Оптимизация нейронной сети
Перевод
Ссылка на автора
«Цель состоит в том, чтобы попасть в точку оптимизации максимальной стоимости, где глупый риск сбалансирован с чрезмерной осторожностью», — Стивен Дж. Боуэн

Эта статья является третьей в серии статей, направленных на демистификацию нейронных сетей и описание способов их проектирования и реализации. В этой статье я расскажу о следующих концепциях, связанных с оптимизацией нейронных сетей:
- Проблемы с оптимизацией
- инерция
- Адаптивные курсы обучения
- Инициализация параметра
- Пакетная нормализация
Вы можете получить доступ к предыдущим статьям ниже. Первый предоставляет простое введение в тему нейронных сетей, для тех, кто незнаком. Вторая статья охватывает более промежуточные темы, такие как функции активации, нейронная архитектура и функции потерь.
Простое введение в нейронные сети
Подробный обзор нейронных сетей с множеством примеров и простых изображений.
towardsdatascience.com
Комплексное введение в архитектуру нейронной сети
Подробный обзор нейронной архитектуры, функций активации, функций потерь, блоков вывода.
towardsdatascience.com
Эти учебные пособия в значительной степени основаны на заметках и примерах из нескольких классов, преподаваемых в Гарварде и Стэнфорде на факультетах информатики и данных.
Весь код, который обсуждается в этом и последующих уроках по темам (полностью подключенных) нейронных сетей, будет доступен через мойНейронные сетиGitHub репозиторий, который можно найти по ссылке ниже.
mrdragonbear / Neural-сети
Внесите свой вклад в развитие mrdragonbear / Neural-Networks, создав учетную запись на GitHub.
github.com

Проблемы с оптимизацией
Говоря об оптимизации в контексте нейронных сетей, мы обсуждаемневыпуклая оптимизация,
Выпуклая оптимизация включает в себя функцию, в которой есть только один оптимум, соответствующий глобальному оптимуму (максимум или минимум). Для выпуклых задач оптимизации не существует понятия локальной оптимальности, что делает их относительно простыми для решения — это общие вводные темы в классах оптимизации для студентов и выпускников.
Невыпуклая оптимизациявключает в себя функцию, которая имеет несколько оптимумов, только один из которых является глобальным оптимумом. В зависимости от поверхности потерь, может быть очень трудно найти глобальный оптимальный
Для нейронной сети кривая или поверхность, о которой мы говорим, является поверхностью потерь. Поскольку мы пытаемся свести к минимуму ошибку прогнозирования сети, мы заинтересованы в поиске глобального минимума на этой поверхности потерь — это цель обучения нейронной сети.
Есть несколько проблем, связанных с этим:
- Какова разумная скорость обучения?Слишком маленькая скорость обучения занимает слишком много времени, чтобы сходиться, а слишком большая скорость обучения будет означать, что сеть не будет сходиться.
- Как нам избежать застревания в локальной оптиме?Один локальный оптимум может быть окружен особенно крутой функцией потерь, и может быть трудно «избежать» этого локального оптимума.
- Что если морфология поверхности потери изменится?Даже если мы сможем найти глобальный минимум, нет гарантии, что он будет оставаться глобальным минимумом бесконечно долго. Хороший пример этого — когда тренируешься на наборе данных, который не является представителем фактического распределения данных — при применении к новым данным поверхность потерь будет другой. Это одна из причин, почему попытка сделать наборы обучающих и тестовых данных репрезентативными для общего распределения данных имеет такое большое значение. Другим хорошим примером являются данные, которые обычно изменяются в распределении из-за его динамического характера — примером этого могут быть пользовательские предпочтения для популярной музыки или фильмов, которые меняются изо дня в день и из месяца в месяц.
К счастью, существуют методы, которые обеспечивают способы решения всех этих проблем, таким образом смягчая их потенциально отрицательные последствия.
Местная Оптима
Ранее локальные минимумы рассматривались как основная проблема в обучении нейронной сети. В настоящее время исследователи обнаружили, что при использовании достаточно больших нейронных сетей большинство локальных минимумов требуют низких затрат, и, таким образом, не особенно важно найти истинный глобальный минимум — локальный минимум с достаточно низкой ошибкой является приемлемым.

Седловые Очки
Недавние исследования показывают, что в больших измерениях седловые точки более вероятны, чем локальные минимумы. Седловые точки также более проблематичны, чем локальные минимумы, потому что вблизи седловой точки градиент может быть очень маленьким Таким образом, градиентный спуск приведет к незначительным обновлениям в сети, и, следовательно, обучение сети прекратится.

Примером функции, которая часто используется для тестирования производительности алгоритмов оптимизации на седловых точках, является Функция Розенбрука, Функция описывается формулой:f (x, y) = (a-x) ² + b (y-x²) ²,который имеет глобальный минимум в(х, у) = (а, а²),
Это невыпуклая функция с глобальным минимумом, расположенным в длинной и узкой долине. Найти долину относительно легко, но трудно достичь глобального минимума из-за плоской долины, которая, таким образом, имеет небольшие градиенты, поэтому трудно сходиться процедурам оптимизации на основе градиента.


Плохое кондиционирование
Важной проблемой является конкретная форма функции ошибок, которая представляет проблему обучения. Давно замечено, что производные функции ошибки обычноплохо обусловленной, Эта плохая обусловленность отражается в ландшафтах ошибок, которые содержат много седловых точек и плоских участков
Чтобы понять это, мы можем посмотреть наГессенская матрица— квадратная матрица частных производных второго порядка скалярной функции.гессенскийописывает локальную кривизну функции многих переменных.

Гессиан может использоваться для определения того, является ли данная стационарная точка седловой или нет. Если гессиан неопределен в этом месте, эта стационарная точка является седловой. Это также можно обосновать аналогичным образом, посмотрев на собственные значения.

Вычисление и хранение полной матрицы Гессена занимаетO (N²)память, которая невозможна для многомерных функций, таких как функции потерь нейронных сетей. Для таких ситуаций усечены-Ньютон а также квазиньютоновский алгоритмы часто используются. Последнее семейство алгоритмов использует приближения к гессиану; один из самых популярных квазиньютоновских алгоритмов BFGS,
Часто для нейронных сетей матрица Гессе плохо обусловленный — выход изменяется быстро при небольшом изменении ввода. Это нежелательное свойство, поскольку оно означает, что процесс оптимизации не особенно стабилен. В этих средах обучение идет медленно, несмотря на наличие сильных градиентов, поскольку колебания замедляют процесс обучения.

Исчезающие / Взрывающиеся Градиенты
До сих пор мы обсуждали только структуру целевой функции — в данном случае функцию потерь — и ее влияние на процесс оптимизации. Есть дополнительные проблемы, связанные с архитектурой нейронной сети, которая особенно актуальна для приложений глубокого обучения.

Приведенная выше структура является примером глубокой нейронной сети сNскрытые слои. Поскольку объекты на первом уровне распространяются через сеть, они подвергаются аффинным преобразованиям, за которыми следует функция активации, описанная ниже:

Приведенные выше уравнения верны для одного слоя. Мы можем написать вывод дляNсеть:

Теперь есть два возможных случая для вышеупомянутой формулировки, в зависимости от величиныа такжеб,

Если значения больше 1, для большого значенияN(глубокая нейронная сеть), значения градиента будут быстро взрываться по мере их распространения по сети. Взрывающиеся градиенты приводят к «обрывам», если не реализовано ограничение градиента (градиент обрезается, если он превышает определенное пороговое значение).


Если значения меньше 1, градиенты быстро стремятся к нулю. Если бы компьютеры могли хранить бесконечно малые числа, то это не было бы проблемой, но компьютеры сохраняли значения только до конечного числа десятичных разрядов. Если значение градиента станет меньше этого значения, оно будет просто распознано как ноль.
Так что же нам делать? Мы обнаружили, что нейронные сети обречены иметь большое количество локальных оптимумов, часто содержащих как острые, так и плоские долины, которые приводят к стагнации обучения и нестабильному обучению.
Теперь я расскажу о некоторых способах, которыми мы можем помочь смягчить проблемы, которые мы только что обсудили в отношении оптимизации нейронной сети, начиная с импульса.
инерция
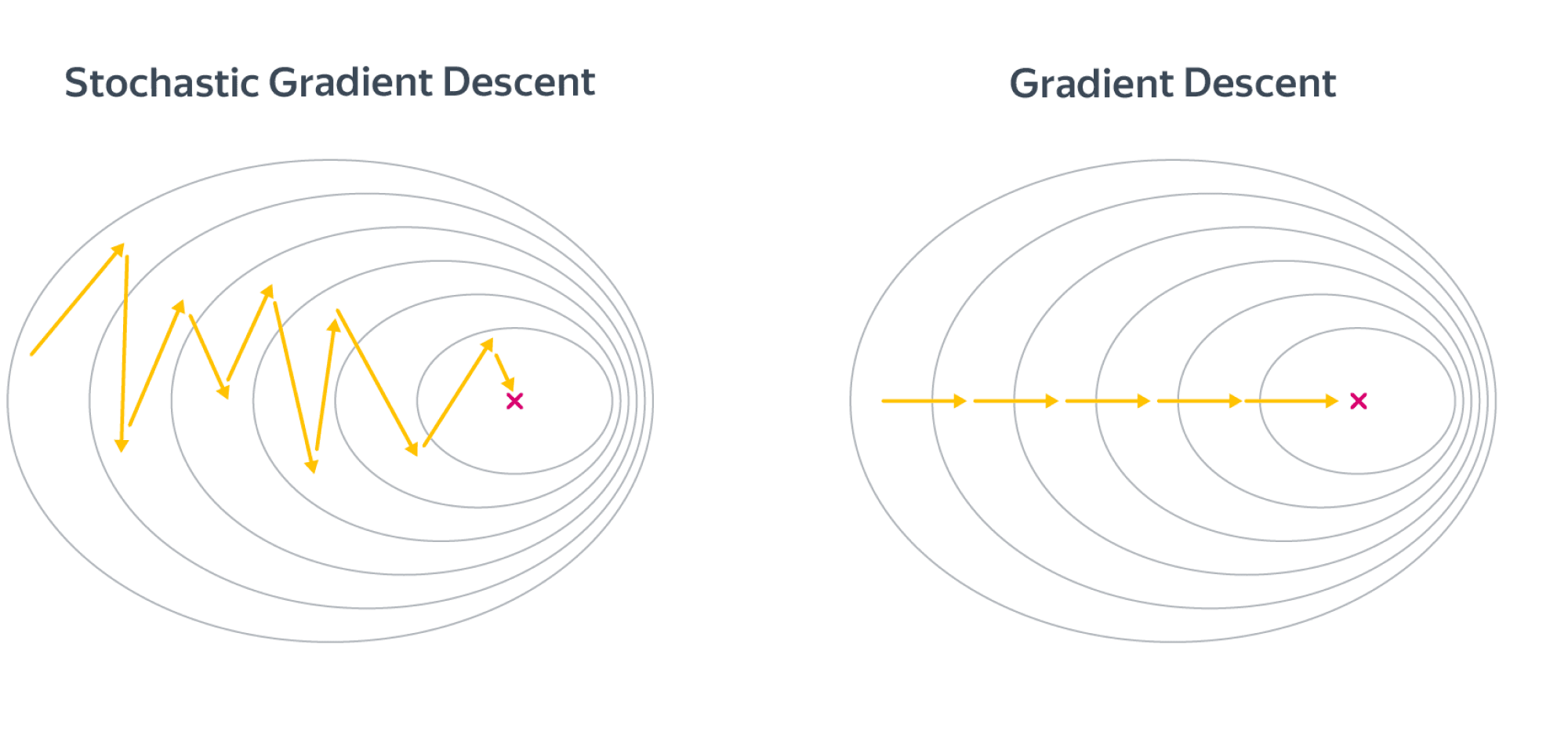
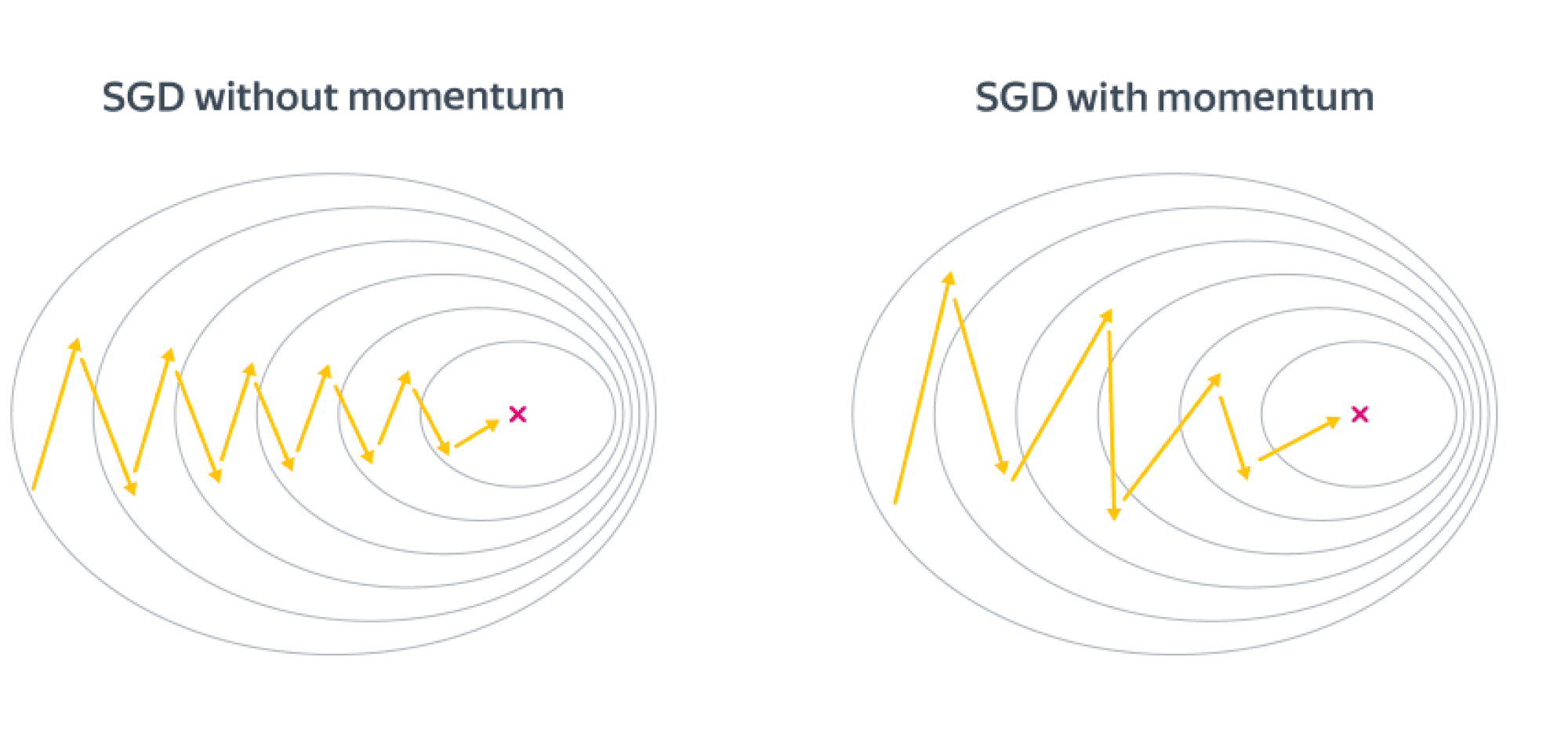
Одной из проблем, связанных со стохастическим градиентным спуском (SGD), является наличие колебаний, возникающих в результате обновлений, не использующих информацию о кривизне. Это приводит к медленной SGD при высокой кривизне.

