Метод наименьших квадратов (мнк).
Пример.
Экспериментальные
данные о значениях переменных х
и у
приведены
в таблице.
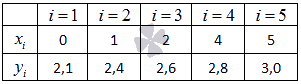
В
результате их выравнивания получена
функция
![]()
Используя
метод
наименьших квадратов ,
аппроксимировать эти данные линейной
зависимостью y=ax+b
(найти параметры а
и b).
Выяснить, какая из двух линий лучше (в
смысле метода наименьших квадратов)
выравнивает экспериментальные данные.
Сделать чертеж.
Суть метода наименьших квадратов (мнк).
Задача
заключается в нахождении коэффициентов
линейной зависимости, при которых
функция двух переменных а
и b
![]() принимает
принимает
наименьшее значение. То есть, при данныха
и b
сумма квадратов отклонений экспериментальных
данных от найденной прямой будет
наименьшей. В этом вся суть метода
наименьших квадратов.
Таким
образом, решение примера сводится к
нахождению экстремума функции двух
переменных.
Вывод формул для нахождения коэффициентов.
Составляется
и решается система из двух уравнений с
двумя неизвестными. Находим частные
производные функции
![]() по
по
переменныма
и b,
приравниваем эти производные к нулю.

Решаем
полученную систему уравнений любым
методом (например методом
подстановки
или методом
Крамера)
и получаем формулы для нахождения
коэффициентов по методу наименьших
квадратов (МНК).

При
данных а и
b функция
![]() принимает
принимает
наименьшее значение. Доказательство
этого факта приведенониже
по тексту в конце страницы .
Вот
и весь метод наименьших квадратов.
Формула для нахождения параметра a
содержит суммы
![]() ,
,![]() ,
,![]() ,
,![]() и
и
параметрn
— количество экспериментальных данных.
Значения этих сумм рекомендуем вычислять
отдельно. Коэффициент b
находится после вычисления a.
Пришло
время вспомнить про исходый пример.
Решение.
В
нашем примере n=5
. Заполняем
таблицу для удобства вычисления сумм,
которые входят в формулы искомых
коэффициентов.

Значения
в четвертой строке таблицы получены
умножением значений 2-ой строки на
значения 3-ей строки для каждого номера
i .
Значения
в пятой строке таблицы получены
возведением в квадрат значений 2-ой
строки для каждого номера i
.
Значения
последнего столбца таблицы – это суммы
значений по строкам.
Используем
формулы метода наименьших квадратов
для нахождения коэффициентов а
и b.
Подставляем в них соответствующие
значения из последнего столбца таблицы:
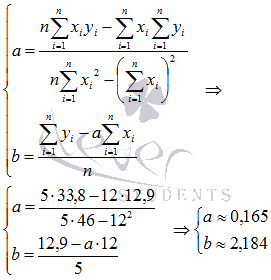
Следовательно,
y = 0.165x+2.184
— искомая аппроксимирующая прямая.
Осталось
выяснить какая из линий y
= 0.165x+2.184 или
![]() лучше
лучше
аппроксимирует исходные данные, то есть
произвести оценку методом наименьших
квадратов.
Оценка погрешности метода наименьших квадратов.
Для
этого требуется вычислить суммы квадратов
отклонений исходных данных от этих
линий
![]() и
и![]() ,
,
меньшее значение соответствует линии,
которая лучше в смысле метода наименьших
квадратов аппроксимирует исходные
данные.
Так
как
![]() ,
,
то прямаяy
= 0.165x+2.184
лучше приближает исходные данные.
Графическая иллюстрация метода наименьших квадратов (мнк).
На
графиках все прекрасно видно. Красная
линия – это найденная прямая y
= 0.165x+2.184,
синяя линия – это
![]() ,
,
розовые точки – это исходные данные.

На
практике при моделировании различных
процессов — в частности, экономических,
физических, технических, социальных —
широко используются те или иные способы
вычисления приближенных значений
функций по известным их значениям в
некоторых фиксированных точках.
Такого
рода задачи приближения функций часто
возникают:
-
при построении
приближенных формул для вычисления
значений характерных величин исследуемого
процесса по табличным данным, полученным
в результате эксперимента; -
при численном
интегрировании, дифференцировании,
решении дифференциальных уравнений и
т. д.; -
при необходимости
вычисления значений функций в
промежуточных точках рассматриваемого
интервала; -
при определении
значений характерных величин процесса
за пределами рассматриваемого интервала,
в частности при прогнозировании.
Если
для моделирования некоторого процесса,
заданного таблицей, построить функцию,
приближенно описывающую данный процесс
на основе метода наименьших квадратов,
она будет называться аппроксимирующей
функцией (регрессией), а сама задача
построения аппроксимирующих функций
— задачей аппроксимации.
В
данной статье рассмотрены возможности
пакета MS Excel для решения такого рода
задач, кроме того, приведены методы и
приемы построения (создания) регрессий
для таблично заданных функций (что
является основой регрессионного
анализа).
В
Excel для построения регрессий имеются
две возможности.
-
Добавление
выбранных регрессий (линий тренда —
trendlines) в диаграмму, построенную на
основе таблицы данных для исследуемой
характеристики процесса (доступно лишь
при наличии построенной диаграммы); -
Использование
встроенных статистических функций
рабочего листа Excel, позволяющих получать
регрессии (линии тренда) непосредственно
на основе таблицы исходных данных.
Добавление
линий тренда в диаграмму
Для
таблицы данных, описывающих некоторый
процесс и представленных диаграммой,
в Excel имеется эффективный инструмент
регрессионного анализа, позволяющий:
-
строить на основе
метода наименьших квадратов и добавлять
в диаграмму пять типов регрессий,
которые с той или иной степенью точности
моделируют исследуемый процесс; -
добавлять к
диаграмме уравнение построенной
регрессии; -
определять степень
соответствия выбранной регрессии
отображаемым на диаграмме данным.
На
основе данных диаграммы Excel позволяет
получать линейный, полиномиальный,
логарифмический, степенной, экспоненциальный
типы регрессий, которые задаются
уравнением:
y
= y(x)
где
x — независимая переменная, которая часто
принимает значения последовательности
натурального ряда чисел (1; 2; 3; …) и
производит, например, отсчет времени
протекания исследуемого процесса
(характеристики).
1.
Линейная регрессия хороша при моделировании
характеристик, значения которых
увеличиваются или убывают с постоянной
скоростью. Это наиболее простая в
построении модель исследуемого процесса.
Она строится в соответствии с уравнением:
y
= mx + b
где
m — тангенс угла наклона линейной регрессии
к оси абсцисс; b — координата точки
пересечения линейной регрессии с осью
ординат.
2.
Полиномиальная линия тренда полезна
для описания характеристик, имеющих
несколько ярко выраженных экстремумов
(максимумов и минимумов). Выбор степени
полинома определяется количеством
экстремумов исследуемой характеристики.
Так, полином второй степени может хорошо
описать процесс, имеющий только один
максимум или минимум; полином третьей
степени — не более двух экстремумов;
полином четвертой степени — не более
трех экстремумов и т. д.
В
этом случае линия тренда строится в
соответствии с уравнением:
y
= c0 + c1x + c2x2 + c3x3 + c4x4 + c5x5 + c6x6
где
коэффициенты c0, c1, c2,… c6 — константы,
значения которых определяются в ходе
построения.
3.
Логарифмическая линия тренда с успехом
применяется при моделировании
характеристик, значения которых вначале
быстро меняются, а затем постепенно
стабилизируются.
Строится
в соответствии с уравнением:
y
= c ln(x) + b
где
коэффициенты b, с — константы.
4.
Степенная линия тренда дает хорошие
результаты, если значения исследуемой
зависимости характеризуются постоянным
изменением скорости роста. Примером
такой зависимости может служить график
равноускоренного движения автомобиля.
Если среди данных встречаются нулевые
или отрицательные значения, использовать
степенную линию тренда нельзя.
Строится
в соответствии с уравнением:
y
= c xb
где
коэффициенты b, с — константы.
5.
Экспоненциальную линию тренда следует
использовать в том случае, если скорость
изменения данных непрерывно возрастает.
Для данных, содержащих нулевые или
отрицательные значения, этот вид
приближения также неприменим.
Строится
в соответствии с уравнением:
y
= c ebx
где
коэффициенты b, с — константы.
При
подборе линии тренда Excel автоматически
рассчитывает значение величины R2,
которая характеризует достоверность
аппроксимации: чем ближе значение R2 к
единице, тем надежнее линия тренда
аппроксимирует исследуемый процесс.
При необходимости значение R2 всегда
можно отобразить на диаграмме.
Определяется
по формуле:

Для
добавления линии тренда к ряду данных
следует:
-
активизировать
построенную на основе ряда данных
диаграмму, т. е. щелкнуть в пределах
области диаграммы. В главном меню
появится пункт Диаграмма; -
после щелчка на
этом пункте на экране появится меню, в
котором следует выбрать команду Добавить
линию тренда.
Эти
же действия легко реализуются, если
навести указатель мыши на график,
соответствующий одному из рядов данных,
и щелкнуть правой кнопкой мыши; в
появившемся контекстном меню выбрать
команду Добавить линию тренда. На экране
появится диалоговое окно Линия тренда
с раскрытой вкладкой Тип (рис. 1).

После
этого необходимо:
Выбрать
на вкладке Тип необходимый тип линии
тренда (по умолчанию выбирается тип
Линейный). Для типа Полиномиальная в
поле Степень следует задать степень
выбранного полинома.
1.
В поле Построен на ряде перечислены все
ряды данных рассматриваемой диаграммы.
Для добавления линии тренда к конкретному
ряду данных следует в поле Построен на
ряде выбрать его имя.

