Критерий Стьюдента применяется для проверки равенства средних значений двух выборок, сравнение количественных значений только двух выборок с нормальным распределением случайной величины.
Критерий Стьюдента определяется по формуле:
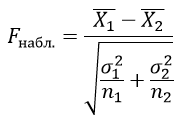
$bar{X_1}$ – выборочные средние значения первой выборки;
$bar{X_2}$ – выборочные средние значения второй выборки;
n1 – объем первой выборки;
n2 – объем второй выборки;
σ1 и σ2 – среднее квадратическое отклонение в соответствующих выборках и находятся из формулы:
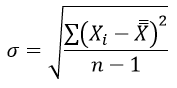
Число степеней свободы определяется по формуле:
k=n1+n2−2
Fкр(α, k) определяется по таблице
При Fнабл<Fкр нулевая гипотеза принимается.
Формула критерия Стьюдента для несвязанных независимых выборок:
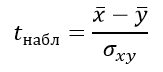
Формула для определения стандартной ошибки разности средних арифметических σxy:
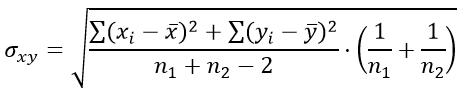
Число степеней свободы определяется выражением:
k=n1+n2–2
При n1=n2 число степеней свободы находится по формуле:
k=2n-2
а стандартная ошибка разности средних арифметических σxy задаётся выражением:
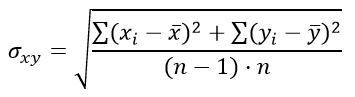
Пример
Даны две выборки.
В первой выборки продажа товара со скидкой, а во второй без скидки.
| № п/п | X | Y |
| 1 | 25 | 19 |
| 2 | 34 | 31 |
| 3 | 23 | 17 |
| 4 | 35 | 24 |
| 5 | 33 | 28 |
| 6 | 25 | 31 |
| 7 | 45 | 39 |
| 8 | 41 | 32 |
| 9 | 27 | 38 |
| 10 | 54 | 43 |
| 11 | 32 | 21 |
| 12 | 32 |
По критерию Стьюдента определить зависит ли спрос на товар от скидок на него при p=0.99?
Решение
В соответствии с таблицей n1=12, n2=11
Вычислим дисперсии D(X), D(Y)
| № п/п | X | Y | D(X) | D(Y) |
| 1 | 25 | 19 | 78,028 | 107,4 |
| 2 | 34 | 31 | 0,0278 | 2,6777 |
| 3 | 23 | 17 | 117,36 | 152,86 |
| 4 | 35 | 24 | 1,3611 | 28,769 |
| 5 | 33 | 28 | 0,6944 | 1,8595 |
| 6 | 25 | 31 | 78,028 | 2,6777 |
| 7 | 45 | 39 | 124,69 | 92,86 |
| 8 | 41 | 32 | 51,361 | 6,9504 |
| 9 | 27 | 38 | 46,694 | 74,587 |
| 10 | 54 | 43 | 406,69 | 185,95 |
| 11 | 32 | 21 | 3,3611 | 69,95 |
| 12 | 32 | 3,3611 | ||
| Сумма | 406 | 323 | 911,67 | 726,55 |
| Среднее | 33,833 | 29,364 |
Подставим значения в формулу стандартной ошибки разности средних арифметических σxy:
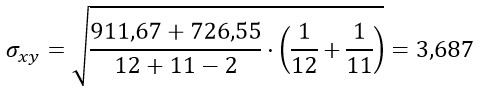
Вычисляем критерий Стьюдента:
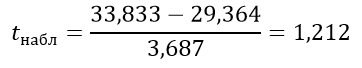
Число степеней свободы равно:
k=12+11–2=21
По таблице Стьюдента находим критическое значение:
tкрит=2,8310
Отсюда tкрит> tнабл, следовательно, зависит.
![]() 15612
15612
Непараметрические
критерии статистики — свободны
от допущения о законе распределения
выборок и базируются на предположении
о независимости наблюдений.
В
группу параметрических
критериев методов
математической статистики входят
методы для вычисления описательных
статистик, построения графиков на
нормальность распределения, проверка
гипотез о принадлежности двух выборок
одной совокупности. Эти методы
основываются на предположении о том,
что распределение выборок подчиняется
нормальному (гауссовому) закону
распределения. Среди параметрических
критериев статистики нами будут
рассмотрены критерий Стьюдента и Фишера.