Взяв средний градиент, мы можем получить более быстрый путь к оптимизации Это помогает смягчить колебания, потому что градиенты в противоположных направлениях устраняются.
Название импульса происходит от того факта, что это аналогично понятию линейного импульса в физике. Объект, который имеет движение (в данном случае это общее направление, в котором движется алгоритм оптимизации), имеет некоторую инерцию, которая заставляет его стремиться двигаться в направлении движения. Таким образом, если алгоритм оптимизации движется в общем направлении, импульс заставляет его «сопротивляться» изменениям направления, что приводит к ослаблению колебаний для поверхностей с высокой кривизной.

Импульс — это дополнительный термин в целевой функции, который представляет собой значение от 0 до 1, которое увеличивает размер шагов, предпринимаемых к минимуму, пытаясь выпрыгнуть из локального минимума. Если срок импульса велик, то скорость обучения должна быть меньше. Большое значение импульса также означает, что конвергенция произойдет быстро. Но если и импульс, и скорость обучения поддерживаются на больших значениях, вы можете пропустить минимум с огромным шагом. Небольшое значение импульса не может надежно избежать локальных минимумов, а также может замедлить обучение системы. Импульс также помогает сгладить изменения, если градиент продолжает менять направление. Правильное значение импульса может быть получено либо методом проб и проб, либо путем перекрестной проверки.
Momentum использует градиенты прошлого для обновления значений, как показано в формуле ниже. Значениеvсвязанный с импульсом часто называют «скоростью». Больший вес применяется к более новым градиентам, создавая экспоненциально убывающее среднее значение градиентов.


Мы можем видеть влияние добавления импульса на алгоритм оптимизации. Первые несколько обновлений не показывают реального преимущества перед стандартным SGD — поскольку у нас нет предыдущих градиентов, которые мы могли бы использовать для нашего обновления. По мере того, как количество обновлений увеличивается, мы запускаем импульс и ускоряем конвергенцию.

Другой тип импульса, который существует — это импульс Нестерова, который мы кратко обсудим.
Нестеров Импульс
Хорошее обсуждение импульса Нестерова дано в Суцкевер, Мартенс и др. «О важности инициализации и импульса в глубоком обучении» 2013,
Основное отличие состоит в том, что в классическом импульсе вы сначала корректируете свою скорость, а затем делаете большой шаг в соответствии с этой скоростью (а затем повторяете), но в импульсе Нестерова вы сначала делаете шаг в направлении скорости, а затем вносите поправку в вектор скорости. на основе нового местоположения (затем повторите).
т.е. классический импульс:
vW(t+1) = momentum.*Vw(t) - scaling .* gradient_F( W(t) )
W(t+1) = W(t) + vW(t+1)
В то время как импульс Нестеров заключается в следующем:
vW(t+1) = momentum.*Vw(t) - scaling .* gradient_F( W(t) + momentum.*vW(t) )
W(t+1) = W(t) + vW(t+1)
Разница невелика, но на практике это может иметь огромное значение.

Эту концепцию может быть трудно понять, поэтому ниже приведено визуальное представление о разнице между традиционным обновлением импульса и импульсом Нестерова.

Адаптивная скорость обучения
Колебания вдоль вертикального направления — Обучение должно быть медленнее по параметру 2 Использовать разную скорость обучения для каждого параметра?

AdaGrad
Momentum добавляет обновления наклона нашей функции ошибок и ускоряет SGD по очереди. AdaGrad адаптирует обновления к каждому отдельному параметру для выполнения больших или меньших обновлений в зависимости от их важности.

Одним из главных преимуществ Adagrad является то, что он устраняет необходимость ручной настройки скорости обучения и приводит к большему прогрессу в слегка наклонных направлениях.
Основным недостатком AdaGrad является накопление квадратов градиентов в знаменателе: поскольку каждый добавленный член является положительным, накопленная сумма продолжает расти в процессе обучения. Это, в свою очередь, приводит к уменьшению скорости обучения и в конечном итоге становится бесконечно малым, и в этот момент алгоритм больше не может получать дополнительные знания.
RMSProp
Для невыпуклых задач AdaGrad может преждевременно снизить скорость обучения. Мы можем использовать экспоненциально взвешенное среднее для накопления градиента.

Адам
Адам представляет собой комбинацию RMSprop и импульса (аналогично, Надам относится к комбинации RMSprop и Нестерова импульса). Адам относится кадаптивная оценка момента,и это самый популярный оптимизатор, используемый сегодня для нейронных сетей.
Адам вычисляет адаптивные показатели обучения для каждого параметра. В дополнение к хранению экспоненциально убывающего среднего значения прошлых квадратов градиентов vt, как Adadelta и RMSprop, Адам также сохраняет экспоненциально убывающее среднее значение прошлых градиентов, аналогично импульсу.

Инициализация параметра
В предыдущих разделах мы рассмотрели, как лучше ориентироваться на поверхности потерь целевой функции нейронной сети, чтобы сходиться к глобальному оптимуму (или приемлемому хорошему локальному оптимуму). Теперь мы рассмотрим, как мы можем манипулировать самой сетью, чтобы облегчить процедуру оптимизации.
Инициализация сетевых весов является важной и часто упускаемой из виду характеристикой нейронных сетей. Существует несколько проблем, связанных с плохо инициализированными сетями, которые могут отрицательно сказаться на производительности сети.
Возьмем для примера сеть, которую мы инициализируем со всеми значениями нуля. Что произойдет в этом сценарии? Сеть на самом деле ничего не узнает. Даже после обновления градиента все веса будут по-прежнему равны нулю из-за того, как мы вычисляем обновления градиента.
Представьте, что мы реализовали это и решили, что это проблема, а затем решили установить для нашей инициализации сети все то же значение 0,5. Что теперь будет? Сеть действительно может чему-то научиться, но мы преждевременно прописали некоторую форму симметрии между нейронными единицами.
В целом, это хорошая идея, чтобы избежать предположения любой формы нейронной структуры путем рандомизации весов в соответствии с нормальным распределением. Это часто делается в Keras путем указания случайного состояния (которое обеспечивает случайность, но обеспечивает повторяемость измерений).
Каков должен быть масштаб этой инициализации? Если мы выберем большие значения для весов, это может привести к взрыву градиентов. С другой стороны, небольшие значения весов могут привести к исчезновению градиентов. Есть некоторое приятное место, которое обеспечивает оптимальный компромисс между этими двумя, но это не может быть известноаприории должно быть выведено методом проб и ошибок.
Xavier Initialization
Инициализация Xavier — это простая эвристика для назначения весов сети. С каждым проходящим слоем мы хотим, чтобы дисперсия оставалась неизменной. Это помогает нам не допустить взрыва сигнала до высоких значений или исчезновения до нуля. Другими словами, нам нужно инициализировать веса таким образом, чтобы дисперсия оставалась одинаковой как для ввода, так и для вывода.
Веса взяты из распределения с нулевым средним и определенной дисперсией. Для полностью связного слоя смвходы:

Значениеминогда называютвентилятор в:количество поступающих нейронов (входные единицы в весовом тензоре).
Важно помнить, что это эвристический подход и, следовательно, не имеет особой теоретической поддержки — он просто наблюдался эмпирически, чтобы продемонстрировать свою эффективность Вы можете прочитать оригинал статьи Вот,
Он нормальная инициализация
Обычная инициализация, по сути, такая же, как инициализация Ксавье, за исключением того, что дисперсия умножается в два раза.
В этом методе веса инициализируются с учетом размера предыдущего слоя, что помогает быстрее и эффективнее достичь глобального минимума функции стоимости. Веса все еще случайны, но различаются по дальности в зависимости от размера предыдущего слоя нейронов. Это обеспечивает контролируемую инициализацию, следовательно, более быстрый и эффективный градиентный спуск.
Для блоков ReLU рекомендуется:

Инициализация смещения
Смещение инициализации относится к тому, как смещения нейронов должны быть инициализированы. Мы уже описали, что веса должны быть случайным образом инициализированы с некоторой формой нормального распределения (чтобы нарушить симметрию), но как мы должны приблизиться к уклонам?
Перефразируя курс Stanford CS231n: Самый простой и распространенный способ инициализации смещений — установить их на ноль — поскольку нарушение асимметрии обеспечивается небольшими случайными числами в весах. Для нелинейностей ReLU некоторым людям нравится использовать небольшие постоянные значения, такие как 0,01 для всех смещений, потому что это гарантирует, что все блоки ReLU срабатывают в начале и, следовательно, получают и распространяют некоторый градиент. Тем не менее, неясно, обеспечивает ли это постоянное улучшение, и более распространено устанавливать смещения на ноль.
Одна из главных проблем с инициализацией смещения заключается в том, чтобы избежать насыщения при инициализации в скрытых единицах — это можно сделать, например, в ReLU, инициализируя смещения до 0,1 вместо нуля.
Предварительная инициализация
Еще один метод инициализации весов заключается в использовании предварительной инициализации. Это характерно для сверточных сетей, используемых для изучения изображений. Метод включает в себя импорт весов уже обученной сети (такой как VGG16) и использование их в качестве начальных весов обучаемой сети.
Этот метод действительно применим только для сетей, которые должны использоваться с данными, аналогичными тем, на которых сеть обучалась. Например, VGG16 был разработан для анализа изображений, если вы планируете анализировать изображения, но у вас мало образцов данных в наборе данных, предварительная инициализация может быть подходящим методом для использования. Это основная концепция, лежащая в основе трансферного обучения, но термины «предварительная инициализация» и «трансферное обучение» не обязательно являются синонимами.
Пакетная нормализация
До этого момента мы рассматривали способы навигации по поверхности потерь нейронной сети с использованием импульса и адаптивных скоростей обучения. Мы также рассмотрели несколько методов инициализации параметров, чтобы минимизироватьаприориуклоны внутри сети. В этом разделе мы рассмотрим, как мы можем манипулировать самими данными, чтобы помочь нашей оптимизации модели.
Для этого мы рассмотрим пакетную нормализацию и некоторые способы ее реализации, чтобы помочь оптимизации нейронных сетей.
Нормализация функций
Нормализация функций — это именно то, что она говорит, она включает в себя нормализацию функций перед применением алгоритма обучения. Это включает масштабирование функции и обычно выполняется во время предварительной обработки.
Согласно статье « Пакетная нормализация: ускорение глубокого сетевого обучения за счет уменьшения внутреннего ковариатного сдвига Градиентный спуск сходится гораздо быстрее при масштабировании объекта, чем без него.
Есть несколько способов масштабирования данных. Одним из распространенных методов являетсямин-макс нормализация, Посредством чего
Самый простой способ масштабирования данных известен какмин-макс нормализацияи включает масштабирование диапазона признаков для масштабирования диапазона в [0, 1] или [-1, 1]. Это делается путем вычитания каждого значения на минимальное значение, а затем масштабирования его на диапазон значений, представленных в наборе данных. Если распределение данных сильно искажено, это может привести к множеству значений, сгруппированных в одном месте. Если это происходит, его иногда можно смягчить, взяв логарифм переменной свойства (так как это имеет тенденцию сворачивать выбросы, поэтому они оказывают меньшее влияние на распределение).

Другой распространенный методсредняя нормализацияэто, по сути, то же самое, что и нормализация min-max, за исключением того, что из каждого значения вычитается среднее значение Это наименее распространенный из трех, обсуждаемых в этой статье.

Стандартизация функцийделает значения каждого признака в данных нулевым средним (при вычитании среднего в числителе) и единицей дисперсии. Этот метод широко используется для нормализации во многих алгоритмах машинного обучения (обычно таких, которые основаны на дистанционных методах). Общий метод расчета заключается в определении среднего распределения и стандартного отклонения для каждого признака. Далее мы вычитаем среднее значение из каждой функции. Затем мы делим значения (среднее значение уже вычтено) каждого признака на его стандартное отклонение.

Выполняя нормализацию, мы уменьшаем искажение (такое как удлинение одного признака по сравнению с другим признаком) набора данных и делаем его более однородным.

Сдвиг внутренней ковариации
Эта идея также исходит из ранее упомянутой статьи « Пакетная нормализация: ускорение глубокого сетевого обучения за счет уменьшения внутреннего ковариатного сдвига ».
Авторы определяютсдвиг внутренней ковариации:
Мы определяем Внутренний Сдвиг Covariate как изменение в распределении активаций сети из-за изменения параметров сети во время обучения.
Это может быть немного расплывчато, поэтому я попытаюсь распаковать это. В нейронных сетях выход первого слоя подается на второй слой, выход второго слоя подается на третий, и так далее. При изменении параметров слоя распределение входов на последующие слои также изменяется.

Эти сдвиги во входных распределениях могут быть проблематичными для нейронных сетей, поскольку они имеют тенденцию замедлять обучение, особенно глубокие нейронные сети, которые могут иметь большое количество слоев.
Хорошо известно, что сети сходятся быстрее, если входные данные были отбелены (т. Е. Нулевое среднее, единичные отклонения) и являются некоррелированными, а внутреннее ковариатное смещение приводит к прямо противоположному.
Пакетная нормализация является методом, предназначенным для уменьшения внутреннего ковариатного сдвига для нейронных сетей.
Пакетная нормализация
Пакетная нормализация является расширением идеи стандартизации функций для других уровней нейронной сети. Если входной слой может извлечь выгоду из стандартизации, почему бы не остальные сетевые уровни?

Чтобы повысить стабильность нейронной сети, нормализация партии нормализует выходные данные предыдущего слоя активации путем вычитания среднего значения партии и деления на стандартное отклонение партии.