При
необходимости, перейдя на вкладку
Параметры (рис. 2), можно для линии тренда
задать следующие параметры:
-
изменить название
линии тренда в поле Название
аппроксимирующей (сглаженной) кривой. -
задать количество
периодов (вперед или назад) для прогноза
в поле Прогноз; -
вывести в область
диаграммы уравнение линии тренда, для
чего следует включить флажок показать
уравнение на диаграмме; -
вывести в область
диаграммы значение достоверности
аппроксимации R2, для чего следует
включить флажок поместить на диаграмму
величину достоверности аппроксимации
(R^2); -
задать точку
пересечения линии тренда с осью Y, для
чего следует включить флажок пересечение
кривой с осью Y в точке; -
щелкнуть на кнопке
OK, чтобы закрыть диалоговое окно.
Для
того, чтобы начать редактирование уже
построенной линии тренда, существует
три способа:
-
воспользоваться
командой Выделенная линия тренда из
меню Формат, предварительно выбрав
линию тренда; -
выбрать команду
Формат линии тренда из контекстного
меню, которое вызывается щелчком правой
кнопки мыши по линии тренда; -
двойным щелчком
по линии тренда.
На
экране появится диалоговое окно Формат
линии тренда (рис. 3), содержащее три
вкладки: Вид, Тип, Параметры, причем
содержимое последних двух полностью
совпадает с аналогичными вкладками
диалогового окна Линия тренда (рис.1-2).
На вкладке Вид, можно задать тип линии,
ее цвет и толщину.

Для
удаления уже построенной линии тренда
следует выбрать удаляемую линию тренда
и нажать клавишу Delete.
Достоинствами
рассмотренного инструмента регрессионного
анализа являются:
-
относительная
легкость построения на диаграммах
линии тренда без создания для нее
таблицы данных; -
достаточно широкий
перечень типов предложенных линий
трендов, причем в этот перечень входят
наиболее часто используемые типы
регрессии; -
возможность
прогнозирования поведения исследуемого
процесса на произвольное (в пределах
здравого смысла) количество шагов
вперед, а также назад; -
возможность
получения уравнения линии тренда в
аналитическом виде; -
возможность, при
необходимости, получения оценки
достоверности проведенной аппроксимации.
К
недостаткам можно отнести следующие
моменты:
-
построение линии
тренда осуществляется лишь при наличии
диаграммы, построенной на ряде данных; -
процесс формирования
рядов данных для исследуемой характеристики
на основе полученных для нее уравнений
линий тренда несколько загроможден:
искомые уравнения регрессий обновляются
при каждом изменении значений исходного
ряда данных, но только в пределах области
диаграммы, в то время как ряд данных,
сформированный на основе старого
уравнения линии тренда, остается без
изменения; -
в отчетах сводных
диаграмм при изменении представления
диаграммы или связанного отчета сводной
таблицы имеющиеся линии тренда не
сохраняются, то есть до проведения
линий тренда или другого форматирования
отчета сводных диаграмм следует
убедиться, что макет отчета удовлетворяет
необходимым требованиям.
Линиями
тренда можно дополнить ряды данных,
представленные на диаграммах типа
график, гистограмма, плоские ненормированные
диаграммы с областями, линейчатые,
точечные, пузырьковые и биржевые.
Нельзя
дополнить линиями тренда ряды данных
на объемных, нормированных, лепестковых,
круговых и кольцевых диаграммах.
Использование
встроенных функций Excel
В
Excel имеется также инструмент регрессионного
анализа для построения линий тренда
вне области диаграммы. Для этой цели
можно использовать ряд статистических
функций рабочего листа, однако все они
позволяют строить лишь линейные или
экспоненциальные регрессии.
В
Excel имеется несколько функций для
построения линейной регрессии, в
частности:
-
ТЕНДЕНЦИЯ;
-
ЛИНЕЙН;
-
НАКЛОН и ОТРЕЗОК.
А
также несколько функций для построения
экспоненциальной линии тренда, в
частности:
-
РОСТ;
-
ЛГРФПРИБЛ.
Следует
отметить, что приемы построения регрессий
с помощью функций ТЕНДЕНЦИЯ и РОСТ
практически совпадают. То же самое можно
сказать и о паре функций ЛИНЕЙН и
ЛГРФПРИБЛ. Для четырех этих функций при
создании таблицы значений используются
такие возможности Excel, как формулы
массивов, что несколько загромождает
процесс построения регрессий. Заметим
также, что построение линейной регрессии,
на наш взгляд, легче всего осуществить
с помощью функций НАКЛОН и ОТРЕЗОК, где
первая из них определяет угловой
коэффициент линейной регрессии, а вторая
— отрезок, отсекаемый регрессией на оси
ординат.
Достоинствами
инструмента встроенных функций для
регрессионного анализа являются:
-
достаточно простой
однотипный процесс формирования рядов
данных исследуемой характеристики для
всех встроенных статистических функций,
задающих линии тренда; -
стандартная
методика построения линий тренда на
основе сформированных рядов данных; -
возможность
прогнозирования поведения исследуемого
процесса на необходимое количество
шагов вперед или назад.
А
к недостаткам относится то, что в Excel
нет встроенных функций для создания
других (кроме линейного и экспоненциального)
типов линий тренда. Это обстоятельство
часто не позволяет подобрать достаточно
точную модель исследуемого процесса,
а также получить близкие к реальности
прогнозы. Кроме того, при использовании
функций ТЕНДЕНЦИЯ и РОСТ не известны
уравнения линий тренда.
Следует
отметить, что авторы не ставили целью
статьи изложение курса регрессионного
анализа с той или иной степенью полноты.
Основная ее задача — на конкретных
примерах показать возможности пакета
Excel при решении задач аппроксимации;
продемонстрировать, какими эффективными
инструментами для построения регрессий
и прогнозирования обладает Excel;
проиллюстрировать, как относительно
легко такие задачи могут быть решены
даже пользователем, не владеющим
глубокими знаниями регрессионного
анализа.
Примеры решения
конкретных задач
Рассмотрим
решение конкретных задач с помощью
перечисленных инструментов пакета
Excel.
Задача
1
С
таблицей данных о прибыли автотранспортного
предприятия за 1995-2002 гг. необходимо
выполнить следующие действия.
-
Построить диаграмму.
-
В диаграмму
добавить линейную и полиномиальную
(квадратичную и кубическую) линии
тренда. -
Вывести уравнения
полученных линий тренда, а также величины
достоверности аппроксимации R2 для
каждой из них. -
Используя уравнения
линий тренда, получить табличные данные
по прибыли предприятия для каждой линии
тренда за 1995-2004 г.г. -
Составить прогноз
по прибыли предприятия на 2003 и 2004 гг.
Решение
задачи

-
В диапазон ячеек
A4:C11 рабочего листа Excel вводим рабочую
таблицу, представленную на рис. 4. -
Выделив диапазон
ячеек В4:С11, строим диаграмму. -
Активизируем
построенную диаграмму и по описанной
выше методике после выбора типа линии
тренда в диалоговом окне Линия тренда
(см. рис. 1) поочередно добавляем в
диаграмму линейную, квадратичную и
кубическую линии тренда. В этом же
диалоговом окне открываем вкладку
Параметры (см. рис. 2), в поле Название
аппроксимирующей (сглаженной) кривой
вводим наименование добавляемого
тренда, а в поле Прогноз вперед на:
периодов задаем значение 2, так как
планируется сделать прогноз по прибыли
на два года вперед. Для вывода в области
диаграммы уравнения регрессии и значения
достоверности аппроксимации R2 включаем
флажки показывать уравнение на экране
и поместить на диаграмму величину
достоверности аппроксимации (R^2). Для
лучшего визуального восприятия изменяем
тип, цвет и толщину построенных линий
тренда, для чего воспользуемся вкладкой
Вид диалогового окна Формат линии
тренда (см. рис. 3). Полученная диаграмма
с добавленными линиями тренда представлена
на рис. 5. -
Для получения
табличных данных по прибыли предприятия
для каждой линии тренда за 1995-2004 гг.
воспользуемся уравнениями линий тренда,
представленными на рис. 5. Для этого в
ячейки диапазона D3:F3 вводим текстовую
информацию о типе выбранной линии
тренда: Линейный тренд, Квадратичный
тренд, Кубический тренд. Далее вводим
в ячейку D4 формулу линейной регрессии
и, используя маркер заполнения, копируем
эту формулу c относительными ссылками
в диапазон ячеек D5:D13. Следует отметить,
что каждой ячейке с формулой линейной
регрессии из диапазона ячеек D4:D13 в
качестве аргумента стоит соответствующая
ячейка из диапазона A4:A13. Аналогично
для квадратичной регрессии заполняется
диапазон ячеек E4:E13, а для кубической
регрессии — диапазон ячеек F4:F13. Таким
образом, составлен прогноз по прибыли
предприятия на 2003 и 2004 гг. с помощью
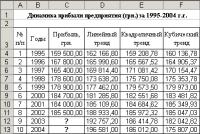
трех трендов. Полученная таблица
значений представлена на рис. 6.

