1.2.1. Стандартная ошибка оценки по регрессии
Обозначается как
Sy,xи вычисляется по формуле
Sy,x=![]() .
.
Стандартная ошибка
оценки по регрессии показывает, на
сколько в среднем мы ошибаемся, оценивая
значение зависимой переменной по
найденному уравнению регрессии при
фиксированном значении независимой
переменной.
Квадрат стандартной
ошибки по регрессии является несмещенной
оценкой дисперсии ![]() 2,
2,
т.е.
![]() =
=
![]() =
=![]() .
.
Дисперсия ошибок
характеризует воздействие в модели
(1.1) неучтенных факторов и ошибок.
1.2.2. Оценка
значимости уравнения регрессии
(дисперсионный анализ регрессии)
Для оценки
значимости уравнения регрессии
устанавливают, соответствует ли выбранная
модель анализируемым данным. Для этого
используется дисперсионный анализ
регрессии. Основная его посылка – это
разложение общей суммы квадратов
отклонений
![]() на
на
составляющие. Известно, что такое
разложение имеет вид
![]() =
=![]() +
+![]() .
.
Второе слагаемое
в правой части разложения – это часть
общей суммы квадратов отклонений,
объясняемая действием случайных и
неучтенных факторов. Первое слагаемое
этого разложения – это часть общей
суммы квадратов отклонений, объясняемая
регрессионной зависимостью. Следовательно,
если регрессионная зависимость между
уихотсутствует, то
общая сумма квадратов отклонений
объясняется действием только случайных
факторов или ошибок, т.е.![]() =
=![]() .
.
В случае функциональной зависимости
между уихдействие
случайных факторов и ошибок отсутствует
и тогда![]() =
=![]() .
.
Будучи отнесенными к соответствующему
числу степеней свободы, эти суммы
называются средними квадратами отклонений
и служат оценками дисперсии![]() в
в
разных предположениях.
MSE= (![]() )/(n–2)
)/(n–2)
– остаточная дисперсия, которая является
оценкой![]() в
в
предположении отсутствия регрессионной
зависимости, аMSR= (![]() )/1
)/1
– аналогичная оценка без этого
предположения. Следовательно, если
регрессионная зависимость отсутствует,
то эти оценки должны быть близкими.
Сравниваются они на основе критерия
Фишера:F=MSR/MSE.
Расчетное значение
этого критерия сравнивается с критическим
значением F(с числом степеней свободы числителя,
равным 1, числом степеней свободы
знаменателя, равнымn–2,
и фиксированным уровнем значимости![]() ).
).
ЕслиF![]() <F, то гипотеза о не значимости
<F, то гипотеза о не значимости
уравнения регрессии не отклоняется, т.
е. признается, что уравнение регрессии
незначимо. В этом случае надо либо
изменить вид зависимости, либо пересмотреть
набор исходных данных.
При компьютерных
расчетах оценка значимости уравнения
регрессии осуществляется на основе
дисперсионного анализа регрессии в
таблицах вида:
Таблица
1.1
Дисперсионный
анализ регрессии
|
Источник вариации |
Суммы квадратов |
Степени свободы |
Средние квадраты |
F-отношение |
p-value |
|
Модель |
SSR |
1 |
MSR |
MSR/MSE |
Уровень |
|
Ошибки |
SSE |
n–2 |
MSE |
значимости |
|
|
общая |
SST |
n–1 |
Здесь p-value– это вероятность выполнения неравенстваF<F![]() ,
,
т. е. того, что расчетное значениеF-статистики попало в
область принятия гипотезы. Если эта
вероятность мала (меньше![]() ),
),
то нулевая гипотеза отклоняется.
Стандартная ошибка оценки по уравнению регрессии
Стандартная ошибка оценки, также известная как стандартная ошибка уравнения регрессии, определяется следующим образом (см. (6.23)) [c.280]
Стандартная ошибка уравнения регрессии, Эта статистика SEE представляет собой стандартное отклонение фактических значений теоретических значений У. [c.650]
Что такое стандартная ошибка уравнения регрессии ).Какие допущения лежат в основе парной регрессии 10. Что такое множественная регрессия [c.679]
Следующий этап корреляционного анализа — расчет уравнения связи (регрессии). Решение проводится обычно шаговым способом. Сначала в расчет принимается один фактор, который оказывает наиболее значимое влияние на результативный показатель, потом второй, третий и т.д. И на каждом шаге рассчитываются уравнение связи, множественный коэффициент корреляции и детерминации, /»»-отношение (критерий Фишера), стандартная ошибка и другие показатели, с помощью которых оценивается надежность уравнения связи. Величина их на каждом шаге сравнивается с предыдущей. Чем выше величина коэффициентов множественной корреляции, детерминации и критерия Фишера и чем ниже величина стандартной ошибки, тем точнее уравнение связи описывает зависимости, сложившиеся между исследуемыми показателями. Если добавление следующих факторов не улучшает оценочных показателей связи, то надо их отбросить, т.е. остановиться на том уравнении, где эти показатели наиболее оптимальны. [c.149]
Прогнозное значение ур определяется путем подстановки в уравнение регрессии ух =а + Ьх соответствующего (прогнозного) значения хр. Вычисляется средняя стандартная ошибка прогноза [c.9]
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка ть и та. [c.53]
В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур) значение как точечный прогноз ух при хр =хь т. е. путем подстановки в уравнение регрессии 5 = а + b х соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ух, т. е. Шух, и соответственно интервальной оценкой прогнозного значения (у ) [c.57]
Чтобы понять, как строится формула для определения величин стандартной ошибки ух, обратимся к уравнению линейной регрессии ух = а + b х. Подставим в это уравнение выражение параметра а [c.57]
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора. [c.61]
В скобках указаны стандартные ошибки параметров уравнения регрессии. [c.327]
В скобках указаны стандартные ошибки параметров уравнения регрессии. Определим по этому уравнению расчетные значения >>, ,, а затем параметры уравнения регрессии (7.44). Получим следующие результаты [c.328]