Пакетная нормализация позволяет каждому уровню сети учиться самостоятельно независимо от других уровней.
Однако после этого сдвига / шкалы активации по некоторым случайно инициализированным параметрам веса в следующем слое перестают быть оптимальными. SGD (Стохастический градиентный спуск) отменяет эту нормализацию, если это способ минимизировать функцию потерь.
Следовательно, пакетная нормализация добавляет два обучаемых параметра к каждому слою, поэтому нормализованный выходной сигнал умножается на параметр «стандартное отклонение» (γ) и добавляет «средний» параметр (β) Другими словами, пакетная нормализация позволяет SGD выполнять денормализацию, изменяя только эти два веса для каждой активации, вместо потери устойчивости сети путем изменения всех весов.
Эта процедура известна какпакетное преобразование нормализации,

Чтобы проиллюстрировать это наглядно, мы можем проанализировать приведенный ниже рисунок. Мы смотрим на первый скрытый слой, сразу после входного слоя. Для каждого изNПо мини-партиям мы можем рассчитать среднее и стандартное отклонение выхода.

Впоследствии это повторяется для всех последующих скрытых слоев. После этого мы можем дифференцировать потерю сустава дляNмини-партии, а затем распространять обратно через операции нормализации.

Пакетная нормализация уменьшает переоснащение, потому что имеет небольшой эффект регуляризации. Похожий навыбыватьдобавляет шум к активациям каждого скрытого слоя.
Во время теста среднее и стандартное отклонения заменяются средними значениями, собранными во время тренировки. Это то же самое, что использование статистики населения вместо мини-пакетной статистики, поскольку это гарантирует, что выходные данные детерминистически зависят от входных данных.
Есть несколько преимуществ использования пакетной нормализации:
- Уменьшает внутренний ковариантный сдвиг.
- Уменьшает зависимость градиентов от масштаба параметров или их начальных значений.
- Регуляризация модели и снижение потребности в отсевах, фотометрических искажениях, нормализации местных реакций и других методах регуляризации.
- Позволяет использовать насыщающие нелинейности и более высокие скорости обучения.
Заключительные комментарии
На этом мы завершаем третью часть моей серии статей о полностью связанных нейронных сетях. В следующих статьях я приведу несколько подробных кодированных примеров, демонстрирующих, как выполнить оптимизацию нейронной сети, а также более сложные темы для нейронных сетей, такие как теплый перезапуск, ансамбли снимков и многое другое.
Дальнейшее чтение
Курсы глубокого обучения:
- Курс Эндрю Нг по машинному обучению имеет хороший вводный раздел по нейронным сетям.
- Курс Джеффри Хинтона: Coursera Нейронные сети для машинного обучения (осень 2012)
- Бесплатная книга Майкла НильсенаНейронные сети и глубокое обучение
- Йошуа Бенжио, Йен Гудфеллоу и Аарон Курвилл написали книга по глубокому обучению (2016)
- Курс Уго Ларошеля (видео + слайды) в Университете Шербрука
- Стэнфордский учебник (Эндрю Нг и др.) По неконтролируемому обучению и глубокому обучению
- Оксфордский курс ML 2014–2015
- Курс глубокого обучения NVIDIA (лето 2015)
- Курс глубокого обучения Google по Udacity (январь 2016 г.)
НЛП-ориентированные:
- Stanford CS224d: глубокое обучение для обработки естественного языка (весна 2015), Ричард Сошер
- Учебное пособие, данное на NAACL HLT 2013: глубокое обучение обработке естественного языка (без магии) (видео + слайды)
Vision-ориентированные:
- CS231n сверточные нейронные сети для визуального распознавания от Andrej Karpathy (предыдущая версия, короче и менее отточенная: Руководство хакера по нейронным сетям).
Важные статьи нейронной сети:
- Глубокое обучение в нейронных сетях: обзор
- Непрерывное обучение в течение всей жизни с помощью нейронных сетей: обзор — открытый доступ
- Последние достижения в области физических пластовых вычислений: обзор — открытый доступ
- Глубокое обучение в пики нейронных сетей
- Нейронные сети ансамбля (ENN): стохастический метод без градиента — открытый доступ
- Многослойные сети с прямой связью — универсальные аппроксиматоры
- Сравнение глубоких сетей с функцией активации ReLU и методами линейного сплайнового типа — Открытый доступ
- Сети пиковых нейронов: третье поколение моделей нейронных сетей
- Аппроксимационные возможности многослойных сетей прямой связи
- Об импульсном члене в алгоритмах обучения градиентному спуску
Введение
Зачастую задачи машинного обучения формулируются таким образом, что «веса» модели, которую мы строим, возникают, как решение оптимизационной задачи. В качестве VIP-примера рассмотрим задачу линейной регрессии:
$$
Vert y — Xw Vert_2^2 to min_w,
$$
По сути, мы получили чистейшую задачу квадратичной оптимизации. В чем особенность конкретно этой задачи? Она выпуклая.
Для интересующихся определением.
Функция $f colon mathbb{R}^d to mathbb{R}$ является (нестрого) выпуклой (вниз), если для любых $x_1,x_2 in mathbb{R}^d$ верно, что
$$
forall t in [0,1] : f(tx_1 + (1-t)x_2) leq t f(x_1) + (1-t) f(x_2).
$$
Чтобы запомнить, в какую сторону неравенство, всегда полезно рисовать следующую картинку с графическим определением выпуклой функции.
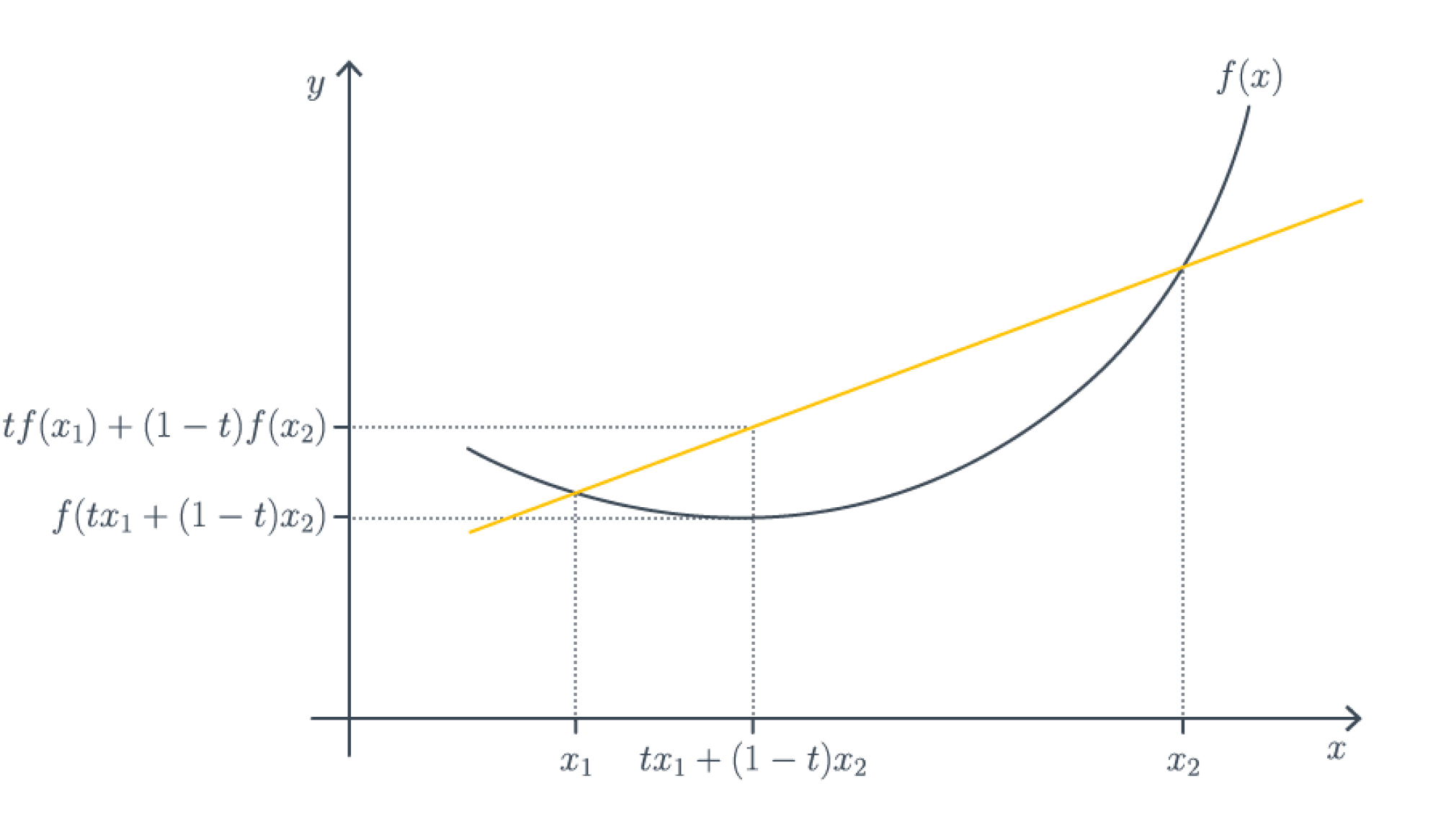
Эквивалентное определение, если функция достаточно гладкая – гессиан неотрицательно определен в любой точке, то есть в каждой точке функция хорошо приближается параболоидом ветвями вверх. Отсюда по критерию минимальности второго порядка автоматически следует, что всякая точка локального оптимума является точкой локального минимума, то есть локальных максимумов и сёдел в выпуклом мире попросту не существует.
Важное свойство выпуклых функций – локальный минимум автоматически является глобальным (но не обязательно единственным!). Это позволяет избегать уродливых ситуаций, которые с теоретической точки зрения могут встретиться в невыпуклом случае, например, вот такой:
Теорема (No free lunch theorem) Пусть $A$ – алгоритм оптимизации, использующий локальную информацию (все производные в точке). Тогда существует такая невыпуклая функция $f colon [0,1]^d to [0,1]$, что для нахождения глобального минимума на квадрате $[0,1]^d$ с точностью $frac{1}{m}$ требуется совершить хотя бы $m^d$ шагов.
Для интересующихся доказательствами.
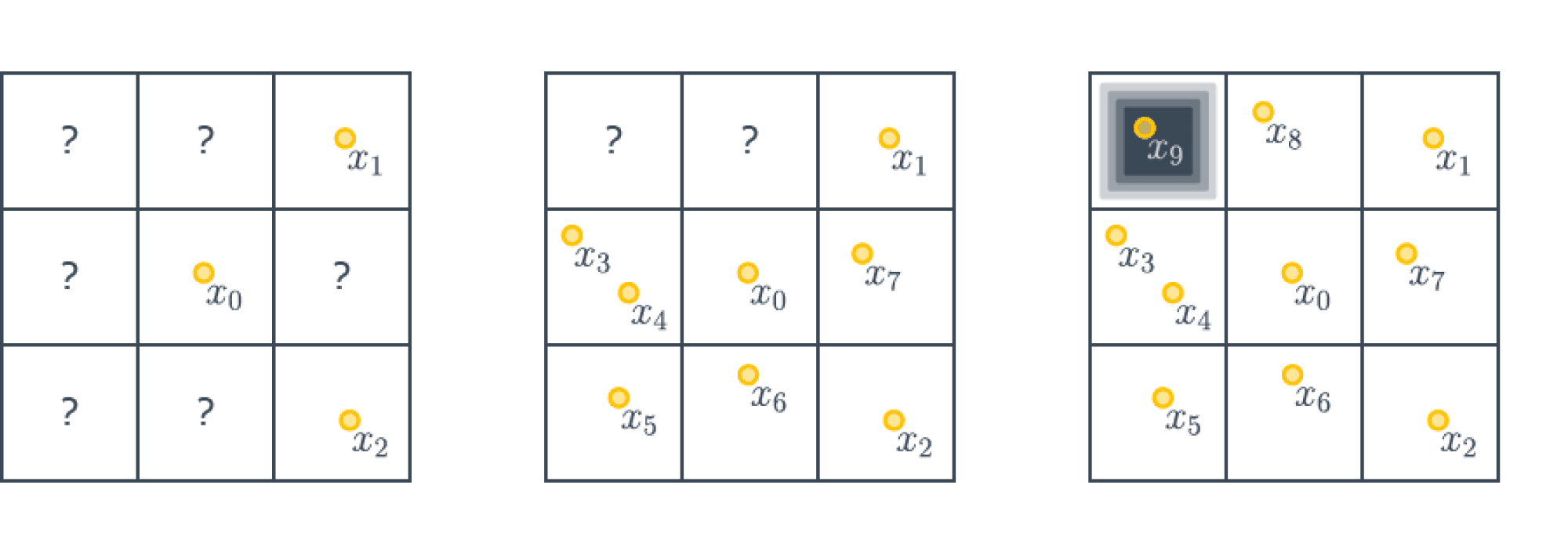
Будем строить наш контрпример, пользуясь принципом сопротивляющегося оракула (или рассуждениями с противником, кому как привычнее называть).
Разделим нашу область на подкубики размера $1/m times ldots times 1/m$. Зададим функцию следующим образом – она будет тождественно равна $1$ на всех кубиках, кроме одного, в середине которого будет точка с значением $0$ (мы не специфицируем, как значение будет гладко «снижаться» до $0$; можно построить кусочно-линейную функцию, а потом сгладить её).
А именно поставим ноль в тот кубик, который наш алгоритм оптимизации $A$ посетит последним. Так как кубиков у нас $m^d$, то алгоритм должен всегда совершить как минимум $m^d$ шагов, попробовав все кубики. Итого у нас следующая картинка ($m=3, d=2$):
Отметим дополнительно, что полученный контрпример можно сделать какой угодно гладкости (но не аналитическим).
Мы видим, что в общем случае без выпуклости нас ожидает полное разочарование. Ничего лучше перебора по сетке придумать в принципе невозможно. В выпуклом случае же существуют алгоритмы, которые находят глобальный минимум за разумное время.
Встречаются ли в жизни функции невыпуклые? Повсеместно! Например, функция потерь при обучении нейронных сетей, как правило, не является выпуклой. Но отсюда не следует, что любой алгоритм их оптимизации будет обязательно неэффективным: ведь «контрпример» из теоремы довольно специфичен. И, как мы увидим, оптимизировать невыпуклые функции очень даже возможно.
Найти глобальный минимум невыпуклой функции – очень трудная задача, но зачастую нам хватает локального, который является, в частности, стационарной точкой: такой, в которой производная равна нулю. Все теоретические результаты в случае невыпуклых задач, как правило, касаются поиска таких точек, и алгоритмы тоже направлены на их отыскание.
Этим объясняется и то, что большинство алгоритмов оптимизации, придуманных для выпуклого случая, дословно перешли в невыпуклый. Теоретическая причина в следующем: в выпуклом случае поиск стационарной точки и поиск минимума – буквально одна и та же задача, поэтому то, что хорошо ищет минимум в выпуклом случае, ожидаемо будет хорошо искать стационарные точки в невыпуклом. Практическая же причина в том, что оптимизаторы в библиотеках никогда не спрашивают, выпуклую ли им функцию подают на вход, а просто работают и работают хорошо.
Внимательный читатель мог возразить на моменте подмены задачи: подождите-ка, мы ведь хотим сделать функцию как можно меньше, а не стационарную точку искать какую-то непонятную. Доказать в невыпуклом случае тут, к сожалению, ничего невозможно, но на практике мы снова используем алгоритмы изначально для выпуклой оптимизации. Почему?
Причина номер 1: сойтись в локальный минимум лучше, чем никуда. Об этом речь уже шла.
Причина номер 2: в окрестности локального минимума функция становится выпуклой, и там мы сможем быстро сойтись.
Причина номер 3: иногда невыпуклая функция является в некотором смысле «зашумленной» версией выпуклой или похожей на выпуклую. Например, посмотрите на эту картинку (функция Леви):
У этой функции огромное количество локальных минимумов, но «глобально» она кажется выпуклой. Что-то отдаленно похожее наблюдается и в случае нейронных сетей. Нашей задачей становится не скатиться в маленький локальный минимум, который всегда рядом с нами, а в большую-большую ложбину, где значение функции минимально и в некотором смысле стабильно.
Причина номер 4: оказывается, что градиентные методы весьма часто сходятся именно к локальным минимумам.
Сразу отметим важную разницу между выпуклой и невыпуклой задачами: в выпуклом случае работа алгоритма оптимизации не очень существенно зависит от начальной точки, поскольку мы всегда скатимся в точку оптимума. В невыпуклом же случае правильно выбранная точка старта – это уже половина успеха.
Теперь перейдём к разбору важнейших алгоритмов оптимизации.
Градиентный спуск (GD)
Опишем самый простой метод, который только можно придумать – градиентный спуск. Для того, чтобы его определить, вспомним заклинание из любого курса матанализа: «градиент – это направление наискорейшего локального возрастания функции», тогда антиградиент – это направление наискорейшего локального убывания.
Для интересующихся формализмом.
Воспользуемся формулой Тейлора для $Vert h Vert = 1$ (направления спуска):
$$
f(x + alpha h) = f(x) + alpha langle nabla f(x), h rangle + o(alpha).
$$
Мы хотим уменьшить значение функции, то есть
$$
f(x) + alpha langle nabla f(x), h rangle + o(alpha) < f(x).
$$
При $alpha to 0$ имеем $langle nabla f(x), Delta x rangle leq 0$. Более того, мы хотим наискорешйшего убывания, поэтому это скалярное произведение хочется минимизировать. Сделаем это при помощи неравенства Коши-Буняковского:
$$
langle nabla f(x), h rangle geq — Vert nabla f(x) Vert_2 Vert h Vert_2 = Vert nabla f(x) Vert_2.
$$
Равенство в неравенстве Коши-Буняковского достигается при пропорциональности аргументов, то есть
$$
h = — frac{nabla f(x)}{Vert nabla f(x) Vert_2}.
$$
$$tag*{$blacksquare$}$$
Тогда пусть $x_0$ – начальная точка градиентного спуска. Тогда каждую следующую точку мы выбираем следующим образом:
$$
x_{k+1} = x_k — alpha nabla f(x_k),
$$
где $alpha$ – это размер шага (он же learning rate). Общий алгоритм градиентного спуска пишется крайне просто и элегантно:
x = normal(0, 1) # можно пробовать и другие виды инициализации
repeat S times: # другой вариант: while abs(err) > tolerance
h = grad_f(x) # вычисляем направление спуска
x -= alpha * h # обновляем значение в точке
Эту схему в приложении к линейной регрессии можно найти в главе про линейные модели.
После всего этого начинаются тонкости:
- А как вычислять градиент?
- А как выбрать размер шага?
- А есть ли какие-то теоретические оценки сходимости?
Начнем разбирать вопросы постепенно. Для вычисления градиентов современный человек может использовать инструменты автоматического дифференцирования. Идейно, это вариация на тему алгоритма обратного распространения ошибки (backpropagation), ведь как правило человек задает функции, составленные из элементарных при помощи умножений/делений/сложений/композиций. Такой метод реализован во всех общих фреймворках для нейронных сетей (Tensorflow, PyTorch, Jax).
Но, вообще говоря, возникает некоторая тонкость. Например, расмотрим задачу линейной регрессии. Запишем её следующим образом:
$$
f(w) = frac{1}{N} sum_{i=1}^N (w^top x_i — y_i)^2.
$$
Видим, что слагаемых суммарно $N$ – размер выборки. При $N$ порядка $10^6$ и $d$ (это количество признаков) порядка $10^4$ вычисление градиента за $O(Nd)$ становится жутким мучением. Но если от $d$ избавиться без дополнительных предположений (например, о разреженности) нельзя, то с зависимостью от $N$ в каком-то смысле удастся разделаться при помощи метода стохастического градиентного спуска.
Хранение градиентов тоже доставит нам проблемы. У градиента столько же компонент, сколько параметров у модели, и если мы имеем дело с глубокой нейросетью, это даст значительные затраты дополнительной памяти. Хуже того, метод обратного распространения ошибки устроен так, что нам приходится помнить все промежуточные представления для вычисления градиентов. Поэтому вычислить градиент целиком невозможно ни для какой нормальной нейросети, и от этой беды тоже приходится спасаться с помощью стохастического градиентного спуска.
Теперь перейдем к размеру шага. Теория говорит о том, что если функция гладкая, то можно брать достаточно маленький размер шага, где под достаточно маленьким подразумевается $alpha leq frac1L$, где $L$ – некоторая константа, которая зависит от гладкости задачи (так называемая константа Липшица). Вычисление этой константы может быть задачей сложнее, чем изначальная задача оптимизации, поэтому этот вариант нам не годится. Более того, эта оценка крайне пессимистична – мы ведь хотим размер шага как можно больше, чтобы уменьшить функцию как можно больше, а тут мы будем изменять все очень мало.
Существует так называемый метод наискорейшего спуска: выбираем размер шага так, чтобы как можно сильнее уменьшить функцию:
$$
alpha_k = argmin_{alpha geq 0} f(x_k — alpha nabla f(x_k)).
$$
Одномерная оптимизация является не сильно сложной задачей, поэтому теоретически мы можем её совершать (например, методом бинарного/тернарного поиска или золотого сечения), можно этот шаг также совершать неточно. Но сразу стоит заметить, что это можно делать, только если функция $f$ вычислима более-менее точно за разумное время, в случае линейной регрессии это уже не так (не говоря уже о нейронных сетях).
Также есть всевозможные правила Армихо/Гольдштейна/Вульфа и прочее и прочее, разработанные в давние 60-е, и для их проверки требуется снова вычислять значения функции в точке. Желающие могут посмотреть на эти условия на википедии. Про более хитрые вариации выбора шагов мы поговорим позже, но сразу стоит сказать, что эта задача довольно сложная.
По поводу теории: сначала скажем что-то про выпуклый случай.
В максимально общем выпуклом случае без дополнительных предположений оценки для градиентного спуска крайне и крайне пессемистичные: чтобы достичь качества $varepsilon$, то есть
$$vert f(x_k) — f(x^*) vertleq varepsilon $$
достаточно сделаеть $O(R^2/varepsilon^2)$ шагов, где $R^2$ — это расстояние от $x_0$ до $x^*$. Выглядит очень плохо: ведь чтобы достичь точности $10^{-2}$, необходимо сделать порядка $10^4$ шагов градиентного спуска. Но на практике такого не происходит, потому что на самом деле верны разные предположения, дающие более приятные свойства. Для контраста, укажем оценку в случае гладкой и сильно выпуклой в точке оптимума функции: за $k$ шагов будет достигнута точность
