13.04.2021
Дата обновления: 02.03.2022
Если в работе сервера, компьютера или программного обеспечения возникла неизвестная ошибка, в первую очередь смотрят логи. Лог — текстовый файл с информацией о действиях программного обеспечения или пользователей, который хранится на компьютере или сервере. Это хронология событий и их источников, ошибок и причин, по которым они произошли. Читать и анализировать логи можно с помощью специального ПО.
Логирование: что это и где применяется
Логированием называют запись логов. Оно позволяет ответить на вопросы, что происходило, когда и при каких обстоятельствах. Без логов сложно понять, из-за чего появляется ошибка, если она возникает периодически и только при определенных условиях. Чтобы облегчить задачу администраторам и программистам, в лог записывается информация не только об ошибках, но и о причинах их возникновения.
После перехода в продакшен, работу приложения нужно постоянно мониторить, чтобы предотвращать и быстро реагировать на потенциальные ЧП. Анализ логов — один из базовых инструментов в работе ИТ-специалистов. Он помогает обнаружить источники многих проблем, выявить конфликты в конфигурационных файлах, отследить события, связанные с ИБ. А главное, благодаря логам найденные ошибки можно быстро исправить. Поэтому логирование так важно при отладке программ, поиске источников проблем с прикладным программным обеспечением и базами данных.
Логи должны записываться во время работы каждого ИТ-компонента.
Вот несколько типичных случаев, в которых применяются логи:
- Администратор ищет причины возникновения технических проблем, сбоев в устройства или операционной системы и недоступности сайта.
- Разработчик проводит дебаг, то есть ищет, локализует и устраняет ошибки.
- Seo-специалисты собирают статистику посещаемости, оценивают качество целевого трафика.
- Администратор интернет-магазина отслеживает историю взаимодействия с платежными системами и данные об изменениях в заказах.
Типы логов
Существуют разные уровни и разные подробности логирования. Когда ошибку сложно воспроизвести, используют максимально подробные логи; если это не требуется, собирают только ключевую информацию. Для работы с логами и поиском информации в огромных текстовых данных используют специализированные инструменты.
Для удобной работы с логами их делят на типы. Это помогает быстрее находить нужные и выбирать правильные инструменты для работы с ними. Например, выделяют:
- системные логи, то есть те, которые связаны с системными событиями;
- серверные логи, регистрирующие обращения к серверу и возникшие при этом ошибки;
- логи баз данных, фиксирующие запросы к базам данных;
- почтовые логи, относящиеся к входящим/исходящим письмам и отслеживающие ошибки, из-за которых письма не были доставлены;
- логи авторизации;
- логи аутентификации;
- логи приложений, установленных на этих операционных системах.
Также логи можно типизировать по степени их важности:
- Fatal/critical error — то, что нужно срочно исправить.
- Not critical error — ошибки, которые не влияют на пользователя.
- Warning — предупреждения, то, на что нужно обратить внимание.
- Initial information — информация о вызовах API сервиса, запросах в БД, вызовах других сервисов.
Где ITGLOBAL.COM использует логирование
Специалисты ITGLOBAL.COM настраивают автоматический сбор, хранение и обработку логов в облачном хранилище. Облако позволяет воспроизвести события на целевой системе даже при ее полном отказе.
Поясним на примере. Допустим, файловая система одной из виртуальных машин повредилась и все данные на сервере были уничтожены. Инженеры получают уведомление об этом инциденте от системы мониторинга и восстанавливают работоспособность сервера через бэкапы. После этого они анализируют логи, которые сохранились благодаря удаленной системе хранения. Они похожи на черный ящик самолета, так как с их помощью специалисты восстанавливают последовательность событий при инциденте, делают выводы и вырабатывают решения, которые предотвратят появление таких инцидентов в будущем.
Также инженеры ITGLOBAL.COM используют логи для анализа действий пользователей. Они в любой момент могут восстановить, кто и когда совершал определенные действия внутри системы. Для этого специалисты используют инструменты, которые автоматически контролируют базовые события, касающиеся безопасности. Например, если в субботу ночью появится учетная запись с правами суперпользователя, система сразу зарегистрирует это событие и пришлет уведомление. Инженеры уточнят легитимность новой записи, чтобы предотвратить попытку несанкционированного доступа.
Инструменты
Сбор, хранение и анализ логов выполняется с помощью специальных инструментов. Расскажем, какие из них используют специалисты ITGLOBAL.COM.
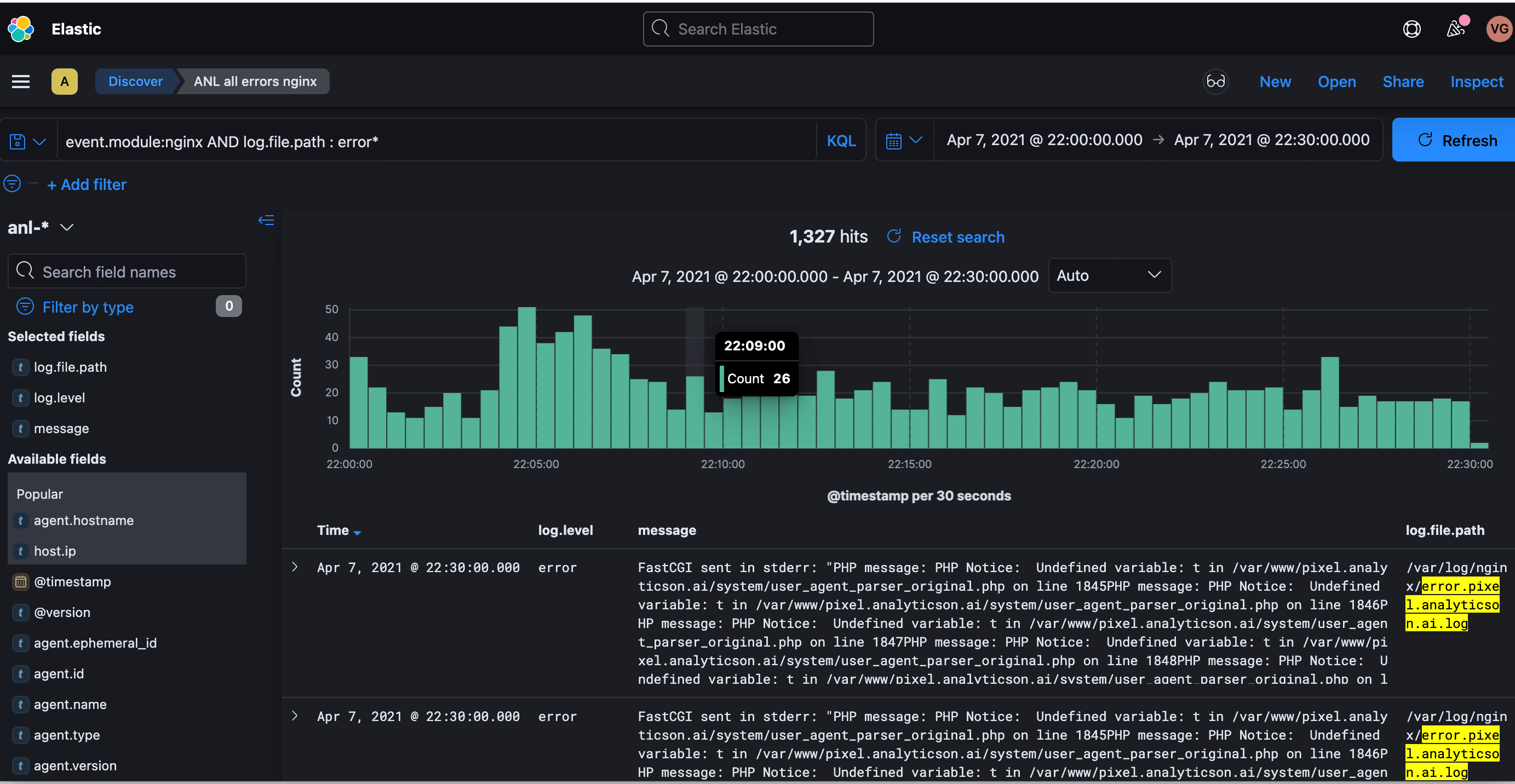
Elasticsearch, Logstash и Kibana
Логи всех информационных систем, подключенных к услуге Managed IT, хранятся в распределенном хранилище на базе решения ELK (Elasticsearch, Logstash и Kibana). Механизм сбора логов выглядит так: Logstash собирает логи и переносит их в хранилище, Elasticsearch помогает найти нужные строки в этих логах, а Kibana визуализирует их. Все три компонента разработаны на основе открытого кода, благодаря чему их можно модифицировать под потребности компании.
