклонение равно 0,0071624.
Реклама
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:





-
1
Чтобы вычислить стандартную ошибку, воспользуйтесь базовой формулой со среднеквадратическим отклонением.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:
Таким образом в нашем примере стандартная ошибка (среднеквадратическое отклонение выборочного среднего) составляет 0,0032031 грамма.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:

Советы
- Стандартную ошибку и среднеквадратическое отклонение часто путают. Обратите внимание, что стандартная ошибка описывает среднеквадратическое отклонение выборочного распределения статистических данных, а не распределения отдельных значений
- В научных журналах понятия стандартной ошибки и среднеквадратического отклонения несколько размыты. Для объединения двух величин используется знак ±.
Реклама
Об этой статье
Эту страницу просматривали 48 427 раз.
Была ли эта статья полезной?
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
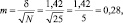 (2.1)
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: 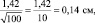 а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
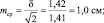
при объеме выборки N = 4 ошибка будет
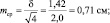
при объеме выборки N = 16 ошибка будет
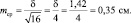
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в 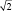 = в 1,41 раза; при выборках из 4 шт. –
= в 1,41 раза; при выборках из 4 шт. –
в 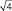 = в 2 раза; при выборках из 9 шт. – в
= в 2 раза; при выборках из 9 шт. – в 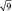 = в 3 раза и т.д.
= в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит 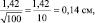 а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда 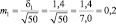 и
и 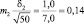 и пределы колебаний возможных значений средних будут:
и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.

Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).

Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: 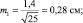
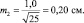 Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
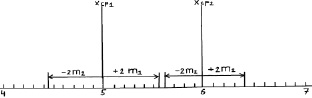
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.
Автор:
Laura McKinney
Дата создания:
7 Апрель 2021
Дата обновления:
9 Февраль 2023

Содержание
- Сравнительная таблица
- Определение стандартного отклонения
- Определение стандартной ошибки
- Ключевые различия между стандартным отклонением и стандартной ошибкой
- Вывод
 Стандартное отклонение определяется как абсолютная мера дисперсии ряда. Он уточняет стандартную величину отклонения по обе стороны от среднего. Его часто неправильно истолковывают со стандартной ошибкой, поскольку он основан на стандартном отклонении и размере выборки.
Стандартное отклонение определяется как абсолютная мера дисперсии ряда. Он уточняет стандартную величину отклонения по обе стороны от среднего. Его часто неправильно истолковывают со стандартной ошибкой, поскольку он основан на стандартном отклонении и размере выборки.
Стандартная ошибка используется для измерения статистической точности оценки. Он в основном используется в процессе проверки гипотез и оценки интервала.
Это две важные концепции статистики, которые широко используются в области исследований. Разница между стандартным отклонением и стандартной ошибкой основана на различии между описанием данных и их выводом.
Сравнительная таблица
| Основа для сравнения | Стандартное отклонение | Стандартная ошибка |
|---|---|---|
| Имея в виду | Стандартное отклонение подразумевает меру отклонения набора значений от их среднего. | Стандартная ошибка означает меру статистической точности оценки. |
| Статистика | Описательный | Логический |
| Меры | Насколько наблюдения отличаются друг от друга. | Насколько точно среднее значение выборки соответствует истинному среднему значению генеральной совокупности. |
| Распределение | Распределение наблюдения относительно нормальной кривой. | Распределение оценки относительно нормальной кривой. |
| Формула | Корень квадратный из дисперсии | Стандартное отклонение, деленное на квадратный корень из размера выборки. |
| Увеличение размера выборки | Дает более конкретную меру стандартного отклонения. | Уменьшает стандартную ошибку. |
Определение стандартного отклонения
Стандартное отклонение — это мера разброса ряда или расстояния от стандарта. В 1893 году Карл Пирсон ввел понятие стандартного отклонения, которое, несомненно, является наиболее часто используемой мерой в научных исследованиях.
Это квадратный корень из среднего квадрата отклонений от их среднего значения. Другими словами, для данного набора данных стандартное отклонение — это среднеквадратичное отклонение от среднего арифметического. Для всего населения он обозначается греческой буквой «сигма (σ)», а для выборки — латинской буквой «s».
Стандартное отклонение — это мера, которая количественно определяет степень дисперсии набора наблюдений. Чем дальше точки данных от среднего значения, тем больше отклонение в наборе данных, что означает, что точки данных разбросаны по более широкому диапазону значений и наоборот.
Определение стандартной ошибки
Вы могли заметить, что разные выборки одинакового размера, взятые из одной и той же совокупности, дадут разные значения рассматриваемой статистики, т.е. выборочное среднее. Стандартная ошибка (SE) представляет собой стандартное отклонение различных значений выборочного среднего. Он используется для сравнения выборочных средних по совокупности.
Короче говоря, стандартная ошибка статистики — это не что иное, как стандартное отклонение ее выборочного распределения. Он играет большую роль в проверке статистических гипотез и интервальной оценке. Это дает представление о точности и достоверности сметы. Чем меньше стандартная ошибка, тем больше однородность теоретического распределения и наоборот.
- Формула: Стандартная ошибка для выборочного среднего = σ / √n
Где, σ — стандартное отклонение совокупности
Ключевые различия между стандартным отклонением и стандартной ошибкой
Приведенные ниже моменты существенны с точки зрения разницы между стандартным отклонением:
- Стандартное отклонение — это мера, которая оценивает степень вариации набора наблюдений. Стандартная ошибка измеряет точность оценки, т. Е. Является мерой изменчивости теоретического распределения статистики.
- Стандартное отклонение — это описательная статистика, тогда как стандартная ошибка — это выводимая статистика.
- Стандартное отклонение измеряет, насколько отдельные значения отличаются от среднего значения. Напротив, насколько близко среднее значение выборки к среднему значению генеральной совокупности.
- Стандартное отклонение — это распределение наблюдений относительно нормальной кривой. В отличие от этого, стандартная ошибка — это распределение оценки относительно нормальной кривой.
- Стандартное отклонение определяется как квадратный корень из дисперсии. И наоборот, стандартная ошибка описывается как стандартное отклонение, деленное на квадратный корень из размера выборки.
- Когда размер выборки увеличивается, это дает более конкретную меру стандартного отклонения. В отличие от стандартной ошибки, когда размер выборки увеличивается, стандартная ошибка имеет тенденцию к уменьшению.
Вывод
В целом стандартное отклонение считается одним из лучших показателей дисперсии, который измеряет отклонение значений от центрального значения. С другой стороны, стандартная ошибка в основном используется для проверки надежности и точности оценки, поэтому чем меньше ошибка, тем выше ее надежность и точность.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD – это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM – это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.