Задача
2
С
таблицей данных о прибыли автотранспортного
предприятия за 1995-2002 гг., приведенной в
задаче 1, необходимо выполнить следующие
действия.
-
Построить диаграмму.
-
В диаграмму
добавить логарифмическую, степенную
и экспоненциальную линии тренда. -
Вывести уравнения
полученных линий тренда, а также величины
достоверности аппроксимации R2 для
каждой из них. -
Используя уравнения
линий тренда, получить табличные данные
о прибыли предприятия для каждой линии
тренда за 1995-2002 гг. -
Составить прогноз
о прибыли предприятия на 2003 и 2004 гг.,
используя эти линии тренда.
Решение
задачи
Следуя
методике, приведенной при решении задачи
1, получаем диаграмму с добавленными в
нее логарифмической, степенной и
экспоненциальной линиями тренда (рис.
7). Далее, используя полученные уравнения
линий тренда, заполняем таблицу значений
по прибыли предприятия, включая
прогнозируемые значения на 2003 и 2004 гг.
(рис. 8).


На
рис. 5 и рис. видно, что модели с
логарифмическим трендом, соответствует
наименьшее значение достоверности
аппроксимации
R2
= 0,8659
Наибольшие
же значения R2 соответствуют моделям с
полиномиальным трендом: квадратичным
(R2 = 0,9263) и кубическим (R2 = 0,933).
Задача
3
С
таблицей данных о прибыли автотранспортного
предприятия за 1995-2002 гг., приведенной в
задаче 1, необходимо выполнить следующие
действия.
-
Получить ряды
данных для линейной и экспоненциальной
линии тренда с использованием функций
ТЕНДЕНЦИЯ и РОСТ. -
Используя функции
ТЕНДЕНЦИЯ и РОСТ, составить прогноз о
прибыли предприятия на 2003 и 2004 гг. -
Для исходных
данных и полученных рядов данных
построить диаграмму.
Решение
задачи
Воспользуемся
рабочей таблицей задачи 1 (см. рис. 4).
Начнем с функции ТЕНДЕНЦИЯ:
-
выделяем диапазон
ячеек D4:D11, который следует заполнить
значениями функции ТЕНДЕНЦИЯ,
соответствующими известным данным о
прибыли предприятия; -
вызываем команду
Функция из меню Вставка. В появившемся
диалоговом окне Мастер функций выделяем
функцию ТЕНДЕНЦИЯ из категории
Статистические, после чего щелкаем по
кнопке ОК. Эту же операцию можно
осуществить нажатием кнопки (Вставка
функции) стандартной панели инструментов. -
В появившемся
диалоговом окне Аргументы функции
вводим в поле Известные_значения_y
диапазон ячеек C4:C11; в поле Известные_значения_х
— диапазон ячеек B4:B11; -
чтобы вводимая
формула стала формулой массива,
используем комбинацию клавиш + + .
Введенная
нами формула в строке формул будет иметь
вид: ={ТЕНДЕНЦИЯ(C4:C11;B4:B11)}.
В
результате диапазон ячеек D4:D11 заполняется
соответствующими значениями функции
ТЕНДЕНЦИЯ (рис. 9).

Для
составления прогноза о прибыли предприятия
на 2003 и 2004 гг. необходимо:
-
выделить диапазон
ячеек D12:D13, куда будут заноситься
значения, прогнозируемые функцией
ТЕНДЕНЦИЯ. -
вызвать функцию
ТЕНДЕНЦИЯ и в появившемся диалоговом
окне Аргументы функции ввести в поле
Известные_значения_y — диапазон ячеек
C4:C11; в поле Известные_значения_х —
диапазон ячеек B4:B11; а в поле Новые_значения_х
— диапазон ячеек B12:B13. -
превратить эту
формулу в формулу массива, используя
комбинацию клавиш Ctrl + Shift + Enter. -
Введенная формула
будет иметь вид: ={ТЕНДЕНЦИЯ(C4:C11;B4:B11;B12:B13
)}, а диапазон ячеек D12:D13 заполнится
прогнозируемыми значениями функции
ТЕНДЕНЦИЯ (см. рис. 9).
Аналогично
заполняется ряд данных с помощью функции
РОСТ, которая используется при анализе
нелинейных зависимостей и работает
точно так же, как ее линейный аналог
ТЕНДЕНЦИЯ.
На
рис.10 представлена таблица в режиме
показа формул.


Для
исходных данных и полученных рядов
данных построена диаграмма, изображенная
на рис. 11.
Задача
4
С
таблицей данных о поступлении в
диспетчерскую службу автотранспортного
предприятия заявок на услуги за период
с 1 по 11 число текущего месяца необходимо
выполнить следующие действия.
-
Получить ряды
данных для линейной регрессии: используя
функции НАКЛОН и ОТРЕЗОК; используя
функцию ЛИНЕЙН. -
Получить ряд
данных для экспоненциальной регрессии
с использованием функции ЛГРФПРИБЛ. -
Используя
вышеназванные функции, составить
прогноз о поступлении заявок в
диспетчерскую службу на период с 12 по
14 число текущего месяца. -
Для исходных и
полученных рядов данных построить
диаграмму.
Решение
задачи
Отметим,
что, в отличие от функций ТЕНДЕНЦИЯ и
РОСТ, ни одна из перечисленных выше
функций (НАКЛОН, ОТРЕЗОК, ЛИНЕЙН, ЛГРФПРИБ)
не является регрессией. Эти функции
играют лишь вспомогательную роль,
определяя необходимые параметры
регрессии.
Для
линейной и экспоненциальной регрессий,
построенных с помощью функций НАКЛОН,
ОТРЕЗОК, ЛИНЕЙН, ЛГРФПРИБ, внешний вид
их уравнений всегда известен, в отличие
от линейной и экспоненциальной регрессий,
соответствующих функциям ТЕНДЕНЦИЯ и
РОСТ.
1.
Построим линейную регрессию, имеющую
уравнение:
y
= mx+b
с
помощью функций НАКЛОН и ОТРЕЗОК, причем
угловой коэффициент регрессии m
определяется функцией НАКЛОН, а свободный
член b — функцией ОТРЕЗОК.
Для
этого осуществляем следующие действия:
-
заносим исходную
таблицу в диапазон ячеек A4:B14; -
значение параметра
m будет определяться в ячейке С19. Выбираем
из категории Статистические функцию
Наклон; заносим диапазон ячеек B4:B14 в
поле известные_значения_y и диапазон
ячеек А4:А14 в поле известные_значения_х.
В ячейку С19 будет введена формула:
=НАКЛОН(B4:B14;A4:A14); -
по аналогичной
методике определяется значение параметра
b в ячейке D19. И ее содержимое будет иметь
вид: =ОТРЕЗОК(B4:B14;A4:A14). Таким образом,
необходимые для построения линейной
регрессии значения параметров m и b
будут сохраняться соответственно в
ячейках C19, D19; -
далее заносим в
ячейку С4 формулу линейной регрессии
в виде: =$C*A4+$D. В этой формуле ячейки С19
и D19 записаны с абсолютными ссылками
(адрес ячейки не должен меняться при
возможном копировании). Знак абсолютной
ссылки $ можно набить либо с клавиатуры,
либо с помощью клавиши F4, предварительно
установив курсор на адресе ячейки.
Воспользовавшись маркером заполнения,
копируем эту формулу в диапазон ячеек
С4:С17. Получаем искомый ряд данных (рис.
12). В связи с тем, что количество заявок
— целое число, следует установить на
вкладке Число окна Формат ячеек числовой
формат с числом десятичных знаков 0.
2.
Теперь построим линейную регрессию,
заданную уравнением:
y
= mx+b
с
помощью функции ЛИНЕЙН.
Для
этого:
-
вводим в диапазон
ячеек C20:D20 функцию ЛИНЕЙН как формулу
массива: ={ЛИНЕЙН(B4:B14;A4:A14)}. В результате
получаем в ячейке C20 значение параметра
m, а в ячейке D20 — значение параметра b; -
вводим в ячейку
D4 формулу: =$C*A4+$D; -
копируем эту
формулу с помощью маркера заполнения
в диапазон ячеек D4:D17 и получаем искомый
ряд данных.
3.
Строим экспоненциальную регрессию,
имеющую уравнение:
y
= bmx
с
помощью функции ЛГРФПРИБЛ оно выполняется
аналогично:
-
в диапазон ячеек
C21:D21 вводим функцию ЛГРФПРИБЛ как
формулу массива: ={ ЛГРФПРИБЛ
(B4:B14;A4:A14)}. При этом в ячейке C21 будет
определено значение параметра m, а в
ячейке D21 — значение параметра b; -
в ячейку E4 вводится
формула: =$D*$C^A4; -
с помощью маркера
заполнения эта формула копируется в
диапазон ячеек E4:E17, где и расположится
ряд данных для экспоненциальной
регрессии (см. рис. 12).

