Содержание
- Detect local storage changes and show on page without reloading
- 4 Answers 4
- Check if localStorage is available
- 12 Answers 12
- Русские Блоги
- Когда git push превышает 100M ресурсов, он запрашивает удаленный: ошибка: GH001: обнаружены большие файлы. Ограничение размера файла GitHub 100M
- What causes the JNI error «use of deleted local reference»?
- 2 Answers 2
- Related
- Hot Network Questions
- Subscribe to RSS
- How to solve MySQL General error: 1030 Got error 139 from storage engine
- Why does this happens?
- 1. Verify if Barracuda format is available
- 2. Change file format to Barracuda
- 3. Change row format of the table to DYNAMIC
Detect local storage changes and show on page without reloading
I have an issue with angular,ionic 4 localstorage.When i save data on localstorage from one page ,and want to show the data to an other page,i need to reload the page to make it work.I thought about checking for localstorage changes in the page i want to show the data.Do you know how can i detect changes in localstorage in angular 7,ionic 4?

4 Answers 4
I think you should use rxjs stream to accomplish this.

To check if a value in the storage has changed you can add a listener to the event of the storage like this:

To remove you can use

You can have a service which takes care of setting and retrieving values to/from localStorage in property setters and getters.
Once the template is bound to properties, your respective components will be updated on change detections.
For example, this is your service with one property you want to set in localStorage.
And your components like:
Your view will be bound to the property which is ultimately getting its data from localStorage (through the service).
Источник
Check if localStorage is available
I know there has been many questions about checking for localStorage but what if someone manually shuts it off in their browser? Here’s the code I’m using to check:
Simple function and it works. But if I go into my Chrome settings and choose the option «Don’t Save Data» (I don’t remember exactly what it’s called), when I try to run this function I get nothing but Uncaught Error: SecurityError: DOM Exception 18 . So is there a way to check if the person has it turned off completely?
UPDATE: This is the second function I tried and I still get no response (alert).
12 Answers 12
Use modernizr ‘s approach:
It’s not as concise as other methods but that’s because it’s designed to maximise compatibility.
I’d check that localStorage is defined prior to any action that depends on it:
UPDATE:
If you need to validate that the feature is there and that it is also not turned off, you have to use a safer approach. To be perfectly safe:

Feature-detecting local storage is tricky. You need to actually reach into it. The reason for this is that Safari has chosen to offer a functional localStorage object when in private mode, but with it’s quotum set to zero. This means that although all simple feature detects will pass, any calls to localStorage.setItem will throw an exception.
Mozilla’s Developer Network entry on the Web Storage API’s has a dedicated section on feature detecting local storage. Here is the method recommended on that page:
And here is how you would use it:
If you are using NPM, you can grab storage-available using
then use the function like so:
Disclaimer: Both the documentation section on MDN and the NPM package were authored by me.
MDN updated the storage detect function. In 2018, it’s more reliable:
Browsers that support localStorage will have a property on the window object named localStorage. However, for various reasons, just asserting that property exists may throw exceptions. If it does exist, that is still no guarantee that localStorage is actually available, as various browsers offer settings that disable localStorage. So a browser may support localStorage, but not make it available to the scripts on the page. One example of that is Safari, which in Private Browsing mode gives us an empty localStorage object with a quota of zero, effectively making it unusable. However, we might still get a legitimate QuotaExceededError, which only means that we’ve used up all available storage space, but storage is actually available. Our feature detect should take these scenarios into account.
Источник
Русские Блоги
Когда git push превышает 100M ресурсов, он запрашивает удаленный: ошибка: GH001: обнаружены большие файлы. Ограничение размера файла GitHub 100M
1. Описание проблемы
При использовании ресурсов Git push, размер которых превышает 100M, push завершится сбоем, с запросом:

Согласно приведенному выше сообщению об ошибке, мы видим, что ресурс push превышает 100M, мы можем попробовать использоватьGit для хранения больших файлов(LFS)
PS:Git для хранения больших файлов(Git Large File Storage (LFS)) можно просто понимать как Git, в котором хранятся большие наборы текста, видео и данных. Ниже приводится определение официального сайта:
1. СкачатьGit-LFS, И установить. На следующем рисунке показан каталог после установки.

2. CMD входит в установленный каталог и выполняет git lfs install.

3. Выберите файлы, которые необходимо отправить в Git LFS.

4. Отслеживайте .gittattributes.

5. Следующие операции аналогичны операциям Git.
Источник
What causes the JNI error «use of deleted local reference»?
I have an Android app where the following C method is called when the app starts (in Activity.onCreate ).
When this method is called the app crashes and I get the error:
JNI DETECTED ERROR IN APPLICATION: use of deleted local reference 0xd280e8d5
Step debugging shows that this line causes the crash:
What causes this error? And how can I call System.getProperty(«os.name») using JNI without getting this error?

2 Answers 2
The issue is that env->CallStaticObjectMethod is expecting a jstring as its 3rd argument and is instead being supplied with a string literal.
Creating a jstring first
fixed the problem.