6.1.1 Методы проверки выборки на нормальность
Чтобы
определить, имеем ли мы дело с
нормальным распределением, можно
применять следующие методы:
1)
в пределах осей можно нарисовать полигон
частоты (эмпирическую функцию
распределения) и кривую нормального
распределения на основе данных
исследования. Исследуя формы кривой
нормального распределения и графика
эмпирической функции распределения,
можно выяснить те параметры, которыми
последняя кривая отличается от первой;
2)
вычисляется среднее, медиана и мода и
на основе этого определяется отклонение
от нормального распределения. Если
мода, медиана и среднее арифметическое
друг от друга значительно не отличаются,
мы имеем дело с нормальным распределением.
Если медиана значительно отличается
от среднего, то мы имеем дело с асимметричной
выборкой.
3)
эксцесс кривой распределения должен
быть равен 0.
Кривые с положительным эксцессом значительно вертикальнее
кривой нормального распределения.
Кривые с отрицательным эксцессом
являются более покатистыми по сравнению
с кривой нормального распределения;
4)
после определения среднего
значения распределения частоты и
стандартного oтклонения находят следующие
четыре интервала распределения сравнивают
их с действительными данными ряда:
а) ![]() —
—
к интервалу должно относиться около
25% частоты совокупности,
б) ![]() —
—
к интервалу должно относиться около
50% частоты совокупности,
в) ![]() —
—
к интервалу должно относиться около
75% частоты совокупности,
г) ![]() —
—
к интервалу должно относиться около
100% частоты совокупности.
6.1.2 Критерий Стьюдента (t-критерий)
Критерий
позволяет найти вероятность того, что
оба средних значения в выборке относятся
к одной и той же совокупности. Данный
критерий наиболее часто используется
для проверки гипотезы: «Средние двух
выборок относятся к одной и той же
совокупности».
При
использовании критерия можно выделить
два случая. В первом случае его применяют
для проверки гипотезы о равенстве
генеральных средних
двух независимых, несвязанныхвыборок
(так называемый двухвыборочный t-критерий).
В этом случае есть контрольная группа
и экспериментальная (опытная) группа,
количество испытуемых в группах может
быть различно.
Во
втором случае, когда одна и та же группа
объектов порождает числовой материал
для проверки гипотез о средних,
используется так называемый парный
t-критерий.
Выборки при этом называют зависимыми, связанными.
а)
случай независимых выборок
Статистика
критерия для случая несвязанных,
независимых выборок равна:
![]() (1)
(1)
где ![]() ,
,![]() —
—
средние арифметические в экспериментальной
и контрольной группах,
![]() —
—
стандартная ошибка разности средних
арифметических. Находится из формулы:
![]() , (2)
, (2)
где n1 и n2 соответственно
величины первой и второй выборки.
Если n1=n2,
то стандартная ошибка разности средних
арифметических будет считаться по
формуле:
 (3)
(3)
где
n величина выборки.
Подсчет числа
степеней свободы осуществляется
по формуле:
k
= n1 +
n2 –
2. (4)
При
численном равенстве выборок k =
2n —
2.
Далее
необходимо сравнить полученное
значение tэмп с
теоретическим значением t—распределения
Стьюдента (см. приложение к учебникам
статистики). Если tэмп<tкрит,
то гипотезаH0 принимается,
в противном случае нулевая гипотеза
отвергается и принимается альтернативная
гипотеза.
Рассмотрим
пример использования t-критерия
Стьюдента для несвязных и неравных по
численности выборок.
Пример 1. В
двух группах учащихся — экспериментальной
и контрольной — получены следующие
результаты по учебному предмету
(тестовые баллы; см. табл. 1).[1]
Таблица
1. Результаты эксперимента
|
Первая |
Вторая N2=9 |
|
12 14 13 16 11 9 13 15 15 18 14 |
13 9 11 10 7 6 8 10 11 |
Общее
количество членов выборки: n1=11, n2=9.
Расчет
средних арифметических: Хср=13,636; Yср=9,444
Стандартное
отклонение: sx=2,460; sy=2,186
По
формуле (2) рассчитываем стандартную
ошибку разности арифметических средних:
![]()
Считаем
статистику критерия:
![]()
Сравниваем
полученное в эксперименте значение t с
табличным значением с учетом степеней
свободы, равных по формуле (4) числу
испытуемых минус два (18).
Табличное
значение tкрит равняется
2,1 при допущении возможности риска
сделать ошибочное суждение в пяти
случаях из ста (уровень значимости=5 %
или 0,05).