$$
Oleft( minleft{R^2 exp
left(-frac{k}{4kappa}right), frac{R^2}{k} right}right),
$$
где $kappa$ – это так называемое число обусловленности задачи. По сути, это число измеряет, насколько линии уровня функции вытянуты в окрестности оптимума.
Морали две:
- Скорость сходимости градиентного спуска сильно зависит от обусловленности задачи;
- Также она зависит от выбора хорошей точки старта, ведь везде входит расстояние от точки старта до оптимума.
В качестве ссылки на доказательство укажем на работу Себастиана Стича, где оно довольно простое и общее.
В невыпуклом же случае все куда хуже с точки зрения теории: требуется порядка $O(1/varepsilon^2)$ шагов в худшем случае даже для гладкой функции, где $varepsilon$ – желаемая точность уменьшения нормы градиента.
Стохастический градиентный спуск (SGD)
Теперь мы попробуем сэкономить в случае регрессии и подобных ей задач. Будем рассматривать функционалы вида
$$
f(x) = sum_{i=1}^N mathcal{L}(x, y_i),
$$
где сумма проходится по всем объектам выборки (которых может быть очень много). Теперь сделаем следующий трюк: заметим, что это усреднение – это по сути взятие матожидания. Таким образом, мы говорим, что наша функция выглядит как
$$
f(x) = mathbb{E}[mathcal{L}(x, xi)],
$$
где $xi$ равномерно распределена по обучающей выборке. Задачи такого вида возникают не только в машинном обучении; иногда встречаются и просто задачи стохастического программирования, где происходит минимизация матожидания по неизвестному (или слишком сложному) распределению.
Для функционалов такого вида мы также можем посчитать градиент, он будет выглядеть довольно ожидаемо:
$$
nabla f(x) = mathbb{E} nabla mathcal{L}(x, xi).
$$
Будем считать, что вычисление матожидания напрямую невозможно.
Новый взгляд из статистики дает возможность воспользоваться классическим трюком: давайте подменим матожидание на его несмещенную Монте-Карло оценку. Получается то, что можно назвать стохастическим градиентом:
$$
tilde nabla f(x) = frac{1}{B} sum_{i=1}^B nabla mathcal{L}(x, xi_i).
$$
Говоря инженерным языком, мы подменили вычисление градиента по всей выборке вычислением по случайной подвыборке. Подвыборку $xi_1,ldots,xi_B$ часто называют (мини)батчем, а число $B$ – размерном батча.
По-хорошему, наука предписывает нам каждый раз независимо генерировать батчи, но это трудно с вычислительной точки зрения. Вместо этого воспользуемся следующим приёмом: сначала перемешаем нашу выборку (чтобы внести дополнительную случайность), а затем будем рассматривать последовательно блоки по $B$ элементов выборки. Когда мы просмотрели всю выборку – перемешиваем еще раз и повторяем проход. Очередной прогон по обучающей выборке называется эпохой. И, хотя, казалось бы, независимо генерировать батчи лучше, чем перемешивать лишь между эпохами, есть несколько результатов, демонстрирующих обратное: одна работа и вторая (более новая); главное условие успеха – правильно изменяющийся размер шага.
Получаем следующий алгоритм, называемый стохастическим градиентным спуском (stochastic gradient descent, SGD):
x = normal(0, 1) # инициализация
repeat E times: # цикл по количеству эпох
for i = 0; i <= N; i += B:
batch = data[i:i+B]
h = grad_loss(batch).mean() # вычисляем оценку градиента как среднее по батчу
x -= alpha * h
Дополнительное удобство такого подхода – возможность работы с внешней памятью, ведь выборка может быть настолько большой, что она помещается только на жёсткий диск. Сразу отметим, что в таком случае $B$ стоит выбирать достаточно большим: обращение к данным с диска всегда медленнее, чем к данным из оперативной памяти, так что лучше бы сразу забирать оттуда побольше.
Поскольку стохастические градиенты являются лишь оценками истинных градиентов, SGD может быть довольно шумным:
Поэтому если вы обучаете глубокую нейросеть и у вас в память влезает лишь батч размером с 2-4 картинки, модель, возможно, ничего хорошего не сможет выучить. Аппроксимация градиента и поведение SGD может стать лучше с ростом размера батча $B$ – и обычно его действительно хочется подрастить, но парадоксальным образом слишком большие батчи могут порой испортить дело (об этом дальше в этой главе!).
Теоретический анализ
Теперь перейдем к теоретической стороне вопроса. Сходимость SGD обеспечивается несмещенностью стохастического градиента. Несмотря на то, что во время итераций копится шум, суммарно он зачастую оказывается довольно мал.
Теперь приведем оценки. Сначала, по традиции, в выпуклом случае. Для выпуклой функции потерь за $k$ шагов будет достигнута точность порядка
$$
Oleft( minleft{R^2 exp
left(-frac{k}{4kappa} right)+ frac{sigma^2}{mu k}, frac{R^2}{k} + frac{sigma^2 R}{sqrt{k}} right}right),
$$
где $sigma^2$ – это дисперсия стохградиента, а $mu$ – константа сильной выпуклости, показывающая, насколько функция является «не плоской» в окрестности точки оптимума. Доказательство в том же препринте С. Стича.
Мораль в следующем: дисперсия стохастического градиента, вычисленного по батчу размера $B$ равна $sigma_0^2/B$, где $sigma_0^2$ – это дисперсия одного градиента. То есть увеличение размера батча помогает и с теоретической точки зрения.
В невыпуклом случае оценка сходимости SGD просто катастрофически плохая: требуется $O(1/varepsilon^4)$ шагов для того, чтобы сделать норму градиента меньше $varepsilon$. В теории есть всевозможные дополнительные способы снижения дисперсии с лучшими теоретическими оценками (Stochastic Variance Reduced Gradient (SVRGD), Spider, etc), но на практике они активно не используются.
Использование дополнительной информации о функции
Методы второго порядка
Основной раздел.
Постараемся усовершенствовать метод стохастического градиентного спуска. Сначала заметим, что мы используем явно не всю информацию об оптимизируемой функции.
Вернемся к нашему VIP-примеру линейной регресии с $ell_2$ регуляризацией:
$$
Vert y — Xw Vert_2^2 + lambda Vert w Vert_2^2 to min_w.
$$
Эта функция достаточно гладкая, и может быть неплохой идеей использовать её старшие производные для ускорения сходимости алгоритма. В наиболее чистом виде этой философии следует метод Ньютона и подобные ему; о них вы можете прочитать в соответствующем разделе. Отметим, что все такие методы, как правило, довольно дорогие (исключая L-BFGS), и при большом размере задачи и выборки ничего лучше вариаций SGD не придумали.
Проксимальные методы
Основной раздел.
К сожалению, не всегда функции такие красивые и гладкие. Для примера рассмотрим Lasso-регресию:
$$
Vert y — Xw Vert_2^2 + lambda Vert w Vert_1 to min_w.
$$
Второе, не гладкое слагаемое резко ломает все свойства этой задачи: теоретически оценки для градиентного спуска становятся гораздо хуже (и на практике тоже). С другой стороны, регуляризационное слагаемое устроено очень просто, и эту дополнительную структурную особенность можно и нужно эксплуатировать. Методы решения задачи вида
$$
f(x) + h(x) to min_x,
$$
где $h$ – простая функция (в некотором смысле), а $f$ – гладкая, называются методами композитной оптимизации. Глубже погрузиться в них можно в соответствующем разделе, посвященном проксимальным методам.
Использование информации о предыдущих шагах
Следующая претензия к методу градиентного спуска – мы не используем информацию о предыдущих шагах, хотя, кажется, там может храниться что-то полезное.
Метод инерции, momentum
Начнем с физической аналогии. Представим себе мячик, который катится с горы. В данном случае гора – это график функции потерь в пространстве параметров нашей модели, а мячик – её текущее значение. Реальный мячик не застрянет перед небольшой кочкой, так как у него есть некоторая масса и уже накопленный импульс – некоторое время он способен двигаться даже вверх по склону. Аналогичный прием может быть использован и в градиентной оптимизации. В англоязычной литературе он называется Momentum.
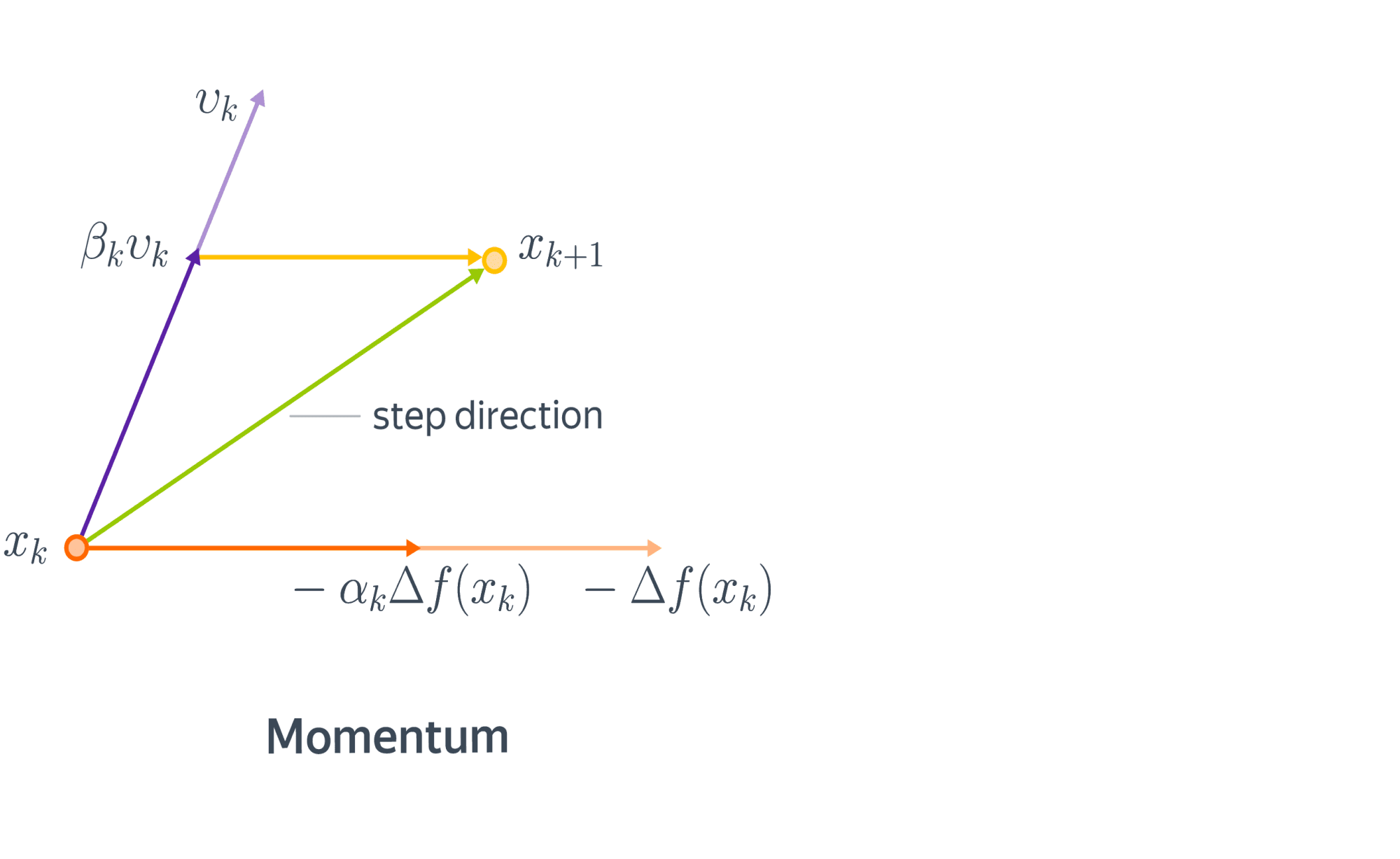
С математической точки зрения, мы добавляем к градиентному шагу еще одно слагаемое:
$$
x_{k+1} = x_k — alpha_k nabla f(x_k) + color{red}{beta_k (x_k — x_{k-1})}.
$$
Сразу заметим, что мы немного усугубили ситуацию с подбором шага, ведь теперь нужно подбирать не только $alpha_k$, но и $beta_k$. Для обычного, не стохастического градиентного спуска мы можем адаптировать метод наискорейшего и получить метод тяжелого шарика:
$$
(alpha_k, beta_k) = argmin_{alpha,beta} f(x_k — alpha nabla f(x_k) + beta (x_k — x_{k-1})).
$$
Но, увы, для SGD это работать не будет.
Выгода в невыпуклом случае от метода инерции довольно понятна – мы будем пропускать паразитные локальные минимумы и седла и продолжать движение вниз. Но выгода есть также и в выпуклом случае. Рассмотрим плохо обусловленную квадратичную задачу, для которой линии уровня оптимизируемой функции будут очень вытянутыми эллипсами, и запустим на SGD с инерционным слагаемым и без него. Направление градиента будет иметь существенную вертикальную компоненту, а добавление инерции как раз «погасит» паразитное направление. Получаем следующую картинку:
Также удобно бывает представить метод моментума в виде двух параллельных итерационных процессов:
$$begin{align}
v_{k+1} &= beta_k v_k — alpha_k nabla f(x_k)
x_{k+1} &= x_k + v_{k+1}.
end{align}
$$
Accelerated Gradient Descent (Nesterov Momentum)
Рассмотрим некоторую дополнительную модификацию, которая была предложена в качестве оптимального метода первого порядка для решения выпуклых оптимизационных задач.
Можно доказать, что в сильно выпуклом и гладком случае найти минимум с точностью $varepsilon$ нельзя быстрее, чем за
$$
Omegaleft( R^2expleft(-frac{k}{sqrt{kappa}}right) right)
$$
итераций, где $kappa$ – число обусловленности задачи. Напомним, что для обычного градиентного спуска в экспоненте у нас был не корень из $kappa$, а просто $kappa$, то есть, градиентный спуск справляется с плохой обусловленностью задачи хуже, чем мог бы.
В 1983 году Ю.Нестеровым был предложен алгоритм, имеющий оптимальную по порядку оценку. Для этого модифицируем немного моментум и будем считать градиент не в текущей точке, а как бы в точке, в которую мы бы пошли, следуя импульсу:
$$begin{align}
v_{k+1} &= beta_k v_k — alpha_k nabla f(color{red}{x_k + beta_k v_k})
x_{k+1} &= x_k + v_{k+1}
end{align}
$$
Сравним с обычным momentum:
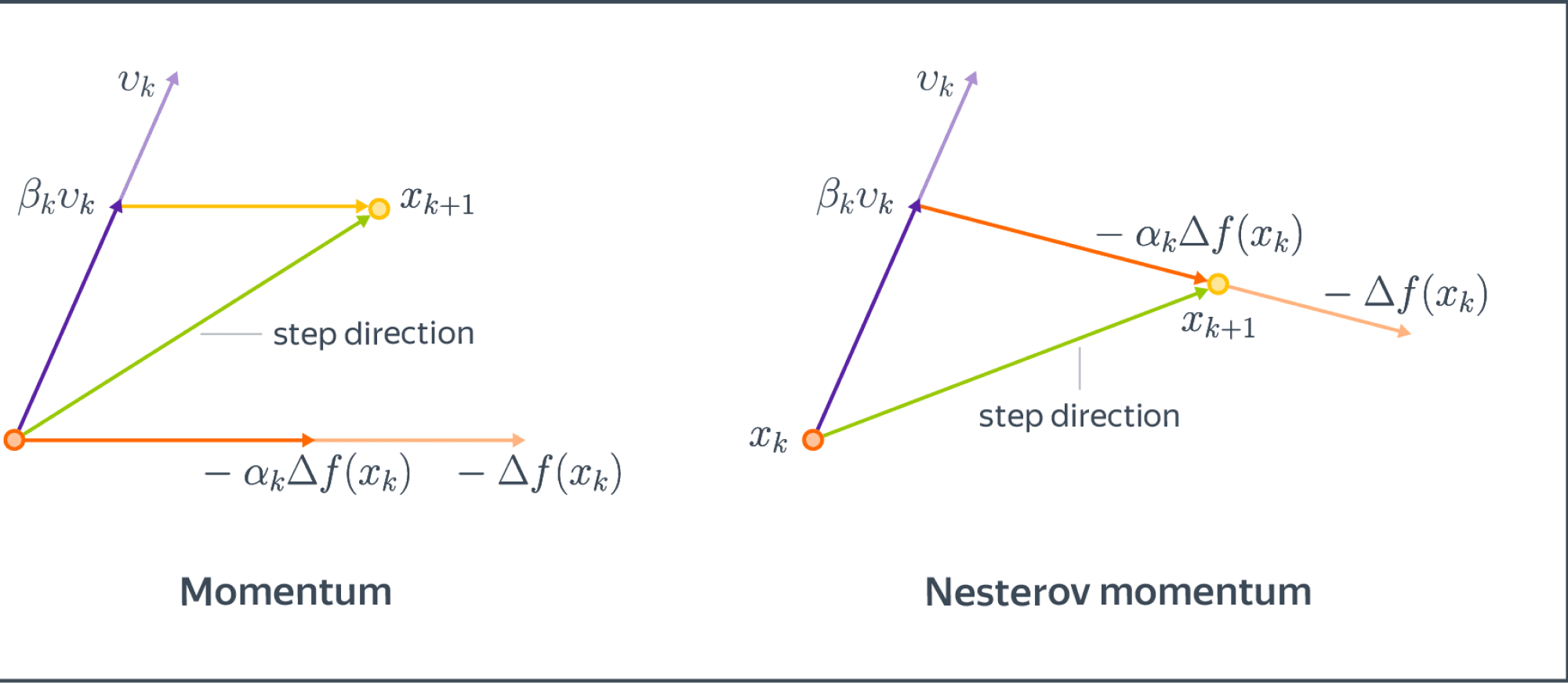
Комментарий: иногда упоминается, что Nesterov Momentum «заглядывает в будущее» и исправляет ошибки на данном шаге оптимизации. Конечно, никто не заглядывает в будущее в буквальном смысле.
В работе Нестерова были предложены конкретные (и довольно магические) константы для импульса, которые получаются из некоторой еще более магической последовательности. Мы приводить их не будем, поскольку мы в первую очередь заинтересованы невыпуклым случаем.
Nesterov Momentum позволяет значительно повысить устойчивость и скорость сходимости в некоторых случаях. Но, конечно, он не является серебряной пулей в задачах оптимизации, хотя в выпуклом мире и является теоретически неулучшаемым.
Также отметим, что ускоренный метод может напрямую примениться к проксимальному градиентному спуску. В частности, применение ускоренного метода к проксимальному алгоритму решения $ell_1$ регрессии (ISTA) называется FISTA (Fast ISTA).
Общие выводы:
- Добавление momentum к градиентному спуску позволяет повысить его устойчивость и избегать маленьких локальных минимумов/максимумов;
- В выпуклом случае добавление моментного слагаемого позволяет доказуемо улучшить асимптотику и уменьшить зависимость от плохой обусловленности задачи.
- Идея ускорения применяется к любым около-градиентным методам, в том числе и к проксимальным, позволяя получить, например, ускоренный метод для $ell_1$-регрессии.
Адаптивный подбор размера шага
Выше мы попытались эксплуатировать свойства градиентного спуска. Теперь же пришел момент взяться за больной вопрос: как подбирать размер шага? Он максимально остро встаёт в случае SGD: ведь посчитать значение функции потерь в точке очень дорого, так что методы в духе наискорейшего спуска нам не помогут!
Нужно действовать несколько хитрее.
Adagrad
Рассмотрим первый алгоритм, который является адаптацией стохастического градиентного спуска. Впервые он предложен в статье в JMLR 2011 года, но она написана в очень широкой общности, так что читать её достаточно сложно.
Зафиксируем $alpha$ – исходный learning rate. Затем напишем следующую формулу обновления:
$$begin{align}
G_{k+1} &= G_k + (nabla f(x_k))^2
x_{k+1} &= x_k — frac{alpha}{sqrt{G_{k+1} + varepsilon}} nabla f(x_k).
end{align}
$$
Возведение в квадрат и деления векторов покомпонентные. По сути, мы добавляем некоторую квазиньютоновость и начинаем динамически подбирать размер шага для каждой координаты по отдельности. Наш размера шага для фиксированной координаты – это какая-то изначальная константа $alpha$ (learning rate), деленная на корень из суммы квадратов координат градиентов плюс дополнительный параметр сглаживания $varepsilon$, предотвращающий деление на ноль. Добавка $varepsilon$ на практике оставляется дефолтными 1e-8 и не изменяется.
Идея следующая: если мы вышли на плато по какой-то координате и соответствующая компонента градиента начала затухать, то нам нельзя уменьшать размер шага слишком сильно, поскольку мы рискуем на этом плато остаться, но в то же время уменьшать надо, потому что это плато может содержать оптимум. Если же градиент долгое время довольно большой, то это может быть знаком, что нам нужно уменьшить размер шага, чтобы не пропустить оптимум. Поэтому мы стараемся компенсировать слишком большие или слишком маленькие координаты градиента.
Но довольно часто получается так, что размер шага уменьшается слишком быстро и для решения этой проблемы придумали другой алгоритм.
RMSProp
Модифицируем слегка предыдущую идею: будем не просто складывать нормы градиентов, а усреднять их в скользящем режиме:
$$begin{align}
G_{k+1} &= gamma G_k + (1 — gamma)(nabla f(x_k))^2
x_{k+1} &= x_k — frac{alpha}{sqrt{G_{k+1} + varepsilon}} nabla f(x_k).
end{align}
$$
Такой выбор позволяет все еще учитывать историю градиентов, но при этом размер шага уменьшается не так быстро.
Общие выводы:
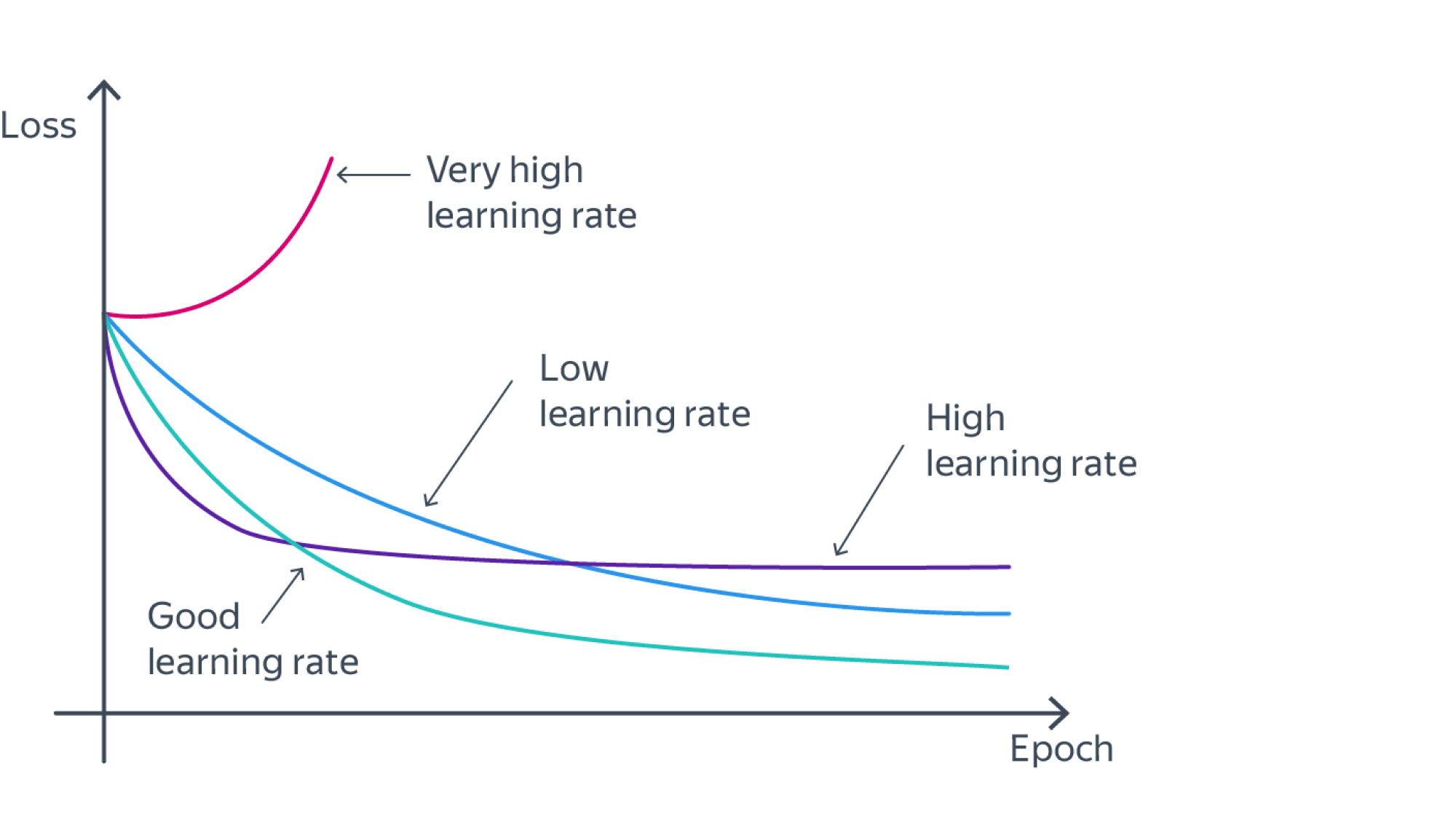
- Благодаря адаптивному подбору шага в современных оптимизаторах не нужно подбирать последовательность $alpha_k$ размеров всех шагов, а достаточно выбрать всего одно число – learning rate $alpha$, всё остальное сделает за вас сам алгоритм. Но learning rate все еще нужно выбирать крайне аккуратно: алгоритм может либо преждевременно выйти на плато, либо вовсе разойтись. Пример приведен на иллюстрации ниже.
Объединяем все вместе…
Adam
Теперь покажем гвоздь нашей программы: алгоритм Adam, который считается решением по умолчанию и практически серебряной пулей в задачах стохастической оптимизации.
Название Adam = ADAptive Momentum намекает на то, что мы объединим идеи двух последних разделов в один алгоритм. Приведем его алгоритм, он будет немного отличаться от оригинальной статьи отсутствием коррекций смещения (bias correction), но идея останется той же самой:
$$begin{align}
v_{k+1} &= beta_1 v_k + (1 — beta_1) nabla f(x_k)
G_{k+1} &= beta_2 G_k + (1 — beta_2)(nabla f(x_k))^2
x_{k+1} &= x_k — frac{alpha}{sqrt{G_{k+1} + varepsilon}} v_{k+1}.
end{align}
$$
Как правило, в этом алгоритме подбирают лишь один гиперпараметр $alpha$ – learning rate. Остальные же: $beta_1$, $beta_2$ и $varepsilon$ – оставляют стандартными и равными 0.9, 0.99 и 1e-8 соответственно. Подбор $alpha$ составляет главное искусство.
Зачастую, при начале работы с реальными данными начинают со значения learning rate равного 3e-4. История данного значения достаточно забавна: в 2016 году Андрей Карпатый (Andrej Karpathy) опубликовал шутливый пост в Twitter.