In my case, I was using a local reference that was created in a function and was used in another function. For example:
The above statement returns a local reference of jclass. Suppose we store this in a global variable and use it in another function funB after funA is completed, then this local reference will not be considered as valid and will return «use of deleted local reference error».
To resolve this we need to do this:
First, get the local reference and then get the global reference from local reference. globalClass can be used globally (in different functions).

Hot Network Questions
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.1.14.43159
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
How to solve MySQL General error: 1030 Got error 139 from storage engine

Carlos Delgado
Learn how to solve the MySQL General error: 1030 Got error 139 from storage engine.
You will face this kind of error random times, where an insert statement will fail, causing the fatal error 139. It happens normally in production, when the user inserts a lot of text in some field of a table (although the field may be of type LONGTEXT). Innodb triggers this error when it is unable to store all of the variable-length columns for a given row on a single database page.
In this article, we’ll show you how to bypass this limitation and explain you why this happens.
Why does this happens?
Innodb has a known limit for the maximum row size, which is slightly less than the half of a database page (the actual math is 16K — (page header + page trailer)/2. For the default page size of 16kb. this sets an
8000 bytes limit on row size. This limit is a consequence of InnoDB storing two rows on a page. If you’re using compression, however, you can store a single row on a page. If your row has variable length columns and the complete row size exceeds this limit, InnoDB chooses variable length columns for off-page storage.
It’s worth mentioning that this limit applies to the byte-size of values, not the character-size. This means if you insert a 500 character string with all multi-byte characters into a VARCHAR(500) column, that value will also be chosen for off page storage. This means it is possible that you hit this error after converting from a native language character set to utf8, as it can increase the size dramatically. For example, in case that you have a table with at least 8 columns with text (TEXT, LONGTEXT) and each exceeds 768 bytes, then you’ll have at least 8448 bytes for local storage. This exceeds the limit and therefore you will face the exception.
In short words, a lot of data that InnoDB is unable to store with the current configuration. The best solution for this problem is changing the default format of your MySQL installation from Compact or Redundant to Dynamic or Compressed.
You will face normally this exception on MySQL versions equal or lower than 5.5 (MySQL 5.7 introduces the option innodb_default_row_format , which defaults to DYNAMIC, so in newer versions you will never see this exception).
1. Verify if Barracuda format is available
The solution to this problem is to set the row format of the table where you have the problem to DYNAMIC, however this options is not available when the format of the table is set to Antelope. To verify if your MySQL server has the Barracuda format enabled, you can check for example with a tool like PHPMyAdmin the row format options of any table:
If you don’t see the DYNAMIC or COMPRESSED option, you need to change the innodb_file_format to barracuda following the step #2, which normally is set Antelope. If you don’t have a tool like PHPMyAdmin available, you can open the mysql terminal and get the information with the following command:
A mysql version with this problem should output something like:
As you can see, the file format is set to Antelope, which doesn’t support the dynamic row format.
2. Change file format to Barracuda
The first thing that you need to do is to locate the configuration file of Mysql ( my.cnf in unix or my.ini in windows) and add the new 2 options with the following values on the mysqld block:
If after adding these options, the mysql server is unable to start, then the format is not supported, which means that the solution to the problem isn’t neither. You will be forced to upgrade the MySQL server version to have the DYNAMIC and COMPACT row formats available.
Restart the mysql server and repeat the first step to see if the DYNAMIC and COMPACT row formats are available or running again the following instruction in the mysql terminal:
Which should output now:
Using the innodb_file_format with Barracuda as value, you will be able to use the required Dynamic row format on the table where you have this storage engine problem.
3. Change row format of the table to DYNAMIC
Now that you have the barracuda file format configured, simply change the table row format either with the tool in PHPMyAdmin (go to the table, then operations and search for Table options and change the row_format option):
Or if you can’t use a tool, with an instruction on the mysql command line:
After modifying the row format of the table, saving a row on the database with a lot of data shouldn’t be a problem anymore and you won’t see this exception neither.
Источник
Why did I receive a «No space left on device” or «DiskFull» error on Amazon RDS for PostgreSQL?
Last updated: 2022-06-23
I have a small Amazon Relational Database Service (Amazon RDS) for PostgreSQL database. The instance’s free storage space is decreasing, and I receive the following error:
«Error message: PG::DiskFull: ERROR: could not extend file «base/16394/5139755″: No space left on device. HINT: Check free disk space.»
I want to resolve the DiskFull errors and prevent storage issues.
Short description
- Temporary tables or files that are created by PostgreSQL transactions
- Data files
- Write ahead logs (WAL logs)
- Replication slots
- DB logs (error files) that are retained for too long
- Other DB or Linux files that support the consistent state of the RDS DB instance
Resolution
1. Use Amazon CloudWatch to monitor your DB storage space using the FreeStorageSpace metric. When you set a CloudWatch alarm for free storage space, you receive a notification when the space starts to decrease. If you receive an alarm, review the causes of storage issues mentioned previously.
2. If your DB instance is still consuming more storage than expected, check for the following:
- Size of the DB log files
- Presence of temporary files
- Constant increase in transaction logs disk usage
- Replication slot:
- Physical replication slots are created by cross-Region read replicas or same-Region read replicas only if they are running on PostgreSQL 14.1 and higher versions
- Logical replication slots are created for a replica or subscriber
- Bloat or improper removal of dead rows
- Presence of orphaned files
3. When your workload is predictable, enable storage autoscaling for your instance. With storage autoscaling enabled, when Amazon RDS detects that you are running out of free database space, your storage is automatically scaled. Amazon RDS starts a storage modification for an autoscaling-enabled DB instance when the following factors apply:
- Free available space is less than 10 percent of the allocated storage.
- The low-storage condition lasts at least five minutes.
- At least six hours have passed since the last storage modification, or storage optimization has completed on the instance, whichever is longer.
You can set a limit for autoscaling your DB instance by setting the maximum storage threshold. For more information, see Managing capacity automatically with Amazon RDS storage autoscaling.
Check the size of the DB log files
By default, Amazon RDS for PostgreSQL error log files have a retention value of 4,320 minutes (three days). Large log files can use more space because of higher workloads or excessive logging. You can change the retention period for system logs using the rds.log_retention_period parameter in the DB parameter group associated with your DB instance. For example, if you set the value to 1440, then logs are retained for one day. For more information, see PostgreSQL database log files.
Also, you can change error reporting and logging parameters in the DB parameter group to reduce excessive logging. This in turn reduces the log file size. For more information, see Error reporting and logging.
Check for temporary files
Temporary files are files that are stored per backend or session connection. These files are used as a resource pool. Review temporary files statistics by running a command similar to this:
Important: The columns temp_files and temp_bytes in view pg_stat_database are collecting statistics in aggregation (accumulative). This is by design because these counters are reset only by recovery at server start. That is, the counters are reset after an immediate shutdown, a server crash, or a point-in-time recovery (PITR). For this reason, it’s a best practice to monitor the growth of these files in number and size, rather than reviewing only the output.
Temporary files are created for sorts, hashes, or temporary query results. To track the creation of temporary tables or files, set log_temp_files in a custom parameter group. This parameter controls the logging of temporary file names and sizes. If you set the log_temp_files value to , then all temporary file information is logged. If you set the parameter to a positive value, then only files that are equal to or larger than the specified number of kilobytes are logged. The default setting is -1, which disables the logging of temporary files.
You can also use an EXPLAIN ANALYZE of your query to review disk sorting. When you review the log output, you can see the size of temporary files created by your query. For more information, see the PostgreSQL documentation for Monitoring database activity.
Check for a constant increase in transaction logs disk usage
The CloudWatch metric for TransactionLogsDiskUsage represents the disk space used by transaction WALs. Increases in transaction log disk usage can happen because of:
- High DB loads (writes and updates that generate additional WALs)
- Streaming read replica lag (replicas in the same Region) or read replica in storage full state
- Replication slots
Replication slots can be created as part of logical decoding feature of AWS Database Migration Service (AWS DMS). For logical replication, the slot parameter rds.logical_replication is set to 1. Replication slots retain the WAL files until the files are externally consumed by a consumer. For example, they might be consumed by pg_recvlogical; extract, transform, and load (ETL) jobs; or AWS DMS.
If you set the rds.logical_replication parameter value to 1, then AWS RDS sets the wal_level, max_wal_senders, max_replication_slots, and max_connections parameters. Changing these parameters can increase WAL generation. It’s a best practice to set the rds.logical_replication parameter only when you are using logical slots. If this parameter is set to 1 and logical replication slots are present but there isn’t a consumer for the WAL files retained by the replication slot, then then transaction logs disk usage can increase. This also results in a constant decrease in free storage space.
Run this query to confirm the presence and size of replication slots:
PostgreSQL v10 and later:
After you identify the replication slot that isn’t being consumed (with an active state that is False), drop the replication slot by running this query:
Note: If an AWS DMS task is the consumer and it is no longer required, then delete the task and manually drop the replication slot.
In this example, the slot name xc36ujql35djp_00013322_907c1e0a_9f8b_4c13_89ea_ef0ea1cf143d has an active state that is False. So this slot isn’t actively used, and the slot is contributing to 129 GB of transaction files.
Drop the query by running the following command:
Check the status of cross-Region read replicas
When you use cross-Region read replication, a physical replication slot is created on the primary instance. If the cross-Region read replica fails, then the storage space on the primary DB instance can be affected. This happens because the WAL files aren’t replicated over to the read replica. You can use CloudWatch metrics, Oldest Replication Slot Lag, and Transaction Logs Disk Usage to determine how far behind the most lagging replica is. You can also see how much storage is used for WAL data.
To check the status of cross-Region read replica, use query pg_replication_slots. For more information, see the PostgreSQL documentation for pg_replication_slots. If the active state is returned as false, then the slot is not currently used for replication.
You can also use view pg_stat_replication on the source instance to check the statistics for the replication. For more information, see the PostgreSQL documentation for pg_stat_replication.
Check for bloat or improper removal of dead rows (tuples)
In normal PostgreSQL operations, tuples that are deleted or made obsolete by an UPDATE aren’t removed from their table. For Multi-Version Concurrency Control (MVCC) implementations, when a DELETE operation is performed the row isn’t immediately removed from the data file. Instead, the row is marked as deleted by setting the xmax field in a header. Updates mark rows for deletion first, and then carry out an insert operation. This allows concurrency with minimal locking between the different transactions. As a result, different row versions are kept as part of MVCC process.
If dead rows aren’t cleaned up, they can stay in the data files but remain invisible to any transaction, which impacts disk space. If a table has many DELETE and UPDATE operations, then the dead tuples might use a large amount of disk space that’s sometimes called «bloat» in PostgreSQL.
The VACUUM operation can free the storage used by dead tuples so that it can be reused, but this doesn’t release the free storage to the filesystem. Running VACUUM FULL releases the storage to the filesystem. Note, however, that during the time of the VACUUM FULL run an access exclusive lock is held on the table. This method also requires extra disk space because it writes a new copy of the table and doesn’t release the old copy until the operation is complete. It’s a best practice to use this method only when you must reclaim a significant amount of space from within the table. It’s also a best practice to perform periodic vacuum or autovacuum operations on tables that are updated frequently. For more information, see the PostgreSQL documentation for VACUUM.
To check for the estimated number of dead tuples, use the pg_stat_all_tables view. For more information, see the PostgreSQL documentation for pg_stat_all_tables view. In this example, there are 1999952 dead tuples (n_dead_tup):
Check for orphaned files
Orphaned files can occur when the files are present in the database directory but there are no objects that point to those files. This might happen if your instance runs out of storage or the engine crashes during an operation such as ALTER TABLE, VACUUM FULL, or CLUSTER. To check for orphaned files, follow these steps:
1. Log in to PostgreSQL in each database.
2. Run these queries to assess the used and real sizes.
3. Note the results. If the difference is significant, then orphaned files might be using storage space.
Источник
What causes the JNI error «use of deleted local reference»?
I have an Android app where the following C method is called when the app starts (in Activity.onCreate ).
When this method is called the app crashes and I get the error:
JNI DETECTED ERROR IN APPLICATION: use of deleted local reference 0xd280e8d5
Step debugging shows that this line causes the crash:
What causes this error? And how can I call System.getProperty(«os.name») using JNI without getting this error?
2 Answers 2
The issue is that env->CallStaticObjectMethod is expecting a jstring as its 3rd argument and is instead being supplied with a string literal.
Creating a jstring first
fixed the problem.
In my case, I was using a local reference that was created in a function and was used in another function. For example:
The above statement returns a local reference of jclass. Suppose we store this in a global variable and use it in another function funB after funA is completed, then this local reference will not be considered as valid and will return «use of deleted local reference error».
To resolve this we need to do this:
First, get the local reference and then get the global reference from local reference. globalClass can be used globally (in different functions).
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.1.12.43152
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
Troubleshoot instance launch issues
The following issues prevent you from launching an instance.
Launch Issues
Invalid device name
Description
You get the Invalid device name device_name error when you try to launch a new instance.
Cause
If you get this error when you try to launch an instance, the device name specified for one or more volumes in the request has an invalid device name. Possible causes include:
The device name might be in use by the selected AMI.
The device name might be reserved for root volumes.
The device name might be used for another volume in the request.
The device name might not be valid for the operating system.
Solution
To resolve the issue:
Ensure that the device name is not used in the AMI that you selected. Run the following command to view the device names used by the AMI.
Ensure that you are not using a device name that is reserved for root volumes. For more information, see Available device names.
Ensure that each volume specified in your request has a unique device name.
Ensure that the device names that you specified are in the correct format. For more information, see Available device names.
Instance limit exceeded
Description
You get the InstanceLimitExceeded error when you try to launch a new instance or restart a stopped instance.
Cause
If you get an InstanceLimitExceeded error when you try to launch a new instance or restart a stopped instance, you have reached the limit on the number of instances that you can launch in a Region. When you create your AWS account, we set default limits on the number of instances you can run on a per-Region basis.
Solution
You can request an instance limit increase on a per-region basis. For more information, see Amazon EC2 service quotas.
Insufficient instance capacity
Description
You get the InsufficientInstanceCapacity error when you try to launch a new instance or restart a stopped instance.
Cause
If you get this error when you try to launch an instance or restart a stopped instance, AWS does not currently have enough available On-Demand capacity to fulfill your request.
Solution
To resolve the issue, try the following:
Wait a few minutes and then submit your request again; capacity can shift frequently.
Submit a new request with a reduced number of instances. For example, if you’re making a single request to launch 15 instances, try making 3 requests for 5 instances, or 15 requests for 1 instance instead.
If you’re launching an instance, submit a new request without specifying an Availability Zone.
If you’re launching an instance, submit a new request using a different instance type (which you can resize at a later stage). For more information, see Change the instance type.
If you are launching instances into a cluster placement group, you can get an insufficient capacity error. For more information, see Working with placement groups.
The requested configuration is currently not supported. Please check the documentation for supported configurations.
Description
You get the Unsupported error when you try to launch a new instance because the instance configuration is not supported.
Cause
The error message provides additional details. For example, an instance type or instance purchasing option might not be supported in the specified Region or Availability Zone.
Solution
Try a different instance configuration. To search for an instance type that meets your requirements, see Find an Amazon EC2 instance type.
Instance terminates immediately
Description
Your instance goes from the pending state to the terminated state.
Cause
The following are a few reasons why an instance might immediately terminate:
You’ve exceeded your EBS volume limits. For more information, see Instance volume limits.
An EBS snapshot is corrupted.
The root EBS volume is encrypted and you do not have permissions to access the KMS key for decryption.
A snapshot specified in the block device mapping for the AMI is encrypted and you do not have permissions to access the KMS key for decryption or you do not have access to the KMS key to encrypt the restored volumes.
The instance store-backed AMI that you used to launch the instance is missing a required part (an image.part.xx file).
For more information, get the termination reason using one of the following methods.
To get the termination reason using the Amazon EC2 console
In the navigation pane, choose Instances, and select the instance.
On the first tab, find the reason next to State transition reason.
To get the termination reason using the AWS Command Line Interface
Use the describe-instances command and specify the instance ID.
Review the JSON response returned by the command and note the values in the StateReason response element.
The following code block shows an example of a StateReason response element.
To get the termination reason using AWS CloudTrail
For more information, see Viewing events with CloudTrail event history in the AWS CloudTrail User Guide.
Solution
Depending on the termination reason, take one of the following actions:
Источник
@koichirok, it’s totally tangential at this point, but I wanted to respond to your comments directed towards me
My examples are minimum code to reproduce this issue,
What you need to provide is a minimal working example. Your contrived code when run as-is causes a different error for a different reason. All that does is make more work for someone trying to reproduce.
when I use normal URL like www.google.com, and open
new window by non JavaScript way (e.g. sending Ctrl+Return),
issue also occurred.
If those conditions reproduce the issue, then why didn’t you just supply an example using them?
And as TheShed412 mentioned above, exception is never thrown.
My point was that the way your code is structured, it will never display a stacktrace, so you wouldn’t know whether an exception was thrown. Using your original example python code, there is no way to differentiate between «no exception was thrown» and «and exception was thrown, but my exception handler swallowed it». Those are 2 very different things.
I made my original comments because a maintainer’s time is valuable and shouldn’t be spent chasing down errors by running contrived and incorrect examples. The better the reproduction steps and examples you can provide, the more likely it will be fixed. Basically, «help me help you».
… kind of like Jerry Maguire pleaded to Rod Tidwell (click to watch):

This article was created in partnership with Ktree. Thank you for supporting the partners who make SitePoint possible.
In this article are looking at how Magento cookies can create issues with the login functionality of both the customer-facing front-end and admin back-end, the reason it occurs and how it should be resolved.
This is also known as the looping issue, as the screen redirects itself to the same screen, even though the username and password is correct.
A script is provided at the end of the article which can help detect a few of the issues. Feel free to use and modify as per your needs.
What is a Cookie?
A cookie is a piece of text that a web server can store on a user’s hard drive, and can also later retrieve it. Magento uses cookies in Cart & Backend Admin functionalities, and they may be the source of a few problems when unable to login to Magento.
What is a Session?
A session is an array variable on the server side, which stores information to be used across multiple pages. For example, items added to the cart are typically saved in sessions, and when the user browses the checkout page they are read from the session.
Sessions are identified by a unique ID. Its name changes depemnding on the programming language — in PHP it is called a ‘PHP Session ID’. As you might have guessed, the same PHP Session ID needs to be stored as a cookie in the client browser to relate.
Magento’s storage of Sessions
Magento can store sessions via multiple session providers and this can be configured in the Magento config file at app/etc/local.xml. These session providers can be chosen here.
File
<session_save><![CDATA[files]]></session_save>
<session_save_path>
<![CDATA[/tmp/session]]>
</session_save_path>
Database
Allowing sessions to store themselves in the database is done in /app/etc/local.xml by adding <session_save><![CDATA[db]]></session_save>.
Magento applications store sessions in the Core_session table.
Redis
<session_save>db</session_save>
<redis_session>
<host>127.0.0.1</host>
<port>6379</port>
</redis_session>
MemCache
session_save><![CDATA[memcache]]></session_save>
<session_save_path>
<![CDATA[tcp://localhost:11211?persistent=1&weight=2&timeout=10&retry_interval=10]]>
</session_save_path>
Magento Usage
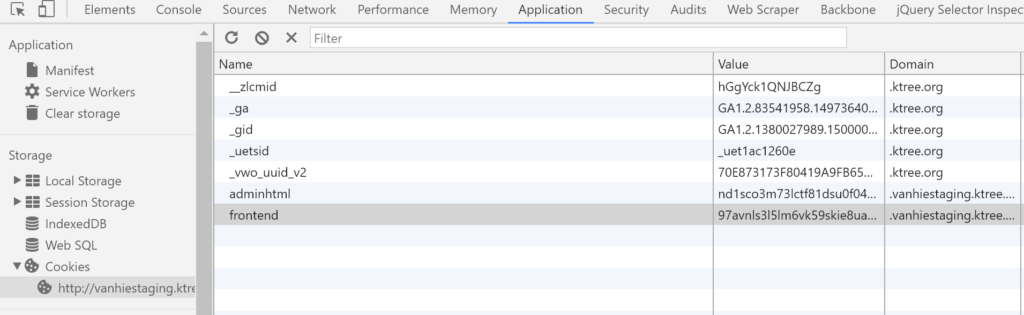
Magento uses two different cookies named ‘frontend’ and ‘adminhtml’. The first one is created when any page is browsed. The same cookie is also updated whenever the customer logs in, and the next one is created when a backend user is logged in. You can check whether the cookies have been created by clicking Inspect Element > Application, as in the below picture (from Chrome):
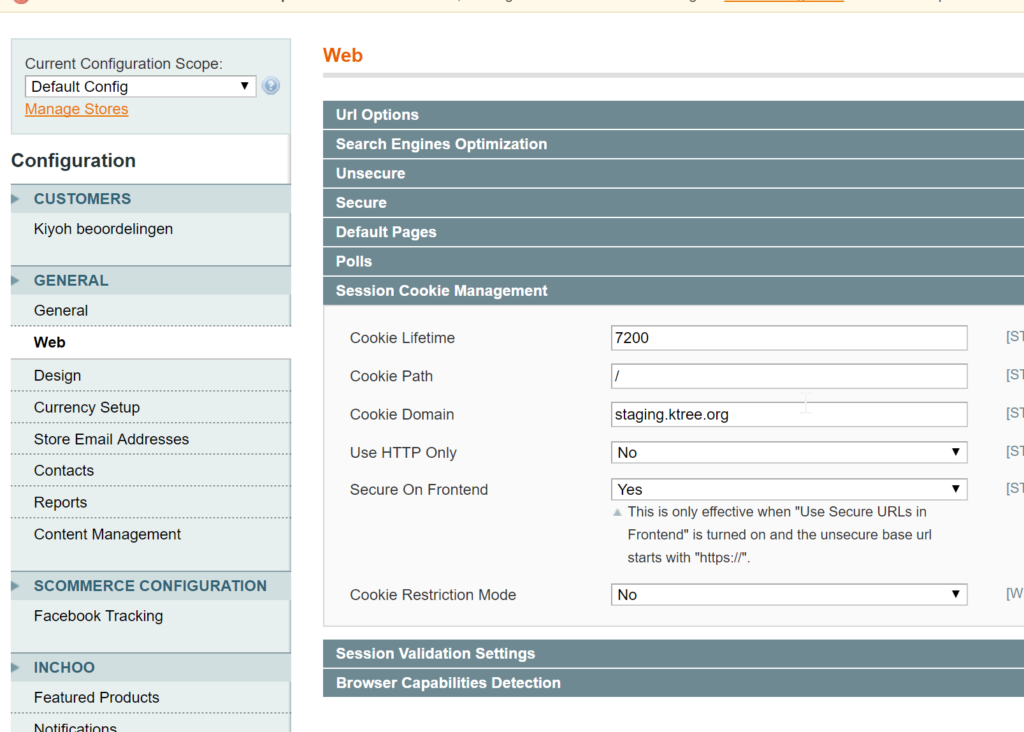
Cookies are configured in Magento via the Configuration admin menu – System > Configuration > General > Web.
Problem: Login Fails & Redirects to Login Page
If you haven’t experienced this problem, then you haven’t worked with Magento long enough!
This is how it typically happens: when you login by entering your username and password, you will be redirected to the same login page and URL, and your browser is appended with nonce id. This happens for both the customer front-end and the Magento back-end login.
Let’s look at a few reasons why this happens, and how we should resolve those issues.
Reason #1: Cookie domain does not match server domain
Let’s say your Magento site is example.com and the cookie domain in Magento is configured as xyz.com.
In this scenario both Magento cookies will set Domain Value as xyz.com, but for validating the session Magento will consider the domain through which the site was accessed — in this case example.com. Since it won’t be able to find an active session with the example.com domain value, it will redirect the user to the login page even when valid credentials are provided.
app/code/core/Mage/Core/Model/Session/Abstract.php
After login or logout, the Magento system will regenerate the session using the following script:
public function renewSession()
{
$this->getCookie()->delete($this->getSessionName());
$this->regenerateSessionId();
$sessionHosts = $this->getSessionHosts();
$currentCookieDomain = $this->getCookie()->getDomain();
if (is_array($sessionHosts)) {
foreach (array_keys($sessionHosts) as $host) {
// Delete cookies with the same name for parent domains
if (strpos($currentCookieDomain, $host) > 0) {
$this->getCookie()->delete($this->getSessionName(), null, $host);
}
}
}
return $this;
}
app/code/core/Mage/Core/Model/Session/Abstract/Varien.php
Magento will validate the session for every request with the following method:
public function init($namespace, $sessionName=null)
{
if (!isset($_SESSION)) {
$this->start($sessionName);
}
if (!isset($_SESSION[$namespace])) {
$_SESSION[$namespace] = array();
}
$this->_data = &$_SESSION[$namespace];
$this->validate();
$this->revalidateCookie();
return $this;
}
You may normally see this when you migrate your Magento instance from one domain to another domain, for example from Production to Staging, and forget to change the cookie domain.
Note: you can run the provided cookieTest.php script, which validates what the server cookie domain is, and what is set in the Magento config.
Solution:
Change the Cookie Domain via the Configuration admin menu. Go to System > Configuration > General > Web, as per the screenshot.
Alternatively you can change this by running these SQL queries.
For validating the cookie domain use this select query to get the configuration:
SELECT * FROM core_config_data WHERE path = 'web/cookie/cookie_domain';
After executing this query, we will get the results. Verify the ‘value’ column is the same as your domain. Update the value if it is not the same as your domain.
To update the cookie domain, use this query:
UPDATE core_config_data SET VALUE = "domain.com" WHERE path = 'web/cookie/cookie_domain';
Reason #2: Multiple subdomains used and Magento’s cookie configuration is incorrect
Let’s say your site is example.com. Logging into example.com/admin works fine.
But on your staging/QA site, for example staging.example.com/admin, you are unable to login without deleting all cookies. The system may allow logins to staging.example.com, but when we login again to example.com/admin, your next click on staging.example.com kicks you back to the login page. Similar behavior is experienced for customers using the front-end login as well.
Solution 1
Option A: If your main domain and subdomains are hosted on the same server
- Change the Cookie Domain via the Configuration admin menu. Go to System > Configuration > General > Web, as per the screenshot.
- See if Cookie Domain is
example.com, or.example.com(note the period in front). If not, set it to.example.com.
Option B: If your main domain and subdomains are hosted on different servers
- Change the Cookie Domain via the Configuration admin menu. Go to System > Configuration > General > Web, as per the screenshot.
- See if the Cookie Domain is
www.example.com, or.www.example.com(note the period in front). If not, set it to.www.example.com. - In the
test.example.comshop, set the Cookie Domain to.test.example.comon the test environment.
Alternatively, change this by running these sql queries.
For validating the cookie domain use the following select query to get the configuration:
SELECT * FROM core_config_data WHERE path = 'web/cookie/cookie_domain';
After executing the above query we will get the results. Verify whether the ‘value’ column is the same as your domain or not. Update the value if it is not same as your domain.
For updating the cookie domain, use the following query:
UPDATE core_config_data SET VALUE = "domain.com" WHERE path = 'web/cookie/cookie_domain';
Solution 2
Check whether your php.ini file has the same cookie domain as in your Magento config — if not change it to the same as the Magento config, as below:
cookie_domain = example.com
Solution 3
This is not the recommended approach, but if all options fail you can try this code, changing the option by changing the adminhtml cookie name for subdomains. Copy the file action.php and keep it in the same folder path as local so your core code file can be overridden.
There are two changes to make in the file app/code/core/Mage/Core/Controller/Varien/Action.php.
In the preDispatch function, change these lines:
/** @var $session Mage_Core_Model_Session */ $session = Mage::getSingleton('core/session', array('name' => $this->_sessionNamespace))->start();
To:
$namespace = $this->_sessionNamespace.($_SERVER['SERVER_NAME']=='subdomain.example.com'?'_subdomain':''); /** @var $session Mage_Core_Model_Session */ $session = Mage::getSingleton('core/session', array('name' => $namespace))->start();
In the function setRedirectWithCookieCheck, change:
/** @var $session Mage_Core_Model_Session */ session = Mage::getSingleton('core/session', array('name' => $this->_sessionNamespace));
To:
$namespace = $this->_sessionNamespace.($_SERVER['SERVER_NAME']=='subdomain.example.com'?'_subdomain':''); /** @var $session Mage_Core_Model_Session */ $session = Mage::getSingleton('core/session', array('name' => $namespace));
After that, search for the following text in all files:
Mage::getSingleton('core/session', array('name' => 'adminhtml'));`
If any occurrences are found, replace them with:
Mage::getSingleton('core/session', array('name' => 'adminhtml'.($_SERVER['SERVER_NAME']=='subdomain.example.com'?'_subdomain':'')));
Reason #3: Double front-end cookies causing intermittent login issues
In a few scenarios, there is the possibility of the system creating multiple frontend cookies, which prevents the system from allowing you to login..
Scenario 1
When your Magento system has the same configuration for your main domain and subdomain in the Magento config, and if the user logs in to both the sites, Magento creates two cookies. One has ‘Domain Value’ set with the main domain, and another with the subdomain. As such we will have two front-end cookie sessions, so we won’t be able to login to the system.
Solution
Change the Cookie Domain setting to .example.com for both the domain and subdomain configurations.
Scenario 2
In this scenario, let’s say in your php.ini, no cookie domain is configured and the Magento Domain Value of example.com is configured. Now when the user logs in via www.example.com, the system creates a cookie with a Domain Value of example.com from the Magento config. When the user logs out, Magento will regenerate the cookie with a Domain Value from the URL accessed (i.e www.example.com), since in php.ini no cookie domain was specified. Note that if the user logs in using example.com or a cookie domain is configured in php.ini, no issues will arise.
Solution 1
Add a cookie domain to your php.ini file that is the same as your Magento config.
session.cookie_domain = example.com
Solution 2
Change the Cookie Domain to .example.com for both domain and subdomain configurations.
Note: Use our cookieTest.php script to see if you have double frontend cookies.
Reason #4: Failed to create (read) session ID
Recoverable Error: session_regenerate_id(): Failed to create(read) session ID: user (path: /var/lib/php/sessions) in app/code/core/Mage/Core/Model/Session/Abstract/Varien.php on line 492
This is an error you may see in the exception log, and might occur only for PHP7, as PHP7 does strict type checking.
The solution for this is to change the Magento core read function by typecasting. More on this here.
public function read($sessId) {
//return $data;
return (string)$data;
}
Reason #5: Session data file is not created by your uid
Warning: session_start(): Session data file is not created by your uid in app/code/core/Mage/Core/Model/Session/Abstract/Varien.php on line 125
Solution 1
This error occurs if you are saving sessions in files, and the folder or files lack webserver user permission. So in the case of nginx, if your webserver user is www-data, you need to grant ownership to the folder using:
sudo chown -R www-data:www-data
Solution 2
If you are running on Vagrant, you may have to make sure or change the file session path.
Solution 3
Another reason is that there could be some old sessions in the var/sessions folder — delete them and test whether that fixes the problem.
Note: If you have the option to use different session providers, switch to another. For example, go from Redis to file. Clear your var/cache folder and see if it works — and again, only try this in your development environment.
A PHP Script to Detect Cookie Issues
<?php
ini_set('display_errors', 1);
$mageFileName = getcwd() . '/app/Mage.php';
require $mageFileName;
Mage::app();
echo "<b> Server Cookie Domain Configuration : </b> ".ini_get('session.cookie_domain')."<br>";
foreach (Mage::app()->getStores() as $store) {
echo "<b>" . $store->getName() . "</b><br>";
$configCookieDomain = Mage::getStoreConfig('web/cookie/cookie_domain', $store->getId());
$storeConfigUrl = Mage::getStoreConfig('web/unsecure/base_url', $store->getId());
$sourceUrl = parse_url($storeConfigUrl);
$storeDomain = $sourceUrl['host'];
$cookieDomainResult = ($configCookieDomain == $storeDomain || $configCookieDomain == '.' . $storeDomain) ? "" : "not";
echo "Config cookie Domain : " . $configCookieDomain . " and Store Domain: " . $storeDomain . " " . $cookieDomainResult . " configured properly<br>";
}
//echo "<b>Request Cookies:</b> ";
$requestCookie = Mage::app()->getRequest()->getHeader('cookie');
$requestCookieArr = explode(';', $requestCookie);
$sessionIds = array();
foreach ($requestCookieArr as $requestCookieItem) {
$cookieValue = explode('=', $requestCookieItem);
// echo $requestCookieItem."<br>";
if (trim($cookieValue[0]) == 'frontend' || trim($cookieValue[0]) == 'adminhtml') {
$cookieName = trim($cookieValue[0]);
$sessionId = trim($cookieValue[1]);
$sessionIds[$cookieName][] = $sessionId;
}
}
$areas = array("frontend", "adminhtml");
foreach ($areas as $area => $cookieName) {
echo "<b>validating " . $cookieName . " cookie </b><br>";
$cookieExpires = Mage::getModel('core/cookie')->getLifetime($cookieName);
$cookiePath = Mage::getModel('core/cookie')->getPath($cookieName);
$cookieDomain = Mage::getModel('core/cookie')->getDomain($cookieName);
$cookieSecure = Mage::getModel('core/cookie')->isSecure($cookieName);
$cookieHttpOnly = Mage::getModel('core/cookie')->getHttponly($cookieName);
echo "Cookie Lifetime : " . $cookieExpires . " <br>";
echo "Cookie Path : " . $cookiePath . " <br>";
echo "Cookie Domain : " . $cookieDomain . " <br>";
echo "Cookie Is Secure : " . $cookieSecure . " <br>";
echo "Cookie Httponly : " . $cookieHttpOnly . " <br>";
if (count($sessionIds[$cookieName]) > 1) {
echo "<span style='color:red'><b>We have " . count($sessionIds[$cookieName]) . " " . $cookieName . " Cookies with values : </b>" . implode(',', $sessionIds[$cookieName]) . "<br>";
//$encryptedSessionId = Mage::getSingleton("core/session")->getEncryptedSessionId();
$encryptedSessionId = Mage::getModel('core/cookie')->get($cookieName);
echo "Original Cookie value : " . $encryptedSessionId . "<br>";
echo "Please verify the Subdomain and Main Site Cookie Domain Configuration</span><br>";
}
}
?>
Output:
Magento Store EN
Config cookie Domain : staging.abc.com and Store Domain: staging.abc.com configured properly
Magento Store FR
Config cookie Domain : staging.abc.com and Store Domain: staging.abc.com configured properly
validating frontend cookie
Cookie Lifetime : 31536000
Cookie Path : /
Cookie Domain : staging.zeb.be
Cookie Is Secure :
Cookie Httponly : 1
validating adminhtml cookie
Cookie Lifetime : 31536000
Cookie Path : /
Cookie Domain : staging.zeb.be
Cookie Is Secure :
Cookie Httponly : 1