- Logstash — приложение для работы с большими объемами данных, собирает информацию из разных источников и переводит ее в удобный формат.
- Elasticsearch — система для поиска информации. Помогает быстро найти нужные строки в файлах хранения.
- Kibana — плагин визуализации данных и аналитики в Elasticsearch. Помогает обрабатывать информацию, находить в ней закономерности и слабые места.
Wazuh
Решение с открытым кодом для поиска логов, коррелирующих с моделями угроз информационной безопасности. С его помощью специалисты ITGLOBAL.COM мониторят целостность ИТ-систем и оперативно реагируют на инциденты.
Wazuh помогает:
- обнаружить скрытые процессы программ, которые используют уязвимости в ПО для обхода антивирусных систем;
- автоматически блокировать сетевую атаку, останавливать вредоносные процессы и файлы, зараженные вирусами.
Почему логирование нужно каждой компании
Логирование — еще один способ эффективно контролировать состояние инфраструктуры. В ITGLOBAL.COM оно входит в пакет услуг Managed IT. Вместе с сервисами мониторинга логирование существенно экономит время инженеров при расследовании тех или иных инцидентов. А главное, с помощью анализа логов можно предотвратить инциденты в будущем.
Компании, которые используют логирование в рамках услуги Managed IT, уменьшают общее количество инцидентов и получают принципиально другой уровень контроля над инфраструктурой.
Также сервис удобен для разработчиков, которые с помощью простых интерфейсов могут в режиме реального времени отслеживать работу своих приложений.
Известно, что программисты проводят много времени, отлаживая свои программы, пытаясь разобраться, почему они не работают — или работают неправильно. Когда говорят про отладку, обычно подразумевают либо отладочную печать, либо использование специальных программ – дебагеров. С их помощью отслеживается выполнение кода по шагам, во время которого видно, как меняется содержимое переменных. Эти способы хорошо работают в небольших программах, но в реальных приложениях быстро становятся неэффективными.
- Сложность реальных приложений
- Логирование
- Уровни логирования
- Ротация логов
Сложность реальных приложений
Возьмем для примера типичный сайт. Что он в себя включает?
- DNS. Система трансляции имени сайта в ip-адрес сервера.
- Веб-сервер. Программа, обслуживающая входящие запросы, перенаправляет их в код приложения и забирает от приложения данные для пользователей.
- Физический сервер (или виртуальный) с его окружением. Включает в себя операционную систему, установленные и запущенные обслуживающие программы, например, мониторинг.
- База данных. Внешнее хранилище, с которым связывается код приложения и обменивается информацией.
- Само приложение. Помимо кода, который пишут программисты, приложение включает в себя сотни тысяч и миллионы строк кода сторонних библиотек. Кроме этого, код работает внутри фреймворка, у которого свои собственные правила обработки входящих запросов.
- Фронтенд часть. Код, который выполняется в браузере пользователя. И системы сборки для разработки, например, Webpack.
И это только самый простой случай. Реальность же значительно сложнее: множество разноплановых серверов, системы кеширования (ускорения доступа), асинхронный код, очереди, внешние сервисы, облачные сервисы. Все это выглядит как многослойный пирог, внутри которого где-то работает написанный нами код. И этот код составляет лишь небольшую часть всего происходящего. Как в такой ситуации понять, на каком этапе был сбой, или все пошло не по плану? Для этого, как минимум, нужно определить, в каком слое произошла ошибка. Но даже это не самое сложное. Об ошибках в работающем приложении узнают не сразу, а уже потом, — когда ошибка случилась и, иногда, больше не воспроизводится.
Логирование
И для всего этого многообразия систем существует единое решение — логирование. В простейшем случае логирование сводится к файлу на диске, куда разные программы записывают (логируют) свои действия во время работы. Такой файл называют логом или журналом. Как правило, внутри лога одна строчка соответствует одному действию.
# Формат: ip-address / date / HTTP-method / uri / response code / body size
173.245.52.110 - [19/Jan/2021:01:54:20 +0000] "GET /my HTTP/1.1" 200 46018
108.162.219.13 - [19/Jan/2021:01:54:20 +0000] "GET /sockjs-node/244/gdt1vvwa/websocket HTTP/1.1" 0 0
162.158.62.12 - [19/Jan/2021:01:54:20 +0000] "GET /packs/css/application.css HTTP/1.1" 304 0
162.158.62.84 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/runtime-eb0a99abbe8cf813f110.js HTTP/1.1" 304 0
108.162.219.111 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/application-2cba5619945c4e5946f1.js HTTP/1.1" 304 0
108.162.219.21 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/0564a7b5d773bab52e53.js HTTP/1.1" 304 0
108.162.219.243 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/6fb7e908211839fac06e.js HTTP/1.1" 304 0
Выше небольшой кусок лога веб-сервера Хекслета. Из него видно ip-адрес, с которого выполнялся запрос на страницу и какие ресурсы загружались, метод HTTP, ответ бекенда (кода) и размер тела ответа в HTTP. Очень важно наличие даты. Благодаря ей всегда можно найти лог за конкретный период, например на то время, когда возникла ошибка. Для этого логи грепают:
# Выведет 4 минуты логов за 31 марта 2020 года с 19:31 по 19:35
grep "31/Mar/2020:19:3[1-5]" access.log
Когда программисты только начинают свой путь, они, часто не зная причину ошибки, опускают руки и говорят «я не знаю, что случилось, и что делать». Опытный же разработчик всегда первым делом говорит «а что в логах?». Анализировать логи — один из базовых навыков в разработке. В любой непонятной ситуации нужно смотреть логи. Логи пишут все программы без исключения, но делают это по-разному и в разные места. Чтобы точно узнать, куда и как, нужно идти в документацию конкретной программы и читать соответствующий раздел документации. Вот несколько примеров:
- Ruby On Rails (Ruby)
- Django (Python)
- Laravel (PHP)
- Spring Boot (Java)
- Fastify (Node.js)
Многие программы логируют прямо в консоль, например Webpack показывает процесс и результаты сборки:
# Сюда же выводятся ошибки, если они были
「wds」: Project is running at http://hexletdev4.com/
「wds」: webpack output is served from /packs/
「wds」: Content not from webpack is served from /root/hexlet/public/packs
「wds」: 404s will fallback to /index.html
「wdm」: assets by chunk 10.8 MiB (auxiliary name: application) 115 assets
sets by path js/ 13.8 MiB
assets by path js/*.js 13.8 MiB 52 assets
assets by path js/pages/*.js 5.1 KiB
asset js/pages/da223d3affe56711f31f.js 2.6 KiB [emitted] [immutable] (name: pages/my_learning) 1 related asset
asset js/pages/04adacfdd660803b19f1.js 2.5 KiB [emitted] [immutable] (name: pages/referral) 1 related asset
sets by chunk 9.14 KiB (auxiliary id hint: vendors)
Во фронтенде файлов нет, поэтому логируют либо прямо в консоль, либо к себе в бекенды (что сложно), либо в специализированные сервисы, такие как LogRocket.