На каждом шаге рассматриваются уравнение регрессии, коэффициенты корреляции и детерминации, F-критерий, стандартная ошибка оценки и другие оценочные показатели. После каждого шага перечисленные оценочные показатели сравниваются с [c.39]
Проблемы с методологией регрессии. Методология регрессии — это традиционный способ уплотнения больших массивов данных и их сведения в одно уравнение, отражающее связь между мультипликаторами РЕ и финансовыми фундаментальными переменными. Но данный подход имеет свои ограничения. Во-первых, независимые переменные коррелируют друг с другом . Например, как видно из таблицы 18,2, обобщающей корреляцию между коэффициентами бета, ростом и коэффициентами выплат для всех американских фирм, быстрорастущие фирмы обычно имеют большой риск и низкие коэффициенты выплат. Обратите внимание на отрицательную корреляцию между коэффициентами выплат и ростом, а также на положительную корреляцию между коэффициентами бета и ростом. Эта мультиколлинеарность делает мультипликаторы регрессии ненадежными (увеличивает стандартную ошибку) и, возможно, объясняет ошибочные знаки при коэффициентах и крупные изменения этих мультипликаторов в разные периоды. Во-вторых, регрессия основывается на линейной связи между мультипликаторами РЕ и фундаментальными переменными, и данное свойство, по всей вероятности, неадекватно. Анализ остаточных явлений, связанных с корреляцией, может привести к трансформациям независимых переменных (их квадратов или натуральных логарифмов), которые в большей степени подходят для объяснения мультипликаторов РЕ. В-третьих, базовая связь между мультипликаторами РЕ и финансовыми переменными сама по себе не является стабильной. Если же эта связь смещается из года в год, то прогнозы, полученные из регрессионного уравнения, могут оказаться ненадежными для более длительных периодов времени. По всем этим причинам, несмотря на полезность регрессионного анализа, его следует рассматривать только как еще один инструмент поиска подлинного значения ценности. [c.649]
На рисунке 16.6 явно просматривается четкая линейная зависимость объема частного потребления от величины располагаемого дохода. Уравнение парной линейной регрессии, оцененное по этим данным, имеет вид С= -217,6 + 1,007 Yf Стандартные ошибки для свободного члена и коэффициента парной регрессии равны, соответственно, 28,4 и 0,012, а -статистики — -7,7 и 81 9. Обе они по модулю существенно превышают 3, следовательно, их статистическая значимость весьма высока. Впрочем, несмотря на то, что здесь удалось оценить статистически значимую линейную функцию потребления, в ней нарушены сразу две предпосылки Кейнса — уровень автономного потребления С0 оказался отрицательным, а предель- [c.304]
Стандартные ошибки свободного члена и коэффициента регрессии равны, соответственно, 84,7 и 0,46 их /-статистики — (-21,4 и 36,8). По абсолютной величине /-статистики намного превышают 3, и это свидетельствует о высокой надежности оцененных коэффициентов. Коэффициент детерминации /Р уравнения равен 0,96, то есть объяснено 96% дисперсии объема потребления. И в то же время уже по рисунку видно, что оцененная рефессия не очень хоро- [c.320]
Эта стандартная ошибка S у, равная 0,65, указывает отклонение фактических данных от прогнозируемых на основании использования воздействующих факторов j i и Х2 (влияние среди покупателей бабушек с внучками и высокопрофессионального вклада Шарика). В то же время мы располагаем обычным стандартным отклонением Sn, равным 1,06 (см. табл.8), которое было рассчитано для одной переменной, а именно сами текущие значения уги величина среднего арифметического у, которое равно 6,01. Легко видеть, что S у tTa6n. В противном случае доверять полученной оценке параметра нет оснований. [c.139]
Для определения профиля посетителей магазинов местного торгового центра, не имеющих определенной цели (browsers), маркетологи использовали три набора независимых переменных демографические, покупательское поведение психологические. Зависимая переменная представляет собой индекс посещения магазина без определенной цели, индекс (browsing index). Методом ступенчатой включающей все три набора переменных, выявлено, что демографические факторы — наиболее сильные предикторы, определяющие поведение покупателей, не преследующих конкретных целей. Окончательное уравнение регрессии, 20 из 36 возможных переменных, включало все демографические переменные. В следующей таблице приведены коэффициенты регрессии, стандартные ошибки коэффициентов, а также их уровни значимости. [c.668]
Смотреть страницы где упоминается термин Стандартная ошибка уравнения регрессии
Маркетинговые исследования Издание 3 (2002) — [ c.650 ]
Лекции по дисциплине «Эконометрика» (заочное отделение) (стр. 2 )
 |
Из за большого объема этот материал размещен на нескольких страницах: 1 2 3 4 |

Параметр формально является значением Y при X = 0. Он может не иметь экономического содержания. Интерпретировать можно лишь знак при параметре . Если > 0, то относительное изменение результата происходит медленнее, чем изменение фактора. Иными словами, вариация по фактору X выше вариации для результата Y. Также считают, что включает в себя неучтенные в модели факторы.
По итогам 2008 года были собраны данные по прибыли и оборачиваемости оборотных средств 500 торговых предприятий г. Челябинска. Результаты наблюдения сведены в таблицу.
Годовая прибыль предприятия, млн. руб.
Годовая оборачиваемость оборотных средств, раз
Требуется построить зависимость прибыли предприятий от оборачиваемости оборотных средств и оценить качество полученного уравнения.
Пусть y – прибыль предприятия, x – оборачиваемость оборотных средств.
На основе исходных данных были рассчитаны следующие показатели:
Уровень доверия возьмем q=0,95 или 95%.

