Table 28. Error event IDs and error codes (continued)
Event
Notification
ID
type
Condition
010030
E
A managed disk error recovery procedure (ERP) has
occurred. The node or controller reported the following:
v Sense
v Key
v Code
v Qualifier
010031
E
One or more MDisks on a controller are degraded.
010032
W
The controller configuration limits failover.
010033
E
The controller configuration uses the RDAC mode; this is
not supported.
010034
E
Persistent unsupported controller configuration.
010040
E
The controller system device is only connected to the
node through a single initiator port.
010041
E
The controller system device is only connected to the
node through a single target port.
010042
E
The controller system device is only connected to the
clustered system nodes through a single target port.
010043
E
The controller system device is only connected to the
clustered system nodes through half of the expected
target ports.
010044
E
The controller system device has disconnected all target
ports to the clustered system nodes.
010050
W
A solid-state drive (SSD) failed. A rebuild is required.
010052
E
A solid-state drive (SSD) is offline as a result of a drive
hardware error.
010053
E
A solid-state drive (SSD) is reporting a predictive failure
analysis (PFA).
010054
E
A solid-state drive (SSD) is reporting too many errors.
010055
W
An unrecognized SAS device.
010056
E
SAS error counts exceeded the warning thresholds.
010057
E
SAS errors exceeded critical thresholds.
010058
E
The drive initialization failed because of an unknown
block size or a block size that is not valid; an unknown
capacity or a capacity that is not valid; or was not able to
set the required mode pages.
010059
E
A solid-state drive (SSD) is offline due to excessive
errors.
010060
E
A solid-state drive (SSD) exceeded the warning
temperature threshold.
010061
E
A solid-state drive (SSD) exceeded the offline
temperature threshold.
010062
E
A drive exceeded the warning temperature threshold.
010063
W
Drive medium error.
010066
W
Controller indicates that it does not support descriptor
sense for LUNs that are greater than 2 TBs.
Error
code
1370
1623
1625
1624
1695
1627
1627
1627
1627
1627
1201
1205
1215
1215
1665
1216
1216
1661
1311
1217
1218
1217
1321
1625
Chapter 9. Event reporting
131
Содержание
- Setting warning_threshold to 0 appears to incorrectly show a violation #2403
- Comments
- New Issue Checklist
- Describe the bug
- Environment
- Error count exceeded warning threshold
- Коды ошибок MegaRAID LSI / MegaRAID Event Messages
- Коды ошибок MegaRAID LSI / MegaRAID Event Messages
Setting warning_threshold to 0 appears to incorrectly show a violation #2403
New Issue Checklist
- Updated SwiftLint to the latest version
- I searched for existing GitHub issues
Describe the bug
Setting my warning_threshold to 0 appears to incorrectly show a violation
Complete output when running SwiftLint, including the stack trace and command used
Environment
- SwiftLint version (run swiftlint version to be sure)?
- Installation method used (Homebrew, CocoaPods, building from source, etc)?
CocoaPods - Paste your configuration file:
- Are you using nested configurations?
No.
If so, paste their relative paths and respective contents. - Which Xcode version are you using (check xcode-select -p )? Version 9.4.1 (9F2000)
- Do you have a sample that shows the issue? Run echo «[string here]» | swiftlint lint —no-cache —use-stdin —enable-all-rules
to quickly test if your example is really demonstrating the issue. If your example is more
complex, you can use swiftlint lint —path [file here] —no-cache —enable-all-rules .
Example showing violation
The text was updated successfully, but these errors were encountered:
The idea behind this setting was that if it was reached, the exit code would report an error. So if you set the threshold to 5, if you get 5 warnings or more SwiftLint would exit with an error code.
Your PR #2405 changes that behavior in a way that’s not backwards compatible.
I think what you want to use is —strict , which reports an error code if any warnings or errors are found. Or perhaps you want to set the warning threshold to 1.
Источник
Error count exceeded warning threshold

Коды ошибок MegaRAID LSI / MegaRAID Event Messages

Коды ошибок MegaRAID LSI-MegaRAID Event Messages
Всем привет, хочу поделиться с вами кодами ошибок MegaRAID LSI, хотя эта памятка больше для себя. Знание кодов ошибок сильно помогает с решением проблем и общению с технической поддержкой, где вы всегда можете понять степень риска ваших данных, можно ли еще подождать и не торопиться с заменой оборудования или же уже пора перевозить сервисы или виртуальные машины на запасные сервера.
