|
0 / 0 / 0 Регистрация: 15.03.2019 Сообщений: 11 |
|
|
1 |
|
Перекодирование имени файла15.03.2019, 07:34. Показов 5919. Ответов 26
Столкнулся с такой проблемой, бьюсь уже почти сутки, но решения найти не могу…. Без предистории) Имею 13 000 важных файлов у которых в именах (только в именах), слетела кодировка и теперь какая-то белеберда. вручную переименовать — ну это просто не реально, возможно ли как-то сделать это батником? Взять имя файла-перекодировать-присвоить полученное имя файлу. Естественно куча папок и файлов в них, и все файлы разные. В какой кодировке имя сейчас в принципе известно, если это конечно имеет значение…
__________________
0 |

|
5718 / 1693 / 292 Регистрация: 10.12.2013 Сообщений: 5,959 |
|
|
15.03.2019, 08:19 |
2 |
|
В какой кодировке имя сейчас в принципе известно, если это конечно имеет значение Ну какое это может иметь значение, значительнее важнее твои воспоминания о том, что кто-то сделал кучу Ещё очень важно ни под каким видом не показывать никому имена, которые требуется восстановить ( даже если будут очень просить), лучше всего мягко уводить беседу в сторону и рассказывать о круглосуточной борьбе.
0 |