1. Стандартные ошибки оценок , . намного больше =0,39, следовательно, низкая точность коэффициента . очень мала по сравнению с , следовательно, высокая точность коэффициента .
2. Интервальные оценки коэффициентов уравнения регрессии.
n – 2 = 500 – 2 = 498;
α:  →
→  → очень низкая точность коэффициента;
→ очень низкая точность коэффициента;
β:  →
→  → высокая точность коэффициента.
→ высокая точность коэффициента.
3. Значимость коэффициентов регрессии.
 = >1,96 → коэффициент значим;
= >1,96 → коэффициент значим;
 = >1,96 → коэффициент значим.
= >1,96 → коэффициент значим.
4. Стандартная ошибка регрессии. Se=0,91, по сравнению со средним значением =34,5 ошибка невысокая, точность уравнения хорошая.
5. Коэффициент детерминации. R2 = rxy2=0,782=0,6084 не очень близко к 1, качество подгонки среднее.
6. Средняя ошибка аппроксимации. A=11%, качество подгонки уравнения среднее.
Экономическая интерпретация: при увеличении оборачиваемости оборотных средств предприятия на 1 раз в год средняя годовая прибыль увеличится на 5,86 млн. руб.
Тема 6. Нелинейная парная регрессия
Часто на практике между зависимой и независимыми переменными существует нелинейная форма взаимосвязи. В этом случае существует два выхода:
1) подобрать к анализируемым переменным преобразование, которое бы позволило представить существующую зависимость в виде линейной функции;
2) применить нелинейный метод наименьших квадратов.
Основные нелинейные регрессионные модели и приведение их к линейной форме
1. Экспоненциальное уравнение  .
.
Если прологарифмировать левую и правую части данного уравнения, то получится
 .
.
Это уравнение является линейным, но вместо y в левой части стоит ln y.
В данном случае параметр β1 имеет следующий экономический смысл: при увеличении переменной x на единицу переменная y в среднем увеличится примерно на 100·β% (более точно: y увеличится в  раз).
раз).
2. Логарифмическое уравнение  .
.
Переход к линейному уравнению осуществляется заменой переменной x на X=lnx..
Параметр β1 имеет следующий экономический смысл: для увеличения y на единицу необходимо увеличить переменную x в  раз, т. е. примерно на
раз, т. е. примерно на  .
.
3. Гиперболическое уравнение  .
.
В этом случае необходимо сделать замену переменных x на  . Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
. Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
4. Степенное уравнение  .
.
Прологарифмировав левую и правую части данного уравнения, получим
 .
.
Заменив соответствующие ряды их логарифмами, получится линейная регрессия.
Экономический смысл параметра β1: если значение переменной x увеличить на 1%, то y увеличится на β1%.
5. Показательное уравнение  (β1>0, β1≠1).
(β1>0, β1≠1).
Прологарифмировав левую и правую части уравнения, получим
 .
.
Проведя замены Y=ln y и B1=ln β1, получится линейная регрессия.
Экономический смысл параметра β1: при увеличении переменной x на единицу переменная y в среднем увеличится в β1 раз.
Тема 7. Множественная линейная регрессия: определение и оценка параметров
1. Понятие множественной линейной регрессии
Модель множественной линейной регрессии является обобщением парной линейной регрессии и представляет собой следующее выражение:
 , t=1. n,
, t=1. n,
где yt – значение зависимой переменной для наблюдения t,
xit – значение i-й независимой переменной для наблюдения t,
εt – значение случайной ошибки для наблюдения t,
n – число наблюдений,
m – число независимых переменных x.
2. Матричная форма записи множественной линейной регрессии
Уравнение множественной линейной регрессии можно записать в матричной форме:
 ,
,
где  ,
,  ,
,  ,
,  .
.
3. Основные предположения
2.  для всех наблюдений;
для всех наблюдений;
3.  = const для всех наблюдений;
= const для всех наблюдений;
4.  ;
;
В случае выполнения вышеперечисленных гипотез модель называется нормальной линейной регрессионной.
4. Метод наименьших квадратов
Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК):  .
.
Чтобы найти минимум этой функции необходимо вычислить производные по каждому из параметров и приравнять их к нулю, в результате получается система уравнений, решение которой в матричном виде следующее:
 →
→  .
.
 ,
,

5. Теорема Гаусса-Маркова
Если выполнены предположения 1-5 из пункта 3, то оценки , полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе линейных несмещенных оценок, то есть являются несмещенными, состоятельными и эффективными.
Тема 8. Множественная линейная регрессия: оценка качества
1. Общая схема проверки качества парной регрессии
Адекватность модели – остатки должны удовлетворять условиям теоремы Гаусса-Маркова.
Основные показатели качества коэффициентов регрессии:
1. Стандартные ошибки оценок (анализ точности определения оценок).
2. Интервальные оценки коэффициентов уравнения регрессии (построение доверительных интервалов).
3. Значимость коэффициентов регрессии (проверка гипотез относительно коэффициентов регрессии).
Основные показатели качества уравнения регрессии в целом:
1. Стандартная ошибка регрессии Se (анализ точности уравнения регрессии).
2. Значимость уравнения регрессии в целом (проверка гипотезы относительно всех коэффициентов регрессии).
3. Коэффициент детерминации R2 (проверка качества подгонки уравнения к исходным данным).
4. Скорректированный коэффициент детерминации R2adj (проверка качества подгонки уравнения к исходным данным).
5. Средняя ошибка аппроксимации (проверка качества подгонки уравнения к эмпирическим данным).
2. Стандартные ошибки оценок
Стандартные ошибки коэффициентов регрессии – это средние квадратические отклонения коэффициентов регрессии от их истинных значений.
 ,
,
где 
 — диагональные элементы матрицы
— диагональные элементы матрицы  ,
,
 .
.