Уровни логирования
Чем больше информации выводится в логах, тем лучше и проще отладка, но когда данных слишком много, то в них тяжело искать нужное. В особо сложных случаях логи могут генерироваться с огромной скоростью и в гигантских размерах. Работать в такой ситуации нелегко. Чтобы как-то сгладить ситуацию, системы логирования вводят разные уровни. Обычно это:
- debug
- info
- warning
- error
Поддержка уровней осуществляется двумя способами. Во-первых, внутри самой программы расставляют вызовы библиотеки логирования в соответствии с уровнями. Если произошла ошибка, то логируем как error, если это отладочная информация, которая не нужна в обычной ситуации, то уровень debug.
// Пример логирования внутри программы
// Логер: https://github.com/pinojs/pino
import buildLogger from 'pino';
const logger = buildLogger(/* возможная конфигурация */);
logger.info('тут что то полезное');
Во-вторых, во время запуска программы указывается уровень логирования, необходимый в конкретной ситуации. По умолчанию используется уровень info, который используется для описания каких-то ключевых и важных вещей. При таком уровне будут выводиться и warning, и error. Если поставить уровень error, то будут выводиться только ошибки. А если debug, то мы получим лог, максимально наполненный данными. Обычно debug приводит к многократному росту выводимой информации.
Уровни логирования, обычно, выставляются через переменную окружения во время запуска программы. Например, так:
# https://github.com/fastify/fastify-cli#options
FASTIFY_LOG_LEVEL=debug fastify-server.js
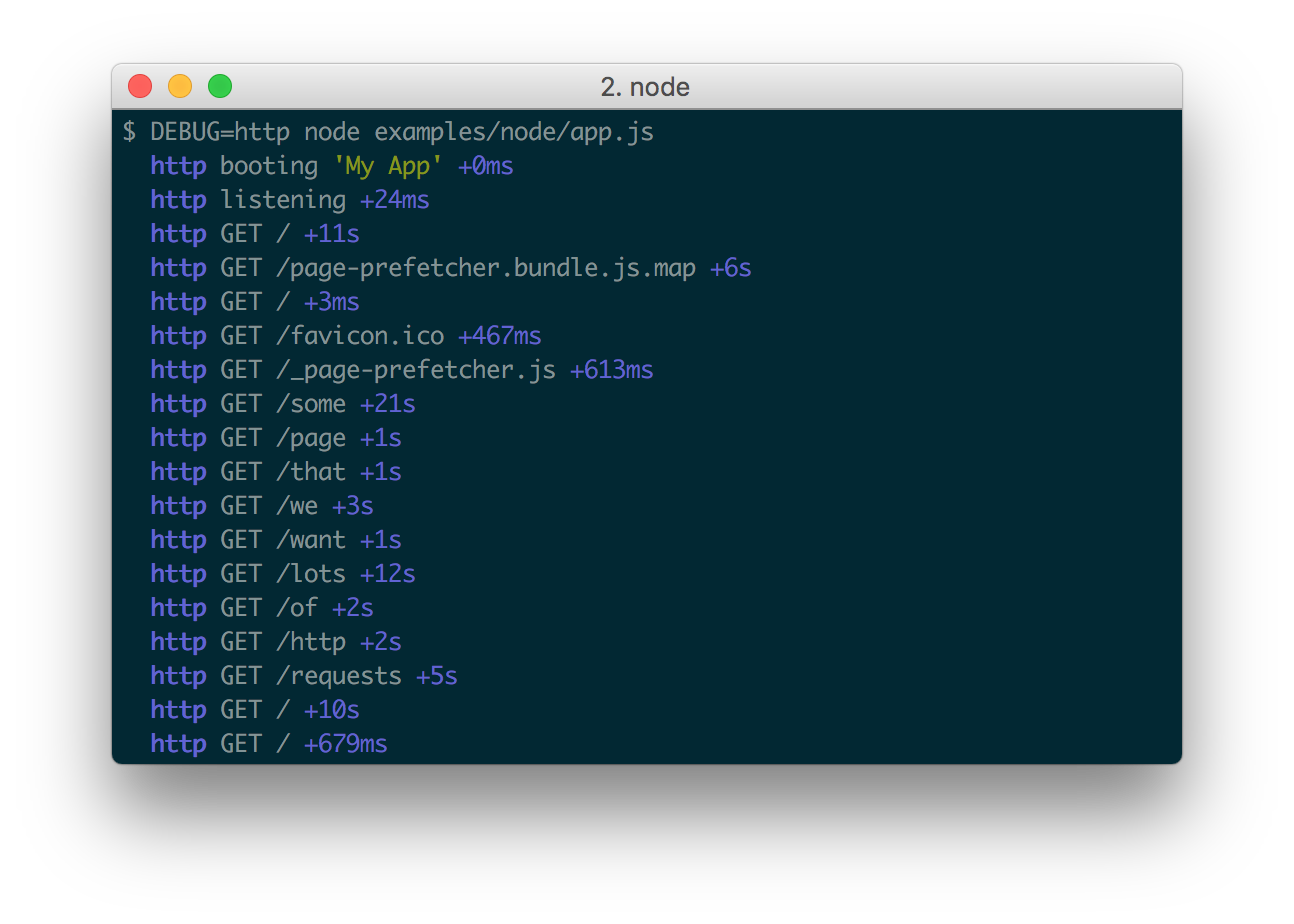
Существует и другой подход, основанный не на уровнях, а на пространствах имен. Этот подход получил широкое распространение в JS-среде, и является там основным. Фактически, он построен вокруг одной единственной библиотеки debug для логирования, которой пронизаны практически все JavaScript-библиотеки как на фронтенде, так и на бекенде.