|
YuS_2 Любознательный 3228 / 866 / 233 Регистрация: 10.03.2016 Сообщений: 2,043 |
||||
|
15.03.2019, 08:37 |
3 |
|||
|
Естественно куча папок и файлов в них, и все файлы разные. В какой кодировке имя сейчас в принципе известно, если это конечно имеет значение… Если бы были приведены, хотя бы примеры нескольких названий и заодно кодировка, то,возможно и решение было бы.
0 |
")
|
0 / 0 / 0 Регистрация: 15.03.2019 Сообщений: 11 |
|
|
15.03.2019, 09:21 [ТС] |
4 |
|
Извиняюсь за неточность вопроса… вот уточнения (сами файлы выложить не могу) … и опять-же, внутри файлов всё в порядке, только имена файлов сбились. Миниатюры
0 |
|
5718 / 1693 / 292 Регистрация: 10.12.2013 Сообщений: 5,959 |
|
|
15.03.2019, 09:39 |
5 |
|
Больше похоже, что это UTF-8 приведённый к Windows-1252. Добавлено через 1 минуту
0 |
|
0 / 0 / 0 Регистрация: 15.03.2019 Сообщений: 11 |
|
|
15.03.2019, 09:46 [ТС] |
6 |
|
декодер говорит вот что… Миниатюры
0 |
|
5296 / 2485 / 988 Регистрация: 06.06.2017 Сообщений: 8,519 |
|
|
15.03.2019, 10:07 |
7 |
|
Karamba2233, приведите имена текстом, а скриншотом.
0 |
|
5718 / 1693 / 292 Регистрация: 10.12.2013 Сообщений: 5,959 |
|
|
15.03.2019, 10:10 |
8 |
|
Как я его научил, так он и сделал — Молодец. Уважаю.
0 |
|
0 / 0 / 0 Регистрация: 15.03.2019 Сообщений: 11 |
|
|
15.03.2019, 10:27 [ТС] |
9 |
|
Исходный-закодированный Полученный-раскодированный ну и естественно расширение .doc
0 |
|
YuS_2 Любознательный 3228 / 866 / 233 Регистрация: 10.03.2016 Сообщений: 2,043 |
||||
|
15.03.2019, 10:30 |
10 |
|||
|
ТеориÑ-прапорщики и женщины
Сам конвертер, работает так: Код PS_5.1> "ТеориÑ^Ï-прапорщики и женщины"|convert utf-8 windows-1252 Теория-прапорщики и женщины
1 |
|
0 / 0 / 0 Регистрация: 15.03.2019 Сообщений: 11 |
|
|
15.03.2019, 11:35 [ТС] |
11 |
|
т.е. я могу брать смело этот код, в батник, кидать этот .bat в каталог с файлами и пусть переименовывает?
0 |
|
1882 / 1106 / 426 Регистрация: 22.01.2016 Сообщений: 3,050 |
|
|
15.03.2019, 11:59 |
12 |
|
т.е. я могу брать смело этот код, в батник, кидать этот .bat в каталог с файлами и пусть переименовывает? Вам ответят — да, вы запустите этот не батник и по какой-то причине, безвозвратно потеряете имена «13 000 важных файлов» Разумный человек, во первых, предварительно самостоятельно проверит предложенный вариант, например, на тестовом каталоге (с копией нескольких файлов). А во вторых, перед изменением важных данных, не забудет и про резервное копирование…
4 |
|
YuS_2 Любознательный 3228 / 866 / 233 Регистрация: 10.03.2016 Сообщений: 2,043 |
||||
|
15.03.2019, 12:52 |
13 |
|||
|
могу брать смело этот код, в батник, кидать этот .bat в каталог с файлами и пусть переименовывает? Нет. Там ведь подписан код
Предварительно, в скрипте powershell укажите необходимый каталог, там где есть комментарий «корневой каталог» и потом уже запускайте батник.
0 |
|
FlasherX 5296 / 2485 / 988 Регистрация: 06.06.2017 Сообщений: 8,519 |
||||
|
15.03.2019, 14:06 |
14 |
|||
|
кидать этот .VBS в каталог с файлами и пусть переименовывает?
1 |
|
0 / 0 / 0 Регистрация: 15.03.2019 Сообщений: 11 |
|
|
16.03.2019, 08:45 [ТС] |
15 |
|
Сам конвертер, работает так: Почему-то выдает ошибку… типа не может найти параметр для file… Миниатюры
0 |
|
5296 / 2485 / 988 Регистрация: 06.06.2017 Сообщений: 8,519 |
|
|
16.03.2019, 10:07 |
16 |
|
Karamba2233, мой вариант без танцев с бубном не судьба использовать? Кодировка сохранения script.vbs — ANSI.
0 |
|
0 / 0 / 0 Регистрация: 15.03.2019 Сообщений: 11 |
|
|
16.03.2019, 10:31 [ТС] |
17 |
|