Стандартная ошибка является оценкой среднего квадратического отклонения коэффициента регрессии от его истинного значения. Чем меньше стандартная ошибка тем точнее оценка.
3. Интервальные оценки коэффициентов множественной линейной регрессии
Доверительные интервалы для коэффициентов регрессии определяются следующим образом:
1. Выбирается уровень доверия q (0,9; 0,95 или 0,99).
2. Рассчитывается уровень значимости g = 1 – q.
3. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
4. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
5. Рассчитывается доверительный интервал для параметра  :
:
 .
.
Доверительный интервал показывает, что истинное значение параметра с вероятностью q находится в данных пределах.
Чем меньше доверительный интервал относительно коэффициента, тем точнее полученная оценка.
4. Значимость коэффициентов регрессии
Процедура оценки значимости коэффициентов осуществляется аналогичной парной регрессии следующим образом:
1. Рассчитывается значение t-статистики для коэффициента регрессии по формуле  .
.
2. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
3. Рассчитывается уровень значимости g = 1 – q.
4. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
5. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
6. Если  , то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
, то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
t-тесты обеспечивают проверку значимости предельного вклада каждой переменной при допущении, что все остальные переменные уже включены в модель.
5. Стандартная ошибка регрессии
Стандартная ошибка регрессии Se показывает, насколько в среднем фактические значения зависимой переменной y отличаются от ее расчетных значений
 .
.
Используется как основная величина для измерения качества модели (чем она меньше, тем лучше).
Значения Se в однотипных моделях с разным числом наблюдений и (или) переменных сравнимы.
6. Оценка значимости уравнения регрессии в целом
Уравнение значимо, если есть достаточно высокая вероятность того, что существует хотя бы один коэффициент, отличный от нуля.
Имеются альтернативные гипотезы:
Если принимается гипотеза H0, то уравнение статистически незначимо. В противном случае говорят, что уравнение статистически значимо.
Значимость уравнения регрессии в целом осуществляется с помощью F-статистики.
Оценка значимости уравнения регрессии в целом основана на тождестве дисперсионного анализа:
 Þ
Þ
TSS – общая сумма квадратов отклонений
ESS – объясненная сумма квадратов отклонений
RSS – необъясненная сумма квадратов отклонений
F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы)

n – число выборочных наблюдений, m – число независимых переменных.
При отсутствии линейной зависимости между зависимой и независимой переменными F-статистика имеет F-распределение Фишера-Снедекора со степенями свободы k1 = m, k2 = n – m –1.
Процедура оценки значимости уравнения осуществляется следующим образом:
7. Рассчитывается значение F-статистики по формуле  .
.
8. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
9. Рассчитывается уровень значимости g = 1 – q.
10. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
11. Определяется критическое значение F-статистики (Fкр) по таблицам распределения Фишера на основе g и n – m – 1.
12. Если  , то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
, то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
В парной регрессии F-статистика равна квадрату t-статистики:  , а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
, а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
Качество оценки уравнения можно проверить путем расчета коэффициента детерминации R2, который показывает степень соответствия найденного уравнения экспериментальным данным.
 .
.
Коэффициент R2 показывает долю дисперсии переменной y, объясненную регрессией, в общей дисперсии y.
Коэффициент детерминации лежит в пределах 0 £ R2 £ 1.
Чем ближе R2 к 1, тем выше качество подгонки уравнения к статистическим данным.
Чем ближе R2 к 0, тем ниже качество подгонки уравнения к статистическим данным.
Коэффициенты R2 в разных моделях с разным числом наблюдений и переменных несравнимы.
8. Скорректированный коэффициент детерминации R2adj
Низкое значение R2 не свидетельствует о плохом качестве модели, и может объясняться наличием существенных факторов, не включенных в модель
R2 всегда увеличивается с включением новой переменной. Поэтому его необходимо корректировать, и рассчитывают скорректированный коэффициент детерминации

Если R2adj выходит за пределы интервала [0;1], то его использовать нельзя.
Если при добавлении новой переменной в модель увеличивается не только R2, но и R2adj, то можно считать, что вклад этой переменной в повышение качества модели существенен.
9. Средняя ошибка аппроксимации
Средняя ошибка аппроксимации (средняя абсолютная процентная ошибка) – показывает в процентах среднее отклонение расчетных значений зависимой переменной от фактических значений yi

Если A ≤ 10%, то качество подгонки уравнения считается хорошим. Чем меньше значение A, тем лучше.
10. Использование показателей качества коэффициентов и уравнения регрессии для интерпретации и корректировки модели
В случае незначимости уравнения, необходимо устранить ошибки модели. Наиболее распространенными являются следующие ошибки:
— неправильно выбран вид функции регрессии;
— в модель включены незначимые регрессоры;
— в модели отсутствуют значимые регрессоры.
После устранения ошибок требуется заново оценить параметры уравнения и его качество, продолжая этот процесс до тех пор, пока качество уравнения не станет удовлетворительным. Если после поделанных процедур, мы не достигли требуемого уровня значимости, то необходимо устранять другие ошибки (спецификации, классификации, наблюдения и т. д., см. тему 3, п. 6).
11. Интерпретация множественной линейной регрессии
Коэффициент регрессии при переменной xi показывает, на сколько увеличится среднее значение зависимой переменной y при увеличении xi на 1, при условии постоянства других переменных.
В апреле 2006 года были собраны данные по стоимости 200 двухкомнатных квартир в Металлургическом районе г. Челябинска, их жилой площади, площади кухни и расстоянии до центра города (пл. Революции). Результаты наблюдения сведены в таблицу.
Оценка результатов линейной регрессии
Введение
Модель линейной регрессии
Итак, пусть есть несколько независимых случайных величин X1, X2, . Xn (предикторов) и зависящая от них величина Y (предполагается, что все необходимые преобразования предикторов уже сделаны). Более того, мы предполагаем, что зависимость линейная, а ошибки рапределены нормально, то есть 
где I — единичная квадратная матрица размера n x n.