На
рис. 13 приведена таблица, где видны
используемые нами функции с необходимыми
диапазонами ячеек, а также формулы.
Величина R2 называется
коэффициентом
детерминации.
Задачей построения
регрессионной зависимости является
нахождение вектора коэффициентов m
модели (1) при котором коэффициент R
принимает максимальное значение.
Для оценки значимости
R применяется F-критерий Фишера, вычисляемый
по формуле

где n
— размер выборки (количество экспериментов);
k — число коэффициентов
модели.
Если F превышает
некоторое критическое значение для
данных n
и k
и принятой доверительной вероятности,
то величина R считается существенной.
Таблицы критических значений F приводятся
в справочниках по математической
статистике.
Таким образом,
значимость R определяется не только его
величиной, но и соотношением между
количеством экспериментов и количеством
коэффициентов (параметров) модели.
Действительно, корреляционное отношение
для n=2 для простой линейной модели равно
1 (через 2 точки на плоскости можно всегда
провести единственную прямую). Однако
если экспериментальные данные являются
случайными величинами, доверять такому
значению R следует с большой осторожностью.
Обычно для получения значимого R и
достоверной регрессии стремятся к тому,
чтобы количество экспериментов
существенно превышало количество
коэффициентов модели (n>k).
Для построения
линейной регрессионной модели необходимо:
1) подготовить
список из n строк и m столбцов, содержащий
экспериментальные данные (столбец,
содержащий выходную величину Y
должен быть
либо первым, либо последним в списке);
для примера возьмем данные предыдущего
задания, добавив столбец с названием
«№ периода», пронумеруем номера
периодов от 1 до 12. (это будут значения
Х)
2) обратиться к
меню Данные/Анализ
данных/Регрессия

Если пункт «Анализ
данных» в
меню «Сервис» отсутствует,
то следует обратиться к пункту
«Надстройки» того
же меню и установить флажок «Пакет
анализа».
3) в диалоговом
окне «Регрессия» задать:
·
входной интервал Y;
·
входной интервал X;
·
выходной интервал — верхняя левая ячейка
интервала, в который будут помещаться
результаты вычислений (рекомендуется
разместить на новом рабочем листе);

4) нажать «Ok»
и проанализировать результаты.
Метод приближения в статистике  Результат подгонки набора точек данных квадратичной функцией
Результат подгонки набора точек данных квадратичной функцией  Коническая подгонка набора точек с использованием аппроксимации наименьших квадратов
Коническая подгонка набора точек с использованием аппроксимации наименьших квадратов
Метод наименьших квадратов является стандартным подходом в регрессионном анализе для аппроксимации решения переопределенных систем (наборы уравнения, в которых уравнений больше, чем неизвестных) путем минимизации суммы квадратов остатков, полученных в результате каждого отдельного уравнения.
Наиболее важное приложение — подгонка данных. Наилучшее соответствие в смысле наименьших квадратов минимизирует сумму возведенных в квадрат остатков (остаток: разница между наблюдаемым значением и подобранным значением, предоставленным моделью). Когда проблема имеет существенные неопределенности в независимой переменной (переменной x), тогда возникают проблемы с простыми методами регрессии и наименьших квадратов; в таких случаях вместо метода наименьших квадратов можно использовать методологию, необходимую для подбора моделей ошибок в переменных.
Задачи наименьших квадратов делятся на две категории: линейные или обычные наименьшие квадраты и нелинейные наименьшие квадраты, в зависимости от того, являются ли невязки линейными по всем неизвестным. Проблема линейных наименьших квадратов возникает в статистическом регрессионном анализе ; у него есть закрытое решение. Нелинейная задача обычно решается итеративным уточнением; на каждой итерации система аппроксимируется линейной, поэтому расчет керна в обоих случаях одинаков.
Полиномиальный метод наименьших квадратов описывает дисперсию предсказания зависимой переменной как функцию независимой переменной и отклонения от подобранной кривой.
Когда наблюдения происходят из экспоненциального семейства и удовлетворяются мягкие условия, оценки методом наименьших квадратов и оценки максимального правдоподобия идентичны. Метод наименьших квадратов также может быть получен как метод оценки моментов.
Следующее обсуждение в основном представлено в терминах линейных функций, но использование наименьших квадратов допустимо и практично для более общих семейств функций. Кроме того, итеративно применяя локальную квадратичную аппроксимацию к правдоподобию (через информацию Фишера ), можно использовать метод наименьших квадратов для аппроксимации обобщенной линейной модели.
Метод наименьших квадратов: обычно приписывается Карлу Фридриху Гауссу (1795), но впервые он был опубликован Адрианом-Мари Лежандром (1805).
Содержание
- 1 История
- 1.1 Основание
- 1.2 Метод
- 2 Постановка проблемы
- 3 Ограничения
- 4 Решение задачи наименьших квадратов
- 4.1 Линейный метод наименьших квадратов
- 4.2 Нелинейный метод наименьших квадратов
- 4.3 Различия между линейным и нелинейный метод наименьших квадратов
- 5 Регрессионный анализ и статистика
- 6 Взвешенный метод наименьших квадратов
- 7 Отношение к основным компонентам
- 8 Регуляризация
- 8.1 Регуляризация Тихонова
- 8.2 Метод лассо
- 9 См. также
- 10 Ссылки
- 11 Дополнительная литература
- 12 Внешние ссылки
История
Основание
Метод наименьших квадратов вырос из области астрономии и геодезия, поскольку ученые и математики стремились найти решения проблем навигации по океанам Земли во время эпохи исследований. Точное описание поведения небесных тел было ключом к тому, чтобы корабли могли плавать в открытом море, где моряки больше не могли полагаться на наземные наблюдения для навигации.
Этот метод стал кульминацией нескольких достижений, имевших место в течение восемнадцатого века:
- Комбинация различных наблюдений как наилучшая оценка истинной ценности; ошибки уменьшаются с агрегированием, а не увеличиваются, что, возможно, впервые было выражено Роджером Котсом в 1722 году.
- Комбинация различных наблюдений, сделанных в одинаковых условиях, вопреки простому стремлению изо всех сил наблюдать и записывать разовое наблюдение точно. Этот подход был известен как метод средних значений. Этот подход особенно использовался Тобиасом Майером при изучении либраций Луны в 1750 году, а также Пьером-Симоном Лапласом в его работе по объяснению различий в движение Юпитера и Сатурна в 1788 году.
- Комбинация различных наблюдений, сделанных в разных условиях. Этот метод стал известен как метод наименьшего абсолютного отклонения. В частности, это было выполнено Роджером Джозефом Босковичем в его работе о форме земли в 1757 году и Пьером-Симоном Лапласом в той же задаче в 1799 году.
- Разработка критерия, который может быть оценен, чтобы определить, когда было достигнуто решение с минимальной ошибкой. Лаплас попытался определить математическую форму плотности вероятности для ошибок и определить метод оценки, который минимизирует ошибку оценки. Для этой цели Лаплас использовал симметричное двустороннее экспоненциальное распределение, которое мы теперь называем распределением Лапласа для моделирования распределения ошибок, и использовал сумму абсолютных отклонений в качестве ошибки оценки. Он чувствовал, что это самые простые предположения, которые он мог сделать, и надеялся получить среднее арифметическое как наилучшую оценку. Вместо этого его оценкой была апостериорная медиана.
Метод
 Карл Фридрих Гаусс
Карл Фридрих Гаусс
Первое четкое и краткое изложение метода наименьших квадратов было опубликовано Лежандром в 1805 году. описывается как алгебраическая процедура подгонки линейных уравнений к данным, а Лежандр демонстрирует новый метод, анализируя те же данные, что и Лаплас, для формы Земли. Ценность метода наименьших квадратов Лежандра была немедленно признана ведущими астрономами и геодезистами того времени.
В 1809 Карл Фридрих Гаусс опубликовал свой метод расчета орбит небесных тел. В этой работе он утверждал, что владеет методом наименьших квадратов с 1795 года. Это, естественно, привело к спору о приоритете с Лежандром. Однако, к чести Гаусса, он вышел за рамки Лежандра и сумел связать метод наименьших квадратов с принципами вероятности и нормальным распределением. Ему удалось завершить программу Лапласа по определению математической формы плотности вероятности для наблюдений, зависящей от конечного числа неизвестных параметров, и определить метод оценки, который минимизирует ошибку оценки. Гаусс показал, что среднее арифметическое действительно является наилучшей оценкой параметра местоположения, изменив как плотность вероятности, так и метод оценки. Затем он решил проблему, задав вопрос, какую форму должна иметь плотность и какой метод оценки следует использовать, чтобы получить среднее арифметическое значение в качестве оценки параметра местоположения. В этой попытке он изобрел нормальное распределение.
Ранняя демонстрация силы метода Гаусса произошла, когда он использовался для предсказания будущего местоположения недавно открытого астероида Церера. 1 января 1801 года итальянский астроном Джузеппе Пьяцци открыл Цереру и смог проследить ее путь в течение 40 дней, прежде чем она затерялась в ярком солнечном свете. Основываясь на этих данных, астрономы хотели определить местоположение Цереры после того, как она появилась из-за Солнца, не решая сложных нелинейных уравнений движения планет Кеплера. Единственные предсказания, которые позволили венгерскому астроному Францу Ксаверу фон Заку переместить Цереру, были сделаны 24-летним Гауссом с использованием анализа наименьших квадратов.
В 1810 году, после прочтения работы Гаусса, Лаплас, после доказательства центральной предельной теоремы, использовал ее для обоснования большой выборки метода наименьших квадратов и нормального распределения. В 1822 году Гаусс смог заявить, что подход наименьших квадратов к регрессионному анализу является оптимальным в том смысле, что в линейной модели, где ошибки имеют нулевое среднее значение, некоррелированы и имеют равные дисперсии, наилучшая линейная несмещенная оценка коэффициенты — это оценка методом наименьших квадратов. Этот результат известен как теорема Гаусса – Маркова.
Идея анализа наименьших квадратов была также независимо сформулирована американцем Робертом Адрейном в 1808 году. В последующие два столетия работники теории ошибок и в статистике обнаружено много различных способов реализации метода наименьших квадратов.
Постановка проблемы
Цель состоит в настройке параметров модельной функции для наилучшего соответствия набору данных. Простой набор данных состоит из n точек (пар данных) (xi, yi) { displaystyle (x_ {i}, y_ {i}) !} , i = 1,…, n, где xi { displaystyle x_ {i} !}
, i = 1,…, n, где xi { displaystyle x_ {i} !} — независимая переменная и yi { displaystyle y_ {i} !}
— независимая переменная и yi { displaystyle y_ {i} !} — это зависимая переменная, значение которой определяется путем наблюдения. Модельная функция имеет вид f (x, β) { displaystyle f (x, beta)}
— это зависимая переменная, значение которой определяется путем наблюдения. Модельная функция имеет вид f (x, β) { displaystyle f (x, beta)} , где m настраиваемых параметров хранятся в векторе β { displaystyle { boldsymbol { beta}}}
, где m настраиваемых параметров хранятся в векторе β { displaystyle { boldsymbol { beta}}} . Цель состоит в том, чтобы найти значения параметров для модели, которые «наилучшим образом» соответствуют данным. Подгонка модели к точке данных измеряется ее невязкой, определяемой как разница между фактическим значением зависимой переменной и значением, предсказанным моделью:
. Цель состоит в том, чтобы найти значения параметров для модели, которые «наилучшим образом» соответствуют данным. Подгонка модели к точке данных измеряется ее невязкой, определяемой как разница между фактическим значением зависимой переменной и значением, предсказанным моделью:
- ri = yi — f ( xi, β). { displaystyle r_ {i} = y_ {i} -f (x_ {i}, { boldsymbol { beta}}).}

 Остатки наносятся на соответствующий x { displaystyle x}значений. Случайные колебания около ri = 0 { displaystyle r_ {i} = 0}указывают на то, что подходит линейная модель.
Остатки наносятся на соответствующий x { displaystyle x}значений. Случайные колебания около ri = 0 { displaystyle r_ {i} = 0}указывают на то, что подходит линейная модель.