без танцев с бубном Почему-то тоже ругается, только на то что файл уже существует.. Если я правильно в коде разобрался, то нужно где-то дописать или чтобы замена файла происходила, или чтобы файл копировался куда-то в другое место…
0 |
|
5296 / 2485 / 988 Регистрация: 06.06.2017 Сообщений: 8,519 |
|
|
16.03.2019, 10:36 |
18 |
|
А, ну, конечно. Он же сам себя не переименует, т.к. смена кодировки латиницу не изменит. Добавьте спереди любую букву кириллицы.
0 |
|
0 / 0 / 0 Регистрация: 15.03.2019 Сообщений: 11 |
|
|
16.03.2019, 10:44 [ТС] |
19 |
|
А можно уточнить — где именно добавить? )
0 |
|
FlasherX 5296 / 2485 / 988 Регистрация: 06.06.2017 Сообщений: 8,519 |
||||
|
16.03.2019, 11:11 |
20 |
|||
|
Убрал проблему совпадений (имя скрипта — любое):
Кое-что дополнил.
0 |
Материал из Кафедра ИУ5 МГТУ им. Н.Э.Баумана — студенческое сообщество
В статье рассказывается о том, как упаковывать файлы в ZIP-архив с кодировкой имён в UTF-8.
Содержание
- 1 Описание проблемы
- 2 Почему так
- 3 Что делать
- 3.1 Как это автоматизировать
Описание проблемы
Иногда при открытии архивов ZIP в именах файлов написаны иероглифы. В основном, это случается при работе с архивами, упакованными в среде Windows, в других операционных системах, например Linux и Mac OS.
Вот как это выглядит:
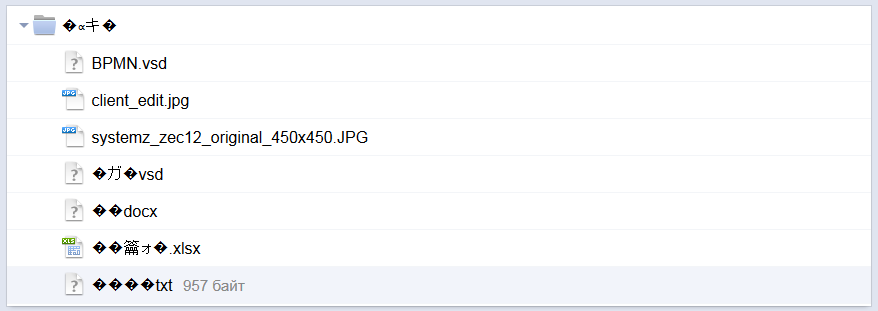
Почему так
Такое получается из-за разных кодировок в разных операционных системах. А точнее из-за того, что Windows до сих пор использует свою WIN1251, когда давно уже существует UTF-8, созданная специально во избежание подобных проблем. ZIP, хоть и являясь старейшим и распространённейшим форматом архивов, испытывает проблемы с этим при переносе архива с платформы на платформу.
Не имеет значения, какую программу-архиватор вы используете — причина именно в самом формате ZIP. Для проверки мы упаковали тестовый архив с настройками по умолчанию сначала архиватором WinRAR, затем — архиватором 7-Zip. После чего просмотрели архивы в среде Mac OS — в обоих архивах кириллические имена файлов превратились в набор кракозябр.
Ну так может тогда не стоит использовать формат ZIP и паковать всё, например, в 7z? В общем-то, это хорошая идея, но дело в том (и это единственная причина), что ZIP, как уже говорилось, является наиболее распространённым форматом архивов, потому чтобы большинство ваших пользователей смогло распаковать ваш архив, использовать рекомендуется именно его.
Что делать
Нужно как-то принудительно указать архиватору, что при кодировке имён файлов он должен использовать UTF-8.
И у архиватора 7-Zip есть такая возможность. Формат команды следующий:
7z.exe a -tzip -mcu archname.zip file2pack.txt
Здесь:
-
7z.exe— имя исполняемого файла архиватора; -
a— команда архивации; -
-tzip— формат архива: ZIP; -
-mcu— именно эти ключи указывают на кодировку UTF-8; -
archname.zip— имя итогового файла архива; -
file2pack.txt— файлы для упаковки.
После создание архива такой командой кириллица в именах файлов сохраняется на всех платформах, использующих UTF-8 (то есть, практически везде):
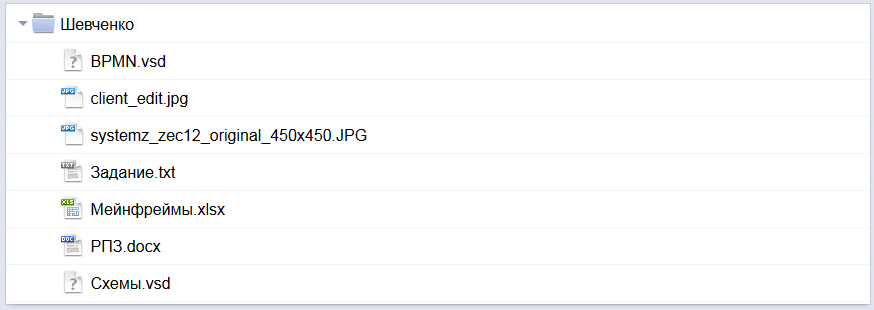
Очередная медаль на грудь славного архиватора 7-Zip.
Как это автоматизировать
Понятное дело, что каждый раз лезть в командную строку и писать там команду архивации с необходимыми ключами очень сильно обламывает, ведь хочется, чтобы всё выполнялось в два клика мышью.
Как вариант, можно написать свою оболочку для 7z.exe или просто создать .bat-файл.
А можно воспользоваться приложением Open++ и добавить нужный пункт в контекстное меню Windows.
Вычислительная
система кафедры перешла на использование многобайтовой кодировки UTF-8