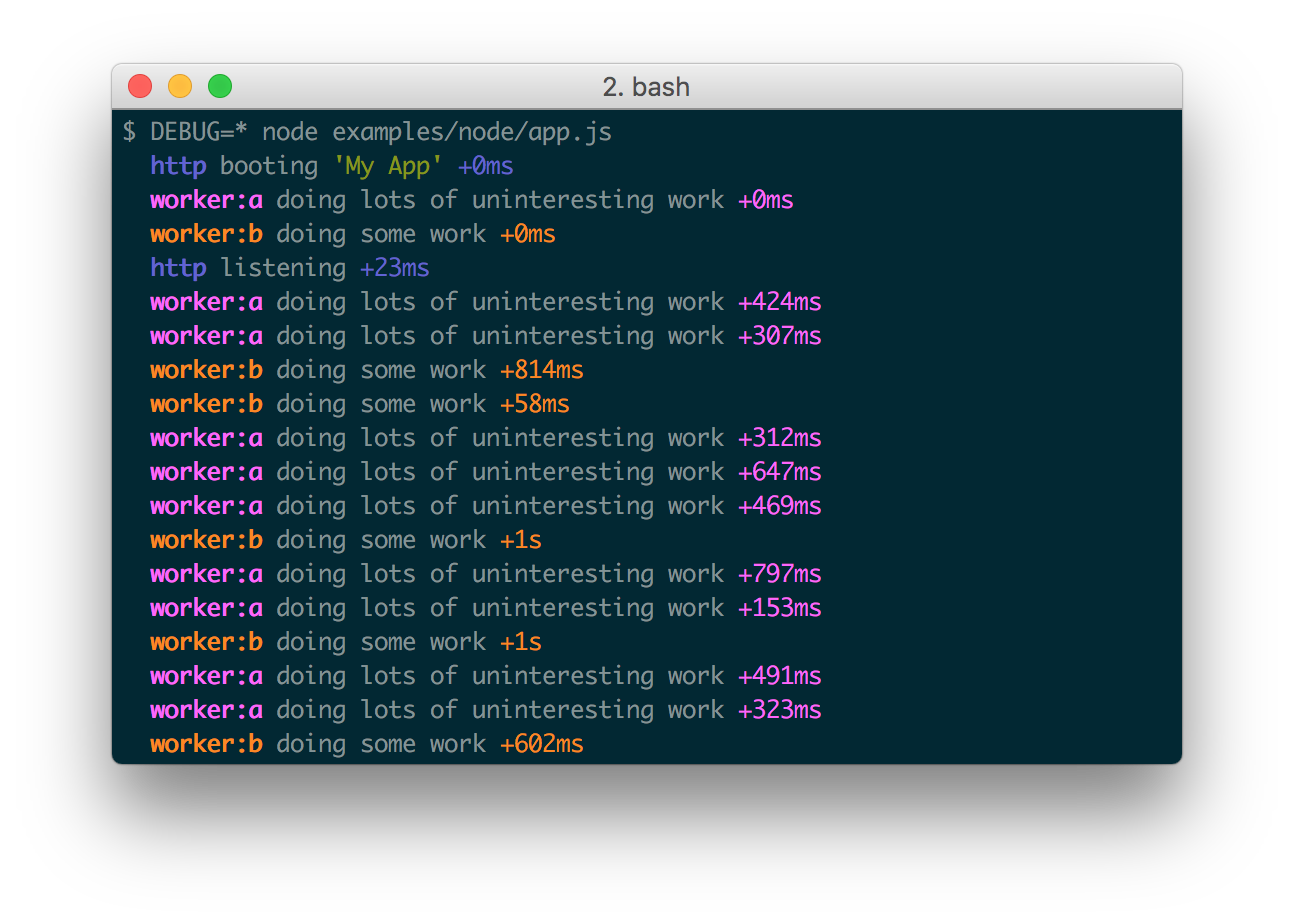
Принцип работы здесь такой. Под нужную ситуацию создается специализированная функция логирования с указанием пространства имен, которая затем используется для всех событий одного процесса. В итоге библиотека позволяет легко отфильтровать только нужные записи, соответствующие нужному пространству.
import debug from 'debug';
// Пространство имен http
const logHttp = debug('http');
const logSomethingElse = debug('another-namespace');
// Где-то в коде
logHttp(/* информация о http запросе */);
Запуск с нужным пространством:
DEBUG=http server.js
Ротация логов
Со временем количество логов становится большим, и с ними нужно что-то делать. Для этого используется ротация логов. Иногда за это отвечает сама программа, но чаще — внешнее приложение, задачей которого является чистка. Эта программа по необходимости разбивает логи на более мелкие файлы, сжимает, перемещает и, если нужно, удаляет. Подобная система встроена в любую операционную систему для работы с логами самой системы и внешних программ, которые могут встраиваться в нее.
С веб-сайтами все еще сложнее. Даже на небольших проектах используется несколько серверов, на каждом из которых свои логи. А в крупных проектах тысячи серверов. Для управления такими системами созданы специализированные программы, которые следят за логами на всех машинах, скачивают их, складывают в заточенные под логи базы данных и предоставляют удобный способ поиска по ним.
Здесь тоже есть несколько путей. Можно воспользоваться готовыми решениями, такими как DataDog Logging, либо устанавливать и настраивать все самостоятельно через, например, ELK Stack
Логирование: понятие, механизмы и уровни
Программисты и системные администраторы занимаются структурированием и контролем за работой сайтов, серверов и программного обеспечения отдельного компьютера. При возникновении ошибок в работе того или иного сервиса специалист обращается к логам.

Что такое логи?
При возникновении любой ошибки программист проверяет логи — это хронология работы любой системы, которая расскажет, что происходило в системе, какой именно пользователь это сделал и когда. Грамотные администраторы обращаются к логам раньше, чем произойдет ошибка, чтобы ее предотвратить.
Лог представляет собой текстовый файл, записанный языком программирования, как и всё, что скрыто за красивыми картинками, которые видит обычный пользователь. Такие текстовые файлы хранятся на компьютере, на удалённом жёстком диске, да и вообще на любом удобном носителе.
Типы логов
В зависимости от программного обеспечения и оттого, чью работу описывает лог, а именно:
- сайта,
- приложения,
- базы данных,
- почтового агента
- или сервера —
они делят на различные типы: системные, файлы БД, серверные, почтовые, аутентификации, авторизации, логи приложений. Группировка логов таким образом помогает быстрее находить нужный лог и оптимизировать работу с ним.
Еще одна полезная классификация логов в порядке их важности для ситуационной ошибки:
- Срочное исправление — Fatal error
- Ошибки, не влияющие на пользователя — Not critical error
- События, требующие внимания — Warning
- Информация о вызовах различных серверов — Initial information
О чем расскажет логирование
Понимая, что такое файлы логирования, или файлы с историей о работе системы, и на какие типы они делятся, можно перейти к процессу их создания. Логирование — это запись логов, структурирование и перемещение их в отдельные файлы для быстрого доступа к ним. Более продвинутый уровень записи хронологии позволяет классифицировать логи по важности, в некоторых случаях даже удалять ненужные.
Программисты настраивают автоматический сбор хранения и обработки логов в облачных хранилищах, чтобы во время возникновения ошибки на сервере была возможность сохранить данные и анализировать их для предотвращения будущих ошибок. Это и является основной задачей регистрации данных — не только следить за работой программного обеспечения, но и производить анализ этой работы. Самые продвинутые специалисты смотрят в будущее, даже если произошла ошибка сейчас, важно не только устранить ее в конкретной ситуации, но и придумать решения, чтобы такой ошибки больше никогда не возникало.
Если обобщить все вышесказанное, логирование данных — это история работы системы, помогающая пользователю не наступить на одни и те же грабли два раза, а то и несколько раз, если избегать грамотной работы с логами.
Для специалиста файлы с логами, как книга, по которой он читает, что происходило в системе.
Благодаря правильной организации хранения логов, их запись представляет собой самый эффективный способ контроля над информацией. История событий расскажет все, что происходит внутри сервера, или сайта или любой другой системы. Какие действия были совершены конкретным пользователем тоже прописывается в логах. Одним словом, каждый шаг под контролем благодаря логированию.
Механизмы записи информации
Расшифровка логов имеет свои особенности с учетом производителя программного обеспечения и стоит следовать рекомендациям разработчика во время анализа логов. Программисты используют различные механизмы записи логов:
- Самый понятный и распространенный механизм — запись логов в текстовый файл, это запись каждого события единственной строкой. Способ доступен к реализации, читается любым текстовым редактором.
- Более углубленный лог — одно событий записывается несколькими строками, одно событие разбивается на много маленьких, для чтения используется специальные программы.
- Бинарный — самый сложный тип файлов, обычно такие логи обрабатываются программным обеспечением производителя, что и приложение, записывающее логи.
- Приложения использующие БД или сами СУБД (система управления БД). Запись логов в БД замедляет их работу из-за интенсивной записи логов.
Логирование должно быть незаметным для пользователей, если все приложения подобраны правильно, процесс работы системы не замедляется, в обратном случае снижается производительность из-за нехватки места на диске.