Итак, у нас есть данные, состоящие из k наблюдений величин Y и Xi и мы хотим оценить коэффициенты. Стандартным методом для нахождения оценок коэффициентов является метод наименьших квадратов. И аналитическое решение, которое можно получить, применив этот метод, выглядит так: 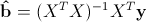
где b с крышкой — оценка вектора коэффициентов, y — вектор значений зависимой величины, а X — матрица размера k x n+1 (n — количество предикторов, k — количество наблюдений), у которой первый столбец состоит из единиц, второй — значения первого предиктора, третий — второго и так далее, а строки соответствуют имеющимся наблюдениям.
Функция summary.lm() и оценка получившихся результатов
Теперь рассмотрим пример построения модели линейной регрессии в языке R:
Таблица gala содержит некоторые данные о 30 Галапагосских островах. Мы будем рассматривать модель, где Species — количество разных видов растений на острове линейно зависит от нескольких других переменных.
Рассмотрим вывод функции summary.lm().
Сначала идет строка, которая напоминает, как строилась модель.
Затем идет информация о распределении остатков: минимум, первая квартиль, медиана, третья квартиль, максимум. В этом месте было бы полезно не только посмотреть на некоторые квантили остатков, но и проверить их на нормальность, например тестом Шапиро-Уилка.
Далее — самое интересное — информация о коэффициентах. Здесь потребуется немного теории.
Сначала выпишем следующий результат: 
при этом сигма в квадрате с крышкой является несмещенной оценкой для реальной сигмы в квадрате. Здесь b — реальный вектор коэффициентов, а эпсилон с крышкой — вектор остатков, если в качестве коэффициентов взять оценки, полученные методом наименьших квадратов. То есть при предположении, что ошибки распределены нормально, вектор коэффициентов тоже будет распределен нормально вокруг реального значения, а его дисперсию можно несмещенно оценить. Это значит, что можно проверять гипотезу на равенство коэффициентов нулю, а следовательно проверять значимость предикторов, то есть действительно ли величина Xi сильно влияет на качество построенной модели.
Для проверки этой гипотезы нам понадобится следующая статистика, имеющая распределение Стьюдента в том случае, если реальное значение коэффициента bi равно 0: 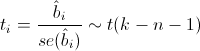
где
 — стандартная ошибка оценки коэффициента, а t(k-n-1) — распределение Стьюдента с k-n-1 степенями свободы.
— стандартная ошибка оценки коэффициента, а t(k-n-1) — распределение Стьюдента с k-n-1 степенями свободы.
Теперь все готово для продолжения разбора вывода функции summary.lm().
Итак, далее идут оценки коэффициентов, полученные методом наименьших квадратов, их стандартные ошибки, значения t-статистики и p-значения для нее. Обычно p-значение сравнивается с каким-нибудь достаточно малым заранее выбранным порогом, например 0.05 или 0.01. И если значение p-статистики оказывается меньше порога, то гипотеза отвергается, если же больше, ничего конкретного, к сожалению, сказать нельзя. Напомню, что в данном случае, так как распределение Стьюдента симметричное относительно 0, то p-значение будет равно 1-F(|t|)+F(-|t|), где F — функция распределения Стьюдента с k-n-1 степенями свободы. Также, R любезно обозначает звездочками значимые коэффициенты, для которых p-значение достаточно мало. То есть, те коэффициенты, которые с очень малой вероятностью равны 0. В строке Signif. codes как раз содержится расшифровка звездочек: если их три, то p-значение от 0 до 0.001, если две, то оно от 0.001 до 0.01 и так далее. Если никаких значков нет, то р-значение больше 0.1.
В нашем примере можно с большой уверенностью сказать, что предикторы Elevation и Adjacent действительно с большой вероятностью влияют на величину Species, а вот про остальные предикторы ничего определенного сказать нельзя. Обычно, в таких случаях предикторы убирают по одному и смотрят, насколько изменяются другие показатели модели, например BIC или Adjusted R-squared, который будет разобран далее.
Значение Residual standart error соответствует просто оценке сигмы с крышкой, а степени свободы вычисляются как k-n-1.
А теперь самая важные статистики, на которые в первую очередь стоит смотреть: R-squared и Adjusted R-squared: 
где Yi — реальные значения Y в каждом наблюдении, Yi с крышкой — значения, предсказанные моделью, Y с чертой — среднее по всем реальным значениям Yi. 
Начнем со статистики R-квадрат или, как ее иногда называют, коэффициента детерминации. Она показывает, насколько условная дисперсия модели отличается от дисперсии реальных значений Y. Если этот коэффициент близок к 1, то условная дисперсия модели достаточно мала и весьма вероятно, что модель неплохо описывает данные. Если же коэффициент R-квадрат сильно меньше, например, меньше 0.5, то, с большой долей уверенности модель не отражает реальное положение вещей.
Однако, у статистики R-квадрат есть один серьезный недостаток: при увеличении числа предикторов эта статистика может только возрастать. Поэтому, может показаться, что модель с большим количеством предикторов лучше, чем модель с меньшим, даже если все новые предикторы никак не влияют на зависимую переменную. Тут можно вспомнить про принцип бритвы Оккама. Следуя ему, по возможности, стоит избавляться от лишних предикторов в модели, поскольку она становится более простой и понятной. Для этих целей была придумана статистика скорректированный R-квадрат. Она представляет собой обычный R-квадрат, но со штрафом за большое количество предикторов. Основная идея: если новые независимые переменные дают большой вклад в качество модели, значение этой статистики растет, если нет — то наоборот уменьшается.
Для примера рассмотрим ту же модель, что и раньше, но теперь вместо пяти предикторов оставим два:
Как можно увидеть, значение статистики R-квадрат снизилось, однако значение скорректированного R-квадрат даже немного возросло.