Коды ошибок MegaRAID LSI / MegaRAID Event Messages
0x0000 Information MegaRAID firmware initialization started (PCI ID %04x/%04x/%04x/%04x)
0x0001 Information MegaRAID firmware version %s
0x0002 Fatal Unable to recover cache data from TBBU
0x0003 Information Cache data recovered from TBBU successfully
0x0004 Information Configuration cleared
0x0005 Warning Cluster down; communication with peer lost
0x0006 Information Virtual drive %s ownership changed from %02x to %02x
0x0007 Information Alarm disabled by user
0x0008 Information Alarm enabled by user
0x0009 Information Background initialization rate changed to %d%%
0x000a Fatal Controller cache discarded due to memory/battery problems
0x000b Fatal Unable to recover cache data due to configuration mismatch
0x000c Information Cache data recovered successfully
0x000d Fatal Controller cache discarded due to firmware version incompatibility
0x000e Information Consistency Check rate changed to %d%%
0x000f Fatal Fatal firmware error: %s
0x0010 Information Factory defaults restored
0x0011 Information Flash downloaded image corrupt
0x0012 Critical Flash erase error
0x0013 Critical Flash timeout during erase
0x0014 Critical Flash error
0x0015 Information Flashing image: %s
0x0016 Information Flash of new firmware image(s) complete
0x0017 Critical Flash programming error
0x0018 Critical Flash timeout during programming
0x0019 Critical Flash chip type unknown
0x001a Critical Flash command set unknown
0x001b Critical Flash verify failure
0x001c Information Flush rate changed to %d seconds
0x001d Information Hibernate command received from host
0x001e Information Event log cleared
0x001f Information Event log wrapped
0x0020 Fatal Multi-bit ECC error: ECAR=%x, ELOG=%x, (%s)
0x0021 Warning Single-bit ECC error: ECAR=%x, ELOG=%x, (%s)
0x0022 Fatal Not enough controller memory
0x0023 Information Patrol Read complete
0x0024 Information Patrol Read paused
0x0025 Information Patrol Read Rate changed to %d%%
0x0026 Information Patrol Read resumed
0x0027 Information Patrol Read started
0x0028 Information Rebuild rate changed to %d%%
0x0029 Information Drive group modification rate changed to %d%%
0x002a Information Shutdown command received from host
0x002b Information Test event: %s
0x002c Information Time established as %s; (%d seconds since power on)
0x002d Information User entered firmware debugger
0x002e Warning Background Initialization aborted on %s
0x002f Warning Background Initialization corrected medium error (%s at %lx
0x0030 Information Background Initialization completed on %s
0x0031 Fatal Background Initialization completed with uncorrectable errors on %s
0x0032 Fatal Background Initialization detected uncorrectable double medium errors (%s at %lx on %s)
0x0033 Critical Background Initialization failed on %s
0x0034 Progress Background Initialization progress on %s is %s
0x0035 Information Background Initialization started on %s
0x0036 Information Policy change on %s from %s to %s
0x0038 Warning Consistency Check aborted on %s
0x0039 Warning Consistency Check corrected medium error (%s at %lx
0x003a Information Consistency Check done on %s
0x003b Information Consistency Check done with corrections on %s
0x003c Fatal Consistency Check detected uncorrectable double medium errors (%s at %lx on %s)
0x003d Critical Consistency Check failed on %s
0x003e Fatal Consistency Check completed with uncorrectable data on %s
0x003f Warning Consistency Check found inconsistent parity on %s at strip %lx
0x0040 Warning Consistency Check inconsistency logging disabled on %s (too many inconsistencies)
0x0041 Progress Consistency Check progress on %s is %s
0x0042 Information Consistency Check started on %s
0x0043 Warning Initialization aborted on %s
0x0044 Critical Initialization failed on %s
0x0045 Progress Initialization progress on %s is %s
0x0046 Information Fast initialization started on %s
0x0047 Information Full initialization started on %s
0x0048 Information Initialization complete on %s
0x0049 Information LD Properties updated to %s (from %s)
0x004a Information Drive group modification complete on %s
0x004b Fatal Drive group modification of %s stopped due to unrecoverable errors
0x004c Fatal Reconstruct detected uncorrectable double medium errors (%s at %lx on %s at %lx)
0x004d Progress Drive group modification progress on %s is %s
0x004e Information Drive group modification resumed on %s
0x004f Fatal Drive group modification resume of %s failed due to configuration mismatch
0x0050 Information Modifying drive group started on %s
0x0051 Information State change on %s from %s to %s
0x0052 Information Drive Clear aborted on %s
0x0053 Critical Drive Clear failed on %s (Error %02x)
0x0054 Progress Drive Clear progress on %s is %s
0x0055 Information Drive Clear started on %s
0x0056 Information Drive Clear completed on %s
0x0057 Warning Error on %s (Error %02x)
0x0058 Information Format complete on %s
0x0059 Information Format started on %s
0x005a Critical Hot Spare SMART polling failed on %s (Error %02x)
0x005b Information Drive inserted: %s
0x005c Warning Drive %s is not supported
0x005d Warning Patrol Read corrected medium error on %s at %lx
0x005e Progress Patrol Read progress on %s is %s
0x005f Fatal Patrol Read found an uncorrectable medium error on %s at %lx
0x0060 Critical Predictive failure: CDB: %s
0x0061 Fatal Patrol Read puncturing bad block on %s at %lx
0x0062 Information Rebuild aborted by user on %s
0x0063 Information Rebuild complete on %s
0x0064 Information Rebuild complete on %s
0x0065 Critical Rebuild failed on %s due to source drive error
0x0066 Critical Rebuild failed on %s due to target drive error
0x0067 Progress Rebuild progress on %s is %s
0x0068 Information Rebuild resumed on %s
0x0069 Information Rebuild started on %s
0x006a Information Rebuild automatically started on %s