Метод наименьших квадратов находит оптимальные значения параметров, минимизируя сумму, S { displaystyle S} , квадратов остатков:
, квадратов остатков:
S = ∑ i = 1 nri 2. { displaystyle S = sum _ {i = 1} ^ {n} r_ {i} ^ {2}.}
Примером двухмерной модели является модель с прямой линией. Обозначив точку пересечения оси Y как β 0 { displaystyle beta _ {0}} , а наклон как β 1 { displaystyle beta _ {1}}
, а наклон как β 1 { displaystyle beta _ {1}} , модельная функция задается следующим образом: f (x, β) = β 0 + β 1 x { displaystyle f (x, { boldsymbol { beta}}) = beta _ {0} + бета _ {1} x}
, модельная функция задается следующим образом: f (x, β) = β 0 + β 1 x { displaystyle f (x, { boldsymbol { beta}}) = beta _ {0} + бета _ {1} x} . См. линейный метод наименьших квадратов для получения полностью разработанного примера этой модели.
. См. линейный метод наименьших квадратов для получения полностью разработанного примера этой модели.
Точка данных может состоять из более чем одной независимой переменной. Например, при подгонке плоскости к набору измерений высоты плоскость является функцией двух независимых переменных, скажем, x и z. В наиболее общем случае в каждой точке данных может быть одна или несколько независимых переменных и одна или несколько зависимых переменных.
Справа — остаточный график, иллюстрирующий случайные колебания около ri = 0 { displaystyle r_ {i} = 0} , что указывает на то, что линейная модель (Y i = α + β xi + U i) { displaystyle (Y_ {i} = alpha + beta x_ {i} + U_ {i})}
, что указывает на то, что линейная модель (Y i = α + β xi + U i) { displaystyle (Y_ {i} = alpha + beta x_ {i} + U_ {i})} подходит. U i { displaystyle U_ {i}}
подходит. U i { displaystyle U_ {i}} — независимая случайная величина.
— независимая случайная величина.
 Остатки наносятся на график против соответствующего
Остатки наносятся на график против соответствующего
x { displaystyle x}
 ценности. Параболическая форма колебаний около
ценности. Параболическая форма колебаний около
ri = 0 { displaystyle r_ {i} = 0}
указывает на то, что подходит параболическая модель.
Если остаточные точки имели некоторую форму и не колеблются случайно, линейная модель не подходит. Например, если остаточный график имел параболическую форму, если смотреть справа, параболическая модель (Y i = α + β xi + γ xi 2 + U i) { displaystyle (Y_ {i} = alpha + beta x_ {i} + gamma x_ {i} ^ {2} + U_ {i})} подходит для данных. Невязки для параболической модели могут быть вычислены с помощью ri = yi — α ^ — β ^ xi — γ ^ xi 2 { displaystyle r_ {i} = y_ {i} — { hat { alpha}} — { hat { beta}} x_ {i} — { widehat { gamma}} x_ {i} ^ {2}}
подходит для данных. Невязки для параболической модели могут быть вычислены с помощью ri = yi — α ^ — β ^ xi — γ ^ xi 2 { displaystyle r_ {i} = y_ {i} — { hat { alpha}} — { hat { beta}} x_ {i} — { widehat { gamma}} x_ {i} ^ {2}} .
.
Ограничения
Эта формулировка регрессии учитывает только ошибки наблюдения в зависимой переменная (но альтернативная регрессия методом наименьших квадратов может учитывать ошибки в обеих переменных). Есть два довольно разных контекста с разными значениями:
- Регрессия для прогнозирования. Здесь модель подбирается для обеспечения правила прогнозирования для применения в аналогичной ситуации, к которой применяются данные, используемые для подгонки. Здесь зависимые переменные, соответствующие такому будущему применению, будут подвержены тем же типам ошибок наблюдения, что и в данных, используемых для подгонки. Следовательно, логически согласовано использование правила прогнозирования наименьших квадратов для таких данных.
- Регрессия для подбора «истинного отношения». В стандартном регрессионном анализе , который приводит к аппроксимации методом наименьших квадратов, неявно предполагается, что ошибки в независимой переменной равны нулю или строго контролируются, чтобы ими можно было пренебречь. Когда ошибки в независимой переменной нельзя пренебречь, можно использовать модели погрешности измерения ; такие методы могут привести к оценкам параметров, проверке гипотез и доверительным интервалам, которые учитывают наличие ошибок наблюдения в независимых переменных. Альтернативный подход — подобрать модель по общему количеству наименьших квадратов ; это можно рассматривать как прагматический подход к уравновешиванию эффектов различных источников ошибок при формулировании целевой функции для использования при подгонке модели.
Решение задачи наименьших квадратов
Минимум суммы квадратов находится путем установки градиента на ноль. Поскольку модель содержит m параметров, существует m уравнений градиента:
- ∂ S ∂ β j = 2 ∑ iri ∂ ri ∂ β j = 0, j = 1,…, m, { displaystyle { frac { partial S} { partial beta _ {j}}} = 2 sum _ {i} r_ {i} { frac { partial r_ {i}} { partial beta _ {j}}} = 0, j = 1, ldots, m,}

и поскольку ri = yi — f (xi, β) { displaystyle r_ {i} = y_ {i} -f (x_ {i}, { boldsymbol { beta}})} , уравнения градиента принимают вид
, уравнения градиента принимают вид
- — 2 ∑ iri ∂ f (xi, β) ∂ β j = 0, j = 1,…, m. { displaystyle -2 sum _ {i} r_ {i} { frac { partial f (x_ {i}, { boldsymbol { beta}})} { partial beta _ {j}}} = 0, j = 1, ldots, m.}

Уравнения градиента применимы ко всем задачам наименьших квадратов. Каждая конкретная проблема требует определенных выражений для модели и ее частных производных.
Линейный метод наименьших квадратов
Модель регрессии является линейной, если модель содержит линейную комбинацию из параметры, т. е.
- е (x, β) = ∑ j = 1 м β j ϕ j (x), { displaystyle f (x, beta) = sum _ {j = 1} ^ {m } beta _ {j} phi _ {j} (x),}

где функция ϕ j { displaystyle phi _ {j}} является функцией x { displaystyle x}.
является функцией x { displaystyle x}.
Пусть X ij = ϕ j (xi) { displaystyle X_ {ij} = phi _ {j} (x_ {i})} и поместив независимые и зависимые переменные в матрицы X { displaystyle X}
и поместив независимые и зависимые переменные в матрицы X { displaystyle X} и Y { displaystyle Y}
и Y { displaystyle Y} , мы можем вычислить наименьшие квадраты следующим образом обратите внимание, что D { displaystyle D}
, мы можем вычислить наименьшие квадраты следующим образом обратите внимание, что D { displaystyle D} — это набор всех данных.
— это набор всех данных.
- L (D, β →) = | | X β → — Y | | 2 знак равно (Икс β → — Y) T (Икс β → — Y) = YTY — YTX β → — β → TXTY + β → TXTX β → { Displaystyle L (D, { vec { beta}}) = || X { vec { beta}} — Y || ^ {2} = (X { vec { beta}} — Y) ^ {T} (X { vec { beta}} — Y) = Y ^ {T} YY ^ {T} X { vec { beta}} — { vec { beta}} ^ {T} X ^ {T} Y + { vec { beta}} ^ {T } X ^ {T} X { vec { beta}}}

Найти минимум можно, установив градиент потерь на ноль и решив для β → { displaystyle { vec { beta}}}
- ∂ L (D, β →) ∂ β → = ∂ (YTY — YTX β → — β → TXTY + β → TXTX β →) ∂ β → = — 2 XTY + 2 XTX β → { Displaystyle { frac { partial L (D, { vec { beta}})} { partial { vec { beta}}}} = { frac { partial left (Y ^ {T} YY ^ {T} X { vec { beta}} — { vec { beta}} ^ {T} X ^ {T} Y + { vec { beta}} ^ {T} X ^ {T} X { vec { beta}} right)} { partial { vec { beta}}}} = — 2X ^ {T} Y + 2X ^ {T} X { vec { beta}}}