После чего сообщество подхватило эту идею (до такой степени, что иногда число 3e-4 называют Karpathy constant).
Обращаем ваше внимание, что при работе с учебными данными зачастую полезно выбирать более высокий (на 1-2 порядка) начальный learning rate (например, при классификации MNIST, Fashion MNIST, CIFAR или при обучении языковой модели на примере поэзии выбранного поэта).
Также стоит помнить, что Adam требует хранения как параметров модели, так и градиентов, накопленного импульса и нормировочных констант (cache). Т.е. достижение более быстрой (с точки зрения количества итераций/объема рассмотренных данных) сходимости требует больших объемов памяти. Кроме того, если вы решите продолжить обучение модели, остановленное на некоторой точке, необходимо восстановить из чекпоинта не только веса модели, но и накопленные параметры Adam. В противном случае оптимизатор начнёт сбор всех своих статистик с нуля, что может сильно сказаться на качестве дообучения. То же самое касается вообще всех описанных выше методов, так как каждый из них накапливает какие-то статистики во время обучения.
Интересный факт: Adam расходится на одномерном контрпримере, что совершенно не мешает использовать его для обучения нейронных сетей. Этот факт отлично демонстрирует, насколько расходятся теория и практика в машинном обучении. В той же работе предложено исправление этого недоразумения, но его активно не применяют и продолжают пользоваться «неправильным» Adamом потому что он быстрее сходится на практике.
AdamW
А теперь давайте добавим $ell_2$-регуляризацию неявным образом, напрямую в оптимизатор и минуя адаптивный размер шага:
$$begin{align}
v_{k+1} &= beta_1 v_k + (1 — beta_1) nabla f(x_k)
G_{k+1} &= beta_2 G_k + (1 — beta_2)(nabla f(x_k))^2
x_{k+1} &= x_k — left( frac{alpha}{sqrt{G_{k+1} + varepsilon}} v_{k+1} color{red}{ + lambda x_{k}} right).
end{align}
$$
Это сделано для того, чтобы эффект $ell_2$-регуляризации не затухал со временем и обобщающая способность модели была выше. Оставим ссылку на одну заметку про этот эффект. Отметим, впрочем, что этот алгоритм особо не используется.
Практические аспекты
Расписания
Часто learning rate понижают итеративно: каждые условные 5 эпох (LRScheduler в Pytorch) или же при выходе функции потерь на плато. При этом лосс нередко ведет себя следующим схематичным образом:
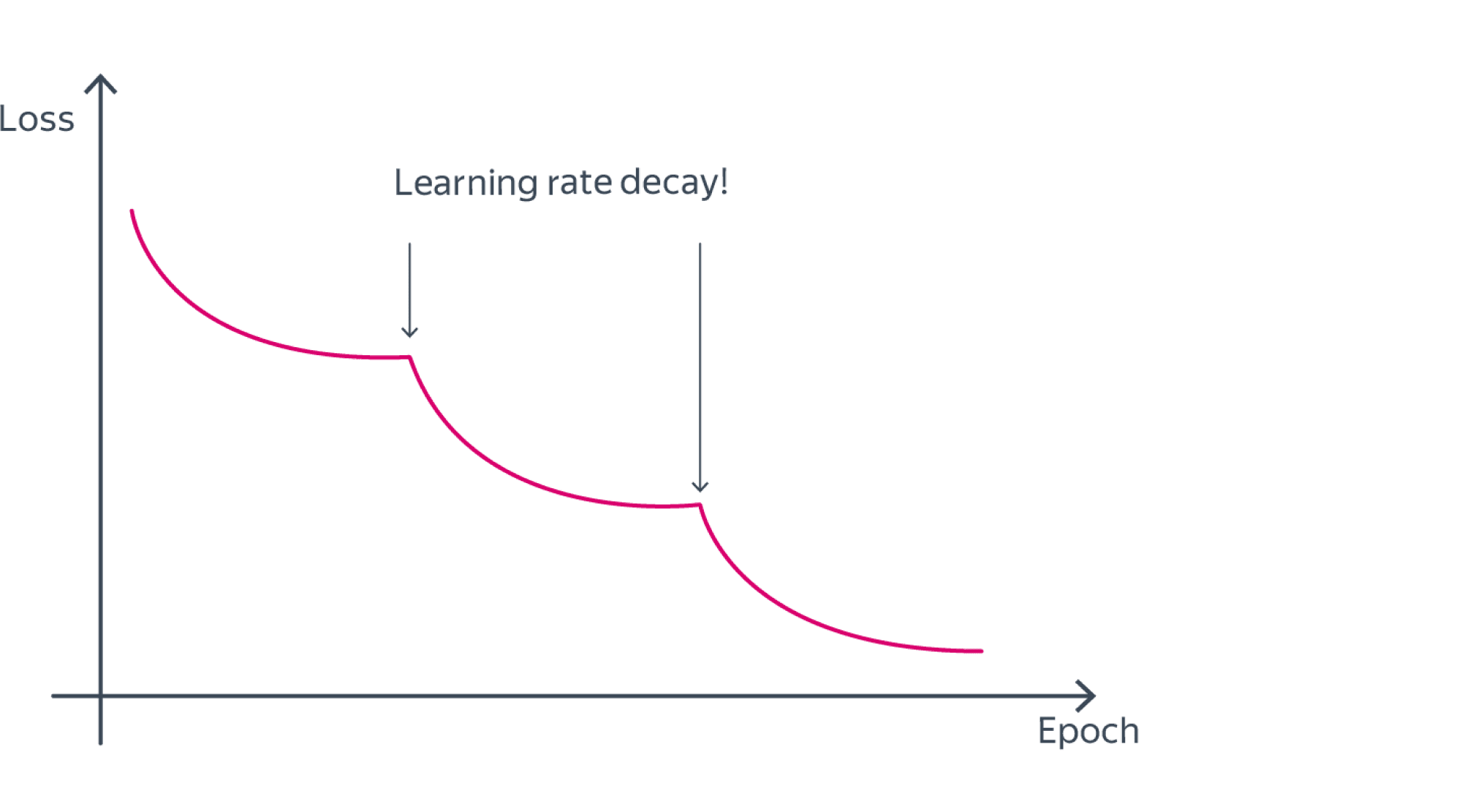
Помимо этого используют другие варианты «расписаний» для learning rate. Из часто применяемых неочевидных лайфхаков: сначала сделать warmup, то есть увеличивать learning rate, а затем начать постепенно понижать. Использовалось в известной статье про трансформеры. В ней предложили следующую формулу:
$$
lr = d^{-0.5}_{rm{model}} cdot min(step_ num^{-0.5}, step_ num cdot warmup_ steps^{-1.5}).
$$
По сути, первые $warmup_ steps$ шагов происходит линейный рост размера шага, а затем он начинает уменьшаться как $1/sqrt{t}$, где $t$ — число итераций.
Есть и вариант с косинусом из отдельной библиотеки для трансформеров.
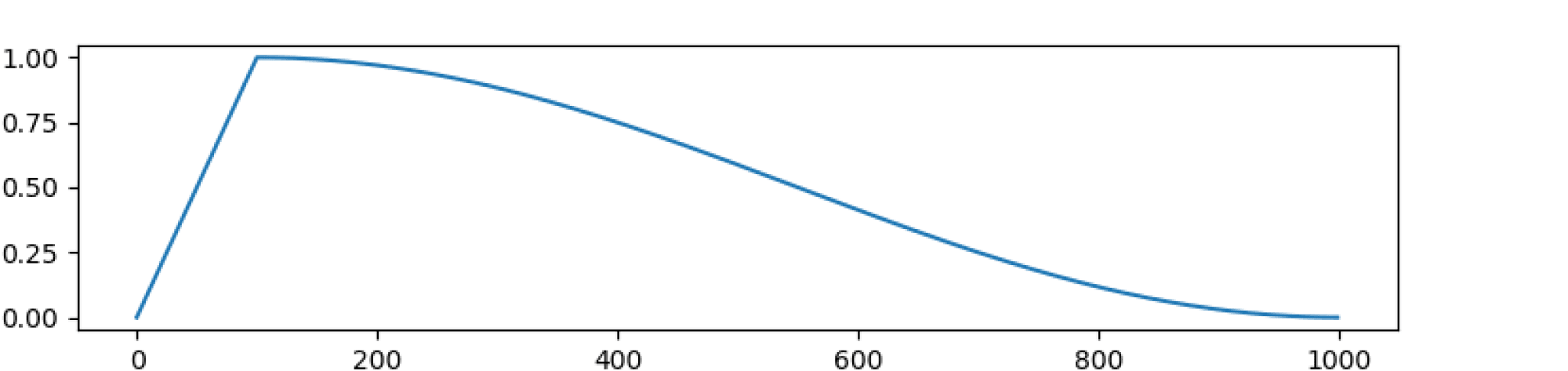
В этой же библиотеке можно также почерпнуть идею рестартов: с какого-то момента мы снова включаем warmup, увеличивая размер шага.
Большие батчи
Представим ситуацию, что мы хотим обучить свою нейронную на нескольких GPU. Одно из решений выглядит следующим образом: загружаем на каждую видеокарту нейронную сеть и свой отдельный батч, вычисляем стохастические градиенты, а затем усредняем их по всем видеокартам и делаем шаг. Что плохого может быть в этом?
По факту, эта схема в некотором смысле эквивалентна работе с одним очень большим батчем. Хорошо же, нет разве?
На самом деле существует так называемый generalization gap: использование большого размера батча может приводить к худшей обобщающей способности итоговой модели. О причине этого эффекта можно поспекулировать, базируясь на текущих знаниях о ландшафтах функций потерь при обучении нейронных сетей.
Больший размер батча приводит к тому, что оптимизатор лучше «видит» ландшафт функции потерь для конкретной выборки и может скатиться в маленькие «узкие» паразитные локальные минимумы, которые не имеют обобщающий способности — при небольшом шевелении этого ландшафта (distributional shift c тренировочной на тестовую выборку) значение функции потерь резко подскакивает. В свою очередь, широкие локальные минимумы дают модель с лучшей обобщающей способностью. Эту идею можно увидеть на следующей картинке:
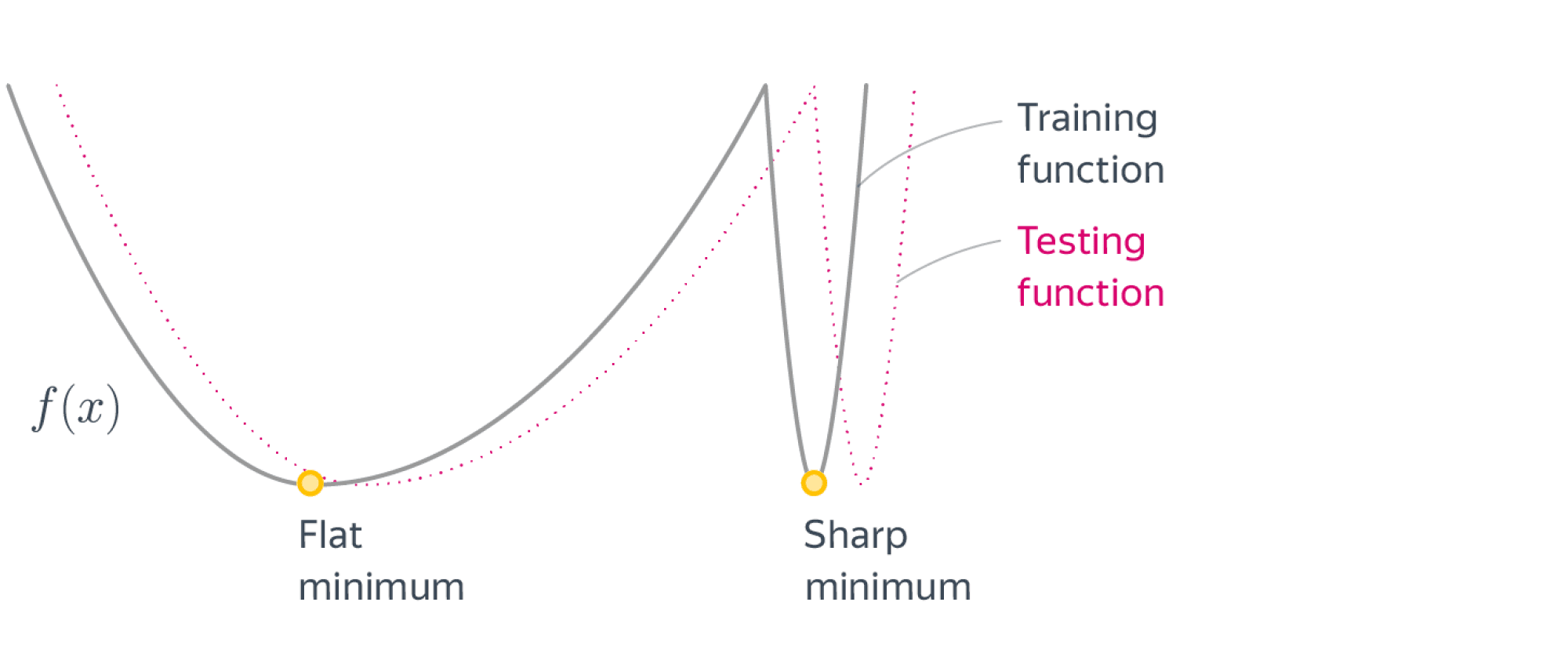
Иными словами, большие батчи могут приводить к переобучению, но это можно исправить правильным динамическим подбором learning rate, как будет продемонстрировано далее. Сразу отметим, что совсем маленькие батчи – это тоже плохо, с ними ничего не получится выучить, так как каждая итерация SGD знает слишком мало о ландшафте функции потерь.
LARS
Мы рассмотрим нестандартный оптимизатор для обучения нейронных сетей, которого нет в Pytorch по умолчанию, но который много где используется: Layer-wise Adaptive Rate Scaling (LARS). Он позволяет эффективно использовать большие размеры батчей, что очень важно при вычислении на нескольких GPU.
Основная идея заключена в названии – нужно подбирать размер шага не один для всей сети или каждого нейрона, а отдельный для каждого слоя по правилу, похожему на RMSProp. По сравнению с оригинальным RMSProp подбор learning rate для каждого слоя дает большую стабильность обучения.
Теперь рассмотрим формулу пересчета: пусть $w_l$ – это веса слоя $l$, $l < L$. Параметры алгоритма: базовый learning rate $eta$ (на который запускается расписание), коэффициент инерции $m$, коэффециент затухания весов $beta$ (как в AdamW).
for l in range(L): # Цикл по слоям
g_l = stochgrad(w_prev)[l] # Вычисляем стохградиент из батча для текущего слоя
lr = eta * norm(w[l]) / (norm(g_l) + beta * norm(w[l])) # Вычислеяем learning rate для текущего слоя
v[l] = m * v[l] + lr * (g_l + beta * w[l]) # Обновляем momentum
w[l] -= v[l] # Делаем градиентный шаг по всему слою сразу
w_prev = w # Обновляем веса
LAMB
Этот оптимизатор введен в статье Large Batch Optimization For Deep Learning и является идейным продолжателем LARS, более приближенным к Adam, чем к обычному RMSProp. Его параметры – это параметры Adam $eta, beta_1, beta_2, varepsilon$, которые беруется как в Adam, а также параметр $lambda$, который отвечает за затухание весов ($beta$ в LARS).
for l in range(L): # Цикл по слоям
g_l = stochgrad(w_prev)[l] # Вычисляем стохградиент из батча для текущего слоя
m[l] = beta_1 * m[l] + (1 - beta_1) * g_l # Вычисляем моментум
v[l] = beta_2 * v[l] + (1 - beta_2) * g_l # Вычисляем новый размер шага
m[l] /= (1 - beta_1**t) # Шаг для уменьшения смещения из Adam
v[l] /= (1 - beta_2**t)
r[l] = m[l] / sqrt(v[l] + eps) # Нормируем моментум как предписывает Adam
lr = eta * norm(w[l]) / norm(r[l] + llambda * w[l]) # Как в LARS
w[l] = w[l] - lr * (r[l] + llambda * w[l]) # Делаем шаг по моментуму
w_prev = w # Обновляем веса
Усреднение
Теперь снова заглянем в теорию: на самом деле, все хорошие теоретические оценки для SGD проявляются, когда берётся усреднение по точкам.
Этот эффект при обучении нейронных сетей был исследован в статье про алгоритм SWA. Суть очень проста: давайте усреднять веса модели по каждой $c$-й итерации; можно считать, что по эпохам. В итоге, веса финальной модели являются усреднением весов моделей, имевщих место в конце каждой эпохи.
В результате такого усреднения сильно повышается обобщающая способность модели: мы чаще попадаем в те самые широкие локальные минимумы, о которых мы говорили в разделе про большие батчи. Вдохновляющая картинка из статьи прилагается:
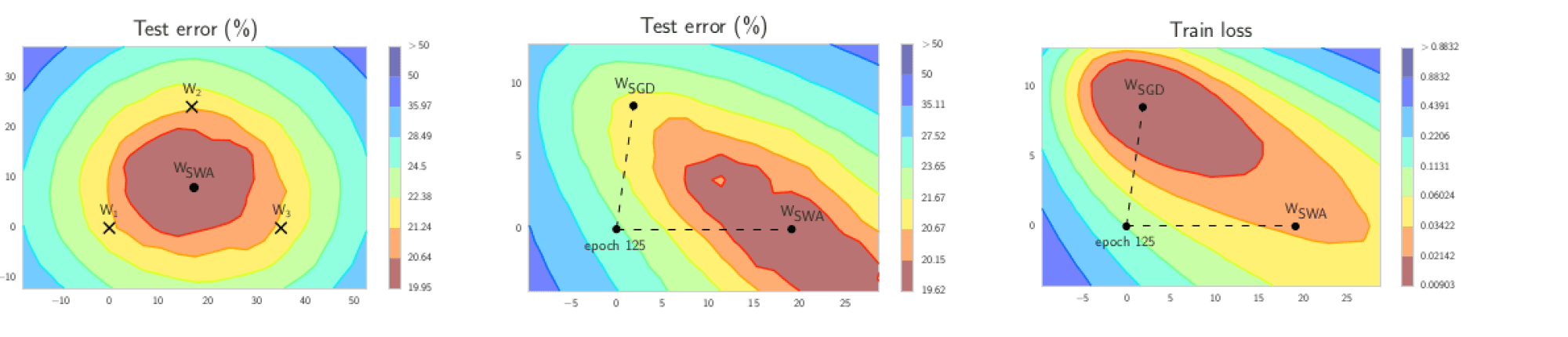
На второй и третьей картинке изображено сравнение SGD и SWA при обучении нейронной сети (Preactivation ResNet-164 on CIFAR-100) при одной и той же инициализации.
На первой же картинке изображено, как идеологически должен работать SWA. Также мы видим тут демонстрацию эффекта концентрации меры: после обучения стохастический градиентный спуск становится случайным блужданием по области в окрестности локального минимума. Если, например, предположить, что итоговая точка – это нормальное распределение с центром в реальном минимуме в размерности $d > 10^6$, то все эти точки с большой вероятности будут находиться в окрестности сферы радиуса $sqrt{d}$. Интуитивную демонстрацию многомерного нормального распределения можно увидеть на следующей картинке из книги Р.Вершинина «High-Dimensional Probability» (слева в размерности 2, справа в большой размерности):