Уровни логирования
При любом механизме записи событий их объем очень большой, работать с таким количеством информации сложно. Для этого логи разделяют на уровни, стандартно выделяют следующие уровни логирования:
- debug
- info
- waring
- error
На уровне debug едет запись значимых переходных состояний, например, запуск или остановка сервера, запрос в БД и верификация обработки информации.
Уровень info расскажет программисту об общих событиях работы сервиса. Экстренные ситуации, проблемы, некорректные запросы будут записаны в waring. Основные ошибки на уровне error.
Чтобы соблюдались уровни логирования, программисту нужно прописать условия или внутри самой программы или выставлять условия в зависимости от ситуации при запуске программы, которая производит логирование.
Ротация файлов
Представим, что логирование данных системы налажено согласно уровням и вышеописанным механизмам. Например, мы прописали в приложении уровни: debug, info, waring, error. Выбрали в качестве механизма текстовые файлы и у нас благополучно се логи копятся в отдельный файл Нам пора обратиться к ротации.
Ротация файлов логирования, как и любой другой информации означает их классификацию, не по типам, как описывалось выше, а по уровням. Во время ротации возможна сортировка не только по уровням, но и удаление файлов, к которым точно не нужно будет обращаться. Такой подход позволяет сократить количество памяти на жёстком диске, которое будет занято хронологическими файлами, не все они представляют собой одинаковую значимость для системного администратора, поэтому в их удалении заложен сакральный смысл сохранения работоспособности системы. Ведь чем больше памяти на жёстком диске, тем быстрее обрабатываются запросы пользователей.
Имеются системы логирования с высокими рейтингами, которые берут на себя функцию записи истории событий и их последующей ротации.
Важность логирования
Логирование — неотъемлемая часть процесса работы всех видов систем, которая позволяет увеличить коэффициент производительности и уменьшить процент ошибок. Благодаря анализу хронологии событий инженеры, программисты и системные администраторы:
- экономят время компаний, которые доверяют им обработку и хранение своей информации,
- составляют прогноз будущих ошибок,
- выявляют причины сбоев работы сервера,
- отслеживают ошибки по которым письма электронной почты не доставляются адресату или не приходят клиенту,
- устраняют ошибки авторизации и аутентификации,
- находят ошибки в работе приложений.
Качественным отличием опытного программиста является умение настроить процесс логирования до возникновения критических ситуаций, то есть предотвращение возможных ошибок до запуска проекта, и уделения внимания, а новичка — в недооцененности хронологии ошибок и отсутствие настройки своевременного логирования.
Логирование в Java
Введение
Логирование(logging) — это процесс записи информации о событиях, происходящих в рамках какого-либо процесса с некоторым объектом. Запись может проводиться в файл регистрации или в базу данных.
Слово
log, на самом деле, имеет множество значений, например протокол или журнал.
Однако обычно все говорят именно лог и производные от него: логирование и логировать.Хотя правильнее было бы говорить наверное журналирование/протоколирование и вести журнал/протокол соответственно.
Но так никто никогда не говорит, конечно ¯(ツ)/¯
По сути логирование — это то, что позволяет следить за ходом выполнения вашего приложения, вашего кода.
При работе приложения надо понимать, что вообще происходит внутри, особенно при разборе ошибок и инцидентов. В этом как раз и помогают логи — это как запись черного ящика на самолетах.
Нет информации о происходящих событий в приложении — мы ничего не знаем о том, что происходит. И если такое поведение может устраивать в случае, когда все идеально работает (да и то сомнительно), то во всех остальных случаях такое поведение категорически не устраивает никого.
Поэтому «логи всякие нужны, логи всякие важны».
Пришла пора сформулировать требования — чего вообще хотелось бы от логера.
Требования
Еще одним важным вопросом на который надо ответить — это что логировать.
Работа приложения — это происходящие в нем события, которые в свою очередь могут быть классифицированы на:
- события, связанные с бизнес-логикой
- события, связанные с безопасностью приложения
- и системные события, связанные с уже конкретикой реализации — вызовов ОС, использования библиотек, фреймворков и т.д.
Все ли нужно логировать?
Если вы вдруг залогируете в общий файл-лога пароль и логин пользователя, то никто такому рад не будет, что подводит нас к мысли, что логировать надо тоже с умом.
Опять же, если логировать все подряд, то размеры таких логов будут не просто большими, они будут огромными. И у вас возникнет уже другая проблема — где все это хранить.
Добавим сюда еще и то, что логирование — это тоже работа, а значит процессорное время. И чем больше логов мы пишем — тем больше процессорного времени тратится на это, а в ситуации, когда все работает хорошо такое чрезмерное логирование только тормозит.
С другой стороны, при возникновении проблем, особенно спорадических ошибок, чем больше у вас информации — тем лучше.
Т.е возникает требование управления информацией, которая нам нужна в данный момент, а также форматом ее вывода.
При этом, логично, что изменения этого формата и того, что мы хотим видеть в логе не должны требовать перекомпиляции всего проекта или изменения кода.
Уровни логирования
Уровень логирования — это разделение событий по приоритетам, по степени важности. Например, error — пишем ошибки, debug — пишем более подробно в лог и т.д.
| Уровень логирования | Описание |
|---|---|
| ALL | Все сообщения |
| TRACE | Сообщение для более точной отладки |
| DEBUG | Дебаг-сообщение, для отладки |
| INFO | Обычное сообщение |
| WARN | Предупреждение, не фатально, но что-то не идеально |
| ERROR | Ошибка |
| FATAL | Фатальная ошибка, дело совсем плохо |
| OFF | Без сообщения |
Если проиллюстрировать это:

Принципы и понятия
В основе большинства библиотек логирования лежат три понятия: logger, appender и layout.
Это наиболее распространенные и устоявшиеся понятия, можно сказать, что это — стандарт.
Logger
Логер — это объект, область ответственности которого — вывод данных в лог и управление уровнем (детализацией) этого вывода.
Логер создается с помощью фабрики и на этапе создания ему присваивается имя. Имя может быть любым, но по стандарту имя должно быть сопряжено с именем класса, в котором вы собираетесь что-то логировать:
Logger logger = LoggerFactory.getLogger(SomeClass.class.getName());
Это дает нам имя логера в виде: ru.aarexer.example.SomeClass.
Почему так рекомендуется делать?
Потому что важным свойством логгеров является то, что они организованы иерархично. Каждый логгер имеет имя, описывающее иерархию, к которой он принадлежит. Разделитель – точка. Принцип полностью аналогичен формированию имени пакета в Java.
Получается выстраивается следующая иерархия логеров:
root <- ru <- aarexer <- example <- SomeClass
И каждому логеру можно выставить свой уровень. Установленный логгеру уровень вывода распространяется на все его дочерние логгеры, для которых явно не выставлен уровень.
При этом во главе иерархии логеров всегда стоит некотрый дефолтный рутовый(корневой) логер.
Поэтому у всех логеров будет уровень логирования, даже если явно мы не прописали для ru.aarexer.example.SomeClass его, то он унаследуется от рутового.
Вопрос:
Мы установили рутовый уровень в INFO, а ru.aarexer в DEBUG, остальным в иерархии уровень не назначен, т.е:
| Логер | Назначенный уровень |
|---|---|
| root | INFO |
| ru | Не назначен |
| ru.aarexer | DEBUG |
| ru.aarexer.example | Не назначен |
Какой у какого логера будет уровень логирования?