Теперь проверим гипотезу о равенстве нулю всех коэффициентов при предикторах. То есть, гипотезу о том, зависит ли вообще величина Y от величин Xi линейно. Для этого можно использовать следующую статистику, которая, если гипотеза о равенстве нулю всех коэффициентов верна, имеет распределение Фишера c n и k-n-1 степенями свободы: 
Значение F-статистики и p-значение для нее находятся в последней строке вывода функции summary.lm().
Заключение
В этой статье были описаны стандартные методы оценки значимости коэффициентов и некоторые критерии оценки качества построенной линейной модели. К сожалению, я не касался вопроса рассмотрения распределения остатков и проверки его на нормальность, поскольку это увеличило бы статью еще вдвое, хотя это и достаточно важный элемент проверки адекватности модели.
Очень надеюсь что мне удалось немного расширить стандартное представление о линейной регрессии, как об алгоритме который просто оценивает некоторый вид зависимости, и показать, как можно оценить его результаты.
источники:
http://pandia.ru/text/78/101/1285-2.php
http://habr.com/ru/post/195146/
This article is to tell you the whole interpretation of the regression summary table. There are many statistical softwares that are used for regression analysis like Matlab, Minitab, spss, R etc. but this article uses python. The Interpretation is the same for other tools as well. This article needs the basics of statistics including basic knowledge of regression, degrees of freedom, standard deviation, Residual Sum Of Squares(RSS), ESS, t statistics etc.
In regression there are two types of variables i.e. dependent variable (also called explained variable) and independent variable (explanatory variable).
The regression line used here is,

The summary table of the regression is given below.
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.669
Model: OLS Adj. R-squared: 0.667
Method: Least Squares F-statistic: 299.2
Date: Mon, 01 Mar 2021 Prob (F-statistic): 2.33e-37
Time: 16:19:34 Log-Likelihood: -88.686
No. Observations: 150 AIC: 181.4
Df Residuals: 148 BIC: 187.4
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -3.2002 0.257 -12.458 0.000 -3.708 -2.693
x1 0.7529 0.044 17.296 0.000 0.667 0.839
==============================================================================
Omnibus: 3.538 Durbin-Watson: 1.279
Prob(Omnibus): 0.171 Jarque-Bera (JB): 3.589
Skew: 0.357 Prob(JB): 0.166
Kurtosis: 2.744 Cond. No. 43.4
==============================================================================
Dependent variable: Dependent variable is one that is going to depend on other variables. In this regression analysis Y is our dependent variable because we want to analyse the effect of X on Y.
Model: The method of Ordinary Least Squares(OLS) is most widely used model due to its efficiency. This model gives best approximate of true population regression line. The principle of OLS is to minimize the square of errors ( ∑ei2 ).
Number of observations: The number of observation is the size of our sample, i.e. N = 150.
Degree of freedom(df) of residuals:
Degree of freedom is the number of independent observations on the basis of which the sum of squares is calculated.
D.f Residuals = 150 – (1+1) = 148
Degree of freedom(D.f) is calculated as,
Degrees of freedom, D . f = N – K
Where, N = sample size(no. of observations) and K = number of variables + 1
Df of model:
Df of model = K – 1 = 2 – 1 = 1 ,
Where, K = number of variables + 1
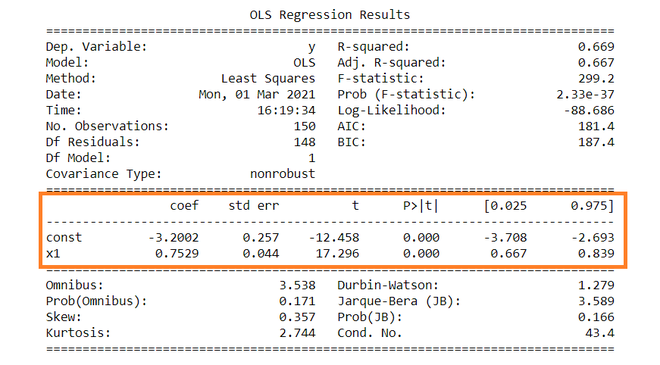
Constant term: The constant terms is the intercept of the regression line. From regression line (eq…1) the intercept is -3.002. In regression we omits some independent variables that do not have much impact on the dependent variable, the intercept tells the average value of these omitted variables and noise present in model.
Coefficient term: The coefficient term tells the change in Y for a unit change in X i.e if X rises by 1 unit then Y rises by 0.7529. If you are familiar with derivatives then you can relate it as the rate of change of Y with respect to X .
Standard error of parameters: Standard error is also called the standard deviation. Standard error shows the sampling variability of these parameters. Standard error is calculated by as –
Standard error of intercept term (b1):

Standard error of coefficient term(b2):

Here, σ2 is the Standard error of regression (SER) . And σ2 is equal to RSS( Residual Sum Of Square i.e ∑ei2 ).
t – statistics:
In theory, we assume that error term follows the normal distribution and because of this the parameters b1 and b2 also have normal distributions with variance calculated in above section.
That is ,
- b1 ∼ N(B1, σb12)
- b2 ∼ N(B2 , σb22)
Here B1 and B2 are true means of b1 and b2.
t – statistics are calculated by assuming following hypothesis –
- H0 : B2 = 0 ( variable X has no influence on Y)
- Ha : B2 ≠ 0 (X has significant impact on Y)
Calculations for t – statistics :
t = ( b1 – B1 ) / s.e (b1)
From summary table , b1 = -3.2002 and se(b1) = 0.257, So,
t = (-3.2002 – 0) / 0.257 = -12.458
Similarly, b2 = 0.7529 , se(b2) = 0.044
t = (0.7529 – 0) / 0.044 = 17.296
p – values:
In theory, we read that p-value is the probability of obtaining the t statistics at least as contradictory to H0 as calculated from assuming that the null hypothesis is true. In the summary table, we can see that P-value for both parameters is equal to 0. This is not exactly 0, but since we have very larger statistics (-12.458 and 17.296) p-value will be approximately 0.