для файловых систем и пользовательского окружения вместо однобайтовой
кодировки KOI8-R. В данной инструкции рассматриваются типичные
проблемы, которые могли возникнуть у пользователей в связи с данным
переходом и предлагаются способы их решения (изменения настроек,
команды и т.п.).
Основные понятия
Юнико́д, или Унико́д (англ. Unicode™) — стандарт кодирования
символов, позволяющий представить знаки практически всех письменных
языков.
UTF-8 (от англ. Unicode Transformation Format — формат
преобразования Юникода) — кодировка, реализующая представление Юникода,
совместимое с 8-битным кодированием текста.
Важно понимать, что один символ в кодировке UTF-8 может быть
представлен более чем одним байтом. С этим связано, например, то, что
файл, содержащий текст в кодировке UTF-8 будет иметь больший размер по
сравнению с файлом, содержащим тот-же текст в кодировке KOI8-R.
Пример: команда wc имеет ключ -c для подсчета байтов и ключ -m для подсчета символов.
$ echo -n "Слово." | wc -c 11 $ echo -n "Слово." | wc -m 6
Имена файлов
Имена файлов были перекодированы автоматически с помощью утилиты convmv:
convmv -r -f koi8-r -t utf-8 --notest <каталог>
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
convmv -r -f utf-8 -t koi8-r <файлы и каталоги>
После проверки вывода команды повторить с ключем —notest. Ключ -r включает рекурсивный обход каталогов.
Содержимое файлов
Для того, чтобы преобразовать содержимое файлов из кодировки KOI8-R в кодировку UTF-8 можно воспользоваться командой:
recode koi8-r..utf-8 <filename>
Для потокового перекодирования используется команда:
iconv -f koi8-r <filename>
Редактор Emacs может автоматически распознать кодировку текста при
открытии файла. Принудительно задать кодировку открытия или сохранения
файла в редакторе Emacs можно следующим образом:
- Ввести комбинацию клавиш
C-x RET c. - Внизу экрана будет запрошена кодировка, которую вы хотите применить для следующей команды.
- Введите команду, которая будет выполнена с применением введенной на предыдущем шаге кодировки, например:
- комбинацию клавиш для открытия файла:
C-x C-f; - комбинацию клавиш для сохранения файла:
C-x C-s.
- комбинацию клавиш для открытия файла:
Приложения
Текстовый терминал из Windows
Для корректного отображения русского текста при входе на серверы
кафедры с помощью терминального клиента PuTTY нужно указать в
настройках:
- Раздел Window/Translation
- Character set translation on recieved data: UTF-8
Текстовый терминал из Linux
Если системная локаль не UTF-8, то необходимо запустить X-терминал с поддержкой UTF-8 и выполнить вход по ssh из него.
Если системная локаль UTF-8, то никаких дополнительных действий предпринимать не надо.
Если по какой-то причине при входе по ssh не установились правильно переменные окружения локали (вывод команды locale не содержит строки LANG=ru_RU.UTF-8), то необходимо выполнить команду:
export LANG=ru_RU.UTF-8
WinSCP
Для корректного отображения русских имен файлов:
- Раздел Environment
- UTF-8 encoding for filenames: On
TEX
- После выполнения перекодировки содержимого tex-файла (см. Содержимое файлов) необходимо сменить кодировку в преамбуле:
Было:
usepackage[koi8-r]{inputenc}
Стало:
usepackage[utf8x]{inputenc}
- Также необходимо подключить пакет ucs:
usepackage{ucs}
- Для установки диакритических знаков (ударений) нужно использовать полную форму стандартной записи ‘, т.е.:
Б'{о}льшую
Bibtex
Bib-файлы, содержащие описание литературы, хранятся в кодировке KOI8-R. После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Блокнот Windows
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню «Файл – Сохранить как».