0x006b Critical Rebuild stopped on %s due to loss of cluster ownership
0x006c Fatal Reassign write operation failed on %s at %lx
0x006d Fatal Unrecoverable medium error during rebuild on %s at %lx
0x006e Information Corrected medium error during recovery on %s at %lx
0x006f Fatal Unrecoverable medium error during recovery on %s at %lx
0x0070 Information Drive removed: %s
0x0071 Warning Unexpected sense: %s, CDB%s, Sense: %s
0x0072 Information State change on %s from %s to %s
0x0073 Information State change by user on %s from %s to %s
0x0074 Warning Redundant path to %s broken
0x0075 Information Redundant path to %s restored
0x0076 Information Dedicated Hot Spare Drive %s no longer useful due to deleted drive group
0x0077 Critical SAS topology error: Loop detected
0x0078 Critical SAS topology error: Unaddressable device
0x0079 Critical SAS topology error: Multiple ports to the same SAS address
0x007a Critical SAS topology error: Expander error
0x007b Critical SAS topology error: SMP timeout
0x007c Critical SAS topology error: Out of route entries
0x007d Critical SAS topology error: Index not found
0x007e Critical SAS topology error: SMP function failed
0x007f Critical SAS topology error: SMP CRC error
0x0080 Critical SAS topology error: Multiple subtractive
0x0081 Critical SAS topology error: Table to table
0x0082 Critical SAS topology error: Multiple paths
0x0083 Fatal Unable to access device %s
0x0084 Information Dedicated Hot Spare created on %s (%s)
0x0085 Information Dedicated Hot Spare %s disabled
0x0086 Critical Dedicated Hot Spare %s no longer useful for all drive groups
0x0087 Information Global Hot Spare created on %s (%s)
0x0088 Information Global Hot Spare %s disabled
0x0089 Critical Global Hot Spare does not cover all drive groups
0x008a Information Created %s>
0x008b Information Deleted %s>
0x008c Information Marking LD %s inconsistent due to active writes at shutdown
0x008d Information Battery Present
0x008e Warning Battery Not Present
0x008f Information New Battery Detected
0x0090 Information Battery has been replaced
0x0091 Critical Battery temperature is high
0x0092 Warning Battery voltage low
0x0093 Information Battery started charging
0x0094 Information Battery is discharging
0x0095 Information Battery temperature is normal
0x0096 Fatal Battery needs to be replacement, SOH Bad
0x0097 Information Battery relearn started
0x0098 Information Battery relearn in progress
0x0099 Information Battery relearn completed
0x009a Critical Battery relearn timed out
0x009b Information Battery relearn pending: Battery is under charge
0x009c Information Battery relearn postponed
0x009d Information Battery relearn will start in 4 days
0x009e Information Battery relearn will start in 2 day
0x009f Information Battery relearn will start in 1 day
0x00a0 Information Battery relearn will start in 5 hours
0x00a1 Information Battery removed
0x00a2 Information Current capacity of the battery is below threshold
0x00a3 Information Current capacity of the battery is above threshold
0x00a4 Information Enclosure (SES) discovered on %s
0x00a5 Information Enclosure (SAFTE) discovered on %s
0x00a6 Critical Enclosure %s communication lost
0x00a7 Information Enclosure %s communication restored
0x00a8 Critical Enclosure %s fan %d failed
0x00a9 Information Enclosure %s fan %d inserted
0x00aa Critical Enclosure %s fan %d removed
0x00ab Critical Enclosure %s power supply %d failed
0x00ac Information Enclosure %s power supply %d inserted
0x00ad Critical Enclosure %s power supply %d removed
0x00ae Critical Enclosure %s SIM %d failed
0x00af Information Enclosure %s SIM %d inserted
0x00b0 Critical Enclosure %s SIM %d removed
0x00b1 Warning Enclosure %s temperature sensor %d below warning threshold
0x00b2 Critical Enclosure %s temperature sensor %d below error threshold
0x00b3 Warning Enclosure %s temperature sensor %d above warning threshold
0x00b4 Critical Enclosure %s temperature sensor %d above error threshold
0x00b5 Critical Enclosure %s shutdown
0x00b6 Warning Enclosure %s not supported; too many enclosures connected to port
0x00b7 Critical Enclosure %s firmware mismatch
0x00b8 Warning Enclosure %s sensor %d bad
0x00b9 Critical Enclosure %s phy %d bad
0x00ba Critical Enclosure %s is unstable
0x00bb Critical Enclosure %s hardware error
0x00bc Critical Enclosure %s not responding
0x00bd Information SAS/SATA mixing not supported in enclosure; Drive %s disabled
0x00be Information Enclosure (SES) hotplug on %s was detected, but is not supported
0x00bf Information Clustering enabled
0x00c0 Information Clustering disabled
0x00c1 Information Drive too small to be used for auto-rebuild on %s
0x00c2 Information BBU enabled; changing WT virtual drives to WB
0x00c3 Warning BBU disabled; changing WB virtual drives to WT
0x00c4 Warning Bad block table on drive %s is 80% full
0x00c5 Fatal Bad block table on drive %s is full; unable to log block %lx
0x00c6 Information Consistency Check Aborted due to ownership loss on %s
0x00c7 Information Background Initialization (BGI) Aborted Due to Ownership Loss on %s
0x00c8 Critical Battery/charger problems detected; SOH Bad
0x00c9 Warning Single-bit ECC error: ECAR=%x, ELOG=%x, (%s); warning threshold exceeded
0x00ca Critical Single-bit ECC error: ECAR=%x, ELOG=%x, (%s); critical threshold exceeded
0x00cb Critical Single-bit ECC error: ECAR=%x, ELOG=%x, (%s); further reporting disabled
0x00cc Critical Enclosure %s Power supply %d switched off
0x00cd Information Enclosure %s Power supply %d switched on
0x00ce Critical Enclosure %s Power supply %d cable removed
0x00cf Information Enclosure %s Power supply %d cable inserted
0x00d0 Information Enclosure %s Fan %d returned to normal
0x00d1 Information BBU Retention test was initiated on previous boot
0x00d2 Information BBU Retention test passed
0x00d3 Critical BBU Retention test failed!