Ответ:
Вспоминаем, что, если уровень логирования не назначен для логера, то он унаследует его от родительского, смотрим на иерархию:
root <- ru <- aarexer <- example
И получаем ответ:
| Logger | Назначенный уровень | Уровень, который будет |
|---|---|---|
| root | Все сообщения | INFO |
| ru | Не назначен | INFO |
| ru.aarexer | DEBUG | DEBUG |
| ru.aarexer.example | Не назначен | DEBUG |
Подход с иерархией логеров очень гибкий – можно для всех выставить требуемый уровень, например, ERROR, а для необходимых логеров его менять, причем как в сторону понижения, так и в сторону повышения уровня.
Задача логера одна — это вызывать событие, которое приведет к логированию.
logger.info("Application started"); logger.debug("Or not");
Это событие по сути состоит из двух полей:
message = "Application started" level = Level.Info
Appender
Аппендер – это та точка, куда события приходят в конечном итоге.
Это может быть файл, БД, консоль, сокет и т.д.
Здесь нас никто не ограничивает — можно написать свой аппендер, который пишет сообщения куда-угодно.
Получается у нас есть две точки, первая — это логгер, это начало пути, вторая — аппендер, это уже конечная точка.
Логеры и аппендеры связаны в отношении many-to-many.
У одного логгера может быть несколько аппендеров, а к одному аппендеру может быть привязано несколько логгеров.
Логеры при этому наследуют от родительских не только уровни логирования, но и аппендеры.
Например, если к root-логгеру привязан аппендер A1, а к логгеру ru.aarexer – A2, то вывод в логгер ru.aarexer попадет в A2 и A1, а вывод в ru – только в A1.
Вопрос:
Пусть у нас есть несколько аппендеров и логеров
| Logger | Appender |
|---|---|
| root | А1 |
| ru.aarexer | А2 |
| ru.aarexer.example.SomeClass | А3 |
В какой аппендер попадет лог-сообщение:
LoggerFactory.getLogger(SomeClass.class.getName()).info("hello");
Ответ:
У логеров есть такое свойство как additivity. По умолчанию она установлена в true.
Это говорит о том, что логер-наследник будет свои события передавать логеру-родителю.
Смотрим на иерархию:
root <- ru <- aarexer <- example
Из всего вышесказанного делаем вывод, что событие «hello» с уровнем Level.INFO попадет во все три аппендера.
Но такое наследование аппендеров можно отключить через конфигурацию, для этого стоит посмотреть в сторону выставления флага additivity="false" на логгерах.
Layout
Layout — это формат вывода данных.
Т.е как лог-сообщения будут отформативарованы, соответственно тут у каждой библиотеки свой набор доступных форматов.
Теперь пришла пора посмотреть — что вообще есть в Java.
Библиотеки логирования в Java
Ну и самым первым логером, который можно представить себе, был и есть System.out.println и System.err.println. При этом надо помнить, что err и out — это два разных потока вывода, где err вывод не буферизуется и работает быстрее, чем out.
По сути, такой логер может писать либо info-сообщения, либо error.
Однако он не отвечает всем тем требованиям, которые мы сформулировали выше, поэтому рассмотрим альтернативы.
Наиболее популярные библиотеки логирования в Java:
java.util.loggingилиJUL, является частьюJDK.Apache log4jlogback, разработанная создателямиlog4jApache log4j2, продолжениеlog4j
Это все по сути реализации логеров в Java, ну а мы бы не писали на Java, если бы не попытались сделать нечто объединяющее, чтобы иметь возможность подменять реализации, не изменяя свой код. Некоторый адаптер.
И поэтому появились еще две библиотеки:
Apache Commons Logging—JCLSimple Logging Facade for Java—SLF4J
Apache log4j
Это самая первая библиотека логирования, появилась еще в 1999 году.
Конфигурируется через xml, либо через properties.
Поддерживает большое количество способов вывода логов: от консоли и файла до записи в БД.
Также имеет поддержку обширного формата логирования: от обычного текстового вывода до html.
Именно он ввел понятие appender — кто пишет в лог, layout — форматирование.
В конфигурации задаются эти самые appender-ы и какого уровня сообщения попадают к какому appender-у.
Ввел соответствие иерархичности категорий и пакетов: например, можно логгировать все сообщения из org.hibernate и заглушить всё из org.hibernate.type.
Благодаря подобной иерархии лишнее отсекается и поэтому логер работает быстро.

Проект сейчас не развивается и по сути заброшен, с версией Java 9 уже не совместим.
Поэтому на данный момент рекомендуется использовать log4j2, о котором речь пойдет ниже.
Вклад
log4jв мир логирования настолько велик, что многие идеи были взяты в библиотеки логирования для других языков.
JUL
Зачем нужно было изобретать что-то новое, если уже был log4j мне лично не понятно, однако в рамках формирования JSR 47 взяли не log4j, так появился JUL.
Логер включен в стандарт(в рамках JSR 47) и поставляется вместе с JDK. JUL имеет следующие уровни логгирования по возрастанию: FINEST, FINER, FINE, CONFIG, INFO, WARNING, SEVERE, а так же ALL и OFF, включающий и отключающий все уровни соответственно.
Вот эти все FINEST, FINER, FINE — это три уровня логирования для отладочных сообщений, три, Карл!

Чувствуете насколько все переосложнено?
JUL очень похож на log4j, но предоставляет гораздо меньше возможностей.
Так как стандартных средств форматирования логов недостаточно, то все сводилось к тому, что писались свои. Это при том, что log4j предоставлял больший функционал, работал как минимум не медленнее и в целом себя чувствовал хорошо.
Настраивается только с помощью properties.
И вот мы уже имеем два логгера, одни библиотеки использовали log4j, другие jul и это было начало хаоса.
Именно это послужило толчком к созданию Apache Commons Logging или JCL.
JCL
Как уже было сказано, JCL — это обертка над log4j и JUL.
Уровни логгирования у JCL совпадают с log4j, а в случае взаимодействия с JUL происходит следующее сопоставление:
| JCL | JUL |
|---|---|
| ALL | Все сообщения |
| TRACE | Level.FINEST |
| DEBUG | Level.FINE |
| INFO | Level.INFO |
| WARN | Level.WARNING |
| ERROR | Level.SEVERE |
| FATAL | Level.SEVERE |
| OFF | Без сообщения |
Конфигурация JCL содержит отдельные блоки для log4j, JUL и собственной реализации.
Внутри себя она часто использует reflection, поэтому проседает по производительности и утяжеляет приложение.
JCL на данный момент почти никогда не встречается в новых проектах, это довольно старая библиотека, которая встречается разве что в старых legacy-проектах.
С уверенностю можно сказать сейчас, что в эту сторону даже смотреть не стоит. Пациент мертв.
Разработчик
JCLдаже как-то высказался в духе: Commons Logging was my fault.
| Лицензия | Apache License Version 2.0 |
| Последняя версия | 1.2 |
| Дата выпуска последней версии | июль 2014 |
Apache log4j2
Какое-то время все так и существовало, но по мере попытки усидеть на двух стульях происходит раскол и создание log4j2 — на новых идеях, использующая все модные фишки.
При этом она оказывается полностью несовместима с log4j.
Но добавили много нового, парочка из них:
- Система плагинов, которая позволяет добавить новые
appender-ы,layout-ы и т.д - Улучшения производительности.
- Появилась поддержка конфигруаций через
jsonиyaml. - Поддержка
jmx.
Полный список тут.
Правда перестали поддерживать properties конфигурации и конфигурации от log4j на xml надо было переписывать заново.
На данный момент рекомендуется использовать именно log4j2. Однако надо помнить, что Log4j 2 работает только с Java 6+.
| Лицензия | Apache License Version 2.0 |
| Последняя версия | 2.11.2 |
| Дата выпуска последней версии | февраль 2019 |
SLF4J
Появление нового логера и проблемы JCL послужили появлению slf4j — еще одной обертке.