В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку «Сохранить».

К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню «Кодировки – Кириллица» и выбрать нужный вариант.

После открытия текста можно изменить его кодировку. Для этого нужно открыть меню «Кодировки» и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.

После преобразования файл нужно сохранить с помощью меню «Файл – Сохранить» или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню «Файл – Открыть».

В открывшемся окне нужно выделить текстовый файл, снять отметку «Автовыбор» и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.

Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню «Файл – Сохранить как» и сохранить документ с указанием новой схемы кодирования.

В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
Посмотрите также:
- Чем открыть PDF файл в Windows 7 или Windows 10
- Как перевернуть страницу в Word
- Как копировать текст с помощью клавиатуры
- Как сделать рамку в Word
- Как сделать буклет в Word
Автор
Александр Степушин
Создатель сайта comp-security.net, автор более 2000 статей о ремонте компьютеров, работе с программами, настройке операционных систем.
Остались вопросы?
Задайте вопрос в комментариях под статьей или на странице
«Задать вопрос»
и вы обязательно получите ответ.
Your incorrect files appear to be double-UTF-8 encoded.
For instance, the ä U+00E4 has been encoded as:
- U+00E4 -> 0xc3 0xa4 (UTF-8 encoding)
- 0xc3 -> 0xc3 0x83 (iso8859-1
Ã-> UTF-8), 0xa4 -> 0xc3 0xa4 (iso8859-1¤-> UTF-8) where each byte of the UTF-8 encoding of U+00E4 has been interpreted as if they were the encoding of some other character in a single-byte charset (here likely iso8859-1 or windows-1252) and encoded again in UTF-8.
So you’re right to use convmv -f utf8 -t iso-8859-1 for that. To leave the files that are not double-encoded alone, convmv has a special option for that: --fixdouble, so it should just be:
convmv --fixdouble -f utf8 -t iso-8859-1 -r --notest .
There’s a section dedicated to that in convmv‘s manual:
How to undo double UTF-8 (or other) encoded filenames
Sometimes it might happen that you «double-encoded» certain filenames, for example the file names already were UTF-8 encoded and you
accidentally did another conversion from some charset to UTF-8. You can simply undo that by converting that the other way round. The
from-charset has to be UTF-8 and the to-charset has to be the from-charset you previously accidentlly used. If you use the
«—fixdouble» option convmv will make sure that only files will be processed that will still be UTF-8 encoded after conversion and it
will leave non-UTF-8 files untouched. You should check to get the correct results by doing the conversion without «—notest» before,
also the «—qfrom» option might be helpful, because the double utf-8 file names might screw up your terminal if they are being printed —
they often contain control sequences which do funny things with your terminal window. If you are not sure about the charset which was
accidentally converted from, using «—qfrom» is a good way to fiddle out the required encoding without destroying the file names finally.
Files that are double-UTF-encoded via iso8859-1 (which covers code points U+0000 U+00FF) will contain sequences of non-ASCII characters consisting of one character in the the U+00C2 -> U+00F4 range (ÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóô) followed by one or more characters in the U+0080 -> U+00BF range (U+0080 to U+009F being control character plus non-breaking space plus ¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿). Those sequences are relatively unlikely to occur in non-double-encoded text, especially considering that characters above U+00E0 (the lower case ones in the first set above) have to be followed by at least 2 characters in the second set, so convmv --fixdouble is unlikely to get it wrong.
Your incorrect files appear to be double-UTF-8 encoded.
For instance, the ä U+00E4 has been encoded as:
- U+00E4 -> 0xc3 0xa4 (UTF-8 encoding)
- 0xc3 -> 0xc3 0x83 (iso8859-1
Ã-> UTF-8), 0xa4 -> 0xc3 0xa4 (iso8859-1¤-> UTF-8) where each byte of the UTF-8 encoding of U+00E4 has been interpreted as if they were the encoding of some other character in a single-byte charset (here likely iso8859-1 or windows-1252) and encoded again in UTF-8.
So you’re right to use convmv -f utf8 -t iso-8859-1 for that. To leave the files that are not double-encoded alone, convmv has a special option for that: --fixdouble, so it should just be:
convmv --fixdouble -f utf8 -t iso-8859-1 -r --notest .
There’s a section dedicated to that in convmv‘s manual:
How to undo double UTF-8 (or other) encoded filenames
Sometimes it might happen that you «double-encoded» certain filenames, for example the file names already were UTF-8 encoded and you
accidentally did another conversion from some charset to UTF-8. You can simply undo that by converting that the other way round. The
from-charset has to be UTF-8 and the to-charset has to be the from-charset you previously accidentlly used. If you use the
«—fixdouble» option convmv will make sure that only files will be processed that will still be UTF-8 encoded after conversion and it
will leave non-UTF-8 files untouched. You should check to get the correct results by doing the conversion without «—notest» before,
also the «—qfrom» option might be helpful, because the double utf-8 file names might screw up your terminal if they are being printed —
they often contain control sequences which do funny things with your terminal window. If you are not sure about the charset which was
accidentally converted from, using «—qfrom» is a good way to fiddle out the required encoding without destroying the file names finally.
Files that are double-UTF-encoded via iso8859-1 (which covers code points U+0000 U+00FF) will contain sequences of non-ASCII characters consisting of one character in the the U+00C2 -> U+00F4 range (ÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóô) followed by one or more characters in the U+0080 -> U+00BF range (U+0080 to U+009F being control character plus non-breaking space plus ¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿). Those sequences are relatively unlikely to occur in non-double-encoded text, especially considering that characters above U+00E0 (the lower case ones in the first set above) have to be followed by at least 2 characters in the second set, so convmv --fixdouble is unlikely to get it wrong.
- Печать
Страницы: [1] Вниз

Тема: Смена кодировок имен файлов и папок (Прочитано 5425 раз)
0 Пользователей и 1 Гость просматривают эту тему.