0x00d4 Information NVRAM Retention test was initiated on previous boot
0x00d5 Information NVRAM Retention test passed
0x00d6 Critical NVRAM Retention test failed!
0x00d7 Information %s test completed %d passes successfully
0x00d8 Critical %s test FAILED on %d pass. Fail data: errorOffset=%x goodData=%x badData=%x
0x00d9 Information Self check diagnostics completed
0x00da Information Foreign Configuration detected
0x00db Information Foreign Configuration imported
0x00dc Information Foreign Configuration cleared
0x00dd Warning NVRAM is corrupt; reinitializing
0x00de Warning NVRAM mismatch occurred
0x00df Warning SAS wide port %d lost link on PHY %d
0x00e0 Information SAS wide port %d restored link on PHY %d
0x00e1 Warning SAS port %d, PHY %d has exceeded the allowed error rate
0x00e2 Warning Bad block reassigned on %s at %lx to %lx
0x00e3 Information Controller Hot Plug detected
0x00e4 Warning Enclosure %s temperature sensor %d differential detected
0x00e5 Information Drive test cannot start. No qualifying drives found
0x00e6 Information Time duration provided by host is not sufficient for self check
0x00e7 Information Marked Missing for %s on drive group %d row %d
0x00e8 Information Replaced Missing as %s on drive group %d row %d
0x00e9 Information Enclosure %s Temperature %d returned to normal
0x00ea Information Enclosure %s Firmware download in progress
0x00eb Warning Enclosure %s Firmware download failed
0x00ec Warning %s is not a certified drive
0x00ed Information Dirty cache data discarded by user
0x00ee Information Drives missing from configuration at boot
0x00ef Information Virtual drives (VDs) missing drives and will go offline at boot: %s
0x00f0 Information VDs missing at boot: %s
0x00f1 Information Previous configuration completely missing at boot
0x00f2 Information Battery charge complete
0x00f3 Information Enclosure %s fan %d speed changed
0x00f4 Information Dedicated spare %s imported as global due to missing arrays
0x00f5 Information %s rebuild not possible as SAS/SATA is not supported in an array
0x00f6 Information SEP %s has been rebooted as a part of enclosure firmware download. SEP will be unavailable until this process completes.
0x00f7 Information Inserted PD: %s Info: %s
0x00f8 Information Removed PD: %s Info: %s
0x00f9 Information VD %s is now OPTIMAL
0x00fa Warning VD %s is now PARTIALLY DEGRADED
0x00fb Critical VD %s is now DEGRADED
0x00fc Fatal VD %s is now OFFLINE
0x00fd Warning Battery requires reconditioning; please initiate a LEARN cycle
0x00fe Warning VD %s disabled because RAID-5 is not supported by this RAID key
0x00ff Warning VD %s disabled because RAID-6 is not supported by this controller
0x0100 Warning VD %s disabled because SAS drives are not supported by this RAID key
0x0101 Warning PD missing: %s
0x0102 Warning Puncturing of LBAs enabled
0x0103 Warning Puncturing of LBAs disabled
0x0104 Critical Enclosure %s EMM %d not installed
0x0105 Information Package version %s
0x0106 Warning Global affinity Hot Spare %s commissioned in a different enclosure
0x0107 Warning Foreign configuration table overflow
0x0108 Warning Partial foreign configuration imported, PDs not imported:%s
0x0109 Information Connector %s is active
0x010a Information Board Revision %s
0x010b Warning Command timeout on PD %s, CDB:%s
0x010c Warning PD %s reset (Type %02x)
0x010d Warning VD bad block table on %s is 80% full
0x010e Fatal VD bad block table on %s is full; unable to log block %lx (on %s at %lx)
0x010f Fatal Uncorrectable medium error logged for %s at %lx (on %s at %lx)
0x0110 Information VD medium error corrected on %s at %lx
0x0111 Warning Bad block table on PD %s is 100% full
0x0112 Warning VD bad block table on PD %s is 100% full
0x0113 Fatal Controller needs replacement, IOP is faulty
0x0114 Information CopyBack started on PD %s from PD %s
0x0115 Information CopyBack aborted on PD %s and src is PD %s
0x0116 Information CopyBack complete on PD %s from PD %s
0x0117 Progress CopyBack progress on PD %s is %s
0x0118 Information CopyBack resumed on PD %s from %s
0x0119 Information CopyBack automatically started on PD %s from %s
0x011a Critical CopyBack failed on PD %s due to source %s error
0x011b Warning Early Power off warning was unsuccessful
0x011c Information BBU FRU is %s
0x011d Information %s FRU is %s
0x011e Information Controller hardware revision ID %s
0x011f Warning Foreign import shall result in a backward incompatible upgrade of configuration metadata
0x0120 Information Redundant path restored for PD %s
0x0121 Warning Redundant path broken for PD %s
0x0122 Information Redundant enclosure EMM %s inserted for EMM %s Number Type Event Text
0x0123 Information Redundant enclosure EMM %s removed for EMM %s
0x0124 Warning Patrol Read can’t be started, as PDs are either not ONLINE, or are in a VD with an active process, or are in an excluded VD
0x0125 Information Copyback aborted by user on PD %s and src is PD %s
0x0126 Critical Copyback aborted on hot spare %s from %s, as hot spare needed for rebuild
0x0127 Warning Copyback aborted on PD %s from PD %s, as rebuild required in the array
0x0128 Fatal Controller cache discarded for missing or offline VD %s. When a VD with cached data goes offline or missing during runtime,
the cache for the VD is discarded. Because the VD isoffline, the cache cannot be saved.
0x0129 Information Copyback cannot be started as PD %s is too small for src PD %s
0x012a Information Copyback cannot be started on PD %s from PD %s, as SAS/SATA is not supported in an array
0x012b Information Microcode update started on PD %s
0x012c Information Microcode update completed on PD %s
0x012d Warning Microcode update timeout on PD %s
0x012e Warning Microcode update failed on PD %s
0x012f Information Controller properties changed
0x0130 Information Patrol Read properties changed
0x0131 Information CC Schedule properties changed
0x0132 Information Battery properties changed
0x0133 Warning Periodic Battery Relearn is pending. Please initiate manual learn cycle as Automatic learn is not enabled
0x0134 Information Drive security key created
0x0135 Information Drive security key backed up
0x0136 Information Drive security key from escrow, verified
0x0137 Information Drive security key changed
0x0138 Warning Drive security key, re-key operation failed
0x0139 Warning Drive security key is invalid
0x013a Information Drive security key destroyed
0x013b Warning Drive security key from escrow is invalid
0x013c Information VD %s is now secured
0x013d Warning VD %s is partially secured
0x013e Information PD %s security activated
0x013f Information PD %s security disabled
0x0140 Information PD %s is reprovisioned
0x0141 Information PD %s security key changed
0x0142 Fatal Security subsystem problems detected for PD %s
0x0143 Fatal Controller cache pinned for missing or offline VD %s
0x0144 Fatal Controller cache pinned for missing or offline VDs: %s
0x0145 Information Controller cache discarded by user for VDs: %s
0x0146 Information Controller cache destaged for VD %s
0x0147 Warning Consistency Check started on an inconsistent VD %s
0x0148 Warning Drive security key failure, cannot access secured configuration
0x0149 Warning Drive security password from user is invalid
0x014a Warning Detected error with the remote battery connector cable
0x014b Information Power state change on PD %s from %s to %s
0x014c Information Enclosure %s element (SES code 0x%x) status changed
0x014d Information PD %s rebuild not possible as HDD/SSD mix is not supported in a drive group
0x014e Information Copyback cannot be started on PD %s from %s, as HDD/SSD mix is not supported in a drive group
0x014f Information VD bad block table on %s is cleared
0x0150 Caution SAS topology error: 0x%lx[/wpspoiler]
Вот такой полезный список ошибок MegaRAID LSI / MegaRAID Event Messages
Источник
Table 53. Error event IDs and error codes (continued) Event ID Notification type Condition 144 <strong>SAN</strong> <strong>Volume</strong> <strong>Controller</strong>: <strong>Troubleshooting</strong> <strong>Guide</strong> Error code 009171 W The FlashCopy feature capacity is not set. 3031 009172 W The Virtualization feature has exceeded the amount that is licensed. 3032 009173 W The FlashCopy feature has exceeded the amount that is licensed. 3032 009174 W The Metro Mirror or Global Mirror feature has exceeded the amount that is licensed. 3032 009175 W The usage for the thin-provisioned volume is not licensed. 3033 009176 W The value set for the virtualization feature capacity is not valid. 3029 009177 E A physical disk FlashCopy feature license is required. 3035 009178 E A physical disk Metro Mirror and Global Mirror feature license is required. 3036 009179 E A virtualization feature license is required. 3025 009180 E Automatic recovery of offline node failed. 1194 009181 W Unable to send email to any of the configured email servers. 3081 009182 W The external virtualization feature license limit was exceeded. 3032 009183 W Unable to connect to LDAP server. 2251 009184 W The LDAP configuration is not valid. 2250 009185 E The limit for the compression feature license was exceeded. 3032 009186 E The limit for the compression feature license was exceeded. 3032 010002 E The node ran out of base event sources. As a result, the node has stopped and exited the system. 2030 010003 W The number of device logins has reduced. 1630 010006 E A software error has occurred. 2030 010008 E The block size is invalid, the capacity or LUN identity has changed during the managed disk initialization. 1660 010010 E The managed disk is excluded because of excessive errors. 1310 010011 E The remote port is excluded for a managed disk and node. 1220 010012 E The local port is excluded. 1210 010013 E The login is excluded. 1230 010017 E A timeout has occurred as a result of excessive processing time. 1340 010018 E An error recovery procedure has occurred. 1370 010019 E A managed disk I/O error has occurred. 1310 010020 E The managed disk error count threshold has exceeded. 1310
Table 53. Error event IDs and error codes (continued) Event ID Notification type Condition Error code 010021 W There are too many devices presented to the cluster (system). 1200 010022 W There are too many managed disks presented to the cluster (system). 1200 010023 W There are too many LUNs presented to a node. 1200 010024 W There are too many drives presented to a cluster (system). 1200 010025 W A disk I/O medium error has occurred. 1320 010026 W A suitable MDisk or drive for use as a quorum disk was not found. 1330 010027 W The quorum disk is not available. 1335 010028 W A controller configuration is not supported. 1625 010029 E A login transport fault has occurred. 1360 010030 E A managed disk error recovery procedure (ERP) has occurred. The node or controller reported the following: 1370 v Sense v Key v Code v Qualifier 010031 E One or more MDisks on a controller are degraded. 1623 010032 W The controller configuration limits failover. 1625 010033 E The controller configuration uses the RDAC mode; this is not supported. 1624 010034 E Persistent unsupported controller configuration. 1695 010040 E The controller system device is only connected to the node through a single initiator port. 1627 010041 E The controller system device is only connected to the node through a single target port. 1627 010042 E The controller system device is only connected to the cluster (system) nodes through a single target port. 1627 010043 E The controller system device is only connected to the cluster (system) nodes through half of the expected target ports. 1627 010044 E The controller system device has disconnected all target ports to the cluster (system) nodes. 1627 010055 W An unrecognized SAS device. 1665 010056 E SAS error counts exceeded the warning thresholds. 1216 010057 E SAS errors exceeded critical thresholds. 1216 010066 W <strong>Controller</strong> indicates that it does not support descriptor sense for LUNs that are greater than 2 TBs. 1625 010067 W Too many enclosures were presented to a cluster (system). 1200 010070 W Too many controller target ports were presented to the cluster (system). 1200 Chapter 7. Diagnosing problems 145
- Page 1 and 2:
IBM System Storage SAN Volume Contr
- Page 3 and 4:
| | Contents Figures . . . . . . .
- Page 5 and 6:
International Electrotechnical Comm
- Page 7 and 8:
Figures 1. SAN Volume Controller sy
- Page 9 and 10:
Tables 1. Terminology mapping table
- Page 11 and 12:
| | | | About this guide Who should
- Page 13 and 14:
v Support statements for 10 Gbps Et
- Page 15 and 16:
Table 3. SAN Volume Controller libr
- Page 17 and 18:
Table 4. Other IBM publications (co
- Page 19 and 20:
Chapter 1. SAN Volume Controller ov
- Page 21 and 22:
| | Hosts send I/O to volumes. Node
- Page 23 and 24:
Systems applications on the hosts.
- Page 25 and 26:
SAN fabric overview Ethernet router
- Page 27 and 28:
Chapter 2. Introducing the SAN Volu
- Page 29 and 30:
Figure 7 shows the controls and ind
- Page 31 and 32:
You can select the language that is
- Page 33 and 34:
▌4▐ System-information LED ▌5
- Page 35 and 36:
Figure 14 shows the operator-inform
- Page 37 and 38:
Ethernet-activity LED An Ethernet-a
- Page 39 and 40:
Figure 19. Power connector Neutral
- Page 41 and 42:
▌5▐ Power-cord connector for po
- Page 43 and 44:
5 ▌1▐ Fibre Channel port 1 ▌2
- Page 45 and 46:
▌1▐ Fibre Channel port 1 ▌2
- Page 47 and 48:
▌4▐ Fibre Channel port 4 ▌5
- Page 49 and 50:
7 Ac and dc LEDs SAN Volume Control
- Page 51 and 52:
Ethernet port. The bottom LED is th
- Page 53 and 54:
Ac LED The upper LED (▌1▐) indi
- Page 55 and 56:
Circuit breaker requirements The 21
- Page 57 and 58:
Input-voltage requirements Ensure t
- Page 59 and 60:
Location Additional space requireme
- Page 61 and 62:
Dimensions and weight Ensure that s
- Page 63 and 64:
Preparing your environment The foll
- Page 65 and 66:
Environment Temperature Altitude Sh
- Page 67 and 68:
Ensure that space is available in a
- Page 69 and 70:
Uninterruptible power supply The si
- Page 71 and 72:
▌1▐ Load segment 2 indicator
- Page 73 and 74:
Figure 50. 2145 UPS-1U connectors a
- Page 75 and 76:
microprocessor, memory module, CMOS
- Page 77 and 78:
Table 19. SAN Volume Controller 214
- Page 79 and 80:
Table 22. 2145 UPS-1U FRU descripti
- Page 81 and 82:
Table 24. SAN Volume Controller 214
- Page 83 and 84:
Table 26. SAN Volume Controller 214
- Page 85 and 86:
Chapter 3. SAN Volume Controller us
- Page 87 and 88:
www.ibm.com/storage/support/2145 Yo
- Page 89 and 90:
in the I/O group is offline. Fabric
- Page 91 and 92:
Adding nodes to a system by using t
- Page 93 and 94:
v Upgrade software on nodes manuall
- Page 95 and 96:
Chapter 4. Performing recovery acti
- Page 97 and 98:
When you issue the repairsevdiskcop
- Page 99 and 100:
v All errors in the system event lo
- Page 101 and 102:
can change, which impacts the abili
- Page 103 and 104:
previous node. The multipathing dev
- Page 105 and 106:
Chapter 5. Viewing the vital produc
- Page 107 and 108:
About this task Perform the followi
- Page 109 and 110:
Table 29 shows the fields that you
- Page 111 and 112: Table 36. Fields that are provided
- Page 113 and 114: Table 41. Fields that are provided
- Page 115 and 116: Chapter 6. Using the front panel of
- Page 117 and 118: Power failure Powering off The node
- Page 119 and 120: Validate WWNN? option The front pan
- Page 121 and 122: Main Options Secondary Options R /
- Page 123 and 124: The IPv4 subnet mask addresses are
- Page 125 and 126: No Cluster This node is not a membe
- Page 127 and 128: Table 42. When options are availabl
- Page 129 and 130: Enter Service? Exit Service? Recove
- Page 131 and 132: Cluster IPv4 or Cluster IPv6 option
- Page 133 and 134: or down button is pressed and held
- Page 135 and 136: increase the highlighted value, hol
- Page 137 and 138: IPv6 Address option The IPv6 Addres
- Page 139 and 140: To exit service state, ensure that
- Page 141 and 142: About this task To select the langu
- Page 143 and 144: Chapter 7. Diagnosing problems Even
- Page 145 and 146: Managing the event log The event lo
- Page 147 and 148: Events with notification type Error
- Page 149 and 150: v Object ID v Problem data Inventor
- Page 151 and 152: Table 47. Informational events Noti
- Page 153 and 154: Table 47. Informational events (con
- Page 155 and 156: Table 48. Configuration event IDs (
- Page 157 and 158: Table 48. Configuration event IDs (
- Page 159 and 160: SCSI Sense Nodes notify the hosts o
- Page 161: Table 52. Object types (continued)
- Page 165 and 166: Table 53. Error event IDs and error
- Page 167 and 168: Table 53. Error event IDs and error
- Page 169 and 170: Table 53. Error event IDs and error
- Page 171 and 172: Table 53. Error event IDs and error
- Page 173 and 174: Booting 130 Figure 67. Example of a
- Page 175 and 176: You must perform software problem a
- Page 177 and 178: | | | | | transceiver with the same
- Page 179 and 180: FRU replacement Ensure that you are