Помимо того, что она не имеет проблем с производительностью, как у JCL, является оберткой над всеми известными логерами типа logback, log4j, jul и т.д, она предоставляет еще параметризованные сообщения:
log.debug("User {} connected from {}", user, request.getRemoteAddr());
При этом преобразование параметров в строку и окончательное форматирование лог-записи происходит только при установленном уровне DEBUG.
| Лицензия | MIT License |
| Последняя версия | 2.0.0-alpha0 |
| Дата выпуска последней версии | июнь 2019 |
Logback
logback был сделан разработчиком log4j, поэтому многие фишки перекочевали сразу, а учитывая, что разрабатывался он позже, то старческие болячки log4j обошли.
При этом, logback не является частью Apache или еще какой-то компании и независим.
Может быть сконфигурирован через xml и groovy.
Для logback:
| Лицензия | EPL/LGPL 2.1 |
| Последняя версия | 1.3.0-alpha4 |
| Дата выпуска последней версии | февраль 2018 |
На данный момент это самый мощный логер по количеству предоставляемых возможностей ‘из коробки’. Однако, из-за некоторой его обособленности и сложной лицензии многие опасаются его использования и предпочитают log4j или log4j2.
В данный момент все чаще встречаются проекты, которые выбрали связку SLF4J + Logback.
При этом в версии
1.2.3стоит явное ограничение на количество файлов, с которым умеет работать логер при ротировании — это трехзначное число, в поздней версии это ограничение убрали.
Что выбрать
Сейчас я бы выбрал связку SLF4J и logback, так как при необходимости вы сможете переключиться с logback на другую реализацию логера. При этом logback обладает всеми преимуществами slf4j, но без старых болячек и с дополнительными плюшками.
Из минусов logback — это лицензия(LGPL/EPL) и то, что он независимый. Т.е он не принадлежит ни Apache, ни каким-то еще компаниям, а это для некоторых может стать серьезным минусом.
Если минусы для вас существенны, то я бы выбирал log4j2 или log4j.
В случае, если ваш проект мал и прост, при этом вы не разрабатываете библиотеку, а пишите именно законченный, маленький продукт и логирование вам не слишком важно — можно взять и jul.
Разбираем SLF4J
Так как из адаптеров это по сути единственный выбор, да и встречается slf4j все чаще, то стоит рассмотреть его устройство.
Вся обертка делится на две части — API, который используется приложениями, и реализация логера, которая представлена отдельными jar-файлами для каждого вида логирования. Такие реализиации для slf4j называются binding. Например, slf4j-log4j12 или logback-classic.
Достаточно только положить в CLASSPATH нужный binding, после чего — опа! весь код проекта и все используемые библиотеки (при условии, что они обращаются к SLF4J) будут логировать в нужном направлении.
Вопрос:
А что будет, если в CLASSPATH окажется несколько binding-ов?
Ответ:
SLF4J найдет все доступные binding-и и напишет об этом, после чего выберет какой-то и тоже об этом напишет.
Вот пример поведения slf4j, когда в CLASSPATH оказалось два binding: logback и slf4j-log4j12:
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:.gradle/caches/modules-2/files-2.1/ch.qos.logback/logback-classic/1.2.3/7c4f3c474fb2c041d8028740440937705ebb473a/logback-classic-1.2.3.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:.gradle/caches/modules-2/files-2.1/org.slf4j/slf4j-log4j12/1.7.26/12f5c685b71c3027fd28bcf90528ec4ec74bf818/slf4j-log4j12-1.7.26.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [ch.qos.logback.classic.util.ContextSelectorStaticBinder]
Что делать при такой ситуации. Если коротко, то надо просто вычистить из CLASSPATH-а все ненужные binding-и и оставить только один.
Т.е вы строите дерево зависимостей проекта, после чего методично вырезаем все, что нам не нужно в CLASSPATH-е.
Вроде все проблемы решены, пусть и такими радикальными способоами.
Но это еще не все.

Проблема
В идеальном мире все должны выводить сообщения через интерфейс обертки, и тогда у нас все будет хорошо, но реальный мир диктует свои правила и приходится взаимодействовать со сторонними библиотеками, которые используют другие логгеры и которые ничего знать не знают о slf4j.
Например, Spring использует адаптер jcl.
И вот в такой ситуации, чтобы все работало с slf4j используют так называемые bridge-ы.
Что такое bridge? Это jar-ник, который кладется в CLASSPATH вместо настоящей библиотеки логирования, в этом jar-нике все классы, которые существуют в настойщей библиотеке логирования, но они просто делегируют все события логирования в slf4j.
Например, jcl-over-slf4j.jar, log4j-over-slf4j.jar или jul-to-slf4j.jar, которые переопределяют поведение соответствующих логгеров и перенаправляют сообщения в slf4j.
Таким образом, чтобы работать со Spring получается надо сделать CLASSPATH подобным образом:
compile "org.slf4j:jcl-over-slf4j:$slf4_version" exclude group: "commons-logging", module: "commons-logging"
Т.е исключить из CLASSPATH уже не нужный нам jcl, после чего добавить bridge, чтобы он перенаправлял все события логирования Spring в slf4j.
Подробнее об этом.
Проблемы bridge-а:
-
Если конфигурация сделана программно, то
bridgeне будет работать. -
В
CLASSPATHможет оказаться иbinding, иbridgeна один и тот же логгер. В этом случае они начнут бесконечно перекидывать друг другу сообщения логирования, пока не свалятся наStackOverflowError.Например,
log4j-over-slf4j.jarиslf4j-log4j12в одномCLASSPATHприведут кStackOverflowError. -
Проблема с
JUL.Если вы внимательно читали то, что мы говорили про
bridge, то уже поняли в чем дело:bridgeпо сути подменяет классы, а подменить классыjdk— нельзя.Поэтому
bridgeдляjdkлогера работает иначе — устанавливается специальный обработчик наrootлогер, который заворачивает события вslf4j.И все бы ничего, но такой обработчик заворачивает все события от
jul, даже те, для которых не указаныappender-ы. Отсюда мы получаем большойoverheadи проседает производительность.

Заключение
Проблема логирования в Java стоит остро до сих пор. В том, что появилась такая проблема как многообразие логеров и отсутствие какого-то внятного стандарта виноваты все, в том числе и, на мой взгляд, какие-то политические моменты, как например с JSR 47.
Бесконтрольно подтягиваемые транзитивные зависимости библиотек, которые вы используете в своем проекте, рано или поздно принесут какие-то свои библиотеки логирования, отчего могут открыться врата прямиком в ад.
Поэтому следите за CLASSPATH, смотрите что вы используете и не разводите log-зоопарк.
Если говорить о выборе, то я бы выбрал связку SLF4J и logback, так как при необходимости вы сможете переключиться с logback на другую реализацию логера. При этом logback довольно мощная библиотека, предоставляющая большое количество возможностей и layout-ов.
При этом, если вы разрабатываете библиотеку, то:
- Не используейте
jul. - Задумайтесь о том, что нужна ли библиотека логирования, которую вы используете, другим людям как транзитивная зависимость вашей библиотеки?
Очень важно также не забывать о том, что такое логирование и для чего оно нужно.
Поэтому нельзя скатываться в бесмысленные записи в лог, вывод личных данных и так далее.
Думайте о том что вы пишите в лог!
Полезные ссылки
- Java Logging: история кошмара
- Владимир Красильщик — Что надо знать о логировании прагматичному Java-программисту
- Ведение лога приложения
- Java logging. Hello World
Этот материал мы ориентировали на тех, кто в первый раз сталкивается с логированием серверных служб и web-серверов. Познакомим с уровнями логирования, расскажем об основных типах логов и перечислим инструменты для работы с ними.