Наконец, установив градиент потерь на ноль и решив для β → { displaystyle { vec { beta}}}, мы получим:
- — 2 XTY + 2 XTX β → = 0 ⇒ XTY = XTX β → ⇒ β ^ → = (XTX) — 1 XTY { displaystyle -2X ^ {T} Y + 2X ^ {T} X { vec { beta}} = 0 Rightarrow X ^ {T} Y = X ^ {T} X { vec { beta}} Rightarrow { vec { hat { beta}}} = (X ^ {T} X) ^ {- 1} X ^ {T} Y}

Нелинейный метод наименьших квадратов
В некоторых случаях существует решение в замкнутой форме нелинейной задачи наименьших квадратов, но в целом его нет. В случае отсутствия решения в закрытой форме используются численные алгоритмы для нахождения значения параметров β { displaystyle beta} , которое минимизирует цель. Большинство алгоритмов включают выбор начальных значений параметров. Затем параметры уточняются итеративно, то есть значения получаются последовательным приближением:
, которое минимизирует цель. Большинство алгоритмов включают выбор начальных значений параметров. Затем параметры уточняются итеративно, то есть значения получаются последовательным приближением:
- β jk + 1 = β jk + Δ β j, { displaystyle { beta _ {j}} ^ {k + 1 } = { beta _ {j}} ^ {k} + Delta beta _ {j},}

где верхний индекс k — номер итерации, а вектор приращений Δ β j { displaystyle Delta beta _ {j}} называется вектором сдвига. В некоторых часто используемых алгоритмах на каждой итерации модель может быть линеаризована путем приближения к разложению ряда Тейлора первого порядка около β k { displaystyle { boldsymbol { beta}} ^ {k }}
называется вектором сдвига. В некоторых часто используемых алгоритмах на каждой итерации модель может быть линеаризована путем приближения к разложению ряда Тейлора первого порядка около β k { displaystyle { boldsymbol { beta}} ^ {k }} :
:
- f (xi, β) = fk (xi, β) + ∑ j ∂ f (xi, β) ∂ β j (β j — β jk) = fk (xi, β) + ∑ j J ij Δ β j. { displaystyle { begin {align} f (x_ {i}, { boldsymbol { beta}}) = f ^ {k} (x_ {i}, { boldsymbol { beta}}) + sum _ {j} { frac { partial f (x_ {i}, { boldsymbol { beta}})} { partial beta _ {j}}} left ( beta _ {j} — { beta _ {j}} ^ {k} right) \ = f ^ {k} (x_ {i}, { boldsymbol { beta}}) + sum _ {j} J_ {ij} , Delta beta _ {j}. End {align}}}

Якобиан Jявляется функцией констант, независимой переменной и параметров, поэтому он изменяется от одной итерации к другой. Остатки определяются как
- r i = y i — f k (x i, β) — ∑ k = 1 m J i k Δ β k = Δ y i — j = 1 m J i j Δ β j. { displaystyle r_ {i} = y_ {i} -f ^ {k} (x_ {i}, { boldsymbol { beta}}) — sum _ {k = 1} ^ {m} J_ {ik} , Delta beta _ {k} = Delta y_ {i} — sum _ {j = 1} ^ {m} J_ {ij} , Delta beta _ {j}.}

Чтобы минимизировать сумму квадратов ri { displaystyle r_ {i}} , уравнение градиента устанавливается равным нулю и решается для Δ β j { displaystyle Delta beta _ { j}}:
, уравнение градиента устанавливается равным нулю и решается для Δ β j { displaystyle Delta beta _ { j}}:
- — 2 ∑ я знак равно 1 N J ij (Δ yi — ∑ k = 1 м J ik Δ β k) = 0, { displaystyle -2 sum _ {i = 1} ^ {n} J_ {ij} left ( Delta y_ {i} — sum _ {k = 1} ^ {m} J_ {ik} , Delta beta _ {k} right) = 0,}

которые при перестановке превращаются в m одновременных линейных уравнений, нормальные уравнения :
- ∑ i = 1 n ∑ k = 1 m J ij J ik Δ β k = ∑ i = 1 n J ij Δ yi (j = 1,…, м). { displaystyle sum _ {i = 1} ^ {n} sum _ {k = 1} ^ {m} J_ {ij} J_ {ik} , Delta beta _ {k} = sum _ { i = 1} ^ {n} J_ {ij} , Delta y_ {i} qquad (j = 1, ldots, m).}

Нормальные уравнения записываются в матричной записи как
- ( JTJ) Δ β = JT Δ y. { displaystyle mathbf {(J ^ {T} J) , Delta { boldsymbol { beta}} = J ^ {T} , Delta y}. ,}

Это определяющие уравнения алгоритма Гаусса – Ньютона.
Различия между линейным и нелинейным методом наименьших квадратов
- Модельная функция f в LLSQ (линейный метод наименьших квадратов) представляет собой линейную комбинацию параметров вида f = X я 1 β 1 + Икс я 2 β 2 + ⋯ { displaystyle f = X_ {i1} beta _ {1} + X_ {i2} beta _ {2} + cdots}Модель может представлять прямую линию, параболу или любую другую линейную комбинацию функций. В NLLSQ (нелинейный метод наименьших квадратов) лучше как функции, например β 2, e β x { displaystyle beta ^ {2}, e ^ { beta x}}и т. Д. вперед. Если производные ∂ f / ∂ β j { displaystyle partial f / partial beta _ {j}}либо постоянны, либо зависят только от значений независимой переменной, модель линейна по параметрам. В противном случае модель будет нелинейной.
- Требуются начальные значения для параметров, чтобы найти решение проблемы NLLSQ; Для LLSQ они не требуются.
- Алгоритмы решения для NLLSQ часто требуют, чтобы якобиан мог быть вычислен аналогично LLSQ. Аналитические выражения для частных производных могут быть сложными. Если получить невозможно аналитические выражения, либо частные производные должны быть вычислены с помощью численного приближения, либо должна быть сделана оценка якобиана, часто с помощью конечных разностей.
- Несходимость (неспособность алгоритма найти минимум) является обычным явлением в NLLSQ.
- LLSQ является глобально вогнутым, поэтому несходимость не является проблемой.
- Решение NLLSQ обычно представляет собой итеративный процесс, который должен быть завершен, когда критерий сходимости удовлетворен. Решения LLSQ могут быть вычислены с помощью специальных методов, как правило, с помощью таких методов, как метод Гаусса — Зейделя.
- В решении LLSQ является уникальным, но в NLLSQ может быть несколько минимумов в сумме квадратов.
- При условии, что ошибки не коррелируют с переменными-предикторами, LLSQ дает несмещенные оценки, но даже при этом условии оценки NLLSQ обычно смещены.
 Модель может представлять прямую линию, параболу или любую другую линейную комбинацию функций. В NLLSQ (нелинейный метод наименьших квадратов) лучше как функции, например β 2, e β x { displaystyle beta ^ {2}, e ^ { beta x}}
Модель может представлять прямую линию, параболу или любую другую линейную комбинацию функций. В NLLSQ (нелинейный метод наименьших квадратов) лучше как функции, например β 2, e β x { displaystyle beta ^ {2}, e ^ { beta x}} и т. Д. вперед. Если производные ∂ f / ∂ β j { displaystyle partial f / partial beta _ {j}}
и т. Д. вперед. Если производные ∂ f / ∂ β j { displaystyle partial f / partial beta _ {j}} либо постоянны, либо зависят только от значений независимой переменной, модель линейна по параметрам. В противном случае модель будет нелинейной.
либо постоянны, либо зависят только от значений независимой переменной, модель линейна по параметрам. В противном случае модель будет нелинейной.Эти особенности необходимо учитывать, когда ищется решение нелинейной задачи наименьших квадратов.
Регрессионный анализ и статистика
Метод наименьших квадратов часто используется для создания оценок и другой статистики. в регрессионном анализе.
Рассмотрим простой пример из физики. Пружина должна подчиняться закону Гука, который гласит, что растяжение пружины y пропорционально приложенной к ней силе F.
- y = f (F, k) = k F { displaystyle y = f (F, k) = kF !}

составляет модель, где F — независимая переменная. Чтобы оценить силовую постоянную , k, мы проводим серию из n измерений разными силами для получения набора данных, (F i, yi), i = 1,…, n { displaystyle (F_ { i}, y_ {i}), i = 1, dots, n !} , где y i — измеренное растяжение пружины. Каждое экспериментальное наблюдение будет содержать некоторую ошибку, ε { displaystyle varepsilon}
, где y i — измеренное растяжение пружины. Каждое экспериментальное наблюдение будет содержать некоторую ошибку, ε { displaystyle varepsilon} , поэтому мы можем указать эмпирическую модель для наших наблюдений,
, поэтому мы можем указать эмпирическую модель для наших наблюдений,
- y i = k F i + ε i. { displaystyle y_ {i} = kF_ {i} + varepsilon _ {i}. ,}

Есть много методов, которые мы можем использовать для оценки неизвестного парка. Переопределенную систему с одним неизвестным и n уравнениями, мы оцениваем k, используя метод наименьших квадратов. Сумма квадратов, которую нужно минимизировать, равна
- S = ∑ i = 1 n (yi — k F i) 2. { displaystyle S = sum _ {i = 1} ^ {n} (y_ {i} — kF_ {i}) ^ {2}.}

Дается оценка силовой постоянной k методом наименьших квадратов по
- k ^ = ∑ i F iyi ∑ i F i 2. { displaystyle { hat {k}} = { frac { sum _ {i} F_ {i} y_ {i}} { sum _ {i} F_ {i} ^ {2}}}.}

