Метод коррекции ошибки — метод обучения перцептрона, предложенный Ф.Розенблаттом. Представляет собой такой метод обучения, при котором вес связи не изменяется до тех пор, пока текущая реакция перцептрона остается правильной. При появлении неправильной реакции вес изменяется на единицу, а знак (+/-) определяется противоположным от знака ошибки.
Модификации метода
В теореме сходимости перцептрона различаются различные виды этого метода, доказано, что любой из них позволяет получить схождение при решении любой задачи классификации.
Метод коррекции ошибок без квантования
Если реакция на стимул 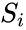 правильная, то никакого подкрепления не вводится, но при появлении ошибок к весу каждого активного А-элемента прибавляется величина
правильная, то никакого подкрепления не вводится, но при появлении ошибок к весу каждого активного А-элемента прибавляется величина  , где
, где 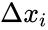 — число единиц подкрепления, выбирается так, чтобы величина сигнала превышала порог θ,
— число единиц подкрепления, выбирается так, чтобы величина сигнала превышала порог θ,
а 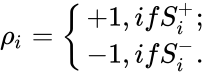 , при этом
, при этом 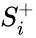 — стимул, принадлежащий положительному классу, а
— стимул, принадлежащий положительному классу, а  — стимул, принадлежащий отрицательному классу.
— стимул, принадлежащий отрицательному классу.
Метод коррекции ошибок с квантованием
Отличается от метода коррекции ошибок без квантованиея только тем, что 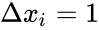 , то есть равно одной единице подкрепления.
, то есть равно одной единице подкрепления.
Это метод и метод коррекции ошибок без квантованиея являются одинаковыми по скорости достяжения решения в общем случае, и более эффективными по сравнению с методами коррекции ошибок со случайным знаком или случайными возмущениями.
Метод коррекции ошибок со случайным знаком подкрепления
Отличается тем, что знак подкрепления 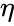 выбирается случайно независимо от реакции перцептрона и с равной вероятностью может быть положительным или отрицательным. Но так же как и в базовом методе — если перцептрон дает правильную реакцию, то подкрепление равно нулю.
выбирается случайно независимо от реакции перцептрона и с равной вероятностью может быть положительным или отрицательным. Но так же как и в базовом методе — если перцептрон дает правильную реакцию, то подкрепление равно нулю.
Метод коррекции ошибок со случайными возмущениями
Отличается тем, что величина и знак для каждой связи в системе выбираются отдельно и независимо в соответствии с некоторым распределением вероятностей. Это метод приводит к самой медленной сходимости, по сравнению с выше описанными модификациями.
См. также
- Теорема сходимости Перцептрона
- Дельта-правило
- Перцептрон
Литература
- Фрэнк Розенблатт Принципы нейродинамики: перцептроны и теория механизмов мозга = Principles of Neurodynamic: perceptrons and the theory of brain mechanisms. — М.: «Мир», 1965.
Это основополагающая версия, написанная участниками этого проекта. Но содержимое этой страницы очень близкое по содержанию предоставлено для раздела Википедии на русском языке. Так же, как и в этом проекте, текст этой статьи, размещённый в Википедии, доступен на условиях CC-BY-SA . Статью, размещенную в Википедии можно найти по адресу: Метод коррекции ошибки.
Рад снова всех приветствовать, и сегодня продолжим планомерно двигаться в выбранном направлении. Речь, конечно, о масштабном разборе искусственных нейронных сетей для решения широкого спектра задач. Продолжим ровно с того момента, на котором остановились в предыдущей части, и это означает, что героем данного поста будет ключевой процесс — обучение нейронных сетей.
Тема эта крайне важна, поскольку именно процесс обучения позволяет сети начать выполнять задачу, для которой она, собственно, и предназначена. То есть нейронная сеть функционирует не по какому-либо жестко заданному на этапе проектирования алгоритму, она совершенствуется в процессе анализа имеющихся данных. Этот процесс и называется обучением нейронной сети. Математически суть процесса обучения заключается в корректировке значений весов синапсов (связей между имеющимися нейронами). Изначально значения весов задаются случайно, затем производится обучение, результатом которого будут новые значения синаптических весов. Это все мы максимально подробно разберем как раз в этой статье.
На своем сайте я всегда придерживаюсь концепции, при которой теоретические выкладки по максимуму сопровождаются практическими примерами для максимальной наглядности. Так мы поступим и сейчас 👍
Итак, суть заключается в следующем. Пусть у нас есть простейшая нейронная сеть, которую мы хотим обучить (продолжаем рассматривать сети прямого распространения):

То есть на входы нейронов I1 и I2 мы подаем какие-либо числа, а на выходе сети получаем соответственно новое значение. При этом нам необходима некая выборка данных, включающая в себя значения входов и соответствующее им, правильное, значение на выходе:
| bold{I_1} | bold{I_2} | bold{O_{net}} |
|---|---|---|
| x_{11} | x_{12} | y_{1} |
| x_{21} | x_{22} | y_{2} |
| x_{31} | x_{32} | y_{3} |
| … | … | … |
| x_{N1} | x_{N2} | y_{N} |
Допустим, сеть выполняет суммирование значений на входе, тогда данный набор данных может быть таким:
| bold{I_1} | bold{I_2} | bold{O_{net}} |
|---|---|---|
| 1 | 4 | 5 |
| 2 | 7 | 9 |
| 3 | 5 | 8 |
| … | … | … |
| 1000 | 1500 | 2500 |
Эти значения и используются для обучения сети. Как именно — рассмотрим чуть ниже, пока сконцентрируемся на идее процесса в целом. Для того, чтобы иметь возможность тестировать работу сети в процессе обучения, исходную выборку данных делят на две части — обучающую и тестовую. Пусть имеется 1000 образцов, тогда можно 900 использовать для обучения, а оставшиеся 100 — для тестирования. Эти величины взяты исключительно ради наглядности и демонстрации логики выполнения операций, на практике все зависит от задачи, размер обучающей выборки может спокойно достигать и сотен тысяч образцов.
Итак, итог имеем следующий — обучающая выборка прогоняется через сеть, в результате чего происходит настройка значений синаптических весов. Один полный проход по всей выборке называется эпохой. И опять же, обучение нейронной сети — это процесс, требующий многократных экспериментов, анализа результатов и творческого подхода. Все перечисленные параметры (размер выборки, количество эпох обучения) могут иметь абсолютно разные значения для разных задач и сетей. Четкого правила тут просто нет, в этом и кроется дополнительный шарм и изящность )
Возвращаемся к разбору, и в результате прохода обучающей выборки через сеть мы получаем сеть с новыми значениями весов синапсов.
Далее мы через эту, уже обученную в той или иной степени, сеть прогоняем тестовую выборку, которая не участвовала в обучении. При этом сеть выдает нам выходные значения для каждого образца, которые мы сравниваем с теми верными значениями, которые имеем.
Анализируем нашу гипотетическую выборку:

Таким образом, для тестирования подаем на вход сети значения x_{(M+1)1}, x_{(M+1)2} и проверяем, чему равен выход, ожидаем очевидно значение y_{(M+1)}. Аналогично поступаем и для оставшихся тестовых образцов. После чего мы можем сделать вывод, успешно или нет работает сеть. Например, сеть дает правильный ответ для 90% тестовых данных, дальше уже встает вопрос — устраивает ли нас данная точность или процесс обучения необходимо повторить, либо провести заново, изменив какие-либо параметры сети.
В этом и заключается суть обучения нейронных сетей, теперь перейдем к деталям и конкретным действиям, которые необходимо осуществить для выполнения данного процесса. Двигаться снова будем поэтапно, чтобы сформировать максимально четкую и полную картину. Поэтому начнем с понятия градиентного спуска, который используется при обучении по методу обратного распространения ошибки. Обо всем этом далее…
Обучение нейронных сетей. Градиентный спуск.
Рассмотрев идею процесса обучения в целом, на данном этапе мы можем однозначно сформулировать текущую цель — необходимо определить математический алгоритм, который позволит рассчитать значения весовых коэффициентов таким образом, чтобы ошибка сети была минимальна. То есть грубо говоря нам необходима конкретная формула для вычисления:
Здесь Delta w_{ij} — величина, на которую необходимо изменить вес синапса, связывающего нейроны i и j нашей сети. Соответственно, зная это, необходимо на каждом этапе обучения производить корректировку весов связей между всеми элементами нейронной сети. Задача ясна, переходим к делу.
Пусть функция ошибки от веса имеет следующий вид:
Для удобства рассмотрим зависимость функции ошибки от одного конкретного веса:

В начальный момент мы находимся в некоторой точке кривой, а для минимизации ошибки попасть мы хотим в точку глобального минимума функции:
Нанесем на график вектора градиентов в разных точках. Длина векторов численно равна скорости роста функции в данной точке, что в свою очередь соответствует значению производной функции по данной точке. Исходя из этого, делаем вывод, что длина вектора градиента определяется крутизной функции в данной точке:
Вывод прост — величина градиента будет уменьшаться по мере приближения к минимуму функции. Это важный вывод, к которому мы еще вернемся. А тем временем разберемся с направлением вектора, для чего рассмотрим еще несколько возможных точек:
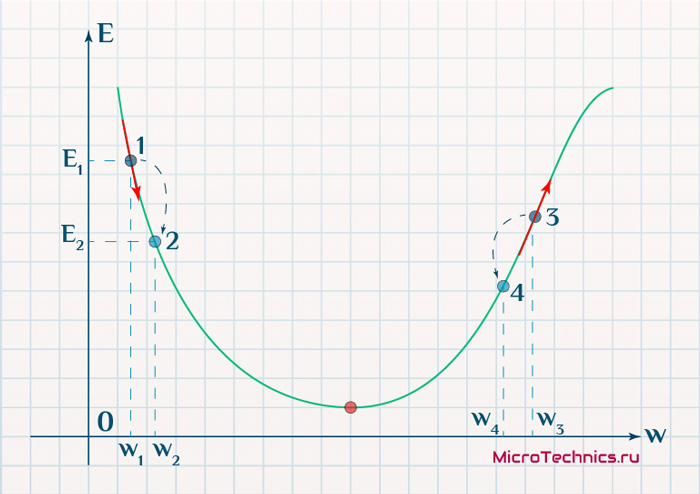
Находясь в точке 1, целью является перейти в точку 2, поскольку в ней значение ошибки меньше (E_2 < E_1), а глобальная задача по-прежнему заключается в ее минимизации. Для этого необходимо изменить величину w на некое значение Delta w (Delta w = w_2 — w_1 > 0). При всем при этом в точке 1 градиент отрицательный. Фиксируем данные факты и переходим к точке 3, предположим, что мы находимся именно в ней.
Тогда для уменьшения ошибки наш путь лежит в точку 4, а необходимое изменение значения: Delta w = w_4 — w_3 < 0. Градиент же в точке 3 положителен. Этот факт также фиксируем.
А теперь соберем воедино эту информацию в виде следующей иллюстрации:
| Переход | bold{Delta w} | Знак bold{Delta w} | Градиент |
|---|---|---|---|
| 1 rArr 2 | w_2 — w_1 | + | — |
| 3 rArr 4 | w_4 — w_3 | — | + |
Вывод напрашивается сам собой — величина, на которую необходимо изменить значение w, в любой точке противоположна по знаку градиенту. И, таким образом, представим эту самую величину в виде:
Delta w = -alpha cdot frac{dE}{dw}
Имеем в наличии:
- Delta w — величина, на которую необходимо изменить значение w.
- frac{dE}{dw} — градиент в этой точке.
- alpha — скорость обучения.
Собственно, логика метода градиентного спуска и заключается в данном математическом выражении, а именно в том, что для минимизации ошибки необходимо изменять w в направлении противоположном градиенту. В контексте нейронных сетей имеем искомый закон для корректировки весов синаптических связей (для синапса между нейронами i и j):
Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}}
Более того, вспомним о важном свойстве, которое мы отдельно пометили. И заключается оно в том, что величина градиента будет уменьшаться по мере приближения к минимуму функции. Что это нам дает? А то, что в том случае, если наша текущая дислокация далека от места назначения, то величина, корректирующая вес связи, будет больше. А это обеспечит скорейшее приближение к цели. При приближении к целевому пункту, величина frac{dE}{dw_{ij}} будет уменьшаться, что поможет нам точнее попасть в нужную точку, а кроме того, не позволит нам ее проскочить. Визуализируем вышеописанное:
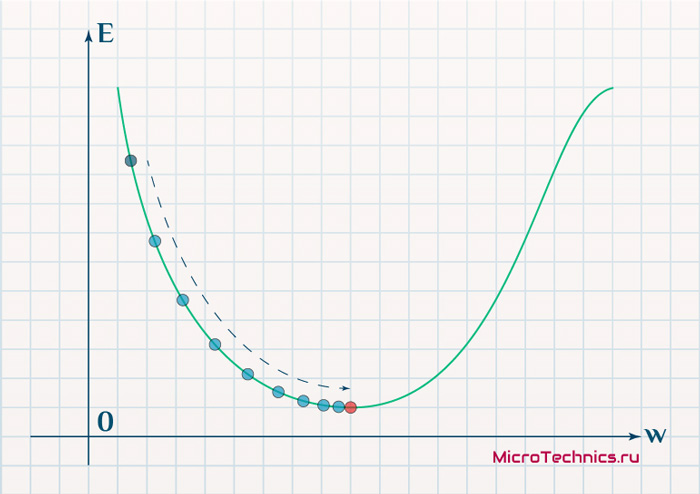
Скорость же обучения несет в себе следующий смысл. Она определяет величину каждого шага при поиске минимума ошибки. Слишком большое значение приводит к тому, что точка может «перепрыгнуть» через нужное значение и оказаться по другую сторону от цели:
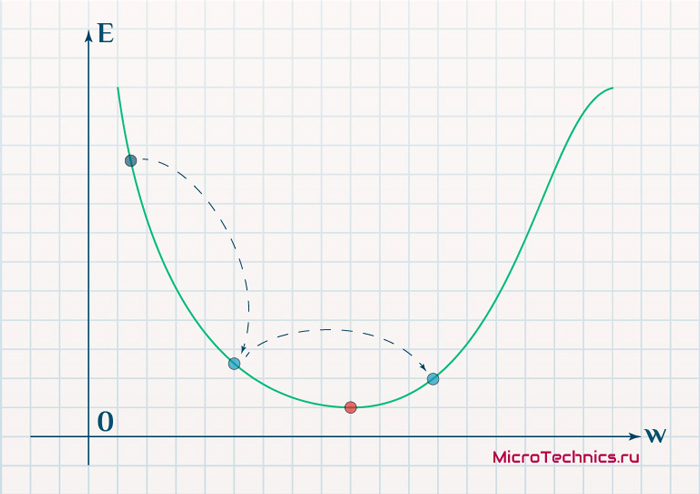
Если же величина будет мала, то это приведет к тому, что спуск будет осуществляться очень медленно, что также является нежелательным эффектом. Поэтому скорость обучения, как и многие другие параметры нейронной сети, является очень важной величиной, для которой нет единственно верного значения. Все снова зависит от конкретного случая и оптимальная величина определяется исключительно исходя из текущих условий.
И даже на этом еще не все, здесь присутствует один важный нюанс, который в большинстве статей опускается, либо вовсе не упоминается. Реальная зависимость может иметь совсем другой вид:
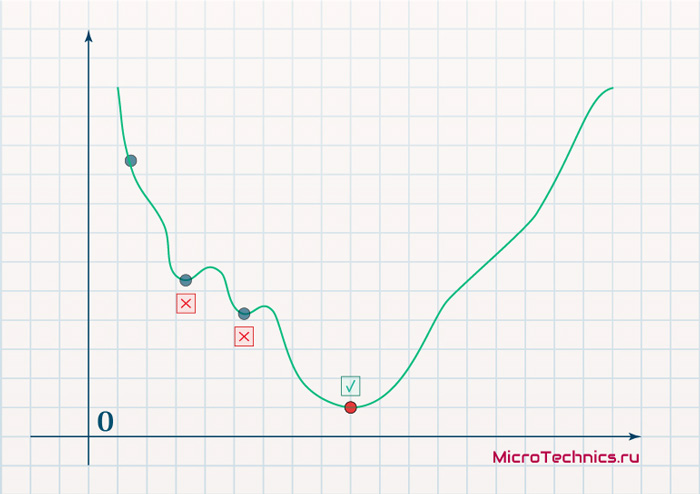
Из чего вытекает потенциальная возможность попадания в локальный минимум, вместо глобального, что является большой проблемой. Для предотвращения данного эффекта вводится понятие момента обучения и формула принимает следующий вид:
Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t - 1}
То есть добавляется второе слагаемое, которое представляет из себя произведение момента на величину корректировки веса на предыдущем шаге.
Итого, резюмируем продвижение к цели:
- Нашей задачей было найти закон, по которому необходимо изменять величину весов связей между нейронами.
- Наш результат — Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t — 1} — именно то, что и требовалось 👍
И опять же, полученный результат логичным образом перенаправляет нас на следующий этап, ставя вопросы — что из себя представляет функция ошибки, и как определить ее градиент.
Обучение нейронных сетей. Функция ошибки.
Начнем с того, что определимся с тем, что у нас в наличии, для этого вернемся к конкретной нейронной сети. Пусть вид ее таков:
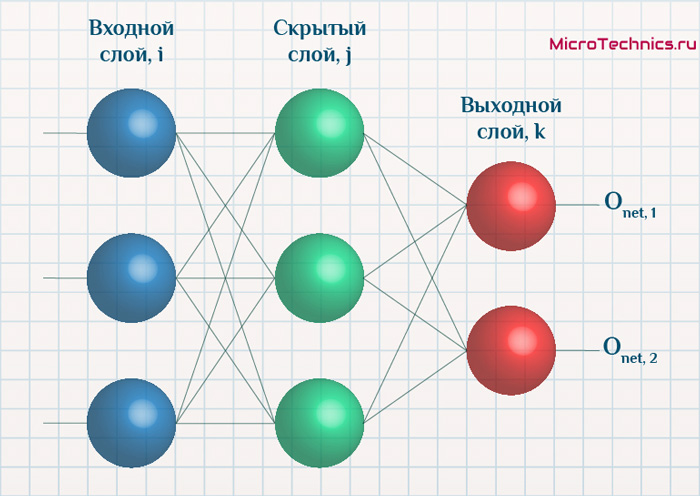
Интересует нас, в первую очередь, часть, относящаяся к нейронам выходного слоя. Подав на вход определенные значения, получаем значения на выходе сети: O_{net, 1} и O_{net, 2}. Кроме того, поскольку мы ведем речь о процессе обучения нейронной сети, то нам известны целевые значения: O_{correct, 1} и O_{correct, 2}. И именно этот набор данных на этом этапе является для нас исходным:
- Известно: O_{net, 1}, O_{net, 2}, O_{correct, 1} и O_{correct, 2}.
- Необходимо определить величины Delta w_{ij} для корректировки весов, для этого нужно вычислить градиенты (frac{dE}{dw_{ij}}) для каждого из синапсов.
Полдела сделано — задача четко сформулирована, начинаем деятельность по поиску решения.
В плане того, как определять ошибку, первым и самым очевидным вариантом кажется простая алгебраическая разность. Для каждого из выходных нейронов:
E_k = O_{correct, k} - O_{net, k}
Дополним пример числовыми значениями:
| Нейрон | bold{O_{net}} | bold{O_{correct}} | bold{E} |
|---|---|---|---|
| 1 | 0.9 | 0.5 | -0.4 |
| 2 | 0.2 | 0.6 | 0.4 |
Недостатком данного варианта является то, что в том случае, если мы попытаемся просуммировать ошибки нейронов, то получим:
E_{sum} = e_1 + e_2 = -0.4 + 0.4 = 0
Что не соответствует действительности (нулевая ошибка, говорит об идеальной работе нейронной сети, по факту оба нейрона дали неверный результат). Так что вариант с разностью откидываем за несостоятельностью.
Вторым, традиционно упоминаемым, методом вычисления ошибки является использование модуля разности:
E_k = | O_{correct, k} - O_{net, k} |
Тут в действие вступает уже проблема иного рода:
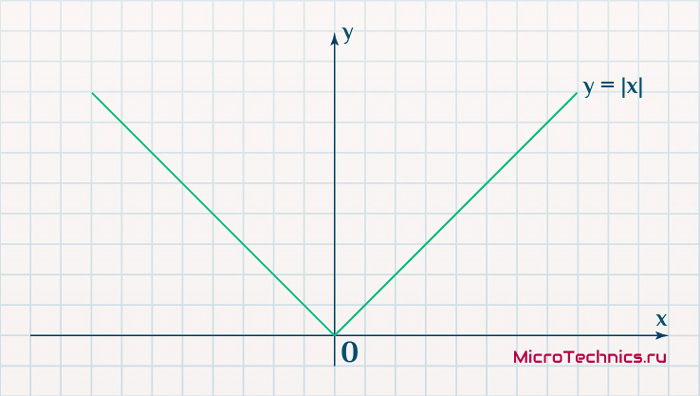
Функция, бесспорно, симпатична, но при приближении к минимуму ее градиент является постоянной величиной, скачкообразно меняясь при переходе через точку минимума. Это нас также не устраивает, поскольку, как мы обсуждали, концепция заключалась в том числе в том, чтобы по мере приближения к минимуму значение градиента уменьшалось.
В итоге хороший результат дает зависимость (для выходного нейрона под номером k):
E_k = (O_{correct, k} - O_{net, k})^2
Функция по многим своим свойствам идеально удовлетворяет нуждам обучения нейронной сети, так что выбор сделан, остановимся на ней. Хотя, как и во многих аспектах, качающихся нейронных сетей, данное решение не является единственно и неоспоримо верным. В каких-то случаях лучше себя могут проявить другие зависимости, возможно, что какой-то вариант даст большую точность, но неоправданно высокие затраты производительности при обучении. В общем, непаханное поле для экспериментов и исследований, это и привлекательно.
Краткий вывод промежуточного шага, на который мы вышли:
- Имеющееся: frac{dE}{dw_{jk}} = frac{d}{d w_{jk}}(O_{correct, k} — O_{net, k})^2.
- Искомое по-прежнему: Delta w_{jk}.
Несложные диффернциально-математические изыскания выводят на следующий результат:
frac{dE}{d w_{jk}} = -(O_{correct, k} - O_{net, k}) cdot f{Large{prime}}(sum_{j}w_{jk}O_j) cdot O_j
Здесь эти самые изыскания я все-таки решил не вставлять, дабы не перегружать статью, которая и так выходит объемной. Но в случае необходимости и интереса, отпишите в комментарии, я добавлю вычисления и закину их под спойлер, как вариант.
Освежим в памяти структуру сети:
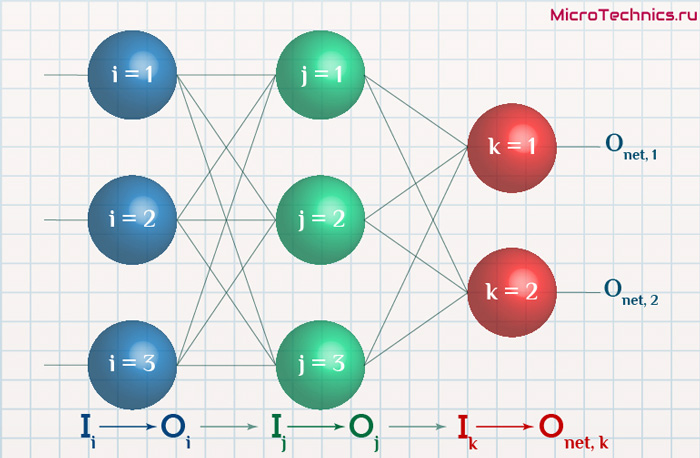
Формулу можно упростить, сгруппировав отдельные ее части:
- (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(sum_{j}w_{jk}O_j) — ошибка нейрона k.
- O_j — тут все понятно, выходной сигнал нейрона j.
f{Large{prime}}(sum_{j}w_{jk}O_j) — значение производной функции активации. Причем, обратите внимание, что sum_{j}w_{jk}O_j — это не что иное, как сигнал на входе нейрона k (I_{k}). Тогда для расчета ошибки выходного нейрона: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k).
Итог: frac{dE}{d w_{jk}} = -delta_k cdot O_j.
Одной из причин популярности сигмоидальной функции активности является то, что ее производная очень просто выражается через саму функцию:
f{'}(x) = f(x)medspace (1medspace-medspace f(x))
Данные алгебраические вычисления справедливы для корректировки весов между скрытым и выходным слоем, поскольку для расчета ошибки мы используем просто разность между целевым и полученным результатом, умноженную на производную.
Для других слоев будут незначительные изменения, касающиеся исключительно первого множителя в формуле:
frac{dE}{d w_{ij}} = -delta_j cdot O_i
Который примет следующий вид:
delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
То есть ошибка для элемента слоя j получается путем взвешенного суммирования ошибок, «приходящих» к нему от нейронов следующего слоя и умножения на производную функции активации. В результате:
frac{dE}{d w_{ij}} = -(sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j) cdot O_i
Снова подводим промежуточный итог, чтобы иметь максимально полную и структурированную картину происходящего. Вот результаты, полученные нами на двух этапах, которые мы успешно миновали:
- Ошибка:
- выходной слой: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k)
- скрытые слои: delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
- Градиент: frac{dE}{d w_{ij}} = -delta_j cdot O_i
- Корректировка весовых коэффициентов: Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t — 1}
Преобразуем последнюю формулу:
Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t - 1}
Из этого мы делаем вывод, что на данный момент у нас есть все, что необходимо для того, чтобы произвести обучение нейронной сети. И героем следующего подраздела будет алгоритм обратного распространения ошибки.
Метод обратного распространения ошибки.
Данный метод является одним из наиболее распространенных и популярных, чем и продиктован его выбор для анализа и разбора. Алгоритм обратного распространения ошибки относится к методам обучение с учителем, что на деле означает необходимость наличия целевых значений в обучающих сетах.
Суть же метода подразумевает наличие двух этапов:
- Прямой проход — входные сигналы двигаются в прямом направлении, в результате чего мы получаем выходной сигнал, из которого в дальнейшем рассчитываем значение ошибки.
- Обратный проход — обратное распространение ошибки — величина ошибки двигается в обратном направлении, в результате происходит корректировка весовых коэффициентов связей сети.
Начальные значения весов (перед обучением) задаются случайными, есть ряд методик для выбора этих значений, я опишу в отдельном материале максимально подробно. Пока вот можно полистать — ссылка.
Вернемся к конкретному примеру для явной демонстрации этих принципов:
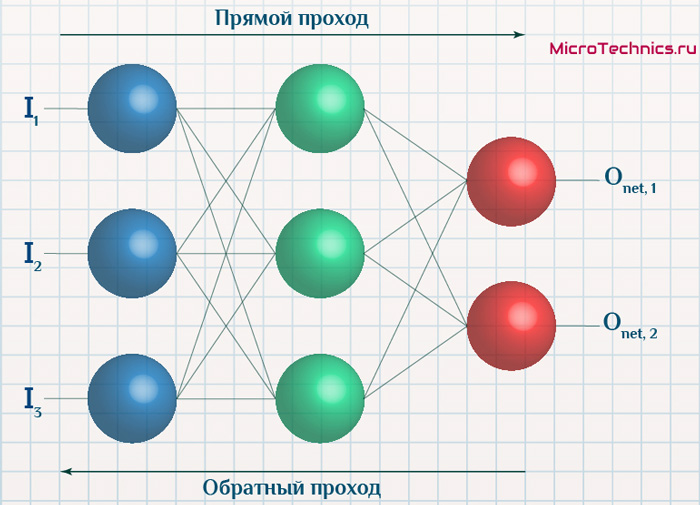
Итак, имеется нейронная сеть, также имеется набор данных обучающей выборки. Как уже обсудили в начале статьи — обучающая выборка представляет из себя набор образцов (сетов), каждый из которых состоит из значений входных сигналов и соответствующих им «правильных» значений выходных величин.
Процесс обучения нейронной сети для алгоритма обратного распространения ошибки будет таким:
- Прямой проход. Подаем на вход значения I_1, I_2, I_3 из обучающей выборки. В результате работы сети получаем выходные значения O_{net, 1}, O_{net, 2}. Этому целиком и полностью был посвящен предыдущий манускрипт.
- Рассчитываем величины ошибок для всех слоев:
- для выходного: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k)
- для скрытых: delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
- Далее используем полученные значения для расчета Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t — 1}
- И финишируем, рассчитывая новые значения весов: w_{ij medspace new} = w_{ij} + Delta w_{ij}
- На этом один цикл обучения закончен, данные шаги 1 — 4 повторяются для других образцов из обучающей выборки.
Обратный проход завершен, а вместе с ним и одна итерация процесса обучения нейронной сети по данному методу. Собственно, обучение в целом заключается в многократном повторении этих шагов для разных образцов из обучающей выборки. Логику мы полностью разобрали, при повторном проведении операций она остается в точности такой же.
Таким образом, максимально подробно концентрируясь именно на сути и логике процессов, мы в деталях разобрали метод обратного распространения ошибки. Поэтому переходим к завершающей части статьи, в которой разберем практический пример, произведя полностью все вычисления для конкретных числовых величин. Все в рамках продвигаемой мной концепции, что любая теоретическая информация на порядок лучше может быть осознана при применении ее на практике.
Пример расчетов для метода обратного распространения ошибки.
Возьмем нейронную сеть и зададим начальные значения весов:
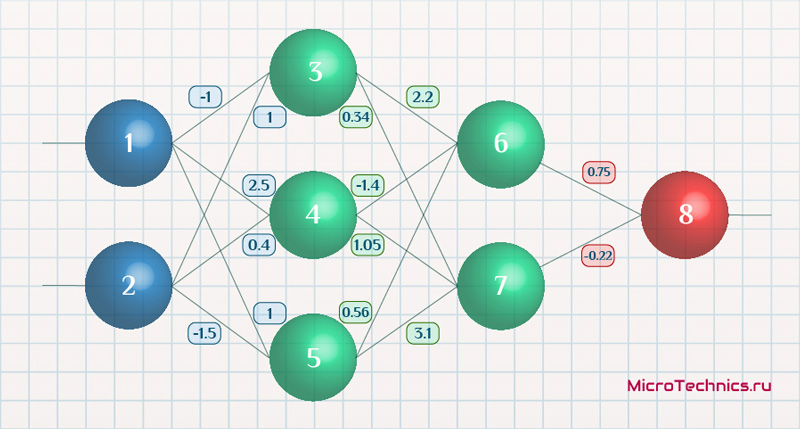
Здесь я задал значения не в соответствии с существующими на сегодняшний день методами, а просто случайным образом для наглядности примера.
В качестве функции активации используем сигмоиду:
f(x) = frac{1}{1 + e^{-x}}
И ее производная:
f{Large{prime}}(x) = f(x)medspace (1medspace-medspace f(x))
Берем один образец из обучающей выборки, пусть будут такие значения:
- Входные: I_1 = 0.6, I_1 = 0.7.
- Выходное: O_{correct} = 0.9.
Скорость обучения alpha пусть будет равна 0.3, момент — gamma = 0.1. Все готово, теперь проведем полный цикл для метода обратного распространения ошибки, то есть прямой проход и обратный.
Прямой проход.
Начинаем с выходных значений нейронов 1 и 2, поскольку они являются входными, то:
O_1 = I_1 = 0.6 \ O_2 = I_2 = 0.7
Значения на входе нейронов 3, 4 и 5:
I_3 = O_1 cdot w_{13} + O_2 cdot w_{23} = 0.6 cdot (-1medspace) + 0.7 cdot 1 = 0.1 \
I_4 = 0.6 cdot 2.5 + 0.7 cdot 0.4 = 1.78 \
I_5 = 0.6 cdot 1 + 0.7 cdot (-1.5medspace) = -0.45
На выходе этих же нейронов первого скрытого слоя:
O_3 = f(I3medspace) = 0.52 \ O_4 = 0.86\ O_5 = 0.39
Продолжаем аналогично для следующего скрытого слоя:
I_6 = O_3 cdot w_{36} + O_4 cdot w_{46} + O_5 cdot w_{56} = 0.52 cdot 2.2 + 0.86 cdot (-1.4medspace) + 0.39 cdot 0.56 = 0.158 \
I_7 = 0.52 cdot 0.34 + 0.86 cdot 1.05 + 0.39 cdot 3.1 = 2.288 \
O_6 = f(I_6) = 0.54 \
O_7 = 0.908
Добрались до выходного нейрона:
I_8 = O_6 cdot w_{68} + O_7 cdot w_{78} = 0.54 cdot 0.75 + 0.908 cdot (-0.22medspace) = 0.205 \
O_8 = O_{net} = f(I_8) = 0.551
Получили значение на выходе сети, кроме того, у нас есть целевое значение O_{correct} = 0.9. То есть все, что необходимо для обратного прохода, имеется.
Обратный проход.
Как мы и обсуждали, первым этапом будет вычисление ошибок всех нейронов, действуем:
delta_8 = (O_{correct} - O_{net}) cdot f{Large{prime}}(I_8) = (O_{correct} - O_{net}) cdot f(I_8) cdot (1-f(I_8)) = (0.9 - 0.551medspace) cdot 0.551 cdot (1-0.551medspace) = 0.0863 \
delta_7 = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_7) = (delta_8 cdot w_{78}) cdot f{Large{prime}}(I_7) = 0.0863 cdot (-0.22medspace) cdot 0.908 cdot (1 - 0.908medspace) = -0.0016 \
delta_6 = 0.086 cdot 0.75 cdot 0.54 cdot (1 - 0.54medspace) = 0.016 \
delta_5 = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_5) = (delta_7 cdot w_{57} + delta_6 cdot w_{56}) cdot f{Large{prime}}(I_7) = (-0.0016 cdot 3.1 + 0.016 cdot 0.56) cdot 0.39 cdot (1 - 0.39medspace) = 0.001 \
delta_4 = (-0.0016 cdot 1.05 + 0.016 cdot (-1.4)) cdot 0.86 cdot (1 - 0.86medspace) = -0.003 \
delta_3 = (-0.0016 cdot 0.34 + 0.016 cdot 2.2) cdot 0.52 cdot (1 - 0.52medspace) = -0.0087
С расчетом ошибок закончили, следующий этап — расчет корректировочных величин для весов всех связей. Для этого мы вывели формулу:
Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t - 1}
Как вы помните, Delta w_{ij}^{t — 1} — это величина поправки для данного веса на предыдущей итерации. Но поскольку у нас это первый проход, то данное значение будет нулевым, соответственно, в данном случае второе слагаемое отпадает. Но забывать о нем нельзя. Продолжаем калькулировать:
Delta w_{78} = alpha cdot delta_8 cdot O_7 = 0.3 cdot 0.0863 cdot 0.908 = 0.0235 \
Delta w_{68} = 0.3 cdot 0.0863 cdot 0.54= 0.014 \
Delta w_{57} = alpha cdot delta_7 cdot O_5 = 0.3 cdot (−0.0016medspace) cdot 0.39= -0.00019 \
Delta w_{47} = 0.3 cdot (−0.0016medspace) cdot 0.86= -0.0004 \
Delta w_{37} = 0.3 cdot (−0.0016medspace) cdot 0.52= -0.00025 \
Delta w_{56} = alpha cdot delta_6 cdot O_5 = 0.3 cdot 0.016 cdot 0.39= 0.0019 \
Delta w_{46} = 0.3 cdot 0.016 cdot 0.86= 0.0041 \
Delta w_{36} = 0.3 cdot 0.016 cdot 0.52= 0.0025 \
Delta w_{25} = alpha cdot delta_5 cdot O_2 = 0.3 cdot 0.001 cdot 0.7= 0.00021 \
Delta w_{15} = 0.3 cdot 0.001 cdot 0.6= 0.00018 \
Delta w_{24} = alpha cdot delta_4 cdot O_2 = 0.3 cdot (-0.003medspace) cdot 0.7= -0.00063 \
Delta w_{14} = 0.3 cdot (-0.003medspace) cdot 0.6= -0.00054 \
Delta w_{23} = alpha cdot delta_3 cdot O_2 = 0.3 cdot (−0.0087medspace) cdot 0.7= -0.00183 \
Delta w_{13} = 0.3 cdot (−0.0087medspace) cdot 0.6= -0.00157
И самый что ни на есть заключительный этап — непосредственно изменение значений весовых коэффициентов:
w_{78 medspace new} = w_{78} + Delta w_{78} = -0.22 + 0.0235 = -0.1965 \
w_{68 medspace new} = 0.75+ 0.014 = 0.764 \
w_{57 medspace new} = 3.1 + (−0.00019medspace) = 3.0998\
w_{47 medspace new} = 1.05 + (−0.0004medspace) = 1.0496\
w_{37 medspace new} = 0.34 + (−0.00025medspace) = 0.3398\
w_{56 medspace new} = 0.56 + 0.0019 = 0.5619 \
w_{46 medspace new} = -1.4 + 0.0041 = -1.3959 \
w_{36 medspace new} = 2.2 + 0.0025 = 2.2025 \
w_{25 medspace new} = -1.5 + 0.00021 = -1.4998 \
w_{15 medspace new} = 1 + 0.00018 = 1.00018 \
w_{24 medspace new} = 0.4 + (−0.00063medspace) = 0.39937 \
w_{14 medspace new} = 2.5 + (−0.00054medspace) = 2.49946 \
w_{23 medspace new} = 1 + (−0.00183medspace) = 0.99817 \
w_{13 medspace new} = -1 + (−0.00157medspace) = -1.00157\
И на этом данную масштабную статью завершаем, конечно же, не завершая на этом деятельность по использованию нейронных сетей. Так что всем спасибо за прочтение, любые вопросы пишите в комментариях и на форуме, ну и обязательно следите за обновлениями и новыми материалами, до встречи!
Кондрашов Александр Владимирович1, Горденко Дмитрий Владимирович1, Павлюк Дмитрий Николаевич1
1Ставропольский государственный аграрный университет
Аннотация
В статье представлен подход коррекции ошибок в модулярном коде с применением нейронной сети Хопфилда.
Kondrashov Alexander1, Gordenko Dmitry1, Pavljuk Dmitry1
1Stavropol State Agrarian University
Abstract
The paper presents an approach of error correction in the modular code using the Hopfield neural network.
Библиографическая ссылка на статью:
Кондрашов А.В., Горденко Д.В., Павлюк Д.Н. Коррекция ошибок в модулярном коде // Исследования в области естественных наук. 2015. № 4 [Электронный ресурс]. URL: https://science.snauka.ru/2015/04/9538 (дата обращения: 30.11.2022).
При разработке вычислительных средств, функционирующих в системе остаточных классов (СОК) возникает важная задача обеспечения достоверности всего потока информации. Обеспечение достоверности всего потока информации прямо и непосредственно связано с увеличением производительности нейрокомпьютера (НК), функционирующего в СОК.
В настоящее время при разработке нейронных сетей (НС), система остаточных классов привлекает все более пристальное внимание из – за ее способности поддерживать высокоскоростную арифметику при параллельной обработки данных.
Система остаточных классов представляет собой такую систему, в которой целое положительное число представляется в виде набора остатков по выбранным основаниям
А = (a1, a2,…, an), an º А (mod pn), n = 1, 2,…, k, (1)
где pn – основания системы остаточных классов.
Для каждого специального кода, обладающего способностью к обнаружению и коррекции ошибки, характерно наличие двух групп цифр – информационной и контрольной. В информационную группу входят цифры, составляющие числовое значение закодированной величины, а в контрольную – цифры, дополнительно вводимые для целей обнаружения и коррекции возможных искажений.
Корректирующие свойства кодов в остатках, как и любого другого кода, проявляется при введении избыточности. Пусть число А представлено остатками a1, a2,…, an по основаниям p1, p2,…, pn. Диапазон представления чисел по выбранным основаниям равен произведению этих оснований.
R = 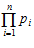 , (2)
, (2)
где R – рабочий диапазон системы.
При введении избыточного основания pn+1, будем представлять числа и производить операции над числами, лежащими не в диапазоне [0, R), а в более широком диапазоне [0, P)
P = R× pn+1, (3)
где P– полный диапазон системы.
Таким образом, для того чтобы обнаружить наличие или отсутствие ошибки в числе А, надо сопоставить его с диапазоном R. При этом если оказалось А³ R, значит, имела место ошибка, по крайней мере, в одной цифре. Если же А < R, то либо ошибки нет, либо она носит более сложный характер.
С повышением интереса к машинной арифметики в СОК возникла возможность построения кодов на основе нейронной сети.
Нейронная сеть является совокупностью элементов (нейронов), соединенных некоторым образом так, чтобы между ними обеспечивалось взаимодействие и представляет собой высокопараллельную динамическую систему. Проблема исследования надежности нейронных сетей находится еще в самом начале своего развития. Ее решение окажет значительное воздействие на реализацию нейрокомпьютеров построенных по новым технологиям. Структура нейронных ЭВМ представляет собой массив процессоров. Это предъявляет особые требования к процедуре диагностики по крайней мере той части нейронных ЭВМ, которая представляет сеть нейронов.
В работе предлагается использование для коррекции ошибок в модулярном коде НС Хопфилда.
Модель Хопфилда занимает особое место в ряду нейросетевых моделей. В ней впервые удалось установить связь между нелинейными динамическими системами и нейронными сетями. Образы памяти сети соответствуют устойчивым предельным точкам динамической системы.
Как уже известно, персептрон относится к классу сетей с направленным потоком распространения информации и не содержит обратных связей. На этапе функционирования каждый нейрон выполняет свою функцию – передачу возбуждения другим нейронам – ровно один раз. Динамика состояний нейронов является безитерационной.
Несколько более сложной является динамика в сети Хопфилда. Нейронная сеть Хопфилда содержит обратные связи, по которым переданное возбуждение возвращается к нейронам, и они повторно выполняют свою функцию (рис.1). Характерная особенность такой системы состоит в том, что выходные сигналы нейронов являются одновременно входными сигналами сети, при этом возбуждающий вектор особо не выделяется. Нейродинамика в таких системах становится итерационной. Это свойство существенно расширяет множество типов нейросетевых архитектур, но одновременно приводит к появлению новых проблем. Обратные связи могут приводить к возникновению неустойчивостей. В нейронных сетях неустойчивость проявляется в блуждающей смене состояний нейронов, не приводящей к возникновению стационарных состояний.
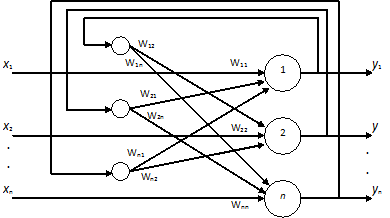
Рис.1. Обобщенная структура нейронной сети Хопфилда
В модели Хопфилда предполагается условие симметричности связей
Wij=Wji, (4)
с нулевыми диагональными элементами Wii=0. Это условие имеет весьма отдаленное отношение к известным свойствам биологических сетей, в которых, наоборот, если один нейрон передает возбуждение другому, то тот, в большинстве случаев, непосредственно не связан с первым. Однако именно симметричность связей существенно влияет на устойчивость динамики.
Изменение состояния каждого нейрона в модели Хопфилда происходит по известному правилу для формальных нейронов. Поступающие на его входы сигналы xi в момент t взвешиваются с весами матрицы связей Wij и суммируются, определяя полный уровень силы входного сигнала:
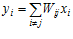
Далее в момент t+1 нейрон изменяет состояние своего возбуждения в зависимости от уровня сигнала y и индивидуального порога каждого нейрона.
Изменение состояний возбуждения всех нейронов может происходить одновременно, в этом случае говорят о параллельной динамике.
Совокупность значений возбуждения всех нейронов в некоторый момент времени образует вектор состояния сети. Вектор состояния можно представить в пространстве состояний нейросети. Это пространство для сети с двумя уровнями возбуждения каждого нейрона, очевидно, представляет собой множество вершин гиперкуба размерности, равной числу нейронов N. Возможные наборы значений координат вершин гиперкуба (см. Рис.2) и определяют возможные значения вектора состояния.
Фаза обучения сети Хопфилда ориентирована на формирование таких значений весов, при которых в режиме функционирования задание начального состояния нейронов, близкого к одному из обучающих векторов х, при соблюдении зависимости.
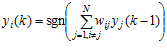 , (5)
, (5)
где N обозначает количество нейронов, N = n,
приводит к стабильному состоянию, в котором реакция нейронов y = x остается неизменной в любой момент времени. При правильно подобранных весах каждая поданная на вход выборка х генерируется на выходе саму себя, мгновенно приводя к искомому состоянию (зависимость (5)).
По завершении подбора весов сети их значения принимают конечное состояние, и сеть может использоваться в режиме распознавания
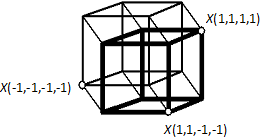
Рис. 2. Проекция 4-х мерного гиперкуба на плоскость
Ассоциативный характер памяти сети Хопфилда качественно отличает ее от обычной, адресной, компьютерной памяти. При использовании ассоциативной памяти доступ к информации производится непосредственно по ее содержанию, т.е. по частично известным искаженным фрагментам. Потеря части информации или ее информационное зашумление не приводит к катастрофическому ограничению доступа, если оставшейся информации достаточно для извлечения идеального образа.
Основываясь на свойствах нейронной сети Хопфилда, предлагается ее использование для коррекции ошибки в модулярном коде. Причем, за счет использования НС Хопфилда мы отступаем от избыточности кода представленного в СОК вводимой для целей обнаружения и коррекции возможных искажений. НС Хопфилда выполняет контроль кода, а при возникновении ошибки на входе будет исправлять ее за счет извлечения идеального образа.
Нейронная сеть Хопфилда может быть, применима для исправления не только одиночной ошибки, но и при некоторых условиях также двойных и тройных ошибок, обеспечивает реальную возможность повышения информационной надежности НК. Это обусловлено специфическими способностями нейронной сети.
Библиографический список
- Горденко Д.В., Резеньков Д.Н., Яйлаханов С.В. Высоконадежные комплексы и средства связи на нейросетевых элементах: монография /. – М.: Илекса, 2010. – 184 с.
- Ткачук Р.В., Горденко Д.В., Павлюк Д.Н., Малофей А.О. Активная безопасность на основе криптографического мультинейропроцессора обработки данных. // Известия высших учебных заведений. Северо-Кавказский регион. – Новочеркасск: РГУ, 2007. С.17-18.
- Калмыков И.А., Резеньков Д.Н., Горденко Д.В., Саркисов А.Б. Методы и алгоритмы реконфигурации непозиционных вычислительных структур для обеспечения отказоустойчивости спецпроцессов: монография /. – Ставрополь.: Фабула, 2014. – 180 с.
- Горденко Д.В., Токарева Г.В. Нейронная сеть для преобразования чисел, представленных в позиционном коде в систему остаточных классов. // Информационные системы и технологии как фактор развития экономики региона. 2013. С. 60-63.
- Горденко Д.В., Горденко Н.В. Неисправности в запоминающих устройствах и в нейронных сетях. // Культура и общество: история и современность. материалы II Всероссийской (с международным участием) научно-практической конференции. под редакцией: Колосовой О.Ю., Гударенко Р.Ф., Ряснянской Н.А., Красиковой Е.А.. 2013. С. 67-70.
- Горденко Д.В., Резеньков Д.Н. Сравнительный анализ метода контроля арифметических операций в системе остаточных классах. // Современные проблемы науки и образования. 2014. № 3. С. 148.
- Горденко Д.В. Перспективное развитие вычислительной техники на основе непозиционного нейрокомпьютера. // Исследования в области естественных наук. 2013. № 12 (24). С. 3.
- Горденко Д.В., Горденко Н.В. Локализация ошибок в устройствах цифровой обработки сигналов на основе алгебры полиномов.// Вестник СевКавГТИ. 2009. № 9. С. 56-61.
- Горденко Д.В., Трошков А.М., Кондрашов А.В., Токарева Г.В. Нейронная реализация локализации ошибок в модулярном коде на основе метода проекций. // Исследования в области естественных наук. 2013. № 10 (22). С. 2.
Все статьи автора «Горденко Дмитрий Владимирович»
Нейронные сети обучаются с помощью тех или иных модификаций градиентного спуска, а чтобы применять его, нужно уметь эффективно вычислять градиенты функции потерь по всем обучающим параметрам. Казалось бы, для какого-нибудь запутанного вычислительного графа это может быть очень сложной задачей, но на помощь спешит метод обратного распространения ошибки.
Открытие метода обратного распространения ошибки стало одним из наиболее значимых событий в области искусственного интеллекта. В актуальном виде он был предложен в 1986 году Дэвидом Э. Румельхартом, Джеффри Э. Хинтоном и Рональдом Дж. Вильямсом и независимо и одновременно красноярскими математиками С. И. Барцевым и В. А. Охониным. С тех пор для нахождения градиентов параметров нейронной сети используется метод вычисления производной сложной функции, и оценка градиентов параметров сети стала хоть сложной инженерной задачей, но уже не искусством. Несмотря на простоту используемого математического аппарата, появление этого метода привело к значительному скачку в развитии искусственных нейронных сетей.
Суть метода можно записать одной формулой, тривиально следующей из формулы производной сложной функции: если $f(x) = g_m(g_{m-1}(ldots (g_1(x)) ldots))$, то $frac{partial f}{partial x} = frac{partial g_m}{partial g_{m-1}}frac{partial g_{m-1}}{partial g_{m-2}}ldots frac{partial g_2}{partial g_1}frac{partial g_1}{partial x}$. Уже сейчас мы видим, что градиенты можно вычислять последовательно, в ходе одного обратного прохода, начиная с $frac{partial g_m}{partial g_{m-1}}$ и умножая каждый раз на частные производные предыдущего слоя.
Backpropagation в одномерном случае
В одномерном случае всё выглядит особенно просто. Пусть $w_0$ — переменная, по которой мы хотим продифференцировать, причём сложная функция имеет вид
$$f(w_0) = g_m(g_{m-1}(ldots g_1(w_0)ldots)),$$
где все $g_i$ скалярные. Тогда
$$f'(w_0) = g_m'(g_{m-1}(ldots g_1(w_0)ldots))cdot g’_{m-1}(g_{m-2}(ldots g_1(w_0)ldots))cdotldots cdot g’_1(w_0)$$
Суть этой формулы такова. Если мы уже совершили forward pass, то есть уже знаем
$$g_1(w_0), g_2(g_1(w_0)),ldots,g_{m-1}(ldots g_1(w_0)ldots),$$
то мы действуем следующим образом:
-
берём производную $g_m$ в точке $g_{m-1}(ldots g_1(w_0)ldots)$;
-
умножаем на производную $g_{m-1}$ в точке $g_{m-2}(ldots g_1(w_0)ldots)$;
-
и так далее, пока не дойдём до производной $g_1$ в точке $w_0$.
Проиллюстрируем это на картинке, расписав по шагам дифференцирование по весам $w_i$ функции потерь логистической регрессии на одном объекте (то есть для батча размера 1):

Собирая все множители вместе, получаем:
$$frac{partial f}{partial w_0} = (-y)cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}cdotfrac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$frac{partial f}{partial w_1} = x_1cdot(-y)cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}cdotfrac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$frac{partial f}{partial w_2} = x_2cdot(-y)cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}cdotfrac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
Таким образом, мы видим, что сперва совершается forward pass для вычисления всех промежуточных значений (и да, все промежуточные представления нужно будет хранить в памяти), а потом запускается backward pass, на котором в один проход вычисляются все градиенты.
Почему же нельзя просто пойти и начать везде вычислять производные?
В главе, посвящённой матричным дифференцированиям, мы поднимаем вопрос о том, что вычислять частные производные по отдельности — это зло, лучше пользоваться матричными вычислениями. Но есть и ещё одна причина: даже и с матричной производной в принципе не всегда хочется иметь дело. Рассмотрим простой пример. Допустим, что $X^r$ и $X^{r+1}$ — два последовательных промежуточных представления $Ntimes M$ и $Ntimes K$, связанных функцией $X^{r+1} = f^{r+1}(X^r)$. Предположим, что мы как-то посчитали производную $frac{partialmathcal{L}}{partial X^{r+1}_{ij}}$ функции потерь $mathcal{L}$, тогда
$$frac{partialmathcal{L}}{partial X^{r}_{st}} = sum_{i,j}frac{partial f^{r+1}_{ij}}{partial X^{r}_{st}}frac{partialmathcal{L}}{partial X^{r+1}_{ij}}$$
И мы видим, что, хотя оба градиента $frac{partialmathcal{L}}{partial X_{ij}^{r+1}}$ и $frac{partialmathcal{L}}{partial X_{st}^{r}}$ являются просто матрицами, в ходе вычислений возникает «четырёхмерный кубик» $frac{partial f_{ij}^{r+1}}{partial X_{st}^{r}}$, даже хранить который весьма болезненно: уж больно много памяти он требует ($N^2MK$ по сравнению с безобидными $NM + NK$, требуемыми для хранения градиентов). Поэтому хочется промежуточные производные $frac{partial f^{r+1}}{partial X^{r}}$ рассматривать не как вычисляемые объекты $frac{partial f_{ij}^{r+1}}{partial X_{st}^{r}}$, а как преобразования, которые превращают $frac{partialmathcal{L}}{partial X_{ij}^{r+1}}$ в $frac{partialmathcal{L}}{partial X_{st}^{r}}$. Целью следующих глав будет именно это: понять, как преобразуется градиент в ходе error backpropagation при переходе через тот или иной слой.
Вы спросите себя: надо ли мне сейчас пойти и прочитать главу учебника про матричное дифференцирование?
Встречный вопрос. Найдите производную функции по вектору $x$:
$$f(x) = x^TAx, Ain Mat_{n}{mathbb{R}}text{ — матрица размера }ntimes n$$
А как всё поменяется, если $A$ тоже зависит от $x$? Чему равен градиент функции, если $A$ является скаляром? Если вы готовы прямо сейчас взять ручку и бумагу и посчитать всё, то вам, вероятно, не надо читать про матричные дифференцирования. Но мы советуем всё-таки заглянуть в эту главу, если обозначения, которые мы будем дальше использовать, покажутся вам непонятными: единой нотации для матричных дифференцирований человечество пока, увы, не изобрело, и переводить с одной на другую не всегда легко.
Мы же сразу перейдём к интересующей нас вещи: к вычислению градиентов сложных функций.
Градиент сложной функции
Напомним, что формула производной сложной функции выглядит следующим образом:
$$left[D_{x_0} (color{#5002A7}{u} circ color{#4CB9C0}{v}) right](h) = color{#5002A7}{left[D_{v(x_0)} u right]} left( color{#4CB9C0}{left[D_{x_0} vright]} (h)right)$$
Теперь разберёмся с градиентами. Пусть $f(x) = g(h(x))$ – скалярная функция. Тогда
$$left[D_{x_0} f right] (x-x_0) = langlenabla_{x_0} f, x-x_0rangle.$$
С другой стороны,
$$left[D_{h(x_0)} g right] left(left[D_{x_0}h right] (x-x_0)right) = langlenabla_{h_{x_0}} g, left[D_{x_0} hright] (x-x_0)rangle = langleleft[D_{x_0} hright]^* nabla_{h(x_0)} g, x-x_0rangle.$$
То есть $color{#FFC100}{nabla_{x_0} f} = color{#348FEA}{left[D_{x_0} h right]}^* color{#FFC100}{nabla_{h(x_0)}}g$ — применение сопряжённого к $D_{x_0} h$ линейного отображения к вектору $nabla_{h(x_0)} g$.
Эта формула — сердце механизма обратного распространения ошибки. Она говорит следующее: если мы каким-то образом получили градиент функции потерь по переменным из некоторого промежуточного представления $X^k$ нейронной сети и при этом знаем, как преобразуется градиент при проходе через слой $f^k$ между $X^{k-1}$ и $X^k$ (то есть как выглядит сопряжённое к дифференциалу слоя между ними отображение), то мы сразу же находим градиент и по переменным из $X^{k-1}$:

Таким образом слой за слоем мы посчитаем градиенты по всем $X^i$ вплоть до самых первых слоёв.
Далее мы разберёмся, как именно преобразуются градиенты при переходе через некоторые распространённые слои.
Градиенты для типичных слоёв
Рассмотрим несколько важных примеров.
Примеры
-
$f(x) = u(v(x))$, где $x$ — вектор, а $v(x)$ – поэлементное применение $v$:
$$vbegin{pmatrix}
x_1
vdots
x_N
end{pmatrix}
= begin{pmatrix}
v(x_1)
vdots
v(x_N)
end{pmatrix}$$Тогда, как мы знаем,
$$left[D_{x_0} fright] (h) = langlenabla_{x_0} f, hrangle = left[nabla_{x_0} fright]^T h.$$
Следовательно,
$$begin{multline*}
left[D_{v(x_0)} uright] left( left[ D_{x_0} vright] (h)right) = left[nabla_{v(x_0)} uright]^T left(v'(x_0) odot hright) =\[0.1cm]
= sumlimits_i left[nabla_{v(x_0)} uright]_i v'(x_{0i})h_i
= langleleft[nabla_{v(x_0)} uright] odot v'(x_0), hrangle.
end{multline*},$$где $odot$ означает поэлементное перемножение. Окончательно получаем
$$color{#348FEA}{nabla_{x_0} f = left[nabla_{v(x_0)}uright] odot v'(x_0) = v'(x_0) odot left[nabla_{v(x_0)} uright]}$$
Отметим, что если $x$ и $h(x)$ — это просто векторы, то мы могли бы вычислять всё и по формуле $frac{partial f}{partial x_i} = sum_jbig(frac{partial z_j}{partial x_i}big)cdotbig(frac{partial h}{partial z_j}big)$. В этом случае матрица $big(frac{partial z_j}{partial x_i}big)$ была бы диагональной (так как $z_j$ зависит только от $x_j$: ведь $h$ берётся поэлементно), и матричное умножение приводило бы к тому же результату. Однако если $x$ и $h(x)$ — матрицы, то $big(frac{partial z_j}{partial x_i}big)$ представлялась бы уже «четырёхмерным кубиком», и работать с ним было бы ужасно неудобно.
-
$f(X) = g(XW)$, где $X$ и $W$ — матрицы. Как мы знаем,
$$left[D_{X_0} f right] (X-X_0) = text{tr}, left(left[nabla_{X_0} fright]^T (X-X_0)right).$$
Тогда
$$begin{multline*}
left[ D_{X_0W} g right] left(left[D_{X_0} left( ast Wright)right] (H)right) =
left[ D_{X_0W} g right] left(HWright)=\
= text{tr}, left( left[nabla_{X_0W} g right]^T cdot (H) W right) =\
=
text{tr} , left(W left[nabla_{X_0W} (g) right]^T cdot (H)right) = text{tr} , left( left[left[nabla_{X_0W} gright] W^Tright]^T (H)right)
end{multline*}$$Здесь через $ast W$ мы обозначили отображение $Y hookrightarrow YW$, а в предпоследнем переходе использовалось следующее свойство следа:
$$
text{tr} , (A B C) = text{tr} , (C A B),
$$где $A, B, C$ — произвольные матрицы подходящих размеров (то есть допускающие перемножение в обоих приведённых порядках). Следовательно, получаем
$$color{#348FEA}{nabla_{X_0} f = left[nabla_{X_0W} (g) right] cdot W^T}$$
-
$f(W) = g(XW)$, где $W$ и $X$ — матрицы. Для приращения $H = W — W_0$ имеем
$$
left[D_{W_0} f right] (H) = text{tr} , left( left[nabla_{W_0} f right]^T (H)right)
$$Тогда
$$ begin{multline*}
left[D_{XW_0} g right] left( left[D_{W_0} left(X astright) right] (H)right) = left[D_{XW_0} g right] left( XH right) =
= text{tr} , left( left[nabla_{XW_0} g right]^T cdot X (H)right) =
text{tr}, left(left[X^T left[nabla_{XW_0} g right] right]^T (H)right)
end{multline*} $$Здесь через $X ast$ обозначено отображение $Y hookrightarrow XY$. Значит,
$$color{#348FEA}{nabla_{X_0} f = X^T cdot left[nabla_{XW_0} (g)right]}$$
-
$f(X) = g(softmax(X))$, где $X$ — матрица $Ntimes K$, а $softmax$ — функция, которая вычисляется построчно, причём для каждой строки $x$
$$softmax(x) = left(frac{e^{x_1}}{sum_te^{x_t}},ldots,frac{e^{x_K}}{sum_te^{x_t}}right)$$
В этом примере нам будет удобно воспользоваться формализмом с частными производными. Сначала вычислим $frac{partial s_l}{partial x_j}$ для одной строки $x$, где через $s_l$ мы для краткости обозначим $softmax(x)_l = frac{e^{x_l}} {sum_te^{x_t}}$. Нетрудно проверить, что
$$frac{partial s_l}{partial x_j} = begin{cases}
s_j(1 — s_j), & j = l,
-s_ls_j, & jne l
end{cases}$$Так как softmax вычисляется независимо от каждой строчки, то
$$frac{partial s_{rl}}{partial x_{ij}} = begin{cases}
s_{ij}(1 — s_{ij}), & r=i, j = l,
-s_{il}s_{ij}, & r = i, jne l,
0, & rne i
end{cases},$$где через $s_{rl}$ мы обозначили для краткости $softmax(X)_{rl}$.
Теперь пусть $nabla_{rl} = nabla g = frac{partialmathcal{L}}{partial s_{rl}}$ (пришедший со следующего слоя, уже известный градиент). Тогда
$$frac{partialmathcal{L}}{partial x_{ij}} = sum_{r,l}frac{partial s_{rl}}{partial x_{ij}} nabla_{rl}$$
Так как $frac{partial s_{rl}}{partial x_{ij}} = 0$ при $rne i$, мы можем убрать суммирование по $r$:
$$ldots = sum_{l}frac{partial s_{il}}{partial x_{ij}} nabla_{il} = -s_{i1}s_{ij}nabla_{i1} — ldots + s_{ij}(1 — s_{ij})nabla_{ij}-ldots — s_{iK}s_{ij}nabla_{iK} =$$
$$= -s_{ij}sum_t s_{it}nabla_{it} + s_{ij}nabla_{ij}$$
Таким образом, если мы хотим продифференцировать $f$ в какой-то конкретной точке $X_0$, то, смешивая математические обозначения с нотацией Python, мы можем записать:
$$begin{multline*}
color{#348FEA}{nabla_{X_0}f =}\
color{#348FEA}{= -softmax(X_0) odot text{sum}left(
softmax(X_0)odotnabla_{softmax(X_0)}g, text{ axis = 1}
right) +}\
color{#348FEA}{softmax(X_0)odot nabla_{softmax(X_0)}g}
end{multline*}
$$
Backpropagation в общем виде
Подытожим предыдущее обсуждение, описав алгоритм error backpropagation (алгоритм обратного распространения ошибки). Допустим, у нас есть текущие значения весов $W^i_0$ и мы хотим совершить шаг SGD по мини-батчу $X$. Мы должны сделать следующее:
- Совершить forward pass, вычислив и запомнив все промежуточные представления $X = X^0, X^1, ldots, X^m = widehat{y}$.
- Вычислить все градиенты с помощью backward pass.
- С помощью полученных градиентов совершить шаг SGD.
Проиллюстрируем алгоритм на примере двуслойной нейронной сети со скалярным output’ом. Для простоты опустим свободные члены в линейных слоях.
 Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
$$nabla_{W_0}mathcal{L} = nabla_{W_0}{left({vphantom{frac12}mathcal{L}circ hcircleft[Wmapsto g(XU_0)Wright]}right)}=$$
$$=g(XU_0)^Tnabla_{g(XU_0)W_0}(mathcal{L}circ h) = underbrace{g(XU_0)^T}_{ktimes N}cdot
left[vphantom{frac12}underbrace{h’left(vphantom{int_0^1}g(XU_0)W_0right)}_{Ntimes 1}odot
underbrace{nabla_{hleft(vphantom{int_0^1}g(XU_0)W_0right)}mathcal{L}}_{Ntimes 1}right]$$
Итого матрица $ktimes 1$, как и $W_0$
$$nabla_{U_0}mathcal{L} = nabla_{U_0}left(vphantom{frac12}
mathcal{L}circ hcircleft[Ymapsto YW_0right]circ gcircleft[ Umapsto XUright]
right)=$$
$$=X^Tcdotnabla_{XU^0}left(vphantom{frac12}mathcal{L}circ hcirc [Ymapsto YW_0]circ gright) =$$
$$=X^Tcdotleft(vphantom{frac12}g'(XU_0)odot
nabla_{g(XU_0)}left[vphantom{in_0^1}mathcal{L}circ hcirc[Ymapsto YW_0right]
right)$$
$$=ldots = underset{Dtimes N}{X^T}cdotleft(vphantom{frac12}
underbrace{g'(XU_0)}_{Ntimes K}odot
underbrace{left[vphantom{int_0^1}left(
underbrace{h’left(vphantom{int_0^1}g(XU_0)W_0right)}_{Ntimes1}odotunderbrace{nabla_{h(vphantom{int_0^1}gleft(XU_0right)W_0)}mathcal{L}}_{Ntimes 1}
right)cdot underbrace{W^T}_{1times K}right]}_{Ntimes K}
right)$$
Итого $Dtimes K$, как и $U_0$
Схематически это можно представить следующим образом:

Backpropagation для двуслойной нейронной сети
Если вы не уследили за вычислениями в предыдущем примере, давайте более подробно разберём его чуть более конкретную версию (для $g = h = sigma$)Рассмотрим двуслойную нейронную сеть для классификации. Мы уже встречали ее ранее при рассмотрении линейно неразделимой выборки. Предсказания получаются следующим образом:
$$
widehat{y} = sigma(X^1 W^2) = sigmaBig(big(sigma(X^0 W^1 )big) W^2 Big).
$$
Пусть $W^1_0$ и $W^2_0$ — текущее приближение матриц весов. Мы хотим совершить шаг по градиенту функции потерь, и для этого мы должны вычислить её градиенты по $W^1$ и $W^2$ в точке $(W^1_0, W^2_0)$.
Прежде всего мы совершаем forward pass, в ходе которого мы должны запомнить все промежуточные представления: $X^1 = X^0 W^1_0$, $X^2 = sigma(X^0 W^1_0)$, $X^3 = sigma(X^0 W^1_0) W^2_0$, $X^4 = sigma(sigma(X^0 W^1_0) W^2_0) = widehat{y}$. Они понадобятся нам дальше.
Для полученных предсказаний вычисляется значение функции потерь:
$$
l = mathcal{L}(y, widehat{y}) = y log(widehat{y}) + (1-y) log(1-widehat{y}).
$$
Дальше мы шаг за шагом будем находить производные по переменным из всё более глубоких слоёв.
-
Градиент $mathcal{L}$ по предсказаниям имеет вид
$$
nabla_{widehat{y}}l = frac{y}{widehat{y}} — frac{1 — y}{1 — widehat{y}} = frac{y — widehat{y}}{widehat{y} (1 — widehat{y})},
$$где, напомним, $ widehat{y} = sigma(X^3) = sigmaBig(big(sigma(X^0 W^1_0 )big) W^2_0 Big)$ (обратите внимание на то, что $W^1_0$ и $W^2_0$ тут именно те, из которых мы делаем градиентный шаг).
-
Следующий слой — поэлементное взятие $sigma$. Как мы помним, при переходе через него градиент поэлементно умножается на производную $sigma$, в которую подставлено предыдущее промежуточное представление:
$$
nabla_{X^3}l = sigma'(X^3)odotnabla_{widehat{y}}l = sigma(X^3)left( 1 — sigma(X^3) right) odot frac{y — widehat{y}}{widehat{y} (1 — widehat{y})} =
$$$$
= sigma(X^3)left( 1 — sigma(X^3) right) odot frac{y — sigma(X^3)}{sigma(X^3) (1 — sigma(X^3))} =
y — sigma(X^3)
$$ -
Следующий слой — умножение на $W^2_0$. В этот момент мы найдём градиент как по $W^2$, так и по $X^2$. При переходе через умножение на матрицу градиент, как мы помним, умножается с той же стороны на транспонированную матрицу, а значит:
$$
color{blue}{nabla_{W^2_0}l} = (X^2)^Tcdot nabla_{X^3}l = (X^2)^Tcdot(y — sigma(X^3)) =
$$$$
= color{blue}{left( sigma(X^0W^1_0) right)^T cdot (y — sigma(sigma(X^0W^1_0)W^2_0))}
$$Аналогичным образом
$$
nabla_{X^2}l = nabla_{X^3}lcdot (W^2_0)^T = (y — sigma(X^3))cdot (W^2_0)^T =
$$$$
= (y — sigma(X^2W_0^2))cdot (W^2_0)^T
$$ -
Следующий слой — снова взятие $sigma$.
$$
nabla_{X^1}l = sigma'(X^1)odotnabla_{X^2}l = sigma(X^1)left( 1 — sigma(X^1) right) odot left( (y — sigma(X^2W_0^2))cdot (W^2_0)^T right) =
$$$$
= sigma(X^1)left( 1 — sigma(X^1) right) odotleft( (y — sigma(sigma(X^1)W_0^2))cdot (W^2_0)^T right)
$$ -
Наконец, последний слой — это умножение $X^0$ на $W^1_0$. Тут мы дифференцируем только по $W^1$:
$$
color{blue}{nabla_{W^1_0}l} = (X^0)^Tcdot nabla_{X^1}l = (X^0)^Tcdot big( sigma(X^1) left( 1 — sigma(X^1) right) odot (y — sigma(sigma(X^1)W_0^2))cdot (W^2_0)^Tbig) =
$$$$
= color{blue}{(X^0)^Tcdotbig(sigma(X^0W^1_0)left( 1 — sigma(X^0W^1_0) right) odot (y — sigma(sigma(X^0W^1_0)W_0^2))cdot (W^2_0)^Tbig) }
$$
Итоговые формулы для градиентов получились страшноватыми, но они были получены друг из друга итеративно с помощью очень простых операций: матричного и поэлементного умножения, в которые порой подставлялись значения заранее вычисленных промежуточных представлений.
Автоматизация и autograd
Итак, чтобы нейросеть обучалась, достаточно для любого слоя $f^k: X^{k-1}mapsto X^k$ с параметрами $W^k$ уметь:
- превращать $nabla_{X^k_0}mathcal{L}$ в $nabla_{X^{k-1}_0}mathcal{L}$ (градиент по выходу в градиент по входу);
- считать градиент по его параметрам $nabla_{W^k_0}mathcal{L}$.
При этом слою совершенно не надо знать, что происходит вокруг. То есть слой действительно может быть запрограммирован как отдельная сущность, умеющая внутри себя делать forward pass и backward pass, после чего слои механически, как кубики в конструкторе, собираются в большую сеть, которая сможет работать как одно целое.
Более того, во многих случаях авторы библиотек для глубинного обучения уже о вас позаботились и создали средства для автоматического дифференцирования выражений (autograd). Поэтому, программируя нейросеть, вы почти всегда можете думать только о forward-проходе, прямом преобразовании данных, предоставив библиотеке дифференцировать всё самостоятельно. Это делает код нейросетей весьма понятным и выразительным (да, в реальности он тоже бывает большим и страшным, но сравните на досуге код какой-нибудь разухабистой нейросети и код градиентного бустинга на решающих деревьях и почувствуйте разницу).
Но это лишь начало
Метод обратного распространения ошибки позволяет удобно посчитать градиенты, но дальше с ними что-то надо делать, и старый добрый SGD едва ли справится с обучением современной сетки. Так что же делать? О некоторых приёмах мы расскажем в следующей главе.