Зачем оно вообще нужно, это логирование?
На анализе логов базируется работа большинства ИТ-специалистов. Администраторы ищут в файлах логирования причины сбоя сервиса. Разработчики опираются на логи, чтобы локализовать и устранить ошибки приложения или веб-сайта. Служба безопасности по логам, как по физическим уликам, определяет вид взлома, оценивает нанесенный ущерб и даже может идентифицировать взломщика. Вот почему логирование мы рекомендуем отладить в первую очередь: в любой непонятной ситуации ответ на вопрос вы будете искать в логах!

Файлы логирования
Уровни логирования
В идеале логи пишутся во время работы всех IT-систем, однако если писать все подряд и «складывать в кучу», полезная информация превратится в хаос. Чтобы упростить поиск и чтение логов, их делят на уровни. Основных четыре:
-
Debug — запись масштабных переходов состояний, например, обращение к базе данных, старт/пауза сервиса, успешная обработка записи и пр.
-
Warning — нештатная ситуация, потенциальная проблема, может быть странный формат запроса или некорректный параметр вызова.
-
Error — типичная ошибка.
-
Fatal — тотальный сбой работоспособности, когда нет доступа к базе данных или сети, сервису не хватает места на жестком диске.
Дополнительно файл логирования может расширяться записями еще двух уровней:
-
Trace — пошаговые записи процесса. Полезен, когда сложно локализовать ошибку.
-
Info — общая информация о работе службы или сервиса.
Работа с уровнями логирования регламентируется методическими документами и внутренними правилами организации. В них может определяться соответствие источника сообщения уровню логирования, значимость, порядок обработки каждого уровня и другие параметры.
Типы логов
Для удобства обработки логов их делят на типы:
-
системные, связанные с системными событиями,
-
серверные, отвечающие за процесс обращения к серверу,
-
почтовые, работающие с отправлениями,
-
логи баз данных, которые отражают процессы обращения к базам данных,
-
авторизационные и аутентификационные, которые отвечают за процесс входа, выхода из системы, восстановление доступа и пр.
У каждого типа логов свой журнал записи. Для проверки логов авторизации нужно идти в журнал доступов, чтобы проверить загрузку системы — в журнал dmesg, за данными о запросах пользователей — в access_log. Когда одни логи пишутся отдельно от других, проще диагностировать ситуацию и найти источник проблемы.

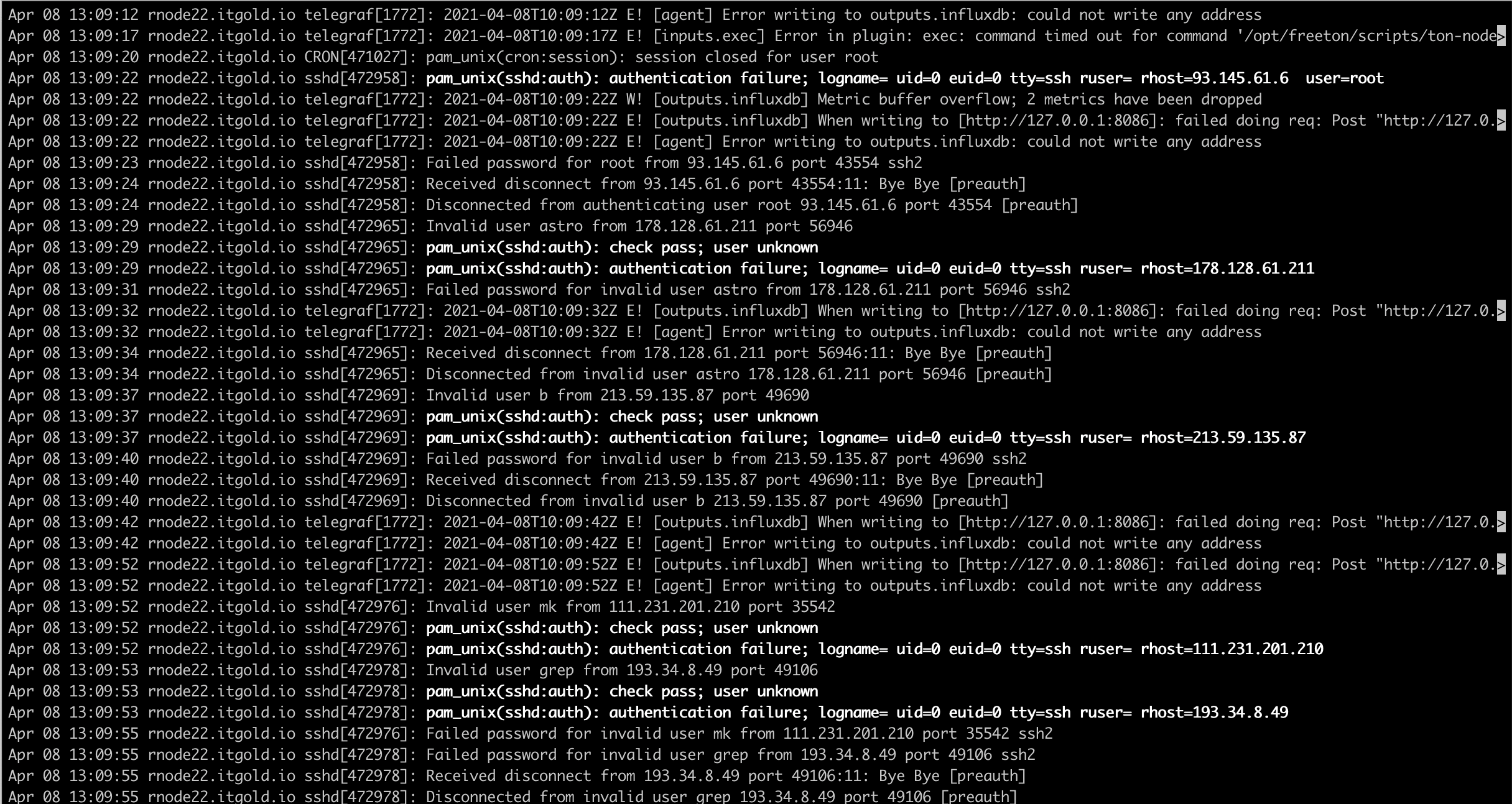
Логи в access_log
Инструменты для работы с логами
Сбор, хранение и анализ логов вручную хороши, когда у вас один сервер. Когда серверный парк разрастается, а приложений и сервисов становится больше десяти, работу с логами целесообразно автоматизировать и использовать специальные системы логирования, например, Graylog, ELK, Loggy или Splunk. Некоторые из них позволяют организовать полномасштабный мониторинг, настроить алерт раннего обнаружения конкретной проблемы или установить пороговые значения показателей, коррелирующих с угрозами информационной безопасности.
Логи сетевого, инженерного оборудования, баз данных и приложений мы храним в облачном хранилище. И вам советуем. Даже когда у вас полно места на жестких дисках и стоит мощная защита на все случаи жизни. Оборудование рано или поздно, а чаще неожиданно, выходит из строя, а злоумышленники давно умеют чистить файлы логирования, так что логи в облаке — это возможность восстановить события и расследовать инцидент даже при полном отказе системы.

Хранение логов в облаке
Логирование кажется второстепенным процессом, который занимает время, но не дает видимых результатов. Однако это только кажется и только до тех пор, пока не появится реальная проблема, с которой можно разобраться только по логам. И только если они записаны, распределены по уровням, собираются и доступны для анализа.