Если
полученное в эксперименте эмпирическое
значение t превышает табличное, то
есть основания принять альтернативную
гипотезу (H1)
о том, что учащиеся экспериментальной
группы показывают в среднем более
высокий уровень знаний. В эксперименте
t=3,981, табличное t=2,10, 3,981>2,10, откуда
следует вывод о преимуществе
экспериментального обучения.
Здесь
могут возникнуть такие вопросы:
1.
Что если полученное в опыте значение t
окажется меньше табличного? Тогда надо
принять нулевую гипотезу.
2.
Доказано ли преимущество экспериментального
метода? Не столько доказано, сколько
показано, потому что с самого начала
допускается риск ошибиться в пяти
случаях из ста (р=0,05). Наш эксперимент
мог быть одним из этих пяти случаев. Но
95% возможных случаев говорит в пользу
альтернативной гипотезы, а это достаточно
убедительный аргумент в статистическом
доказательстве.
3.
Что если в контрольной группе результаты
окажутся выше, чем в экспериментальной?
Поменяем, например, местами, сделав ![]() средней
средней
арифметической экспериментальной
группы, a![]() —
—
контрольной:
![]()
Отсюда
следует вывод, что новый метод пока не
проявил себя с хорошей стороны по
разным, возможно, причинам. Поскольку
абсолютное значение 3,9811>2,1, принимается
вторая альтернативная гипотеза (Н2)
о преимуществе традиционного метода.
б)
случай связанных (парных) выборок
В
случае связанных выборок с равным числом
измерений в каждой можно использовать
более простую формулу t-критерия
Стьюдента.
Вычисление
значения t осуществляется по формуле:
![]() (5)
(5)
где ![]() —
—
разности между соответствующими
значениями переменной X и переменной
У, аd —
среднее этих разностей;
Sd
вычисляется по следующей формуле:
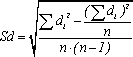 (6)
(6)
Число
степеней свободы k определяется
по формуле k=n-1.
Рассмотрим пример использования t-критерия
Стьюдента для связных и, очевидно, равных
по численности выборок.
Если tэмп<tкрит,
то нулевая гипотеза принимается, в
противном случае принимается
альтернативная.
Пример
2.
Изучался уровень ориентации учащихся
на художественно-эстетические
ценности. С целью активизации формирования
этой ориентации в экспериментальной
группе проводились беседы, выставки
детских рисунков, были организованы
посещения музеев и картинных галерей,
проведены встречи с музыкантами,
художниками и др. Закономерно встает
вопрос: какова эффективность проведенной
работы? С целью проверки эффективности
этой работы до начала эксперимента и
после давался тест. Из методических
соображений в таблице 2 приводятся
результаты небольшого числа
испытуемых.[2]
Таблица
2. Результаты эксперимента
|
Ученики (n=10) |
Баллы |
Вспомогательные |
||
|
до |
в эксперимента |
d |
d2 |
|
|
Иванов |
14 |
18 |
4 |
16 |
|
Новиков |
20 |
19 |
-1 |
1 |
|
Сидоров |
15 |
22 |
7 |
49 |
|
Пирогов |
11 |
17 |
6 |
36 |
|
Агапов |
16 |
24 |
8 |
64 |
|
Суворов |
13 |
21 |
8 |
64 |
|
Рыжиков |
16 |
25 |
9 |
81 |
|
Серов |
19 |
26 |
7 |
49 |
|
Топоров |
15 |
24 |
9 |
81 |
|
Быстров |
9 |
15 |
6 |
36 |
|
å |
148 |
211 |
63 |
477 |
|
Среднее |
14,8 |
21,1 |
Вначале
произведем расчет по формуле:
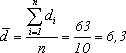
Затем
применим формулу (6), получим:
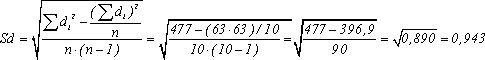
И,
наконец, следует применить формулу (5).
Получим:

Число
степеней свободы: k=10-1=9
и по таблице Приложения 1 находим
tкрит =2.262,
экспериментальное t=6,678, откуда следует
возможность принятия альтернативной
гипотезы (H1)
о достоверных различиях средних
арифметических, т. е. делается вывод об
эффективности экспериментального
воздействия.
В
терминах статистических гипотез
полученный результат будет звучать
так: на 5% уровне гипотеза Н0 отклоняется
и принимается гипотеза Н1 .
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях: