Содержание
- PostgreSQL Copy from Stdin
- Стандартный ввод (stdin):
- Stdin в PostgreSQL
- Копировать данные из стандартного ввода в таблицу
- Копировать данные из таблицы в стандартный ввод
- Вывод с использованием STDOUT вместо оператора SELECT
- Возникновение ошибок при использовании разделителей DELIMITER ’|’
- Заключение
- PostgreSQL pg_dump создает sql-скрипт, но это не sql-скрипт: есть ли способ заставить pg_dump создать стандартный sql-скрипт?
- 1 ответ
- COPY from stdin failed: error in .read() call #22
- Comments
- if file is given, output goes to file, else postgres
PostgreSQL Copy from Stdin
PostgreSQL, как и другие системы управления базами данных, поддерживает стандартные потоки. Эти потоки отвечают за управление данными для хранения в PostgreSQL. Это входные и выходные каналы связи между приложением и средой, которая создается во время выполнения.
Каждый раз, когда мы выполняем команду в PostgreSQL, потоки устанавливают соединение с текстовым терминалом, на котором запущена psql (оболочка). Однако в случае наследования каждый дочерний процесс наследует потоки от родительского процесса. Не каждой программе нужно, чтобы эти потоки были включены в код, некоторые функции, такие как getchar () и putchar (), автоматически используют потоки ввода и вывода. Потоки относятся к категории 3.
Stdin : это стандартный поток ввода. Он используется, когда программа считывает входные данные.
Stdout : это подразумевает стандартный поток вывода, используемый, когда приложение записывает данные (вывод) в файл.
Stderr : этот поток относится к ошибкам в приложении. Это используется для отображения или уведомления пользователя о возникновении ошибки во время выполнения.
Общий синтаксис для этих трех типов:
Стандартный ввод считывается «клавиатурой» устройства ввода, тогда как стандартный вывод и стандартные ошибки отображаются на экране монитора устройства вывода. Первые два потока используются для выборки и отображения данных простыми словами, но третий в основном используется, когда нам нужно диагностировать ошибки. Я говорю об обработке исключений в языках программирования.
Стандартный ввод (stdin):
При создании исходного кода большинство функций зависят от потока stdin для функции ввода. Но некоторые программы, такие как программы dir и ls, не требуют этой функции, поскольку они принимают аргументы командной строки. Такая ситуация возникает, когда программа полагается на систему для ввода, но не взаимодействует с пользователем. Например, программы, связанные с каталогом и путями, не требуют ввода для выполнения.
Каждому файлу, находящемуся в процессе выполнения, система присваивает уникальный номер. Это называется файловым дескриптором. Для стандартного ввода значение дескриптора файла равно «0». В языке программирования C файловый дескриптор имеет переменную file * stdin, аналогично языку C ++. Переменная определяется как std:: cin.
Stdin в PostgreSQL
После установки и настройки базы данных для подключения к серверу вам необходимо ввести пароль, чтобы продолжить. Эти меры предназначены для аутентификации пользователя.

Копировать данные из стандартного ввода в таблицу
Чтобы подтвердить механизм stdin, нам нужно создать фиктивную таблицу. Чтобы мы могли читать и копировать данные из файла в другой, добавив stdin.
>> create table school ( id int , name varchar ( 10 ) , address varchar ( 20 ) , Subject varchar ( 20 ) ) ;
После создания таблицы мы добавим в нее значения с помощью команды вставки. Добавьте образцы данных в несколько строк, остальные будут добавлены с использованием «STDIN».
>> insert into school values ( 1 , ‘Ahmad’ , ‘lahore’ , ‘sciences’ ) , ( 2 , ‘shazain’ , ‘Islamabad’ , ‘Arts’ ) , ( 3 , ‘Zain’ , ‘karachi’ , ‘sciences’ ) ;
Помимо оператора «INSERT», существует альтернатива для загрузки значений в таблицу. Это через «STDIN». В PostgreSQL мы вводим данные в таблицу из терминала построчно, используя разделитель. Этот разделитель является разделителем между значениями двух столбцов строки. В любом случае этот разделитель может быть пробелом, запятой или пробелом. Но рекомендуется использовать разделитель в качестве stdin, CSV (значения, разделенные запятыми). И никакой другой символ здесь не упоминается. Используется ключевое слово «COPY», которое копирует данные с экрана psql, в частности, в таблицу.
Когда вы используете запрос, здесь упоминаются некоторые инструкции по размещению данных. Это пункты, которые помогут пользователю правильно ввести данные. Каждую строку следует вводить с новой строки.
Здесь мы пойдем шаг за шагом. Каждое значение, записанное перед запятыми или между ними, представляет каждый столбец. Поскольку имеется 4 столбца, в качестве CSV используются 4 значения. Введите первую строку и нажмите вкладку.

Когда одна строка будет завершена, вы перейдете к следующей строке. Независимо от того, сколько строк вы хотите добавить, как и в инструкции вставки, все безграничные данные будут помещены внутри таблицы. Возвращаясь к примеру, мы написали вторую строку и переходим к следующей.

Для демонстрации мы использовали 2 ряда. Фактическая вставка приведет к тому, что данные будут соответствовать требованиям. Если вы закончили добавление строк в таблицу и хотите выйти из этого механизма, вы обязательно будете использовать конец файла (EOF).

Вам нужно завершить добавление данных обратной косой чертой () и точкой (.) В последней строке, если вы не хотите добавлять дополнительные строки.

Теперь давайте окончательно рассмотрим весь код от запроса до EOF. В конце «копия 3» указывает, что в таблицу добавлены 3 строки.
Примечание. Оператор EOF не добавляется в качестве символа в новую строку таблицы.
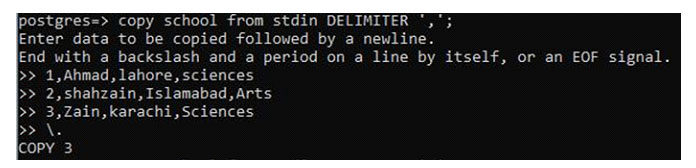
Продолжайте добавлять данные через «стандартный ввод» в соответствии с требованиями. Вы можете проверить данные, которые вы вставили, с помощью оператора select.

Копировать данные из таблицы в стандартный ввод
Если вас интересует копирование данных в одну таблицу из таблицы, то мы используем для этого stdin. Прямое копирование одной таблицы в другую в PostgreSQL невозможно.
Создайте образец таблицы, чтобы скопировать все данные из таблицы (школы). Следует помнить о добавлении данных столбца, тип которых аналогичен целевой таблице.

Теперь добавьте данные этого файла, используя тот же оператор stdin копии. Данные могут быть такими же, или вы можете изменить их, добавив новую строку, которой не было в исходной таблице.
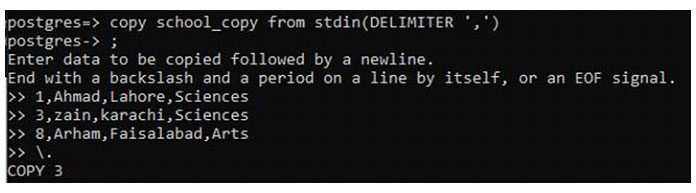
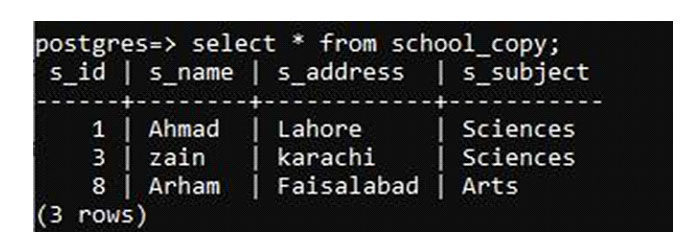
Используйте оператор выбора, чтобы ввести данные.
Вывод с использованием STDOUT вместо оператора SELECT
Поскольку мы используем stdin как альтернативу инструкции вставки. Точно так же STDOUT используется вместо оператора select. Представление не в виде таблицы. Для вывода используется разделитель «|». Этот разделитель автоматически помещается между столбцами в каждой строке.

Возникновение ошибок при использовании разделителей DELIMITER ’|’
Если вы используете разделитель ’|’ при замене CSV это вызовет ошибку. Это не приведет к копированию данных с терминала и вызовет синтаксическую ошибку.

Заключение
«Копирование PostgreSQL из стандартного ввода» помогает дублировать данные одной таблицы в другую. В этой статье мы сначала познакомили вас со стандартными потоками, stdin, он работает, теоретически, а затем кратко объяснили примеры. Конкурентное преимущество stdin перед оператором insert заключается в том, что если строка по ошибке пропущена при копировании данных, мы можем добавить ее между существующими строками. Руководствуясь этим руководством, вы сможете копировать содержимое таблиц.
Источник
PostgreSQL pg_dump создает sql-скрипт, но это не sql-скрипт: есть ли способ заставить pg_dump создать стандартный sql-скрипт?
Я запускаю pg_dump для создания скрипта для автоматизации создания такой системы:
Это создает сценарий sql, но на самом деле это не сценарий sql, поскольку в нем есть код, подобный показанному ниже.
Когда этот сценарий запускается как сценарий sql, он не дает ошибку, показанную ниже.
Есть ли способ заставить pg_dump создать сценарий sql, который является стандартным sql и может выполняться как сценарий sql?
Пример кода из sql, сгенерированного pg_dump:
Ошибка при запуске скрипта, сгенерированного pg_dump:
1 ответ
Клиентский инструмент, который вы используете для восстановления дампа, не может обрабатывать данные из (нестандартной) команды COPY , подмешиваемые в скрипт. Вам нужно psql для восстановления такого дампа.
Вы можете использовать параметр —inserts для pg_dump , чтобы создать дамп, содержащий операторы INSERT , а не COPY . Это будет медленнее для восстановления, но будет работать с большим количеством клиентских инструментов.
Однако ваше желание получить стандартный SQL-скрипт безнадежно. PostgreSQL во многих отношениях расширяет стандарт, поэтому дамп базы данных нельзя создать с помощью стандартного сценария SQL. Обратите внимание, например, что индексы не определены стандартом SQL. Если вы хотите перенести дамп PostgreSQL в другую СУБД, вы будете разочарованы. Это сложнее.
Источник
COPY from stdin failed: error in .read() call #22
Hi,
i’m trying to dump a big mysql database into a postgresql database, and i’m ending up with the following error
No further information on the postgresql receiving side but :
The text was updated successfully, but these errors were encountered:
Is this where it fails consistently? I’ve had mystery failures before if the the query on the mysql side was cancelled for some reason either due to time outs or someone killing the pid.
I’m having a similar issue:
]# py-mysql2pgsql -v -f /root/mysql2pgsql.yml
I found this on postgres log:
WARNING: nonstandard use of in a string literal at character 309
HINT: Use the escape string syntax for backslashes, e.g., E».
ERROR: COPY from stdin failed: error in .read() call
CONTEXT: COPY event, line 1
STATEMENT: COPY «event»(«id»,»department_id»,»shift_id»,»start_date»,»end_date»,»num_users»,»deleted»,»comment»,»start_time»,»end_time»,»pub_date»,»answer_deadline»,»approval_type»,»owner_id»,»status»,»copy_of_id»,»resent_at»,»notification_sent_at»,»extended_at»,»last_change») FROM stdin WITH DELIMITER AS ‘ ‘ NULL AS ‘N’
Any ideas of what is going on?
I fixed the problem by uninstalling py-mysql2pgsql, upgrading my python installation from 2.6 to 2.7 and installing again py-mysql2pgsql. That did the trick
ahh thx, strange.
I fixed the problem by uninstalling py-mysql2pgsql, upgrading my python
installation from 2.6 to 2.7 and installing again py-mysql2pgsql. That did
the trick
—
Reply to this email directly or view it on GitHubhttps://github.com//issues/22#issuecomment-10597157.
Olivier, it seems you are using py-mysql2pgsql version 0.1.6. I’m using version 0.1.5 ( py_mysql2pgsql-0.1.5-py2.7.egg-info). try that one, maybe it can fix your problem
I’m having a similar issue
DONE CREATING TABLES
START WRITING TABLE DATA
START — WRITING DATA TO address_types
Traceback (most recent call last):
File «/usr/local/bin/py-mysql2pgsql», line 5, in
pkg_resources.run_script(‘py-mysql2pgsql==0.1.6’, ‘py-mysql2pgsql’)
File «/usr/local/lib/python2.7/dist-packages/distribute-0.6.35-py2.7.egg/pkg_resources.py», line 505, in run_script
self.require(requires)[0].run_script(script_name, ns)
File «/usr/local/lib/python2.7/dist-packages/distribute-0.6.35-py2.7.egg/pkg_resources.py», line 1245, in run_script
execfile(script_filename, namespace, namespace)
File «/usr/local/lib/python2.7/dist-packages/py_mysql2pgsql-0.1.6-py2.7.egg/EGG-INFO/scripts/py-mysql2pgsql», line 38, in
mysql2pgsql.Mysql2Pgsql(options).convert()
File «/usr/local/lib/python2.7/dist-packages/py_mysql2pgsql-0.1.6-py2.7.egg/mysql2pgsql/mysql2pgsql.py», line 31, in convert
Converter(reader, writer, self.file_options, self.run_options.verbose).convert()
File «/usr/local/lib/python2.7/dist-packages/py_mysql2pgsql-0.1.6-py2.7.egg/mysql2pgsql/lib/converter.py», line 51, in convert
self.writer.write_contents(table, self.reader)
File «/usr/local/lib/python2.7/dist-packages/py_mysql2pgsql-0.1.6-py2.7.egg/mysql2pgsql/lib/init.py», line 86, in decorated_functi
ret = f(_args, *kwargs)
File «/usr/local/lib/python2.7/dist-packages/py_mysql2pgsql-0.1.6-py2.7.egg/mysql2pgsql/lib/postgres_db_writer.py», line 193, in write
self.copy_from(f, ‘»%s»‘ % table.name, [‘»%s»‘ % c[‘name’] for c in table.columns])
File «/usr/local/lib/python2.7/dist-packages/py_mysql2pgsql-0.1.6-py2.7.egg/mysql2pgsql/lib/postgres_db_writer.py», line 116, in copy
columns=columns
psycopg2.extensions.QueryCanceledError: COPY from stdin failed: error in .read() call
I’m running into this problem too. Is there any workaround?
@grigy
try what i did:
I fixed the problem by uninstalling py-mysql2pgsql, upgrading my python installation from 2.6 to 2.7 and installing again py-mysql2pgsql. That did the trick
KK, I’m in. ready to be hit with the logs.
- «WARNING: nonstandard use of in a string literal at character 309» is mostly a result of using psycopg2 and newer postgresql version that yells at regexps in regular strings. This is only a warning though.
- Most errors like «COPY from stdin failed» can be caused both by postgresql and mysql backends but only the last error is reported. In most cases postgresql says that the data wasn’t received and mysql stays silent. Try checking MySQL logs for errors.
I’m having this problem with all the mysql tables using auto_increment. I was also having it with longblog but hacked around that allowing migrate to test in pgsql which is what the application seems to want.
Still researching the auto_increment issue but though I’d post to see if anyone else has been able to resolve that.
The issue is not with auto_increment at all. It is caused by the content of blob columns in mysql. Still researching.
this is pure data content issue. nothing to do with the utility itself which works perfectly
One thing that did the trick for me:
use the file copy option in your yaml config file.
if file is given, output goes to file, else postgres
Источник
All Submissions:
- Have you followed the guidelines in our Contributing document?
- Have you checked to ensure there aren’t other open Pull Requests for the same update/change?
This updates the error message for COPY to STDIN / STDOUT commands that are not executed using the CopyManager API, i.e. via a regular Statement.executeQuery("COPY ... TO STDOUT ..."). The revised text for the error message is:
COPY commands are only supported using the CopyManager API.
If anybody has a better suggestion feel free to chime in. I figure it’s enough that someone who does run into the error can then search for «CopyManager» in the context of pgjdbc and hopefully find more info.
This PR does not update or remove the old value from the translation files. There’s quite a few translations for the old message as it was in the code base for many years. I was considering updating the old message key for the old text so they continue to operate but decided that it’s better to have the new / correct english text show up instead.
Separately, we should look into adding more about the CopyManager interface to either the core README or the jdbc.postgresql.org website as I don’t think either covers that API.
I’m running pg_dump to create a script to automate the creation of a system like this:
pg_dump --dbname=postgresql://postgres:ohdsi@127.0.0.1:5432/OHDSI -t webapi.* > webapi.sql
This creates a sql script, but it is not really a sql script as it has code in it like what is shown below.
When this script is run as a sql script, it fails giving the error shown below.
Is there a way to get pg_dump to create a sql script that is standard sql and can be executed as a sql script?
Code sample from sql generated by pg_dump:
COPY webapi.cohort_version (asset_id, comment, description, version, asset_json, archived, created_by_id, created_date) FROM stdin;
.
--
-- Data for Name: concept_of_interest; Type: TABLE DATA; Schema: webapi; Owner: ohdsi_admin_user
--
COPY webapi.concept_of_interest (id, concept_id, concept_of_interest_id) FROM stdin;
1 4329847 4185932
2 4329847 77670
3 192671 4247120
4 192671 201340
Error seen when running the script generated by pg_dump:
--
-- Name: penelope_laertes_uni_pivot id; Type: DEFAULT; Schema: webapi; Owner: ohdsi_admin_user
--
ALTER TABLE ONLY webapi.penelope_laertes_uni_pivot ALTER COLUMN id SET DEFAULT nextval('webapi.penelope_laertes_uni_pivot_id_seq'::regclass)
--
-- Data for Name: achilles_cache; Type: TABLE DATA; Schema: webapi; Owner: ohdsi_admin_user
--
COPY webapi.achilles_cache (id, source_id, cache_name, cache) FROM stdin
Error executing: COPY webapi.achilles_cache (id, source_id, cache_name, cache) FROM stdin
. Cause: org.postgresql.util.PSQLException: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API.
Where: COPY achilles_cache, line 1
Exception in thread "main" java.lang.RuntimeException: org.apache.ibatis.jdbc.RuntimeSqlException: Error executing: COPY webapi.achilles_cache (id, source_id, cache_name, cache) FROM stdin
. Cause: org.postgresql.util.PSQLException: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API.
Where: COPY achilles_cache, line 1
at org.yaorma.database.Database.executeSqlScript(Database.java:344)
at org.yaorma.database.Database.executeSqlScript(Database.java:332)
at org.nachc.tools.fhirtoomop.tools.build.postgres.build.A04_CreateAtlasWebApiTables.exec(A04_CreateAtlasWebApiTables.java:29)
at org.nachc.tools.fhirtoomop.tools.build.postgres.build.A04_CreateAtlasWebApiTables.main(A04_CreateAtlasWebApiTables.java:19)
Caused by: org.apache.ibatis.jdbc.RuntimeSqlException: Error executing: COPY webapi.achilles_cache (id, source_id, cache_name, cache) FROM stdin
. Cause: org.postgresql.util.PSQLException: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API.
Where: COPY achilles_cache, line 1
at org.apache.ibatis.jdbc.ScriptRunner.executeLineByLine(ScriptRunner.java:109)
at org.apache.ibatis.jdbc.ScriptRunner.runScript(ScriptRunner.java:71)
at org.yaorma.database.Database.executeSqlScript(Database.java:342)
... 3 more
Caused by: org.postgresql.util.PSQLException: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API.
Where: COPY achilles_cache, line 1
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2675)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2365)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:355)
at org.postgresql.jdbc.PgStatement.executeInternal(PgStatement.java:490)
at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:408)
at org.postgresql.jdbc.PgStatement.executeWithFlags(PgStatement.java:329)
at org.postgresql.jdbc.PgStatement.executeCachedSql(PgStatement.java:315)
at org.postgresql.jdbc.PgStatement.executeWithFlags(PgStatement.java:291)
at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:286)
at org.apache.ibatis.jdbc.ScriptRunner.executeStatement(ScriptRunner.java:190)
at org.apache.ibatis.jdbc.ScriptRunner.handleLine(ScriptRunner.java:165)
at org.apache.ibatis.jdbc.ScriptRunner.executeLineByLine(ScriptRunner.java:102)
... 5 more
— EDIT ————————————
The —inserts method in the accepted answer gave me exactly what I needed.
I ended up doing this:
pg_dump —inserts —dbname=postgresql://postgres:ohdsi@127.0.0.1:5432/OHDSI -t webapi.* > webapi.sql
PostgreSQL Copy from Stdin
PostgreSQL, как и другие системы управления базами данных, поддерживает стандартные потоки. Эти потоки отвечают за управление данными для хранения в PostgreSQL. Это входные и выходные каналы связи между приложением и средой, которая создается во время выполнения.
Каждый раз, когда мы выполняем команду в PostgreSQL, потоки устанавливают соединение с текстовым терминалом, на котором запущена psql (оболочка). Однако в случае наследования каждый дочерний процесс наследует потоки от родительского процесса. Не каждой программе нужно, чтобы эти потоки были включены в код, некоторые функции, такие как getchar () и putchar (), автоматически используют потоки ввода и вывода. Потоки относятся к категории 3.
Stdin : это стандартный поток ввода. Он используется, когда программа считывает входные данные.
Stdout : это подразумевает стандартный поток вывода, используемый, когда приложение записывает данные (вывод) в файл.
Stderr : этот поток относится к ошибкам в приложении. Это используется для отображения или уведомления пользователя о возникновении ошибки во время выполнения.
Общий синтаксис для этих трех типов:
Стандартный ввод считывается «клавиатурой» устройства ввода, тогда как стандартный вывод и стандартные ошибки отображаются на экране монитора устройства вывода. Первые два потока используются для выборки и отображения данных простыми словами, но третий в основном используется, когда нам нужно диагностировать ошибки. Я говорю об обработке исключений в языках программирования.
Стандартный ввод (stdin):
При создании исходного кода большинство функций зависят от потока stdin для функции ввода. Но некоторые программы, такие как программы dir и ls, не требуют этой функции, поскольку они принимают аргументы командной строки. Такая ситуация возникает, когда программа полагается на систему для ввода, но не взаимодействует с пользователем. Например, программы, связанные с каталогом и путями, не требуют ввода для выполнения.
Каждому файлу, находящемуся в процессе выполнения, система присваивает уникальный номер. Это называется файловым дескриптором. Для стандартного ввода значение дескриптора файла равно «0». В языке программирования C файловый дескриптор имеет переменную file * stdin, аналогично языку C ++. Переменная определяется как std:: cin.
Stdin в PostgreSQL
После установки и настройки базы данных для подключения к серверу вам необходимо ввести пароль, чтобы продолжить. Эти меры предназначены для аутентификации пользователя.
Копировать данные из стандартного ввода в таблицу
Чтобы подтвердить механизм stdin, нам нужно создать фиктивную таблицу. Чтобы мы могли читать и копировать данные из файла в другой, добавив stdin.
>> create table school ( id int , name varchar ( 10 ) , address varchar ( 20 ) , Subject varchar ( 20 ) ) ;
После создания таблицы мы добавим в нее значения с помощью команды вставки. Добавьте образцы данных в несколько строк, остальные будут добавлены с использованием «STDIN».
>> insert into school values ( 1 , ‘Ahmad’ , ‘lahore’ , ‘sciences’ ) , ( 2 , ‘shazain’ , ‘Islamabad’ , ‘Arts’ ) , ( 3 , ‘Zain’ , ‘karachi’ , ‘sciences’ ) ;
Помимо оператора «INSERT», существует альтернатива для загрузки значений в таблицу. Это через «STDIN». В PostgreSQL мы вводим данные в таблицу из терминала построчно, используя разделитель. Этот разделитель является разделителем между значениями двух столбцов строки. В любом случае этот разделитель может быть пробелом, запятой или пробелом. Но рекомендуется использовать разделитель в качестве stdin, CSV (значения, разделенные запятыми). И никакой другой символ здесь не упоминается. Используется ключевое слово «COPY», которое копирует данные с экрана psql, в частности, в таблицу.
Когда вы используете запрос, здесь упоминаются некоторые инструкции по размещению данных. Это пункты, которые помогут пользователю правильно ввести данные. Каждую строку следует вводить с новой строки.
Здесь мы пойдем шаг за шагом. Каждое значение, записанное перед запятыми или между ними, представляет каждый столбец. Поскольку имеется 4 столбца, в качестве CSV используются 4 значения. Введите первую строку и нажмите вкладку.
Когда одна строка будет завершена, вы перейдете к следующей строке. Независимо от того, сколько строк вы хотите добавить, как и в инструкции вставки, все безграничные данные будут помещены внутри таблицы. Возвращаясь к примеру, мы написали вторую строку и переходим к следующей.
Для демонстрации мы использовали 2 ряда. Фактическая вставка приведет к тому, что данные будут соответствовать требованиям. Если вы закончили добавление строк в таблицу и хотите выйти из этого механизма, вы обязательно будете использовать конец файла (EOF).
Вам нужно завершить добавление данных обратной косой чертой () и точкой (.) В последней строке, если вы не хотите добавлять дополнительные строки.
Теперь давайте окончательно рассмотрим весь код от запроса до EOF. В конце «копия 3» указывает, что в таблицу добавлены 3 строки.
Примечание. Оператор EOF не добавляется в качестве символа в новую строку таблицы.
Продолжайте добавлять данные через «стандартный ввод» в соответствии с требованиями. Вы можете проверить данные, которые вы вставили, с помощью оператора select.
Копировать данные из таблицы в стандартный ввод
Если вас интересует копирование данных в одну таблицу из таблицы, то мы используем для этого stdin. Прямое копирование одной таблицы в другую в PostgreSQL невозможно.
Создайте образец таблицы, чтобы скопировать все данные из таблицы (школы). Следует помнить о добавлении данных столбца, тип которых аналогичен целевой таблице.
Теперь добавьте данные этого файла, используя тот же оператор stdin копии. Данные могут быть такими же, или вы можете изменить их, добавив новую строку, которой не было в исходной таблице.
Используйте оператор выбора, чтобы ввести данные.
Вывод с использованием STDOUT вместо оператора SELECT
Поскольку мы используем stdin как альтернативу инструкции вставки. Точно так же STDOUT используется вместо оператора select. Представление не в виде таблицы. Для вывода используется разделитель «|». Этот разделитель автоматически помещается между столбцами в каждой строке.
Возникновение ошибок при использовании разделителей DELIMITER ’|’
Если вы используете разделитель ’|’ при замене CSV это вызовет ошибку. Это не приведет к копированию данных с терминала и вызовет синтаксическую ошибку.
Заключение
«Копирование PostgreSQL из стандартного ввода» помогает дублировать данные одной таблицы в другую. В этой статье мы сначала познакомили вас со стандартными потоками, stdin, он работает, теоретически, а затем кратко объяснили примеры. Конкурентное преимущество stdin перед оператором insert заключается в том, что если строка по ошибке пропущена при копировании данных, мы можем добавить ее между существующими строками. Руководствуясь этим руководством, вы сможете копировать содержимое таблиц.
Источник
How to import data to postgres database from a copy STDIN file format in DBeaver?
Pedro Paulo
Guest
Pedro Paulo Asks: How to import data to postgres database from a copy STDIN file format in DBeaver?
I have a .sql file with some data in COPY FROM STDIN format:
How can I import that data to a postgres database in Dbeaver? I tried to run the sql statemente, but got this error.
Error occurred during SQL script execution
Reason: SQL Error [57014]: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API. Where: COPY feedback, line 1
Unreplied Threads
Cluster products that are frequently bought together
- Irfan
- 28 minutes ago
- Computer Science
- Replies: 0
Irfan Asks: Cluster products that are frequently bought together
I have a dataset of articles metadata for each article, so something like this:
| product_id | color | type |
|---|---|---|
| 1234 | red | t-shirt |
and another containing the transactions of customers, which looks like this:
| date | customer_id | product_id |
|---|---|---|
| 12/12/12 | abcd | 1234 |
Using the second dataset, I was able to determine which products are often bought together. As such, for each product, I have a sorted list of 10 (different) products (at most, it could be less) that are most frequently bought with it. This information is stored in a dictionary of the following form:
My question is the following. Is there a way for me to create embeddings of products such that a given product is «close» to the products it is most frequently bought with ? In other words, I want to cluster articles that are bought together in a space and have vectors (embeddings) for each product.
Why would I want to do this ?
- To see if I can see an interesting structure in my data
- To recommend items to users, I can look for the k-nearest neighbors of the users’ latest purchases
It looks to me like it is some form of supervised clustering (if that even makes sense), but I can’t exactly find how I would go about doing this.
If you could point to me towards an algorithm or something I am missing here, please let me know.
Want to create 2 column metrics in Pandas based on same dataset
- oazed lium
- 28 minutes ago
- Computer Science
- Replies: 0
oazed lium Asks: Want to create 2 column metrics in Pandas based on same dataset
- Snapshot of the data given below:

I want to create two new columns from this data set.
I need to create a scatter plot to display how each firm performed in the year 2017 based on their average score (x-axis) per their market penetration (y-axis) [# of unique respondents that rated the company / total unique respondents] based on the data (a portion of data is in snapshot)
New column ‘mtkp’. ‘mktp’ is the #unique respondents per company per year / total unique respondents in 2017
New column ‘mean’. mean is the average score given to a company that year.
How do I do it? Any suggestion? I am using Pandas and python 3
Implementation of Hellinger distance with numpy only
- low_rider533
- 28 minutes ago
- Computer Science
- Replies: 0
low_rider533 Asks: Implementation of Hellinger distance with numpy only
I got this task to implement a python function using NumPy. The function should compute the Hellinger distance between two matrices P and Q with dimensions (n, k). p_i is the vector of row i of P & p_i,j is the value of row i in column j of P.
The Hellinger distance for matrices is defined as followed:

H is a vector of length n and h_i is the value i of H, with i = 1. n. So the Hellinger distance between two matrices is equivalent to the Hellinger distance between the rows of the matrices. For each row, the distance is stored in the output vector H.
The task now is to implement the function (using NumPy), which will compute the above-described problem. It gets handed over two 2D-NumPy-Arrays P and Q, and it should return a 1D-Numpy-Array H of the right length.
I never worked with NumPy before, so I would be very grateful for any suggestions.
Coloring labels using scatterplot3d in R
- trolkura
- 28 minutes ago
- Computer Science
- Replies: 0
trolkura Asks: Coloring labels using scatterplot3d in R
I am trying to visualize data using R and scatterplot3d.
I have loaded data and used:
X9 is label column in my dataset. it contains 3 categories : A , B , C.
color : colors of points in the plot, optional if x is an appropriate structure. Will be ignored if highlight.3d = TRUE.
pch: plotting «character», i.e. symbol to use.
Yet I still get this error
I assumed I had to put color for every collumn in dataset, but creating such array where:
yields the same error.
What is the right way to add colors?
Find a transducer that maps a given deterministic process to another
- AG1123
- 28 minutes ago
- Computer Science
- Replies: 0
One can also construct deterministic transducers, that is, input-dependent Hidden Markov Models that take a deterministic process to another deterministic process. The description is similarly given through input-dependent transition matrices $T^<(b|a)>$, with elements $T^<(b|a)>_=Pr(s_=j,B_t=a|s_t=i,A_t=a)$. For example, a deterministic transducer with two states and input and output alphabets $<0,1>$ that either performs the identity or a bit flip could be represented as $$ T^<(0|0)>=begin 1 & 0 \ 0 & 0 \ end,,, , T^<(1|0)>=begin 0 & 0 \ 0 & 1 \ end ,,, , T^<(0|1)>=begin 0 & 0 \ 1 & 0 \ end ,,, , T^<(1|1)>=begin 0 & 1 \ 0 & 0 \ end $$ and would map the previous defined process of alternating zero and one to the process that generates $. 001100110011. $. This process’ description would be $$ hat
^<(0)>=begin 0 & 1 & 0 & 0 \ 0 & 0 & 0 & 0 \ 0 & 0 & 0 & 0 \ 1 & 0 & 0 & 0 \ end , ,, hat
^<(1)>=begin 0 & 0 & 0 & 0 \ 0 & 0 & 1 & 0 \ 0 & 0 & 0 & 1 \ 0 & 0 & 0 & 0 \ end $$ After these definitions and example, I am ready to state my questions.
Question 1: Given two known processes $S$ and $P$ how can one find a transducer that maps one to the other (in general there is no unique solution). More importantly, is there a way to construct a transducer with minimal amount of hidden states? Is there an algorithm to do any of these two tasks?
Question 2: Given a representation of process $S$ with a HMM with $n$ states, how can one find the representation that has minimal number of states? In other words, is there an algorithm that takes a process with $n$ states and generates another with $m$, such that $mleq n$ and equality if and only if the original representation of the process is already minimal?
PS: I do not have a formal background in CS but only maths, so please forgive me if my notation is weird and I am lacking in knowledge of basic results.
Источник
So I’ve been working with postgre databases and I noticed that it throws an error sometimes when I try to read a csv file and copy to a table remotely. It works perfectly when I use a buffered reader but i’m trying to see if there’s a way i can get i to work using the databases COPY FROM method. It works perfectly on the computer where the database is located but my other computer gets an error.
Error occurs in this line:
st.execute("COPY inputdata FROM 'C:\Users\JAMES\Downloads\V24_Mike_110217_RemovedReturnTrips\RyderCombiner\AllNonMatchingWithColNames.csv' CSV HEADER DELIMITER ',';");
Here’s where I connect to database:
Class.forName("org.postgresql.Driver");
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.1.15:5432/postgres", "postgres", "pass");
I read online that maybe STDIN can possibly help me but I haven’t been able to get it to work and most examples online are using pqsl. Is there a way I can get tthis to work or do I need to go back to buffered readers?
UPDATE:
So I’ve tried using the CopyManager API but it has an error when trying to make a connection using DBUtil as it is not recognized even though I downloaded the jar file from this website: http://commons.apache.org/proper/commons-dbutils/download_dbutils.cgi
Code:
Connection connection = DBUtil.getConnection("POSTGRES");
String sql = "COPY inputdata FROM 'C:\Users\JAMES\Downloads\V24_Mike_110217_RemovedReturnTrips\RyderCombiner\AllNonMatchingWithColNames.csv' CSV HEADER DELIMITER ','";
CopyManager copyManager = new CopyManager((BaseConnection)connection);
copyManager.copyIn(sql);
I get the error in the first line with DBUtil…is importing the jar file the only way to make jdbc recognize this variable?
UPDATE2:
Thanks again guys I ended up getting the copyin to work by following the given link and a few adjustments.
public static void readInputData(String inputDataFile, Statement st) throws FileNotFoundException, IOException, SQLException {
Connection connection = DriverManager.getConnection("jdbc:postgresql://192.168.1.15:5432/postgres", "postgres", "pass");
String sql = "COPY INPUTDATA FROM stdin CSV HEADER DELIMITER ','";
BaseConnection pgcon = (BaseConnection)connection;
CopyManager mgr = new CopyManager(pgcon);
try {
Reader in = new BufferedReader(new FileReader(new File(inputDataFile)));
long rowsaffected = mgr.copyIn(sql, in);
} catch (SQLException ex) {
System.err.println(ex.getClass().getName() + ": " + ex.getMessage());
System.exit(0);
}
}
PostgreSQL, как и другие системы управления базами данных, поддерживает стандартные потоки. Эти потоки отвечают за управление данными для хранения в PostgreSQL. Это входные и выходные каналы связи между приложением и средой, которая создается во время выполнения.
Каждый раз, когда мы выполняем команду в PostgreSQL, потоки устанавливают соединение с текстовым терминалом, на котором запущена psql (оболочка). Однако в случае наследования каждый дочерний процесс наследует потоки от родительского процесса. Не каждой программе нужно, чтобы эти потоки были включены в код, некоторые функции, такие как getchar () и putchar (), автоматически используют потоки ввода и вывода. Потоки относятся к категории 3.
Stdin : это стандартный поток ввода. Он используется, когда программа считывает входные данные.
Stdout : это подразумевает стандартный поток вывода, используемый, когда приложение записывает данные (вывод) в файл.
Stderr : этот поток относится к ошибкам в приложении. Это используется для отображения или уведомления пользователя о возникновении ошибки во время выполнения.
Общий синтаксис для этих трех типов:
FILE *stdin;
FILE *stdout;
FILE *stderr;
Стандартный ввод считывается «клавиатурой» устройства ввода, тогда как стандартный вывод и стандартные ошибки отображаются на экране монитора устройства вывода. Первые два потока используются для выборки и отображения данных простыми словами, но третий в основном используется, когда нам нужно диагностировать ошибки. Я говорю об обработке исключений в языках программирования.
Содержание
- Стандартный ввод (stdin):
- Stdin в PostgreSQL
- Копировать данные из стандартного ввода в таблицу
- Копировать данные из таблицы в стандартный ввод
- Вывод с использованием STDOUT вместо оператора SELECT
- Возникновение ошибок при использовании разделителей DELIMITER ’|’
- Заключение
Стандартный ввод (stdin):
При создании исходного кода большинство функций зависят от потока stdin для функции ввода. Но некоторые программы, такие как программы dir и ls, не требуют этой функции, поскольку они принимают аргументы командной строки. Такая ситуация возникает, когда программа полагается на систему для ввода, но не взаимодействует с пользователем. Например, программы, связанные с каталогом и путями, не требуют ввода для выполнения.
Каждому файлу, находящемуся в процессе выполнения, система присваивает уникальный номер. Это называется файловым дескриптором. Для стандартного ввода значение дескриптора файла равно «0». В языке программирования C файловый дескриптор имеет переменную file * stdin, аналогично языку C ++. Переменная определяется как std:: cin.
Stdin в PostgreSQL
После установки и настройки базы данных для подключения к серверу вам необходимо ввести пароль, чтобы продолжить. Эти меры предназначены для аутентификации пользователя.
Копировать данные из стандартного ввода в таблицу
Чтобы подтвердить механизм stdin, нам нужно создать фиктивную таблицу. Чтобы мы могли читать и копировать данные из файла в другой, добавив stdin.
>>create table school (id int, name varchar(10), address varchar(20), Subject varchar(20));
После создания таблицы мы добавим в нее значения с помощью команды вставки. Добавьте образцы данных в несколько строк, остальные будут добавлены с использованием «STDIN».
>> insert into school values ( 1, ‘Ahmad’, ‘lahore’,‘sciences’),( 2, ‘shazain’, ‘Islamabad’,‘Arts’),( 3, ‘Zain’, ‘karachi’,‘sciences’);
Помимо оператора «INSERT», существует альтернатива для загрузки значений в таблицу. Это через «STDIN». В PostgreSQL мы вводим данные в таблицу из терминала построчно, используя разделитель. Этот разделитель является разделителем между значениями двух столбцов строки. В любом случае этот разделитель может быть пробелом, запятой или пробелом. Но рекомендуется использовать разделитель в качестве stdin, CSV (значения, разделенные запятыми). И никакой другой символ здесь не упоминается. Используется ключевое слово «COPY», которое копирует данные с экрана psql, в частности, в таблицу.
>> Copy school from stdin (Delimiter ‘,’);
Когда вы используете запрос, здесь упоминаются некоторые инструкции по размещению данных. Это пункты, которые помогут пользователю правильно ввести данные. Каждую строку следует вводить с новой строки.
Здесь мы пойдем шаг за шагом. Каждое значение, записанное перед запятыми или между ними, представляет каждый столбец. Поскольку имеется 4 столбца, в качестве CSV используются 4 значения. Введите первую строку и нажмите вкладку.
Когда одна строка будет завершена, вы перейдете к следующей строке. Независимо от того, сколько строк вы хотите добавить, как и в инструкции вставки, все безграничные данные будут помещены внутри таблицы. Возвращаясь к примеру, мы написали вторую строку и переходим к следующей.
Для демонстрации мы использовали 2 ряда. Фактическая вставка приведет к тому, что данные будут соответствовать требованиям. Если вы закончили добавление строк в таблицу и хотите выйти из этого механизма, вы обязательно будете использовать конец файла (EOF).
Вам нужно завершить добавление данных обратной косой чертой () и точкой (.) В последней строке, если вы не хотите добавлять дополнительные строки.
Теперь давайте окончательно рассмотрим весь код от запроса до EOF. В конце «копия 3» указывает, что в таблицу добавлены 3 строки.
Примечание. Оператор EOF не добавляется в качестве символа в новую строку таблицы.
Продолжайте добавлять данные через «стандартный ввод» в соответствии с требованиями. Вы можете проверить данные, которые вы вставили, с помощью оператора select.
Копировать данные из таблицы в стандартный ввод
Если вас интересует копирование данных в одну таблицу из таблицы, то мы используем для этого stdin. Прямое копирование одной таблицы в другую в PostgreSQL невозможно.
Создайте образец таблицы, чтобы скопировать все данные из таблицы (школы). Следует помнить о добавлении данных столбца, тип которых аналогичен целевой таблице.
![]()
Теперь добавьте данные этого файла, используя тот же оператор stdin копии. Данные могут быть такими же, или вы можете изменить их, добавив новую строку, которой не было в исходной таблице.
>> copy school_copy from stdin (delimeter ‘,’)
Используйте оператор выбора, чтобы ввести данные.
Вывод с использованием STDOUT вместо оператора SELECT
Поскольку мы используем stdin как альтернативу инструкции вставки. Точно так же STDOUT используется вместо оператора select. Представление не в виде таблицы. Для вывода используется разделитель «|». Этот разделитель автоматически помещается между столбцами в каждой строке.
>> copy school_copy to stdout (DELIMITER ‘|’);
Возникновение ошибок при использовании разделителей DELIMITER ’|’
Если вы используете разделитель ’|’ при замене CSV это вызовет ошибку. Это не приведет к копированию данных с терминала и вызовет синтаксическую ошибку.
Заключение
«Копирование PostgreSQL из стандартного ввода» помогает дублировать данные одной таблицы в другую. В этой статье мы сначала познакомили вас со стандартными потоками, stdin, он работает, теоретически, а затем кратко объяснили примеры. Конкурентное преимущество stdin перед оператором insert заключается в том, что если строка по ошибке пропущена при копировании данных, мы можем добавить ее между существующими строками. Руководствуясь этим руководством, вы сможете копировать содержимое таблиц.
Я запускаю pg_dump для создания скрипта для автоматизации создания такой системы:
pg_dump --dbname=postgresql://postgres:ohdsi@127.0.0.1:5432/OHDSI -t webapi.* > webapi.sql
Это создает сценарий sql, но на самом деле это не сценарий sql, поскольку в нем есть код, подобный показанному ниже.
Когда этот сценарий запускается как сценарий sql, он не дает ошибку, показанную ниже.
Есть ли способ заставить pg_dump создать сценарий sql, который является стандартным sql и может выполняться как сценарий sql?
Пример кода из sql, сгенерированного pg_dump:
COPY webapi.cohort_version (asset_id, comment, description, version, asset_json, archived, created_by_id, created_date) FROM stdin;
.
--
-- Data for Name: concept_of_interest; Type: TABLE DATA; Schema: webapi; Owner: ohdsi_admin_user
--
COPY webapi.concept_of_interest (id, concept_id, concept_of_interest_id) FROM stdin;
1 4329847 4185932
2 4329847 77670
3 192671 4247120
4 192671 201340
Ошибка при запуске скрипта, сгенерированного pg_dump:
--
-- Name: penelope_laertes_uni_pivot id; Type: DEFAULT; Schema: webapi; Owner: ohdsi_admin_user
--
ALTER TABLE ONLY webapi.penelope_laertes_uni_pivot ALTER COLUMN id SET DEFAULT nextval('webapi.penelope_laertes_uni_pivot_id_seq'::regclass)
--
-- Data for Name: achilles_cache; Type: TABLE DATA; Schema: webapi; Owner: ohdsi_admin_user
--
COPY webapi.achilles_cache (id, source_id, cache_name, cache) FROM stdin
Error executing: COPY webapi.achilles_cache (id, source_id, cache_name, cache) FROM stdin
. Cause: org.postgresql.util.PSQLException: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API.
Where: COPY achilles_cache, line 1
Exception in thread "main" java.lang.RuntimeException: org.apache.ibatis.jdbc.RuntimeSqlException: Error executing: COPY webapi.achilles_cache (id, source_id, cache_name, cache) FROM stdin
. Cause: org.postgresql.util.PSQLException: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API.
Where: COPY achilles_cache, line 1
at org.yaorma.database.Database.executeSqlScript(Database.java:344)
at org.yaorma.database.Database.executeSqlScript(Database.java:332)
at org.nachc.tools.fhirtoomop.tools.build.postgres.build.A04_CreateAtlasWebApiTables.exec(A04_CreateAtlasWebApiTables.java:29)
at org.nachc.tools.fhirtoomop.tools.build.postgres.build.A04_CreateAtlasWebApiTables.main(A04_CreateAtlasWebApiTables.java:19)
Caused by: org.apache.ibatis.jdbc.RuntimeSqlException: Error executing: COPY webapi.achilles_cache (id, source_id, cache_name, cache) FROM stdin
. Cause: org.postgresql.util.PSQLException: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API.
Where: COPY achilles_cache, line 1
at org.apache.ibatis.jdbc.ScriptRunner.executeLineByLine(ScriptRunner.java:109)
at org.apache.ibatis.jdbc.ScriptRunner.runScript(ScriptRunner.java:71)
at org.yaorma.database.Database.executeSqlScript(Database.java:342)
... 3 more
Caused by: org.postgresql.util.PSQLException: ERROR: COPY from stdin failed: COPY commands are only supported using the CopyManager API.
Where: COPY achilles_cache, line 1
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2675)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2365)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:355)
at org.postgresql.jdbc.PgStatement.executeInternal(PgStatement.java:490)
at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:408)
at org.postgresql.jdbc.PgStatement.executeWithFlags(PgStatement.java:329)
at org.postgresql.jdbc.PgStatement.executeCachedSql(PgStatement.java:315)
at org.postgresql.jdbc.PgStatement.executeWithFlags(PgStatement.java:291)
at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:286)
at org.apache.ibatis.jdbc.ScriptRunner.executeStatement(ScriptRunner.java:190)
at org.apache.ibatis.jdbc.ScriptRunner.handleLine(ScriptRunner.java:165)
at org.apache.ibatis.jdbc.ScriptRunner.executeLineByLine(ScriptRunner.java:102)
... 5 more
1 ответ
Клиентский инструмент, который вы используете для восстановления дампа, не может обрабатывать данные из (нестандартной) команды COPY, подмешиваемые в скрипт. Вам нужно psql для восстановления такого дампа.
Вы можете использовать параметр --inserts для pg_dump, чтобы создать дамп, содержащий операторы INSERT, а не COPY. Это будет медленнее для восстановления, но будет работать с большим количеством клиентских инструментов.
Однако ваше желание получить стандартный SQL-скрипт безнадежно. PostgreSQL во многих отношениях расширяет стандарт, поэтому дамп базы данных нельзя создать с помощью стандартного сценария SQL. Обратите внимание, например, что индексы не определены стандартом SQL. Если вы хотите перенести дамп PostgreSQL в другую СУБД, вы будете разочарованы. Это сложнее.
0
Laurenz Albe
8 Янв 2023 в 07:42
I have been trying to access the sample database used for the majority of the exercises in the Packt book SQL for Data Analytics and it is making me feel like a failure before I can even get started. The instructions in the book say to copy the file data.dump from the Github page here and then to type psql < data.dump in the command line. Some users here were kind enough to help me get a little closer in this thread.
Unfortunately I am still unable to figure this out. I stored the data.dump file in the bin folder for postgreSQL12. Now when I type psql < «C:Program FilesPostgreSQL12bindata.dump» I am prompted to enter a password for my name. I have no idea what password this refers to. When I add U- postgres and enter the password I created for that user I am given the error
«syntax error at or near «2020»
LINE 1: 2020 Github, Inc. </li>»
I am not sure what this means but maybe that means I copied the file wrong?
I decided to try to just copy the text from the dump file and run it as a sql script in dBeaver (if there is a better alternative please feel free to let me know.) It first gave me an error at points in the script where the Owner sqldaadmin was used, owner of what I am not sure, but I changed it to postgres and that error did not occur again. Running the script again gave me the following error:
«Error occurred during SQL script execution
Reason: SQL Error [57014]: ERROR: COPY from stdin failed: The JDBC driver currently does not support COPY operations. Where: COPY closest_dealerships, line 1″
I do not know what this means, is JDBC something I can update?
I ignore this error and the rest of the script runs. The problem now is that I have no idea where the tables and other stuff the dump file created has gone. Any help would be greatly appreciated.
Sorry if this is not the right sub for this or if posts about the same topic are not allowed. This is driving me bananas.