- Page 181 and 182: Chapter 8. Recovery procedures Reco
- Page 183 and 184: — If you have not been able to rest
- Page 185 and 186: About this task Attention: This ser
- Page 187 and 188: The volumes are online. Use the fin
- Page 189 and 190: v Manual actions might be necessary
- Page 191 and 192: v If the ID of the object is differ
- Page 193 and 194: where offclusterstorage is the name
- Page 195 and 196: 10. Issue the following CLI command
- Page 197 and 198: 4. Turn off the node. 5. Press and
- Page 199 and 200: Chapter 9. Understanding the medium
- Page 201 and 202: Chapter 10. Using the maintenance a
- Page 203 and 204: When the SAN Volume Controller syst
- Page 205 and 206: Has the progress bar stalled? NO Go
- Page 207 and 208: 2) From the Disk WWNN: panel, press
- Page 209 and 210: 1 1 1 2145-CF8 2145-8G4 2145-8F4 21
- Page 211 and 212: Figure 78. Power LED on the SAN Vol
- Page 213 and 214:
Replace the SAN Volume Controller 2
- Page 215 and 216:
MAP 5060: Power 2145-8A4 MAP 5060:
- Page 217 and 218:
Figure 83. SAN Volume Controller 21
- Page 219 and 220:
Before you begin If you are not fam
- Page 221 and 222:
Table 56. 2145 UPS-1U error indicat
- Page 223 and 224:
e. Verify the repair by continuing
- Page 225 and 226:
MAP 5320: Redundant ac power YES Co
- Page 227 and 228:
2. Use the management GUI or the CL
- Page 229 and 230:
v The other node in the I/O group s
- Page 231 and 232:
UPS_unique_id 1:group1node1:10L3ASH
- Page 233 and 234:
MAP 5400: Front panel its write cac
- Page 235 and 236:
| | MAP 5500: Ethernet 6. (from ste
- Page 237 and 238:
▌4▐ SAN Volume Controller 2145-
- Page 239 and 240:
| | | | This MAP applies to the SAN
- Page 241 and 242:
MAP 5600: Fibre Channel a. Replace
- Page 243 and 244:
6. (from step 5 on page 224) Is the
- Page 245 and 246:
Note: After the node joins the syst
- Page 247 and 248:
Table 57. SAN Volume Controller Fib
- Page 249 and 250:
MAP 5800: Light path YES Go to step
- Page 251 and 252:
oth ends. If the error LED is still
- Page 253 and 254:
▌15▐ Power channel A error LED
- Page 255 and 256:
Table 59. Diagnostics panel LED pre
- Page 257 and 258:
oth ends. If the error LED is still
- Page 259 and 260:
▌17▐ Power channel B error LED
- Page 261 and 262:
Table 60. Diagnostics panel LED pre
- Page 263 and 264:
Go to step 5 on page 246. YES Ident
- Page 265 and 266:
Figure 97. SAN Volume Controller 21
- Page 267 and 268:
▌11▐ DIMM 2 error LED ▌12▐
- Page 269 and 270:
Figure 100. SAN Volume Controller 2
- Page 271 and 272:
▌13▐ DIMM 5 error LED ▌14▐
- Page 273 and 274:
Before you begin If you are not fam
- Page 275 and 276:
Model type: 2145-8G4 Model type: 21
- Page 277 and 278:
a. Turn off the node while ensuring
- Page 279 and 280:
Procedure 1. Record the properties
- Page 281 and 282:
Attention: 1. Back up your SAN Volu
- Page 283 and 284:
Appendix. Accessibility features fo
- Page 285 and 286:
Notices This information was develo
- Page 287 and 288:
Trademarks Electronic emission noti
- Page 289 and 290:
IBM Deutschland GmbH Technical Regu
- Page 291 and 292:
Russia Electromagnetic Interference
- Page 293 and 294:
Index Numerics 10 Gbps Ethernet lin
- Page 295 and 296:
FCC (Federal Communications Commiss
- Page 297 and 298:
node (continued) options (continued
- Page 299 and 300:
SAN Volume Controller 2145-8G4 (con
- Page 302:
Part Number: 31P1671 Printed in USA
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
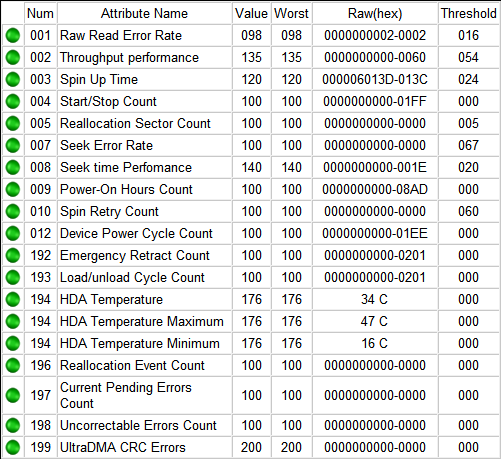
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном  |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
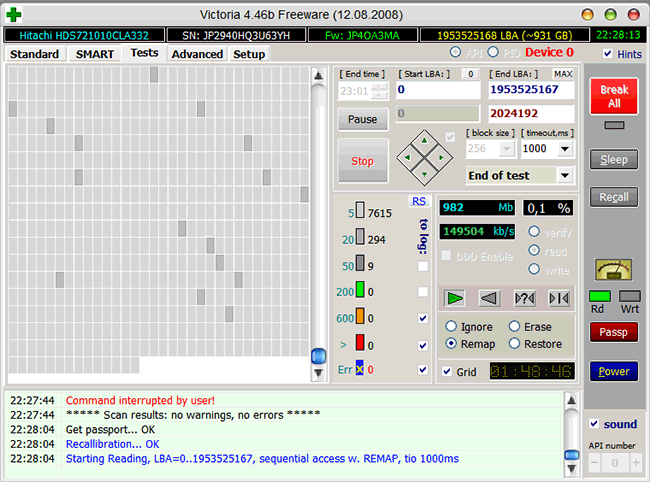
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
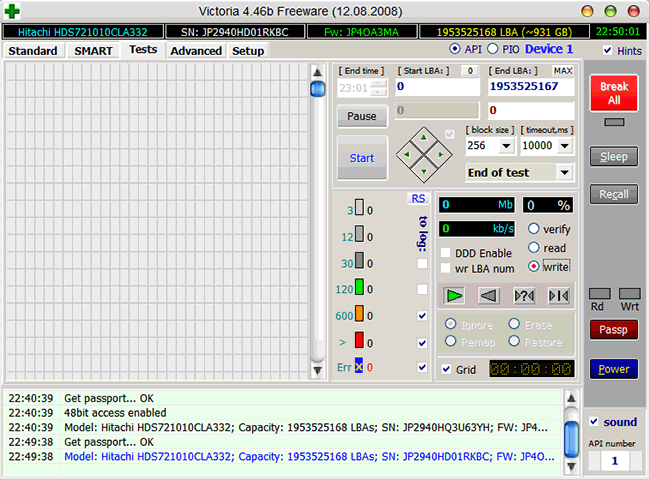
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
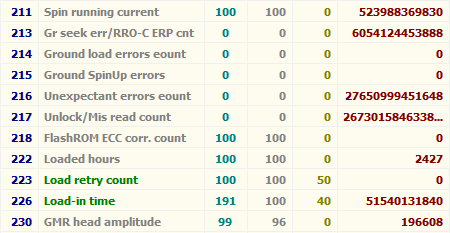
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).