Мы предполагаем, что приложение силы заставляет пружину расширяться. После получения силовой постоянной постоянной наименьших квадратов мы методом прогнозируем расширение по закону Гука.
Исследователь указывает эмпирическую модель в регрессионном анализе. Очень распространенной моделью является прямолинейная модель, которая используется для проверки наличия линейной зависимости между независимыми и зависимыми переменными. Переменные называются коррелированными, если существует линейная зависимость. не доказывает причинно-следственную связь, поскольку обе переменные могут быть коррелированы с другими, скрытыми переменными, или зависимая переменная может «обратить» причину независимых переменных, или переменные могут быть иным образом ложно коррелированы. Например, предположим, что существует корреляция между смертностью от утопления и объемом мороженого на определенном пляже. Тем не менее, как количество людей, идущих купаться, так и объем продаж мороженого увеличиваются по мере, как становится жарче, и, по-видимому, количество смертей от утопления коррелирует с людьми, идущими купаться. Возможно, увеличение числа пловцов приводит к увеличению числа других.
Для статистической проверки результатов необходимо сделать предположения о природе экспериментальных ошибок. Распространенным предположением является то, что принадлежат ошибки нормальному распределению. Центральная предельная теорема поддерживает идею о том, что это хорошее приближение во многих случаях.
- Теорема Гаусса — Маркова. В линейной модели, в которой ошибки имеют математическое ожидание нулевое условие для независимых переменных, некоррелированы и имеют равные дисперсии, наилучшая линейная несмещенная оценка любая линейной комбинации наблюдений — ее оценка методом наименьших квадратов. «Наилучший» означает, что оценка методом наименьших квадратов имеют минимальную дисперсию. Предположение о равной дисперсии действительно, когда все ошибки принадлежат одному и тому же распределению.
- В линейной модели, если ошибки принадлежат нормальному распределению, оценкой методом наименьших квадратов также являются оценками минимальных правдоподобия ошибки.
Однако, если не имеют нормального распределения, центральная предельная теорема , тем не менее, подразумевает, что оценки параметров будут обычно нормально распределены. По этой причине, учитывая важное свойство, заключающееся в том, что среднее значение ошибки не зависит от независимого распределения, распределения члена ошибки не является важным вопросом в регрессионном анализе. В частности, обычно не важно, следует ли член ошибки нормальному распределению.
При вычислении методом наименьших квадратов с единичными весами или в линейной регрессии дисперсия j-го прогноза, обозначаемая var (β ^ j) { displaystyle operatorname {var} ({ hat { beta }} _ {j})} , обычно оценивается как
, обычно оценивается как
- var (β ^ j) = σ 2 ([XTX] — 1) jj ≈ S n — m ([XTX] — 1) jj, { displaystyle operatorname {var} ({ hat { beta}} _ {j}) = sigma ^ {2} ([X ^ {T} X] ^ {- 1}) _ {jj } приблизительно { frac {S} {nm}} ([X ^ {T} X] ^ {- 1}) _ {jj},}
![{ displaystyle operatorname {var} ({ hat { beta}} _ {j}) = sigma ^ {2} ([X ^ {T} X] ^ { -1}) _ {jj} приблизительно { frac {S} {nm}} ([X ^ {T} X] ^ {- 1}) _ {jj},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f77b192f37c6a5f592a7e5b0601ec7fa95b6703d)
где истинная погрешность ошибки σ заменяется на оценку, основанная на минимизированном значении основные функции суммы квадратов С. Знаменатель n — m представляет собой статистические степени свободы ; см. эффективные степени свободы для обобщений.
Если известно распределение вероятностей параметров или сделано асимптотическое приближение, доверительные границы может быть найден. Точно так же можно провести статистические тесты остатков, если распределение вероятностей остатков известно или признано. Мы можем получить вероятность вероятностей любой линейной комбинации зависимых чисел. Сделать вывод легко, если предположить, что ошибки следуют нормальному распределению, следовательно, подразумевая, что оценки параметров и остатки также будут нормально распределены в зависимости от независимых переменных.
Взвешенный метод наименьших квадратов
 «Разветвление. «Эффект гетероскедастичности
«Разветвление. «Эффект гетероскедастичности
Частный случай обобщенных наименьших квадратов, называемый взвешенных наименьших квадратов, возникает, когда все недиагональные элементы Ω (корреляционная матрица остатков) равны нулю; дисперсии наблюдений (по диагонали ковариационной матрицы) все еще могут быть неравными (гетероскедастичность ). Проще говоря, гетероскедастичность — это когда дисперсия Y i { displaystyle Y_ {i}} от значений xi { displaystyle x_ {i}}
от значений xi { displaystyle x_ {i}} , в результате чего остаточный график создает эффект «разветвления» в сторону больших значений Y i { displaystyle Y_ {i}}, как видно на остаточном графике, до права. С другой стороны, гомоскедастичность предполагает, что дисперсия Y i { displaystyle Y_ {i}}и U i { displaystyle U_ {i}}равно.
, в результате чего остаточный график создает эффект «разветвления» в сторону больших значений Y i { displaystyle Y_ {i}}, как видно на остаточном графике, до права. С другой стороны, гомоскедастичность предполагает, что дисперсия Y i { displaystyle Y_ {i}}и U i { displaystyle U_ {i}}равно.
Отношение к основному компоненту
Первый главный компонент о среднем значени и набора точек может быть представлена той линией, которая наиболее приближается к точкам данных (как измерено на квадратном пространстве наибольшего сближения, т.е. перпендикулярно линии). Напротив, линейный метод наименьших квадратов пытается минимизировать расстояние только в направлении y { displaystyle y} . Таким образом, хотя оба этих метода используют схожую метрику ошибки, метод наименьших квадратов — это метод, который обрабатывает одно измерение данных, как тогда PCA обрабатывает все измерения одинаково.
. Таким образом, хотя оба этих метода используют схожую метрику ошибки, метод наименьших квадратов — это метод, который обрабатывает одно измерение данных, как тогда PCA обрабатывает все измерения одинаково.
Регуляризация
Регуляризация Тихонова
В некоторых контекстах регуляризованная версия решений наименьших квадратов может быть предпочтительнее. Регуляризация Тихонова (или гребенчатая регрессия ) большее ограничение, которое ‖ β ‖ 2 { displaystyle | beta | ^ {2}} , L2-norm параметры времени не больше заданного значения. Точно так же он может решить неограниченную минимизацию штрафа методом наименьших квадратов с добавлением α ‖ β ‖ 2 { displaystyle alpha | beta | ^ {2}}
, L2-norm параметры времени не больше заданного значения. Точно так же он может решить неограниченную минимизацию штрафа методом наименьших квадратов с добавлением α ‖ β ‖ 2 { displaystyle alpha | beta | ^ {2}} , где α { displaystyle alpha}
, где α { displaystyle alpha} — константа (это лагранжева форма задачи с ограничениями). В контексте байесовского это эквивалентно помещению нормально распределенного предшествующего с нулевым средним в вектор параметров.
— константа (это лагранжева форма задачи с ограничениями). В контексте байесовского это эквивалентно помещению нормально распределенного предшествующего с нулевым средним в вектор параметров.
Метод лассо
Альтернативой регуляризованной версией наименьших квадратов является лассо (оператор наименьшего сжатия и выбора), который использует ограничение, которое ‖ β ‖ { displaystyle | beta |} , L1-норма события параметров, не больше заданного значения. (Как и выше, это эквивалентно неограниченной минимизации штрафа методом наименьших квадратов с добавлением α ‖ β ‖ { displaystyle alpha | beta |}
, L1-норма события параметров, не больше заданного значения. (Как и выше, это эквивалентно неограниченной минимизации штрафа методом наименьших квадратов с добавлением α ‖ β ‖ { displaystyle alpha | beta |} .) В Байесовский контекст, это эквивалентно помещению Лапласа априорного распределения с нулевым средним в вектор параметров. Проблема оптимизации может быть решена с использованием квадратичного программирования или более общих методов выпуклой оптимизации, а также с помощью конкретных алгоритмов, таких как алгоритм регрессии по наименьшему району.
.) В Байесовский контекст, это эквивалентно помещению Лапласа априорного распределения с нулевым средним в вектор параметров. Проблема оптимизации может быть решена с использованием квадратичного программирования или более общих методов выпуклой оптимизации, а также с помощью конкретных алгоритмов, таких как алгоритм регрессии по наименьшему району.
Одно из основных различий между регрессией лассо и гребневой регрессии состоит в том, что в регрессии гребня при увеличении штрафа все параметры уменьшаются, но все еще остаются ненулевыми, в то время как в лассо увеличение штрафа приводит к большему и больше параметров нужно свести к нулю. Это преимущество лассо перед регрессией гребня, так как приведение параметров к нулю отменяет выбор объектов из регрессии. Таким образом, Lasso автоматически выбирает более релевантные функции и отбрасывает другие, тогда как регрессия Ridge никогда полностью не отбрасывает какие-либо функции. Некоторые методы выбора функций разработаны на основе LASSO, включая Bolasso, который загружает образцы, и FeaLect, который анализирует коэффициенты регрессии, соответствующие различным значениям α { displaystyle alpha}для оценки всех функций.
L-регуляризованная формулировка полезна в некоторых контекстах из-за ее тенденции предпочитать решения, в которых больше параметров равно нулю, что дает решения, которые зависят от меньшего числа переменных. По этой причине лассо и его варианты являются основополагающими в области сжатого зондирования. Расширением этого подхода является эластичная чистая регуляризация.
См. Также
- Корректировка наблюдений
- Байесовская оценка MMSE
- Лучшая линейная несмещенная оценка (СИНИЙ)
- Лучший линейный несмещенный прогноз (BLUP)
- Теорема Гаусса – Маркова
- L2norm
- Наименьшее абсолютное отклонение
- Неопределенность измерения
- Ортогональная проекция
- Методы проксимального градиента для обучения
- Квадратичная функция потерь
- Корень среднеквадратичное
- Квадратные отклонения
Ссылки
Дополнительная литература
- Björck, Å. (1996). Численные методы решения задач наименьших квадратов. СИАМ. ISBN 978-0-89871-360-2.
- Кария, Т.; Курата, Х. (2004). Обобщенные наименьшие квадраты. Хобокен: Вайли. ISBN 978-0-470-86697-9.
- Люенбергер, Д. Г. (1997) [1969]. «Оценка методом наименьших квадратов». Оптимизация методов использования пространства. Нью-Йорк: Джон Вили и сыновья. С. 78–102. ISBN 978-0-471-18117-0.
- Рао, К. Р. ; ; и другие. (2008). Линейные модели: метод наименьших квадратов и альтернативы. Серия Спрингера в статистике (3-е изд.). Берлин: Springer. ISBN 978-3-540-74226-5.
- Вольберг, Дж. (2005). Анализ данных с использованием метода наименьших квадратов: извлечение максимальной информации из экспериментов. Берлин: Springer. ISBN 978-3-540-25674-8.
Внешние ссылки
 СМИ, связанные с методом наименьших квадратов на Wikimedia Commons
СМИ, связанные с методом наименьших квадратов на Wikimedia Commons
Метод наименьших квадратов регрессия
Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид
y=ax+b
a, b – коэффициенты линейного уравнения регрессии;
x – независимая переменная;
y – зависимая переменная.
Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов:
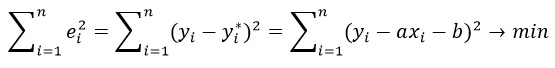
частные производные функции приравниваем к нулю
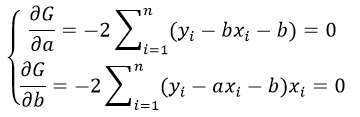
отсюда получаем систему линейных уравнений
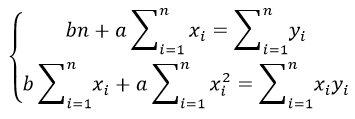
Формулы определения коэффициентов уравнения линейной регрессии:
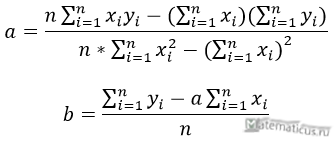
Также запишем уравнение регрессии для квадратной нелинейной функции:
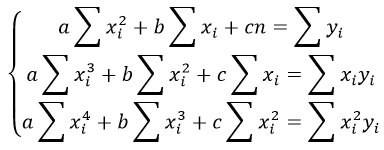
Система линейных уравнений регрессии полинома n-ого порядка:
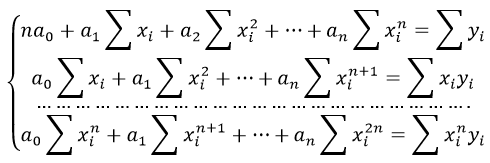
Формула коэффициента детерминации R 2 :
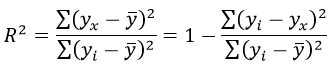
Формула средней ошибки аппроксимации для уравнения линейной регрессии (оценка качества модели):
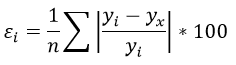
Чем меньше ε, тем лучше. Рекомендованный показатель ε
Формула среднеквадратической погрешности: 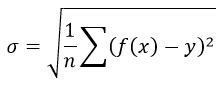
Для примера, проведём расчет для получения линейного уравнения регрессии аппроксимации функции, заданной в табличном виде:
| x | y |
| 3 | 4 |
| 4 | 7 |
| 6 | 11 |
| 7 | 16 |
| 9 | 18 |
| 11 | 22 |
| 13 | 24 |
| 15 | 27 |
| 16 | 30 |
| 19 | 33 |
Решение
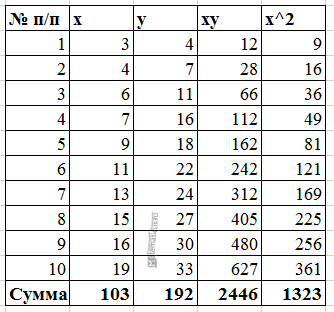
Расчеты значений суммы, произведения x и у приведены в таблицы.
Расчет коэффициентов линейной регрессии:
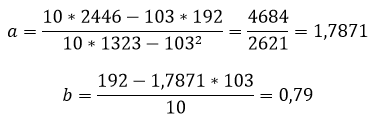
при этом средняя ошибка аппроксимации равна:
ε=11,168%
Получаем уравнение линейной регрессии с помощью метода наименьших квадратов:
y=1,7871x+0,79
График функции линейной зависимости y=1,7871x+0,79 и табличные значения, в виде точек
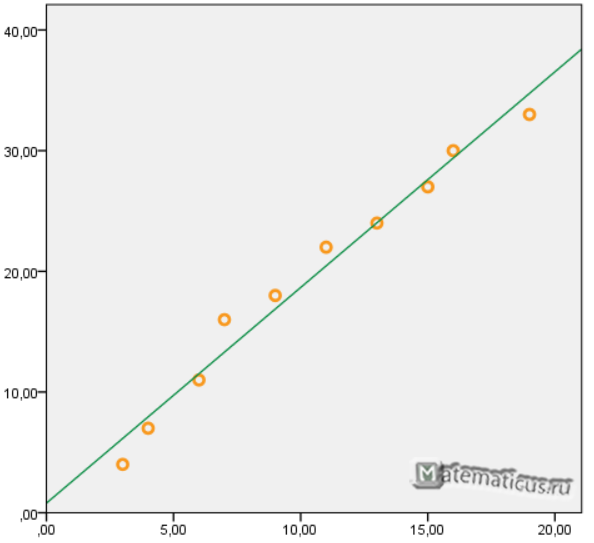
Коэффициент корреляции равен 0,988
Коэффициента детерминации равен 0,976
Решения задач: метод наименьших квадратов
Метод наименьших квадратов применяется для решения различных математических задач и основан на минимизации суммы квадратов отклонений функций от исходных переменных. Мы рассмотриваем его приложение к математической статистике в простейшем случае, когда нужно найти зависимость (парную линейную регрессию) между двумя переменными, заданными выборочными данным. В этом случае речь идет об отклонениях теоретических значений от экспериментальных.
Краткая инструкция по методу наименьших квадратов для чайников: определяем вид предполагаемой зависимости (чаще всего берется линейная регрессия вида $y(x)=ax+b$), выписываем систему уравнений для нахождения параметров $a, b$. По экспериментальным данным проводим вычисления и подставляем значения в систему, решаем систему любым удобным методом (для размерности 2-3 можно и вручную). Получается искомое уравнение.
Иногда дополнительно к нахождению уравнения регрессии требуется: найти остаточную дисперсию, сделать прогноз значений, найти значение коэффициента корреляции, проверить качество аппроксимации и значимость модели. Примеры решений вы найдете ниже. Удачи в изучении!
Примеры решений МНК
Пример 1. Методом наименьших квадратов для данных, представленных в таблице, найти линейную зависимость
Пример 2. Прибыль фирмы за некоторый период деятельности по годам приведена ниже:
Год 1 2 3 4 5
Прибыль 3,9 4,9 3,4 1,4 1,9
1) Составьте линейную зависимость прибыли по годам деятельности фирмы.
2) Определите ожидаемую прибыль для 6-го года деятельности. Сделайте чертеж.
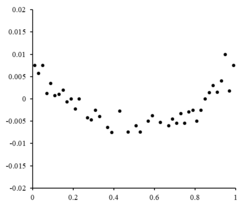
Пример 3. Экспериментальные данные о значениях переменных х и y приведены в таблице:
1 2 4 6 8
3 2 1 0,5 0
В результате их выравнивания получена функция Используя метод наименьших квадратов, аппроксимировать эти данные линейной зависимостью (найти параметры а и b). Выяснить, какая из двух линий лучше (в смысле метода наименьших квадратов) выравнивает экспериментальные данные. Сделать чертеж.
Пример 4. Данные наблюдений над случайной двумерной величиной (Х, Y) представлены в корреляционной таблице. Методом наименьших квадратов найти выборочное уравнение прямой регрессии Y на X.
Пример 5. Считая, что зависимость между переменными x и y имеет вид $y=ax^2+bx+c$, найти оценки параметров a, b и c методом наименьших квадратов по выборке:
x 7 31 61 99 129 178 209
y 13 10 9 10 12 20 26
Пример 6. Проводится анализ взаимосвязи количества населения (X) и количества практикующих врачей (Y) в регионе.
Годы 81 82 83 84 85 86 87 88 89 90
X, млн. чел. 10 10,3 10,4 10,55 10,6 10,7 10,75 10,9 10,9 11
Y, тыс. чел. 12,1 12,6 13 13,8 14,9 16 18 20 21 22
Оцените по МНК коэффициенты линейного уравнения регрессии $y=b_0+b_1x$.
Существенно ли отличаются от нуля найденные коэффициенты?
Проверьте значимость полученного уравнения при $alpha = 0,01$.
Если количество населения в 1995 году составит 11,5 млн. чел., каково ожидаемое количество врачей? Рассчитайте 99%-й доверительный интервал для данного прогноза.
Рассчитайте коэффициент детерминации
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Остатки нормально распределены с нулевым средним значением;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
источники:
http://www.matburo.ru/ex_ms.php?p1=msmnk
http://statistica.ru/theory/osnovy-lineynoy-regressii/