Поэтому, чтобы вычислить центральную точку этой гауссианы, усреднение просто необходимо, по такому же принципу работает и SWA.
Предобуславливание
Теперь мы снова обратимся к теории: скорость сходимости градиентного спуска (даже ускоренного) очень сильно зависит от числа обусловленности задачи. Разумной идеей будет попытаться использовать какие-то сведения о задаче и улучшить этот показатель, тем самым ускорив сходимость.
В теории, здесь могут помочь техники предобуславливания. Но, к сожалению, попытки наивно воплотить эту идею приводят к чему-то, похожему на метод Ньютона, в котором нужно хранить большую-большую матрицу для обучения больших моделей. Способ обойти эту проблему рассмотрели в статье о методе Shampoo, который использует то, что веса нейронной сети зачастую удобно представлять как матрицу или даже многомерный тензор. Таким образом, Shampoo можно рассматривать как многомерный аналог AdaGrad.
Постановка задачи оптимизации при обучении нейронной сети
Пусть имеется нейронная сеть, выполняющая
преобразование F:XYвекторов X из признакового пространства
входовXв вектора Y выходного
пространстваY. Сеть находится
в состоянии W из пространства состоянийW. Пусть далее имеется обучающая
выборка (X,Y),= 1..p. Рассмотрим
полную ошибку E, делаемую сетью в состоянии
W.
![]()
Отметим два свойства полной ошибки.
Во-первых, ошибка E=E(W) является функцией
состоянияW, определенной на пространстве
состояний. По определению, она принимает
неотрицательные значения. Во-вторых, в
некоторомобученномсостоянии W*,
в котором сеть не делает ошибок на
обучающей выборке, данная функция
принимает нулевое значение. Следовательно,
обученные состояния являютсяточками
минимумавведенной функции E(W).
Таким образом, задача обучения нейронной
сети является задачей поиска минимума
функции ошибки в пространстве состояний,
и, следовательно, для ее решения могут
применяться стандарные методы теории
оптимизации. Эта задача относится к
классу многофакторных задач, так,
например, для однослойного персептрона
с N входами и M выходами речь идет о поиске
минимума в NxM-мерном пространстве.
На практике могут использоваться
нейронные сети в состояниях с некоторым
малым значением ошибки, не являющихся
в точности минимумами функции ошибки.
Другими словами, в качестве решения
принимается некоторое состояние из
окрестности обученного состояния W*.
При этом допустимый уровень ошибки
определяется особенностями конкретной
прикладной задачи, а также приемлимым
для пользователя объемом затрат на
обучение.
Задача
Синаптические весовые коэффициенты
однослойного персептрона с двумя входами
и одним выходом могут принимать значения
-1 или 1. Значение порога равно нулю.
Рассмотреть задачу обучения такого
персептрона логической функции “и”,
как задачу многофакторной комбинаторной
оптимизации. Для обучающей выборки
использовать все комбинации двоичных
входов.
Лекция 6. Многослойный персептрон.
Ограничения однослойных нейронных
сетей. Необходимость иерархической
организации нейронной системы.
Многослойный ПЕРСЕПТРОН. Алгоритм
обратного распространения ошибок.
Необходимость иерархической организации нейросетевых архитектур.
На предыдущих лекциях нам уже пришлось
встретиться с весьма жесткими ограничениями
на возможности однослойных сетей, в
частности с требованием линейной
разделимости классов. Особенности
строения биологических сетей подталкивают
тсследователя к использованию более
сложных, и в частности, иерархических
архитектур. Идея относительно проста
— на низшихуровнях иерархии классы
преобразуются таким образом, чтобы
сформировать линейно разделимые
множества, которые в свою очередь будут
успешно распознаваться нейронами на
следующих (высших) уровнях иерархии.
Однако основной проблемой, традиционно
ограничивающей возможные сетевые
топологии простейшими структурами,
является проблема обучения. На этапе
обучения сети пред’являются некоторые
входные образы, называемые обучающей
выборкой, и исследуются получаемые
выходные реакции. Цель обучения состоит
в приведении наблюдаемых реакций на
заданной обучающей выборке к требуемым
(адекватным) реакциям путем изменения
состояний синаптических связей. Сеть
считается обученной, если все реакции
на заданном наборе стимулов являются
адекватными. Данная классическая схема
обучения с учителем требует явного
знания ошибок при функционировании
каждогонейрона, что, разумеется,
затруднено для иерархических систем,
где непосредственно контролируются
только входы и выходы. Кроме того,
необходимая избыточность в иерархических
сетях приводит к тому, что состояние
обучения может быть реализованомногимиспособами, что делает само понятие
“ошибка, делаемая данным нейроном”
весьма неопределенным.
Наличие таких серьезных трудностей в
значительной мере сдерживало прогресс
в области нейронных сетей вплоть до
середины 80-х годов, когда были получены
эффективные алгоритмы обучения
иерархических сетей.