VelzeVul

Добрый день, возник вопрос, надеюсь на вашу помощь.
Есть сервак на нем proftpd версии 1,3,3а, нужно что бы все файла и папки падающие в определенную папку меняли кодировку имени на ср1251.
Для этого использую пакет convmv. Выглядит это так: В кронд поставлен на выполнение скрипт:
#! /bin/sh
#Конвертируем все файлы в папке
convmv -f utf-8 -t cp1251 -r -notest /home/test/test/* 2>&1 | tee -a mv.log
Но штука в том что если в папке есть файл уже в кодировке ср1251 то скрипт прекращает свое выполнение с ошибкой.
This file was not validly encoded in UTF-8: «/home/test/test/тест.rar»
To prevent damage to your files, we won’t continue.
First fix this or correct options!
Хотя по мимо него там есть еще файлы которые именно в utf-8, но стоит ему только «запнуться» как работа скрипта прекращается
Я не очень силен в написании скриптов, но нужно чтоб он находил файлы в кодировке utf8 и менял кодировку только у них, а остальные не трогал.
ArcFi
VelzeVul
find ... -exec ...?
Была такая мысль, но было бы хорошо если бы вы подсказали какой командой можно получить кодировку имени файла или папки и тогда уже if…then…
ArcFi
какой командой можно получить кодировку имени файла
Можно угадать с некоторой достоверностью через enca, но есть ли смысл…
И так само будет пропускать файлы, которые уже переименованы.
По хорошему, конечно, надо работать с utf8.
cp1251 — это унылое вендовое наследие.
alexander.pronin
По хорошему, конечно, надо работать с utf8.
cp1251 — это унылое вендовое наследие.
+1
VelzeVul
На счет enca пробовал, но почему-то выдает unrecognized encoding, хотя возможно я ей попросту не правильно пользуюсь, подскажите как ей получить кодировку имени? А на счет убогости ср1251 согласен, но большинство клиетов под «маздаем» и им не видно utf8 =)
ArcFi
$ touch 'привет, мир!'
$ convmv -f utf-8 -t cp1251 --notest *
Your Perl version has fleas #37757 #49830
mv "./привет, мир!" "./������, ���!"
Ready!
$ echo * | enca -L ru
MS-Windows code page 1251
LF line terminators
VelzeVul
Решил проблему так
find /home/test/test/* -exec convmv -f utf-8 -t cp1251 -r —notest {} ;
я понимаю это так find находит файлы в папке и для каждого в отдельности выполняет команду.
Может кому пригодится. 
Как закрыть тему?
« Последнее редактирование: 06 Декабря 2011, 09:48:34 от VelzeVul »
ArcFi
find /home/test/test/* -exec convmv -f utf-8 -t cp1251 -r —notest {} ;
Ключ -r избыточен, ибо find сам по себе рекурсивен.
VelzeVul
find /home/test/test/* -exec convmv -f utf-8 -t cp1251 -r —notest {} ;
Ключ -r избыточен, ибо find сам по себе рекурсивен.
-r используется для переименования имён каталогов.
« Последнее редактирование: 06 Декабря 2011, 10:00:20 от VelzeVul »
ArcFi
-r используется для переименования имён каталогов.
Нет. Можете проверить.
alexander.pronin
find /home/test/test/* -exec convmv -f utf-8 -t cp1251 -r —notest {} ;
я понимаю это так find находит файлы в папке и для каждого в отдельности выполняет команду.
Можно ограничить поиск только файлами (без директорий), например так
find /home/test/test -type f …
VelzeVul
find /home/test/test/* -exec convmv -f utf-8 -t cp1251 -r —notest {} ;
я понимаю это так find находит файлы в папке и для каждого в отдельности выполняет команду.Можно ограничить поиск только файлами (без директорий), например так
find /home/test/test -type f …
Да фишка в том, что как раз нужно, чтоб и каталоги тоже меняли кодировку, что сейчас и работает.
arcfi вы правы «-r» не играет роли, а так идея с find ваша, за что вам спасибо.
- Печать
Страницы: [1] Вверх