If you know about significance levels then you can see that we can reject the null hypothesis at almost every significance level.
Confidence intervals:
There are many approaches to test the hypothesis, including the p-value approach mentioned above. The confidence interval approach is one of them. 5% is the standard significance level (∝) at which C.I’s are made.
C.I for B1 is ( b1 – t∝/2 s.e(b1) , b1 + t∝/2 s.e(b1) )
Since ∝ = 5 %, b1 = -3.2002, s.e(b1) =0.257 , from t table , t0.025,148 = 1.655,
After putting values the C.I for B1 is approx. ( -3.708 , -2.693 ). Same can be done for b2 as well.
While calculating p values we rejected the null hypothesis we can see same in C.I as well. Since 0 does not lie in any of the intervals so we will reject the null hypothesis.

R – squared value:
R2 is the coefficient of determination that tells us that how much percentage variation independent variable can be explained by independent variable. Here, 66.9 % variation in Y can be explained by X. The maximum possible value of R2 can be 1, means the larger the R2 value better the regression.
F – statistic:
F test tells the goodness of fit of a regression. The test is similar to the t-test or other tests we do for the hypothesis. The F – statistic is calculated as below –

Inserting the values of R2, n and k, F = (0.669/1) / (0.331/148) = 229.12.
You can calculate the probability of F >229.1 for 1 and 148 df, which comes to approx. 0. From this, we again reject the null hypothesis stated above.
The remaining terms are not often used. Terms like Skewness and Kurtosis tells about the distribution of data. Skewness and kurtosis for the normal distribution are 0 and 3 respectively. Jarque-Bera test is used for checking whether an error has normal distribution or not.
This article is to tell you the whole interpretation of the regression summary table. There are many statistical softwares that are used for regression analysis like Matlab, Minitab, spss, R etc. but this article uses python. The Interpretation is the same for other tools as well. This article needs the basics of statistics including basic knowledge of regression, degrees of freedom, standard deviation, Residual Sum Of Squares(RSS), ESS, t statistics etc.
In regression there are two types of variables i.e. dependent variable (also called explained variable) and independent variable (explanatory variable).
The regression line used here is,
The summary table of the regression is given below.
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.669
Model: OLS Adj. R-squared: 0.667
Method: Least Squares F-statistic: 299.2
Date: Mon, 01 Mar 2021 Prob (F-statistic): 2.33e-37
Time: 16:19:34 Log-Likelihood: -88.686
No. Observations: 150 AIC: 181.4
Df Residuals: 148 BIC: 187.4
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -3.2002 0.257 -12.458 0.000 -3.708 -2.693
x1 0.7529 0.044 17.296 0.000 0.667 0.839
==============================================================================
Omnibus: 3.538 Durbin-Watson: 1.279
Prob(Omnibus): 0.171 Jarque-Bera (JB): 3.589
Skew: 0.357 Prob(JB): 0.166
Kurtosis: 2.744 Cond. No. 43.4
==============================================================================
Dependent variable: Dependent variable is one that is going to depend on other variables. In this regression analysis Y is our dependent variable because we want to analyse the effect of X on Y.
Model: The method of Ordinary Least Squares(OLS) is most widely used model due to its efficiency. This model gives best approximate of true population regression line. The principle of OLS is to minimize the square of errors ( ∑ei2 ).
Number of observations: The number of observation is the size of our sample, i.e. N = 150.
Degree of freedom(df) of residuals:
Degree of freedom is the number of independent observations on the basis of which the sum of squares is calculated.
D.f Residuals = 150 – (1+1) = 148
Degree of freedom(D.f) is calculated as,
Degrees of freedom, D . f = N – K
Where, N = sample size(no. of observations) and K = number of variables + 1
Df of model:
Df of model = K – 1 = 2 – 1 = 1 ,
Where, K = number of variables + 1
Constant term: The constant terms is the intercept of the regression line. From regression line (eq…1) the intercept is -3.002. In regression we omits some independent variables that do not have much impact on the dependent variable, the intercept tells the average value of these omitted variables and noise present in model.
Coefficient term: The coefficient term tells the change in Y for a unit change in X i.e if X rises by 1 unit then Y rises by 0.7529. If you are familiar with derivatives then you can relate it as the rate of change of Y with respect to X .
Standard error of parameters: Standard error is also called the standard deviation. Standard error shows the sampling variability of these parameters. Standard error is calculated by as –
Standard error of intercept term (b1):
Standard error of coefficient term(b2):
Here, σ2 is the Standard error of regression (SER) . And σ2 is equal to RSS( Residual Sum Of Square i.e ∑ei2 ).
t – statistics:
In theory, we assume that error term follows the normal distribution and because of this the parameters b1 and b2 also have normal distributions with variance calculated in above section.
That is ,
- b1 ∼ N(B1, σb12)
- b2 ∼ N(B2 , σb22)
Here B1 and B2 are true means of b1 and b2.
t – statistics are calculated by assuming following hypothesis –
- H0 : B2 = 0 ( variable X has no influence on Y)
- Ha : B2 ≠ 0 (X has significant impact on Y)
Calculations for t – statistics :
t = ( b1 – B1 ) / s.e (b1)
From summary table , b1 = -3.2002 and se(b1) = 0.257, So,
t = (-3.2002 – 0) / 0.257 = -12.458
Similarly, b2 = 0.7529 , se(b2) = 0.044
t = (0.7529 – 0) / 0.044 = 17.296
p – values:
In theory, we read that p-value is the probability of obtaining the t statistics at least as contradictory to H0 as calculated from assuming that the null hypothesis is true. In the summary table, we can see that P-value for both parameters is equal to 0. This is not exactly 0, but since we have very larger statistics (-12.458 and 17.296) p-value will be approximately 0.