Оптимизаторы — важный компонент архитектуры нейронных сетей. Они играют важную роль в процессе тренировки нейронных сетей, помогая им делать всё более точные прогнозы. Специально к старту нового потока расширенного курса по машинному и глубокому обучению, делимся с вами простым описанием основных методик, используемых оптимизаторами градиентного спуска, такими как SGD, Momentum, RMSProp, Adam и др.
Оптимизаторы определяют оптимальный набор параметров модели, таких как вес и смещение, чтобы при решении конкретной задачи модель выдавала наилучшие результаты.
Самой распространённой техникой оптимизации, используемой большинством нейронных сетей, является алгоритм градиентного спуска.
Большинство популярных библиотек глубокого обучения, например PyTorch и Keras, имеют множество встроенных оптимизаторов, базирующихся на использовании алгоритма градиентного спуска, например SGD, Adadelta, Adagrad, RMSProp, Adam и пр.
Но почему алгоритмов оптимизации так много? Как выбрать из них правильный?
В документации к каждому из таких оптимизаторов приводится формула, с помощью которой такие оптимизаторы обновляют параметры модели. Что же означает каждая формула, и в чём её смысл?
Хочу уточнить, что данная статья написана для того, чтобы вы поняли общую картину и как в такую картину вписывается каждый алгоритм. Я не буду здесь погружаться в глубинные смыслы самих формул, так как рассуждать о математических тонкостях лучше всего в отдельной статье.
Обзор методов оптимизации на базе алгоритма градиентного спуска
Кривая потерь
Начнём с того, что рассмотрим на 3D-изображении, как работает стандартный алгоритм градиентного спуска.

На рисунке показана сеть с двумя весовыми параметрами:
-
На горизонтальной плоскости размещаются две оси для весов w1 и w2, соответственно.
-
На вертикальной оси откладываются значения потерь для каждого сочетания весов.
Другими словами, форма кривой является отражением “ландшафта потерь” в нейронной сети. Кривая представляет потери для различных значений весов при сохранении неизменным фиксированного набора входных данных.
Синяя линия соответствует траектории алгоритма градиентного спуска при оптимизации:
-
Работа алгоритма начинается с выбора некоторых случайных значений обоих весов и вычисления значения потери.
-
После каждой итерации весовые значения будут обновляться (в результате чего, как можно надеяться, снизится потеря), и алгоритм будет перемещаться вдоль кривой к следующей (более нижней) точке.
-
В конечном итоге алгоритм достигает цели, то есть приходит в нижнюю точку кривой — в точку с самым низким значением потерь.
Вычисление градиента
Алгоритм обновляет значения весов, основываясь на значениях градиента кривой потерь в данной точке, и на параметре скорости обучения.

Градиент измеряет уклон и рассчитывается как значение изменения в вертикальном направлении (dL), поделённое на значение изменения горизонтальном направлении (dW). Другими словами, для крутых уклонов значение градиента большое, для пологих — маленькое.

Практическое применение алгоритма градиентного спуска
Визуальное представление кривых потерь весьма полезно для понимания сути работы алгоритма градиентного спуска. Однако нужно помнить, что описываемый сценарий скорее идеален, чем реален.
-
Во-первых, на приведённом выше рисунке кривая потерь идёт идеально плавно. На самом деле горбов и впадин на ней гораздо больше, чем плавных мест.

-
Во-вторых, мы будем работать не с двумя параметрами, а с гораздо большим их числом. Параметров может быть десятки или даже сотни миллионов, их просто невозможно визуализировать и представить даже мысленно.
На каждой итерации алгоритм градиентного спуска работает, «озираясь по всем направлениям, находя самый перспективный уклон, по которому можно спуститься вниз». Но что произойдёт, если алгоритм выберет лучший, по его мнению, уклон, но это будет не лучшее направление? Что делать, если:
-
Ландшафт круто уходит вниз в одном направлении, но, чтобы попасть в самую нижнюю точку, нужно двигаться в направлении с меньшими изменениями высоты?
-
Весь ландшафт представляется алгоритму плоским во всех направлениях?
-
Алгоритм попадает в глубокую канаву? Как ему оттуда выбраться?
Давайте рассмотрим несколько примеров кривых, перемещение по которым может создавать трудности.
Трудности при оптимизации градиентного спуска
Локальные минимумы
На стандартной кривой потерь, кроме глобального минимума, может встретиться множество локальных минимумов. Главной задачей алгоритма градиентного спуска, как следует из его названия, является спуск всё ниже и ниже. Но, стоит ему спуститься до локального минимума — и подняться оттуда наверх часто становится непосильной задачей. Алгоритм может просто застрять в локальном минимуме, так и не попав на глобальный минимум.

Седловые точки
Ещё одной важной проблемой является прохождение алгоритмом «седловых точек». Седловой называют точку, в которой в одном направлении, соответствующем одному параметру, кривая находится на локальном минимуме; во втором же направлении, соответствующем другому параметру, кривая находится на локальном максимуме.

Какую опасность таят в себе седловые точки, которые алгоритм может встретить на своём пути? Опасность в том, что область, непосредственно окружающая седловую точку, как правило, довольно плоская, она напоминает плато. Плоская область означает практически нулевые градиенты. Оптимизатор начинает колебаться (осциллировать) вокруг седловой точки в направлении первого параметра, не “догадываясь” спуститься вниз по уклону в направлении второго параметра.
Алгоритм градиентного спуска при этом ошибочно полагает, что минимум им найден.
Овраги
Ещё одна головная боль алгоритма градиентного спуска — пересечение оврагов. Овраг — это протяжённая узкая долина, имеющая крутой уклон в одном направлении (т.е. по сторонам долины) и плавный уклон в другом (т.е. вдоль долины). Довольно часто овраг приводит к минимуму. Поскольку навигация по такой форме кривой затруднена, такую кривую часто называют патологическим искривлением (Pathological Curvature).

Представьте узкую речную долину, плавно спускающуюся с холмов и простирающуюся вниз до озера. Вам нужно быстро спуститься вниз по реке, туда, где пролегает долина. Но алгоритм градиентного спуска вполне может начать движение, отталкиваясь попеременно от сторон долины, при этом движение вниз по направлению реки будет весьма медленным.
Алгоритм ванильного градиентного спуска, несмотря на его недостатки, по-прежнему считается основным, в частности, по той причине, что существуют специальные методы его оптимизации.
Первое улучшение алгоритма градиентного спуска — стохастический градиентный спуск (SGD)
Под обычным градиентным спуском (по умолчанию) обычно понимается «градиентный спуск со сменой коэффициентов после обсчёта всей выборки», то есть потери и градиент рассчитываются с использованием всех элементов набора данных.
Также применяется промежуточный стохастический градиентный спуск с мини-пакетами — вариант, при котором коэффициенты меняются после обсчета N элементов выборки, то есть для каждой тренировочной итерации алгоритм выбирает случайное подмножество набора данных.
Случайность выбора хороша тем, что она помогает глубже исследовать ландшафт потерь.
Ранее мы говорили, что кривая потерь получается за счёт изменения параметров модели с сохранением фиксированного набора входных данных. Однако если начать изменять входные данные, выбирая различные данные в каждом мини-пакете, значения потерь и градиентов также будут меняться. Другими словами, изменяя набор входных данных, для каждого мини-пакета мы получим собственную кривую потерь, которая немного отличается от других.
То есть, даже если алгоритм застрянет на каком-либо месте ландшафта в одном мини-пакете, можно будет запустить другой мини-пакет с другим ландшафтом, и вполне вероятно, что алгоритм сможет двигаться дальше. Данная техника предотвращает застревание алгоритма на определённых участках ландшафта, особенно на ранних этапах тренировки.
Второе усовершенствование алгоритма градиентного спуска — накопление импульса (Momentum)
Динамическая корректировка количества обновлений
Один из интересных аспектов алгоритма градиентного спуска связан с его поведением на крутых уклонах. Так как градиент на крутых уклонах большой, алгоритм в этих местах может делать большие шаги, между тем, именно здесь вы на самом деле хотите перемещаться медленно и осторожно. Это может привести к тому, что алгоритм будет «скакать» назад и вперёд, замедляя тем самым процесс тренировки.

В идеале частоту обновлений хочется изменять динамически, чтобы алгоритм мог подстраиваться под изменения окружающего ландшафта. Если уклон очень крутой, алгоритм должен притормаживать. Если склон довольно пологий, скорость вполне можно повысить, и так далее.
Алгоритм градиентного спуска обновляет веса на каждом шаге, используя в качестве параметров значения градиента и скорости обучения. Таким образом, для изменения количества обновлений можно выполнить два действия:
-
Скорректировать градиент.
-
Скорректировать значение скорости обучения.
SGD с функцией накопления импульса и обычный SGD
Первое действие, то есть корректировка градиента, выполняется с помощью функции накопления импульса.
В SGD учитывается только текущее значение градиента, а значения всех прошлых градиентов игнорируются. Это означает, что, если алгоритм внезапно натолкнётся на аномалию на кривой потерь, он может пойти не по нужной траектории.
С другой стороны, при использовании SGD с накоплением импульса учитываются значения прошлых градиентов, общее направление сохраняется, и траектория остаётся правильной. Это позволяет использовать знания об окружающем ландшафте, полученные алгоритмом до того, как он добрался до данной точки, и смягчить эффект аномалии кривой потерь.
-
Сразу встаёт вопрос — как далеко можно углубляться в прошлое? Чем глубже мы погрузимся в прошлое, тем меньше вероятность воздействия аномалий на конечный результат.
-
И второй вопрос — все ли градиенты из прошлого можно расценивать одинаково? Вполне логично рассудить, что вещи из недавнего прошлого должны иметь более высокую значимость, чем вещи из далёкого прошлого. Поэтому, если изменение ландшафта представляет собой не аномалию, а естественное структурное изменение, на такие изменения нужно реагировать соответственно и менять курс постепенно.
Функция накопления импульса использует при работе экспоненциальное скользящее среднее, а не текущее значение градиента.
Переходы через овраги с помощью функции накопления импульса
Функция накопления импульса помогает решить проблему узкого оврага с патологическим искривлением, градиент которого, с одной стороны, очень большой для одного весового параметра, а, с другой стороны, очень маленький для другого параметра.

С помощью функции накопления импульса можно сгладить зигзагообразные скачки алгоритма SGD.
-
Для первого параметра с крутым уклоном большое значение градиента приведёт к резкому повороту от одной стороны оврага к другой. Однако на следующем шаге такое перемещение будет скомпенсировано резким поворотом в обратном направлении.
-
Если же взять другой параметр, мелкие обновления на первом шаге будут усиливаться мелкими обновлениями на втором шаге, так как эти обновления имеют то же направление. И именно такое направление вдоль оврага будет направлением, в котором необходимо двигаться алгоритму.
Вот некоторые примеры алгоритмов оптимизации, использующих функцию накопления импульса в разных формулах:
-
SGD с накоплением импульса
-
Ускоренный градиент Нестерова
Третье усовершенствование алгоритма градиентного спуска — изменение скорости обучения (на базе значения градиента)
Как уже было сказано выше, вторым способом изменения количества обновлений параметров является изменение скорости обучения.
До сих пор на разных итерациях мы сохраняли скорость обучения постоянной. Кроме того, при обновлении градиентов для всех параметров использовалось одно и то же значение скорости обучения.
Однако, как мы уже убедились, градиенты с различными параметрами могут довольно ощутимо отличаться друг от друга. Один параметр может иметь крутой уклон, а другой — пологий.
Мы можем использовать это обстоятельство, чтобы адаптировать скорость обучения к каждому параметру. Чтобы выбрать скорость обучения для данного параметра, мы можем обратиться к прошлым градиентам (для каждого параметра отдельно).
Данная функциональность реализована в нескольких алгоритмах оптимизации, использующих разные, но похожие методы, например Adagrad, Adadelta, RMS Prop.
Например, метод Adagrad возводит в квадрат значения прошлых градиентов и суммирует их в равных весовых пропорциях. Метод RMSProp также возводит в квадрат значения прошлых градиентов, но приводит их к экспоненциальному скользящему среднему, тем самым придавая более высокую значимость последним по времени градиентам.
После возведения градиентов в квадрат все они становятся положительными, то есть получают одно и то же направление. Таким образом, перестаёт действовать эффект, проявляющийся при применении функции накопления импульса (градиенты имеют противоположные направления).
Это означает, что для параметра с крутым уклоном значения градиентов будут большими, и возведение таких значений в квадрат даст ещё большее и всегда положительное значение, поэтому такие градиенты быстро накапливаются. Для погашения данного эффекта алгоритм рассчитывает скорость обучения посредством деления накопленных квадратов градиентов на коэффициент с большим значением. За счет этого алгоритм “притормаживает” на крутых уклонах.
Рассуждая аналогично, если уклоны небольшие, накопления также будут небольшими, поэтому при вычислении скорости обучения алгоритм разделит накопленные квадраты градиентов на коэффициент с меньшим значением. Таким образом, скорость обучения на пологих склонах будет увеличена.
Некоторые алгоритмы оптимизации используют сразу оба подхода — изменяют скорость обучения, как это описано выше, и меняют градиент с помощью функции накопления импульса. Так поступает, например, алгоритм Adam и его многочисленные варианты, а также алгоритм LAMB.
Четвёртое усовершенствование алгоритма градиентного спуска — изменение скорости обучения (на базе тренировочной выборки)
В предыдущем разделе скорость обучения менялась на основе градиентов параметров. Плюс к этому, мы можем менять скорость обучения в зависимости от того, как продвигается процесс тренировки. Скорость обучения устанавливается в зависимости от эпохи тренировочного процесса и не зависит от параметров модели в данной точке.
На самом деле эту задачу выполняет не оптимизатор, а особый компонент нейронной сети, называемый планировщиком. Я упоминаю здесь об этом только для полноты картины и для того, чтобы показать связь с техниками оптимизации, о которых мы здесь говорили. Саму же эту тему логично осветить в отдельной статье.
Заключение
Мы ознакомились с основными приёмами, используемыми методиками оптимизации на базе алгоритма градиентного спуска, рассмотрели причины их использования и взаимосвязи друг с другом. Представленная информация позволит лучше понять принцип действия многих специфических алгоритмов оптимизации. А если вы хотите получить больше знаний — обратите внимание на наш расширенный курс по машинному и глубокому обучению, в рамках которого вы научитесь строить собственные нейронные нейронные сети и решать различные задачи с их помощью.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
-
Профессия Data Scientist
-
Профессия Data Analyst
-
Курс по Data Engineering
-
Курс «Алгоритмы и структуры данных»
Другие профессии и курсы
ПРОФЕССИИ
-
Профессия Fullstack-разработчик на Python
-
Профессия Java-разработчик
-
Профессия QA-инженер на JAVA
-
Профессия Frontend-разработчик
-
Профессия Этичный хакер
-
Профессия C++ разработчик
-
Профессия Разработчик игр на Unity
-
Профессия Веб-разработчик
-
Профессия iOS-разработчик с нуля
-
Профессия Android-разработчик с нуля
КУРСЫ
-
Курс по Machine Learning
-
Курс «Machine Learning и Deep Learning»
-
Курс «Математика для Data Science»
-
Курс «Математика и Machine Learning для Data Science»
-
Курс «Python для веб-разработки»
-
Курс «Алгоритмы и структуры данных»
-
Курс по аналитике данных
-
Курс по DevOps