If you know about significance levels then you can see that we can reject the null hypothesis at almost every significance level.
Confidence intervals:
There are many approaches to test the hypothesis, including the p-value approach mentioned above. The confidence interval approach is one of them. 5% is the standard significance level (∝) at which C.I’s are made.
C.I for B1 is ( b1 – t∝/2 s.e(b1) , b1 + t∝/2 s.e(b1) )
Since ∝ = 5 %, b1 = -3.2002, s.e(b1) =0.257 , from t table , t0.025,148 = 1.655,
After putting values the C.I for B1 is approx. ( -3.708 , -2.693 ). Same can be done for b2 as well.
While calculating p values we rejected the null hypothesis we can see same in C.I as well. Since 0 does not lie in any of the intervals so we will reject the null hypothesis.
R – squared value:
R2 is the coefficient of determination that tells us that how much percentage variation independent variable can be explained by independent variable. Here, 66.9 % variation in Y can be explained by X. The maximum possible value of R2 can be 1, means the larger the R2 value better the regression.
F – statistic:
F test tells the goodness of fit of a regression. The test is similar to the t-test or other tests we do for the hypothesis. The F – statistic is calculated as below –
Inserting the values of R2, n and k, F = (0.669/1) / (0.331/148) = 229.12.
You can calculate the probability of F >229.1 for 1 and 148 df, which comes to approx. 0. From this, we again reject the null hypothesis stated above.
The remaining terms are not often used. Terms like Skewness and Kurtosis tells about the distribution of data. Skewness and kurtosis for the normal distribution are 0 and 3 respectively. Jarque-Bera test is used for checking whether an error has normal distribution or not.
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартная ошибка оценки служит для того, чтобы выяснить, как линия регрессии соответствует набору данных. Если у вас есть набор данных, полученных в результате измерения, эксперимента, опроса или из другого источника, создайте линию регрессии, чтобы оценить дополнительные данные. Стандартная ошибка оценки характеризует, насколько верна линия регрессии.
-

1
Создайте таблицу с данными. Таблица должна состоять из пяти столбцов, и призвана облегчить вашу работу с данными. Чтобы вычислить стандартную ошибку оценки, понадобятся пять величин. Поэтому разделите таблицу на пять столбцов. Обозначьте эти столбцы так:[1]
-
2
Введите данные в таблицу. Когда вы проведете эксперимент или опрос, вы получите пары данных — независимую переменную обозначим как
, а зависимую или конечную переменную как . Введите эти значения в первые два столбца таблицы.
- Не перепутайте данные. Помните, что определенному значению независимой переменной должно соответствовать конкретное значение зависимой переменной.
- Например, рассмотрим следующий набор пар данных:
- (1,2)
- (2,4)
- (3,5)
- (4,4)
- (5,5)
-
3
Вычислите линию регрессии. Сделайте это на основе представленных данных. Эта линия также называется линией наилучшего соответствия или линией наименьших квадратов. Расчет можно сделать вручную, но это довольно утомительно. Поэтому рекомендуем воспользоваться графическим калькулятором или онлайн-сервисом, которые быстро вычислят линию регрессии по вашим данным.[2]
- В этой статье предполагается, что уравнение линии регрессии дано (известно).
- В нашем примере линия регрессии описывается уравнением .
-
4
Вычислите прогнозируемые значения по линии регрессии. С помощью уравнения линии регрессии можно вычислить прогнозируемые значения «y» для значений «x», которые есть и которых нет в наборе данных.
Реклама







-
1
Вычислите ошибку каждого прогнозируемого значения. В четвертом столбце таблицы запишите ошибку каждого прогнозируемого значения. В частности, вычтите прогнозируемое значение (
) из фактического (наблюдаемого) значения ().[3]
- В нашем примере вычисления будут выглядеть так:
-
2
Вычислите квадраты ошибок. Возведите в квадрат каждое значение четвертого столбца, а результаты запишите в последнем (пятом) столбце таблицы.
- В нашем примере вычисления будут выглядеть так:
-
3
Найдите сумму квадратов ошибок. Она пригодится для вычисления стандартного отклонения, дисперсии и других величин. Чтобы найти сумму квадратов ошибок, сложите все значения пятого столбца. [4]
- В нашем примере вычисления будут выглядеть так:
- В нашем примере вычисления будут выглядеть так:
-
4
Завершите расчеты. Стандартная ошибка оценки — это квадратный корень из среднего значения суммы квадратов ошибок. Обычно ошибка оценки обозначается греческой буквой
. Поэтому сначала разделите сумму квадратов ошибок на число пар данных. А потом из полученного значения извлеките квадратный корень.[5]
- Если рассматриваемые данные представляют всю совокупность, среднее значение находится так: сумму нужно разделить на N (количество пар данных). Если же рассматриваемые данные представляют некоторую выборку, вместо N подставьте N-2.
- В нашем примере, скорее всего, имеет место выборка, потому что мы рассматриваем всего 5 пар данных. Поэтому стандартную ошибку оценки вычислите следующим образом:
-
5
Интерпретируйте полученный результат. Стандартная ошибка оценки — это статистический показатель, которые оценивает, насколько близко измеренные данные лежат к линии регрессии. Ошибка оценка «0» означает, что каждая точка лежит непосредственно на линии. Чем выше ошибка оценки, тем дальше от линии регрессии лежат точки.[6]
- В нашем примере выборка достаточно маленькая, поэтому стандартная оценка ошибки 0,894 является довольно низкой и характеризует близко расположенные данные.
Реклама








Об этой статье
Эту страницу просматривали 4342 раза.